提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 一、GPT介绍
- 1.无监督预训练
- 2.有监督下游任务精调
- 3.适配不同的下游任务
- 二、基于pytorch自己训练一个小型chatgpt
- 1.数据集
- 2. 模型
- 3.方法介绍
- 4.核心代码展示
- 4.实现效果
一、GPT介绍
OpenAI公式在2018年提出了一种生成式预训练(Generative Pre-Trainging,GPT)模型用来提升自然语言理解任务的效果,正式将自然语言处理带入预训练时代,预训练时代意味着利用更大规模的文本数据一级更深层次的神经网络模型学习更丰富的文本语义表示。同时,GPT的出现提出了“”生成式预训练+判别式任务精调的自然语言处理新范式,使得自然语言处理模型的搭建变得不在复杂。
- 生成式预训练:在大规模文本数据上训练一个高容量的语言模型,从而学习更加丰富的上下文信息;
- 判别式任务精调:将预训练好的模型适配到下游任务中,并使用有标注的数据学习判别式任务。
GPT的整体结构是一个基于Transformer的单向语言模型,即从左到右对输入文本建模,模型结构如图所示。
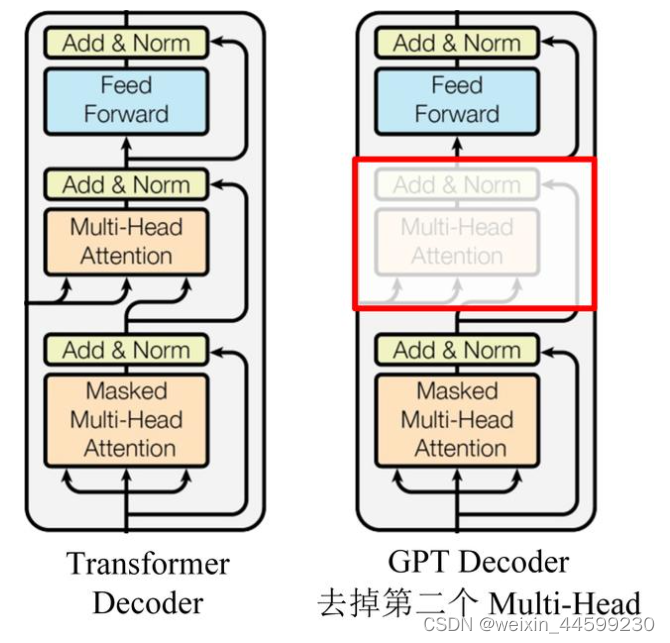
GPT只使用了Transformer的Decoder结构,由于没有了Encoder,就没有Encoder的输出,所以去掉了原本的Encoder-Decoder Attention。
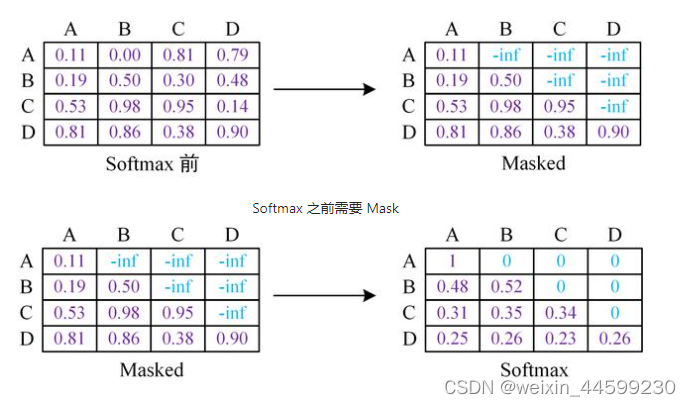
GPT模型使用Transformer的Decoder结构,在Decoder self-attention结构中使用了mask机制,将自注意力矩阵的上三角mask掉,每个单词只能获取它本身以及它之前词的注意力,防止模型看到未来时刻信息,因为语言模型就是要预测未来时刻单词的,让其看到未来时刻信息相当于作弊了,模型学不到任何东西。如图所示,将上三角的值设置为负无穷,经过softmax计算后就会变成0,每个词只能注意到当前词以及之前词。例如图中,A这个词这一行,只有第一列有值,它只能注意自身,B这个词这一行,它前两列有值,说明B只能注意到A以及B,注意不到C和D,因为模型需要根据AB去预测C,所以不让模型注意到C以及更靠后的信息。
1.无监督预训练
GPT利用常规语言建模的方法优化给定文本序列 x = x 1 , x 2 , . . . , x n x=x_{1},x_{2},...,x_{n} x=x1,x2,...,xn的最大似然估计 L P T L^{PT} LPT。
L P T = ∑ i l o g P ( x i ∣ x i − k . . . x i − 1 ; θ ) L^{PT} = \sum_{i}^{}logP(x_{i}|x_{i-k}...x_{i-1};\theta ) LPT=i∑logP(xi∣xi−k...xi−1;θ)
式中k表示语言模型的窗口大小,即基于k个历史词 x i − k . . . x i − 1 x_{i-k}...x_{i-1} xi−k...xi−1预测当前时刻的词 x i x_{i} xi, θ \theta θ表示神经网络的参数。
对于长度为k的窗口词序列 x ′ = x − k . . . x − 1 x'=x_{-k}...x_{-1} x′=x−k...x−1,通过以下方式计算建模概率P。
h [ 0 ] = e x ′ W e + W p h^{[0]}=e_{x'}W^{e}+W^{p} h[0]=ex′We+Wp
h [ l ] = T r a n s f o r m e r - D e c o d e r ( h [ l − 1 ] ) , ∀ l ∈ 1,2,...,L h^{[l]}=Transformer\text{-}Decoder(h^{[l-1]}),\forall l \in \text{{1,2,...,L}} h[l]=Transformer-Decoder(h[l−1]),∀l∈1,2,...,L
P ( x ) = S o f t m a x ( h [ L ] W e T ) P(x)=Softmax(h^{[L]}W^{e^{T}}) P(x)=Softmax(h[L]WeT)
式中, e x ′ ∈ R k × ∣ V ∣ e_{x'} \in R^{k×|V|} ex′∈Rk×∣V∣表示 x ′ x' x′的独热向量表示; W e ∈ R ∣ V ∣ × d W^{e} \in R^{|V|×d} We∈R∣V∣×d表示词向量矩阵, W p W^{p} Wp表示位置向量矩阵,L表示总层数。
现在模型一般不取k个历史词,而是取所有历史词。
2.有监督下游任务精调
在预训练阶段,GPT利用大规模数据训练出基于深层Transformer的语言模型,已经掌握了文本的通用语义表示。精调(fine-tuning)的目的在通用语义的表示基础上,根据下游任务(Downstream task)的特征进行领域适配,使之与下游任务的形式更加契合,以获得更好的下游任务应用效果。
下游任务精调通常是由有标签数据进行训练和优化的。假设下游任务的标注数据为C,其中每个样例的输入是 x = x 1 x 2 . . . x n x=x_{1}x_{2}...x_{n} x=x1x2...xn构成的长度为n的文本序列,与之对应的标签为y。首先将文本序列输入预训练的GPT中,获得最后一层最后一个词对应的隐含层输出 h n [ L ] h^{[L]}_{n} hn[L],紧接着,将该隐含层输出通过一层全连接层,预测最终标签y。
P ( y ∣ x 1 , x 2 , . . . x n ) = S o f t m a x ( h n [ L ] W y ) P(y|x_{1},x_{2},...x_{n})=Softmax(h^{[L]}_{n}W^{y}) P(y∣x1,x2,...xn)=Softmax(hn[L]Wy)
其中, W y ∈ R d ✖ c W^{y} \in R^{d✖c} Wy∈Rd✖c表示全连接层权重,c为类别个数。
最终,通过优化以下损失函数精调下游任务。
L F T ( C ) = ∑ ( x , y ) l o g P ( y ∣ x 1 . x 2 , . . . , x n ) L^{FT}(C) = \sum_{(x,y)}^{}logP(y|x_{1}.x_{2},...,x_{n}) LFT(C)=(x,y)∑logP(y∣x1.x2,...,xn)
另外,为了进一步提升精调后模型的通用性以及收敛速度,可以在下游任务精调时加入一定权重的预训练任务损失。这样做是为了缓解在下游任务精调时出现灾难性遗忘问题。因为在下游任务精调过程中,GPT的训目标是优化下游任务数据上的效果,更强调特殊性。因此势必会对预训练阶段学习的通用知识产生部分的覆盖或者擦除,丢失一定的通用性。通过结合下游任务精调损失和预训练任务损失,可以有效缓解灾难性遗忘问题,在优化下游任务效果的同时保留一定的通用性。在实际应用中,可通过下式精调下游任务。
L ( C ) = L F T ( C ) + λ L P T ( C ) L(C)=L^{FT}(C)+\lambda L^{PT}(C) L(C)=LFT(C)+λLPT(C)
3.适配不同的下游任务
分类任务

对文本开头加一个开始标识符,结尾加上一个抽取标识符,将其输入Transformer解码器,最后的这个抽取标识符得到的结果在经过一个全连接层即可进行分类,使用最后一个标识符的原因是最后一个标识符可以抽取前面所有词的信息。
蕴含任务

给一段话,然后给一个假设,判断这段话有没有蕴含假设提出的内容。
比如假设是a喜欢b,给出的这段话是a喜欢b,那么这段话是支持这个假设的,如果给出这段话是a讨厌b,那么这段话不支持这个假设,如果给出的这段话是a和b是邻居,那么既不支持也不反对,其实本质也是一个三分类任务。将两句话拼接起来,最开始加上开始符,中间加上分隔符,最后加上抽取符。
相似任务

判断两段话是否相似,也是需要将两段话拼接起来,前边加上开始符,中间分隔符,最后抽取符。相似是一个对称问题,a与b相似,那么b与a也是相似的,所以需要将两句话交换个位置,构造两个序列输入模型,将两个结果相加经过全连接层进行分类。
选择题

给定一个问题,以及对应的几个答案,让模型选出正确答案,有N个答案就构造如图所示的N个序列,分别输入模型,得到N个结果再分别输入N个全连接层,全连接层输出大小为1,这N个输出中,最大的我们认为是正确答案。
二、基于pytorch自己训练一个小型chatgpt
1.数据集
本文使用了一个由五十万轮对话组成的数据集,数据集下载地址,(需要科学上网)链接: 数据集下载地址
或者百度网盘百度网盘,提取码jk8d
数据集长这个样子,每轮对话用一个换行符隔开。

这个数据集质量不是很好,数据量也很小,训练出来的模型效果不是特别好,如果读者有更大的以及质量更好的数据集,可以替换到这个数据集重新进行训练。
2. 模型
使用huggingface上开源的中文GPT-2模型,使用100G纯文本预训练后的模型。模型地址https://huggingface.co/uer/gpt2-chinese-cluecorpussmall

将这里的文件全部下载下来。基于这个预训练模型微调我们的对话模型。
3.方法介绍
GPT模型是一个语言模型,只能从前往后一个字符一个字符进行预测,怎么让它完成对话任务呢?
其中一个方法就是将每轮对话拼接起来,中间使用一个[SEP]符号,例如刚才图中的第一轮对话的例子,拼接起来后就变成这样,“谢谢你所做的一切[SEP]你开心就好[SEP]开心[SEP]嗯因为你的心里只有学习[SEP]某某某,还有你[SEP]这个某某某用的好”,将这一轮对话看作是一条样本,中间使用[SEP]拼接起来,以语言模型目标继续微调GPT模型,模型就可以基于前边已知的信息预测后边一个字符。
在推理阶段,输入一句话,假如是,“你在干嘛?”,然后在后面拼接上一个[SEP]输入到模型中,让模型预测下一个字符,比如模型预测出一个"我",然后再将这个"我"字拼接到原来的基础上,得到“你在干嘛?[SEP]我”,然后让模型再预测下一个字符,依此类推,直到模型预测出[SEP],预测出来的这部分作为回答,比如模型依次预测出了“我在玩呢”,将"我在玩呢"作为这句话的回答,如果再次提问,“你在玩什么呢?”,这时候需要将历史信息全部拼接起来,最后再加一个[SEP,]就像这样,“你在干嘛?[SEP]我在玩呢[SEP]你在玩什么呢?[SEP]”,然后再让模型依次预测下一个字符,直到预测出[SEP],这样就可以实现多轮对话的功能,传统的基于seq2seq的对话模型,无法记住上下文信息,他的回答只能通过你当前的问题生成。刚才提到的这种方式,其可以记住上下文,基于上下文进行回答,chatgpt也是基于这种原理记住上下文的。
4.核心代码展示
模型部分:
import syssys.path.append("..")
from transformers import BertTokenizer, GPT2LMHeadModel
from torch import nnfrom utils.utils import get_project_rootpath
import osclass GPT2(nn.Module):def __init__(self):super(GPT2, self).__init__()self.gpt = GPT2LMHeadModel.from_pretrained(os.path.join(get_project_rootpath(), "gpt2-chinese-cluecorpussmall"))def forward(self, batch_inputs):outputs = self.gpt(input_ids=batch_inputs)return outputs模型部分比较简单,直接调用的huggingface的gpt2模型,其中gpt2-chinese-cluecorpussmall这个文件夹里保存的就是刚才huggingface网址下载的那些文件。
dataset:
import json
import torch
import torch.utils.data as Data
from torch import nn, optim
import numpy as npdef make_data(file_path, tokenizer):with open(file_path, 'r', encoding='utf-8') as f:lines = f.readlines()train_datas = []for line in lines:line = line.strip()train_data = [i if i != '\t' else "[SEP]" for i in line] + ['[SEP]']train_num_data = tokenizer.encode(train_data)train_num_data = train_num_data[:-1]train_datas.append(train_num_data)return train_datasclass MyDataSet(Data.Dataset):def __init__(self, datas, vocab2id):self.datas = datasself.vocab2id = vocab2iddef __getitem__(self, item):data = self.datas[item]decoder_input = data[:-1]decoder_output = data[1:]decoder_input_len = len(decoder_input)decoder_output_len = len(decoder_output)return {"decoder_input": decoder_input, "decoder_input_len": decoder_input_len,"decoder_output": decoder_output, "decoder_output_len": decoder_output_len}def __len__(self):return len(self.datas)def padding_batch(self, batch):decoder_input_lens = [d["decoder_input_len"] for d in batch]decoder_output_lens = [d["decoder_output_len"] for d in batch]decoder_input_maxlen = max(decoder_input_lens)decoder_output_maxlen = max(decoder_output_lens)for d in batch:d["decoder_input"].extend([self.vocab2id["[PAD]"]] * (decoder_input_maxlen - d["decoder_input_len"]))d["decoder_output"].extend([self.vocab2id["[PAD]"]] * (decoder_output_maxlen - d["decoder_output_len"]))decoder_inputs = torch.tensor([d["decoder_input"] for d in batch], dtype=torch.long)decoder_outputs = torch.tensor([d["decoder_output"] for d in batch], dtype=torch.long)return decoder_inputs, decoder_outputs训练部分:
import json
import osimport torch
import syssys.path.append("..")
import torch.utils.data as Data
from torch import nn, optim
import numpy as np
import time
from tqdm import tqdmfrom config.train_config import train_parse_args
from src.dataset import make_data, MyDataSet
from src.model import GPT2
from transformers import BertTokenizer
from utils.loss_recorder import AverageMeter
from utils.utils import get_project_rootpathtrain_args = train_parse_args()def epoch_time(start_time, end_time):elapsed_time = end_time - start_timeelapsed_mins = int(elapsed_time / 60)elapsed_secs = int(elapsed_time - (elapsed_mins * 60))return elapsed_mins, elapsed_secsdef train_step(model, data_loader, epoch, optimizer, criterion, clip=1, print_every=None):model.train()if print_every == 0:print_every = 1epoch_loss = 0losses = AverageMeter()temp_time = time.time()for step, (dec_inputs, dec_outputs) in enumerate(data_loader):'''dec_inputs: [batch_size, tgt_len]dec_outputs: [batch_size, tgt_len]'''optimizer.zero_grad()dec_inputs, dec_outputs = dec_inputs.to(device), dec_outputs.to(device)# outputs: [batch_size * tgt_len, tgt_vocab_size]outputs = model(dec_inputs)outputs = outputs.logitsoutputs = outputs.view(-1,outputs.size(-1))loss = criterion(outputs, dec_outputs.view(-1))epoch_loss += loss.item()losses.update(loss.item(), batch_size)loss.backward()# 梯度裁剪torch.nn.utils.clip_grad_norm_(model.parameters(), clip)optimizer.step()if print_every and (step + 1) % print_every == 0:minutes, seconds = epoch_time(temp_time, time.time())print('Epoch: [{0}][{1}/{2}] ''Loss: {loss.val:.4f}({loss.avg:.4f}) ''Elapsed {minutes:s}min {seconds:s}s '.format(epoch, step + 1, len(data_loader),minutes=minutes.__str__(),seconds=seconds.__str__(),loss=losses))temp_time = time.time()return epoch_loss / len(data_loader)def train(model, dataloader, train_args):criterion = nn.CrossEntropyLoss(ignore_index=0).to(device)lr = train_args.lrCLIP = train_args.clipprint_every = train_args.print_everysave_path = train_args.save_pathoptimizer = optim.Adam(model.parameters(), lr=lr)for epoch in range(epochs):start_time = time.time()train_loss = train_step(model, dataloader, epoch, optimizer, criterion, CLIP, print_every=print_every)end_time = time.time()torch.save(model.state_dict(), save_path)epoch_mins, epoch_secs = epoch_time(start_time, end_time)print(f'Epoch: {epoch + 1:02} | Time: {epoch_mins}m {epoch_secs}s')print(f'\tTrain Loss: {train_loss:.3f}')def print_num_parameters(model):# Find total parameters and trainable parameterstotal_params = sum(p.numel() for p in model.parameters())print(f'{total_params:,} total parameters.')total_trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)print(f'{total_trainable_params:,} training parameters.')if __name__ == '__main__':device = train_args.devicetokenizer = BertTokenizer.from_pretrained(os.path.join(get_project_rootpath(), "gpt2-chinese-cluecorpussmall"))epochs = train_args.epochsbatch_size = train_args.batch_sizetrain_file_path = train_args.train_file_pathdatas = make_data(train_file_path, tokenizer)dataset = MyDataSet(datas, tokenizer.vocab)dataloader = Data.DataLoader(dataset, batch_size=batch_size, collate_fn=dataset.padding_batch)model = GPT2().to(device)train(model, dataloader, train_args)这是其中核心代码,并不是完整代码,完整代码在这里:https://www.123pan.com/s/2GpiVv-LFFmH.html提取码:jeAp
先运行process_data.py,将数据处理成需要的格式,config文件夹里是配置参数,自己选择合适的超参数进行训练,然后运行train.py就可以进行训练,在inference文件夹中demo.py是测试文件,运行这个文件进行对话。
我用了一块 NVIDIA Tesla V100-PCIE-32GB 显卡进行训练,由于一些句子较长,所以batch size 设置为8,训练了30个epoch。huggingface的gpt模型最大句子长度是1024,所以将句子长度进行了筛选,一轮对话长度超过1024的都去掉了。
4.实现效果



效果还可以,不算太好,数据量才50w,文件大小只有60MB,这远远不够,要想达到更好的效果,需要更大的数据集。这个项目仅供娱乐。