文章目录
- 深度图
- 深度图是什么
- 深度图的获取方式
- 激光雷达或结构光等传感器的方法
- 激光雷达
- RGB-D相机
- 双目或多目相机的视差信息计算深度
- 采用深度学习模型估计深度
- 深度图的应用场景
- 扩展阅读
深度图
深度图是什么
深度图(depth map)是一种灰度图像,其中每个像素点距离相机的距离信息。它是计算机视觉中常用的一种图像表示方式,用于描述场景的三维结构。

用张图简单直白的表示就是,越红的地方,代表距离观察者(即屏幕)的距离越近。看到图片中的锥体,距离我们观察的位置举例会比较近,所以颜色的更红。而图中的面具,由于是倾斜摆放的,其底部距离我们会更近一点,所以其底部的颜色要比顶部的颜色更红一些。
深度图的获取方式
深度图的发展历史可以追溯到20世纪60年代。最初,深度图像是通过手工标注或利用先验知识推测出来的。随着计算机视觉技术的发展,深度图像的获取方法和算法也不断进步和完善。
深度图的获取方式有多种,常见的方法包括:
-
通过激光雷达或结构光等传感器获取深度信息,再将其转换为深度图像。
-
利用双目或多目相机的视差信息计算深度,再将其转换为深度图像。
-
利用先验知识或模型对图像进行分析,推测出每个像素点的深度信息。
激光雷达或结构光等传感器的方法
激光雷达或结构光等传感器获得的深度,可以得到绝对深度,因为他们的数据是测出来的,根据TOF计算得到的真实距离。所以在连续的图片序列中,由于深度是绝对的,他们具有一样的参考价值。
激光雷达
这种方法也被叫做TOF方法(Time Of Fly)即通过激光/雷达波发出和收到的时间差,结合光速,计算信号在这段时间所走过的路程,所以也就能获得不同物体距离激光发射点的距离了。

RGB-D相机
另外,除了雷达之外激光雷达相机也可以实现类似的效果,也可以利用激光雷达和结构光的配合,获得更加精准的深度数值


双目或多目相机的视差信息计算深度
我们可以模拟人眼的工作方式,使用两个摄像机,这种方法被称为立体视觉。
在下图中,p是空间一点,z是其深度,Ol和Or是左右两个相机,对应上述的O和O’。f是相机焦距。
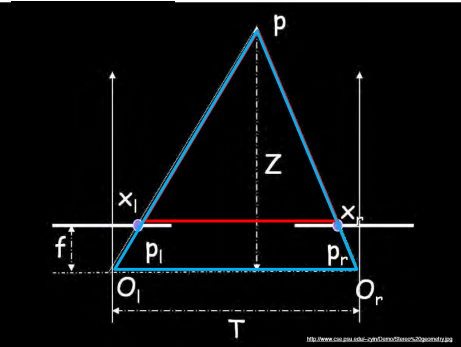
根据相似三角形的公式:
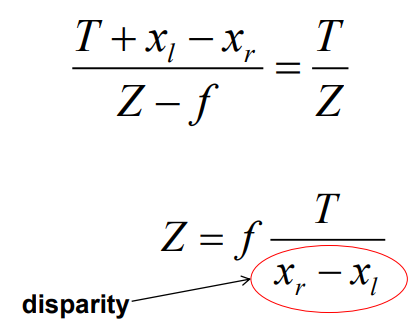
相机的焦距,两相机的距离都是已知的,这样我们可以轻松地知道一个点的深度与x和x’的查成反比,从而得到图中所有点的深度图。
OpenCV也提供了相关的计算函数:

这样我们就能够大致计算出图中的深度了:

可能你会想问,上面的深度图片都是彩色的,为什么这张变成和黑白的,但实际上
这才是深度图本来的样子
我们通过OpenCV的apploycolor map函数对灰度图进行了颜色的映射,让结果看起来更加的生动和fancy。
下面给一个示例来说明applyColorMap的作用:
def ColorMap_demo():img = cv.imread("lena.jpg",cv.IMREAD_GRAYSCALE)if img.shape[0]==0:print("load image fail!")returnwindowname="applyColorMap"cv.namedWindow(windowname,cv.WINDOW_AUTOSIZE)pos=0cv.createTrackbar("Type",windowname,pos,22,callback_trackbar)while True:pos = cv.getTrackbarPos("Type",windowname)imgdst = np.copy(img)if pos != 0 :imgdst = cv.applyColorMap(img,pos-1)cv.imshow(windowname,imgdst)if cv.waitKey(10) == 27:break
if __name__ == "__main__":ColorMap_demo()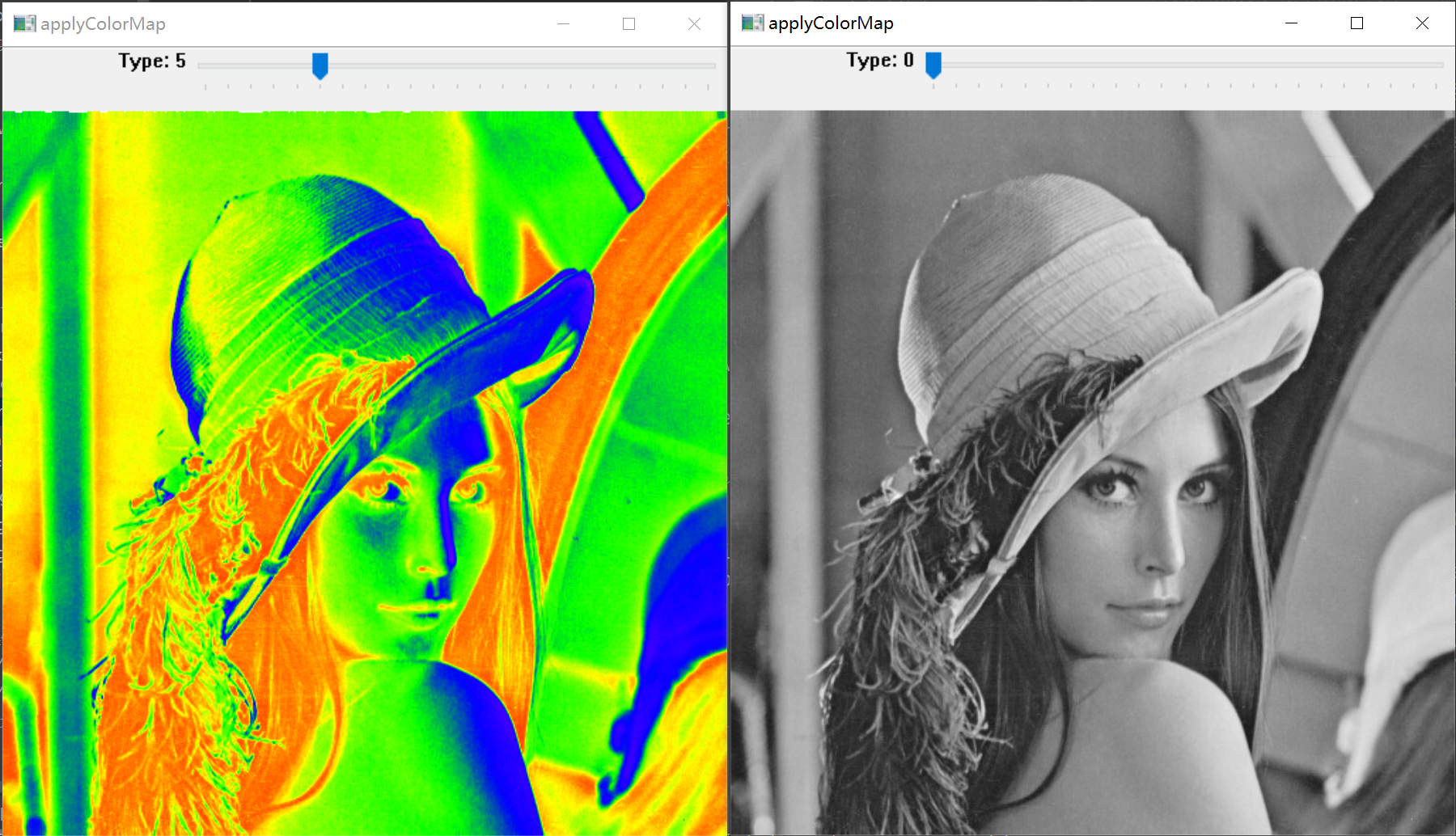

通过双目或多目相机获得的深度,也是绝对的深度,因为其原理是通过固定位置相机的相似三角形计算距离的。所以在连续的图片序列中,由于深度是绝对的,他们具有一样的参考价值。
采用深度学习模型估计深度
典型的采用深度学习的方式来估计RGB图像的深度的方法如下所示:
- 从RGBD相机的输出结果中,获取深度分量,得到真实的深度图。
- 仅输入RGB图,让模型生成对应的深度估计图
- 对模型的深度估计图和实际的深度图求差,获取估计的误差
- 深度学习网络的优化目标即为减小估计深度与实际深度的误差
- 在经过大量的训练之后,就能获得一个可以根据RGB图估计深度图的网络了

这里主要是指用模型估计图片中的物体深度,这样的方式获得的结果,在一张图片中不同的像素点之间的相对深度差,但是在在连续的图片序列中,两帧之间的深度估计结果没有必然的联系。例如,假设上面的面具是一个视频序列,在第一帧面具左眼的深度为100,面具右眼的深度估计为110.第二帧中,面具的左眼的深度可能是1000,而右眼的深度可能为1010。
可以发现,两帧之间同一区域的深度,在采用深度学习模型估计的时候,其绝对值结果是没有参考价值的:例如同样都是左眼,在第一帧中的深度和第二帧的深度估计数值甚至不在一个量级。
但是一帧内的不同位置,其相对深度是具有参考性的:例如不论在哪一帧,左眼和右眼的深度差始终为10.
这也正是由于深度学习模型训练的时候的策略所导致的,单目预测深度基本都是这种的拟合回归,本身数学上就是一个病态问题,不可能从单张2D的图片恢复出三维的信息。因为本身就是缺少信息的。
深度图的应用场景
-
三维重建:深度图可用于创建三维模型,例如建筑物、雕塑、人体等。
-
虚拟现实:深度图可用于创建虚拟现实环境,例如游戏、培训模拟器等。
-
自动驾驶:深度图可用于帮助自动驾驶汽车识别道路、障碍物和其他车辆。
-
医学成像:深度图可用于医学成像,例如X射线、CT扫描和MRI。
-
图层分隔:判断图片素材中物体的远近关系,实现图层前后信息的获取。
这里可以举一个自动驾驶的例子,即通过激光雷达获取周围的环境信息,用来感知各种物体与车体的距离。

扩展阅读
显著图(Saliency Map)