文章目录
- 前言
目录
文章目录
前言
一、主流数据库以及如何登陆数据库
二、常用命令使用
三、SQL分类
3.1 存储引擎
四、创建数据库如何设置编码等问题
4.1操纵数据库
4.2操纵表
五、数据类型
六、表的约束
七、基本查询
八、函数
九、复合查询
十、表的内连和外连
十一、索引
十二、事务
十三、视图
十四、用户管理
十五、连接MySQL
总结
前言
一、主流数据库以及如何登陆数据库
mysql -h 127.0.0.1 -P 3306 -u root -p注意:
如果没有写-h 那么默认连接的就是本地,-P是指定端口号,不写默认是3306.(-h就是指明登录部署了mysql服务的主机)
-u代表要登录的用户,后面跟root代表我们要登录的是root,最后的-p是以输入密码的方式登录。
当然也可以修改配置文件进行root免密码登录:
1. vim /etc/my.cnf 打开mysql配置文件
2.在mysqld最后一栏加入skip-grant-tables选项并且保存退出
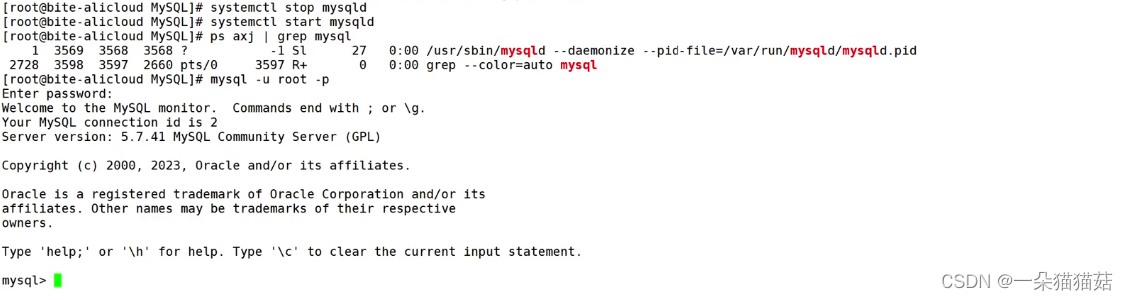
3.systemctl restart mysqld 重启mysql服务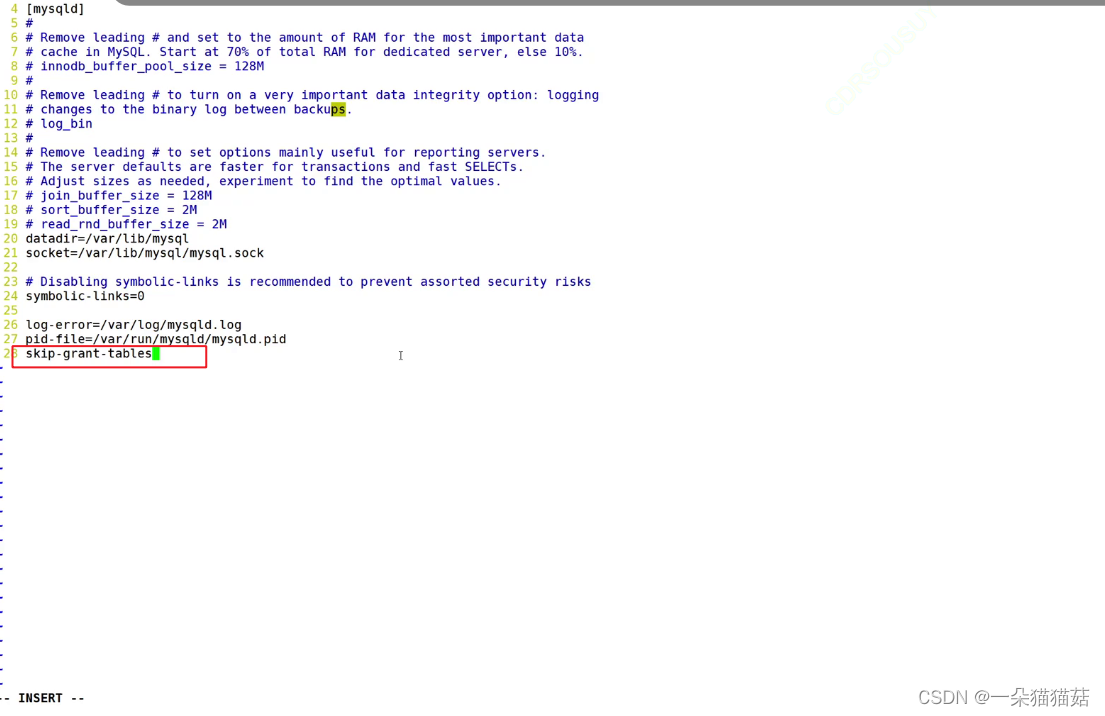

二、常用命令使用
1.显示所有数据库
show databases;注意:SQL语言的后面是用;做结尾的。

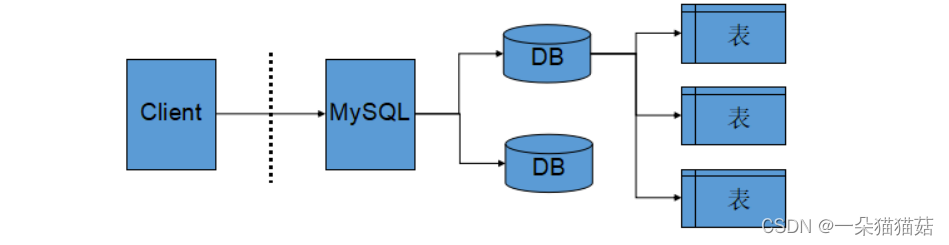
下面我们先认识一下mysql是如何存储数据的:
首先进入/etc/my.cnf文件,然后我们会看到datadir,这个后面的路径就是数据库数据存储的位置

进入该路径后我们就可以看到mysql中显示出来的数据库了:

所以建立一个数据库的本质就是在linux下创建一个目录。
2.创建数据库
create database test;test是用于演示的数据库,这个名字根据需要自己设置。

3.使用数据库
use test;注意:要对某个数据库做操作都需要先进行使用

4.创建数据库表
create table student(id int,name varchar(32),gender varchar(2)
);意思就是在test这个数据库中创建一个student表,这个表中列名称id为int类型,name为varchar类型,varchar是可变的char最大给了32个字节,后面详细讲,gender的类型也是varchar。
当建立一张表后,我们去该数据库目录下看看有什么区别:

所以在数据库内建表本质就是在linux下创建对应的文件即可。
注意:这个操作是mysqld帮我们做的。所以数据库本质也是文件,只不过这些文件不由程序员主动操作,而是由数据库服务帮我们进行操作。
5.表中插入数据
insert into student (id,name,gender) values(1,'张三','男');insert into表示在student这张表中插入数据,表后面括号内三个列名称代表向这三列进行插入,后面的values表示这三列对应的值,也就表示插入id为1,name为张三,gender为男的数据。

6.显示表中数据
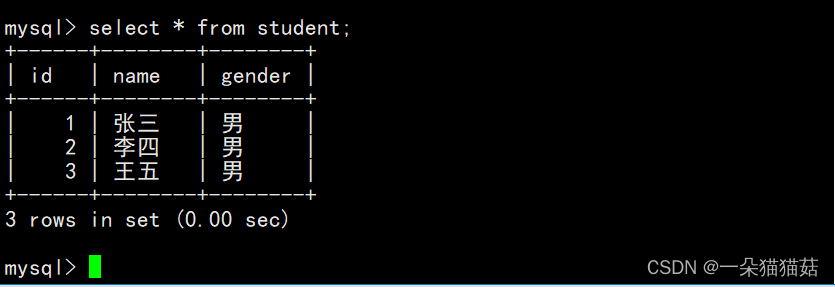
select * from student;显示student这张表的数据:
7.显示数据库中所有表
show tables;
8.删除表
drop table student;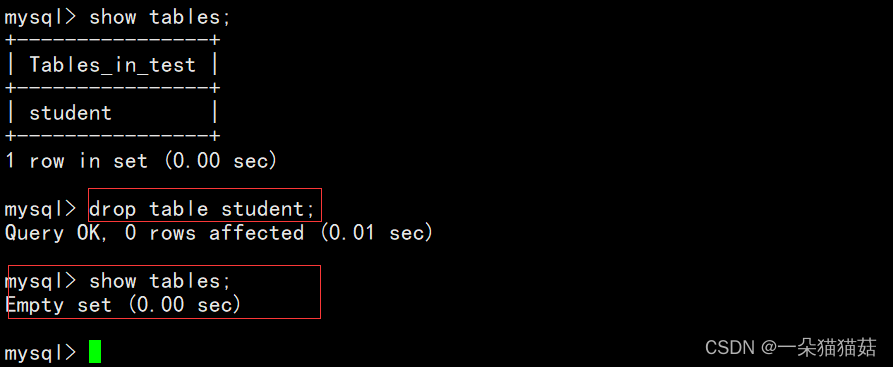
9.删除数据库
drop database test;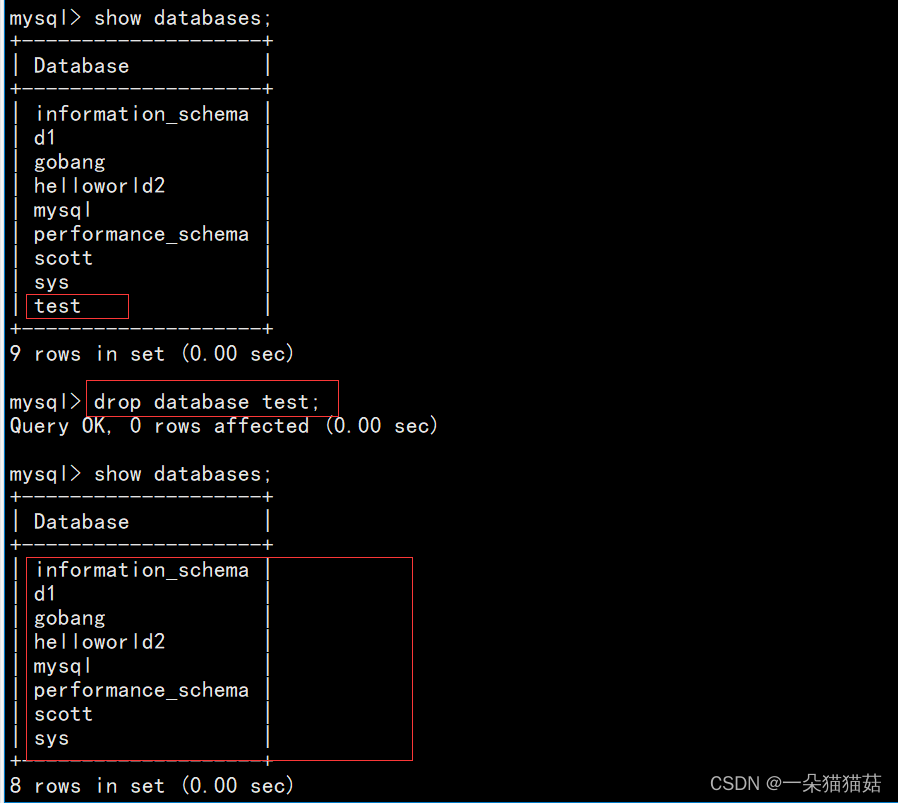

删掉后我们也可以看到linux下的test目录也被删除了,所以用drop命令一定要小心。
三、SQL分类
3.1 存储引擎
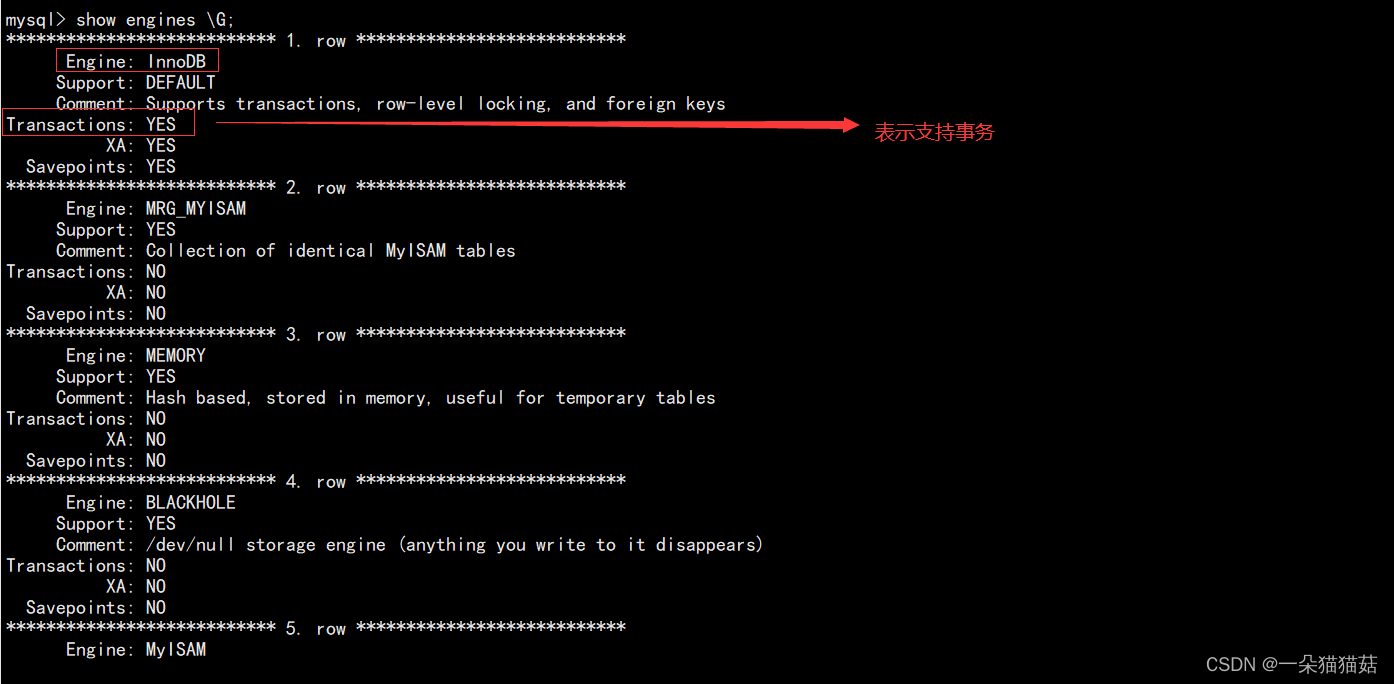
show engines;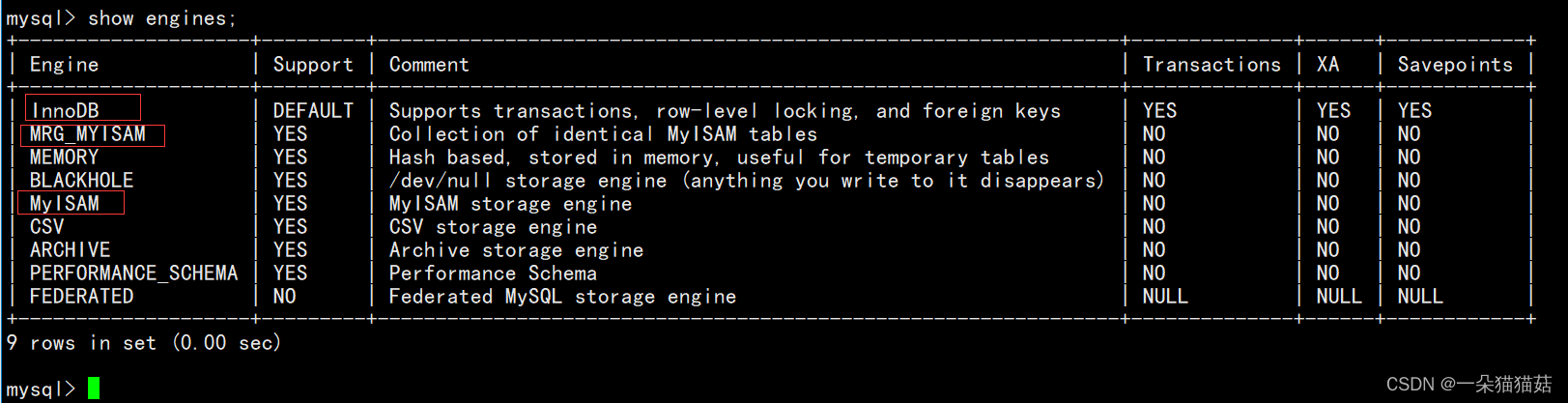
我们经常用到的存储引擎实际上也就是上面标红的。
四、创建数据库如何设置编码等问题
CREATE DATABASE [IF NOT EXISTS] db_name [create_specification [,
create_specification] ...]
create_specification:
[DEFAULT] CHARACTER SET charset_name
[DEFAULT] COLLATE collation_name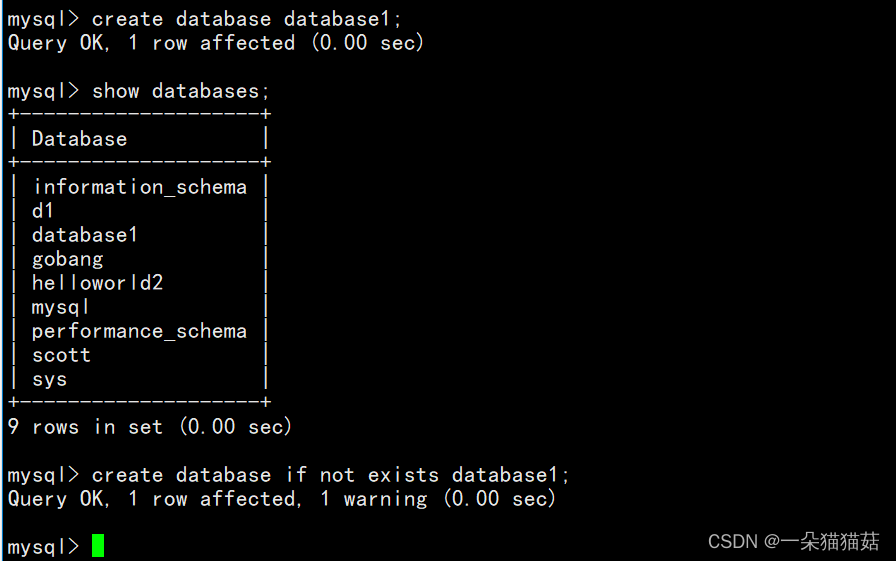
加入if not exists的区别是再次插入重复的数据库时不会报错。
创建数据库的时候,有两个编码集:
1.数据库编码集(数据库未来存储数据用到的编码) 2.数据库校验集(支持数据库进行字段比较使用的编码,本质也是一种读取数据库中数据的采用的编码格式)
以上两个编码集保证了数据库无论对数据做任何操作,都必须保证操作和编码必须是编码一致的。
1.查看编码集的命令
show variables like 'character_set_database';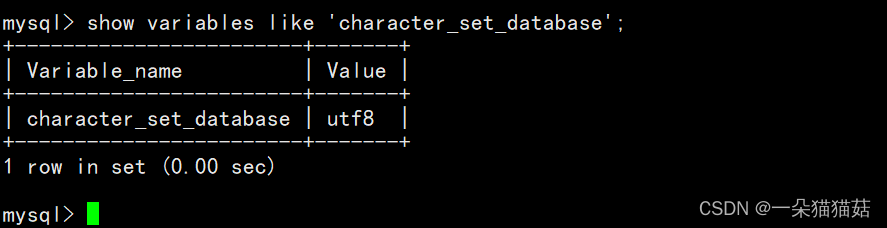
2.查看校验集的命令
show variables like 'collation_database';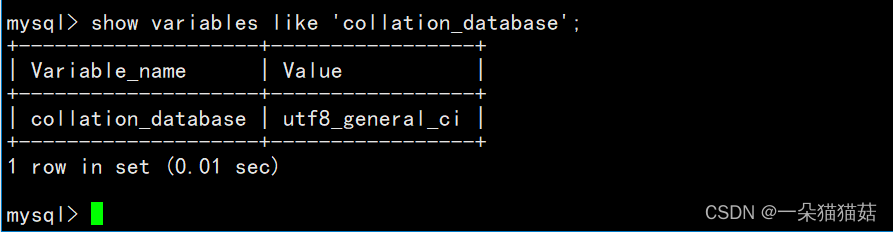
下面我们看看默认创建数据库时的编码集和校验集:
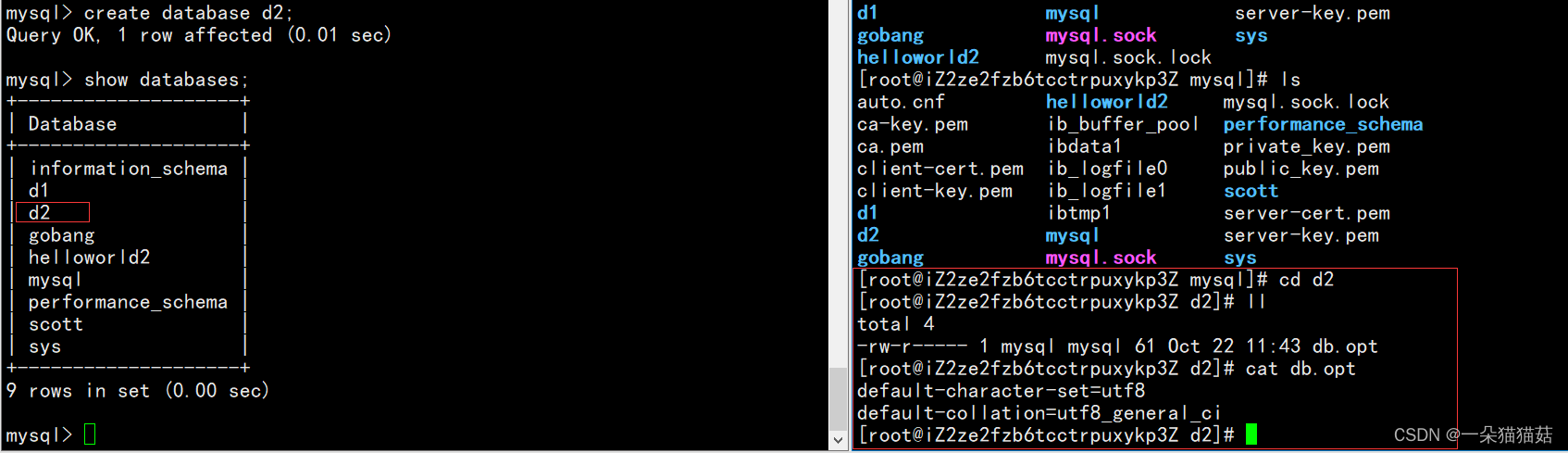
可以看到不指明的时候是按照mysql配置文件中的编码集和校验集来配置的。
下面我创建一个演示数据库d3,创建库并且指定编码集和校验集的命令如下:
create database d3 charset=gbk collate gbk_chinese_ci;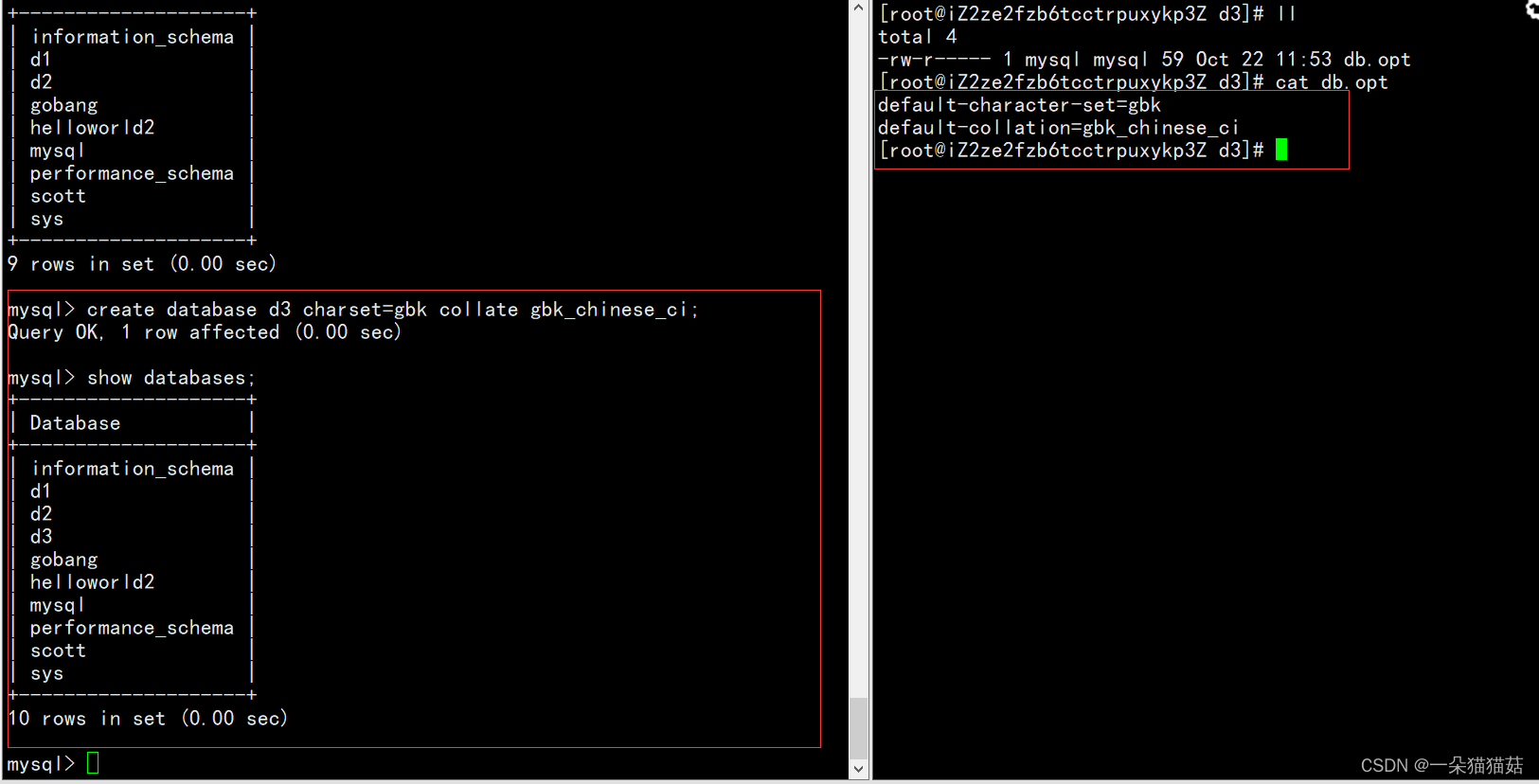
创建完成后我们可以看到编码集和校验集变成我们指定的了。在创建数据库时为什么要设置编码呢?这是因为数据库内的表的编码和校验集都是继承于数据库的。
4.1操纵数据库
1.查看自己在哪个数据库中
select database();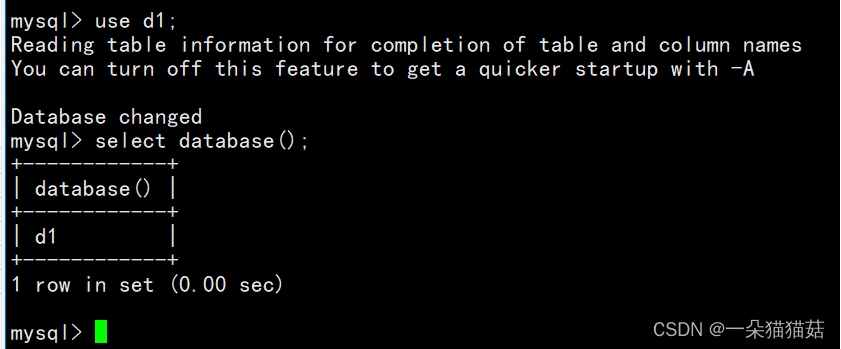
2.修改数据库
alter database d2 charset=gbk collate gbk_chinese_ci;将d2这个数据库的编码集和校验集进行修改。
3.显示创建数据库时的命令
show create database d2;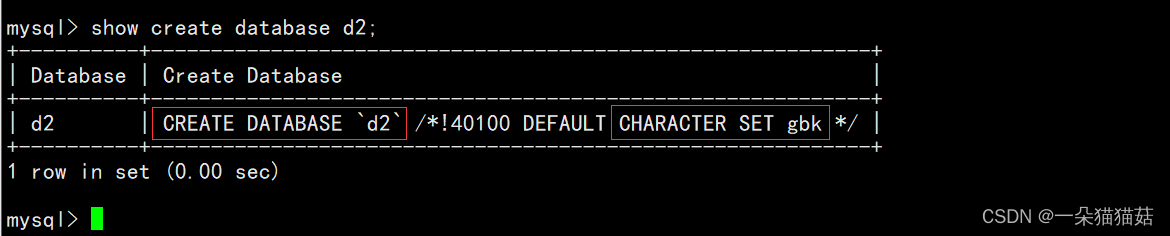
4.备份
# mysqldump -P3306 -u root -p 密码 -B 数据库名 > 数据库备份存储的文件路径示例:将mytest库备份到文件(退出连接)
# mysqldump -P3306 -u root -p123456 -B mytest > D:/mytest.sql
这时,可以打开看看 mytest.sql 文件里的内容,其实把我们整个创建数据库,建表,导入数据的语句
都装载这个文件中。5.还原
mysql> source D:/mysql-5.7.22/mytest.sql;注意事项:
如果备份的不是整个数据库,而是其中的一张表,怎么做?
# mysqldump -u root -p 数据库名 表名1 表名2 > D:/mytest.sql同时备份多个数据库
# mysqldump -u root -p -B 数据库名1 数据库名2 ... > 数据库存放路径
如果备份一个数据库时,没有带上-B参数, 在恢复数据库时,需要先创建空数据库,然后使用数据
库,再使用source来还原6.查看连接情况
show processlist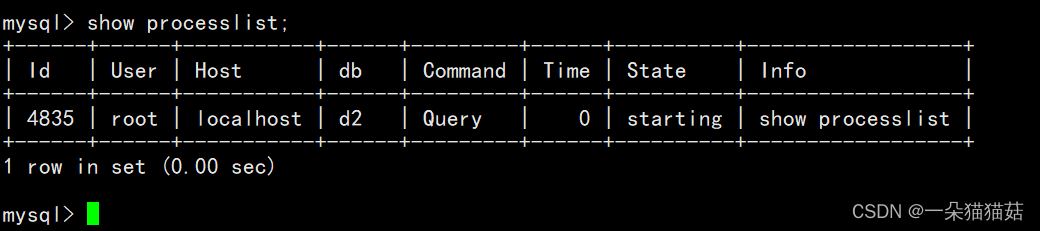
可以告诉我们当前有哪些用户连接到我们的MySQL,如果查出某个用户不是你正常登陆的,很有可能你的数据库被人入侵了。以后大家发现自己数据库比较慢时,可以用这个指令来查看数据库连接情况。
4.2操纵表
1.创建表
create table table_name(field1 datatype,field2 datatype,field3 datatype
) charset 字符集 collate 校验规则 engine 存储引擎;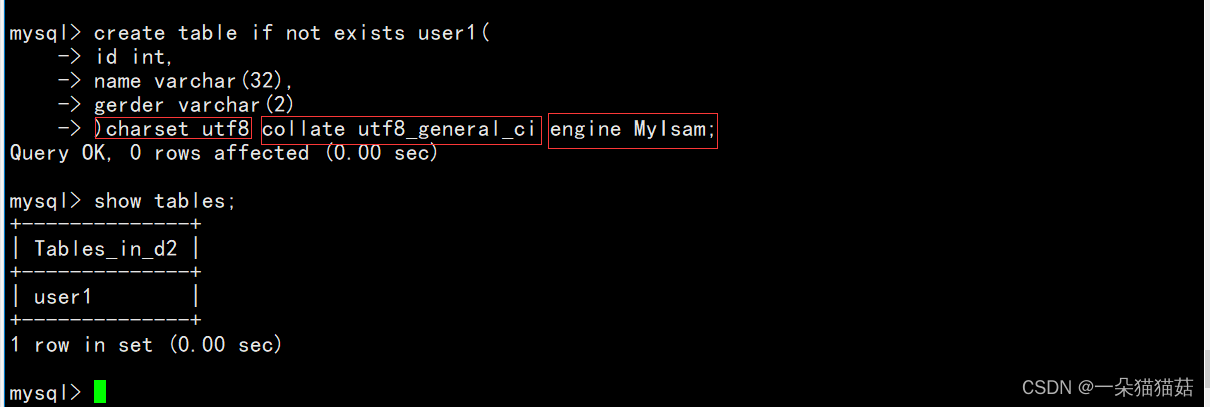
当我们创建成功后看一下这个表在linux目录下是如何显示的:
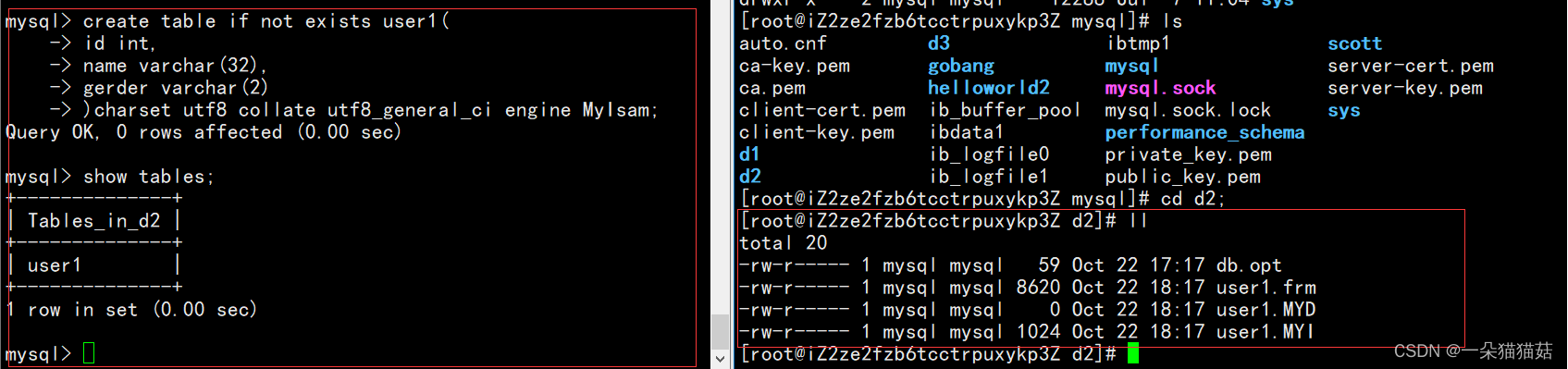
可以看到在d2目录中多出了三个文件,下面我们再创建一个表并且使用不同的存储引擎再来看看效果:
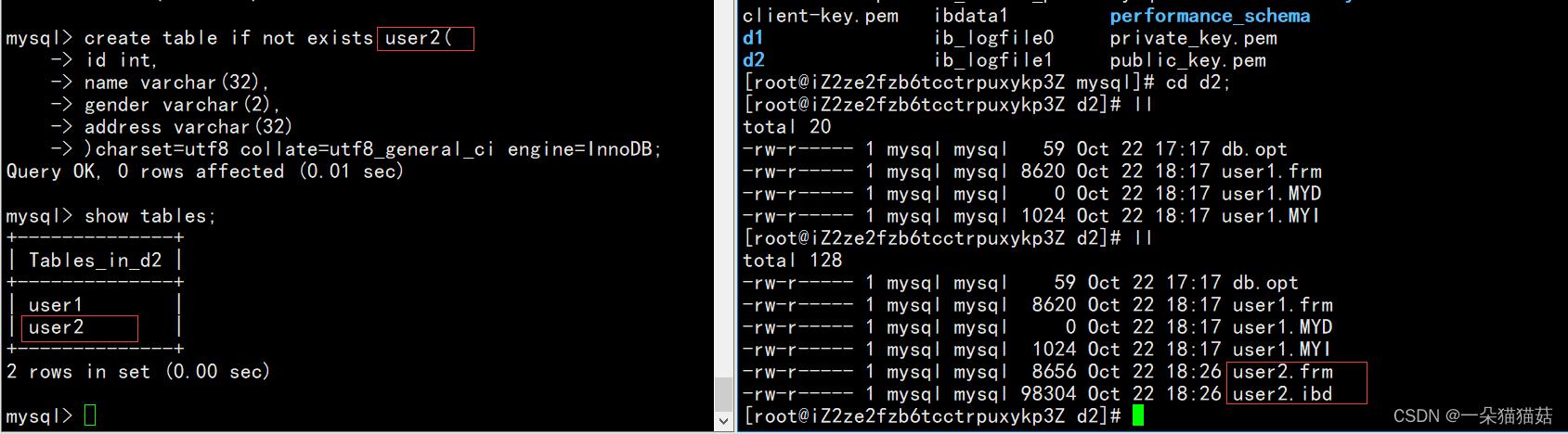
我们可以发现用InnoDB做存储引擎需要创建两个文件,用MyIsam做存储引擎需要创建三个文件。
当然我们刚开始就说过,如果创建的时候不指明使用哪个存储引擎哪个字符集就会使用我们配置文件中默认的那个。
2.查看表
我查看表的基本步骤是:1.先查看使用的是哪个数据库 2.再查看这个数据库中有哪些表 3.然后选择使用这个表。
desc 表名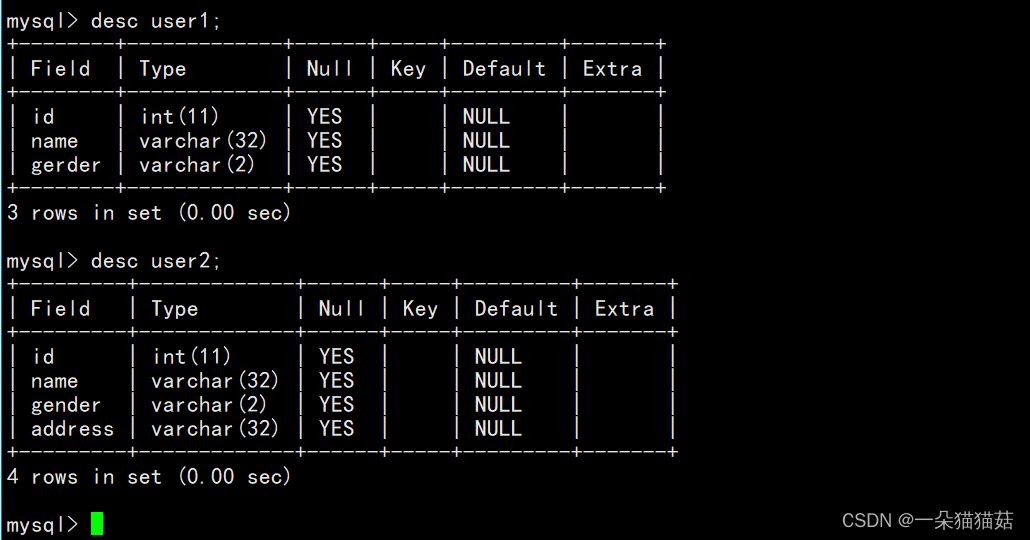
3.查看创建表时的sql语句
show create table user1(表名) \G(格式化)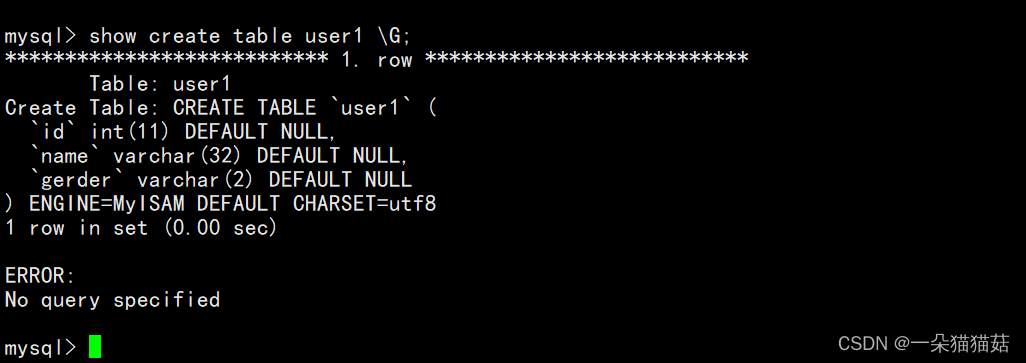
4.修改表
1.添加某一列
alter table 表名 add 添加的列名 添加的列的类型;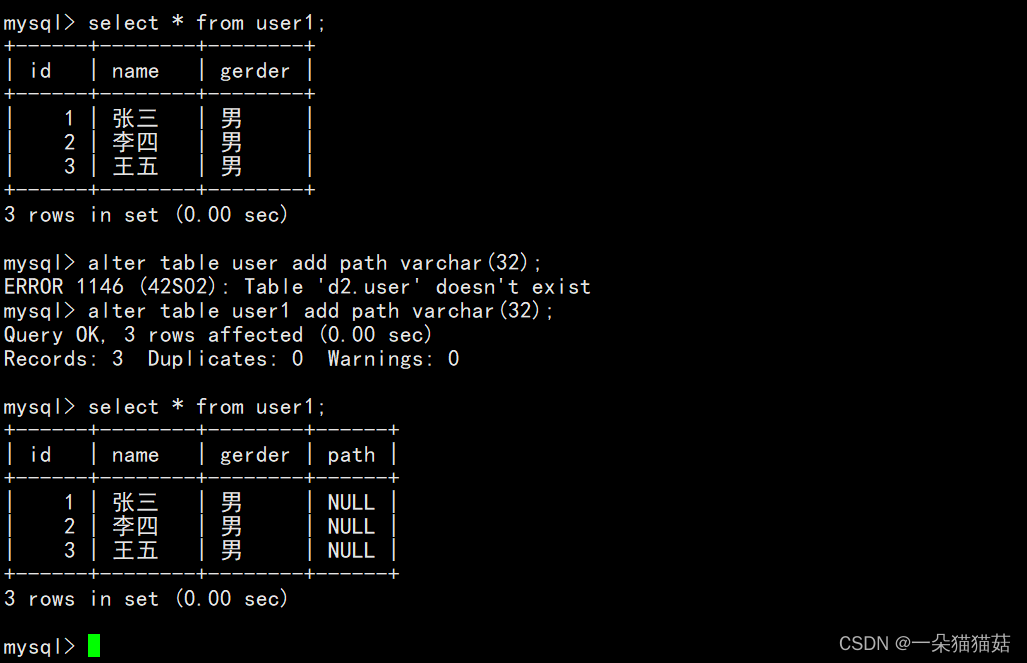
当然也可以指定将新列放在某个位置:
alter table user1 add 列名 列类型 after name上面代码的意思是将新添加的列放在name列的后面。
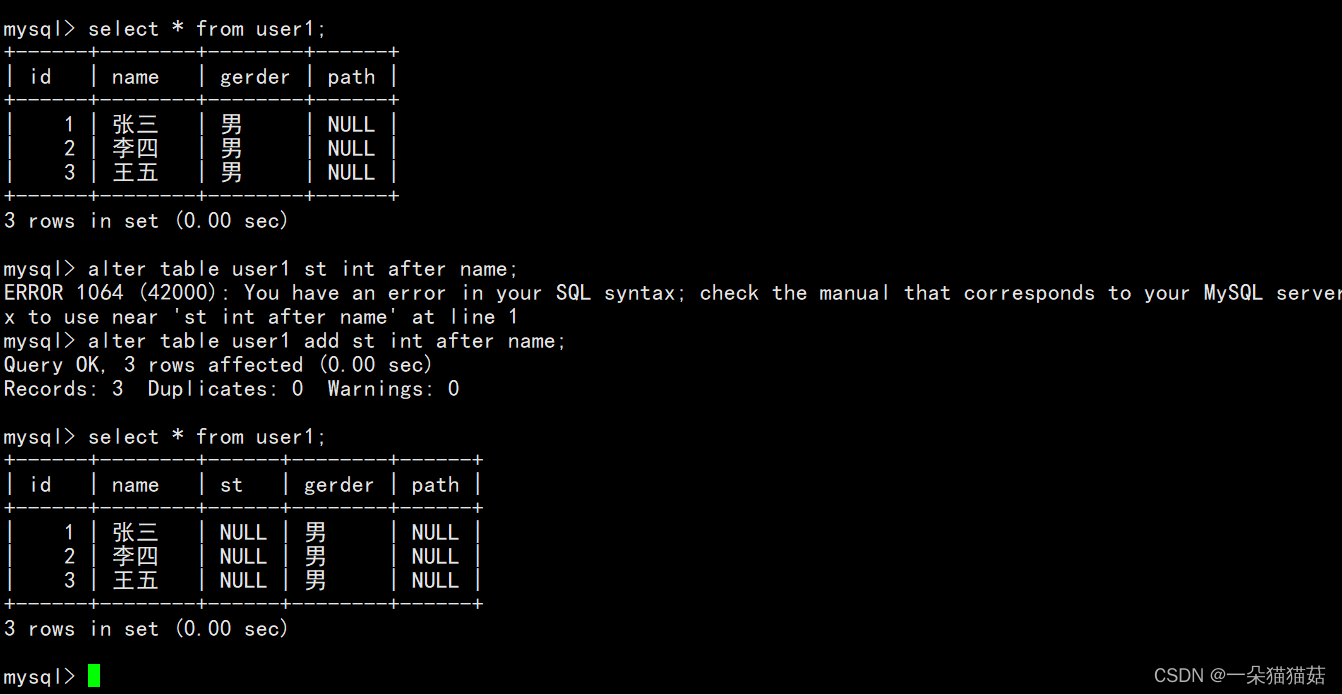
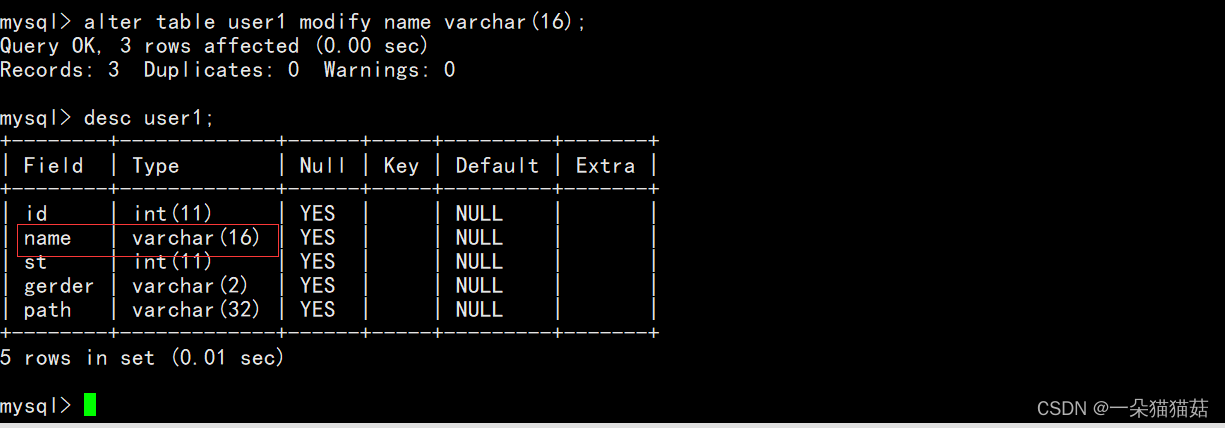
2.修改某一列的属性
alter table user1 modify name varchar(16);将user1表中的name列的属性修改为varchar(16)
3.删除某一列
alter table user1 drop path;
注意:删除后整个列都没有了,数据也没了。
4.修改表名
alter table user1 rename user;
5.修改列名称
alter table user change name xingming varchar(32);
注意:修改列名必须加上列的属性。
6.删除表
drop table 表名注意:轻易不要对表做修改和删除。
五、数据类型
1.数值类型
tinyint:字节数为1,有符号区间为-128~127,无符号区间为0~255
smallint:字节数为2,有符号区间为-32768~32767,无符号区间为0~65535
mediumint:字节数为3,有符号区间为-838608~838607,无符号区间为0~16777215
int:字节数为4,有符号区间为-2147483648~2147483647,无符号区间为0~4294967295
bigint:字节数为8,有符号区间为-9223372036854775808~9223372036854775807,无符号区间为0~18446744073709551615
在MySQL中,整形可以指定是有符号的和无符号的,默认是有符号的。可以通过unsigned来说明某个字段是无符号的。
2.bit类型
3.小数类型
4.decimal

7.日期和时间类型
六、表的约束
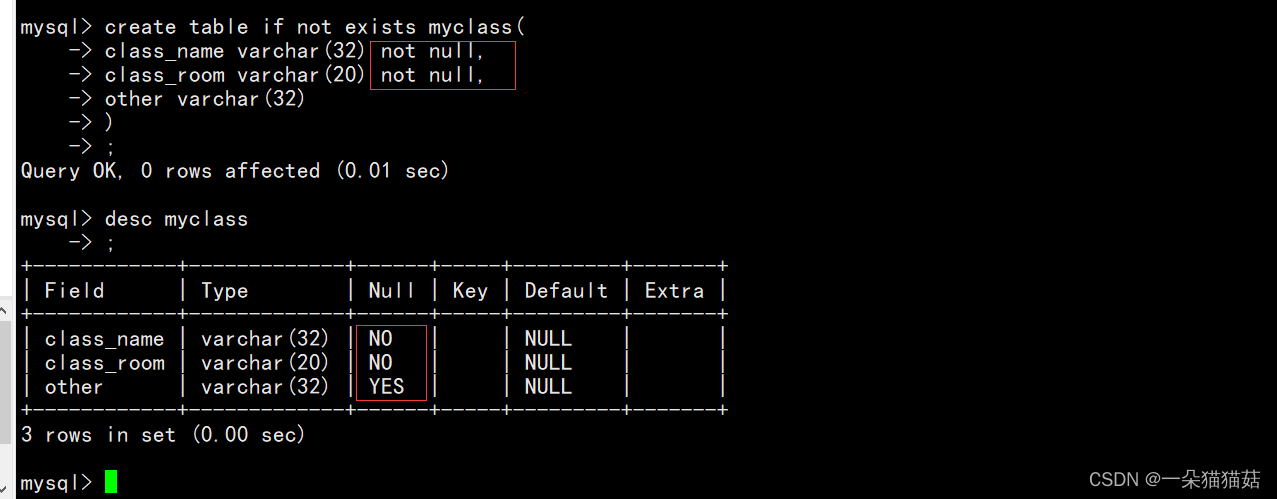

下面我们插入数据试一下:

可以看到张三成功使用了默认值,李四由于自己插入了age列所以不使用默认值。
default和not null的关系:
如果我们没有指定一列要插入,用的是default,如果建表中,对应列默认没有设置default值,无法直接插入。default和not null不冲突,而是相互补充的。
注意:MySQL是支持default和not null同时设置的,但是一般情况下都是设置了not null后就不再设置default.
3.列描述
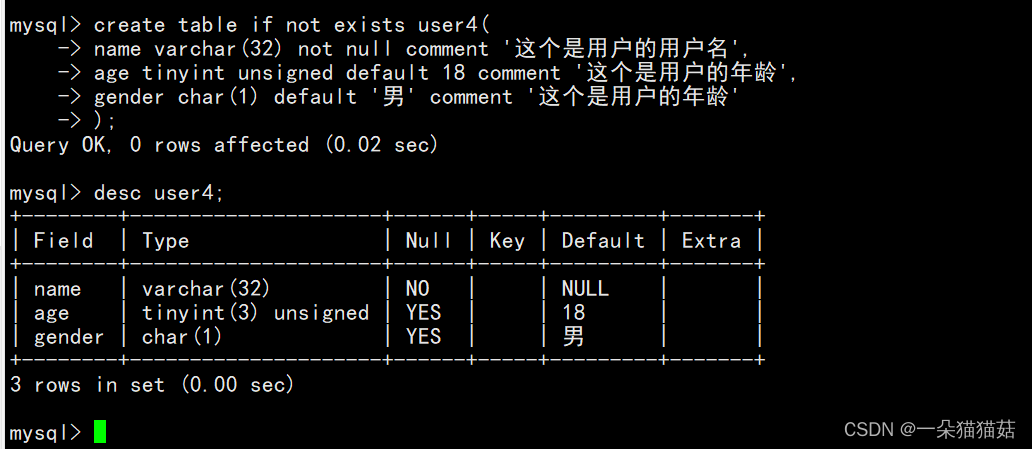
我们可以将comment理解为注释,那么为什么将它归为约束呢,我们看一看mysql内部是如何对comment做处理的:

通过查询创建该表时所用的语句我们得出结论,comment是给操纵数据库的管理员或者程序员看的,这是一种软性的约束。
4.zerofill约束

上图是一个普通int类型,下面我们插入数据看一下是如何显示的:
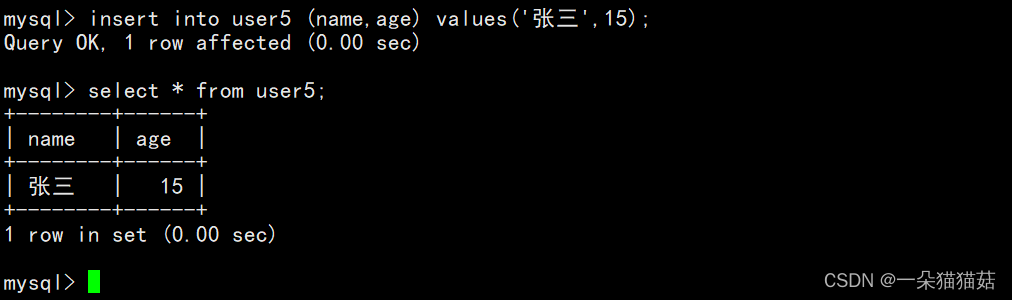
下面我再加上zerofill试一下:
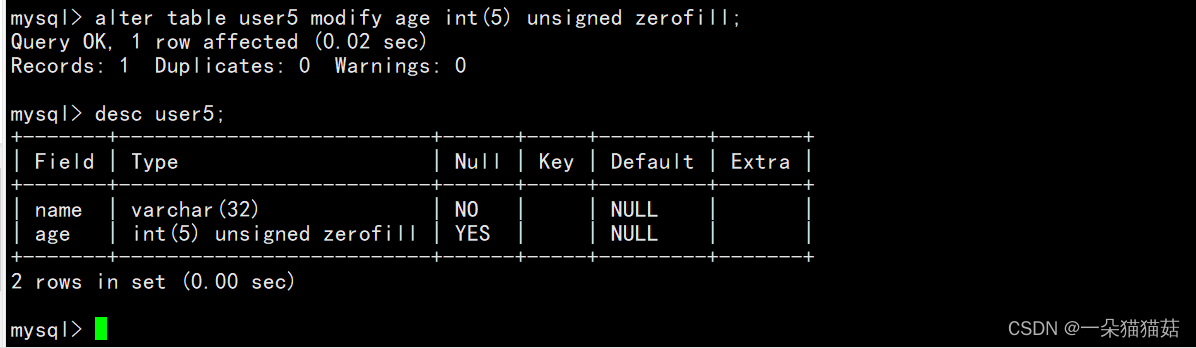
修改成功后我们再看一下数据:
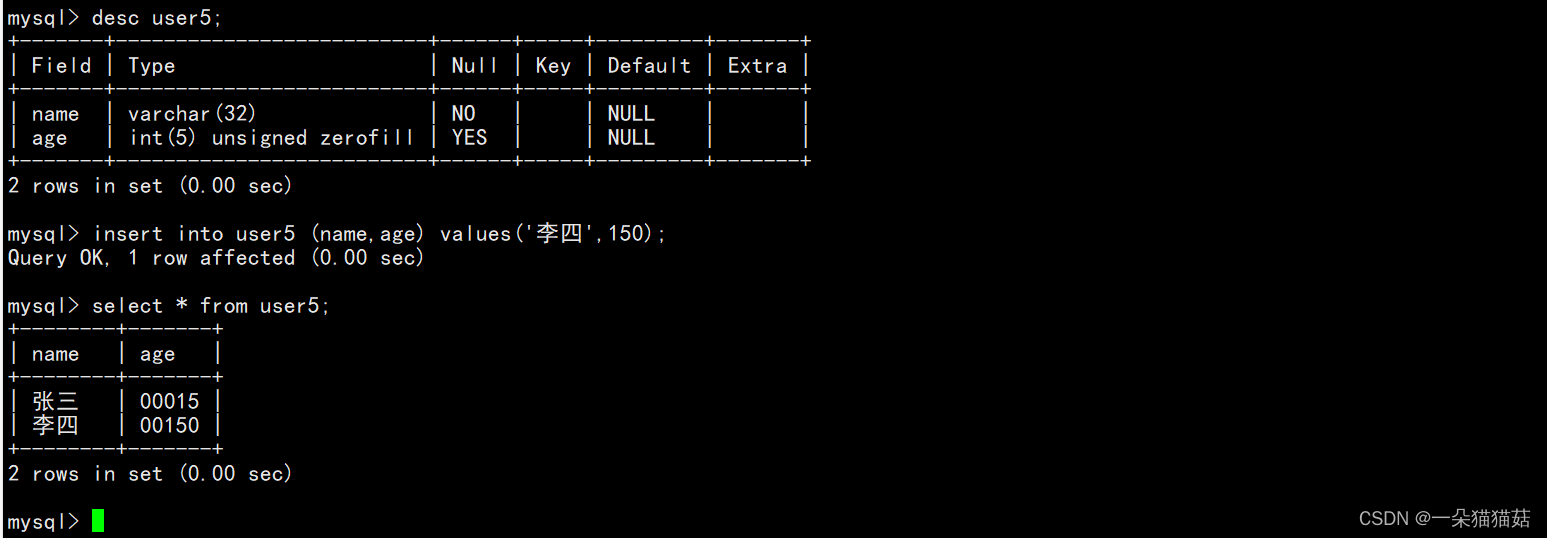
可以看到我们设置的是5位int,当位数不够时会自动在前面帮我们补0。如果够了或者超过指定位数,这个时候就直接显示了。也就是说zerofill是一个至少的行为。
5.主键约束
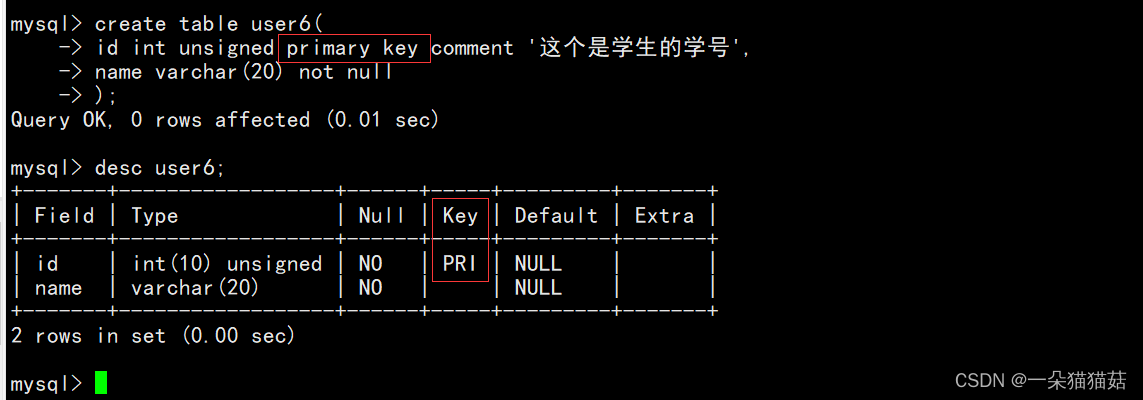
可以看到主键会自动加非空约束,下面我们验证一下唯一性:

可以看到主键是不允许重复的。当然我们也可以删除主键约束:
alter table user6 drop primary key;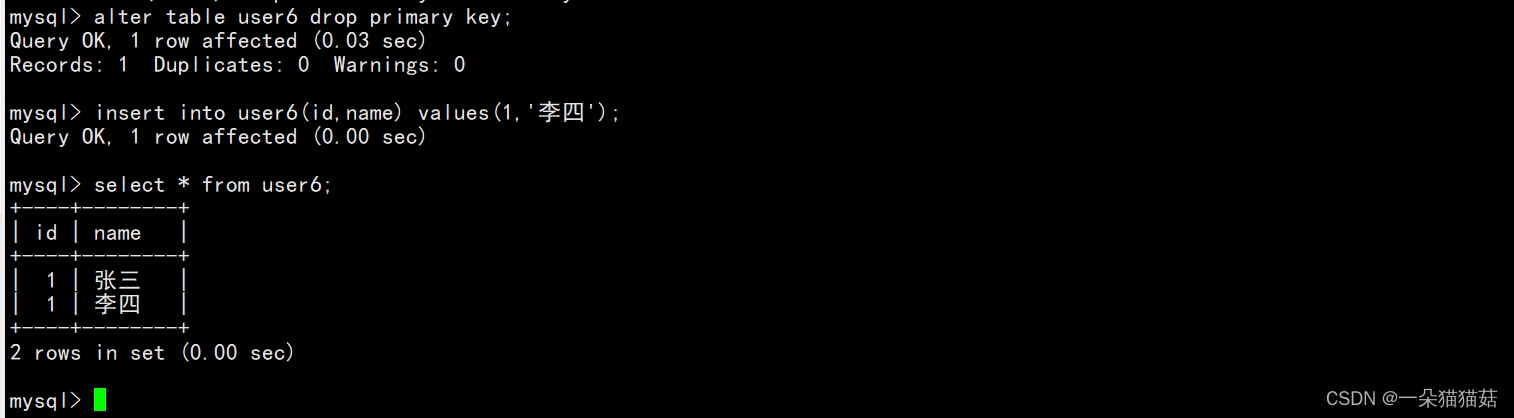
删除主键约束后我们就可以插入相同值了。
复合主键
一个主键不是只能添加给一列,而是可以同时将多个列合成为一个主键。
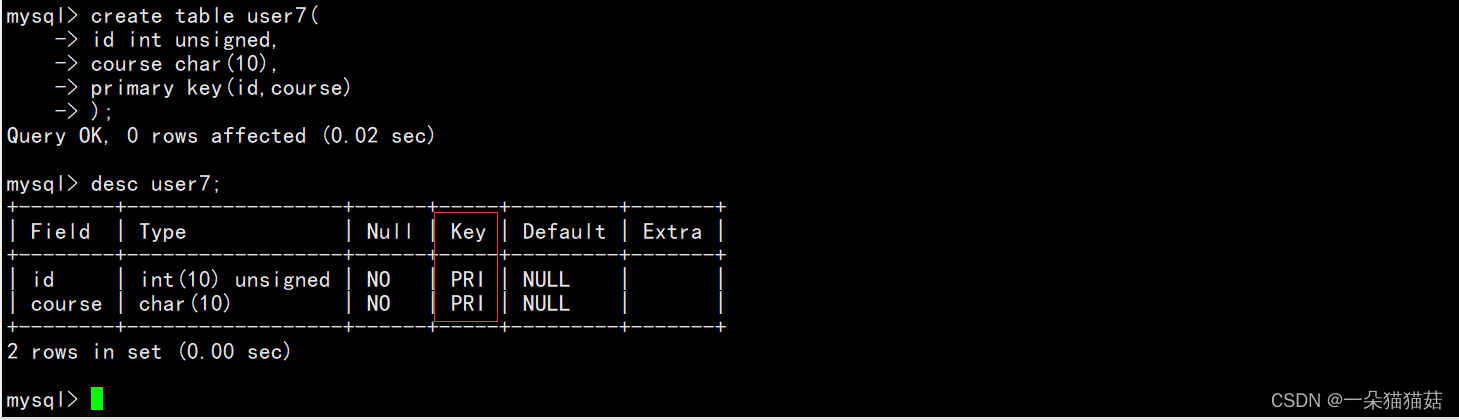
这个表可以保证id和course合起来不冲突。
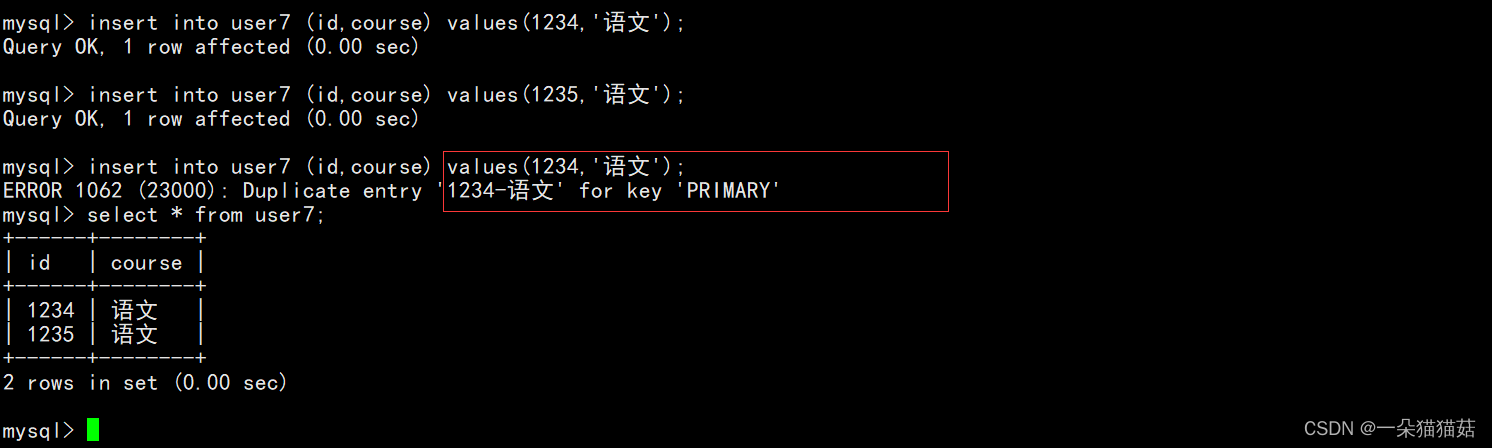
从上图我们可以看到只要两列数据不是完全一样就可以成功插入,复合主键保证了复合的这几列不会出现完全一样的情况。
auto_increment约束
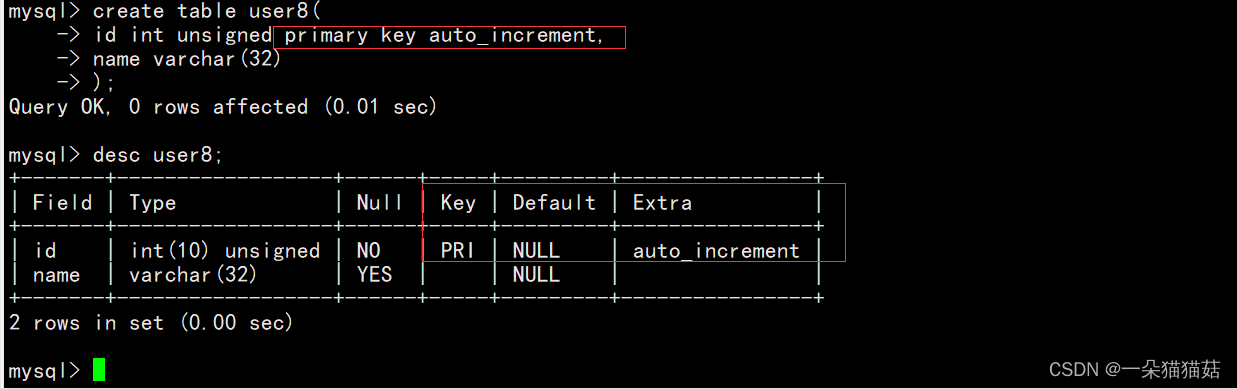
下面我们插入数据看看:
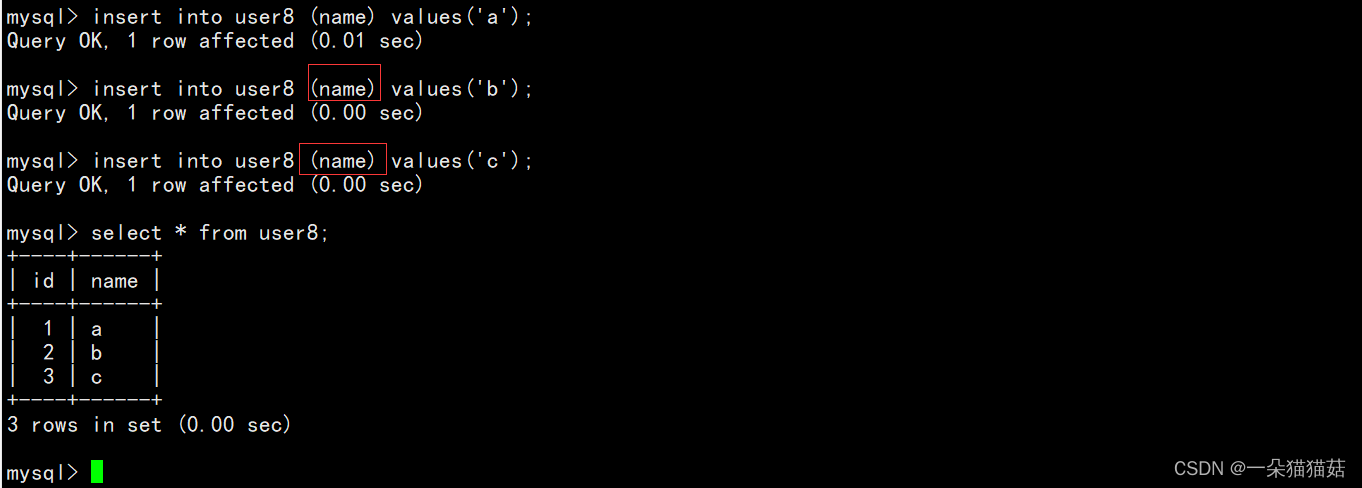
我们可以看到id会自动增加。注意:自增主键默认从1插入。当然我们也可以控制让自增主键默认从一个数开始:
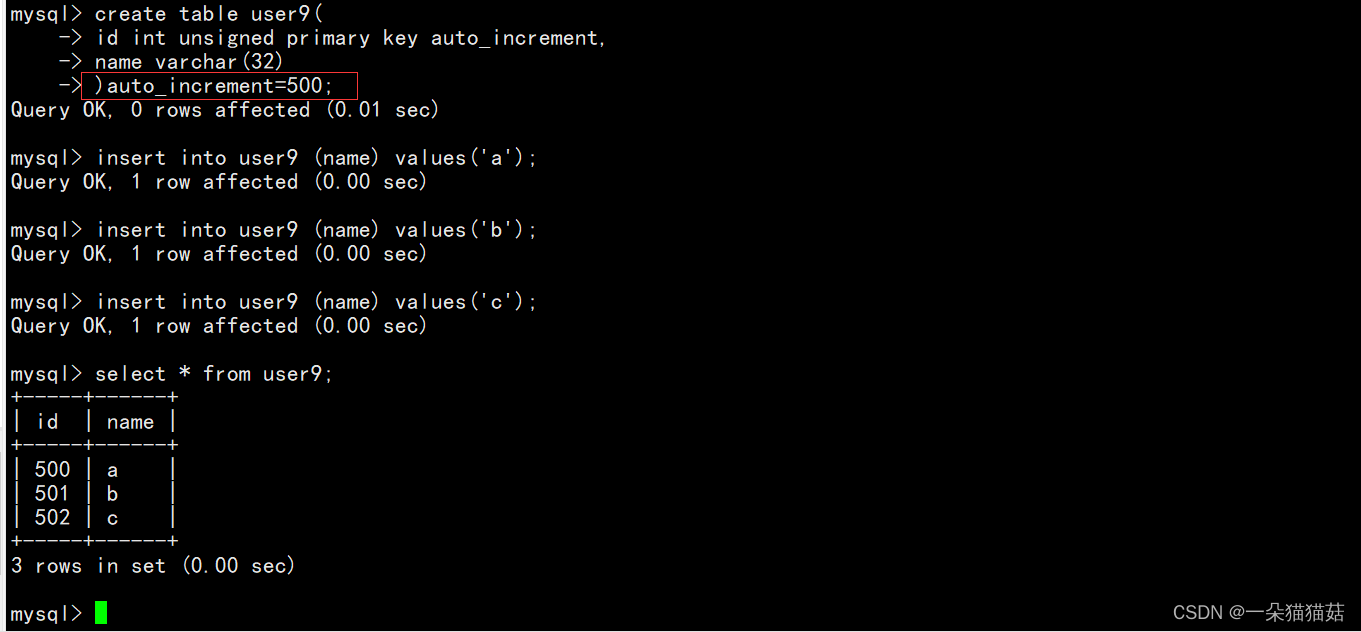
注意:只能有一个自增长,并且自增长必须是主键。
6.唯一键约束

下面我们插入演示一下区别:
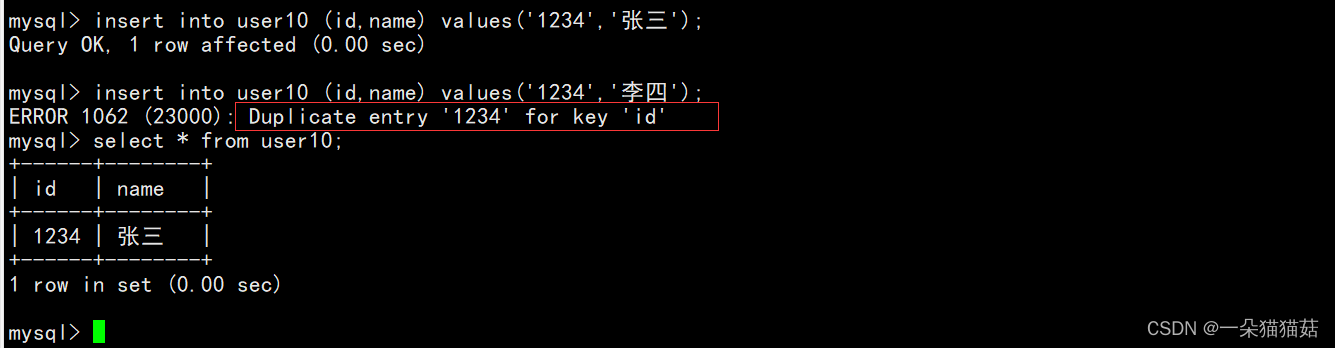
我们可以看到当我们重复插入id为1234的时候出现了错误,原因是唯一键约束了id不能相同。
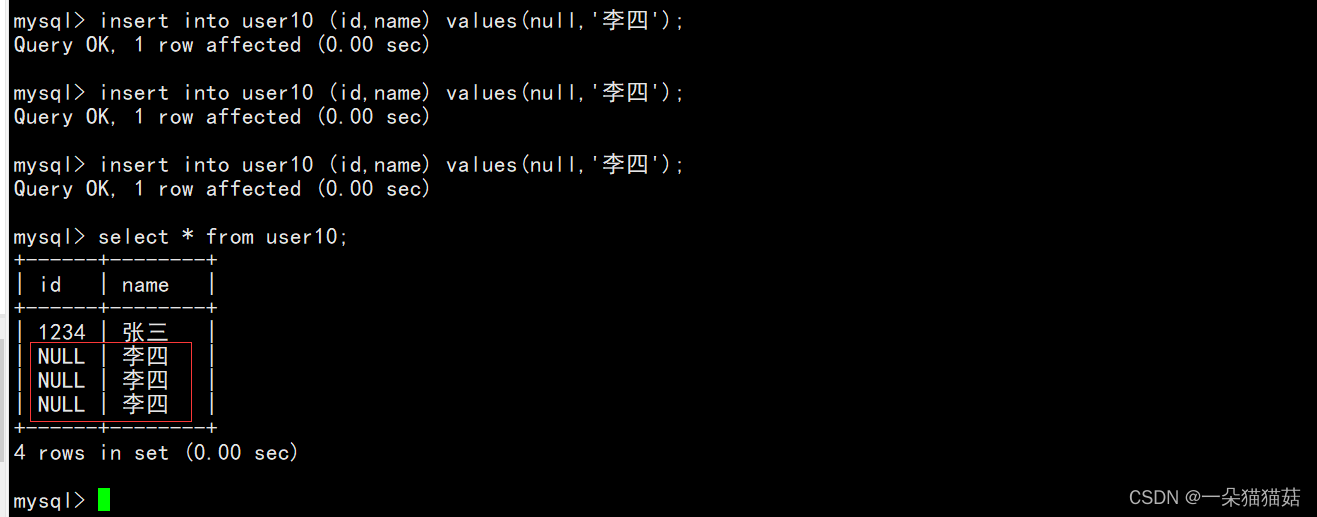
当我们插入空时我们发现是不受约束的,所以主键和唯一键的区别是主键不能为空,唯一键可以为空。主键和唯一键并不冲突而是互相补充的,比如员工表中员工id,姓名,电话三者的关系,员工id用主键约束不为空并且不能有重复值,电话用唯一键因为每个人的电话一定不相同,但是有可能为空。
当然,我们是可以将唯一键设置为非空的,唯一键默认是可以为空的。
7.外键
语法:
foreign key (字段名) references 主表(列)案例:现在有两张表,一个是学生表,一个是班级表,学生表中每个学生都有一个班级id,而通过班级id又可以找到这个班级,所以两个表的结构如下图所示:

像上图这样的关联关系我们称为外键约束。
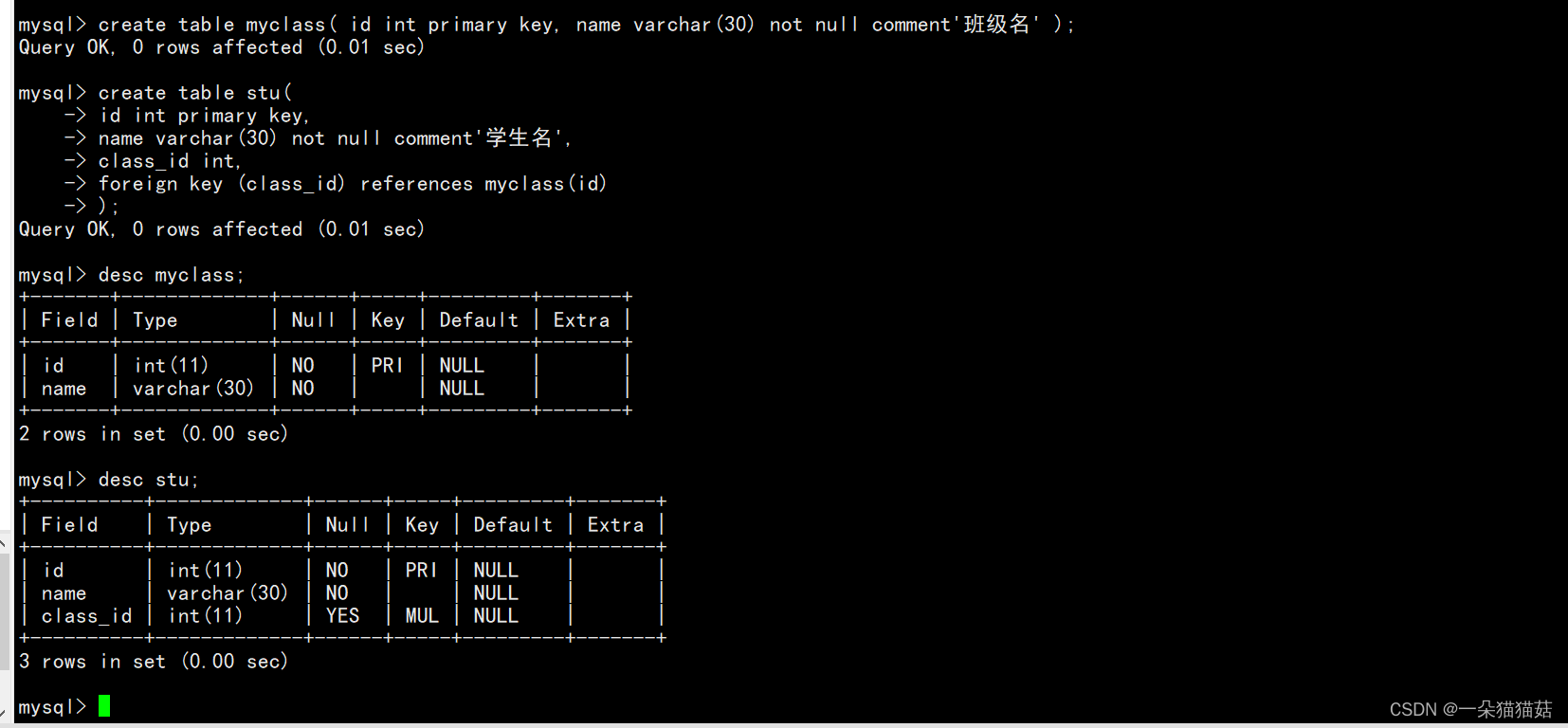
下面我们正常插入数据试试:

我们发现如果插入的学生的班级是存在的那么就没有问题,如果插入的学生的班级是不存在的就会报错,而这个实例中的班级就是外键,而上面的报错就是外键约束。
理解外键约束:
外键约束还有一个有趣的地方:

当一个班级表中还有学生的时候,我们要删除这个班级是不被允许的,因为mysql发现这个班级和某个学生在关联,所以不允许你删除。
当我们将这个班级内的学生删除,让这个班级里没有一个学生这个时候就可以将这个班级删除了。
七、基本查询
单行列插入:
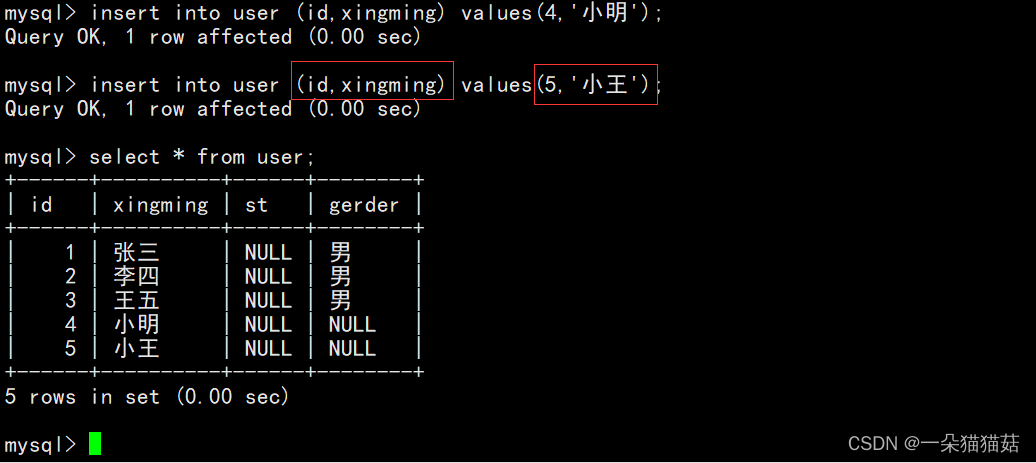
单列插入就是我们选定一列或多列进行数据插入,但是每一列一定要与values相对应。
全列插入:
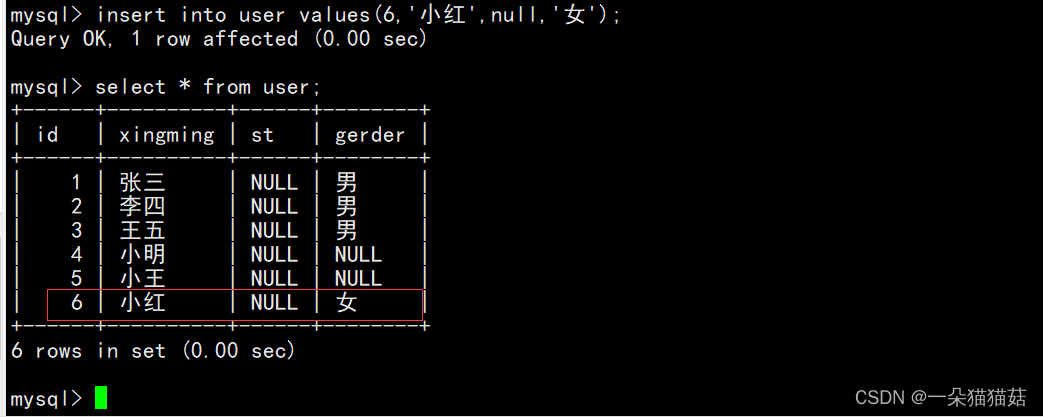
全列插入就是说我们默认对所有列进行插入,同样每一列必须和values里面的数据一一对应。
插入否则更新:
-- 主键冲突
INSERT INTO students (id, sn, name) VALUES (100, 10010, '唐大师');
ERROR 1062 (23000): Duplicate entry '100' for key 'PRIMARY'
-- 唯一键冲突
INSERT INTO students (sn, name) VALUES (20001, '曹阿瞒');
ERROR 1062 (23000): Duplicate entry '20001' for key 'sn'解决方法:
INSERT INTO students (id, sn, name) VALUES (100, 10010, '唐大师')
ON DUPLICATE KEY UPDATE sn = 10010, name = '唐大师';
Query OK, 2 rows affected (0.47 sec)
-- 0 row affected: 表中有冲突数据,但冲突数据的值和 update 的值相等
-- 1 row affected: 表中没有冲突数据,数据被插入
-- 2 row affected: 表中有冲突数据,并且数据已经被更新替换:
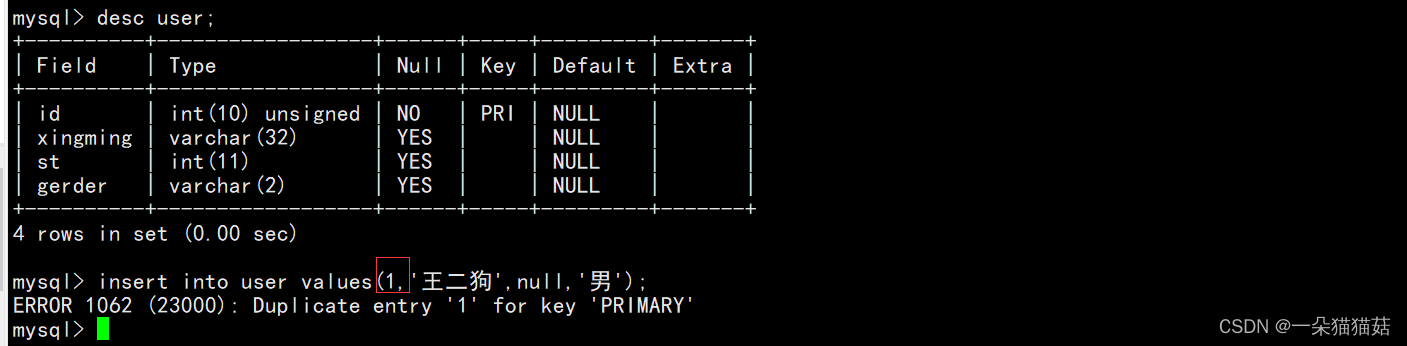
在上图中由于id为1的用于已经存在了,所以我们插入失败,下面我们用replace语句试一下:
-- 主键 或者 唯一键 没有冲突,则直接插入;
-- 主键 或者 唯一键 如果冲突,则删除后再插入
REPLACE INTO user VALUES (1, '曹阿瞒');
Query OK, 2 rows affected (0.00 sec)
-- 1 row affected: 表中没有冲突数据,数据被插入
-- 2 row affected: 表中有冲突数据,删除后重新插入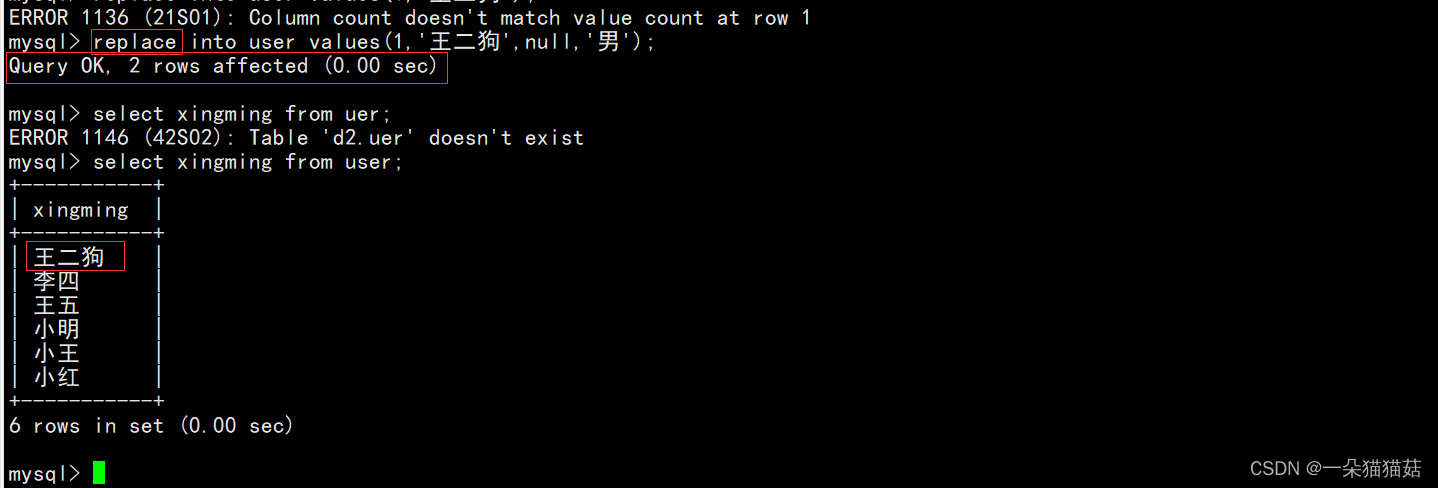
select语句:
基本语法:
SELECT
[DISTINCT] {* | {column [, column] ...}
[FROM table_name]
[WHERE ...]
[ORDER BY column [ASC | DESC], ...]
LIMIT ...select后面跟*表示筛选所有列,跟一列或者多列代表筛选出多列。from后面跟表名字,where可以指定筛选出每一列的值等于多少的数据,order by可以将筛选出来的数据进行排序。

上图是将user表中id和姓名显示出来,当然select也可以显示表达式,比如:

当然我们也可以修改表达式的名字:
只需要在表达式后面加as,as后面是新的名称。
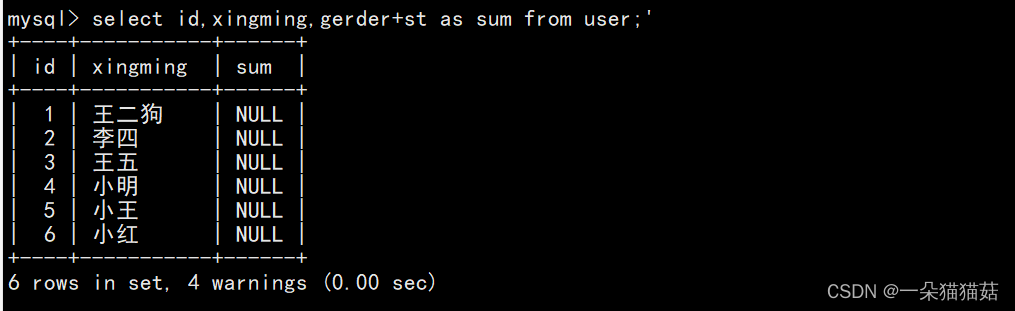
当然我们也可以用distinct来对查询出来的结果进行去重:
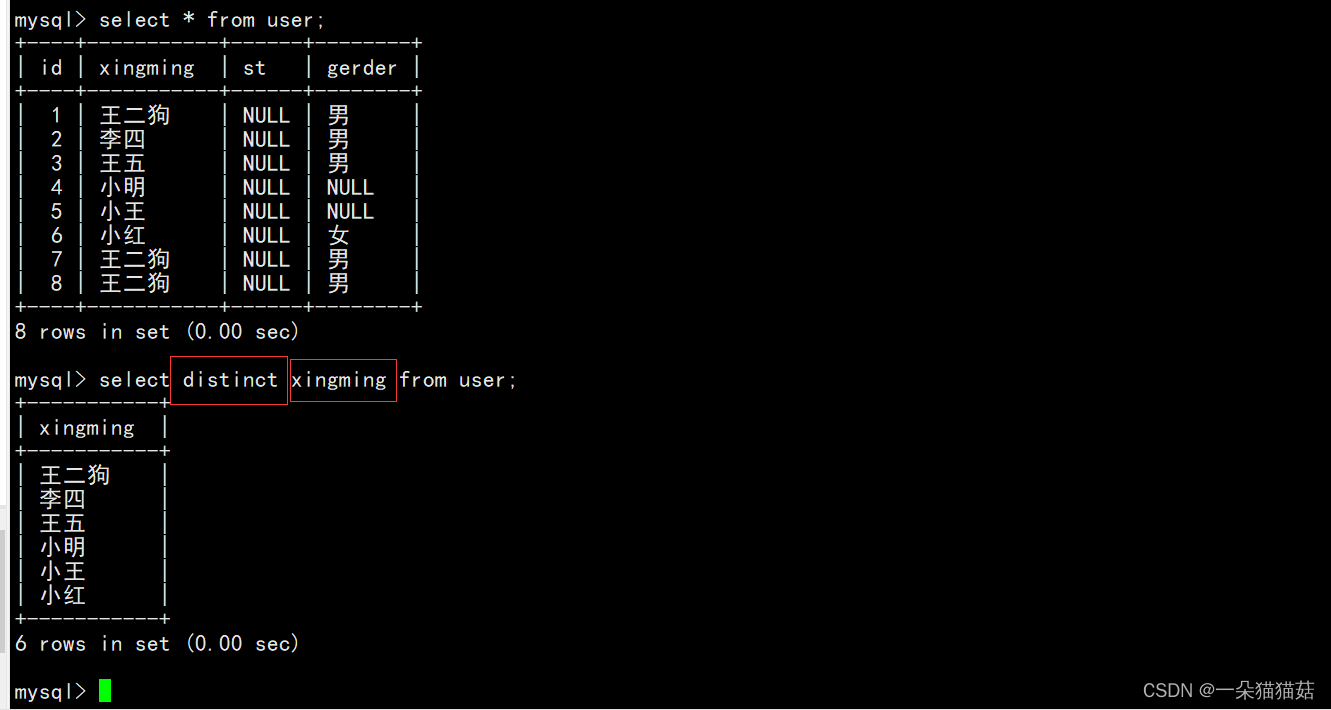
可以看到姓名重复的被自动去重了。
where子句:
在where子句中是需要用到用算符的,下面我们看一下MySQL中的运算符:
比较运算符:

逻辑运算符:

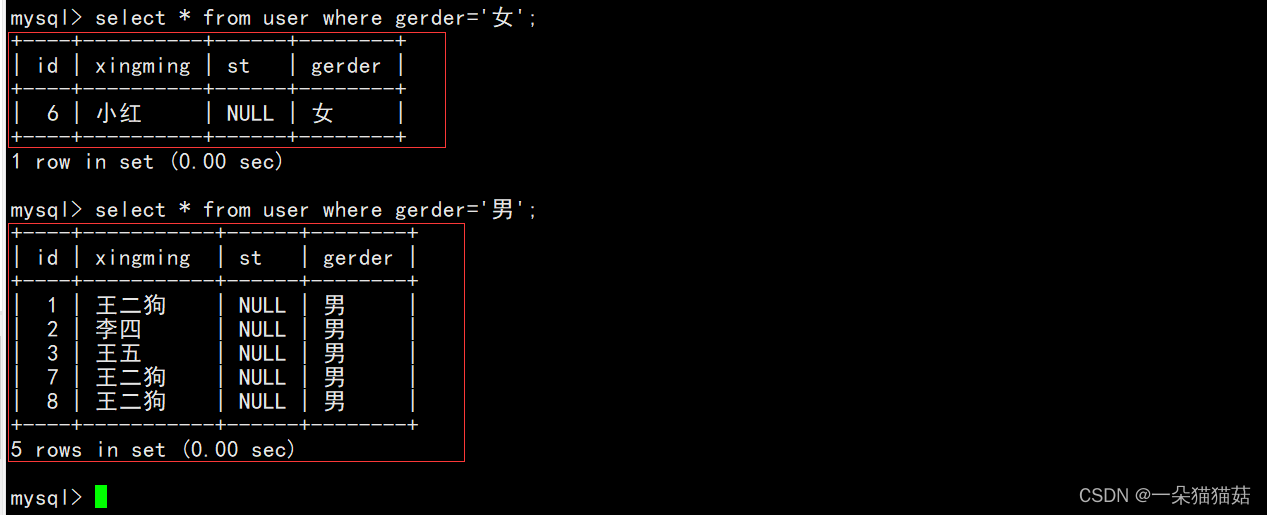
上图演示了当性别为男或为女时显示出来的数据。
下面我们为了演示where语句我们重新构建一张分数表:

这个分数表的结构如上图:
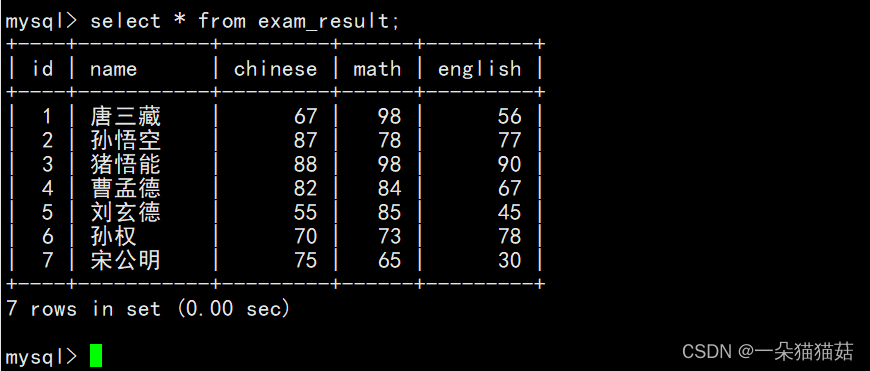
下面我们尝试用更多的要求来练习where语句:

当然我们也可以用用between语句:

当然也可以用或语句:

那如果我们要查询的是姓孙的同学及孙某同学呢?在MySQL中也是有通配符的:
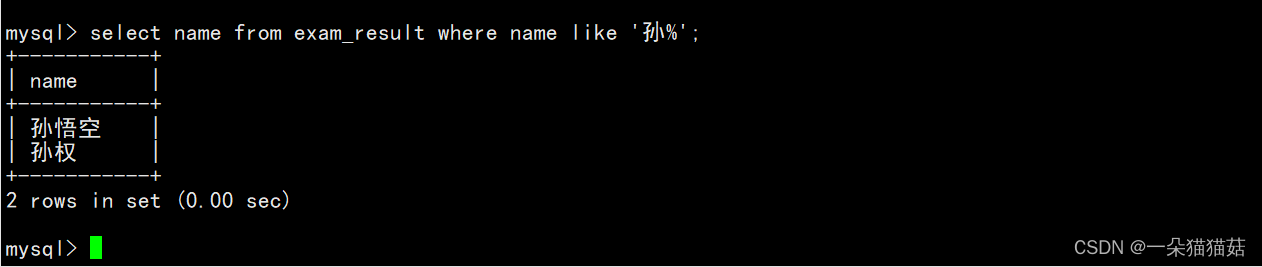
%表示后面通配任意个字符,这就显示了姓孙的同学,如果是孙某呢?也就是说只能是两个字姓孙的同学该如何表示呢?

只需要在后面加一个下划线表示孙后面只有一个字符。
如果要查询语文成绩好于英语成绩的同学呢?
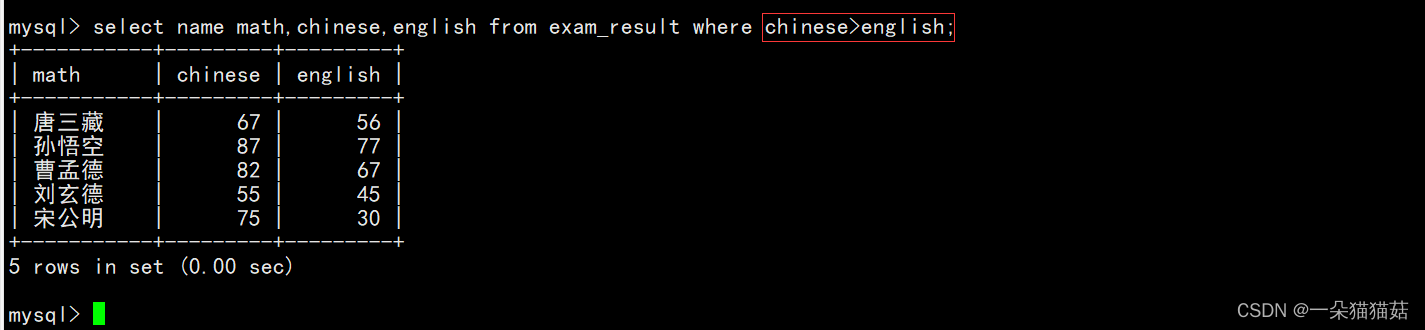
下面我们查询一下总分在200分以下的同学:

语文成绩大于80并且不姓孙的同学:

孙某同学,否则要求总成绩大于200并且语文成绩小于数学成绩并且英语成绩大于80:

order by子句:
order by可以对查询出来的数据做排序,语法如下:
-- ASC 为升序(从小到大)
-- DESC 为降序(从大到小)
-- 默认为 ASC
SELECT ... FROM table_name [WHERE ...]
ORDER BY column [ASC|DESC], [...];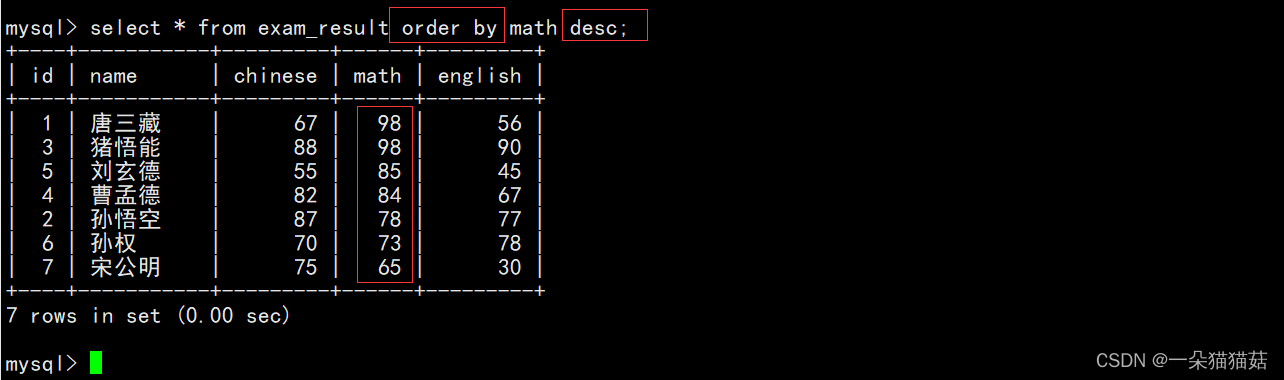
上图是我们将按照math列的大小来做降序排序。
order by默认的排序方式是升序。下面我们用总分降序的方式进行显示:
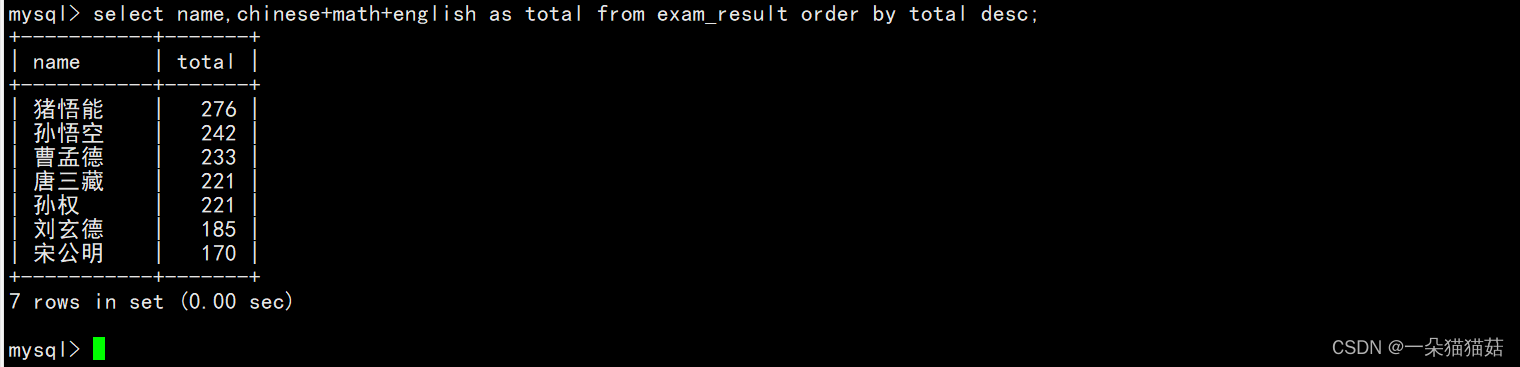
查询姓孙的同学或者姓曹的同学数学成绩,结果按照数学成绩由高到低显示:

-- 起始下标为 0
-- 从 s 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT s, n
-- 从 0 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n;
;
-- 从 s 开始,筛选 n 条结果,比第二种用法更明确,建议使用
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n OFFSET s;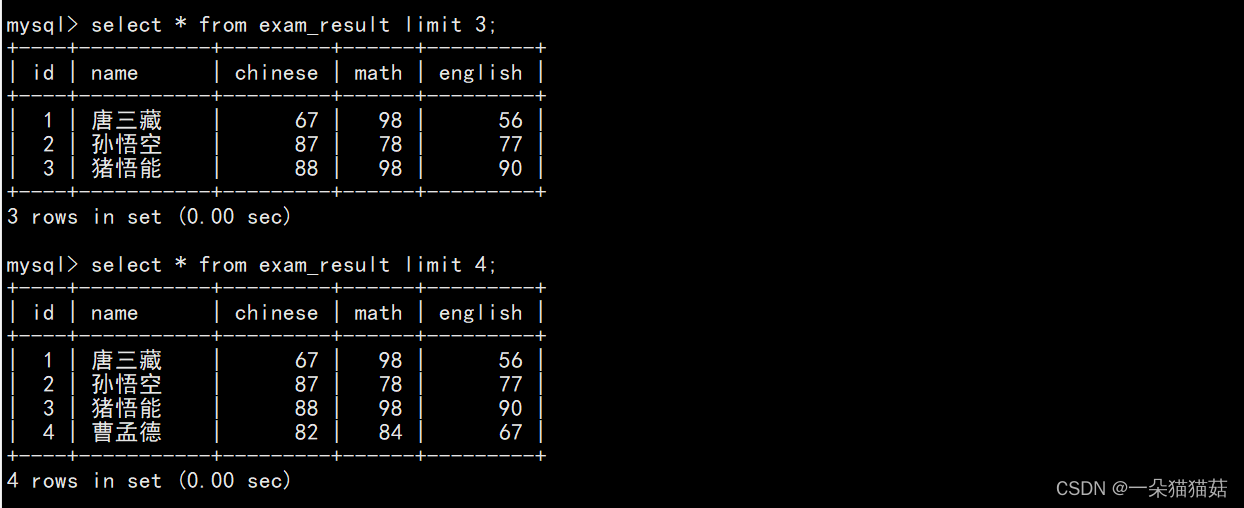
而limit s,n表示从s开始显示n个数据:

注意要想从首行开始s应该为0才对。
UPDATE table_name SET column = expr [, column = expr ...]
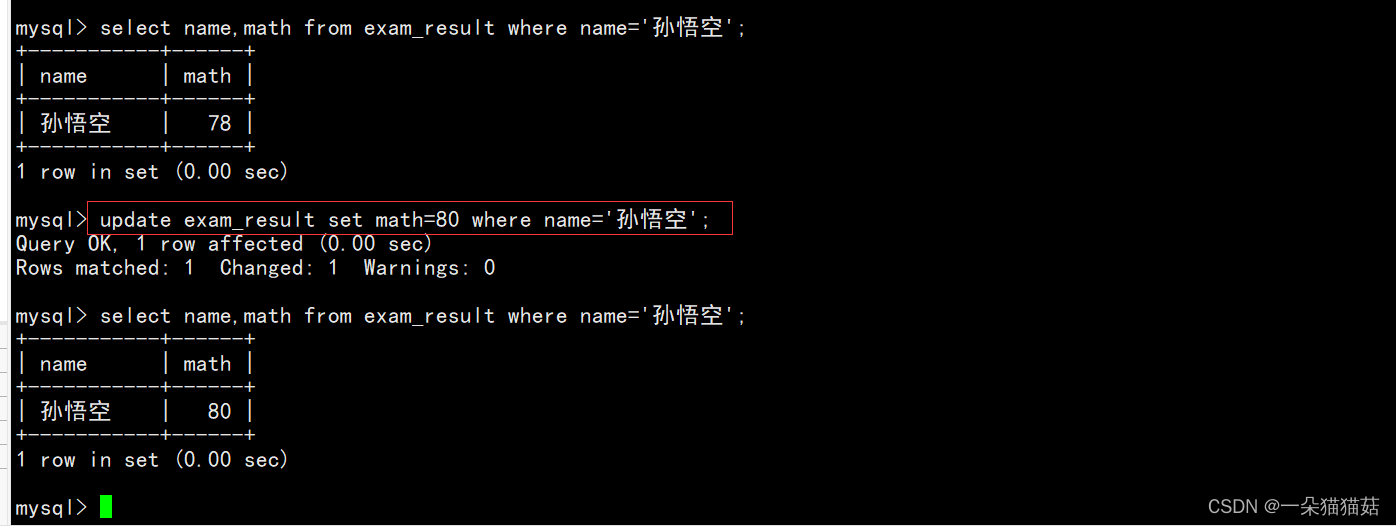
[WHERE ...] [ORDER BY ...] [LIMIT ...]update对查询到的结果进行列值更新。
下面我们演示一下将孙悟空同学的成绩改为80分:
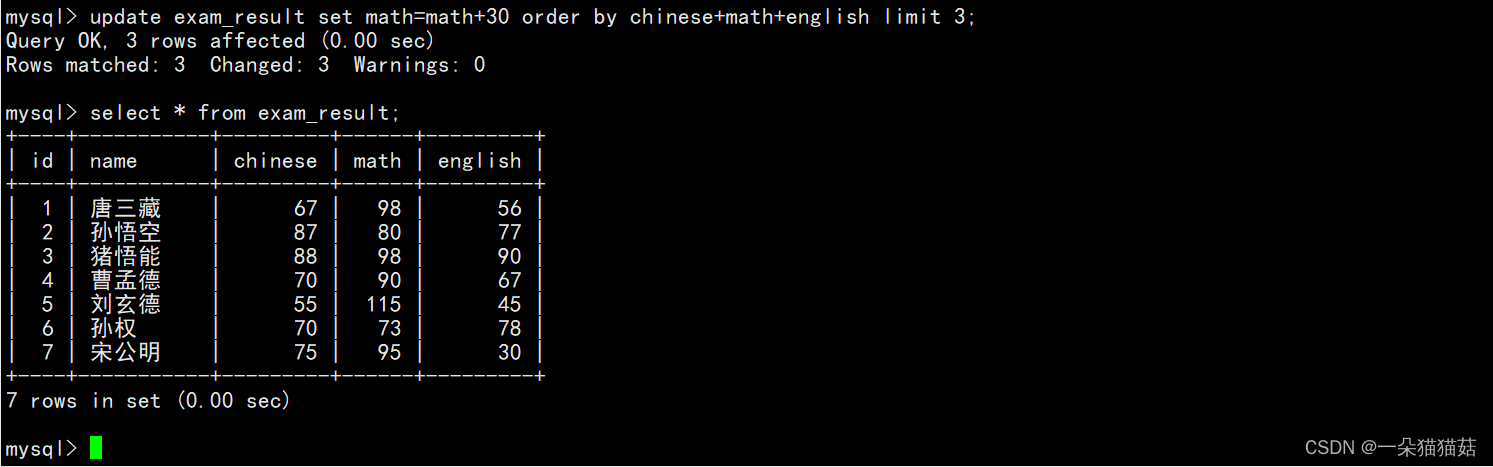
下面演示一下将总分倒数前三的学生的数学成绩加30分:
DELETE FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...]比如我们要删除孙悟空同学的考试成绩:
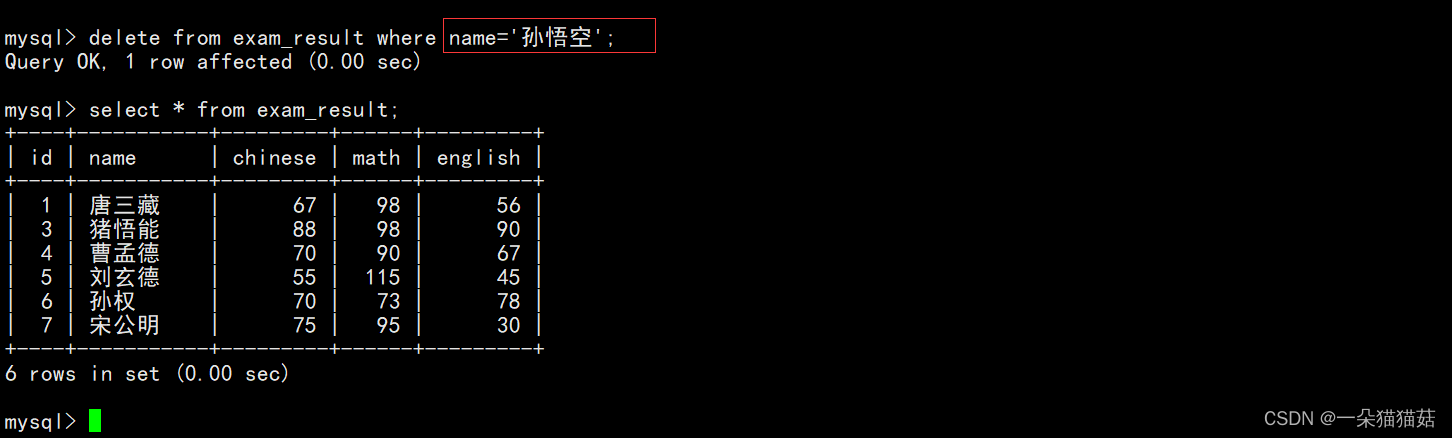
聚合函数

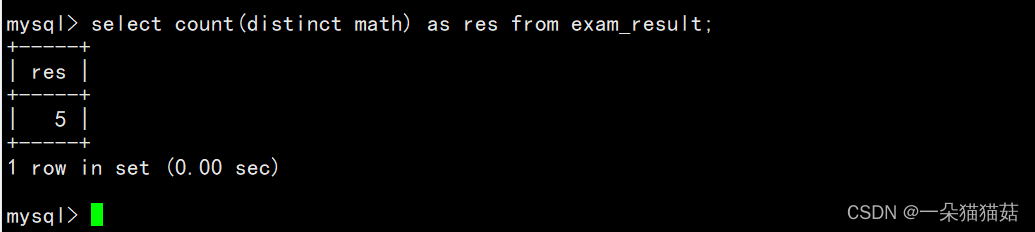
下面我们统计一下数学成绩不相等的个数:
当然也可以求一下数学成绩的总分:

select column1, column2, .. from table group by column;我们现在有一个雇员信息表,表中有EMP员工表,DEPT部门表,SALGRADE工资等级表,那么我们该如何显示每个部门的平均工资和最高工资呢?

从上图中我们可以看到每一位员工都有不同的部门,也就是说每个部门内都有很多员工,下面我们用group by子句对指定列进行分组查询:
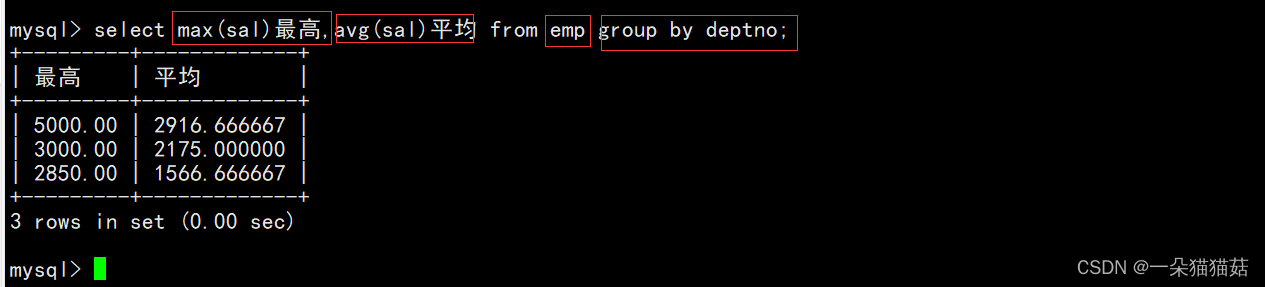
这就是group by子句对指定列进行分组查询的意义。
那么如果我们要查询每个部门的每种岗位的平均工资和最低工资呢?

首先我们要查询的是每个部门内的每种岗位,所以group分组的时候先在部门内分组,然后在部门内将每种岗位进行分组,从而统计出每个部门的每种岗位的平均工资和最低工资。
如何显示平均工资低于2000的部门和它的平均工资?
这里我们需要知道新的语法having,having经常与group by 配合使用,对group by结果进行过滤。

当然我们把条件再苛刻一下,比如要求smith员工不参与统计显示平均工资低于2000的部门和它的平均工资。

八、函数
1.日期函数
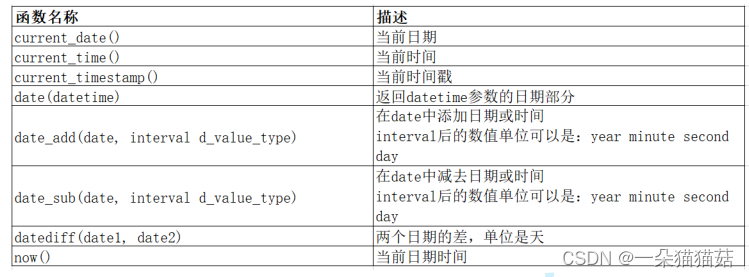

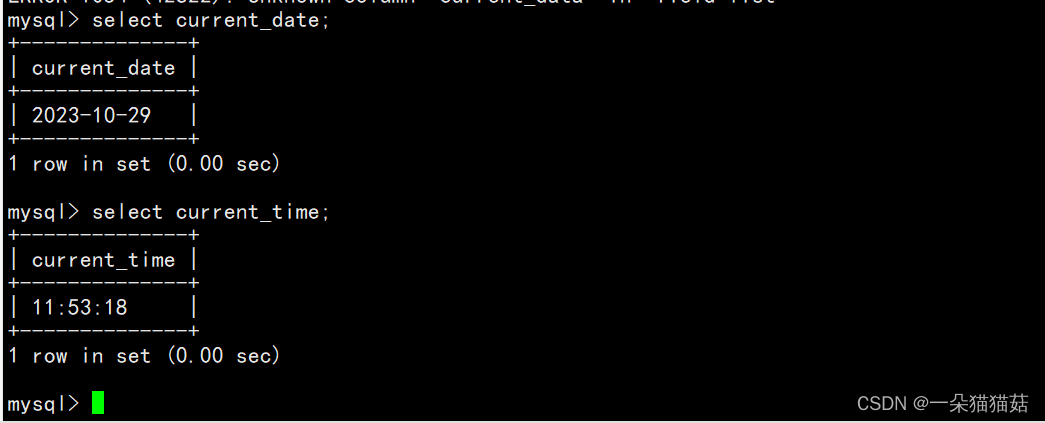
当然也可以在日期的基础上加日期或减日期:
select date_add('2017-10-28', interval 10 day);
+-----------------------------------------+
| date_add('2017-10-28', interval 10 day) |
+-----------------------------------------+
| 2017-11-07 |
+-----------------------------------------+select date_sub('2017-10-1', interval 2 day);
+---------------------------------------+
| date_sub('2017-10-1', interval 2 day) |
+---------------------------------------+
| 2017-09-29 |
+---------------------------------------+select datediff('2017-10-10', '2016-9-1');
+------------------------------------+
| datediff('2017-10-10', '2016-9-1') |
+------------------------------------+
| 404 |
+------------------------------------+下面我们创建一个留言表演示一下:
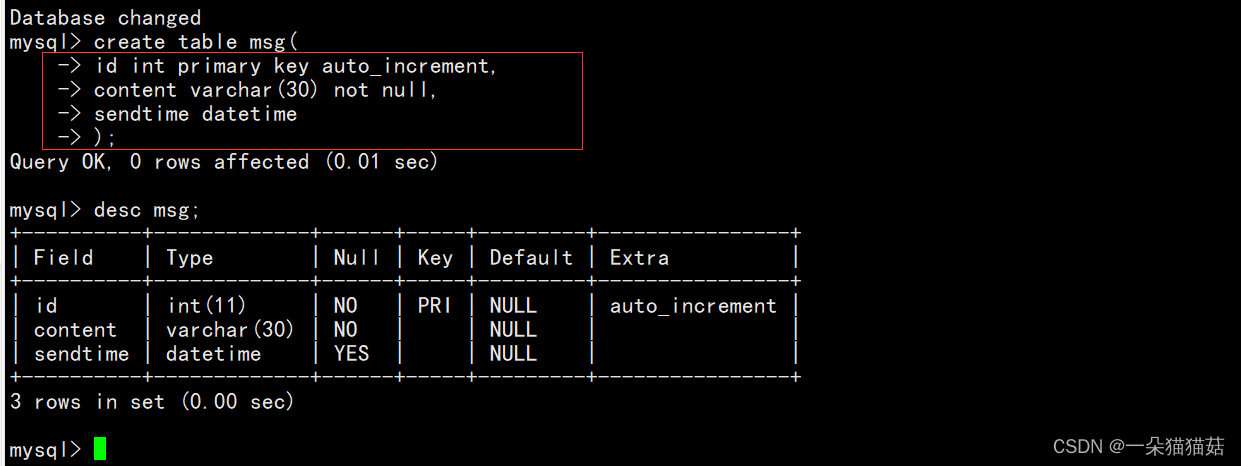
下面我们插入数据试一下:
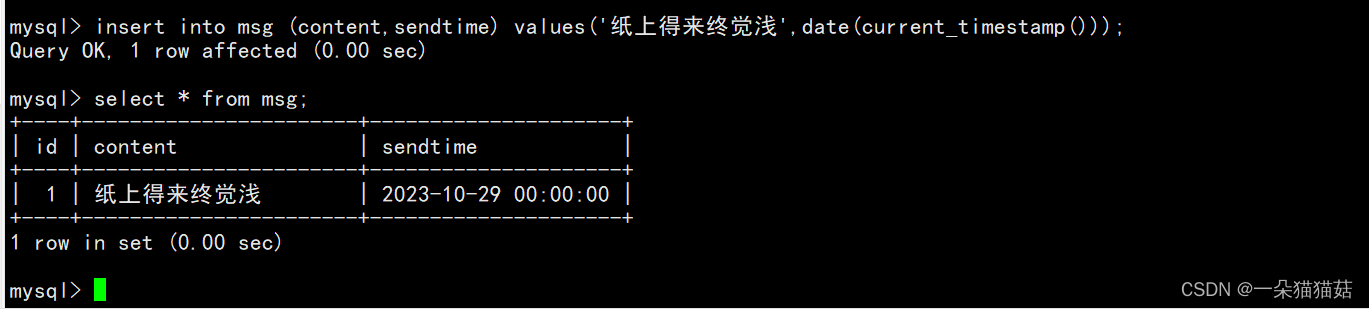
或者:
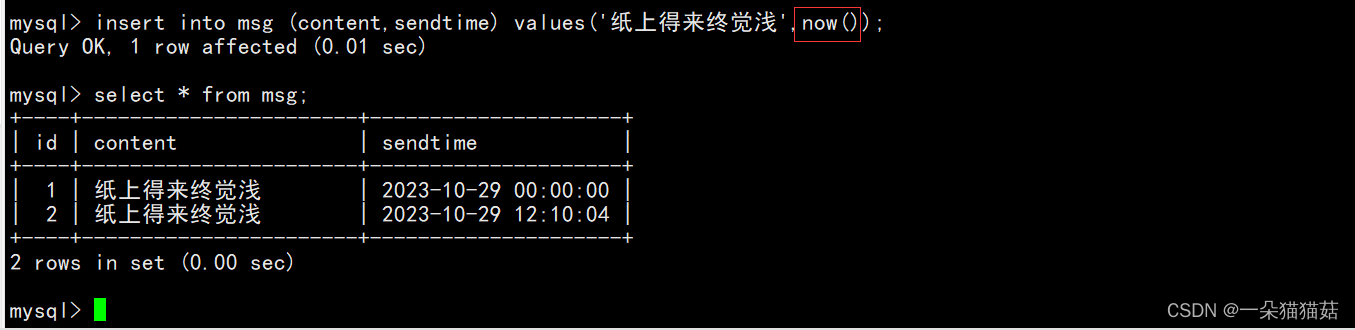
如果只想显示日期的话可以用date函数:

2.字符串函数
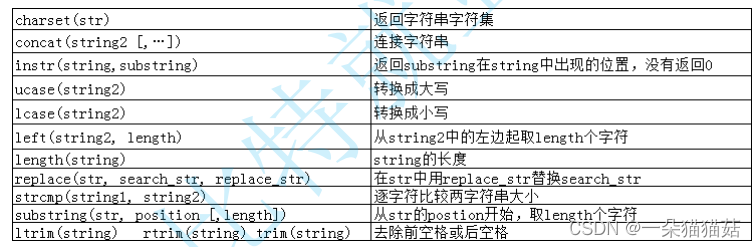
下面我们演示一下:

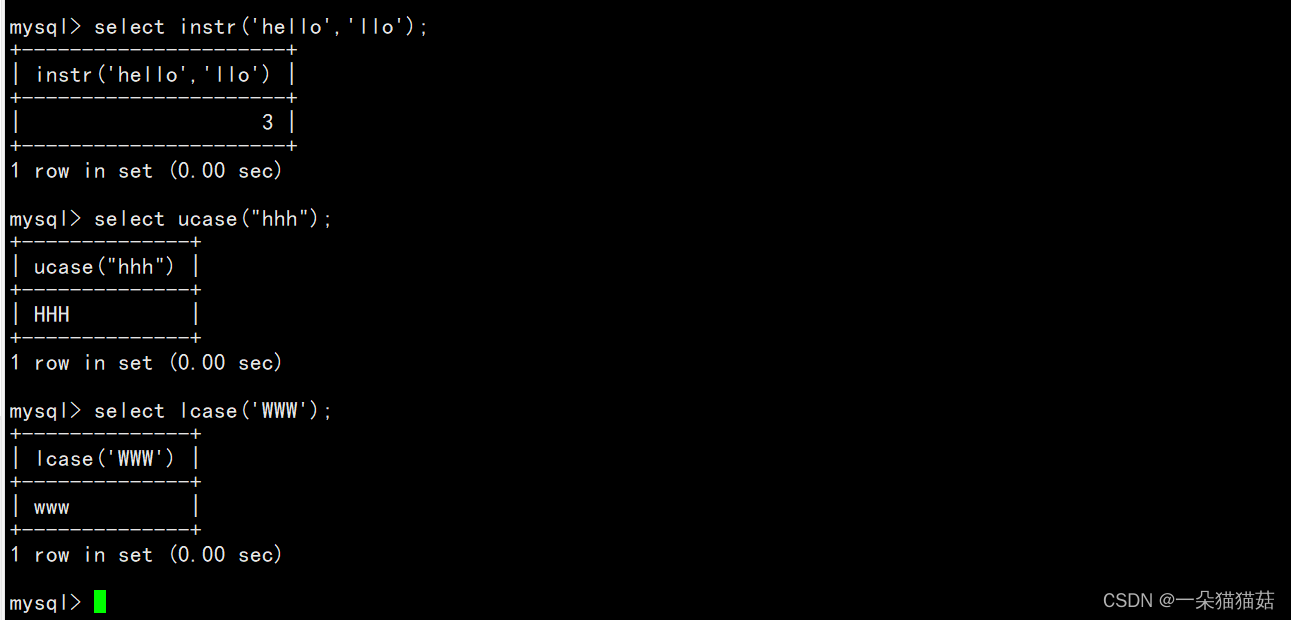
剩下的大家可以自行去验证。
那么这些函数有什么意义呢?下面我们给出一些案例:
比如获取emp表的ename列的字符集:


也可以用替换函数统一替换显示:

3.数学函数
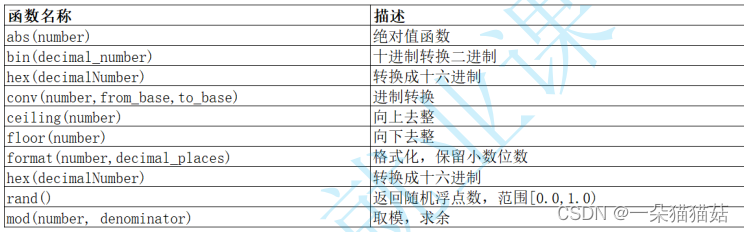


向上取整:就是向比自己大的整数方向进行取整
向下取整:就是向比自己小的整数方向进行取整
4.其他函数

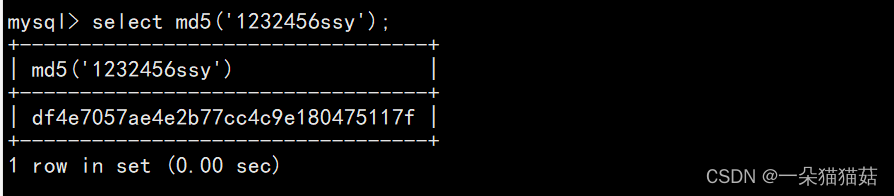
一般我们存放用户密码的时候就会使用此函数

九、复合查询
1.查询工资高于500或岗位为MANAGER的雇员,同时还要满足他们的姓名首字母为大写的J

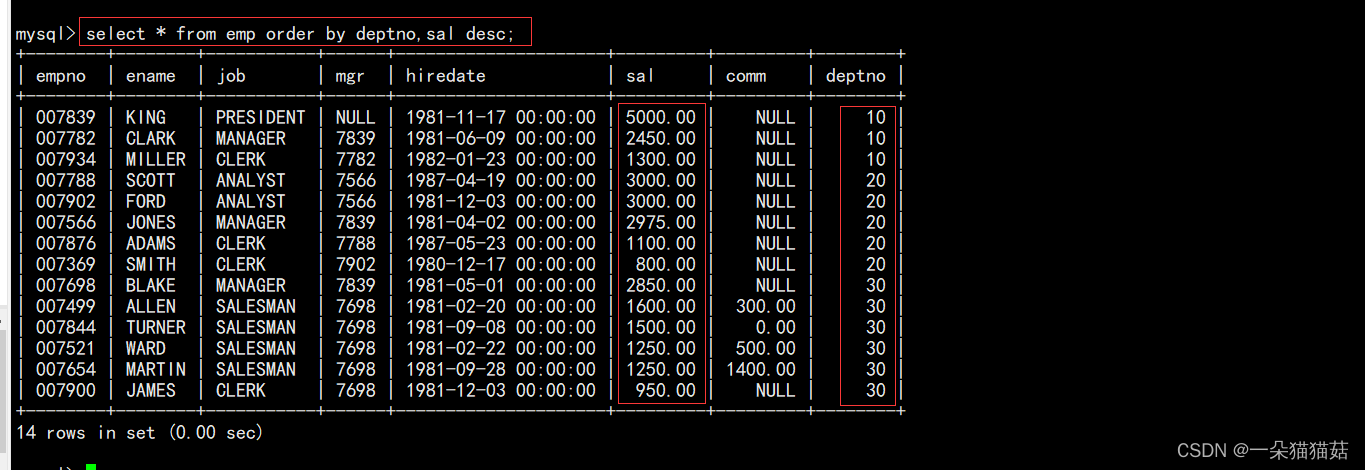
2.按照部门号升序而雇员的工资降序排序
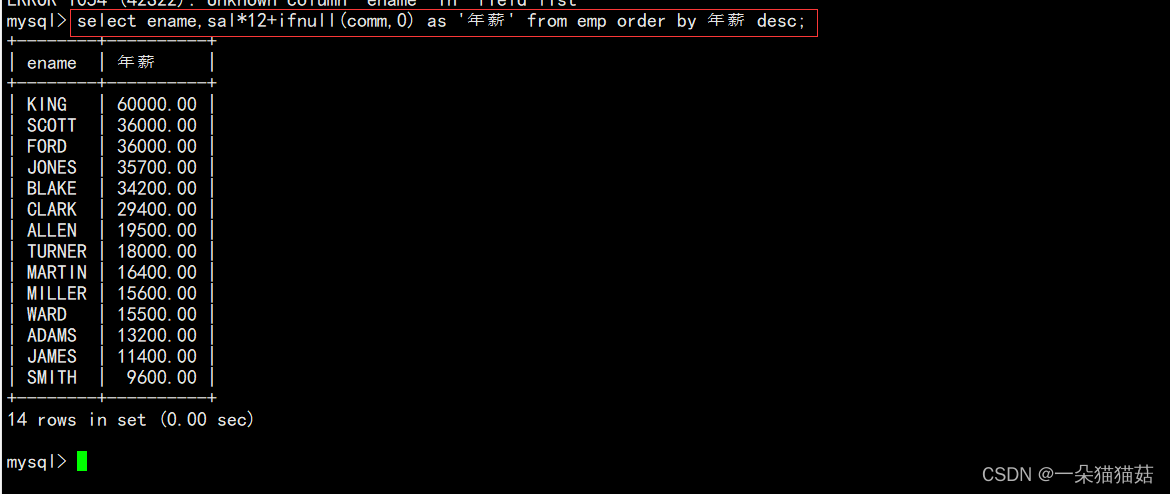
3.使用年薪进行降序排序
4.显示工资最高的员工的名字和工作岗位

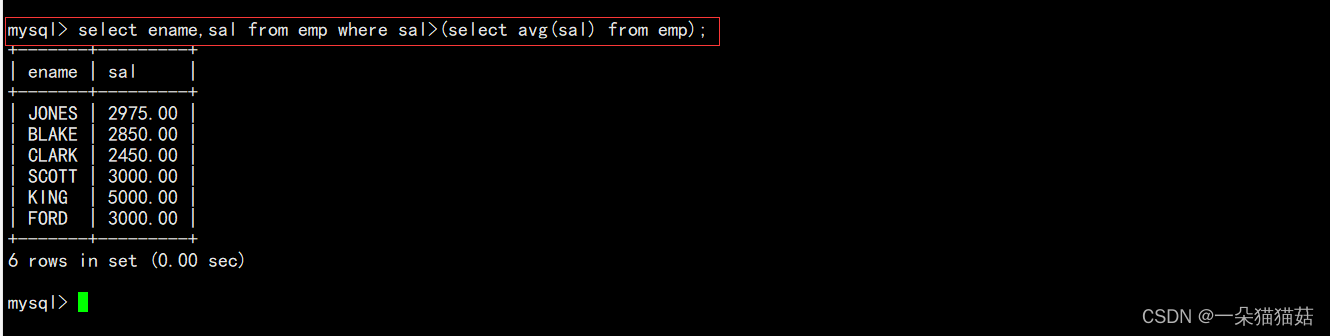
5.显示工资高于平均工资的员工信息
6.显示每个部门的平均工资和最高工资

7.显示平均工资低于2000的部门号和它的平均工资

8.显示每种岗位的雇员总数,平均工资

多表查询
1.显示雇员名、雇员工资以及所在部门的名字因为上面的数据来自EMP和DEPT表,因此要联合查询。

2.显示部门号为10的部门名,员工名和工资

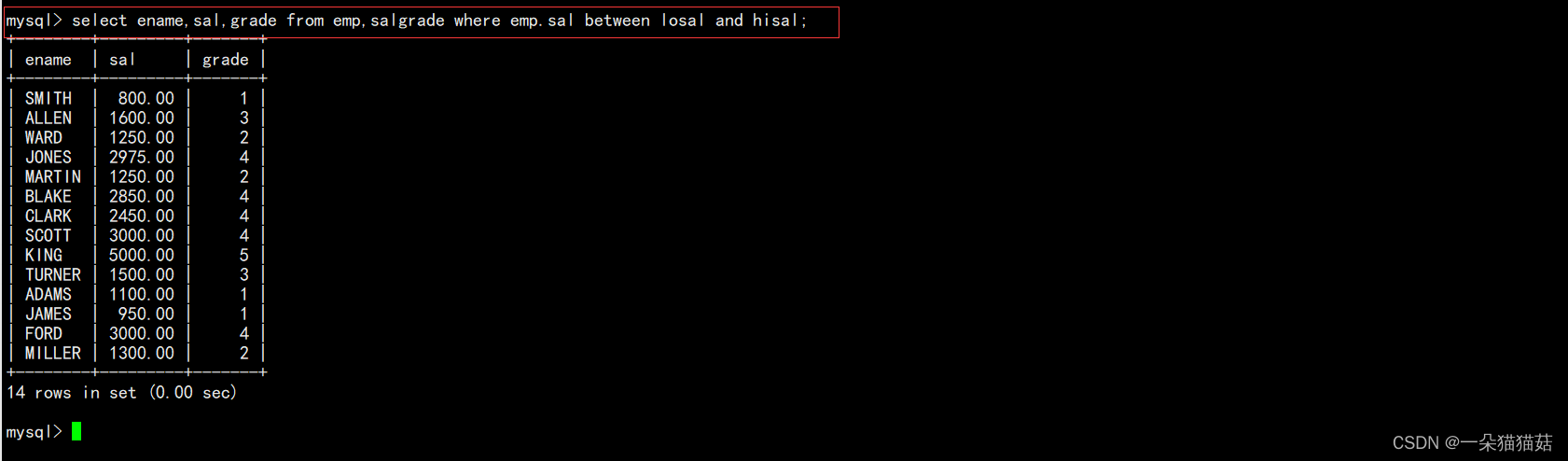
3.显示各个员工的姓名,工资,及工资级别
自连接
自连接是指在同一张表连接查询。
比如:显示员工FORD的上级领导的编号和姓名(mgr是员工领导的编号--empno)

上面我们使用了子查询,子查询就是指嵌入在其他sql语句中的select语句,也叫嵌套查询。
1.单行子查询
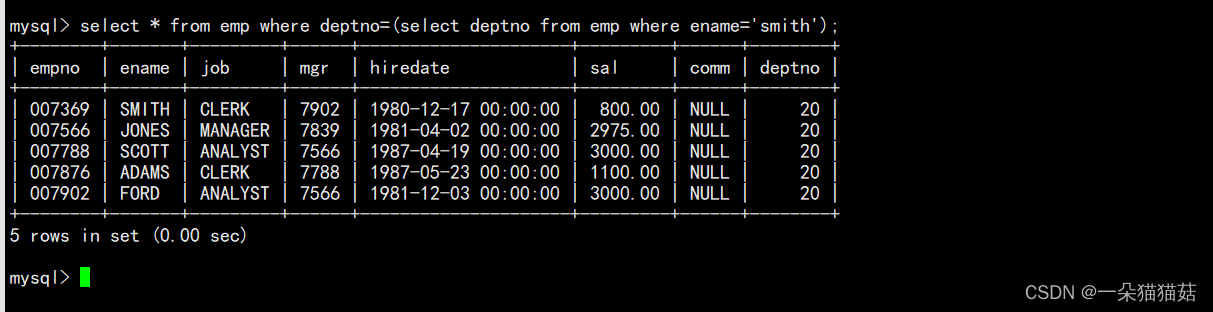
2.多行子查询
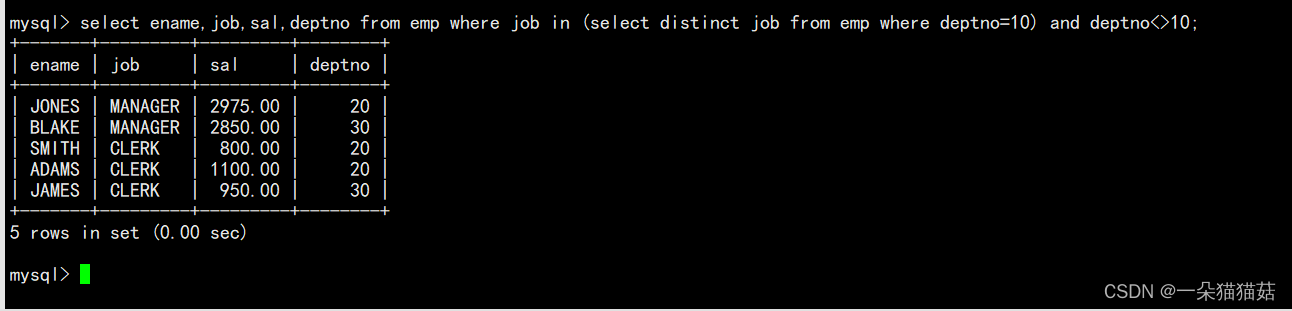
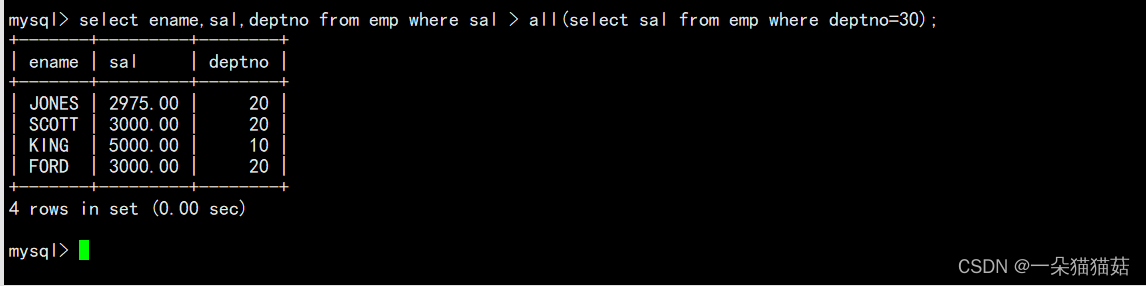
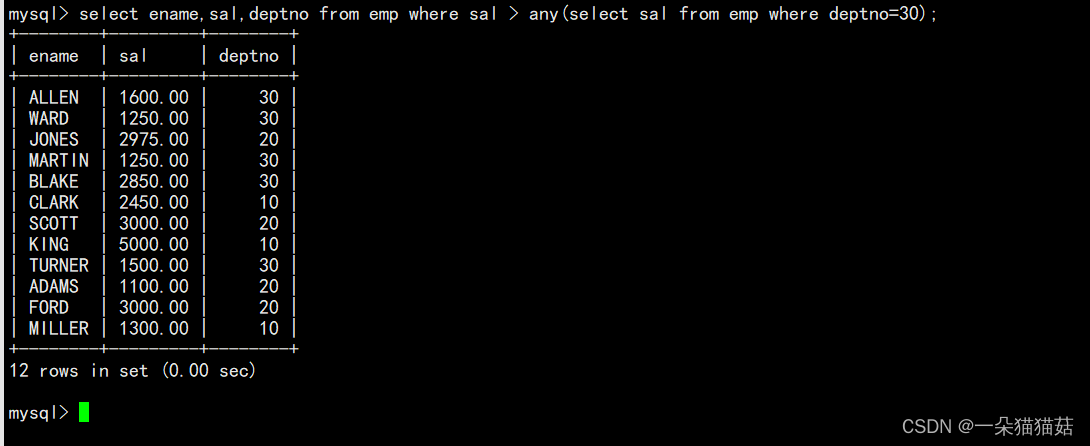
3.多列子查询

在from子句中使用子查询
子查询语句出现在from子句中。这里要用到数据查询的技巧,把一个子查询当做一个临时表使用。 查找每个部门工资最高的人的姓名、工资、部门、最高工资

合并查询
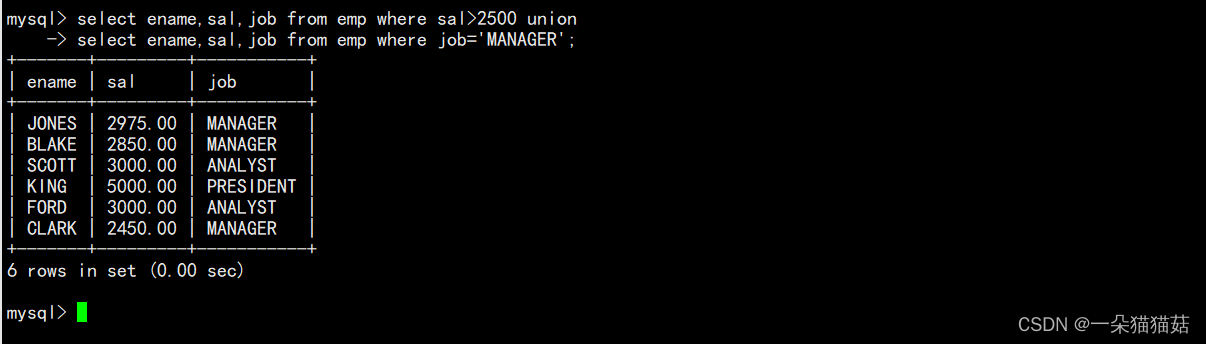
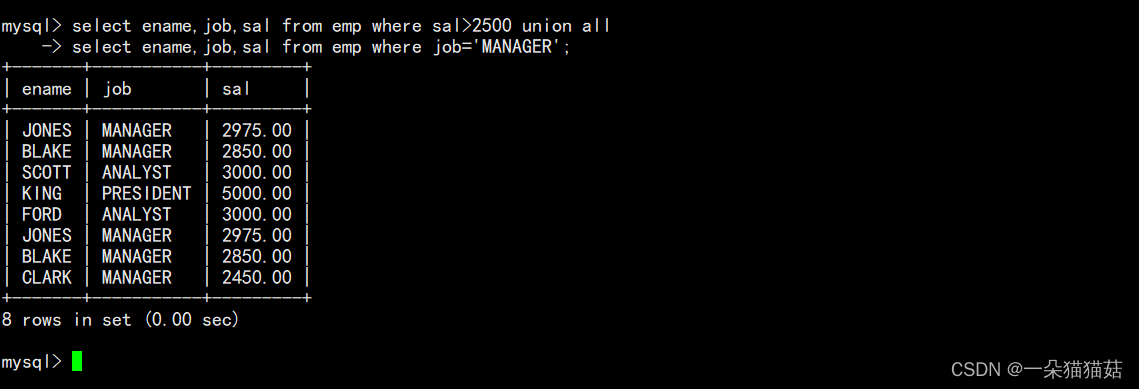
十、表的内连和外连
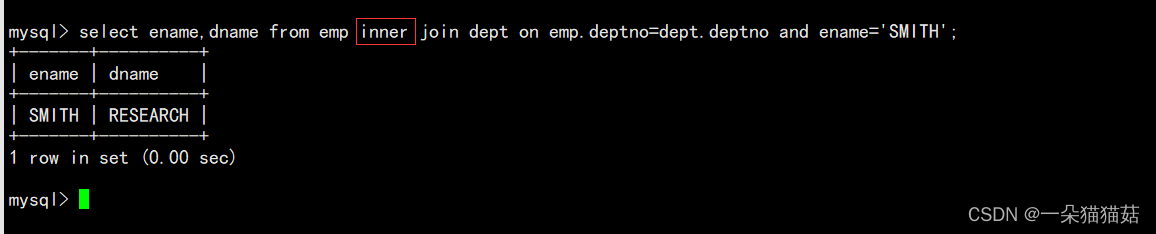
1.内连接
语法
select 字段 from 表1 inner join 表2 on 连接条件 and 其他条件;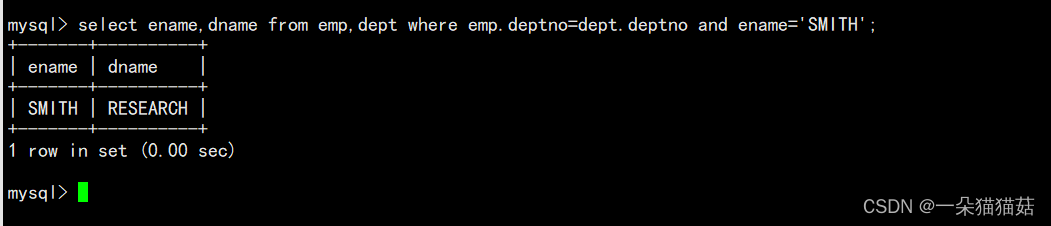
2.外连接
语法
select 字段名 from 表名1 left join 表名2 on 连接条件下面我们创建两张表用来测试,一个是学生表,另一个是成绩表。
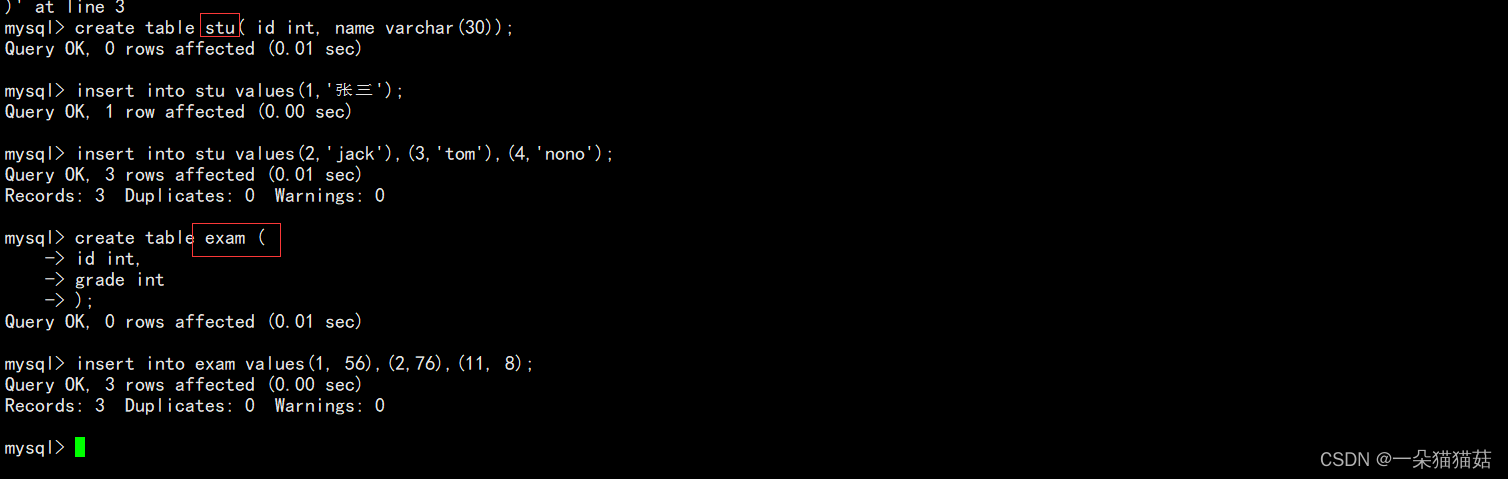

语法
select 字段 from 表名1 right join 表名2 on 连接条件;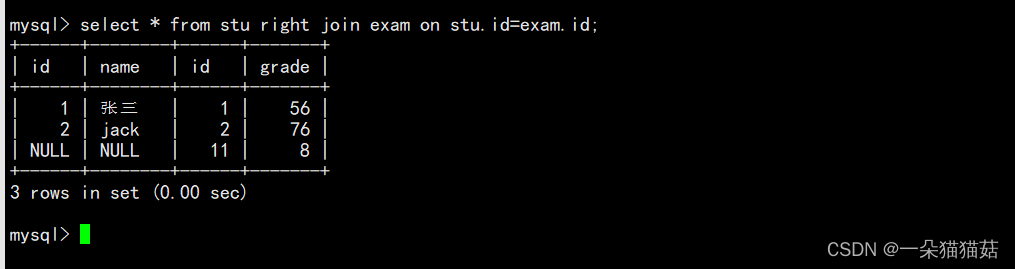
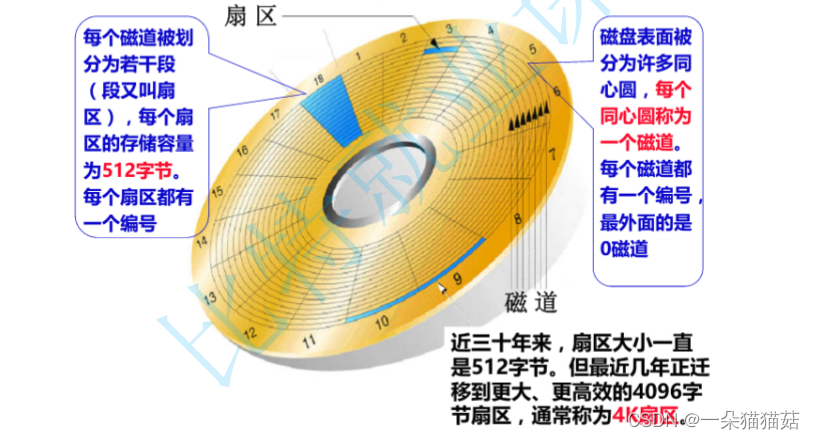
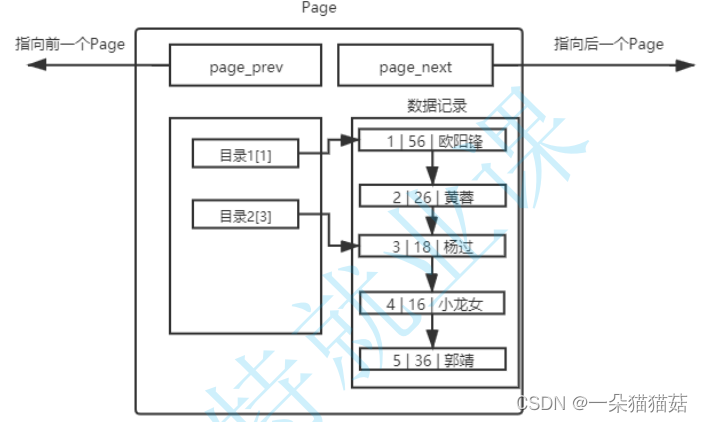
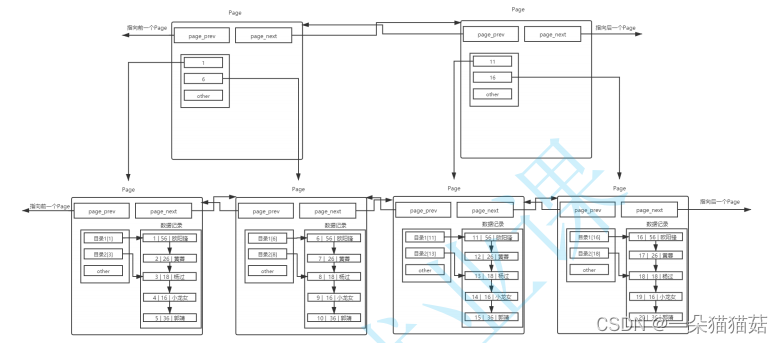
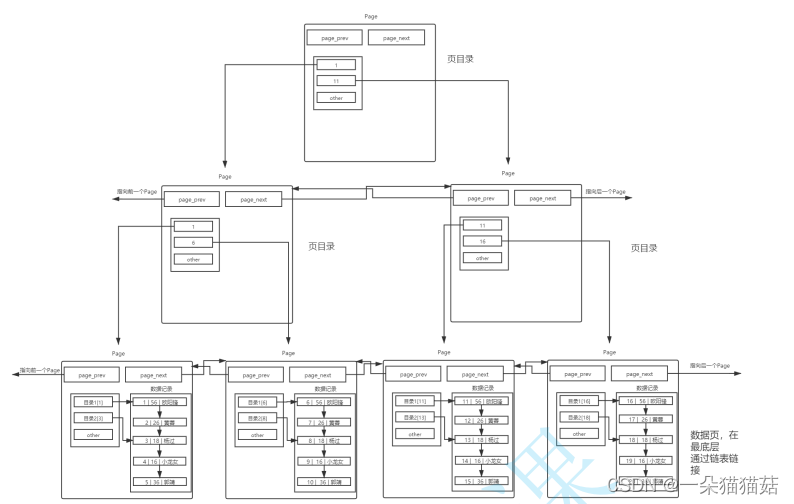
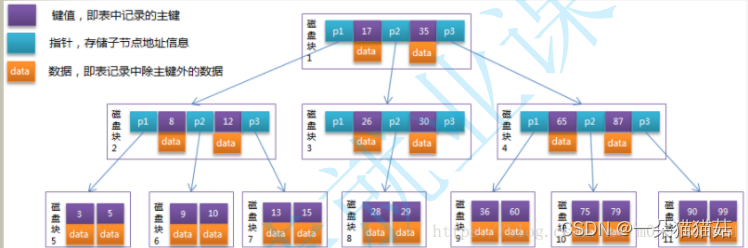
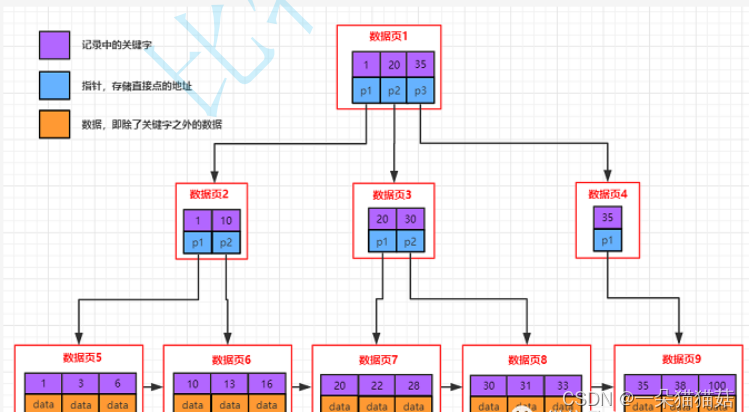
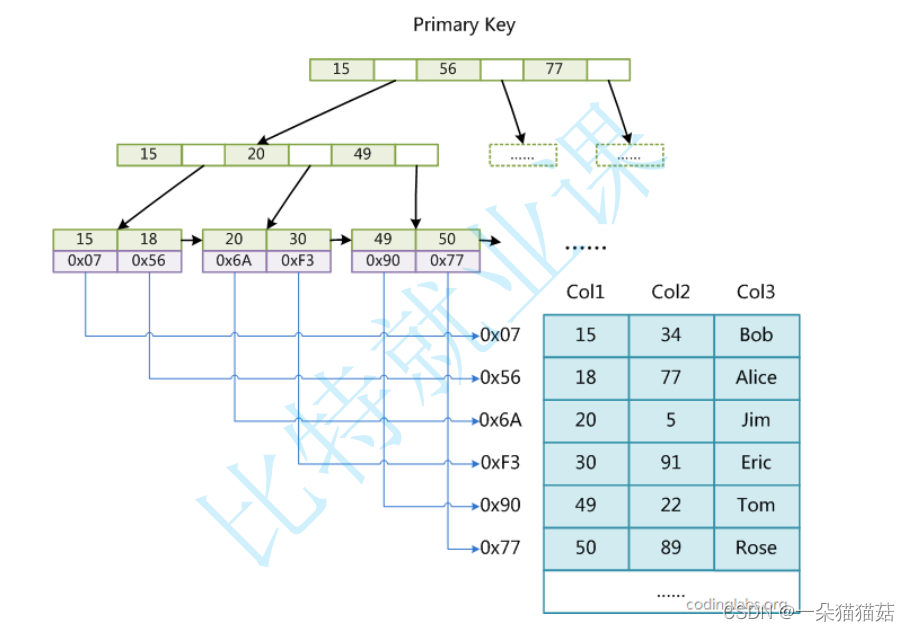
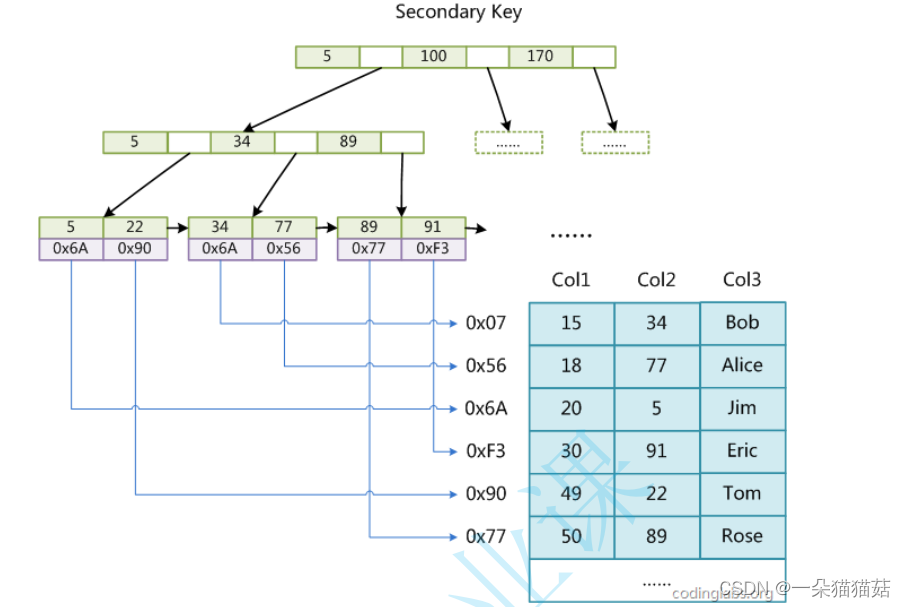
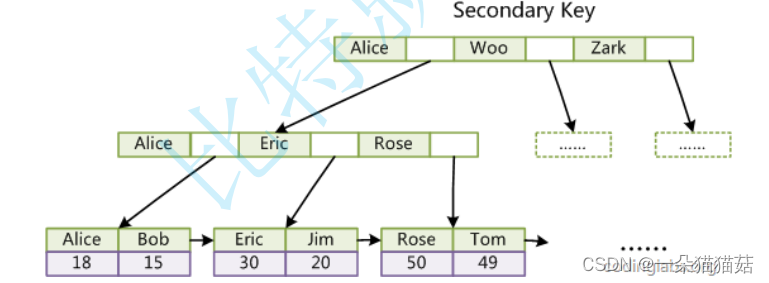
十一、索引


显示页大小
SHOW GLOBAL STATUS LIKE 'innodb_page_size';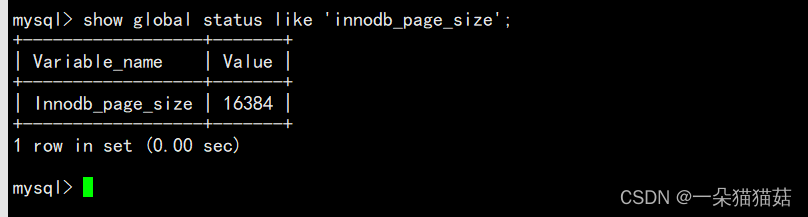




-- 在创建表的时候,直接在字段名后指定 primary key
create table user1(id int primary key, name varchar(30));第二种方式:
-- 在创建表的最后,指定某列或某几列为主键索引
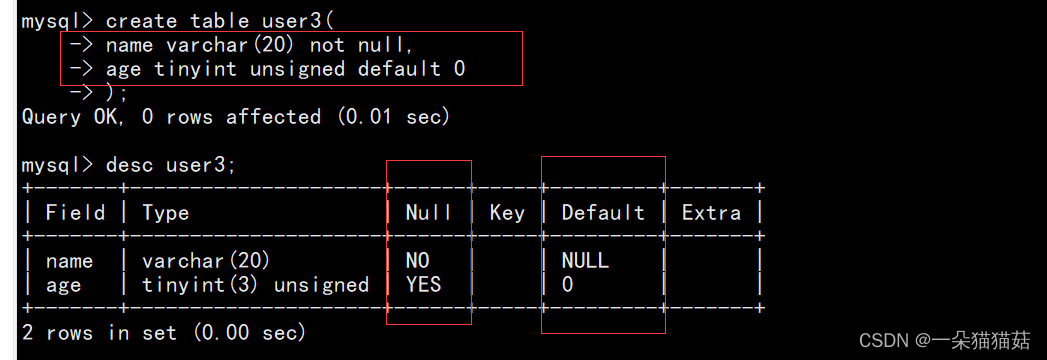
create table user2(id int, name varchar(30), primary key(id));第三种方式:
create table user3(id int, name varchar(30));
-- 创建表以后再添加主键
alter table user3 add primary key(id);-- 在表定义时,在某列后直接指定unique唯一属性。
create table user4(id int primary key, name varchar(30) unique);第二种方式:
-- 创建表时,在表的后面指定某列或某几列为unique
create table user5(id int primary key, name varchar(30), unique(name));create table user6(id int primary key, name varchar(30));
alter table user6 add unique(name);create table user8(id int primary key,
name varchar(20),
email varchar(30),
index(name) --在表的定义最后,指定某列为索引
);create table user9(id int primary key, name varchar(20), email
varchar(30));
alter table user9 add index(name); --创建完表以后指定某列为普通索引create table user10(id int primary key, name varchar(20), email
varchar(30));
-- 创建一个索引名为 idx_name 的索引
create index idx_name on user10(name);CREATE TABLE articles (
id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,
title VARCHAR(200),
body TEXT,
FULLTEXT (title,body)
)engine=MyISAM;INSERT INTO articles (title,body) VALUES
('MySQL Tutorial','DBMS stands for DataBase ...'),
('How To Use MySQL Well','After you went through a ...'),
('Optimizing MySQL','In this tutorial we will show ...'),
('1001 MySQL Tricks','1. Never run mysqld as root. 2. ...'),
('MySQL vs. YourSQL','In the following database comparison ...'),
('MySQL Security','When configured properly, MySQL ...');mysql> select * from articles where body like '%database%';
+----+-------------------+------------------------------------------+
| id | title | body |
+----+-------------------+------------------------------------------+
| 1 | MySQL Tutorial | DBMS stands for DataBase ... |
| 5 | MySQL vs. YourSQL | In the following database comparison ... |
+----+-------------------+------------------------------------------+mysql> explain select * from articles where body like '%database%'\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: articles
type: ALL
possible_keys: NULL
key: NULL <== key为null表示没有用到索引
key_len: NULL
ref: NULL
rows: 6
Extra: Using where
1 row in set (0.00 sec)mysql> SELECT * FROM articles
-> WHERE MATCH (title,body) AGAINST ('database');
+----+-------------------+------------------------------------------+
| id | title | body |
+----+-------------------+------------------------------------------+
| 5 | MySQL vs. YourSQL | In the following database comparison ... |
| 1 | MySQL Tutorial | DBMS stands for DataBase ... |
+----+-------------------+------------------------------------------+mysql> explain SELECT * FROM articles WHERE MATCH (title,body) AGAINST
('database')\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: articles
type: fulltext
possible_keys: title
key: title <= key用到了title
key_len: 0
ref:
rows: 1
Extra: Using wheremysql> show keys from goods\G
*********** 1. row ***********
Table: goods <= 表名
Non_unique: 0 <= 0表示唯一索引
Key_name: PRIMARY <= 主键索引
Seq_in_index: 1
Column_name: goods_id <= 索引在哪列
Collation: A
Cardinality: 0
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE <= 以二叉树形式的索引
Comment:
1 row in set (0.00 sec)十二、事务
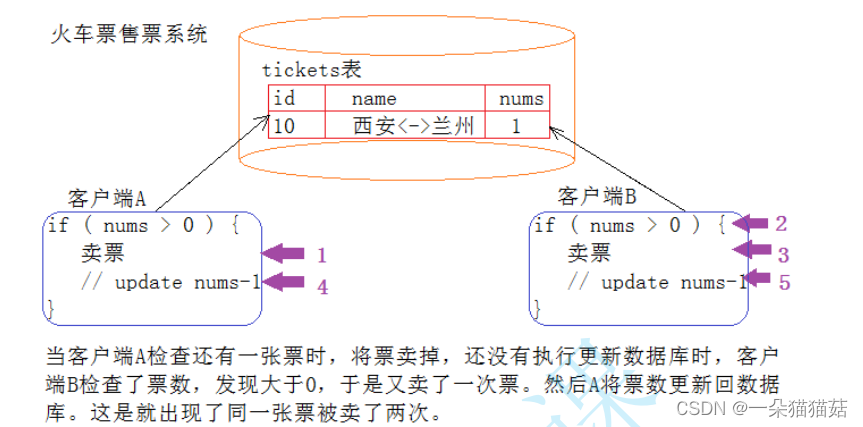

mysql> SET AUTOCOMMIT=0; #SET AUTOCOMMIT=0 禁止自动提交
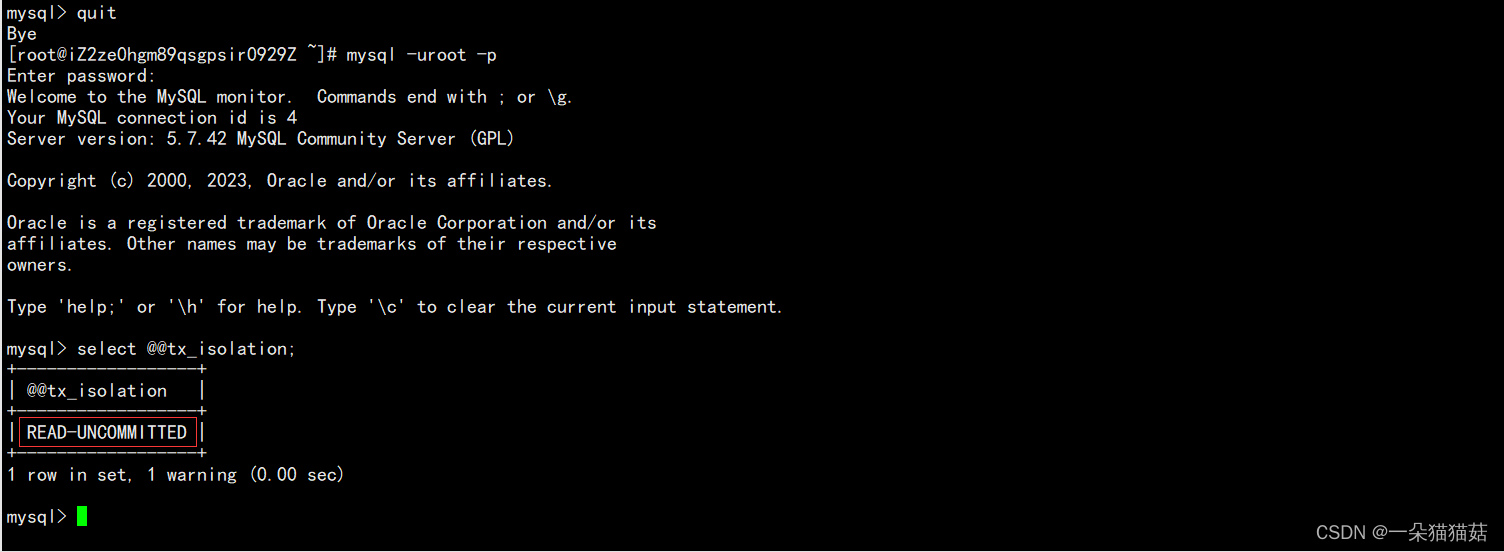
mysql> SET AUTOCOMMIT=1; #SET AUTOCOMMIT=1 开启自动提交下面为了方便演示我们将mysql的默认隔离级别设置为读未提交:









-- 终端A
mysql> select * from account; -- 当前表内无数据
Empty set (0.00 sec)
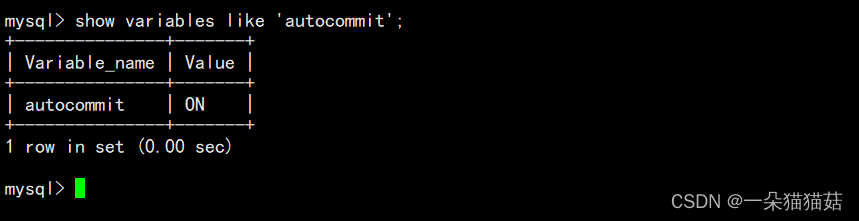
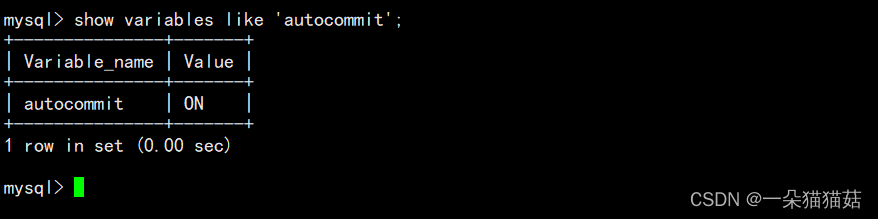
mysql> show variables like 'autocommit'; -- 依旧自动提交
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| autocommit | ON |
+---------------+-------+
1 row in set (0.00 sec)
mysql> begin; --开启事务
Query OK, 0 rows affected (0.00 sec)
mysql> insert into account values (1, '张三', 100); -- 插入记录
Query OK, 1 row affected (0.00 sec)
mysql> select * from account; --数据已经存在,但没有commit,此时同时查看
终端B
+----+--------+--------+
| id | name | blance |
+----+--------+--------+
| 1 | 张三 | 100.00 |
+----+--------+--------+
1 row in set (0.00 sec)
mysql> Aborted -- ctrl + \ 异常终止MySQL
--终端B
mysql> select * from account; --终端A崩溃前
+----+--------+--------+
| id | name | blance |
+----+--------+--------+
| 1 | 张三 | 100.00 |
+----+--------+--------+
1 row in set (0.00 sec)
mysql> select * from account; --数据自动回滚
Empty set (0.00 sec)--终端 A
mysql> show variables like 'autocommit'; -- 依旧自动提交
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| autocommit | ON |
+---------------+-------+
1 row in set (0.00 sec)
mysql> select * from account; -- 当前表内无数据
Empty set (0.00 sec)
mysql> begin; -- 开启事务
Query OK, 0 rows affected (0.00 sec)
mysql> insert into account values (1, '张三', 100); -- 插入记录
Query OK, 1 row affected (0.00 sec)
mysql> commit; --提交事务
Query OK, 0 rows affected (0.04 sec)
mysql> Aborted -- ctrl + \ 异常终止MySQL
--终端 B
mysql> select * from account; --数据存在了,所以commit的作用是将数据持久
化到MySQL中
+----+--------+--------+
| id | name | blance |
+----+--------+--------+
| 1 | 张三 | 100.00 |
+----+--------+--------+
1 row in set (0.00 sec)-- 终端 A
mysql> select *from account; --查看历史数据
+----+--------+--------+
| id | name | blance |
+----+--------+--------+
| 1 | 张三 | 100.00 |
+----+--------+--------+
1 row in set (0.00 sec)
mysql> show variables like 'autocommit'; --查看事务提交方式
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| autocommit | ON |
+---------------+-------+
1 row in set (0.00 sec)
mysql> set autocommit=0; --关闭自动提交
Query OK, 0 rows affected (0.00 sec)
mysql> show variables like 'autocommit'; --查看关闭之后结果
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| autocommit | OFF |
+---------------+-------+
1 row in set (0.00 sec)
mysql> begin; --开启事务
Query OK, 0 rows affected (0.00 sec)
mysql> insert into account values (2, '李四', 10000); --插入记录
Query OK, 1 row affected (0.00 sec)
mysql> select *from account; --查看插入记录,同时查看终端B
+----+--------+----------+
| id | name | blance |
+----+--------+----------+
| 1 | 张三 | 100.00 |
| 2 | 李四 | 10000.00 |
+----+--------+----------+
2 rows in set (0.00 sec)
mysql> Aborted --再次异常终止
-- 终端B
mysql> select * from account; --终端A崩溃前
+----+--------+----------+
| id | name | blance |
+----+--------+----------+
| 1 | 张三 | 100.00 |
| 2 | 李四 | 10000.00 |
+----+--------+----------+
2 rows in set (0.00 sec)
mysql> select * from account; --终端A崩溃后,自动回滚
+----+--------+--------+
| id | name | blance |
+----+--------+--------+
| 1 | 张三 | 100.00 |
+----+--------+--------+
1 row in set (0.00 sec)--实验一
-- 终端A
mysql> select * from account;
+----+--------+--------+
| id | name | blance |
+----+--------+--------+
| 1 | 张三 | 100.00 |
+----+--------+--------+
1 row in set (0.00 sec)
mysql> show variables like 'autocommit';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| autocommit | ON |
+---------------+-------+
1 row in set (0.00 sec)
mysql> set autocommit=0; --关闭自动提交
Query OK, 0 rows affected (0.00 sec)
mysql> insert into account values (2, '李四', 10000); --插入记录
Query OK, 1 row affected (0.00 sec)
mysql> select *from account; --查看结果,已经插入。此时可以在查
看终端B
+----+--------+----------+
| id | name | blance |
+----+--------+----------+
| 1 | 张三 | 100.00 |
| 2 | 李四 | 10000.00 |
+----+--------+----------+
2 rows in set (0.00 sec)
mysql> ^DBye --ctrl + \ or ctrl + d,终止终
端
--终端B
mysql> select * from account; --终端A崩溃前
+----+--------+----------+
| id | name | blance |
+----+--------+----------+
| 1 | 张三 | 100.00 |
| 2 | 李四 | 10000.00 |
+----+--------+----------+
2 rows in set (0.00 sec)
mysql> select * from account; --终端A崩溃后
+----+--------+--------+
| id | name | blance |
+----+--------+--------+
| 1 | 张三 | 100.00 |
+----+--------+--------+
1 row in set (0.00 sec)
-- 实验二
--终端A
mysql> show variables like 'autocommit'; --开启默认提交
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| autocommit | ON |
+---------------+-------+
1 row in set (0.00 sec)
mysql> select * from account;
+----+--------+--------+
| id | name | blance |
+----+--------+--------+
| 1 | 张三 | 100.00 |
+----+--------+--------+
1 row in set (0.00 sec)
mysql> insert into account values (2, '李四', 10000);
Query OK, 1 row affected (0.01 sec)
mysql> select *from account; --数据已经插入
+----+--------+----------+
| id | name | blance |
+----+--------+----------+
| 1 | 张三 | 100.00 |
| 2 | 李四 | 10000.00 |
+----+--------+----------+
2 rows in set (0.00 sec)
mysql> Aborted --异常终止
--终端B
mysql> select * from account; --终端A崩溃前
+----+--------+----------+
| id | name | blance |
+----+--------+----------+
| 1 | 张三 | 100.00 |
| 2 | 李四 | 10000.00 |
+----+--------+----------+
2 rows in set (0.00 sec)
mysql> select * from account; --终端A崩溃后,并不影响,已经持久化。autocommit
起作用
+----+--------+----------+
| id | name | blance |
+----+--------+----------+
| 1 | 张三 | 100.00 |
| 2 | 李四 | 10000.00 |
+----+--------+----------+
2 rows in set (0.00 sec)-- 查看
mysql> SELECT @@global.tx_isolation; --查看全局隔级别
+-----------------------+
| @@global.tx_isolation |
+-----------------------+
| REPEATABLE-READ |
+-----------------------+
1 row in set, 1 warning (0.00 sec)
mysql> SELECT @@session.tx_isolation; --查看会话(当前)全局隔级别
+------------------------+
| @@session.tx_isolation |
+------------------------+
| REPEATABLE-READ |
+------------------------+
1 row in set, 1 warning (0.00 sec)
mysql> SELECT @@tx_isolation; --默认同上 查看会话(当前)全局隔级别
+-----------------+
| @@tx_isolation |
+-----------------+
| REPEATABLE-READ |
+-----------------+
1 row in set, 1 warning (0.00 sec)--设置
-- 设置当前会话 or 全局隔离级别语法
SET [SESSION | GLOBAL] TRANSACTION ISOLATION LEVEL {READ UNCOMMITTED | READ
COMMITTED | REPEATABLE READ | SERIALIZABLE}
--设置当前会话隔离性,另起一个会话,看不多,只影响当前会话
mysql> set session transaction isolation level serializable; -- 串行化
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT @@global.tx_isolation; --全局隔离性还是RR
+-----------------------+
| @@global.tx_isolation |
+-----------------------+
| REPEATABLE-READ |
+-----------------------+
1 row in set, 1 warning (0.00 sec)
mysql> SELECT @@session.tx_isolation; --会话隔离性成为串行化
+------------------------+
| @@session.tx_isolation |
+------------------------+
| SERIALIZABLE |
+------------------------+
1 row in set, 1 warning (0.00 sec)
mysql> SELECT @@tx_isolation; --同上
+----------------+
| @@tx_isolation |
+----------------+
| SERIALIZABLE |
+----------------+
1 row in set, 1 warning (0.00 sec)
--设置全局隔离性,另起一个会话,会被影响
mysql> set global transaction isolation level READ UNCOMMITTED;
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT @@global.tx_isolation;
+-----------------------+
| @@global.tx_isolation |
+-----------------------+
| READ-UNCOMMITTED |
+-----------------------+
1 row in set, 1 warning (0.00 sec)
mysql> SELECT @@session.tx_isolation;
+------------------------+
| @@session.tx_isolation |
+------------------------+
| READ-UNCOMMITTED |
+------------------------+
1 row in set, 1 warning (0.00 sec)
mysql> SELECT @@tx_isolation;
+------------------+
| @@tx_isolation |
+------------------+
| READ-UNCOMMITTED |
+------------------+
1 row in set, 1 warning (0.00 sec)
-- 注意,如果没有现象,关闭mysql客户端,重新连接。--几乎没有加锁,虽然效率高,但是问题太多,严重不建议采用
--终端A
-- 设置隔离级别为 读未提交
mysql> set global transaction isolation level read uncommitted;
Query OK, 0 rows affected (0.00 sec)
--重启客户端
mysql> select @@tx_isolation;
+------------------+
| @@tx_isolation |
+------------------+
| READ-UNCOMMITTED |
+------------------+
1 row in set, 1 warning (0.00 sec)
mysql> select * from account;
+----+--------+----------+
| id | name | blance |
+----+--------+----------+
| 1 | 张三 | 100.00 |
| 2 | 李四 | 10000.00 |
+----+--------+----------+
2 rows in set (0.00 sec)
mysql> begin; --开启事务
Query OK, 0 rows affected (0.00 sec)
mysql> update account set blance=123.0 where id=1; --更新指定行
Query OK, 1 row affected (0.05 sec)
Rows matched: 1 Changed: 1 Warnings: 0
--没有commit哦!!!
--终端B
mysql> begin;
mysql> select * from account;
+----+--------+----------+
| id | name | blance |
+----+--------+----------+
| 1 | 张三 | 123.00 | --读到终端A更新但是未commit的数据[insert,
delete同样]
| 2 | 李四 | 10000.00 |
+----+--------+----------+
2 rows in set (0.00 sec)
--一个事务在执行中,读到另一个执行中事务的更新(或其他操作)但是未commit的数据,这种现象叫做脏读
(dirty read)-- 终端A
mysql> set global transaction isolation level read committed;
Query OK, 0 rows affected (0.00 sec)
--重启客户端
mysql> select * from account; --查看当前数据
+----+--------+----------+
| id | name | blance |
+----+--------+----------+
| 1 | 张三 | 123.00 |
| 2 | 李四 | 10000.00 |
+----+--------+----------+
2 rows in set (0.00 sec)
mysql> begin; --手动开启事务,同步的开始终端B事务
Query OK, 0 rows affected (0.00 sec)
mysql> update account set blance=321.0 where id=1; --更新张三数据
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
--切换终端到终端B,查看数据。
mysql> commit; --commit提交!
Query OK, 0 rows affected (0.01 sec)
--切换终端到终端B,再次查看数据。
--终端B
mysql> begin; --手动开启事务,和终端A一前一后
Query OK, 0 rows affected (0.00 sec)
mysql> select * from account; --终端A commit之前,查看不到
+----+--------+----------+
| id | name | blance |
+----+--------+----------+
| 1 | 张三 | 123.00 | --老的值
| 2 | 李四 | 10000.00 |
+----+--------+----------+
2 rows in set (0.00 sec)
--终端A commit之后,看到了!
--but,此时还在当前事务中,并未commit,那么就造成了,同一个事务内,同样的读取,在不同的时间段
(依旧还在事务操作中!),读取到了不同的值,这种现象叫做不可重复读(non reapeatable read)!!
(这个是问题吗??)
mysql> select *from account;
+----+--------+----------+
| id | name | blance |
+----+--------+----------+
| 1 | 张三 | 321.00 | --新的值
| 2 | 李四 | 10000.00 |
+----+--------+----------+
2 rows in set (0.00 sec)--终端A
mysql> set global transaction isolation level repeatable read; --设置全局隔离级别
RR
Query OK, 0 rows affected (0.01 sec)
--关闭终端重启
mysql> select @@tx_isolation;
+-----------------+
| @@tx_isolation |
+-----------------+
| REPEATABLE-READ | --隔离级别RR
+-----------------+
1 row in set, 1 warning (0.00 sec)
mysql> select *from account; --查看当前数据
+----+--------+----------+
| id | name | blance |
+----+--------+----------+
| 1 | 张三 | 321.00 |
| 2 | 李四 | 10000.00 |
+----+--------+----------+
2 rows in set (0.00 sec)
mysql> begin; --开启事务,同步的,终端B也开始事务
Query OK, 0 rows affected (0.00 sec)
mysql> update account set blance=4321.0 where id=1; --更新数据
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
--切换到终端B,查看另一个事务是否能看到
mysql> commit; --提交事务
--切换终端到终端B,查看数据。
--终端B
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from account; --终端A中事务 commit之前,查看当前表中数据,数据未更新
+----+--------+----------+
| id | name | blance |
+----+--------+----------+
| 1 | 张三 | 321.00 |
| 2 | 李四 | 10000.00 |
+----+--------+----------+
2 rows in set (0.00 sec)
mysql> select * from account; --终端A中事务 commit 之后,查看当前表中数据,数据未更新
+----+--------+----------+
| id | name | blance |
+----+--------+----------+
| 1 | 张三 | 321.00 |
| 2 | 李四 | 10000.00 |
+----+--------+----------+
2 rows in set (0.00 sec)
--可以看到,在终端B中,事务无论什么时候进行查找,看到的结果都是一致的,这叫做可重复读!
mysql> commit; --结束事务
Query OK, 0 rows affected (0.00 sec)
mysql> select * from account; --再次查看,看到最新的更新数据
+----+--------+----------+
| id | name | blance |
+----+--------+----------+
| 1 | 张三 | 4321.00 |
| 2 | 李四 | 10000.00 |
+----+--------+----------+
2 rows in set (0.00 sec)--如果将上面的终端A中的update操作,改成insert操作,会有什么问题??
--终端A
mysql> select *from account;
+----+--------+----------+
| id | name | blance |
+----+--------+----------+
| 1 | 张三 | 321.00 |
| 2 | 李四 | 10000.00 |
+----+--------+----------+
2 rows in set (0.00 sec)
mysql> begin; --开启事务,终端B同步开启
Query OK, 0 rows affected (0.00 sec)
mysql> insert into account (id,name,blance) values(3, '王五', 5432.0);
Query OK, 1 row affected (0.00 sec)
--切换到终端B,查看另一个事务是否能看到
mysql> commit; --提交事务
Query OK, 0 rows affected (0.00 sec)
--切换终端到终端B,查看数据。
mysql> select * from account;
+----+--------+----------+
| id | name | blance |
+----+--------+----------+
| 1 | 张三 | 4321.00 |
| 2 | 李四 | 10000.00 |
| 3 | 王五 | 5432.00 |
+----+--------+----------+
3 rows in set (0.00 sec)
--终端B
mysql> begin; --开启事务
Query OK, 0 rows affected (0.00 sec)
mysql> select * from account; --终端A commit前 查看
+----+--------+----------+
| id | name | blance |
+----+--------+----------+
| 1 | 张三 | 4321.00 |
| 2 | 李四 | 10000.00 |
+----+--------+----------+
2 rows in set (0.00 sec)
mysql> select * from account; --终端A commit后 查看
+----+--------+----------+
| id | name | blance |
+----+--------+----------+
| 1 | 张三 | 4321.00 |
| 2 | 李四 | 10000.00 |
+----+--------+----------+
2 rows in set (0.00 sec)
mysql> select * from account; --多次查看,发现终端A在对应事务中insert的数据,在终端B的事
务周期中,也没有什么影响,也符合可重复的特点。但是,一般的数据库在可重复读情况的时候,无法屏蔽其
他事务insert的数据(为什么?因为隔离性实现是对数据加锁完成的,而insert待插入的数据因为并不存
在,那么一般加锁无法屏蔽这类问题),会造成虽然大部分内容是可重复读的,但是insert的数据在可重复读
情况被读取出来,导致多次查找时,会多查找出来新的记录,就如同产生了幻觉。这种现象,叫做幻读
(phantom read)。很明显,MySQL在RR级别的时候,是解决了幻读问题的(解决的方式是用Next-Key锁
(GAP+行锁)解决的。这块比较难,有兴趣同学了解一下)。
+----+--------+----------+
| id | name | blance |
+----+--------+----------+
| 1 | 张三 | 4321.00 |
| 2 | 李四 | 10000.00 |
+----+--------+----------+
2 rows in set (0.00 sec)
mysql> commit; --结束事务
Query OK, 0 rows affected (0.00 sec)
mysql> select * from account; --看到更新
+----+--------+----------+
| id | name | blance |
+----+--------+----------+
| 1 | 张三 | 4321.00 |
| 2 | 李四 | 10000.00 |
| 3 | 王五 | 5432.00 |
+----+--------+----------+
3 rows in set (0.00 sec)--对所有操作全部加锁,进行串行化,不会有问题,但是只要串行化,效率很低,几乎完全不会被采用
--终端A
mysql> set global transaction isolation level serializable;
Query OK, 0 rows affected (0.00 sec)
mysql> select @@tx_isolation;
+----------------+
| @@tx_isolation |
+----------------+
| SERIALIZABLE |
+----------------+
1 row in set, 1 warning (0.00 sec)
mysql> begin; --开启事务,终端B同步开启
Query OK, 0 rows affected (0.00 sec)
mysql> select * from account; --两个读取不会串行化,共享锁
+----+--------+----------+
| id | name | blance |
+----+--------+----------+
| 1 | 张三 | 4321.00 |
| 2 | 李四 | 10000.00 |
| 3 | 王五 | 5432.00 |
+----+--------+----------+
3 rows in set (0.00 sec)
mysql> update account set blance=1.00 where id=1; --终端A中有更新或者其他操作,会阻
塞。直到终端B事务提交。
Query OK, 1 row affected (18.19 sec)
Rows matched: 1 Changed: 1 Warnings: 0
--终端B
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from account; --两个读取不会串行化
+----+--------+----------+
| id | name | blance |
+----+--------+----------+
| 1 | 张三 | 4321.00 |
| 2 | 李四 | 10000.00 |
| 3 | 王五 | 5432.00 |
+----+--------+----------+
3 rows in set (0.00 sec)
mysql> commit; --提交之后,终端A中的update才会提交。
Query OK, 0 rows affected (0.00 sec)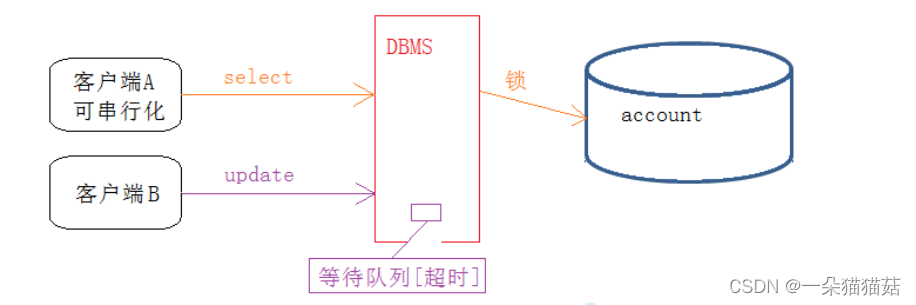

十三、视图
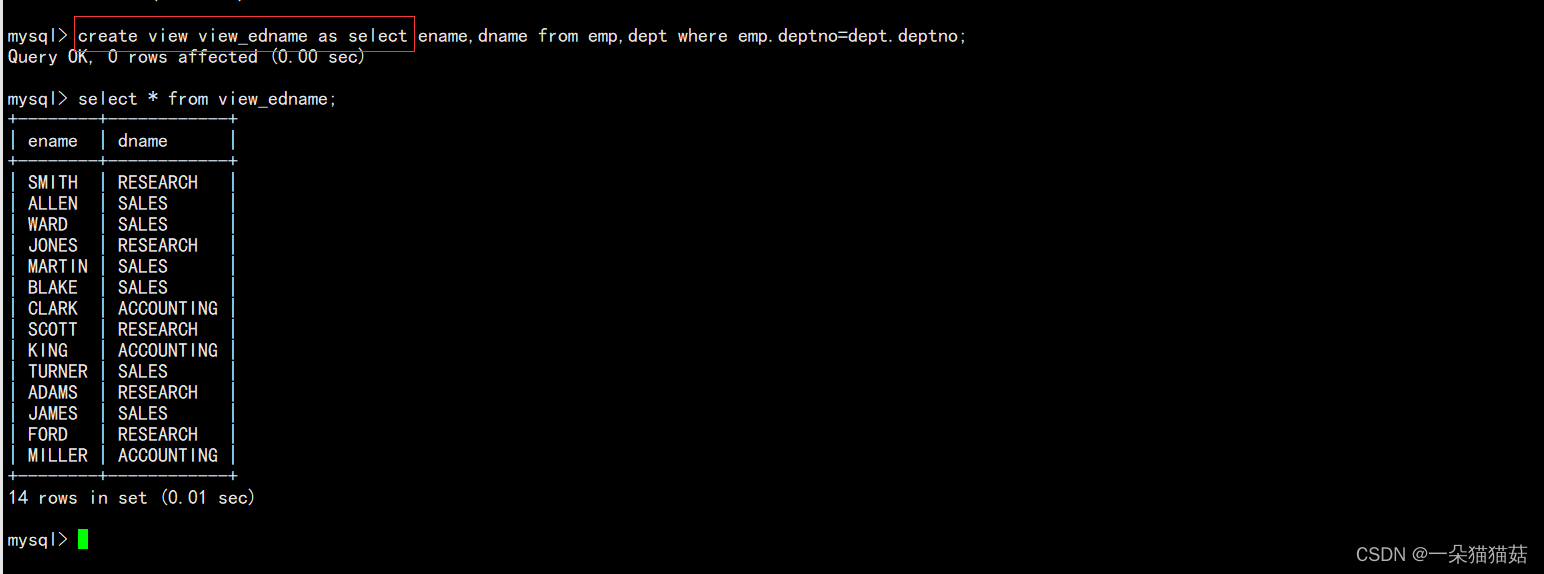
创建视图
create view 视图名 as select语句;比如:
create view v_ename_dname as select ename, dname
from EMP, DEPT where EMP.deptno=DEPT.deptno;
select * from v_ename_dname order by dname;
+--------+------------+
| ename | dname |
+--------+------------+
| CLARK | ACCOUNTING |
| KING | ACCOUNTING |
| MILLER | ACCOUNTING |
| SMITH | RESEARCH |
| JONES | RESEARCH |
| SCOTT | RESEARCH |
| ADAMS | RESEARCH |
| FORD | RESEARCH |
| ALLEN | SALES |
| WARD | SALES |
| MARTIN | SALES |
| BLAKE | SALES |
| TURNER | SALES |
| JAMES | SALES |
+--------+------------+
select emp.ename,dept.dname,dept.deptno from emp,dept where
emp.deptno=dept.deptno order by dname;
update v_ename_dname set ename='TEST' where ename='CLARK';
select * from EMP where ename='CLARK';
select * from EMP where ename='TEST';mysql> update EMP set deptno=10 where ename='JAMES'; -- 修改基表
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select * from v_ename_dname where ename='JAMES';
+-------+----------+
| ename | dname |
+-------+----------+
| JAMES | RESEARCH | <== 视图中的数据也发生了变化
+-------+----------+

drop view 视图名;十四、用户管理
如果我们只能使用root用户,这样存在安全隐患。这时,就需要使用MySQL的用户管理。
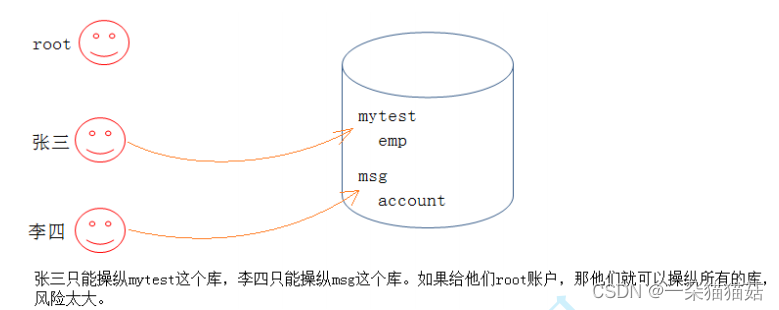
1.用户信息
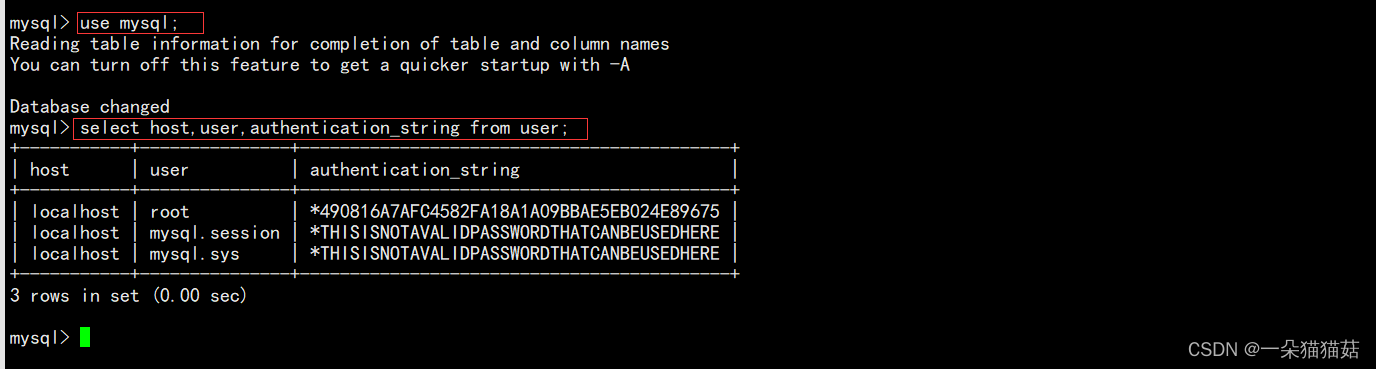
2.创建用户
语法
create user '用户名'@'登陆主机/ip' identified by '密码';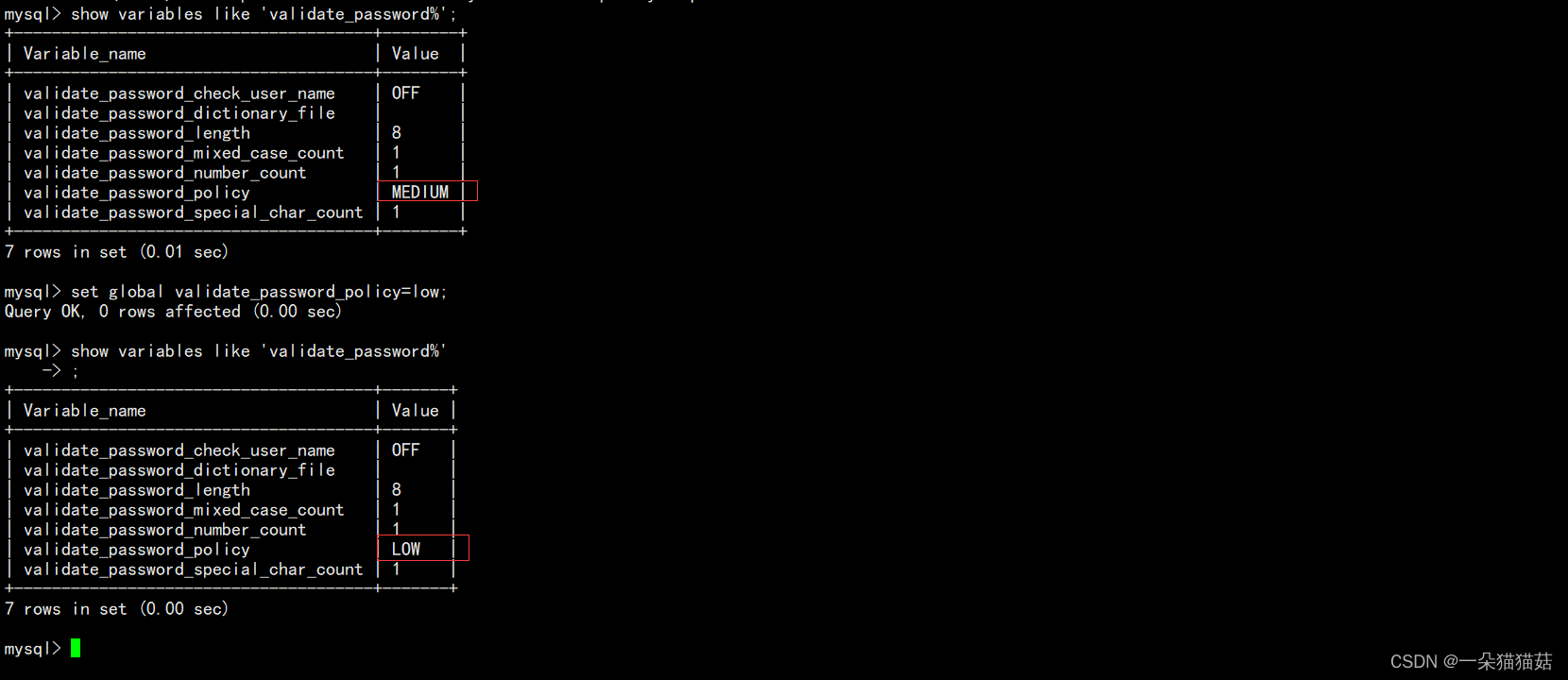
当遇到密码等级的报错时通过上图中的命令进行查看。
3.删除用户
语法
drop user '用户名'@'主机名'4.修改用户密码
自己改自己的密码
set password=password('新的密码');set password for '用户名'@'主机名'=password('新的密码');

grant 权限列表 on 库.对象名 to '用户名'@'登陆位置' [identified by '密码']grant select on ...
grant select, delete, create on ....
grant all [privileges] on ... -- 表示赋予该用户在该对象上的所有权限语法
revoke 权限列表 on 库.对象名 from '用户名'@'登陆位置';十五、连接MySQL
[hb@MiWiFi-R1CL-srv lib]$ tree .
.
├── include
│ ├── big_endian.h
│ ├── byte_order_generic.h
│ ├── byte_order_generic_x86.h
│ ├── decimal.h
│ ├── errmsg.h
│ ├── keycache.h
│ ├── little_endian.h
│ ├── m_ctype.h
│ ├── m_string.h
│ ├── my_alloc.h
│ ├── my_byteorder.h
│ ├── my_compiler.h
│ ├── my_config.h
│ ├── my_dbug.h
│ ├── my_dir.h
│ ├── my_getopt.h
│ ├── my_global.h
│ ├── my_list.h
│ ├── my_pthread.h
│ ├── mysql
│ │ ├── client_authentication.h
│ │ ├── client_plugin.h
│ │ ├── client_plugin.h.pp
│ │ ├── get_password.h
│ │ ├── plugin_auth_common.h
│ │ ├── plugin_trace.h
│ │ ├── psi
│ │ │ ├── mysql_file.h
│ │ │ ├── mysql_idle.h
│ │ │ ├── mysql_mdl.h
│ │ │ ├── mysql_memory.h
│ │ │ ├── mysql_ps.h
│ │ │ ├── mysql_socket.h
│ │ │ ├── mysql_sp.h
│ │ │ ├── mysql_stage.h
│ │ │ ├── mysql_statement.h
│ │ │ ├── mysql_table.h
│ │ │ ├── mysql_thread.h
│ │ │ ├── mysql_transaction.h
│ │ │ ├── psi_base.h
│ │ │ ├── psi.h
│ │ │ └── psi_memory.h
│ │ ├── service_my_snprintf.h
│ │ └── service_mysql_alloc.h
│ ├── mysql_com.h
│ ├── mysql_com_server.h
│ ├── mysqld_ername.h
│ ├── mysqld_error.h
│ ├── mysql_embed.h
│ ├── mysql.h
│ ├── mysql_time.h
│ ├── mysql_version.h
│ ├── my_sys.h
│ ├── my_xml.h
│ ├── sql_common.h
│ ├── sql_state.h
│ ├── sslopt-case.h
│ ├── sslopt-longopts.h
│ ├── sslopt-vars.h
│ └── typelib.h
└── lib
├── libmysqlclient.a
├── libmysqlclient_r.a -> libmysqlclient.a
├── libmysqlclient_r.so -> libmysqlclient.so
├── libmysqlclient_r.so.18 -> libmysqlclient.so.18
├── libmysqlclient_r.so.18.3.0 -> libmysqlclient.so.18.3.0
├── libmysqlclient.so -> libmysqlclient.so.18
├── libmysqlclient.so.18 -> libmysqlclient.so.18.3.0
└── libmysqlclient.so.18.3.0#include <stdio.h>
#include <mysql.h>
int main()
{
printf("mysql client Version: %s\n", mysql_get_client_info());
return 0;
}
[hb@MiWiFi-R1CL-srv lib]$ gcc -o test test.c -I./include -L./lib -lmysqlclient
[hb@MiWiFi-R1CL-srv lib]$ ls
include lib test test.c
[hb@MiWiFi-R1CL-srv lib]$ ./test
./test: error while loading shared libraries: libmysqlclient.so.18: cannot open
shared object file: No such file or directory
[hb@MiWiFi-R1CL-srv lib]$ export LD_LIBRARY_PATH=./lib #动态库查找路径,讲解ldd命令
[hb@MiWiFi-R1CL-srv lib]$ ./test
mysql client Version: 6.1.6MYSQL *mysql_real_connect(MYSQL *mysql, const char *host,
const char *user,
const char *passwd,
const char *db,
unsigned int port,
const char *unix_socket,
unsigned long clientflag);
//建立好链接之后,获取英文没有问题,如果获取中文是乱码:
//设置链接的默认字符集是utf8,原始默认是latin1
mysql_set_character_set(myfd, "utf8");int mysql_query(MYSQL *mysql, const char *q);MYSQL_RES *mysql_store_result(MYSQL *mysql);my_ulonglong mysql_num_rows(MYSQL_RES *res);unsigned int mysql_num_fields(MYSQL_RES *res);MYSQL_FIELD *mysql_fetch_fields(MYSQL_RES *res);比如:
int fields = mysql_num_fields(res);
MYSQL_FIELD *field = mysql_fetch_fields(res);
int i = 0;
for(; i < fields; i++){
cout<<field[i].name<<" ";
}
cout<<endl;MYSQL_ROW mysql_fetch_row(MYSQL_RES *result);i = 0;
MYSQL_ROW line;
for(; i < nums; i++){
line = mysql_fetch_row(res);
int j = 0;
for(; j < fields; j++){
cout<<line[j]<<" ";
}
cout<<endl;
}void mysql_close(MYSQL *sock);my_bool STDCALL mysql_autocommit(MYSQL * mysql, my_bool auto_mode);
my_bool STDCALL mysql_commit(MYSQL * mysql);
my_bool STDCALL mysql_rollback(MYSQL * mysql);总结
本篇文章只作为自己学习MySQL的笔记,其中有错误的地方还希望大家能够指出来。对于想要入门MySQL的同学看这篇文章就足够了,将这篇文章中的案例都进行演示后就可以去刷MySQL的题了。本篇文章的面试重点在于约束,索引,事务这三部分,面试前突击的可以优先看这部分。