作者:SmartX SKS 产品研发工程师 杨海剑

背景
容器的发展催生了容器编排技术,而容器编排技术反过来又推动了容器的发展。容器编排领域则一度出现了 Swarm、Mesos 和 Kubernetes 等百家争鸣的局面。但随着 Kubernetes 脱颖而出,Kubernetes 成为了容器编排领域的事实标准。
带来的问题
Kubernetes 提升了软件自动化运维的效率,为破解降本增效难题带来了新的思路。但同时 Kubernetes 的复杂性也带来了新的挑战。
认知复杂
Borg 是 Google 多年大规模应用容器技术的经验积累产物,而 Kubernetes 则是 Borg 的开源升华。Kubernetes 本身是一个复杂的分布式系统,涉及较多的复杂技术和概念,需要一定的学习成本和经验才能驾驭。
运维复杂
我们需要负责 Kubernetes 的创建、更新、高可用等运维工作。只有保证 Kubernetes 的稳定性,基于 Kubernetes 的云原生平台才有高可用的可能性。
我们可能有不同环境(测试、生产等)、不同产品线、不同团队需要独立环境的需求,这样就带来了 Kubernetes 多集群管理的复杂度。
基于成本或高可用等因素的考虑,我们可能会选择混合和多云架构。我们需要在自己的私有云管理 Kubernetes 集群,同时也需要使用公有云的 Kubernetes 集群。而不同云平台的 Kubernetes 集群的管理往往是相互独立的,这样就带来了跨云的集群管理复杂度。
Kubernetes 进阶之路
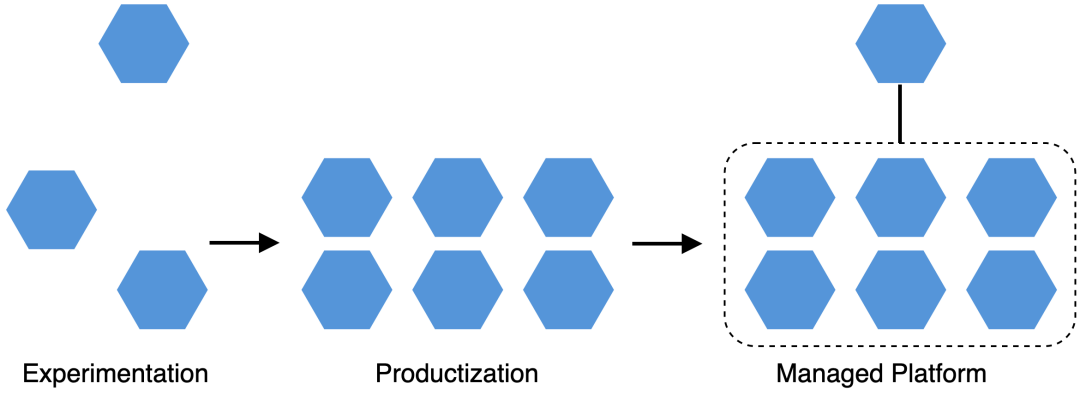
一般我们对 Kubernetes 的使用大致分为三个阶段:
-
探索阶段
-
推广阶段
-
平台化阶段
探索阶段
当前 Kubernetes 还处于不断发展演进的阶段,拥有 Kubernetes 丰富经验的工程师并不多。在引入 Kubernetes 的初始阶段,我们可能会先选择个别项目进行容器化试验探索。这样的好处是可以验证 Kubernetes 落地的可行性,以及积累相关经验。
普及阶段
在经过探索阶段的验证后,我们认识到了 Kubernetes 的价值,开始在内部推广 Kubernetes,更多的项目开始进行容器化改造。Kubernetes 应用到更多的场景(AI、大数据、物联网等),也许还需要对 Kubernetes 进行一些定制化或者生态扩展。
平台化阶段
在经历了普及阶段之后,随着 Kubernetes 更多、更深入的使用,各种相关的功能和需求(多租户、微服务等)整合之后,逐渐演进成一个云原生平台。
如果有一个合适的云原生平台方案,可以灵活满足不同阶段对于 Kubernetes 的需求,可以一定程度降低使用成本和提高效率。
Kubernetes LCM
云原生的核心之一是 Kubernetes,而 Kubernetes 的核心之一是集群生命周期管理(LCM)。解决了 LCM 的问题,可以一定程度上降低 Kubernetes 的使用成本。本文将主要探讨 LCM 相关问题。
LCM 包括但不局限于:
-
集群创建。
-
集群删除。
-
集群扩缩容,增加或减少节点数。
-
集群升级,集群从低版本升级到更高的版本。
-
集群故障恢复,集群出现故障。例如某节点故障,修复节点故障集群恢复正常工作。
Kubernetes LCM 现状
社区目前常用 kubeadm、kOps、kubespray、RKE、kubekey 等工具创建、扩容和升级集群。公有云和私有云则有自己的 Kubernetes 服务,但这些服务一般仅限本平台,对跨平台支持不友好。此外还有 Rancher、KubeSphere 等开源或商业化的容器平台,但它们没有通用的多平台支持,LCM 功能不丰富或是不够自动化。
以上 LCM 方案可能存在的问题:
-
需要掌握一定的 Kubernetes 相关知识和经验。
-
不够自动化,需要手工管理,使用命令行工具或没有 UI,效率低,容易出错。
-
没有统一的技术标准,各自有自己的技术方案,可扩展性不强。
-
跨平台支持不够。
Cluster API
Cluster API(CAPI)是一个 Kubernetes 声明式 API 风格的多 Kubernetes 集群生命周期管理项目。CAPI 的目标是简化 Kubernetes LCM,使得 LCM 自动化,并支持不同的 IaaS(AWS EC2、VMware vSphere 等)。
SMTX Kubernetes 服务(SMTX Kubernetes Service,简称 “SKS”)是 SmartX 企业云基础设施提供的 Kubernetes 服务。SKS 集成了 Cluster API,基于 SmartX 虚拟化、分布式存储、网络与安全等产品组件,可自动创建多台虚拟机以构建高可用的 Kubernetes 集群。
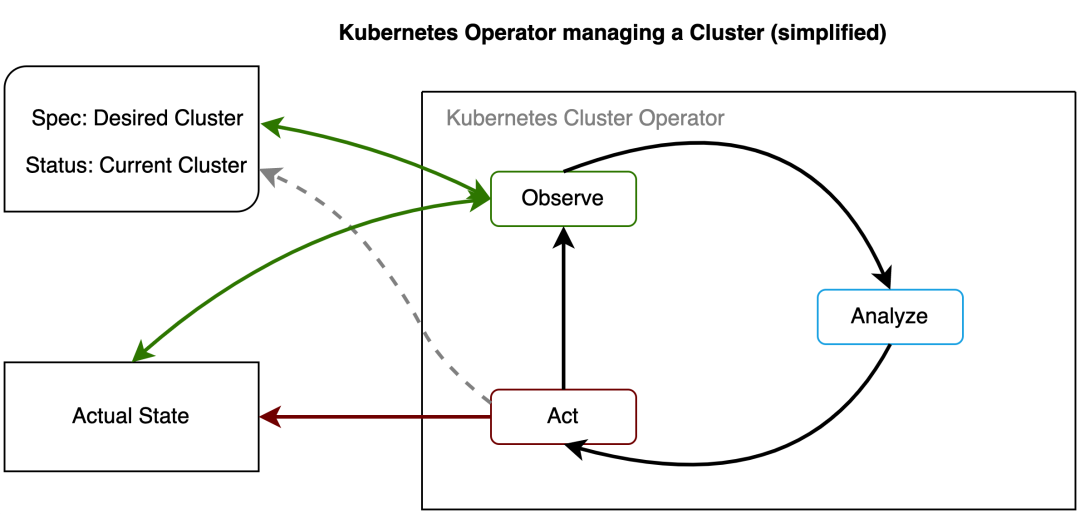
声明式 API
Kubernetes 声明式 API 通过 Resource + Controller 的模式实现。Resource 包括 Kubernetes 原生资源(Pod 等)和自定义资源(CRD)。每个资源对象包含 Spec 表示资源对象预期是什么样的,Status 表示预期资源对象当前的实际状态,Controller 则负责把资源达到预期的 Spec 状态。
在此基础上,Kubernetes 社区发展出了 Operator 模式,用来管理应用和基础设施资源(例如 prometheus-operator)。
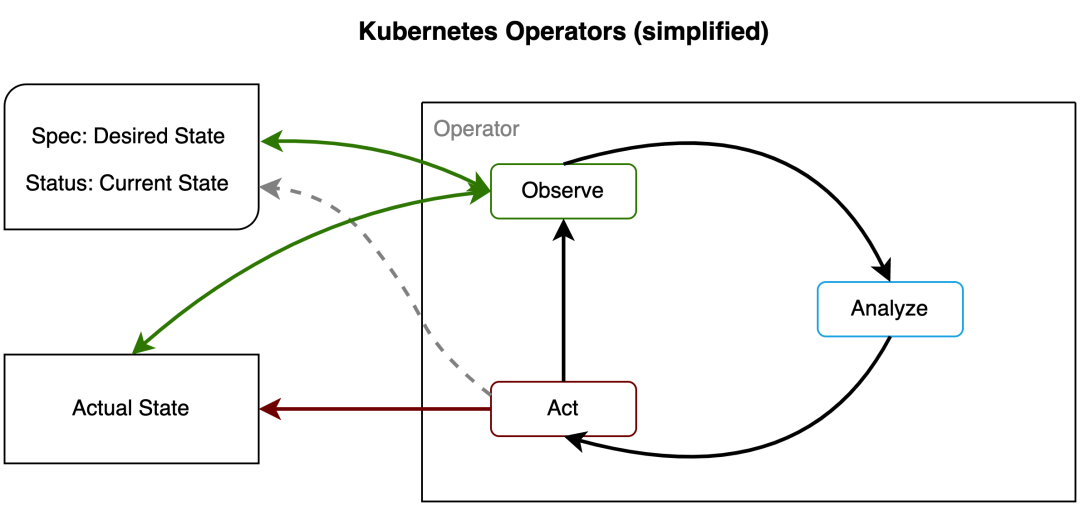
Kubernetes 声明式 API 具有组合的特点,不同的 API 可以组合使用,达到功能扩展的目的。例如 Deployment + ReplicaSet + Pod 组合实现多版本应用部署管理。
声明式 Cluster API
目前常见通过声明式的方式管理分布式系统,而 Kubernetes 本身也是分布式系统,所以通过声明式管理 Kubernetes 集群是合适的。
CAPI 属于 Kubernetes Cluster Lifecycle 生态中的子项目,使用 Kubernetes 声明式风格也是比较天然的(K8s-on-K8s)。可以借用 Kubernetes 生态的优势,同时社区用户也更容易理解和使用。
声明式可以带来以下好处:
-
使用配置文件描述最终状态,不需要考虑流程和目标环境的细节。
-
重复操作不会产生不一致的效果。
-
天然符合不可变基础设施的理念。
-
声明式自愈保证高可用。
工作原理
根据 Kubernetes 声明式 API 的特点,当我们需要一个 Kubernetes 集群的时候,可以通过一个 CRD 定义并描述我们的需求。CAPI 定义了 Cluster 用来描述 Kubernetes 集群。
apiVersion: cluster.x-k8s.io/v1beta1kind: Clustermetadata:name: myclusternamespace: defaultspec: # 集群的规格status: # 集群的当前状态
CAPI controllers 根据 Cluster 创建并管理集群。
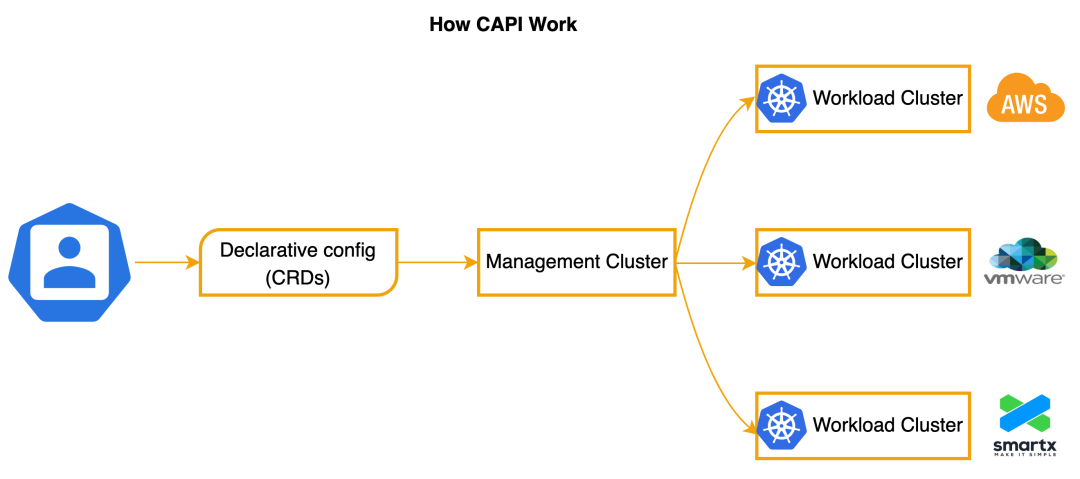
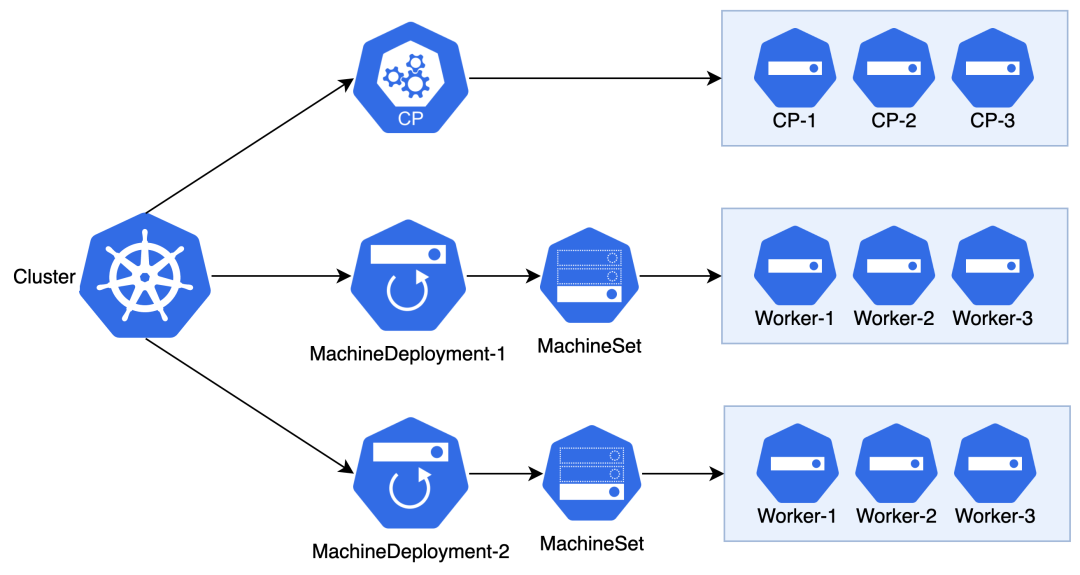
CAPI 部署所在的 Kubernetes 集群称为管控集群(Management Cluster),基于 CAPI 创建的 Kubernetes 集群称为工作负载集群(Workload Cluster)。
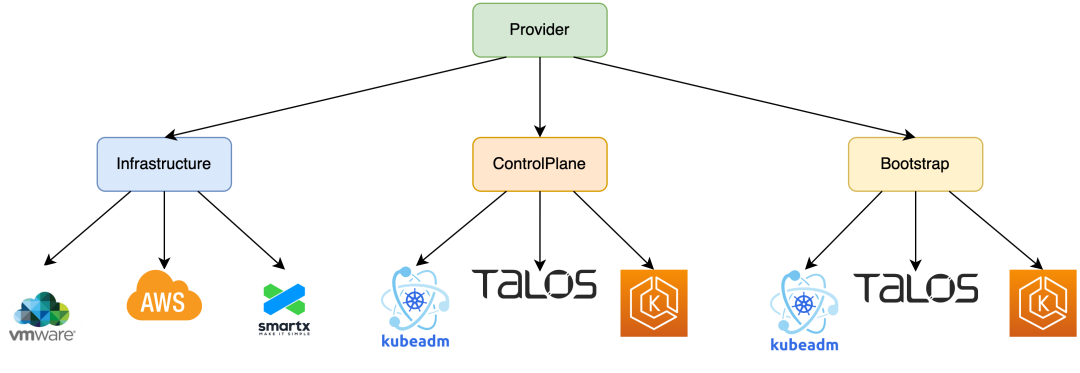
管控集群主要由 CAPI 和 CAPI Providers 组成。
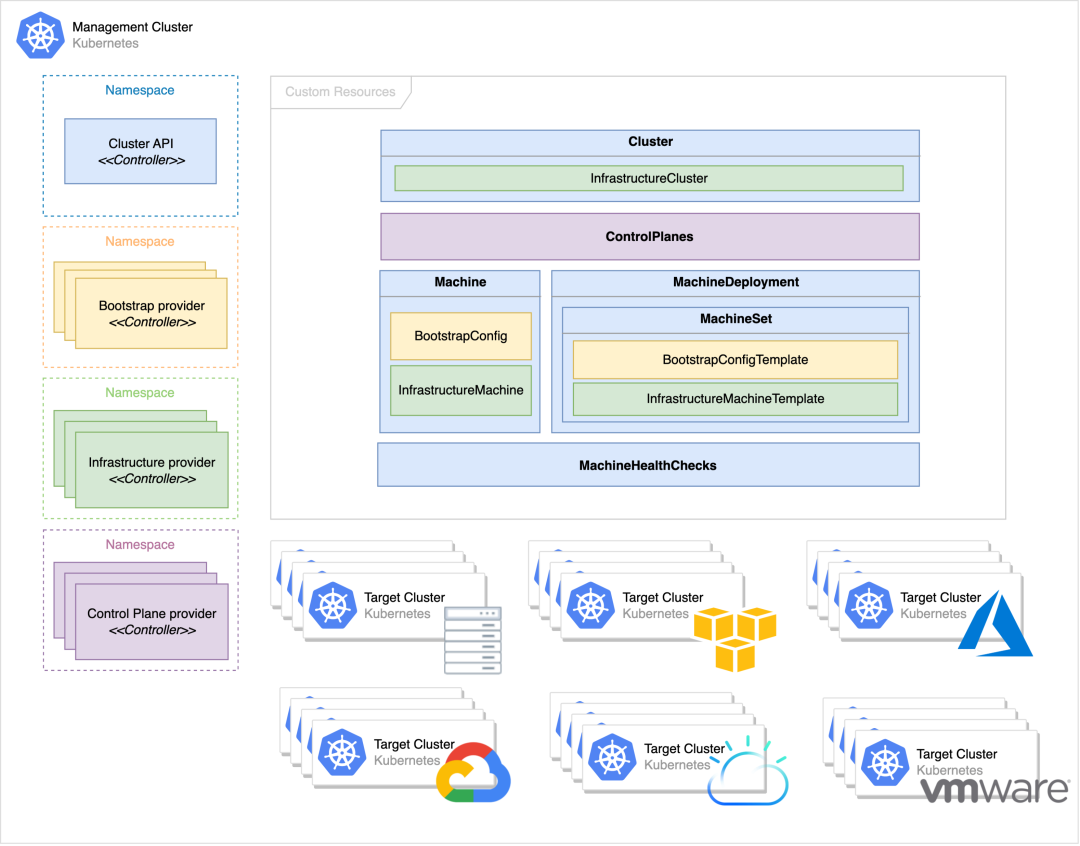
图片来源:https://cluster-api.sigs.k8s.io/images/management-cluster.svg
-
CAPI:集群的基础管理工作、Worker 节点的生命周期管理、协调 Providers 完成集群 LCM 工作。
-
Infrastructure Provider:管理集群所需要的基础设施资源。
-
ControlPlane Provider:Control Plane 节点的生命周期管理。
-
Bootstrap Provider:部署 Kubernetes 节点。
进一步,我们还需要确定集群有几个节点。Kubernetes 使用 Node 表示节点,CAPI 则使用 Machine 表示管理的 Kubernetes 节点,每个 Machine 关联一个节点。
apiVersion: cluster.x-k8s.io/v1beta1kind: Machinemetadata:name: mymachinenamespace: defaultspec:clusterName: mycluster # Machine 所属的集群providerID: elf://508ef880-dbdf-4327-ae58-aa034a450bebversion: v1.22.13 # Kubernetes 版本status:nodeInfo: # 节点信息nodeRef: # 关联的节点
节点是集群的核心,节点的管理也是集群管理的重要部分。节点分为 Control Plane 和 Worker 节点,两者的角色和功能不一样,管理起来也有差异。
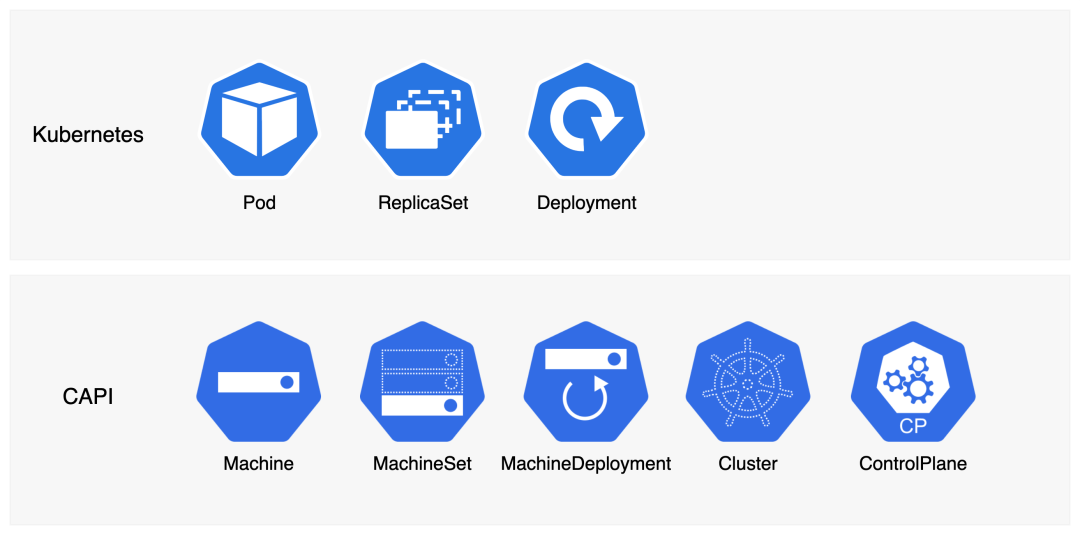
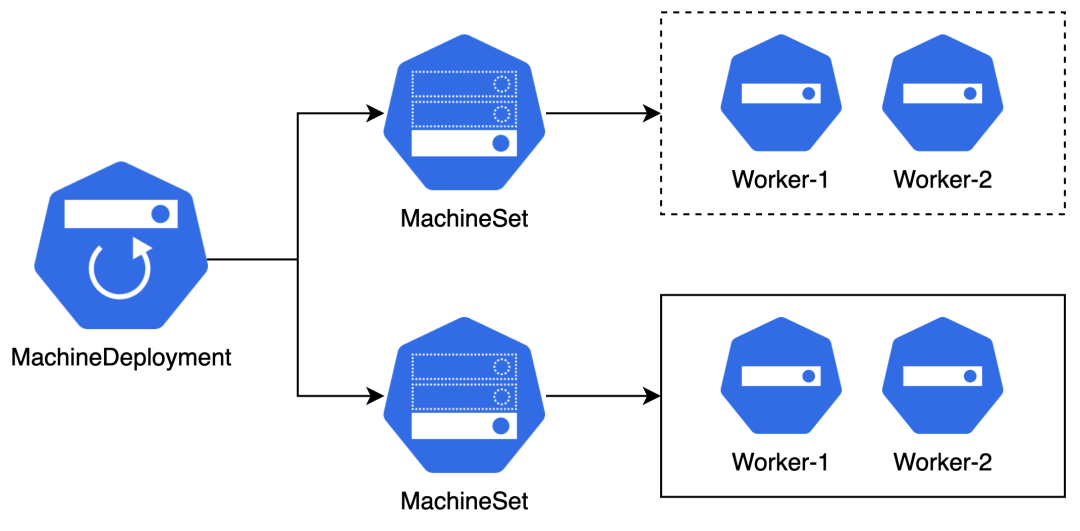
一个 Worker 节点包含多个 Kubernetes 组件程序(kubelet 等),集群升级过程会有多个版本的节点同时存在的情况。这些特点和 Pod 有些相似之处,因此 CAPI 借鉴了 Deployment 的设计理念:MachineDeployment (MD) + MachineSet (MS) + Machine (Pod) 组合,每个 MachineSet 管理同一个版本的节点。
kind: MachineDeploymentmetadata:name: mycluster-workergroupnamespace: defaultownerReferences:- apiVersion: cluster.x-k8s.io/v1beta1kind: Clustername: myclusterspec:clusterName: myclusterreplicas: 3 # 预期的 Worker 节点数strategy: # 滚动更新策略rollingUpdate:maxSurge: 35%maxUnavailable: 0type: RollingUpdatetemplate:spec:bootstrap:configRef:apiVersion: bootstrap.cluster.x-k8s.io/v1beta1kind: KubeadmConfigTemplatename: mycluster-workergroupclusterName: myclusterinfrastructureRef:apiVersion: infrastructure.cluster.x-k8s.io/v1beta1kind: ElfMachineTemplatename: mycluster-workergroupversion: v1.23.14 # Kubernetes 版本status:phase: Runningreplicas: 3 # 当前实际的 Worker 节点数unavailableReplicas: 0updatedReplicas: 3apiVersion: cluster.x-k8s.io/v1beta1kind: MachineSetmetadata:name: mycluster-workergroup-6f4c5dcc74namespace: defaultownerReferences:- apiVersion: cluster.x-k8s.io/v1beta1blockOwnerDeletion: truecontroller: truekind: MachineDeploymentname: mycluster-workergroupspec:clusterName: myclusterdeletePolicy: Randomreplicas: 3 # 预期的 Worker 节点数template:spec:bootstrap:configRef:apiVersion: bootstrap.cluster.x-k8s.io/v1beta1kind: KubeadmConfigTemplatename: mycluster-workergroupclusterName: myclusterinfrastructureRef:apiVersion: infrastructure.cluster.x-k8s.io/v1beta1kind: ElfMachineTemplatename: mycluster-workergroupversion: v1.23.14 # Kubernetes 版本status:replicas: 3 # 当前实际的 Worker 节点数
Control Plane 节点是集群的控制面,业务逻辑和 Worker 节点不一样,除了有 kubelet 还有 APIServer、Etcd 等不同的组件。
Control Plane 节点目前常见以下几种管理方式:
-
集群自身管理,例如 kubeadm 通过 static pods 运行 Control Plane 节点。
-
额外的 Kubernetes 集群部署,使用 Deployment 和 StatefulSet 的形式部署 Control Plane 节点。
-
第三方托管,例如 GKE、AKS、EKS 等。
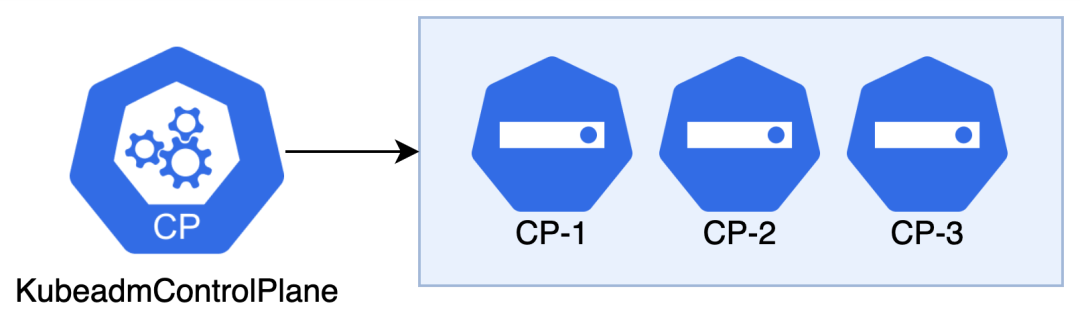
CAPI 提供了 ControlPlane Provider 的概念,我们可以根据不同的 Control Plane 节点管理方式而选择不同的 Provider。CAPI 默认提供了 KubeadmControlPlane(KCP)管理 Control Plane 节点。
apiVersion: controlplane.cluster.x-k8s.io/v1beta1kind: KubeadmControlPlanemetadata:name: mycluster-controlplanenamespace: defaultownerReferences:- apiVersion: cluster.x-k8s.io/v1beta1blockOwnerDeletion: truecontroller: truekind: Clustername: myclusterspec:kubeadmConfigSpec: # kubeadm 相关配置clusterConfiguration:format: cloud-configinitConfiguration:joinConfiguration:preKubeadmCommands:machineTemplate:infrastructureRef:apiVersion: infrastructure.cluster.x-k8s.io/v1beta1kind: ElfMachineTemplatename: mycluster-controlplanenamespace: defaultreplicas: 3 # 预期的 Control Plane 节点数rolloutStrategy: # 滚动更新策略rollingUpdate:maxSurge: 1type: RollingUpdateversion: v1.23.14 # 预期的 kubernetes 版本status:initialized: trueready: truereadyReplicas: 3replicas: 3 # 当前实际的 Control Plane 节点数selector: cluster.x-k8s.io/cluster-name=mycluster,cluster.x-k8s.io/control-planeunavailableReplicas: 0updatedReplicas: 3version: v1.23.14 # 当前实际的 kubernetes 版本
多平台
前面提到我们可能会有多 IaaS 的 Kubernetes 集群需求,不同的 IaaS 管理 Kubernetes 集群会有差异。CAPI 封装了每个 IaaS 通用的 LCM 数据和逻辑,每个 IaaS 只需要处理自己特有的相关逻辑。为此 CAPI 提出了 Infrastructure Provider 的概念,每个 IaaS 按照规范实现即可(参考 Provider Implementers,见附录参考文章)。Provider 体现了 CAPI 利用 Kubernetes 声明式 API 抽象和组合的作用,带来了可以支持不同 IaaS 集群管理的可扩展性。
例如 Cluster API Provider vSphere(CAPV)和 Cluster API Provider AWS(CAPA)分别用来在 vSphere 和 AWS 进行 Kubernetes 集群 LCM(更多请参考 CAPI Provider List,见参考文章)。为了方便,本文我们以 Kubernetes Cluster API Provider ELF (CAPE) 作为 Infrastructure Provider 参考。SMTX OS 是构建超融合平台的核心软件,内建服务器虚拟化、分布式存储组件等。CAPE 用于在 SMTX OS 内置的原生虚拟化服务 ELF 构建并管理 Kubernetes 集群。
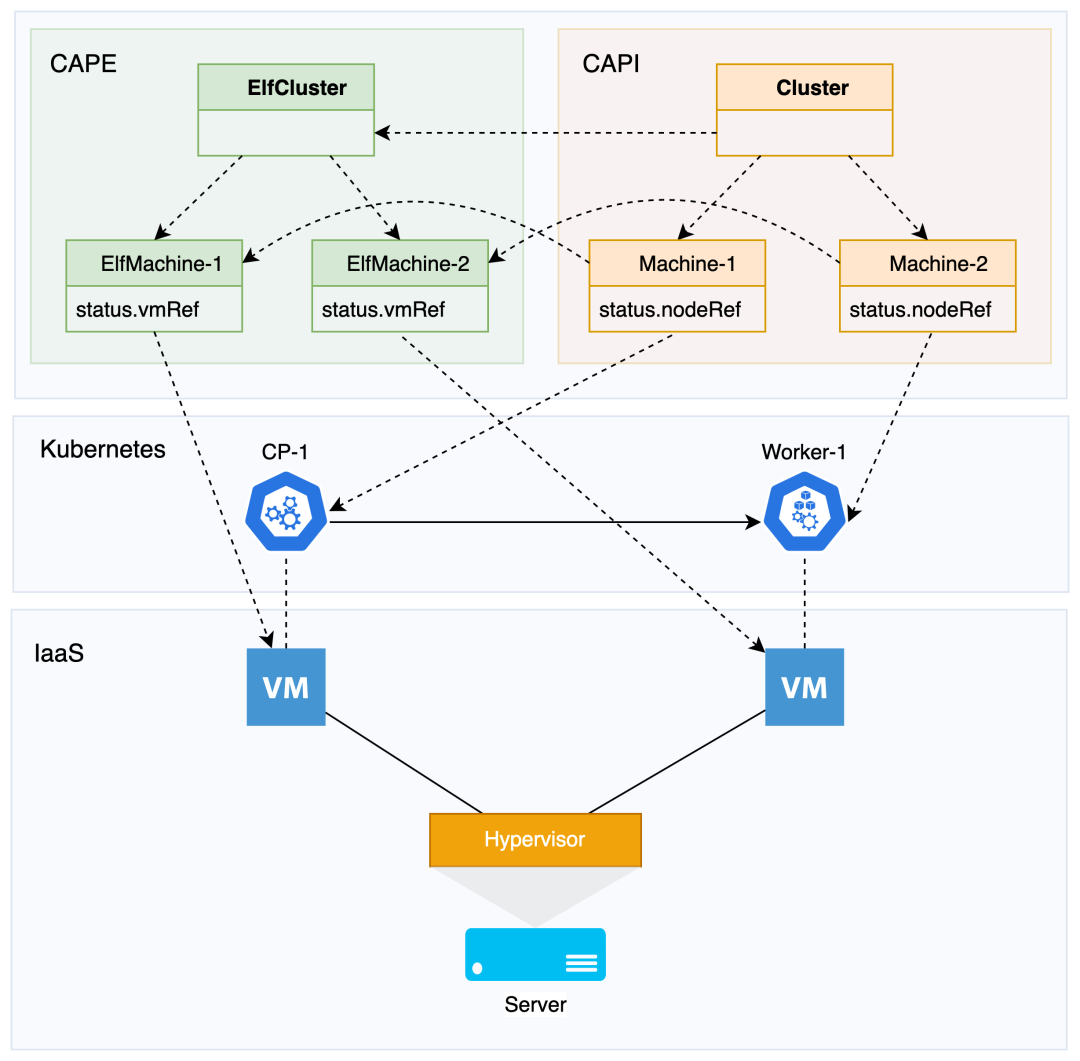
Cluster + InfraCluster 组合表示基于某 IaaS 的 Kubernetes 集群。集群构建于基础设施之上,创建集群需要的基础设施资源(计算资源、存储资源、网络资源等)由 InfraCluster 管理。
apiVersion: cluster.x-k8s.io/v1beta1kind: Clustermetadata:name: myclusternamespace: defaultspec: # 集群的规格status: # 集群的当前状态apiVersion: infrastructure.cluster.x-k8s.io/v1beta1kind: ElfClustermetadata:name: myclusternamespace: defaultspec:cluster: dd1f408f-7715-48c1-a817-13c3568f1d93 # ELF 集群 IDtower: # CloudTower 是 SmartX ELF 虚拟化系统的管控平台server: api.cloudtower.comusername: rootpassword: 123456controlPlaneEndpoint:host: 192.168.160.1 # 集群 VIPport: 6443status:ready: true # True 表示集群所需要的基础设施资源已经创建好
Machine + InfraMachine 表示基于某 IaaS 的 Kubernetes 集群节点。节点需要的 IaaS 资源由 ElfMachine 管理。
apiVersion: infrastructure.cluster.x-k8s.io/v1beta1kind: ElfMachinemetadata:name: mycluster-controlplane-v5rwfnamespace: defaultspec:cloneMode: FastClone # 虚拟机克隆模式ha: true # 虚拟机开启高可用模式diskGiB: 60 # 虚拟机磁盘memoryMiB: 8192 # 虚拟机内存network: # 虚拟机网络配置devices:- networkType: IPV4_DHCPvlan: dd1f408f-7715-48c1-a817-13c3568f1d93_4cd00407-63ca-440b-80b7-ceacfccb8d08nameservers: []numCPUS: 4 # 虚拟机 CPUproviderID: elf://508ef880-dbdf-4327-ae58-aa034a450beb # 节点的 providerIDtemplate: clb6rdohnixp30958owkuy2pp # 虚拟机模板,用来克隆虚拟机并在该虚拟机部署 kubernetes 节点status:ready: true # True 表示虚拟机所需要的基础设施资源已经创建好vmRef: 508ef880-dbdf-4327-ae58-aa034a450beb # 关联的 ELF 虚拟机 ID
创建一个 Kubernetes 节点大致分为以下三个步骤:
-
制备机器(虚拟机、裸金属等),操作系统、存储、网络等资源。
-
在机器部署 Node 节点,安装 Kubelet、kube-apiserver、kube-scheduler、kube-controller-manager、Etcd 等组件。
-
Kubernetes 节点加入集群。
第一部分工作由 Infrastructure Provider 负责。第二部分(2 和 3)目前常用 kOps、kubespray、kubeadm 等方式部署 Kubernetes 节点。CAPI 把部署节点的部分抽象成了 Bootstrap Provider (CABP),用户可以根据自己的情况选择社区已有的 CABP 或者自己开发不同的 CABP。CAPI 提供了目前主流的 kubeadm (CABPK) 作为默认的 CABP。
CABPK 为每个 Machine 创建一个 KubeadmConfig,KubeadmConfig 记录了 Kubeadm 部署一个节点使用的配置。并把部署一个节点的配置生成可执行命令(默认 cloud-init 格式),保存在名为 kubeadmConfig.status.dataSecretName 的 Secret 中。
apiVersion: bootstrap.cluster.x-k8s.io/v1beta1kind: KubeadmConfigmetadata:name: mycluster-controlplane-6rhflnamespace: defaultownerReferences:- apiVersion: cluster.x-k8s.io/v1beta1blockOwnerDeletion: truecontroller: truekind: Machinename: mycluster-controlplane-6xftwspec: # kubeadm 相关配置clusterConfiguration:format: cloud-configinitConfiguration:preKubeadmCommands:status:dataSecretName: mycluster-controlplane-6rhflready: true# Kubeadm 配置复用,用于创建 KubeadmConfigapiVersion: bootstrap.cluster.x-k8s.io/v1beta1kind: KubeadmConfigTemplatemetadata:name: mycluster-controlplanenamespace: defaultspec:template: # 通用的 kubeadm 配置spec:clusterConfiguration:joinConfiguration:preKubeadmCommands:
节点组
在某些场景下,我们需要对集群节点进行分类管理。例如我们需要在集群部署不同类型的应用,有些节点运行 CPU 密集型应用,有些节点运行网络 I/O 密集型应用,有些节点运行 GPU 应用等。CAPI 提供了节点组的功能,可以把同类的节点归为一个节点组统一管理。集群默认只有一个 Control Plane 节点组,由 KCP 管理。每个集群可以有多个 Worker 节点组,每个 MachineDeployment 管理一组 Worker 节点。
扩缩容
当我们增加或者减少集群的节点,从声明式的角度来说,我们只需要告诉 CAPI 我们需要几个节点即可。
例如当前集群有 1 或 5 个 Control Plane 节点,我们想要集群拥有 3 个 Control Plane 节点,我们只需要设置 kcp.spec.replicas = 3,KCP 会自动使集群 Control Plane 节点维持在 3 个,如果当前 Control Plane 节点数多于 3 则缩容,反之则扩容。
apiVersion: controlplane.cluster.x-k8s.io/v1beta1kind: KubeadmControlPlanemetadata:name: mycluster-controlplanenamespace: defaultspec:- replicas: 1+ replicas: 3 # 从 1 扩容到 3
更新
集群更新包括集群的版本更新以及节点相关配置更新等。CAPI 遵循云原生社区广泛应用的不可变基础设施理念,以 Machine 为不可变基础设施的一个基本单位。这意味着如果我们要更新集群,需要通过使用新节点替换旧节点的滚动更新方式。
我们可以通过配置 KCP 和 MD 的滚动更新策略控制滚动更新的过程。例如先删除旧的节点再创建新的节点,还是先创建新的节点再删除旧的节点。详细请参考 KCP RolloutStrategy 和 MD MachineDeploymentStrategy。
滚动更新的方式比较重,我们可以根据实际情况选择其他方式更新。例如有些 IaaS 支持动态修改虚拟机资源配置,我们可以通过虚拟机热更新技术直接修改集群节点所在虚拟机的相关配置,这样就可以避免节点替换更新。此外我们还可以选择不使用 CAPI 默认的滚动更新机制,通过自己实现或扩展 Provider 等方式实现节点的原地更新。
例如当我们需要更新集群版本的时候,通过给 KCP 和 MD 指定版本,KCP 和 MD 会自动完成节点的滚动更新。
apiVersion: controlplane.cluster.x-k8s.io/v1beta1kind: KubeadmControlPlanemetadata:name: mycluster-controlplanenamespace: defaultspec:- version: v1.25.6+ version: v1.26.2 # 从 v1.25.6 升级到 v1.26.2rolloutStrategy: # 滚动更新策略rollingUpdate:maxSurge: 1type: RollingUpdate
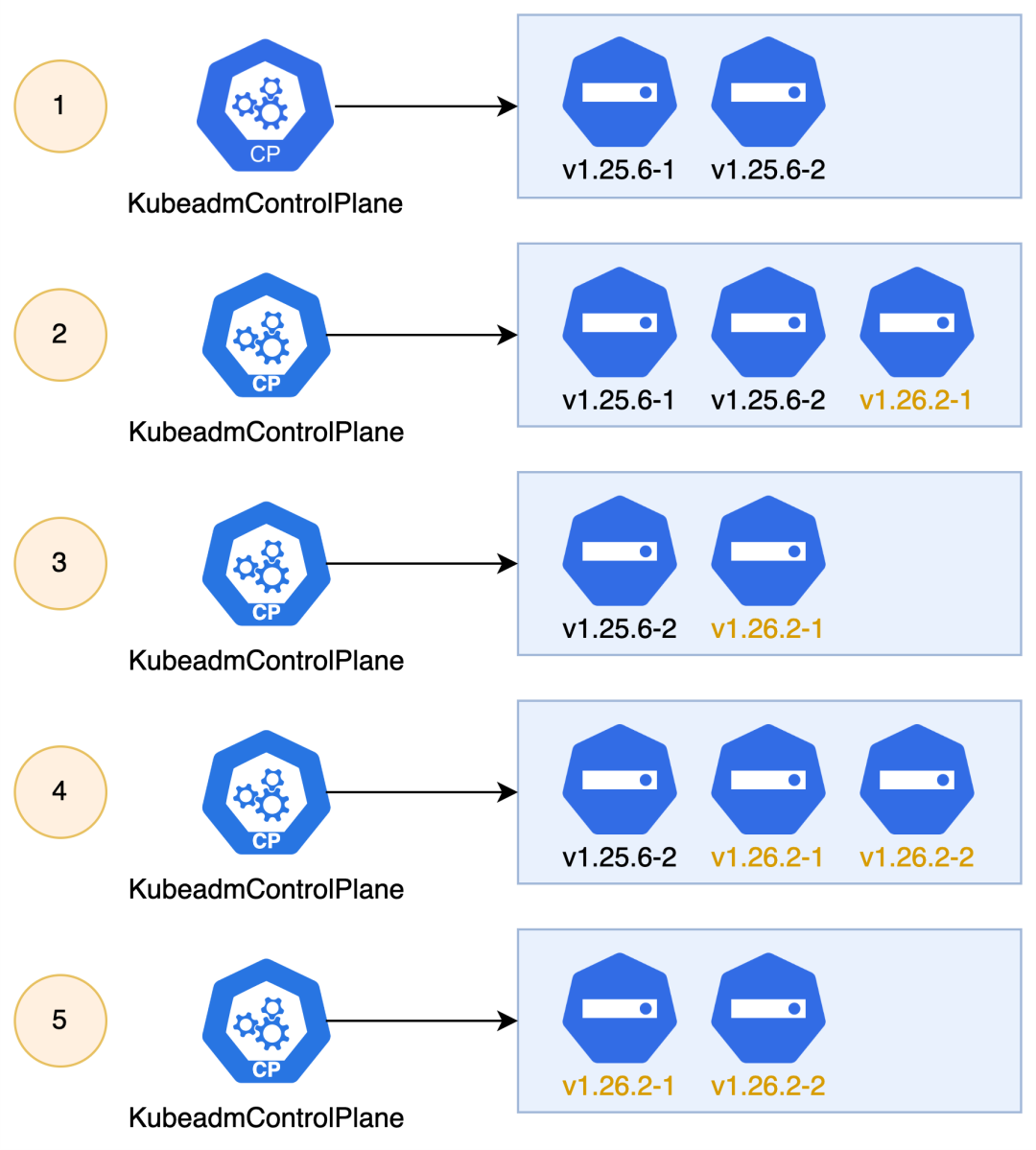
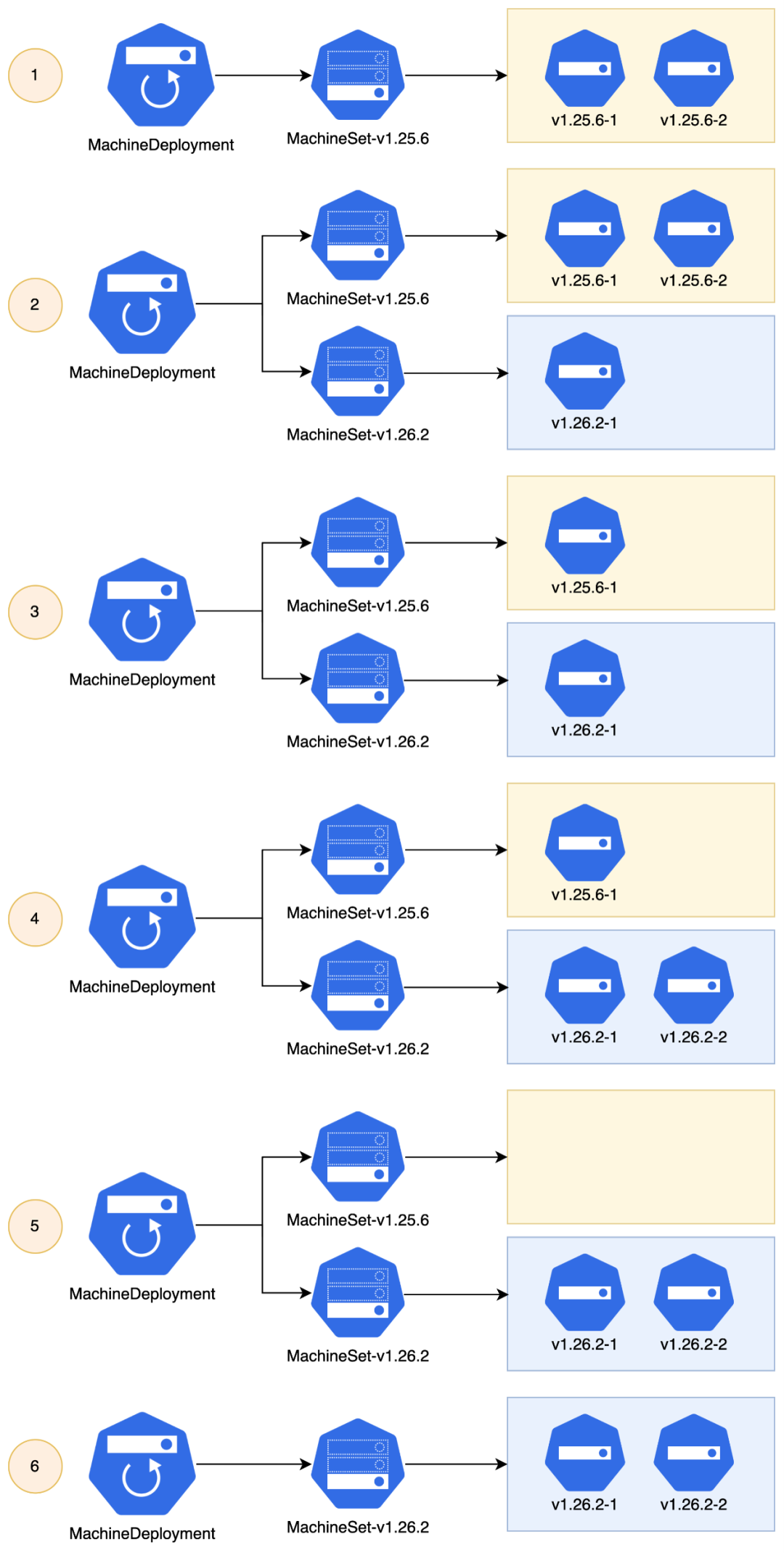
通过给 MD 指定集群版本,MD 会自动完成 Worker 节点的滚动更新。
kind: MachineDeploymentmetadata:name: mycluster-workergroupnamespace: defaultspec:- version: v1.25.6+ version: v1.26.2 # 从 v1.25.6 升级到 v1.26.2strategy: # 滚动更新策略rollingUpdate:maxSurge: 35%maxUnavailable: 0type: RollingUpdate
拓扑
在多集群的场景下,可能存在多个相似集群的情况。例如测试环境和生产环境使用的集群配置一样,只是集群节点数不一样。按照前面介绍的集群管理方式,我们需要为每个集群单独创建相同的 CRD 对象,当集群的配置需要修改(例如升级)的时候又需要挨个修改集群的 CRD 对象。
为此 CAPI 提出了 ClusterClass 的概念,简化多个相似集群的管理。ClusterClass 相当于 Cluster 的抽象,将集群共有的属性抽象出来。通过多个 Cluster 引用 ClusterClass 从而实现创建并管理多个相似集群。
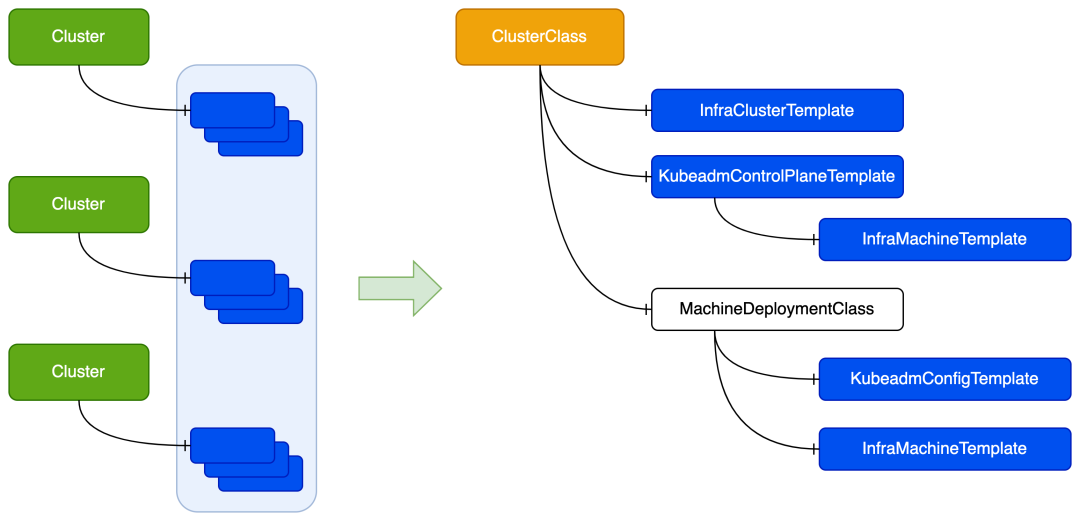
apiVersion: cluster.x-k8s.io/v1beta1kind: ClusterClassmetadata:name: myclusterclassnamespace: defaultspec:infrastructure: # Infrastructure 配置ref:apiVersion: infrastructure.cluster.x-k8s.io/v1beta1kind: ElfClusterTemplatename: myelfcluster-templatenamespace: defaultcontrolPlane: # Control Plane 配置machineInfrastructure:ref:apiVersion: infrastructure.cluster.x-k8s.io/v1beta1kind: ElfMachineTemplatename: myclusterclass-controlplanenamespace: defaultref:apiVersion: controlplane.cluster.x-k8s.io/v1beta1kind: KubeadmControlPlaneTemplatename: myclusterclass-controlplanenamespace: defaultworkers: # Worker 配置machineDeployments:- class: myclusterclass-workergroup-0template:bootstrap:ref:apiVersion: bootstrap.cluster.x-k8s.io/v1beta1kind: KubeadmConfigTemplatename: myclusterclass-workergroup-0namespace: defaultinfrastructure:ref:apiVersion: infrastructure.cluster.x-k8s.io/v1beta1kind: ElfMachineTemplatename: myclusterclass-workergroup-0namespace: defaultvariables: # 定义 Patches 使用的变量- name: imageRepository # 自定义镜像仓库required: trueschema:openAPIV3Schema:type: stringdescription: ImageRepository is the container registry to pull images from.default: registry.capi.iopatches: # 通过 patches 实现 ClusterClass 默认配置参数的定制化- name: imageRepositorydefinitions:- selector:apiVersion: controlplane.cluster.x-k8s.io/v1beta1kind: KubeadmControlPlaneTemplatematchResources:controlPlane: truejsonPatches:- op: addpath: /spec/template/spec/kubeadmConfigSpec/clusterConfiguration/imageRepositoryvalueFrom:variable: imageRepository# 同类集群的默认 ElfCluster 配置apiVersion: infrastructure.cluster.x-k8s.io/v1beta1kind: ElfClusterTemplatemetadata:name: myelfcluster-templatenamespace: defaultspec:template:spec:tower: {}
ClusterClass 一般只会配置多个相似集群共同的属性和默认参数,实际上每个集群还会有自己个性化需求的部分。ClusterClass.sepc.patches 为每个 Cluster 提供了个性化定制的能力,只需要在 Cluster.spec.topology.variables 提供个性化的参数即可。
apiVersion: cluster.x-k8s.io/v1beta1kind: Clustermetadata:name: myclusternamespace: defaultspec:topology: # 拓扑配置class: myclusterclass # 引用 ClusterClassversion: v1.25.6 # kubernetes 版本controlPlane:replicas: 3 # 预期的 Control Plane 节点数workers:machineDeployments:- class: myclusterclass-workergroup-0name: mycluster-workergroup-0replicas: 3 # 预期的 Worker 节点数variables: # 覆盖 ClusterClass 默认配置,提供个性化参数- name: imageRepositoryvalue: dev.registry.capi.io # 指定特定的镜像仓库
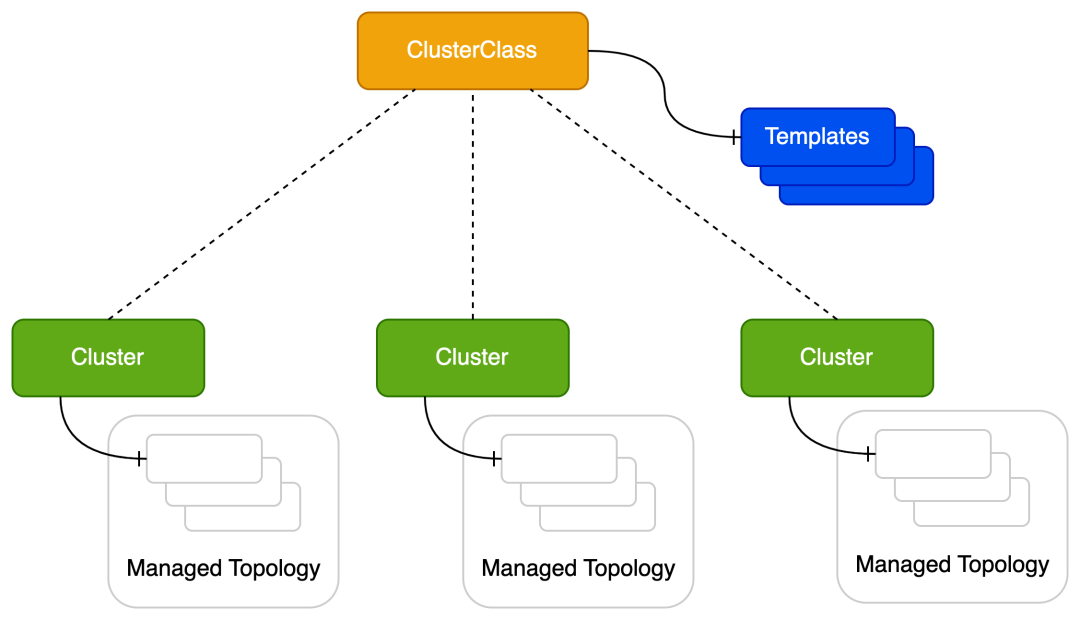
使用 ClusterClass 之后,单个 Cluster 的 LCM 操作也变得更简单(更多请参考 Operating a managed Cluster,见参考文章)。
不使用 ClusterClass 对集群的 LCM 操作一般需要修改 KCP.spec. 和 MD.spec。使用 ClusterClass 之后只需要直接修改 Cluster.spec.topology 的相关属性即可,这样更简单直观。
apiVersion: cluster.x-k8s.io/v1beta1kind: Clustermetadata:name: myclusternamespace: defaultspec:topology:class: myclusterclass- version: v1.25.6+ version: v1.26.2 # 从 v1.25.6 升级到 v1.26.2controlPlane:- replicas: 3+ replicas: 5 # Control Plane 节点从 3 扩容到 5workers:machineDeployments:- class: myclusterclass-workergroup-0name: mycluster-workergroup-0- replicas: 3+ replicas: 6 # Worker 节点从 3 扩容到 6
ClusterClass 被多个 Cluster 引用,如果 ClusterClass 发生了变化,可能会间接影响到这些相似的 Cluster。我们可以利用这个特性实现对多集群进行批量管理,详细请参考 Changing a ClusterClass(见参考文章)。
高可用
影响 Kubernetes 高可用的因素可大概分为两类:集群依赖的环境稳定性,这里主要指 IaaS;Kubernetes 集群自身的高可用设计。
IaaS 的基础设施自身也会提供高可用的保证。例如部署 Kubernetes 节点的虚拟机,一般会提供高可用特性,当虚拟机所在的主机遇到故障的时候会在其他主机启动和运行(可参考 vSphere High Availability,见参考文章)。
Kubernetes 集群高可用可分为两部分:高可用部署和故障自愈。Kubernetes 是声明式自愈系统,例如当节点所在的机器重启后,节点可以自动恢复工作。高可用部署一般通过部署多个 Control Plane 节点实现,每个 Control Plane 节点部署在不同的物理机器。根据对高可用的需求程度,可以部署在不同的机架、不同的机房等。
在实际生产环境,Kubernetes 集群可能会遇到各种故障,例如网络故障、存储损坏等。有些故障是临时的,通过 IaaS 或者 Kubernetes 自身就可以自动恢复。但有些故障是长久或者永久的,例如硬件故障等,IaaS 或者 Kubernetes 不能在预期内自动恢复甚至是不能恢复,需要外部的干预。对于这类场景,我们还需要确保在 Kubernetes 集群出现无法自动恢复故障的时候能进行自动恢复。
高可用部署
多 Control Plane 节点的集群一般通过负载均衡器(LB)分发集群的流量。
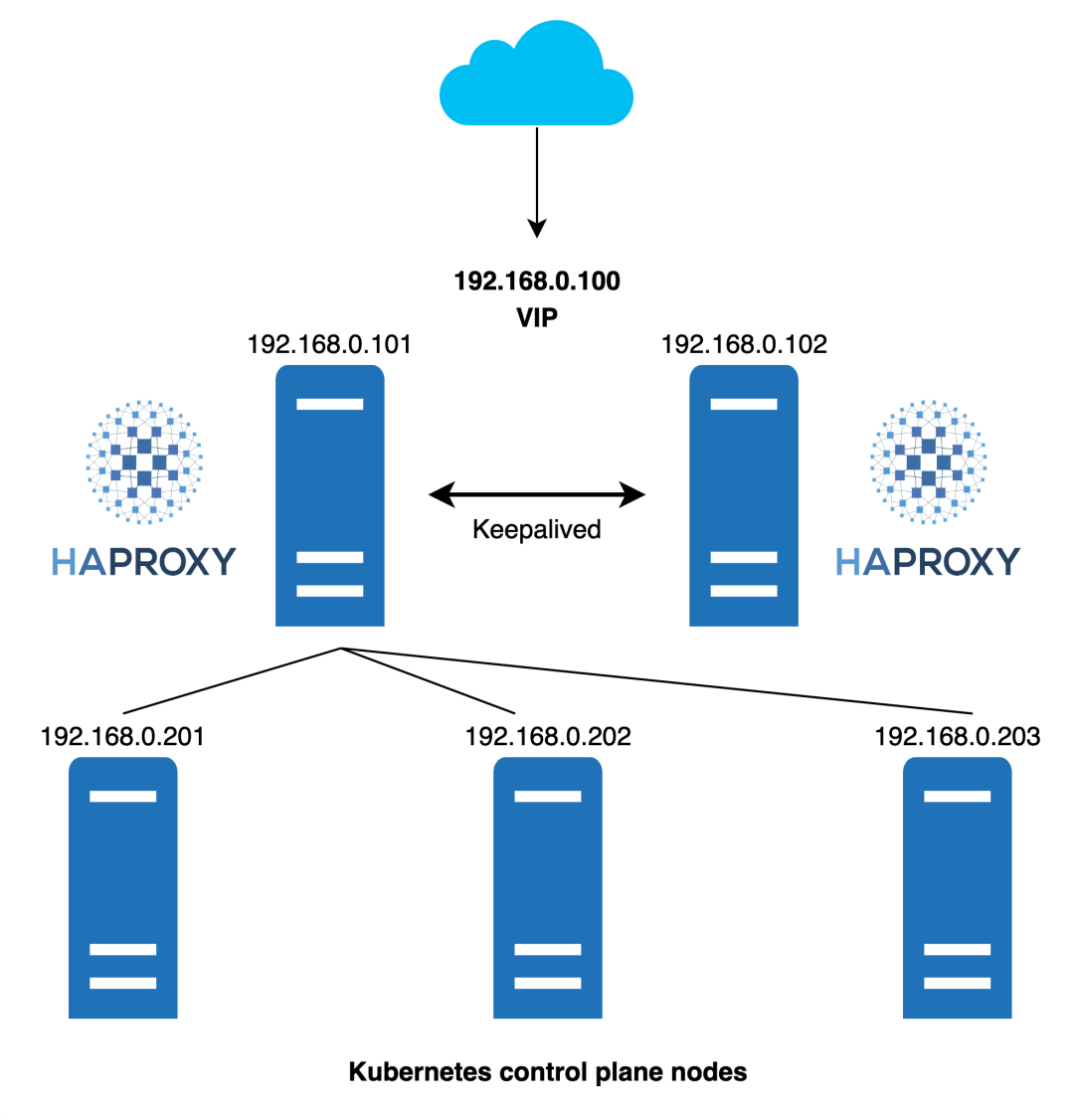
HAProxy
典型的 LB 使用 HAProxy + Keepalived 方案。但 HAProxy + Keepalived 本身也需要保证高可用,所以需要额外的机器部署 LB 集群。
kube-vip
kube-vip 是一个为 Kubernetes 集群内部和外部提供高可用和负载均衡的开源项目。
kube-vip 支持以静态 Pod 的形式运行在 Control Plane 节点上,这样就可以不需要部署 HAProxy + Keepalived 等传统的 LB 来保证高可用。
kube-vip 静态 Pod 通过 ARP 会话来识别每个节点上的其他主机,我们可以选择 BGP 或 ARP 来设置负载平衡器。在 ARP 模式下,会选出一个领导者,这个节点将继承虚拟 IP 并成为集群内负载均衡的 Leader。而在 BGP 模式下,所有节点都会通知 VIP 地址。
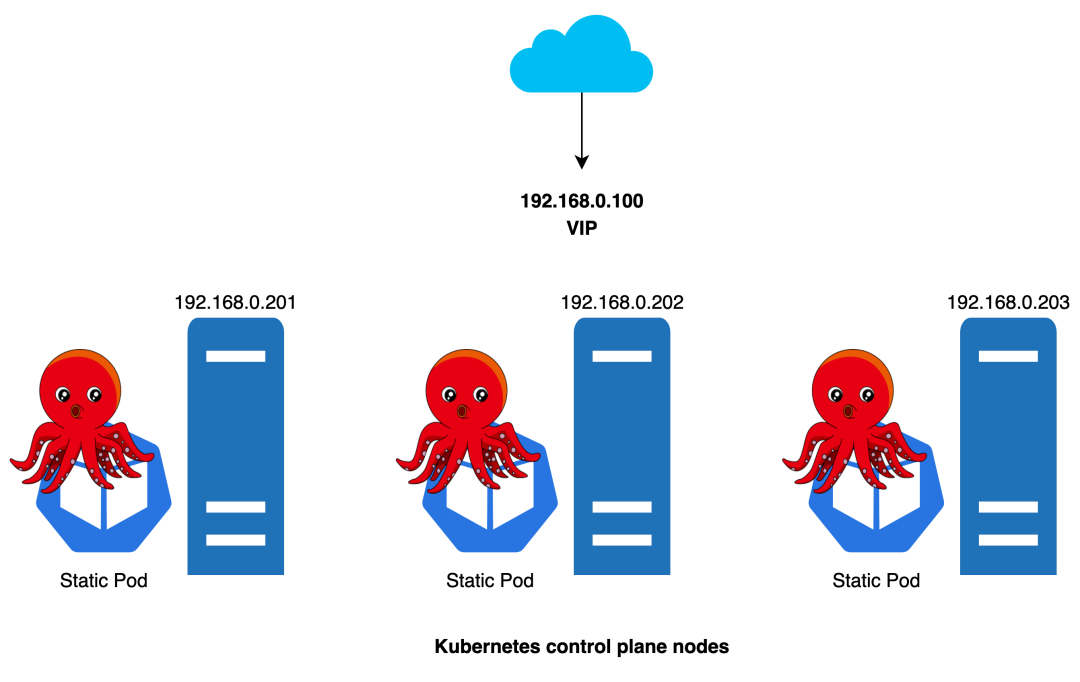
通过把 kube-vip 以静态 Pod 的形式配置到 Control Plane 节点机器上的 /etc/kubernetes/manifests/kube-vip.yaml 文件中。kubeadm 部署 Control Plane 节点的过程,在启动静态 Pod 的阶段,就会启动 kube-vip 服务。
详细请参考 CAPE cluster-template.yaml kube-vip 配置。
故障自动恢复
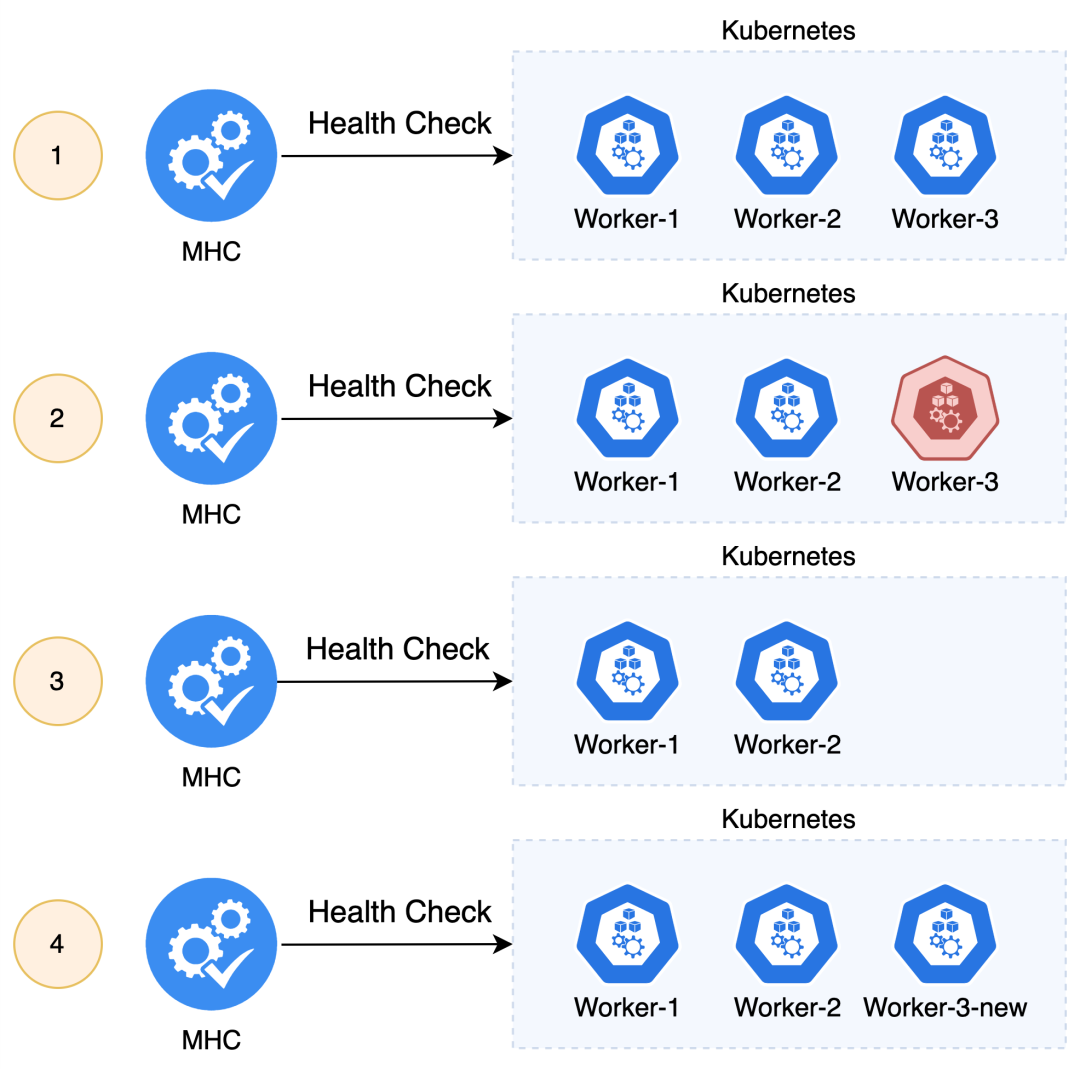
针对集群故障,CAPI 提出了 MachineHealthCheck(MHC)的概念,提供故障节点自动恢复的功能,也就是通过自动删除故障节点再创建新节点的方式。当然 MHC 也不是万能的,对于 MHC 不能覆盖的场景,最终还是需要人工介入。关于 MHC 的限制请参考 Kubeadm Based Control Plane Management - Remediation 和 Limitations and Caveats of a MachineHealthCheck(见参考文章)。
CAPI 通过 MHC 为集群判断节点故障,并由 KCP 和 MD/MS 配合完成故障节点的替换工作。
apiVersion: cluster.x-k8s.io/v1beta1kind: MachineHealthCheckmetadata:name: mycluster-mhcspec:clusterName: mycluster # 应用到的工作负载集群maxUnhealthy: 60% # 最大故障 Machine 比例,默认 100%,可以填百分比或者数字UnhealthyRange: [3-5] # 故障 Machine 数量在一定范围会启动节点替换nodeStartupTimeout: 10m # 节点加入集群的最长等待时间,也就是创建节点的超时时间selector: # 纳管的 Machine,根据标签选择matchLabels:cluster.x-k8s.io/control-plane: "" # 该标签表示监控所有 Control Plane 节点unhealthyConditions: # 自定义节点故障- type: Ready # 可配置 kubernetes Node 原生的 conditionstatus: Unknowntimeout: 100s- type: Readystatus: "False"timeout: 200s- type: my-custom-condition # 可自定义 conditionstatus: "False"timeout: 300s
-
通过 MHC 配置需要监控哪个集群 (clusterName) 的哪些节点 (selector),自定义故障节点的标准(nodeStartupTimeout 和 unhealthyConditions)。
-
MHC controller 根据配置监控集群的节点。当发现节点符合自定义的故障标准,MHC 标记对应的 Machine 为故障,并由 KCP 或 MD/MS 先删除故障节点再创建新的节点(更多细节 Kubeadm Based Control Plane Management Remediation)。
云原生平台
云原生可划分为容器与容器编排、应用开发与部署、服务治理、可观测性等领域,每个领域一般有多种实现方案,云原生平台可以理解为是多个领域的有机整合。与此相似,Kubernetes 也可划分多个领域,网络、存储、容器,每个领域都有标准(CNI、CSI、CRI 等)和不同的实现方案。CAPI 有多种 Provider,每种 Provider 可以有多种实现。这其实就是云原生社区常用的抽象和组合模式,不同的功能通过搭积木的方式组合使用。
我们可以基于 CAPI 构建云原生平台的 Kubernetes 管理模块,CAPI 有以下优势:
-
CAPI 是 Kubernetes SIG 发起的项目,社区活跃度较高。
-
CAPI 目前已经被众多的主流公/私有云使用,社区的主要贡献者也来自这些公司。
-
CAPI 基于 Kubernetes 声明式 API 风格,设计简洁,使用简单。
-
CAPI 功能完善稳定,涵盖了创建/删除/升级/扩缩容/故障恢复等,且还在不断迭代演进。
-
CAPI 可扩展性高,除了开箱即用的社区现有 Provider,还可以自定义 Provider 满足个性化需求,通过 Provider 组合可实现跨平台。同时也可以和云原生社区的其他项目组合使用,例如 Autoscaler。
更多 Kubernetes 运维、选型与管理知识,欢迎点击阅读电子书《IT 基础架构团队的 Kubernetes 管理:从入门到评估》。
附录
概念
-
CAPI Concepts:详见 https://cluster-api.sigs.k8s.io/user/concepts.html
-
IaaS:基础设施平台,包括公有云和私有云。
-
SMTX OS:SmartX 自主研发的构建超融合平台的核心软件,内建服务器虚拟化、分布式存储组件,可选配双活、异步复制、备份与恢复、网络与安全等高级功能。
-
ELF:SMTX OS 内置的原生虚拟化服务。
-
SKS:SmartX 企业云基础设施提供的 Kubernetes 服务。
CRDs
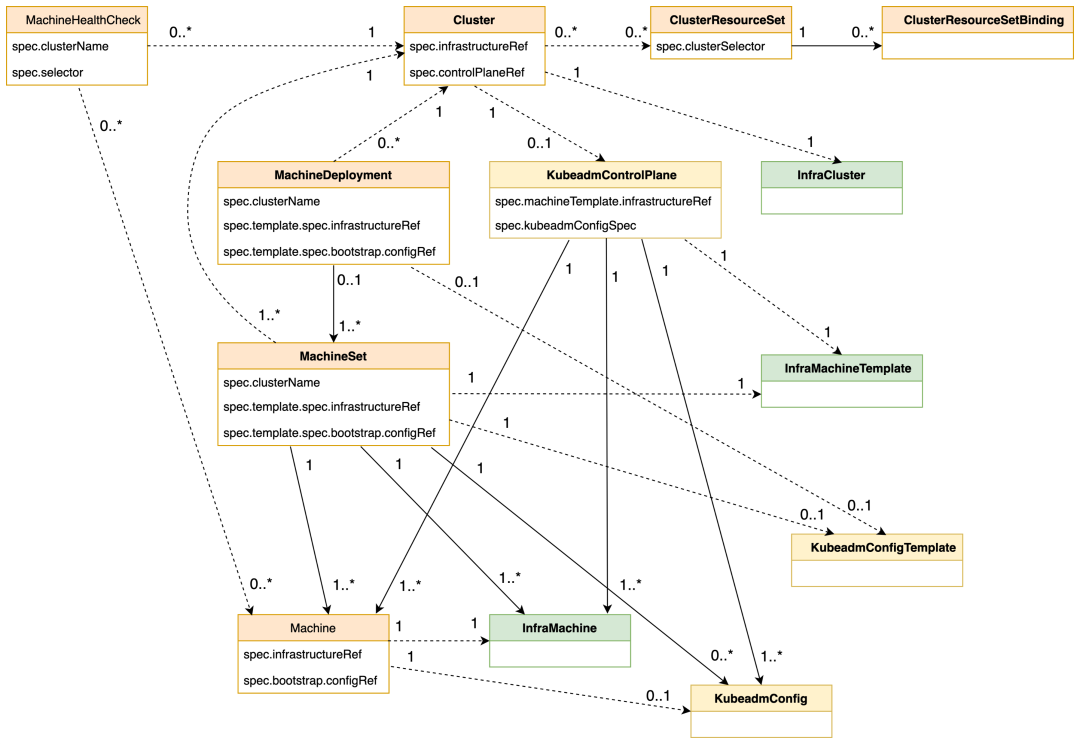
Providers
参考文档:
1. Kubernetes Cluster API
https://cluster-api.sigs.k8s.io
2. Cluster API docs
https://github.com/kubernetes-sigs/cluster-api/tree/main/docs
3. CNCF Operator White Paper - Review Version
https://github.com/cncf/tag-app-delivery/blob/eece8f7307f2970f46f100f51932db106db46968/operator-wg/whitepaper/Operator-WhitePaper_v1-0.md
4. Introducing Operators: Putting Operational Knowledge into Software
https://web.archive.org/web/20170129131616/https://coreos.com/blog/introducing-operators.html
5. Best practices for building Kubernetes Operators and stateful apps
https://cloud.google.com/blog/products/containers-kubernetes/best-practices-for-building-kubernetes-operators-and-stateful-apps
6. Cluster API and Declarative Kubernetes Management
https://learning.oreilly.com/library/view/cluster-api-and/9781098126865
7. Cluster API Deep Dive - Jason DeTiberus, Equinix Metal & Marcel Mue, Giant Swarm
https://www.youtube.com/watch?v=ZT1PXt87qSs
8. Webinar: Cluster API (CAPI) - A Kubernetes subproject to simplify cluster lifecycle management : https://www.youtube.com/watch?v=A2BBuKx1Yhk
9. Cluster API Intro and Deep Dive - Yuvaraj Balaji Rao Kakaraparthi & Vince Prignano, VMware
https://www.youtube.com/watch?v=9H8flXm_lKk
10. Kubernetes Cluster Management with Cluster API
https://www.youtube.com/watch?v=pctQWicYQu0
11. Build Your Own Cluster API Provider the Easy Way - Anusha Hegde, VMware & Richard Case, Weaveworks
https://www.youtube.com/watch?v=HSdgmcAAXa8
12. Deep Dive: Cluster Lifecycle SIG (Cluster API) - Jason DeTiberus, VMware & Hardik Dodiya, SAP
https://www.youtube.com/watch?v=Mtg8jygK3Hs
13. The What and the Why of the Cluster API
https://tanzu.vmware.com/content/blog/the-what-and-the-why-of-the-cluster-api
14. Declarative Management of Kubernetes Objects Using Configuration Files
https://kubernetes.io/docs/tasks/manage-kubernetes-objects/declarative-config
15. Declarative application management in Kubernetes
https://github.com/kubernetes/design-proposals-archive/blob/main/architecture/declarative-application-management.md
16. Fundamentals of Declarative Application Management in Kubernetes
https://www.alibabacloud.com/blog/fundamentals-of-declarative-application-management-in-kubernetes_596265
17.在Cluster API中引入ClusterClass和托管拓扑
https://mp.weixin.qq.com/s/FUGBNlNiamJMY36VIXXlSA
18.容器技术之发展简史
https://mp.weixin.qq.com/s/ccFkJJz97KcuXdO3r5zdXA
19.声明式自愈系统——高可用分布式系统的设计之道 [slide]
https://www.infoq.cn/video/wwlttw9l3lrs65ynpodb
20. CAPI - Provider Implementers
https://cluster-api.sigs.k8s.io/developer/providers/implementers.html
21. CAPI - Provider List
https://cluster-api.sigs.k8s.io/reference/providers.html#infrastructure
22. CAPI - Operating a managed Cluster
https://cluster-api.sigs.k8s.io/tasks/experimental-features/cluster-class/operate-cluster.html
23. CAPI - Changing a ClusterClass
https://cluster-api.sigs.k8s.io/tasks/experimental-features/cluster-class/change-clusterclass.html
24. vSphere High Availability
https://www.vmware.com/cn/products/vsphere/high-availability.html
25. CAPE cluster-template.yaml
https://github.com/smartxworks/cluster-api-provider-elf/blob/master/templates/cluster-template.yaml
26. Kubeadm Based Control Plane Management - Remediation
https://github.com/kubernetes-sigs/cluster-api/blob/main/docs/proposals/20191017-kubeadm-based-control-plane.md#remediation-using-delete-and-recreate
27. CAPI - Limitations and Caveats of a MachineHealthCheck
https://cluster-api.sigs.k8s.io/tasks/automated-machine-management/healthchecking#limitations-and-caveats-of-a-machinehealthcheck