硬件要求
硬件要求如表1所示。
表1 硬件要求
| 项目 | 说明 |
|---|---|
| CPU | 12 * AMD Ryzen 5 5500U with Radeon Graphics |
| 内存 | DDR4 |
| 磁盘 | HDD |
软件要求
软件要求如表2所示。
表2 软件要求
| 项目 | 版本 | 说明 | 下载地址 |
|---|---|---|---|
| CentOS | 7.6 | 操作系统。 | Download |
| kernel | 4.14.0 | 内核。 | 包含在操作系统镜像中。 |
| GCC | 4.8.5 | 编译器。 | 默认系统已安装。 |
| Python | 2.7.5 | 脚本执行工具。 | 默认系统已安装。 |
测试软件包要求:
测试软件包要求如下表3所示。
表3 测试软件包要求
| 项目 | 版本 | 软件包说明 | 获取方法 |
|---|---|---|---|
| RocksDB | 6.10.2 | 待测试软件包 | https://github.com/facebook/rocksdb/archive/refs/tags/v6.10.2.tar.gz |
一、编译工具:db_bench
在安装rocksdb的时候有一个make命令,执行这个命令后就安装了db_bench工具
验证工具。
./db_bench --help测试基准场景
fillseq(顺序写)
- 进入工具所在目录。
cd /home/rocksdb-6.10.2
- 执行测试命令创建数据库并填充数据。
./db_bench --benchmarks="fillseq,stats"
说明:选项--benchmarks的值,也可以由fillrandom替换,fillseq是按顺序填充,fillrandom是随机填充。
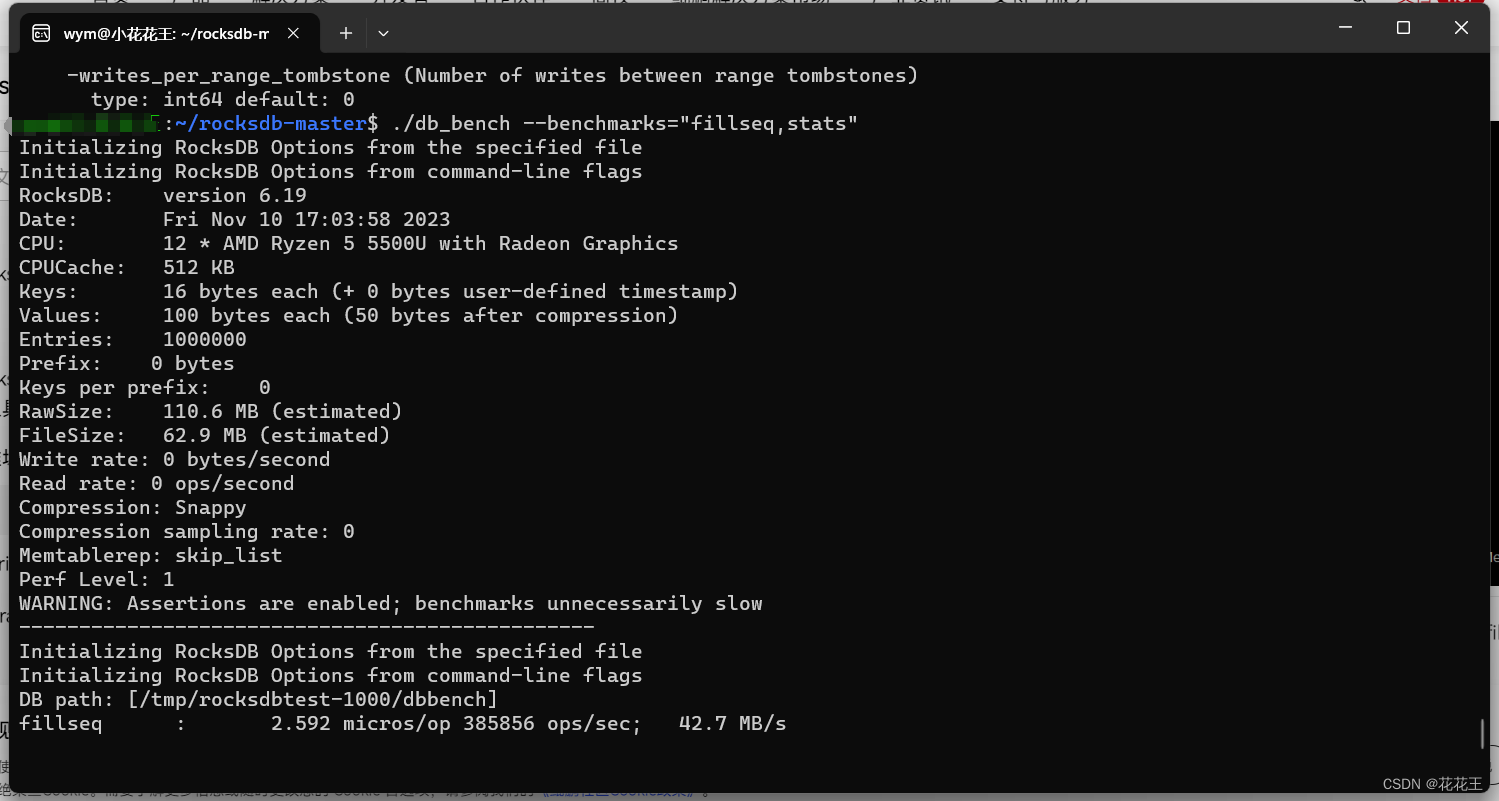
回显信息中:Entries显示数据量,Compression显示压缩类型,Memtablerep显示内存表类型,DB path显示数据库路径,fillseq显示性能数据,Compaction Stats显示合并信息。
overwrite(覆盖写)
- 进入工具所在目录。
cd /home/rocksdb-6.10.2
- 创建数据库并填充数据。
./db_bench --benchmarks="fillseq,stats"
- 在已有数据库的基础上进行覆盖写入。
./db_bench --benchmarks="overwrite,stats" --use_existing_db=true
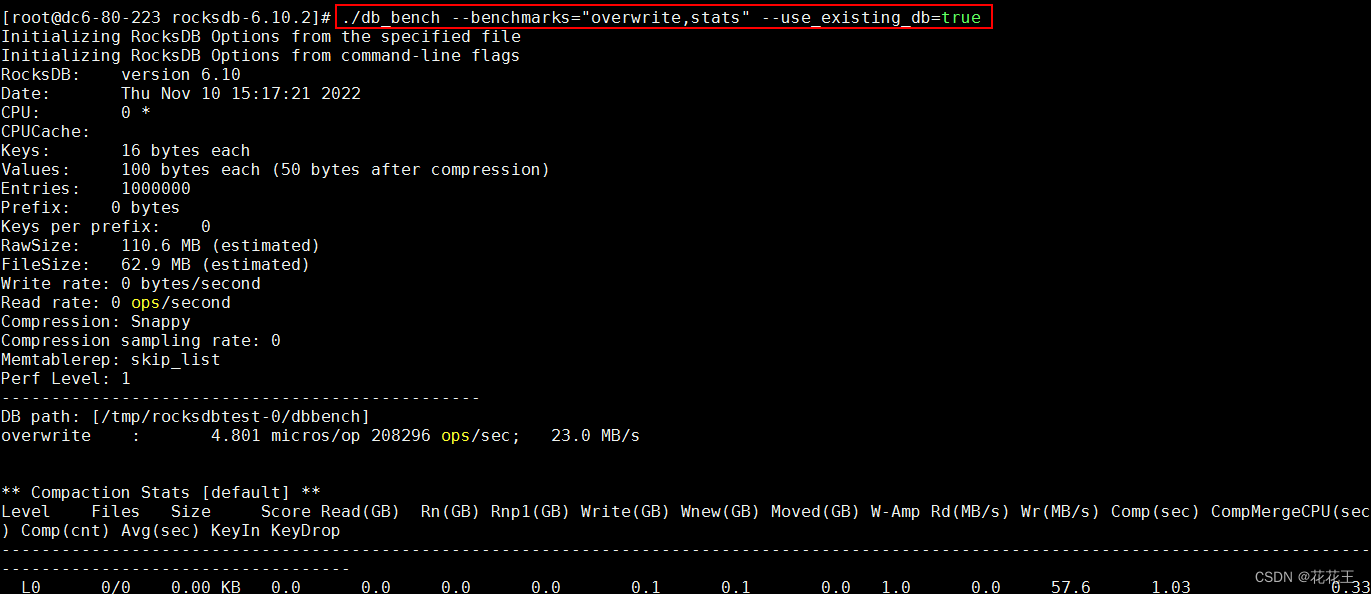
回显信息中:Entries显示数据量,Compression显示压缩类型,Memtablerep显示内存表类型,DB path显示数据库路径,overwrite显示性能数据,Compaction Stats显示合并信息。
deleterandom(随机删)
- 进入工具所在目录。
cd /home/rocksdb-6.10.2
- 创建数据库并填充数据。
./db_bench --benchmarks="fillseq,stats"
- 在已有数据库的基础上进行随机删除。
./db_bench --benchmarks="deleterandom,stats" --use_existing_db=true \ --use_existing_keys=true
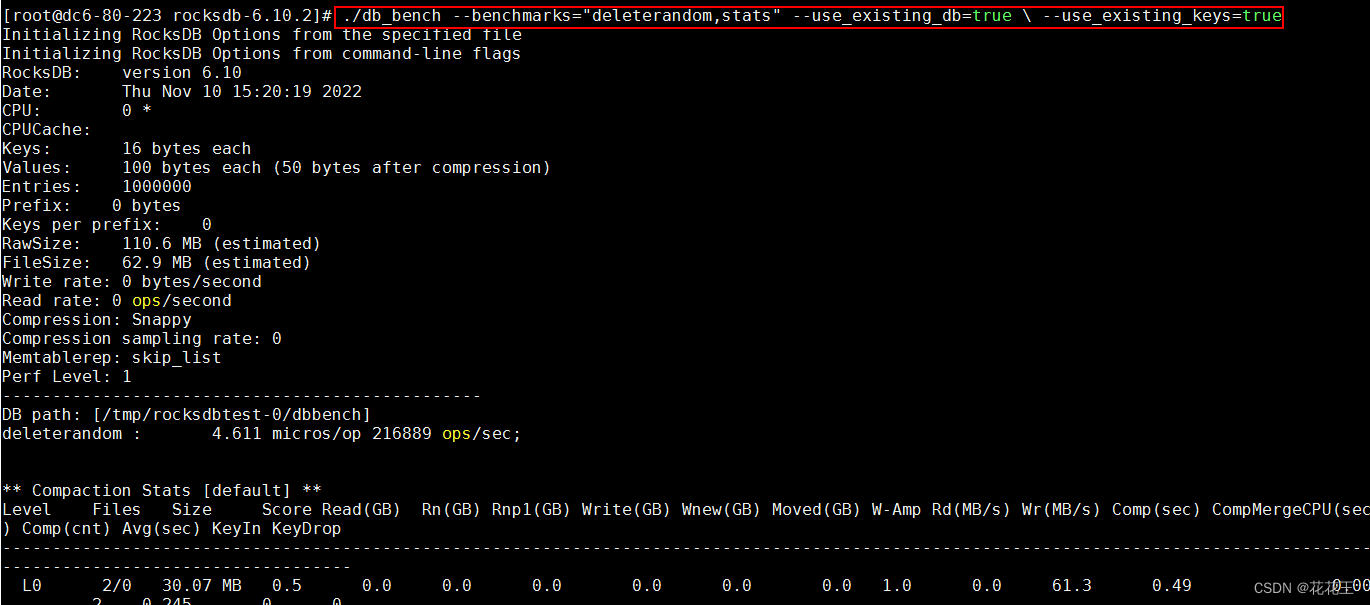
回显信息中:Entries显示数据量,Compression显示压缩类型,Memtablerep显示内存表类型,DB path显示数据库路径,deleterandom显示性能数据,Compaction Stats显示合并信息。
readrandom(随机读)
- 进入工具所在目录。
cd /home/rocksdb-6.10.2
- 创建数据库并填充数据。
./db_bench --benchmarks="fillseq,stats"
- 在已有数据库的基础上进行随机读取数据。
./db_bench --benchmarks="readrandom,stats" --use_existing_db=true \ --use_existing_keys=true
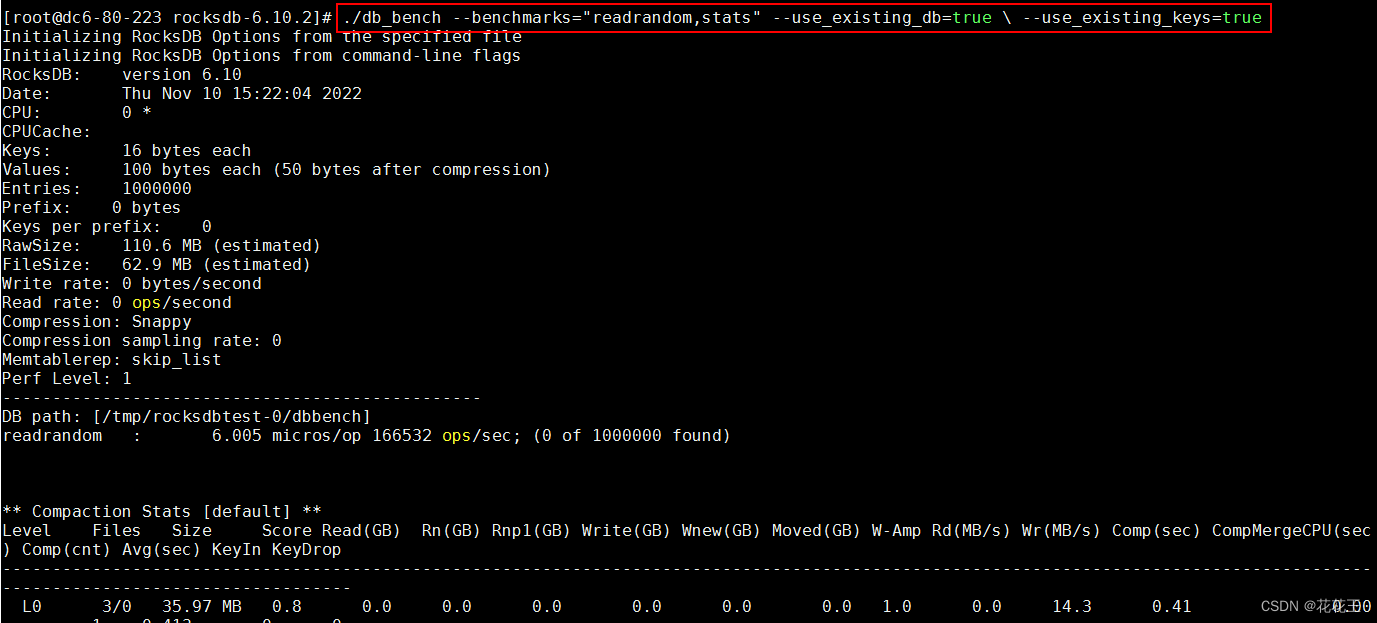
回显信息中:Entries显示数据量,Compression显示压缩类型,Memtablerep显示内存表类型,DB path显示数据库路径,readrandom显示性能数据。
readwhilemerging(合并时读)
- 进入工具所在目录。
cd /home/rocksdb-6.10.2
- 进行readwhilemerging基准场景的性能测试。
./db_bench --benchmarks="readwhilemerging,stats" --merge_operator=put
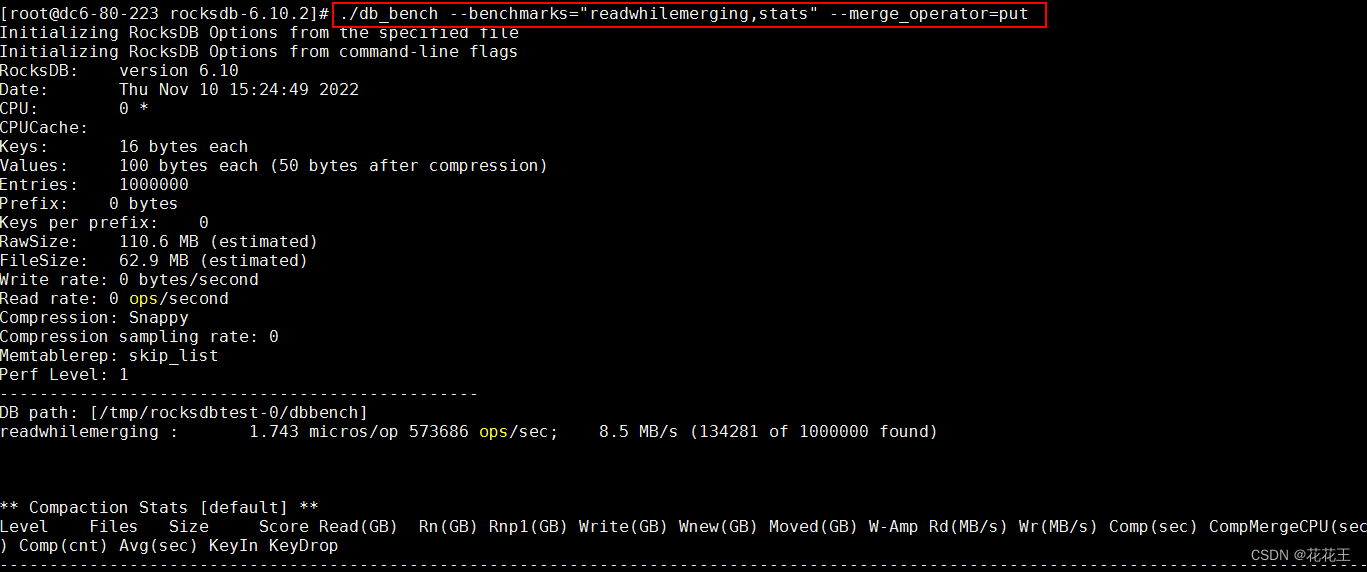
补充
在使用 RocksDB 中的 db_bench 工具之前,需要确保已经成功编译和安装了 RocksDB。然后按照以下步骤使用 db_bench 工具:
-
打开终端或命令提示符,并导航到 RocksDB 的安装目录。
-
运行以下命令启动 db_bench 工具:
./db_bench
- 可以根据需要指定一些参数来配置测试环境。例如,你可以使用
-help参数查看可用的选项列表:
./db_bench -help
- 根据你的需求设置合适的参数来运行性能测试。这些参数包括数据库路径、操作类型、数据大小等。例如,下面是一个示例命令,执行写入 1000 条记录并进行读取测试:
./db_bench --benchmarks=fillrandom,readrandom --num=1000
- 运行命令后,会显示性能测试的结果和统计信息,如吞吐量、延迟等。
请注意,在实际使用时可能还需要进一步配置和调整参数来满足特定场景的需求。建议查阅 RocksDB 的文档或官方资源以获得更详细的信息和使用指南。
补充2. 基本性能压测
由于db_bench工具的选项太多了,这里直接提取社区的测试方式
核心是benchmark,它代表本次测试使用的压测方式,benchmark的列表如下
fillseq -- write N values in sequential key order in async mode
fillseqdeterministic -- write N values in the specified key order and keep the shape of the LSM tree
fillrandom -- write N values in random key order in async mode
filluniquerandomdeterministic -- write N values in a random key order and keep the shape of the LSM tree
overwrite -- overwrite N values in random key order in async mode
fillsync -- write N/100 values in random key order in sync mode
fill100K -- write N/1000 100K values in random order in async mode
deleteseq -- delete N keys in sequential order
deleterandom -- delete N keys in random order
readseq -- read N times sequentially
readtocache -- 1 thread reading database sequentially
readreverse -- read N times in reverse order
readrandom -- read N times in random order
readmissing -- read N missing keys in random order
readwhilewriting -- 1 writer, N threads doing random reads
readwhilemerging -- 1 merger, N threads doing random reads
readrandomwriterandom -- N threads doing random-read, random-write
prefixscanrandom -- prefix scan N times in random order
updaterandom -- N threads doing read-modify-write for random keys
appendrandom -- N threads doing read-modify-write with growing values
mergerandom -- same as updaterandom/appendrandom using merge operator. Must be used with merge_operator
readrandommergerandom -- perform N random read-or-merge operations. Must be used with merge_operator
newiterator -- repeated iterator creation
seekrandom -- N random seeks, call Next seek_nexts times per seek
seekrandomwhilewriting -- seekrandom and 1 thread doing overwrite
seekrandomwhilemerging -- seekrandom and 1 thread doing merge
crc32c -- repeated crc32c of 4K of data
xxhash -- repeated xxHash of 4K of data
acquireload -- load N*1000 times
fillseekseq -- write N values in sequential key, then read them by seeking to each key
randomtransaction -- execute N random transactions and verify correctness
randomreplacekeys -- randomly replaces N keys by deleting the old version and putting the new version
timeseries -- 1 writer generates time series data and multiple readers doing random reads on id
创建一个db,并写入一些数据 ./db_bench --benchmarks="fillseq"但是这样并不会打印更多有效的元信息
DB path: [/tmp/rocksdbtest-1001/dbbench]
fillseq : 2.354 micros/op 424867 ops/sec; 47.0 MB/s
创建一个db,并打印一些元信息./db_bench --benchmarks="fillseq,stats"
--benchmarks表示测试的顺序,支持持续叠加。本次就是顺序写之后打印db的状态信息。
这样会打印db相关的stats信息,包括db的stat信息和compaction的stat信息
DB path: [/tmp/rocksdbtest-1001/dbbench]
# 测试顺序写的性能信息
fillseq : 2.311 micros/op 432751 ops/sec; 47.9 MB/s** Compaction Stats [default] **
Level Files Size Score Read(GB) Rn(GB) Rnp1(GB) Write(GB) Wnew(GB) Moved(GB) W-Amp Rd(MB/s) Wr(MB/s) Comp(sec) CompMergeCPU(sec) Comp(cnt) Avg(sec) KeyIn KeyDrop
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------L0 1/0 28.88 MB 0.2 0.0 0.0 0.0 0.0 0.0 0.0 1.0 0.0 60.6 0.48 0.31 1 0.477 0 0Sum 1/0 28.88 MB 0.0 0.0 0.0 0.0 0.0 0.0 0.0 1.0 0.0 60.6 0.48 0.31 1 0.477 0 0Int 0/0 0.00 KB 0.0 0.0 0.0 0.0 0.0 0.0 0.0 1.0 0.0 60.6 0.48 0.31 1 0.477 0 0** Compaction Stats [default] **
Priority Files Size Score Read(GB) Rn(GB) Rnp1(GB) Write(GB) Wnew(GB) Moved(GB) W-Amp Rd(MB/s) Wr(MB/s) Comp(sec) CompMergeCPU(sec) Comp(cnt) Avg(sec) KeyIn KeyDrop
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
High 0/0 0.00 KB 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 60.6 0.48 0.31 1 0.477 0 0
Uptime(secs): 2.3 total, 2.3 interval
Flush(GB): cumulative 0.028, interval 0.028
AddFile(GB): cumulative 0.000, interval 0.000
AddFile(Total Files): cumulative 0, interval 0
AddFile(L0 Files): cumulative 0, interval 0
AddFile(Keys): cumulative 0, interval 0
Cumulative compaction: 0.03 GB write, 12.34 MB/s write, 0.00 GB read, 0.00 MB/s read, 0.5 seconds
Interval compaction: 0.03 GB write, 12.50 MB/s write, 0.00 GB read, 0.00 MB/s read, 0.5 seconds
Stalls(count): 0 level0_slowdown, 0 level0_slowdown_with_compaction, 0 level0_numfiles, 0 level0_numfiles_with_compaction, 0 stop for pending_compaction_bytes, 0 slowdown for pending_compaction_bytes, 0 memtable_compaction, 0 memtable_slowdown, interval 0 total count** File Read Latency Histogram By Level [default] **** DB Stats **
Uptime(secs): 2.3 total, 2.3 interval
Cumulative writes: 1000K writes, 1000K keys, 1000K commit groups, 1.0 writes per commit group, ingest: 0.12 GB, 53.39 MB/s
Cumulative WAL: 1000K writes, 0 syncs, 1000000.00 writes per sync, written: 0.12 GB, 53.39 MB/s
Cumulative stall: 00:00:0.000 H:M:S, 0.0 percent
Interval writes: 1000K writes, 1000K keys, 1000K commit groups, 1.0 writes per commit group, ingest: 124.93 MB, 54.06 MB/s
Interval WAL: 1000K writes, 0 syncs, 1000000.00 writes per sync, written: 0.12 MB, 54.06 MB/s
Interval stall: 00:00:0.000 H:M:S, 0.0 percent
更多的meta operation操作如下
compact 对整个数据库进行合并
stats 打印db的状态信息
resetstats 重置db的状态信息
levelstats 打印每一层的文件个数以及每一层的占用的空间大小
sstables 打印sst文件的信息
对应的sstables和levelstats显示信息如下
--- level 0 --- version# 2 ---7:30286882[1 .. 448148]['00000000000000003030303030303030' \seq:1, type:1 .. '000000000006D6933030303030303030' seq:448148, type:1](0)
--- level 1 --- version# 2 ---
--- level 2 --- version# 2 ---
--- level 3 --- version# 2 ---
--- level 4 --- version# 2 ---
--- level 5 --- version# 2 ---
--- level 6 --- version# 2 ---Level Files Size(MB)
--------------------0 1 291 0 02 0 03 0 04 0 05 0 06 0 0
单独随机写测试相关的参数可以自己配置,这里仅仅列出一部分参数可以通过 ./db_bench --help自己查看想要的配置参数,当然配置前需要对各个参数有一定的了解。
./db_bench \
--benchmarks="fillrandom,stats,levelstats" \
--enable_write_thread_adaptive_yield=false \
--disable_auto_compactions=false \
--max_background_compactions=32 \
--max_background_flushes=4 \
--write_buffer_size=536870912 \
--min_write_buffer_number_to_merge=2 \
--max_write_buffer_number=6 \
--target_file_size_base=67108864 \
--max_bytes_for_level_base=536870912 \
--compression_type=none \ #关闭压缩
--num=500000000 \ #总共写入的请求个数,如果达不到则写30秒就停止
--duration=30 \ #持续IO的时间是30秒
--threads=1000\ #并发1000个线程
--value_size=8192\ #value size是8K
--key_size=16 \ #key size 16B
--enable_pipelined_write=true \
--db=./db_bench_test \ #指定创建db的目录
--wal_dir=./db_bench_test \ #指定创建wal的目录
--allow_concurrent_memtable_write=true \ #允许并发写memtable
--disable_wal=false \
--batch_size=1 \
--sync=false \ #是否开启sync
在这个workload下,每一次benchmark db_bench都会重新创建db,可能是遗留原因。而有的时候,我们想要在原有db之前追加一定条目的请求,并不希望之前的db被清理掉。可以这样简单更改一下db_bench的代码:我们使用fillrandom workload的时候,搭配use_existing_db=1 默认会退出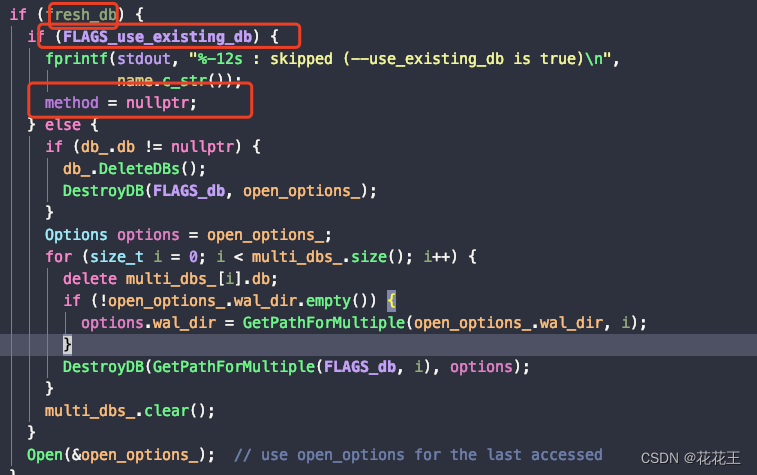
这个时候我们只需要将,fillrandom workload下的fresh_db 更改为false就可以继续测试了,每一次fillrandom都会在之前的基础上增加条目,而不会destory之前的db。

随机读
使用之前fillrandom创建的db,进行随机读取,需要开启use_existing_keys=1和use_existing_db=1,否则都会是not-found,被bloom-filter过滤,不会命中之前写入的数据。
./db_bench \
--benchmarks="fillseq,stats,readrandom,stats"
--enable_write_thread_adaptive_yield=false \
--disable_auto_compactions=false \
--max_background_compactions=32 \
--max_background_flushes=4 \
--write_buffer_size=536870912 \
--min_write_buffer_number_to_merge=2 \
--max_write_buffer_number=6 \
--target_file_size_base=67108864 \
--max_bytes_for_level_base=536870912 \
--use_existing_keys=1 \ #建议使用已存在key进行读,否则就一直被filter过滤掉,打不到磁盘,测试不精确
--use_existing_db=1 \
--cache_size=2147483648 \ #2G的block-cache,默认是8M,实际生产环境,如果read-heavy应该设置为内存大小的三分之一。
--num=500000000 \ #总共写入的请求个数,如果达不到则写30秒就停止
--duration=30 \ #持续IO的时间是30秒
--threads=1000 \ #并发1000个线程
--value_size=8192 \ #value size是8K
--key_size=16 \ #key size 16B
--enable_pipelined_write=true \
--db=./db_bench_test \ #指定创建db的目录
--wal_dir=./db_bench_test \ #指定创建wal的目录
--allow_concurrent_memtable_write=true \ #允许并发写memtable
--disable_wal=false \
-
如果要测试热点读,可以指定参数
--key_id_range=100000,表示生成的key的范围是在100000范围内,该测试需要在benchmark中增加timeseries -
读写混合readwhilewriting
9个线程读,一个线程写
./db_bench \
--benchmarks="readwhilewriting,stats"
--enable_write_thread_adaptive_yield=false \
--disable_auto_compactions=false \
--max_background_compactions=32 \
--max_background_flushes=4 \
--write_buffer_size=536870912 \
--min_write_buffer_number_to_merge=2 \
--max_write_buffer_number=6 \
--target_file_size_base=67108864 \
--max_bytes_for_level_base=536870912 \
--use_existing_keys=1 \ #建议使用已存在key进行读,否则就一直被filter过滤掉,打不到磁盘,测试不精确
--use_existing_db=1 \
--cache_size=2147483648 \ #2G的block-cache,默认是8M,实际生产环境,如果read-heavy应该设置为内存大小的三分之一。
--num=500000000 \ #总共写入的请求个数,如果达不到则写30秒就停止
--duration=30 \ #持续IO的时间是30秒
--threads=1000\ #并发1000个线程
--value_size=8192\ #value size是8K
--key_size=16 \ #key size 16B
--enable_pipelined_write=true \
--db=./db_bench_test \ #指定创建db的目录
--wal_dir=./db_bench_test \ #指定创建wal的目录
--allow_concurrent_memtable_write=true \ #允许并发写memtable
--disable_wal=false \
随机读随机写 ReadRandomWriteRandom随机读一个请求,随机写一个请求,可以指定读写比,readwritepercent;默认是90%的读,可以降低读的比例需要注意开启--use_existing_keys=1 和 --use_existing_db=1
./db_bench \
--benchmarks="readrandomwriterandom,stats"
--enable_write_thread_adaptive_yield=false \
--disable_auto_compactions=false \
--max_background_compactions=32 \
--max_background_flushes=4 \
--write_buffer_size=536870912 \
--min_write_buffer_number_to_merge=2 \
--max_write_buffer_number=6 \
--target_file_size_base=67108864 \
--max_bytes_for_level_base=536870912 \
--use_existing_keys=1 \ #建议使用已存在key进行读,否则就一直被filter过滤掉,打不到磁盘,测试不精确
--use_existing_db=1 \ #建议打开,使用已经存在的db
--cache_size=2147483648 \ #2G的block-cache,默认是8M,实际生产环境,如果read-heavy应该设置为内存大小的三分之一。
--readwritepercent=50 \ #指定读写比 1:1,一次随机读,对应一次随机写
--num=500000000 \ #总共写入的请求个数,如果达不到则写30秒就停止
--duration=30 \ #持续IO的时间是30秒
--threads=1000\ #并发1000个线程
--value_size=8192\ #value size是8K
--key_size=16 \ #key size 16B
--enable_pipelined_write=true \
--db=./db_bench_test \ #指定创建db的目录
--wal_dir=./db_bench_test \ #指定创建wal的目录
--allow_concurrent_memtable_write=true \ #允许并发写memtable
--disable_wal=false \
3. 便捷Benchmark.sh 自动匹配workload
ps: 需要注意的是benchmark.sh 中很多参数并不是默认的,而是官方给的一些适配当前benchmark workload 的系列优化之后的参数,所以如果大家想要测试自己的option,这个方法并不推荐,还是使用上面的db_bench方式来测试。
因为db_bench选项太多,而测试纬度很难做到统一(可能一个memtable大小的配置都会导致测试出来的写性能相关的的数据差异很大),所以官方给出了一个benchmark.sh脚本用来对各个workload进行测试。
该脚本能够将db_bench测试结果中的stats信息进行统计汇总打印(qps,),更放方便查看。
这个测试需要将编译好的db_bench二进制文件和./tools/benchmark.sh放到同一个目录下即可,测试项可以参考官方给出的workload,Performance Benchmarks
随机插入 bulkload,制造好数据集
这里的随机插入是指单纯的随机写,且禁掉自动compaction,将当前请求插入完成之后会再进行手动compaction
NUM_KEYS=900000000 NUM_THREADS=32 CACHE_SIZE=6442450944 benchmark.sh bulkload
总体来说这个随机插入结果相比于默认配置是偏高的,benchmark.sh中的脚本对memtable相关的配置如下: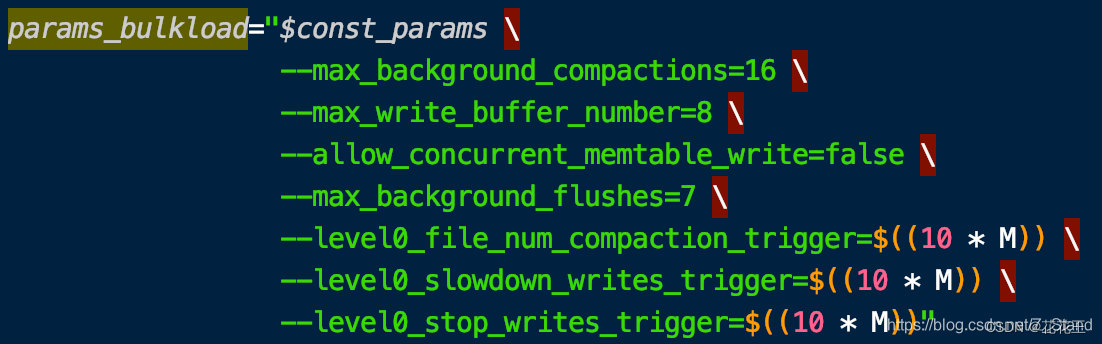
很明显性能肯定好于默认配置,好处是官方有一个在指定硬件之下的workload测试结果,可以进行对比参考。
随机写,覆盖写
在上一次已有的数据基础上进行测试,会覆盖写9亿条key
NUM_KEYS=900000000 NUM_THREADS=32 CACHE_SIZE=6442450944 DURATION=5400 benchmark.sh overwrite
读时写,9个线程读,一个线程写
这里的读是从已经存在的key中进行读
NUM_KEYS=900000000 NUM_THREADS=32 CACHE_SIZE=6442450944 DURATION=5400 benchmark.sh readwhilewriting
随机读
NUM_KEYS=900000000 NUM_THREADS=32 CACHE_SIZE=6442450944 DURATION=5400 benchmark.sh readrandom
4. 上限的benchmark及参数
欢迎大家补充各自的上限 workload 。
4.1 随机写
单进程 32个线程,32个db,各自的写吞吐会以秒计形态输出到一个report.csv。这里线程数 和 db数可以根据自己环境的cpu核心情况而定,基本不用担心write-stall问题。
./db_bench \--benchmarks=fillrandom,stats \--readwritepercent=90 \--num=3000000000 \--threads=32 \--db=./db \--wal_dir=./db \--duration=3600 \-report_interval_seconds=1 \--key_size=16 \--value_size=128 \--max_write_buffer_number=16 \-max_background_compactions=32 \-max_background_flushes=16 \-subcompactions=8 \-num_multi_db=32 \-compression_type=none
如果想要支持 direct_io 写,可以打开
--use_direct_io_for_flush_and_compaction=true,这个配置是在写sst时 也就是flush & compaction 生效。
如果想要测试 mmap 写,则可以打开
--mmap_write=true
4.2 完全随机读
随机读想要命中所有的key,需要打开 use_existing_db=1 和 use_existing_keys=1。
需要注意的是 use_existing_keys 开启之后不能直接读多db,只能读单个db,因为它会在真正执行读workload 之前从这一个db内scan 所有的key 到一个数组中,同时 配置的 --num 选项是失效的,这里会填充扫描上来的key的个数。
使用这个配置之后 worklaod 不会立即启动,会卡一会扫描完所有的key之后才真正开始随机读(读的过程是生成随机下标来进行访问)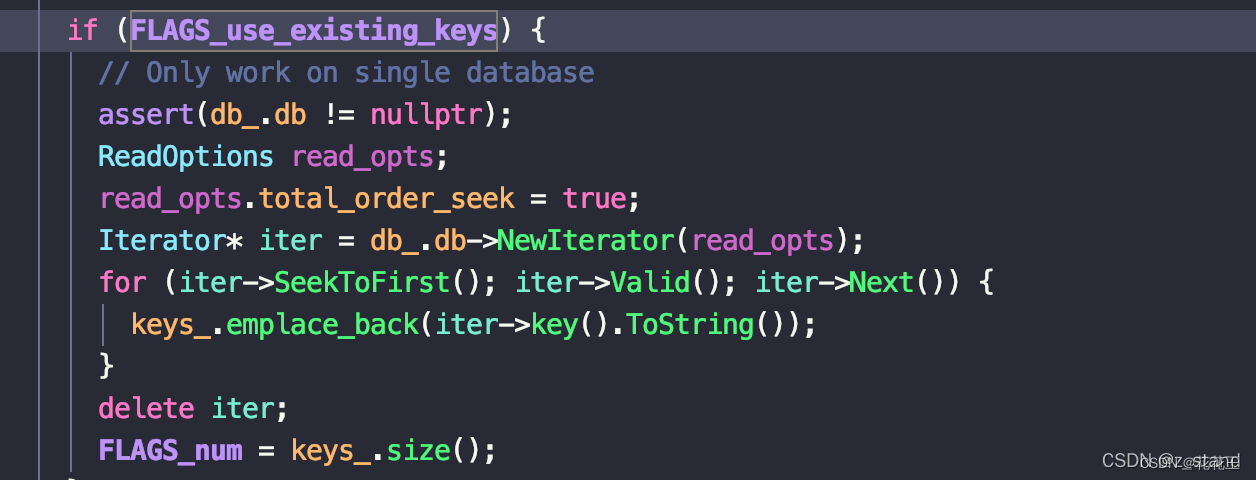
这个测试是使用默认大小的block_cache (8MB),以及 开启bloom filter,因为我们是use_existing_keys,那bloom filter基本没什么用。
$DB_BENCH \--benchmarks=readrandom,stats \--num=3000000000 \--threads=40 \--db=./db \--wal_dir=./db \--duration="$DURATION" \--statistics \-report_interval_seconds=1 \--key_size=16 \--value_size=128 \-use_existing_db=1 \-use_existing_keys=1 \-compression_type=none \
想要测试 direct 读,添加-use_direct_reads=true,那么读就不会用os pagecache了,这里可以搭配-cache_size=1073741824 以及其他block_cache的配置进行测试,来看rocksdb的block_cache 相比于os pagecache的收益。
想要测试 mmap 读,添加-mmap_read=true 即可。
4.3 热点读
这里基本是使用之前的配置,主要是增加一个数据倾斜的配置 read_random_exp_range,它会用来产生倾斜的随机下标。
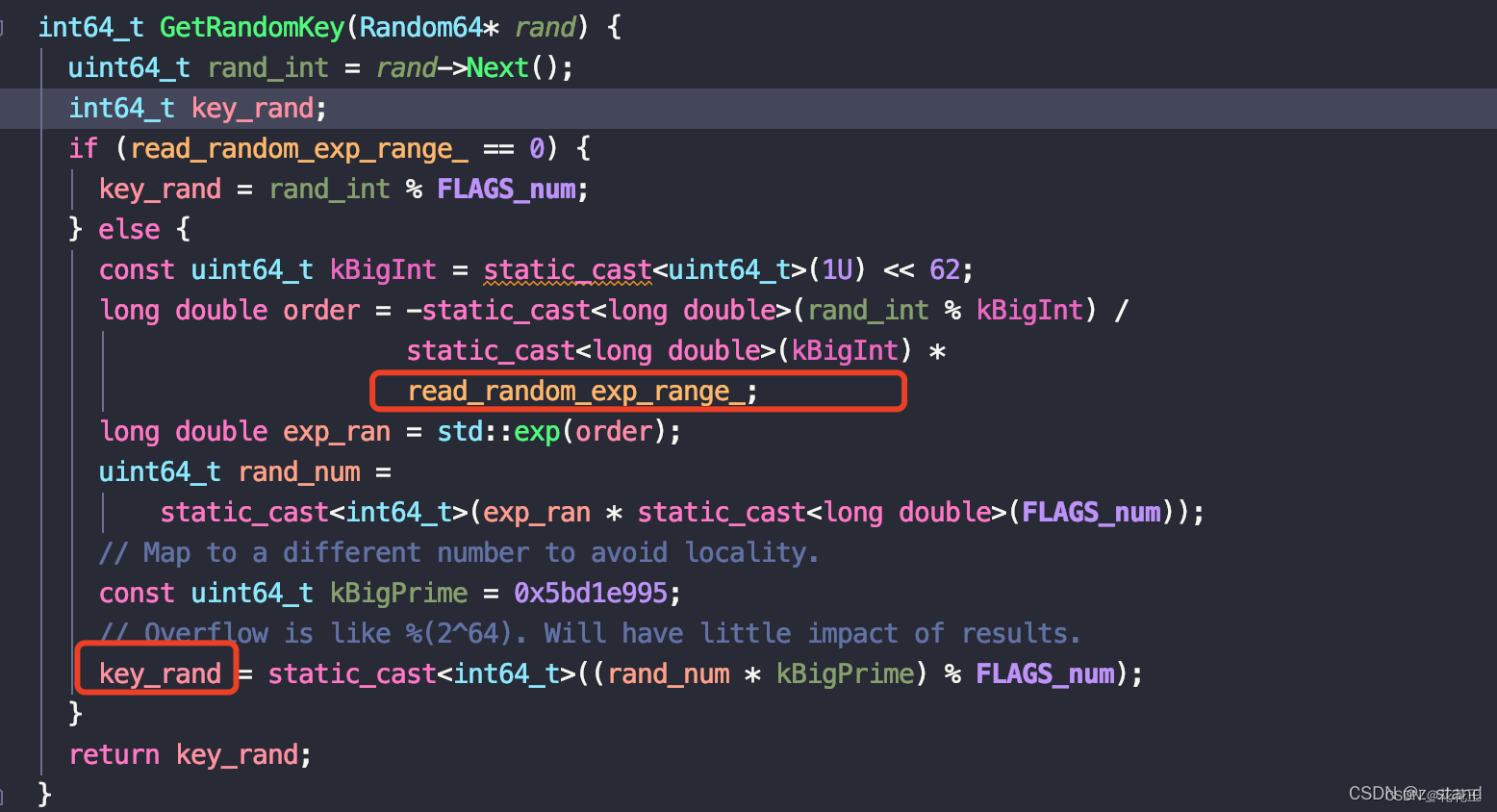
这个值越大,下标的倾斜越严重(可以理解为key-range 越小)。
$DB_BENCH \--benchmarks=readrandom,stats \--num=3000000000 \--threads=40 \--db=./db \--wal_dir=./db \--duration="$DURATION" \--statistics \-report_interval_seconds=1 \--key_size=16 \--value_size=128 \-use_existing_db=1 \-use_existing_keys=1 \-compression_type=none \-read_random_exp_range=0.8 \
以上所有的workload 最后的结果
可以通过 tail -f report.csv 查看 吞吐
secs_elapsed,interval_qps
1,3236083
2,2877314
3,2645623
4,2581939
5,2655481
6,2038635
7,2226018
8,2366941
...
后面可以通过python 绘图脚本系列简单记录进行曲线绘图。
二、rocksdb ldb工具使用
语法格式:
ldb --db=<full_path_to_db_directory> <command>
语法说明:
- 必须指定数据库的路径--db=<full_path_to_db_directory>
- 根据需要,选择需要执行的command
表1 ldb支持的command及其说明
| 命令 | 说明 |
|---|---|
| put <key> <value> [--ttl] | 写入数据到数据库。 |
| get <key> [--ttl] | 从内存memtable或磁盘中的sst文件中读取指定的key对应的值。 |
| batchput <key> <value> [<key> <value>] [..] [--ttl] | 将数据批量写入数据库。 |
| scan [--from] [--to] [--ttl] [--timestamp] [--max_keys=<N>q] [--start_time=<N>:- is inclusive] [--end_time=<N>:- is exclusive] [--no_value] | 扫描数据库中数据,也可以添加条件,指定扫描数据的范围,如key值范围、生命周期的时间等。 |
| delete <key> | 删除指定key的数据。 |
| deleterange <begin key> <end key> | 删除指定范围内的所有键值对。其中,<begin key>和<end key>分别表示要删除的键值对的起始键和结束键。 |
| query [--ttl] | 执行query命令,之后会开始一个EEPL shell,键入help,之后会显示出可用命令的列表,根据列表显示执行命令。 |
| approxsize [--from] [--to] | 该命令用于查询数据在磁盘上所占空间。由key值范围指定要查询的数据。 |
| checkconsistency | 该命令功能为一致性检测,检查文件系统中是否包含所有在生命周期内的文件,以及它们的文件大小与内存记录匹配。 |
| list_file_range_deletes [--max_keys=<N>] | 打印出在sst文件中要删除范围的最大值。 |
管理员命令:
表1 管理员命令及其说明
| 命令 | 说明 |
|---|---|
| dump_wal --walfile=<write_ahead_log_file_path> [--header] [--print_value] [--write_committed=true|false] | 转储wal文件。 |
| compact [--from] [--to] | compact操作范围设定,from参数和to参数的取值是数据库中已存在的key值。 |
| reduce_levels --new_levels=<New number of levels> [--print_old_levels] | 还原指定level。 |
| change_compaction_style --old_compaction_style=<Old compaction style: 0 for level compaction, 1 for universal compaction> --new_compaction_style=<New compaction style: 0 for level compaction, 1 for universal compaction> | 该命令是转换设定对应level层的compation的类型,参数由0和1两个数字代替两种compaction类型,分别是level compaction和universal compaction。 |
| dump [--from] [--to] [--ttl] [--max_keys=<N>] [--timestamp] [--count_only] [--count_delim=<char>] [--stats] [--bucket=<N>] [--start_time=<N>:- is inclusive] [--end_time=<N>:- is exclusive] [--path=<path_to_a_file>] | 该命令用于查询数据库中已存在的key/value类型的数据,将存储文件中的特殊存储格式的数据,转换成可以直接读取识别的数据并回显出来并带有各类控制参数。
|
| load [--create_if_missing] [--disable_wal] [--bulk_load] [--compact] | 该命令用于加载数据库,加载的方式有参数所示的几种方式。 |
| manifest_dump [--verbose] [--json] [--path=<path_to_manifest_file>] | 该命令用于manifest文件的转储。 |
| file_checksum_dump [--path=<path_to_manifest_file>] | 该命令是对数据库中sst文件进行校验和验证,并打印出每个sst文件的校验信息。 |
| list_column_families | 列出指定的数据库中存在的所有列族。 |
| create_column_family --db=<db_path> <new_column_family_name> | 在指定的数据库中添加新的列族。 |
| drop_column_family --db=<db_path> <column_family_name_to_drop> | 在指定的数据库中删除要求的列族。 |
| dump_live_files | 转储在生命周期内的文件。 |
| idump [--from] [--to] [--input_key_hex] [--max_keys=<N>] [--count_only] [--count_delim=<char>] [--stats] | 该命令也是查询数据库中的数据与上述的dump命令类似。但是回显的信息key/value数据更加详细,例如回显信息中增加了每个数据写入数据库中的实际先后次序信息。 |
| repair | 该命令是恢复最进删除的日志文件,例如MANIFEST文件和log文件。将恢复的日志文件放入数据库中的新生成的lost目录中。 |
| backup [--backup_env_uri] [--backup_dir] [--num_threads] [--stderr_log_level=<int (InfoLogLevel)>] | 数据库备份。 |
| restore [--backup_env_uri] [--backup_dir] [--num_threads] [--stderr_log_level=<int (InfoLogLevel)>] | 数据库恢复。 |
| checkpoint [--checkpoint_dir] | 设置检查点。 |
| write_extern_sst <output_sst_path> | 把数据写入指定位置的sst文件。 |
| ingest_extern_sst <input_sst_path> [--move_files] [--snapshot_consistency] [--allow_global_seqno] [--allow_blocking_flush] [--ingest_behind] [--write_global_seqno] | 导入外部sst文件。 |
字符串输入/输出格式参数
如表1所示可选参数控制keys/values是作为十六进制还是普通字符串输入/输出。
表1 字符串输入/输出格式参数及其说明
| 参数 | 说明 |
|---|---|
| --key_hex | keys以十六进制输入/输出。 |
| --value_hex | values以十六进制形式输入/输出。 |
| --hex | keys和values都以十六进制输入/输出。 |
数据库内部控制参数
如表1所示可选参数控制数据库内部。
表1 数据库内部控制参数及其说明
| 参数 | 说明 |
|---|---|
| --column_family=<string> | 该参数是指在列式数据库中,用于指定数据表中的列族。 default:默认列族(即默认表)。 --column_family=default |
| --ttl with 'put','get','scan','dump','query','batchput' | TTL是一种机制,用于在一定时间后自动删除数据,以避免数据过期或占用存储空间。 |
| --try_load_options | 读取数据库的配置文件并打开数据库。 |
| --disable_consistency_checks | 用于禁用一致性校验。 默认值为true。 |
| --ignore_unknown_options | 是否启用加载选项文件时忽略未知选项。 |
| --bloom_bits=<int,e.g.:14> | 每个key对应的bloom过滤器位数,RocksDB若启用bloom过滤器请设置该值(例如14,默认值为-1),若不启用bloom过滤器请设置为0。 |
| --fix_prefix_len=<int,e.g.:14> | 设置前缀bloom筛选器中的固定长度前缀的值,值为整型。 |
| --compression_type=<no|snappy|zlib|bzip2|lz4|lz4hc|xpress|zstd> | 该参数用于指定压缩类型。RocksDB默认的压缩方式是snappy。并且其各层之间的压缩方法无需一致。 |
| --compression_max_dict_bytes=<int,e.g.:16384> | 配置启动压缩库的字典上限,即达到字典上限后会启动压缩库。 |
| --block_size=<block_size_in_bytes> | 用于设置块大小。 块大小通常为4KB。由于更小的块大小会削减解压缩时的开销,块大小越小,随机读速度越快。但过小的块大小会导致压缩失效,因此推荐设置为1KB。 |
| --auto_compaction=<true|false> | 用于指定是否启用RocksDB的auto compaction功能。 |
| --db_write_buffer_size=<int,e.g.:16777216> | 设置所有column family的memtable的大小限制。 |
| --write_buffer_size=<int,e.g.:4194304> | 设置每个column family的memtable的大小。 默认值为64MB。 |
| --file_size=<int,e.g.:2097152> | 设置level层的sst文件大小,即设置配置选项options.target_file_size_base的值。RocksDB使用sst文件分层(level 0层到level N层)管理数据,level层sst文件的总和大小 = sst文件大小 * sst文件的个数。 |
例子:
put和batchput命令
前提条件
执行下列的各个命令之前,需要新建一个目标数据库或已存在数据库。创建数据库详情可参考步骤2。
操作步骤
- 进入目录“/home”。
cd /home
- 创建数据库存储目录。
mkdir –p /home/rocksdb/rkdb
- 使用ldb命令,创建数据库并使用put命令写入第一个数据。
ldb --db=/home/rocksdb/rkdb --create_if_missing put k1 v1

说明
如果ldb工具的操作的目标数据库不存在,出现“does not exist”报错提示,可以添加“--create_if_missing”参数,创建新的目标数据库。
- 使用ldb工具执行put命令添加数据。
ldb --db=/home/rocksdb/rkdb put k2 v2

- 使用ldb命令执行batchput命令,批量写入数据。
ldb --db=/home/rocksdb/rkdb batchput k3 v3 k4 v4 k5 555 kstring abcd

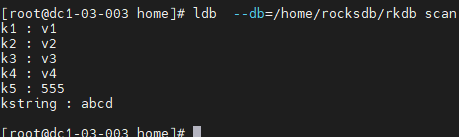
- 使用scan命令,查看写入数据库中的数据。
ldb --db=/home/rocksdb/rkdb scan
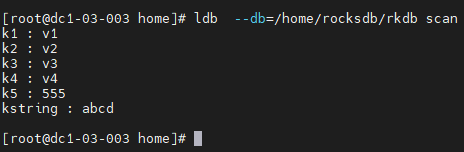
get和scan命令
前提条件
执行下列的各个命令之前,需要新建一个目标数据库或已存在数据库。创建数据库详情可参考步骤2。
操作步骤
- 进入“/home”目录。
cd /home
- 使用ldb工具执行get命令,查看指定key的values。
ldb --db=/home/rocksdb/rkdb get k5
ldb --db=/home/rocksdb/rkdb get k3
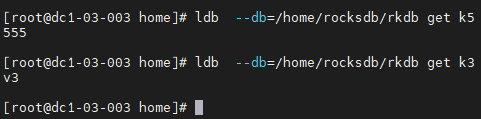
- 使用ldb工具执行scan命令,扫描数据库中的所有数据。
说明
下述命令是scan命令的最简形式,但数据库的数据量较大时,扫描所有数据并回显出来不合适,可以控制扫描数据的key值范围,有指向地扫描数据。控制参数参考ldb支持的command的scan命令说明。
ldb --db=/home/rocksdb/rkdb scan
delete和deleterange命令
前提条件
执行下列的各个命令之前,需要新建一个目标数据库或已存在数据库。创建数据库详情可参考步骤2。
操作步骤
- 进入“/home”目录。
cd /home
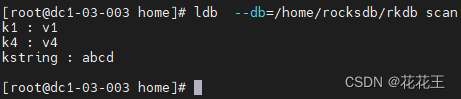
- 使用scan命令,查看数据库现有数据。
ldb --db=/home/rocksdb/rkdb scan
- 使用ldb工具执行delete命令,删除指定key的values。
ldb --db=/home/rocksdb/rkdb delete k5

- 执行get命令,查看k5的values。
ldb --db=/home/rocksdb/rkdb get k5

- 使用ldb工具执行deleterange命令,删除指定范围中key的values。
ldb --db=/home/rocksdb/rkdb deleterange k2 k4

- 查看范围删除后的结果。
ldb --db=/home/rocksdb/rkdb scan
三、验证sst_dump的参数
前提条件
执行下列的各个命令之前,需要新建一个目标数据库或已存在数据库。以下操作默认数据库已存在。
操作步骤
-
进入目录“/home”。
cd /home
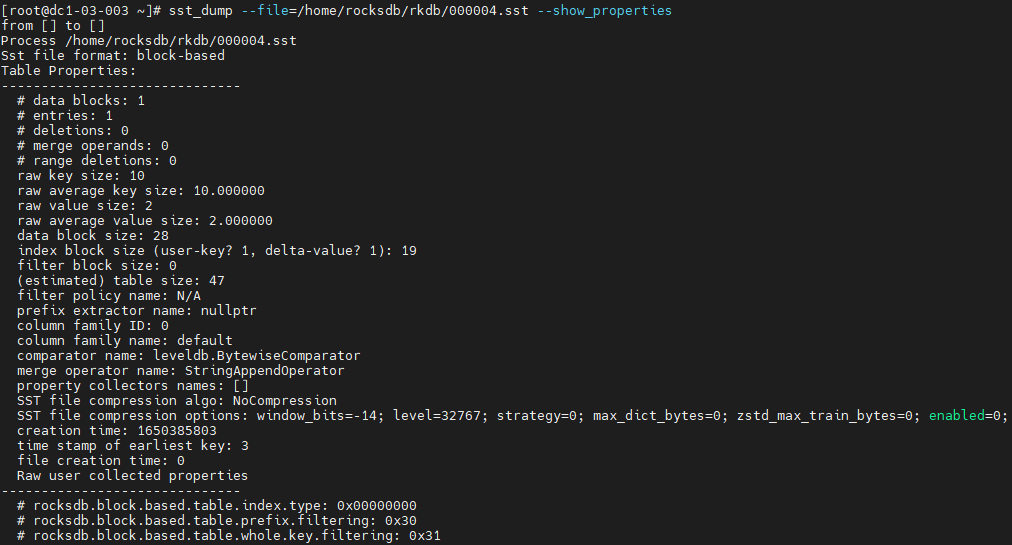
- 打印sst文件的属性。
sst_dump --file=/home/rocksdb/rkdb/000004.sst --show_properties