导读
大模型研发竞赛如火如荼,谷歌紧随OpenAI其后推出PalM2、Gemini等系列模型。Scaling Law是否仍然适用于当下的大模型发展?科技巨头与初创企业在竞争中各有哪些优势和劣势?模型研究者应秉持哪些社会责任?
2023智源大会「基础模型前沿技术」论坛邀请到谷歌研究科学家、T5模型作者周彦祺,她向智源社区介绍了她从事模型研发的前前后后,以及作为一线研究者,在大模型技术和商业路线上的心得体会。(本文仅代表个人观点)

周彦祺
谷歌研究科学家,曾参与T5等重要模型工作,曾在David Wentzlaff 指导下获得普林斯顿大学博士学位 (2011-2017),并曾于吴恩达带领下的百度SVAIL实验室担任研究科学家(2017-2019)。主要研究兴趣为计算机系统和机器学习,致力于通过稀疏性和自适应计算扩展大型语言模型,并与 ML 共同设计未来系统。
▲ 周彦祺是本次智源大会「基础模型前沿技术」论坛的特邀报告嘉宾,本次论坛将于6月9日下午举办,论坛主席为清华大学副教授刘知远,RoBERTa模型作者刘胤焓,紫东太初大模型作者、中科院自动化所刘静等将现场参加,扫描下方二维码,免费报名2023智源大会。

访谈&整理:李梦佳
突破摩尔定律终结的诅咒,从计算机系统转向ML
Q1:从上海交大,到密歇根大学,再到普林斯顿大学,介绍下您的求学经历?有哪些导师对您的影响最为深远?
A:我的本科是上交和密歇根大学联合培养的。上交的两年学习生活充实而愉快,而后两年密歇根的学习就可以称得上硬核。印象最深刻的是密歇根最后的两门毕业设计,EECS470 (computer architecture) 和427 (VLSI),每一门都是一周40小时的工作量,成果分别是用verilog写一个out-of-order的处理器和用cadence layout一个处理器。加上本科最后一年做了两门课的TA,还要做研究生申请的材料,我在密歇根可谓度过了人生最苦最累睡得最少的两年。之所以去普林斯顿读博,是本科导师Zhengya Zhang的建议:不要去不给你financial support的学校。没有拿到斯坦福的奖学金,所以去了东海岸的普林斯顿。
我的博士导师David Wentzlaff对我影响很大。David毕业于MIT,博士论文是关于分布式操作系统,博士期间还做出过第一个多核架构芯片(multi-core architecture processor)。后来,他作为创始团队的一员,和他的导师一起出去创业,创立了芯片公司Tilera(创立于2004年,位于硅谷的无晶圆半导体公司,该公司已经量产了TILE64 64核处理器)。他很聪明又敏锐,很多点子,实际工程能力又很强。我从他那里学到了很多东西,在他手把手的指导下,我独立完成了组里第一个C++ 的simulator,以及设计了第一款用于云计算的芯片架构。

读博是很艰苦,需要沉下心去想问题,从无到有地提出课题,并且想出来解决方案。有了点子还不够,还需要日复一日积少成多地把解决方案用代码的形式搭建出来。我个人的很多核心能力-比如写代码、提出课题、解决问题的能力,都是在读博时期积累起来的。跟随他的指引,我逐渐从一个很容易放弃的人,成长为一个任何事情都去寻求解决办法的人,小到程序里的bug,大到研究课题里遇到的一些瓶颈。我也从一个研究小白过渡到了一个可以自己解决问题的女汉子状态。
总结,David对我影响非常大,尤其是知识架构的搭建和工程经验上的积累。我的博士课题是关于云计算的计算机系统的设计,David推荐我学了很多计算机专业基础的课程,比如计算机网络、编译器、操作系统、算法理论,计算机理论, 这些基础学科对我博士毕业后的科研都影响深远,也极大程度地帮助我适应日后去做语言模型、AI相关的研究。
Q2:做AI,基础理论重要还是工程能力更重要?
A:这是一个好问题,都重要。我在谷歌的研究,聚焦于从根本上解决问题,比如attention架构,科学上来讲,要把计算复杂度做到线性,或者亚线性。这种属于CS的基础理论。
而仅仅知道解决问题的思路和方法还不够,真正解决问题还是需要依靠工程能力。如果你不会写代码,或者写的代码跑的慢或者消耗的内存太大,或者你压根不知道怎么处理几个terabyte的数据,那么做起AI研究可能就稍微比别人要慢一点,迭代起来也会觉得心有余而力不足。有了好的理论基础,如果真想把这个预期的结果跑出来,还需要搭配很强的工程能力,能够快速地迭代科研里的想法。所以理论和工程,一半一半,缺一不可。
Q3:你的科研方向经历过哪些转变?从百度到谷歌,研究方向和职业选择背后有什么原因?
A:从博士到百度的转变比较明显,所参与的会议也从计算机体系和系统相关的会议转变到了和机器学习、AI相关的会议。
因为博士期间专注于计算机系统方向的研究,这个方向原本是对标到谷歌云平台的团队,如果留在云平台团队,可能会去做一个软件工程师。但我本身兴趣广泛,和大语言模型一样,希望自己成为一个全能的人。博士整整5年的时间已经在钻研架构和操作系统,在相关方向顶会也颇有建树,所以更希望进一步拓展研究领域,AI显然是一个不错的选择。
当时百度正好在北美建了一个Silicon Valley AI Lab, 是由吴恩达(Andrew Ng)领头,招揽了一大批斯坦福伯克利的优秀人才做AI system,去构建一个用于DL的大规模分布式系统。这是一个比较特殊的机会,让我得以去做AI相关的科研,喜欢且向往的课题。这个机会是当时Meta,Google等不具备的。于是选择了百度。
到百度以及后来加入谷歌后,我经常参加的会议是ICML、NeurIPS。虽然machine learning for systems这些系统相关的会议我也会参加,但很大精力放在和ML、DL相关的方向上。这是最主要的转折点。
其实在我早期做架构和芯片的时候,当时大佬们已经广泛讨论且达成共识的一个问题,即end of Morse law,芯片与架构的进步空间有限。在2013年,我在MSR的导师Doug Burger就用end of Moore’s Law的这样的难题挑战我,说Intel这些公司已经没有免费的午餐(free lunch)了,不能再依靠的单纯的压缩晶体管的大小去拿到额外的性能了。当时我们提出的解决方案包含domain specific accelerators (也就是说在TPU还没有横空出世的时候我们已经在讨论了)。结合当时一个非常火的领域— 机器学习,我预感到未来很多的应用都会基于机器学习,如果能针对机器学习去做domain specific system, 应该能创造非常大的价值。如果要做这种domain specific system,必须要对这个领域有足够的了解。做一个机器学习的系统,就必须对机器学习有更深的了解。我关心的问题是,不管在算法层面,还是应用层面,ML的瓶颈,所遇到的问题以及未来在哪里?未来的模型会做到什么样的程度?这是我的科研心路历程。
T5模型最大贡献:encoder-decoder结构
Q4:选择模型这个方向,主要原因或兴趣点在于?
A:我们当时在百度的lab还比较领先,17年的时候已经做了一篇关于deep learning scaling的论文,理念就是从实证角度证明了power law,即“参数越多,模型性能更强”,linear scale的scaling,表明未来的系统能支持更高更强的运算,更多的记忆存储就能够有更好的准确性。因此从根本上驱动我们要去做大模型、大数据,因为从理论上证明了大模型可以有更好的准确性。
Q5:截止目前scaling law 依然适用吗?
A:这就涉及到,我现在的研究也集中在条件计算、混合专家这类与稀疏化相关的研究。
Google其实在两年前,像最早的BERT模型已经到500 billion parameter,到这个级别之后再扩展规模是非常难的了。每扩展一次模型的参数会翻番,从训练数据的成本上面来说是非常巨大的,训练时间也会随着模型参数的翻倍和训练数据的相应增加而增加好几倍。如果不是Google、Miscrosoft这种级别的公司很难支付得起模型容量不停地翻倍。
我们当时的感觉是说,做到几百个B参数的这个级别,已经做到头了,谷歌后来好几年也没有超过500个B参数的模型了。一个是训练上非常昂贵,第二个是我们没法去服务这么大的模型。从现实考量,我们不太能够负担运行 500个B左右模型的服务,并且仍然保持盈利。
所以我最近更集中的领域是说如何更有效地扩展这个模型。比如我们会用Conditional Computation,比如Mixture of Experts去做sparcity-activated 模型,然后把不同的输入放到不同的专家模型或者模块里面去。相比之下,密集模型需要根据输入激活所有的神经元,而条件计算模型只需要激活部分神经元。
从计算上来说更加高效,但从能耗和参数来说,是一样的capable,因为总参数不变。我更注重的是这种高效的扩展。
Q6:从T5到PaLM,技术路线的异同点是什么?
A:T5是一个「编码器-解码器」的模型。当时T5最大的贡献是统一了所有类型的NLP任务,把它形式化定义成一个「编码器-解码器」的问题(任何问题都可以)。比如说给定一个段落做总结,encoder做的事情是把这个paragraph给encode起来,生成一个嵌入,然后将嵌入输入到解码器当中,之后decoder 自回归地生成summarization。这是一个encoder-decoder的例子。
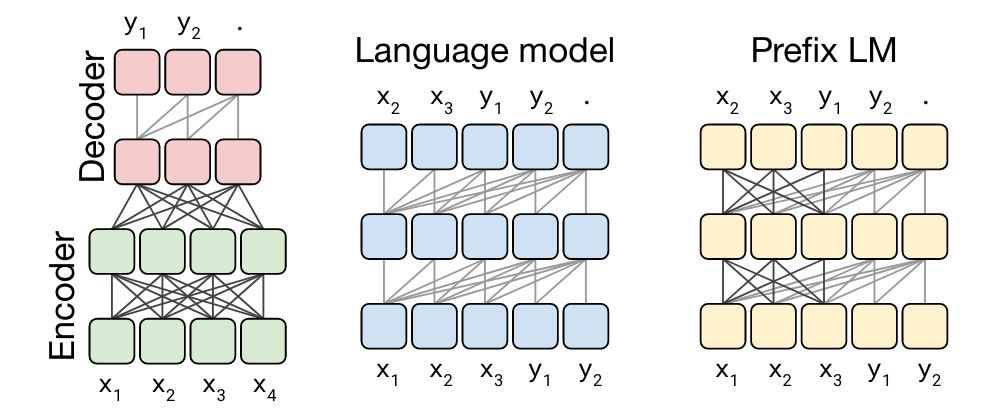
用户评价分类的任务,可以去判断用户review。比如将各种差评和好评encode起来,再输入decoder,去预测是好是坏。翻译任务也一样,将原始的语言,比如法语,encode成一个embedding,然后将嵌入输入到decoder当中,生成英语版本的语句序列(sentence sequence)。所有文本领域的问题都可以定义成一个encoder-decoder的问题。
BERT不同,BERT是encoder-only,它只能做一些总结和分类,做生成任务不行。因为encoder only,它没有自回归生成的那一步,所以T5基本上是第一个一统天下,encoder和decoder结合起来的一个模型。
为什么后来又发展到PalM、GPT这种decoder-only的模型,是因为「编码器-解码器」模型不能很好地处理通用型任务(比如问答或翻译类型任务)。针对通用型任务,就出现了GPT-2、GPT-3等这些最早做decoder only的模型。这些模型通过指令微调去做任何的task,任何的问题都可以转化成prompt去生成。我们在通用型任务中观察到很好的「放缩法则」,这就是为什么后来这些模型逐渐都转变为decoder-only的模型。(因为现在大家更在意通用型任务,因此decoder-only wins)
Q7:您目前的研究重点是?有参与PalM系列的工作吗?
A:我目前的研究重点在于如何高效地给大语言模型扩容,用conditional computation、mixture-of-experts这样的模型架构,并且探索如果高效地训练这样的大模型。我目前的研究重心可以理解为更前沿一点的方向。PaLM我也有一些参与。PaLM可以说是整个brain团队合作的结果。

Q:您个人来讲,T5是在谷歌比较重要的工作可以说是 T5 吗?
A:T5只是我的一个part time project,但我确实是T5最早几个成员之一。我个人之前主攻的方向是ML for system,用机器学习、强化学习去优化编译器和其他系统问题。比如在“Transferable Graph Optimizers for ML Compilers”(https://proceedings.neurips.cc/paper/2020/file/9f29450d2eb58feb555078bdefe28aa5-Paper.pdf) 里我们率先提出用结合graph neural network和transformer的模型做deep reinforcement learning, 去优化编译器里图形优化的问题。也做了一些automl的工作,比如我们提出了用automl去共同优化神经网络的模型结构和其运行硬件的结构 (https://proceedings.mlsys.org/paper/2022/file/31fefc0e570cb3860f2a6d4b38c6490d-Paper.pdf),基于这个工作,我们还落地了几个视觉模型到不同的产品里。最近专注大语言模型的scaling,比如要稀疏化(sparsify)模型,如何将模型做到万亿级别的参数,用尽量小的成本训练模型。包括我最新的论文,是关于MoE的算法优化和模型优化的。
Expert Choice Routing (https://arxiv.org/abs/2202.09368) 是我自己比较喜欢的一个工作,提出了一个简单的MoE routing的算法,取得完美的load balance并且近两倍的模型提速。还有最近的被接收的两篇ICML, Brainformers和Lifelong Language Pretraining with Distribution-Specialized Experts (https://arxiv.org/abs/2305.12281),是我们更前沿的关于MoE的研究。
Q8:谷歌未来会如何继续优化模型?
A:谷歌最近在训练一个新的Gemini(谷歌Project Gemini有望成为全球迄今为止最强大的AI模型https://www.tradesmax.com/component/k2/item/16016-gemini),CEO已经在今年的谷歌开发者大会上宣布,非常值得期待。我个人也推测未来会有非常多的api和产品基于这类的基础大模型(PaLM、Gemini)。我们Brain和deepmind的合并也预示着谷歌会集中力量办大事,在generative AI上持续发力。
总结来说,T5 最大的贡献就是 encoder-decoder 的结构,对后来的NLP大模型有很深远的影响。此外一个比较大的贡献是C4数据集(Colossal Clean Crawled Corpus,超大型干净的爬虫数据集),T5开源了模型和C4数据集,得以让外部的社区能够去使用谷歌生成的数据来训练他们的大语言模型,很多初始的科研都是由T5模型来驱动的。现在我们有新的基于decoder的模型,例如PaLM、Gemini。未来应该还会有更多更高效的基础模型被研发出来。
谷歌与OpenAI:从下至上,or自上而下
Q9:现在布局大模型风生水起,外界看来,谷歌和OpenAI在技术路线上有一定差异,内部如何看待呢?
A:风格不同,就是创业公司和大企业研究团队的差别。对于谷歌来讲,限制在于已有的商业模式和产品。我们的技术应该是补助已有的产品,从内部来讲很难做到颠覆原来的想法。在一个小的公司,却可以build from scratch,从0到1,有些谷歌需要考虑的限制问题,OpenAI就不需要考虑,因为只有成长到一定规模,实现盈利,才会出现很多包括数据在内的法律问题。
当然,现在OpenAI也面临很多社会影响的问题,有很多官司。但谷歌作为大公司,肯定会在比较早期就积极考虑这些问题,比如模型生成的不准确,会对社会产生的负面影响。以及语言模型训练成本的问题。简单说,我们自己挣钱养自己,这种模式和小公司拿投资人的钱养自己是两种思维。
好比Elon Musk去运营推特,拿自己的钱他一定会非常在意成本。假如我是一个创业者,想要推广一个非常新的技术,我是不关心要烧多少钱的,我在意的只有把技术做到极致,将这个产品从量的角度(DAU等)做到最好,而不是说想着如何节省成本。所以小公司和大公司里面做研发、做产品的基础理念是不一致的。
但从我个人角度,我不觉得有什么东西是OpenAI 本质上能够做成,谷歌做不成的,这只是一个早晚的问题。序幕拉开,谷歌方面认为,你是我的敌人,现在你有一点领先,那我要全力弯道超车,要投入更多的资源、人力,我觉得是谷歌可以做的。我们可以重新定义优先级,花更多的资源解除之前的很多限制,让这些产品能够尽快地上线。
正是因为OpenAI燃起了战火,所以才倒逼公司有这样的改变,我觉得对于谷歌来讲未尝不是一件好事。
Q:所以OpenAI发布了ChatGPT之后,谷歌内部才加速这种模型研发的紧张气氛?
A:肯定有,因为这(研发结果)直接反映出外界对公司的期望,反映出华尔街的期望。偶尔有一点风吹草动,公司的board member、CFO、CEO会非常紧张,他们会有一系列举措,去调整公司的资源结构,我明显感觉过去半年,公司内部大家处于一个非常紧张的状态。
Q10:OpenAI的领导层认为,之所以能做出爆款产品,工程能力是核心。其实谷歌也有很多资源和钱去做这件事,为什么OpenAI做成了呢?
A:还是方向的问题,从技术层面去说,我认为谷歌并没有说哪里落后,我们的研究团队正在做更前沿的东西,如何更高效地scale语言模型。从产品化上面,OpenAI最大的优势是他们的团队非常精炼,没有很多分散的投资和拖拖拉拉的团队参与,他们非常核心的团队,和自上而下的结构,带动决策。我听OpenAI的朋友都说,他们的CEO先做决策,给到首席科学家,首席科学家再将这种决策传达给下面的研究员,他们没有管理上的冗余,下面所有的研究员和工程师都要写代码,需要有很强的工程和实践功底,他们没有很冗杂多层的组织架构。目标明确,从上至下。
单凭这一点,和谷歌根本上很大差别,我们这边做研究可能更从下至上一点,大家思维更发散,项目更多,不集中。大家并没有说非要去做大语言模型,大语言模型也不是公司唯一需要的东西。
我们还有很多分散的并且更前沿的研究方向(比如计算机视觉、新的计算机语言、新的芯片、量子计算),所以在比如LLM这样集中的方向上可能不太有大力出奇迹的现象。但是在外部力量的这种推动下,OpenAI出现了非常爆款的产品,聚集了大量用户,他们自己声称要取代谷歌搜索,这对于我们来说就是个非常大的信号。于是我们想是不是要集中精力搞一搞LLM,至少拿出几个相应的产品与之抗衡。自从半年前,ChatGPT出现后,我们开始明确目标要把LLM的产品做好,要把这个产品放到谷歌所有的产品里面去。这是由外部推动产生的一系列变化。
Q11:Google brain和DeepMind合并以后会觉得项目更集中吗?合并后有什么变化?
A:现在仍是一个不确定的状态,未来3到6个月之后会有内部更细节的重组方案,谷歌大脑和DeepMind去更细节地讨论,项目reprioritize、合并、职务变动等细节,可能会在未来3到6个月内发生。因为整个谷歌大脑的目标都是去做generative AI,并将generative AI更好地deploy到谷歌的产品当中,可以说目标现在更明确了。
Q:您目前在谷歌大脑团队具体的职责,以及团队最新的研究方向是什么?
A:我的职位是staff research scientist,需要去定义新的研究方向和搭建自己的研究团队。找合作伙伴和争取计算资源是我一直需要做的事情。从团队研究方向上来看,我们最近发了一些ICML的文章,都是关于混合专家模型的。我从去年开始就已经在专攻混合专家模型,其实我并不是很信奉微调。我更从本质上关心的是让模型高效扩展,然后最终让这个语言模型在谷歌的体量上去更加经济地提供服务。
根据我之前对摩尔定律的理解,我觉得之前OpenAI CEO Sam的观点—万物摩尔定律有些过度乐观,很多事情都是有一个物理极限的,比如在晶体管(transistor)领域,到了原子级别就不可能再扩展,再往下会突破物理极限。在LLM上,scaling law是受限于投入的资金和算力。
所以我最近的研究都放在帮助大语言模型突破end of moore’s law的诅咒:如何在已有的计算能力下面,更有效扩展模型。我们最新的ICML的文章,都是关于MoE。
OpenAI GPT4也用了MoE, 他们有trillion级的参数,外界猜测的GPT4大概是100B16E (100 billon parameters per expert,16 experts) 这样的架构。自从知道OpenAI是MoE的模型之后,我们更加坚信了在MoE方向上的投入是正确的。去年我和我的合作者,包括杜楠、黄彦平、雷涛都做了很多关于MoE的基础模型的研究。
我的两篇ICML的paper,一个是关于做更好的模型架构,去做低秩和多专家的架构。
第二个 paper 是关于终生学习MoE。假设说我有一个数据流,而且不断有新的数据生成(coding数据,书和音乐的数据等等)。拿OpenAI ChatGPT为例,他们的训练数据截止到2021年,如果需要更新数据,很可能需要重新训练,效率很低。直接用新数据微调,难以避免会有过度拟合和catastropic forgetting的问题。而终生学习强调的是持续学习的能力。所以我的第二篇ICML paper说的是做基于MoE 架构的终生持续学习,可以不断地将模型adapt到不同的训练数据上面。
举个例子,比如原来的T5模型,训练数据可能是C4 数据集,过两年新的数据增加,我只需要增加一小部分experts,在新增加的expert上面,针对新增加的数据再去做第二轮的训练。这样的方法让模型训练更加scalable。
Q:你的思路和模型涌现(emergent abilities)应该是两种路线?
A:我觉得我做的课题和模型涌现是orthogonal的。模型涌现(emergent abilities),参数达到一定程度之后,模型可以解决一些原来不能解决的问题,新的能力就出现了。它提出了一种假设和解释了一种现象。可能我做的事情是在想办法如何更经济地实现模型涌现。
模型涌现体现的是模型的能力,但是模型的能力最终需要通过训练数据和训练时长来激发。我的研究解决的正是如何高效地激发模型的能力。我们知道数据的积累是一个连续的过程,同样训练大模型就需要用数据流去持续地激发模型的新能力。MoE的架构赋予了持续学习这个能力。如果用最原始的方法,直接微调模型,会有一个灾难性遗忘的问题,新的数据一来,再在原有的参数上面去做一个迭代,你的模型就会把之前的数据给覆盖掉。MoE的架构及大地缓解了这个问题。
举个具体的例子,我们的大模型都是先用文本数据去做预训练,这样模型具备了一些基本的语言能力和回答通用问题的能力。后来第二轮加入一堆对话的数据(像ChatGPT这样的数据),去做一轮微调,会发现对话的能力变得非常强,但是微调减弱了回答通用问题的能力。
模型,很自然地会有遗忘的问题,就相当于人,学了新的技能,勤加练习,却把旧的技能给生疏了。所以我们做这个基于MoE架构的终生学习,解决的就是遗忘的问题。一旦有新的数据,我们可以去增加模型里的专家数目,重点训练新增的参数,而不是需要重新训练或者重写这个模型。
Q12:关于团队搭建,谷歌团队内部是如何实现高效管理的?
A:我们在谷歌大脑的架构是一个比较精简的结构,没有过多的级别上的冗余。我们的director下面管理若干个研究科学家和工程师。整个谷歌大脑大概有个位数的高级总监。这些高级总监再去汇报给VP。我们每个人都有直接对话VP和Jeff的机会。
职责上没有特别强的界限划分,研究科学家也需要干工程,软件工程师也需要做研究。但对于研究科学家,需要对研究社区有贡献,或者说有创建一个新的研究领域的要求。
Q:团队之间如何去实现高效的协作?
A:非常从下至上,以项目为中心。基本上谁提出一个新课题,他可以去为了项目找上级拨资源。得到资源,就可以组建团队开始项目了。也有很多跨团队合作,我和其他组的同学都有很密切的合作,团队间没有很大的边界,自由度比较高。
Q:假如说你有一个idea,可以直接汇报给Jeff Dean吗?
A:当然是遇到比较大的事情才会去找他说。比如最近我们想要重新回归MoE,想要资源,我们会直接跟他拉个会说这个事情。
Q13:今年大会,作为一线研究者,在学术交流上您有什么样的诉求?
既然现在的趋势是,LLM基础模型会统领一切。我的问题是,如何让所有的产品基于LLM变得更加profitable。我们知道训练LLM大模型是非常昂贵的一件事,不是所有公司都可以做这件事。所有的公司都可以做finetuning,但做出类似GPT-4的万亿级别模型,才能在模型性能上面立于不败之地。
OpenAI现在有点close AI,他们总是对外界声称他们的模型10倍高效,但实际上又没有任何的recipe,告诉外界社区,通过什么让我的模型10倍高效。作为一个有责任感的公司,应该去宣扬共享的文化,不应该是宣扬一种纯粹的竞争,而是应该要把insight分享给社区里面的人,共同搭建更好的商业经济环境,给社会创造价值。
我们应有责任感去推进技术,但现在close AI并不是很好的办法。对于谷歌和OpenAI来说,都有责任更好地公开技术,让更多人能够在你的技术上去迭代,让技术从经济角度更服务大众,让大众受益。
而不是说把它做成一个secret recipe,凸显公司的优势,拿到高额投资,这不符合一个负责任的公司应该去追求的目标。现在 AI 已经发展到一个资本吹泡泡的阶段了。很难辨别,哪些是吹泡泡的部分,哪些是真正能够服务社会的。
Q:您完全支持开源开放?
A:软件的飞速发展得益于开源,OpenAI自己的发展,甚至任何一家科技公司之所以这么繁荣,都是归功于开源社区,如果没有开源就没有这么快的发展,如果当年谷歌如果没有开源transformer,其他公司也不能快速迭代出更好、更先进的方法。百花齐放的状态正是开源社区带来的现象。当然硬件方面的反例是,闭源会导致英伟达等玩家的一家独大。
为什么现在谷歌和OpenAI会变成敌对的状态,难道大家现在都去闭源吗?这对社会并不是很有益。
Q14:在模型安全伦理方向上您有什么关心的议题吗?
众所周知,Autoregressive model会出错,每一个 token都有一定出错的概率,累积起来去生成的几千、几万个 token 的回答当中肯定是容错率是非常高的。专业人士比较容易能够鉴别模型是否在说大话在说瞎话,通过google search等工具去验证生成内容的准确性。当如果是网络上受教育程度比较低的群众,看到模型生成的错误信息,大家无法甄别真伪。对普通用户来讲潜在危害性很大。
这是谷歌在过去好几年一直这么谨慎和保守的原因,因为谷歌是一个以 information retrieval起家的公司,所以它对信息准确性的阈值很高,在发布LLM的时候会更加谨慎,受到的监管也更多,关注它的眼睛会更多,所以难免会有一些限制。
个人生活
Q15:作为女性科学家,在这样的大公司技术团队中,女性还是相对较少,在这方面,您如何看待女性在科技领域的角色?
首先,我自己肯定相信女性在科技领域是中流砥柱的。越来越多的科技圈CEO和高管都是女性。女性在人文关怀和共情能力上有着天然的优势。之所以技术团队里多数成员是男性,我觉得是多方面的原因。第一是兴趣,社会上面刻板印象太多,可能本身来说对工程、对CS感兴趣的女性就不是特别多。从身边环境来看,和自己过去的同学去交流,女生大体上还是偏向喜欢人文社科类的方向居多。有些女孩子也有从众心理,如果自己的女生朋友都选择了文科专业, 可能自己也会倾向于选择文科专业。第二是社会和家庭氛围,国内确实stereotype更严重,会倾向于认为男生比女生工科强,女生学文科比较稳妥。而我个人的经历恰恰相反,我父母都是学文科出身,他们都很崇拜学理工科的人,因为上一辈的理念都是说「学好数理化走遍天下都不怕」。

我父亲从小一直强调培养我理科的能力,他希望我数学好工科好,然后顺便能上个清华就更美了。实话说我学理科确实也挺轻松的,又带着父母的期待,何乐而不为。无奈高考被语文连累,与清华失之交臂,转而在上交结缘计算机工程,进而开始钻研计算机系统,再到人工智能的方向。
Q16:您除了科研,日程安排是什么样?
我每天白天主要在开会,大量时间和同事沟通,和我的合作者讨论,写代码或看论文的时间比较少,只能业余时间利用晚上或周末的时间去做一些coding,以及科研。早期我在刚进 Google 的时候可能自己亲自动手coding会比较多,但是到现在,更多的是需要我去沟通,想新的课题,并招募更多的人帮你实现这个想法。
我自己很愿意花一课余的时间去读论文,读点state of the arts 的东西。周末我喜欢运动,和朋友滑雪、打羽毛球,也会唱ktv、去城里觅食,过的就是普通人的生活。

Q17:两句话可以寄予一下今年的智源大会,期望得到什么样的交流成果?
我希望能够尽我的能力,用过去在AI研究方面的经验,去将LLM的能力和局限性去和大家做一个很好的交流。并且这是一个关键的学习和交流的机会,向学术圈和工业圈的专家学习,看看他们的想法和最新进展,也可以激发我的创造。此外,我认为确实有必要把LLM的局限性进行完善,很多问题亟待解决。在产品化、工业化的进程中,我作为一线研究者有责任去让大家认识到它的不完美和局限性,避免负面的社会影响。
推荐阅读
MIT教授Tegmark:GPT-4敲响警钟,百年后人类何去何从丨智源大会嘉宾风采
40岁高中老师开源的数据集LAION,改变了生成式AI的未来丨智源大会嘉宾风采
人大李崇轩:我的生成模型修炼之路丨智源大会嘉宾风采