一、介绍
在自然语言处理(NLP)领域,文本聚类是一种基本且通用的技术,在信息检索、推荐系统、内容组织和情感分析等各种应用中发挥着关键作用。文本聚类是将相似文档或文本片段分组为簇或类别的过程。这项技术使我们能够发现隐藏的模式、提取有价值的见解并简化大量非结构化文本数据。在本文中,我们将深入研究 NLP 中的文本聚类领域,探讨其重要性、方法论和实际应用。
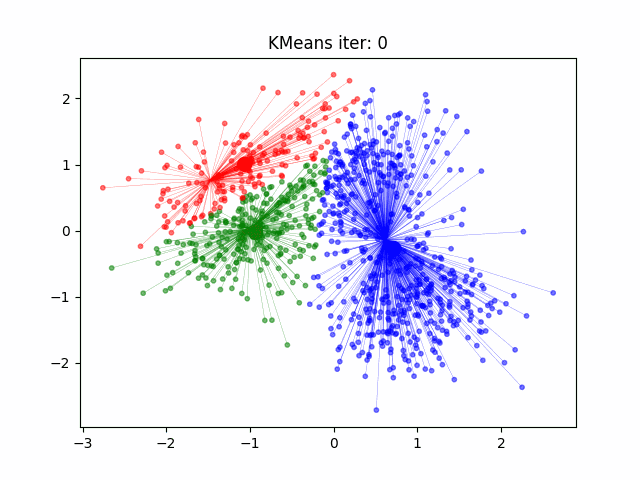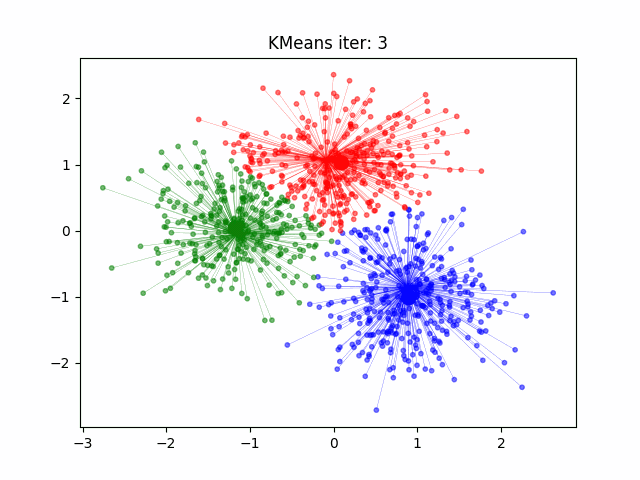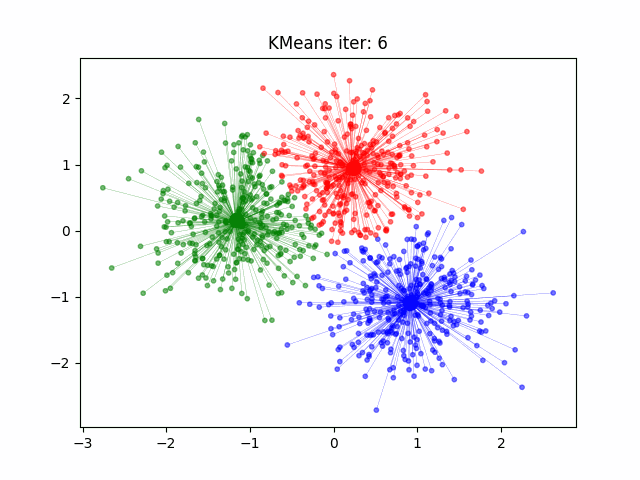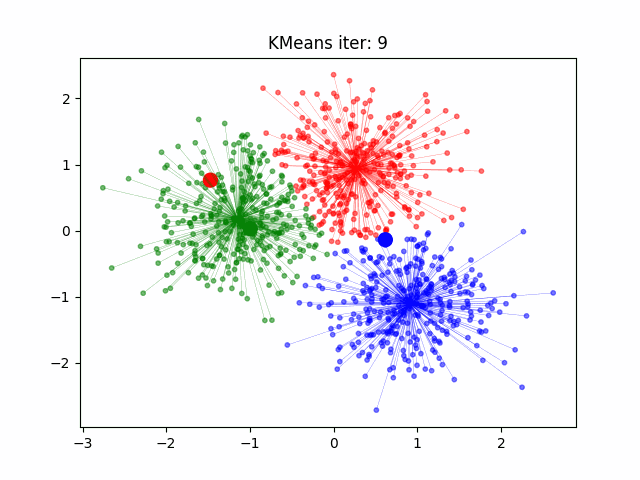
自然语言处理中的文本聚类就像浩瀚文字海洋中的指南针,引导我们到达模式和见解的隐藏海岸。
二、文本聚类的重要性
文本聚类是文本分析中的关键步骤,因为它可以从非结构化文本数据中提取有意义的结构和见解。以下是文本聚类在 NLP 中至关重要的几个关键原因:
- 信息检索:搜索引擎和推荐系统使用文本聚类来有效地分类和检索相关信息。它可以帮助用户找到与其查询语义相关的文档或内容。
- 内容组织:在内容管理中,集群有助于对大量文档档案进行分类和组织。它有助于创建层次结构,使内容更易于导航。
- 主题发现:研究人员和分析师使用文本聚类来识别文档集合中的新兴趋势、主题或模式。这对于跟踪新闻、社交媒体或学术研究特别有用。
- 情绪分析:以情绪为重点的文本聚类有助于衡量公众对各种主题的看法。这对于企业和政府了解公众的看法并相应地调整策略来说非常宝贵。
三、文本聚类方法
文本聚类涉及多种方法和途径。以下是一些常用的技术:
- K-Means 聚类: K-Means 是一种广泛使用的聚类算法。它通过最小化文档与簇质心之间的距离来将文档分配给簇。每个簇代表一组相似的文档。
- 层次聚类:层次聚类创建树状的簇结构。它可以是凝聚性的(自下而上),也可以是分裂性的(自上而下)。这种方法提供了集群的层次结构,提供了更细致的数据视图。
- DBSCAN(基于密度的噪声应用空间聚类): DBSCAN 可以根据数据点的密度有效识别不同形状和大小的聚类。它还可以发现数据中的异常值和噪音。
- 潜在狄利克雷分配(LDA): LDA是一种用于主题建模的概率模型。它发现文档集合中的主题,并为每个文档分配这些主题的分布。
- 词嵌入: Word2Vec 和 Doc2Vec 等技术可创建单词和文档的向量表示,从而更容易根据向量空间中的相似性对文本数据进行聚类。
四、实际应用
文本聚类在各个领域都有应用,提供有价值的见解和解决方案。一些现实世界的例子包括:
- 新闻聚合:新闻网站根据主题对文章进行聚合,为读者提供更有组织性和个性化的新闻源。
- 电子商务:在线零售商使用文本聚类对产品进行分组,使客户更容易找到相关商品并改进推荐。
- 学术研究:研究人员使用文本聚类来识别研究趋势,这可以帮助发现新的探索领域。
- 社交媒体分析:企业使用通过文本聚类进行的情感分析来衡量客户满意度并调整营销策略。
五、代码
使用数据集和绘图创建用于文本聚类的完整 Python 代码示例可能相当广泛,但我可以为您提供一个简化的示例,使用流行的 scikit-learn 库进行文本聚类,并使用 Matplotlib 进行可视化。在此示例中,我们将使用 20 个新闻组数据集,其中包含分类为 20 个不同主题的新闻组文档。
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cluster import KMeans
from sklearn.datasets import fetch_20newsgroups
from sklearn.decomposition import TruncatedSVD
import matplotlib.pyplot as plt# Load the 20 Newsgroups dataset
newsgroups = fetch_20newsgroups(subset='all', remove=('headers', 'footers', 'quotes'))# Vectorize the text data using TF-IDF
tfidf_vectorizer = TfidfVectorizer(max_df=0.5, max_features=1000, stop_words='english')
tfidf_matrix = tfidf_vectorizer.fit_transform(newsgroups.data)# Reduce dimensionality using LSA (Latent Semantic Analysis)
lsa = TruncatedSVD(n_components=2)
lsa_matrix = lsa.fit_transform(tfidf_matrix)# Perform K-Means clustering
k = 20 # Number of clusters (based on the 20 Newsgroups categories)
kmeans = KMeans(n_clusters=k, random_state=42)
kmeans.fit(lsa_matrix)# Visualize the clusters
labels = kmeans.labels_
cluster_centers = kmeans.cluster_centers_plt.figure(figsize=(10, 8))
plt.scatter(lsa_matrix[:, 0], lsa_matrix[:, 1], c=labels, cmap='viridis')
plt.scatter(cluster_centers[:, 0], cluster_centers[:, 1,], s=200, c='red')
plt.title("Text Clustering with K-Means")
plt.show()在此代码中:
- 我们加载 20 个新闻组数据集,其中包含来自不同新闻组的文本文档。
- 我们使用 TF-IDF(词频-逆文档频率)向量化将文本数据转换为数值特征。
- LSA(潜在语义分析)用于将维度降低到 2D 以实现可视化目的。
- K-Means 聚类的聚类数量等于新闻组类别的数量 (k = 20)。
- 最后,我们在 2D 空间中绘制文本文档,并根据聚类对它们进行着色。红点代表聚类中心。
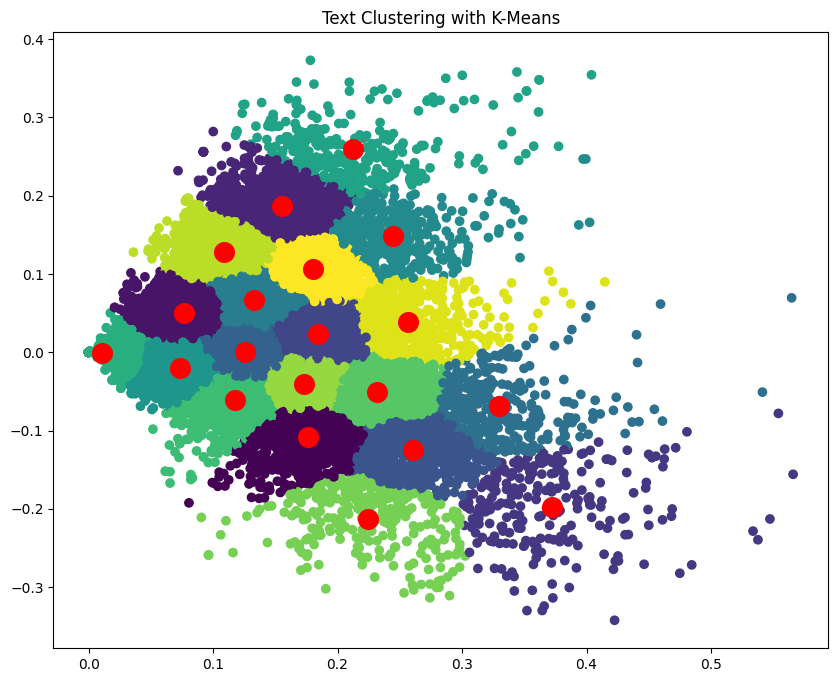
请注意,这是一个简化的示例,在实践中,您可能需要预处理文本数据、调整超参数并使用更高级的技术来获得更好的聚类结果。
六、结论
NLP 中的文本聚类是一种多功能且必不可少的工具,用于从非结构化文本数据中提取有价值的见解和结构。它的方法论,包括 K-Means、层次聚类和 LDA,使我们能够发现模式、对相似文档进行分组并组织内容。它的实际应用有很多,从新闻聚合到电子商务中的情绪分析。随着 NLP 的不断发展,文本聚类仍将是利用文本数据的力量推动各个领域的明智决策和解决方案的基石。
埃弗顿戈梅德