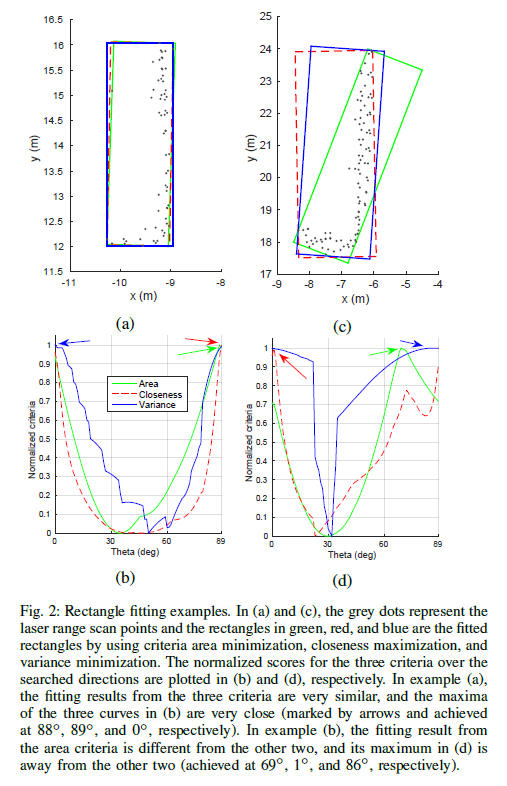
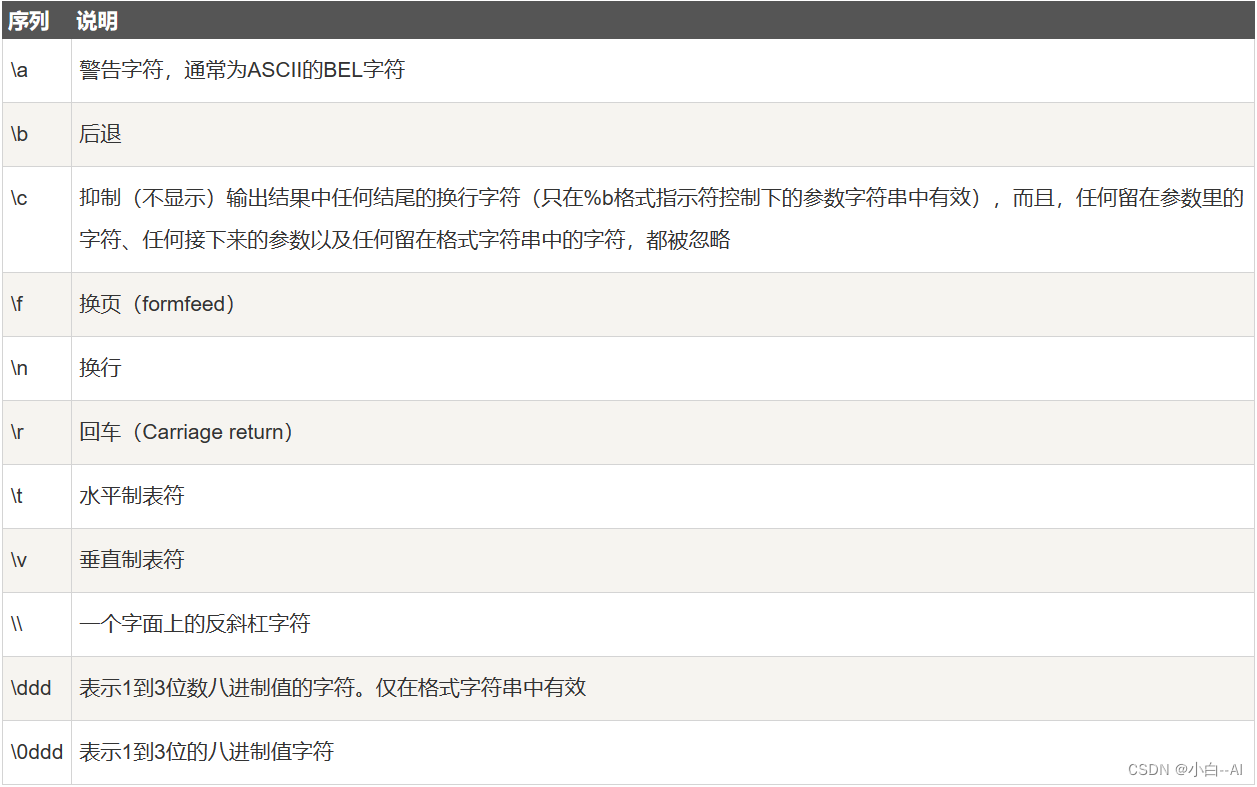
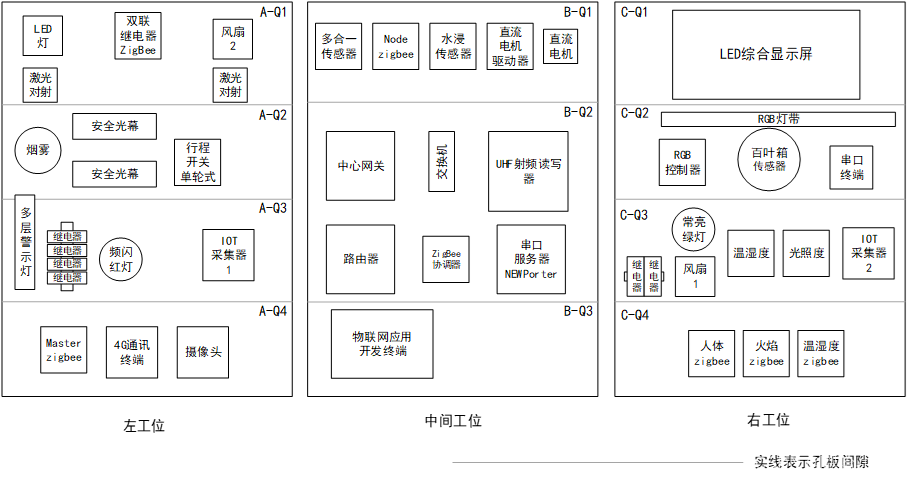
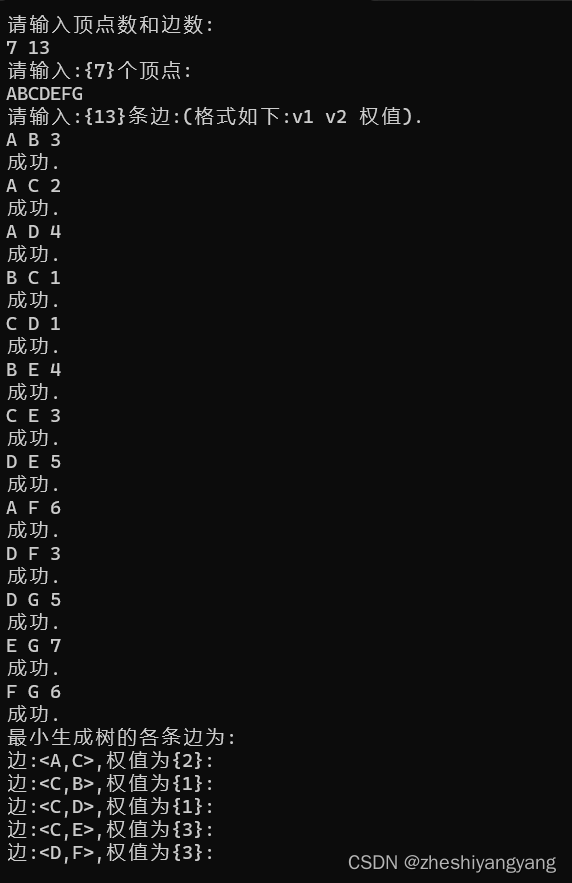
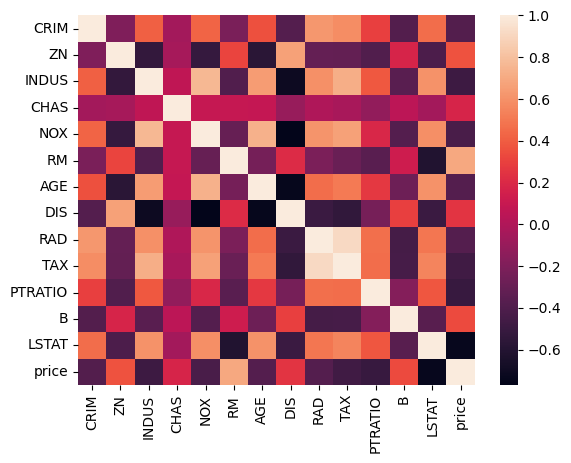
题目描述
有个内含单词的超大文本文件,给定任意两个单词,找出在这个文件中这两个单词的最短距离(相隔单词数)。如果寻找过程在这个文件中会重复多次,而每次寻找的单词不同,你能对此优化吗?示例:输入:words = ["I","am","a","student","from","a","university","in","a","city"], word1 = "a", word2 = "student"
输出:1
提示:words.length <= 100000来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/find-closest-lcci
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
方法 1:双指针
思路
使用双指针去找目标词:
- 当
指针l找到word1时,指针r从指针l的右边出发去找word1或者word2; - 如果
指针r找到了word2,计算距离r - l,同时记录一个最小的距离; - 如果
指针r找到的还是word1,更新指针l到指针r的位置,指针r继续右移寻找;

复杂度分析
- 时间复杂度:$O(N)$,N 为数组长度。
- 空间复杂度:$O(1)$。
代码
JavaScript Code
/*** @param {string[]} words* @param {string} word1* @param {string} word2* @return {number}*/
var findClosest = function (words, word1, word2) {const len = words.length;// 找到 word1 或者 word2const foundTarget = word => [word1, word2].includes(word);// e.g. 如果当前是 word1,那下一个要找的是 word2const getNext = cur => (cur === word1 ? word2 : word1);let res = len;let l = -1,r = -1,next = ''; // 下一个目标词while (r < len) {// 找到 word1 或者 word2if (foundTarget(words[r])) {// 如果找到的是目标词就更新 resif (words[r] === next && r - l < res) res = r - l;// 获取下一个目标词next = getNext(words[r]);l = r;r = r + 1;} else {r++;}}return res;
};
方法 2:哈希表
思路
先用一个哈希表把每个词出现的位置坐标收集起来,再用两个指针分别遍历两个目标词的坐标数组,计算最短距离。
如果寻找过程在这个文件中会重复多次,而每次寻找的单词不同,哈希表的解法更适合。
ps. 下图中 a 和 student 的坐标数组不是题目中的真实结果。
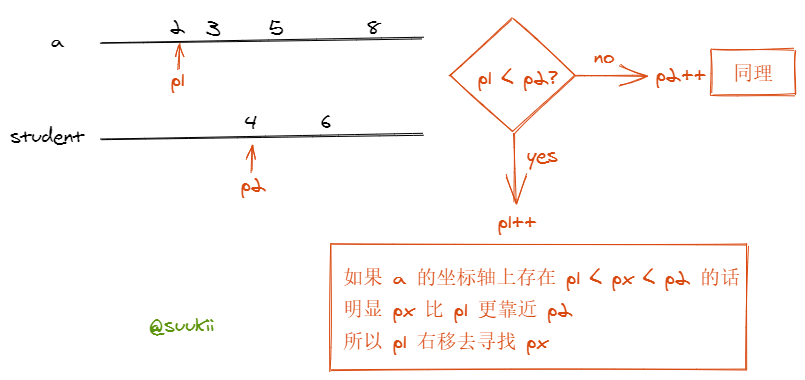
复杂度分析
- 时间复杂度:$O(N)$,N 为数组长度,遍历一次数组记录单词出现位置的时间复杂度 O(N),遍历两个目标单词的位置数组时间复杂度为 O(N)。
- 空间复杂度:$O(N)$,N 为数组长度,用了一个哈希表来记录每个单词出现的所有位置。
代码
JavaScript Code
/*** @param {string[]} words* @param {string} word1* @param {string} word2* @return {number}*/
var findClosest = function (words, word1, word2) {// 记录所有单词出现的位置const dict = {};words.forEach((w, i) => {dict[w] || (dict[w] = []);dict[w].push(i);});const indices1 = dict[word1],indices2 = dict[word2];let p1 = 0,p2 = 0,res = words.length;while (p1 < indices1.length && p2 < indices2.length) {res = Math.min(Math.abs(indices2[p2] - indices1[p1]), res);indices2[p2] > indices1[p1] ? p1++ : p2++;}return res;
};