Python如何绕过检测封号的技巧
Python作为目前最受欢迎的编程语言之一,广泛应用于各种领域。在SEO领域中,Python也发挥着重要的作用,但是在不当的使用下,可能会被搜索引擎检测到并封号。在本文中,我们将介绍几种Python绕过检测封号的技巧,并总结结论。
1. 使用代理IP
使用代理IP是最常见的绕过检测封号的方法之一。在Python中,我们可以使用requests库来设置代理IP。具体实现方式如下:
import requestsproxies = {"http": "http://your_proxy_ip:your_proxy_port","https": "http://your_proxy_ip:your_proxy_port",
}url = "http://www.example.com"
response = requests.get(url, proxies=proxies)
需要注意的是,代理IP也可能被搜索引擎检测和封禁,因此建议使用高质量的代理服务,并定期更换IP。
2. 使用随机User-Agent
搜索引擎通常会通过User-Agent来判断请求是否来自真实的用户。因此,我们可以通过随机生成User-Agent来绕过检测封号。具体实现方式如下:
import random
import requestsuser_agents = ["Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36","Mozilla/5.0 (Windows NT 6.1; WOW64; rv:54.0) Gecko/20100101 Firefox/54.0","Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; AS; rv:11.0) like Gecko",
]url = "http://www.example.com"
headers = {"User-Agent": random.choice(user_agents)
}
response = requests.get(url, headers=headers)
需要注意的是,我们应该使用真实的浏览器User-Agent,而不是虚假的User-Agent,否则可能会被搜索引擎直接识别为爬虫。
3. 设置请求延迟时间
连续发送请求通常是爬虫被搜索引擎检测封禁的原因之一。因此,我们可以通过设置请求延迟时间来模仿真实用户的操作行为,从而绕过检测封号。具体实现方式如下:
import random
import requests
import timeurl = "http://www.example.com"
delay_time = random.randint(1, 5)
response = requests.get(url)
time.sleep(delay_time)
需要注意的是,请求延迟时间应该设置在1-5秒之间,避免被判定为恶意行为。
结论
以上是几种Python绕过检测封号的技巧,但是以上方法不能保证100%成功。为了更好的SEO效果,请尽量避免被搜索引擎封号。同时,我们也应该遵守搜索引擎的规则,以更加健康的方式进行SEO优化。
最后的最后
本文由chatgpt生成,文章没有在chatgpt生成的基础上进行任何的修改。以上只是chatgpt能力的冰山一角。作为通用的Aigc大模型,只是展现它原本的实力。
对于颠覆工作方式的ChatGPT,应该选择拥抱而不是抗拒,未来属于“会用”AI的人。
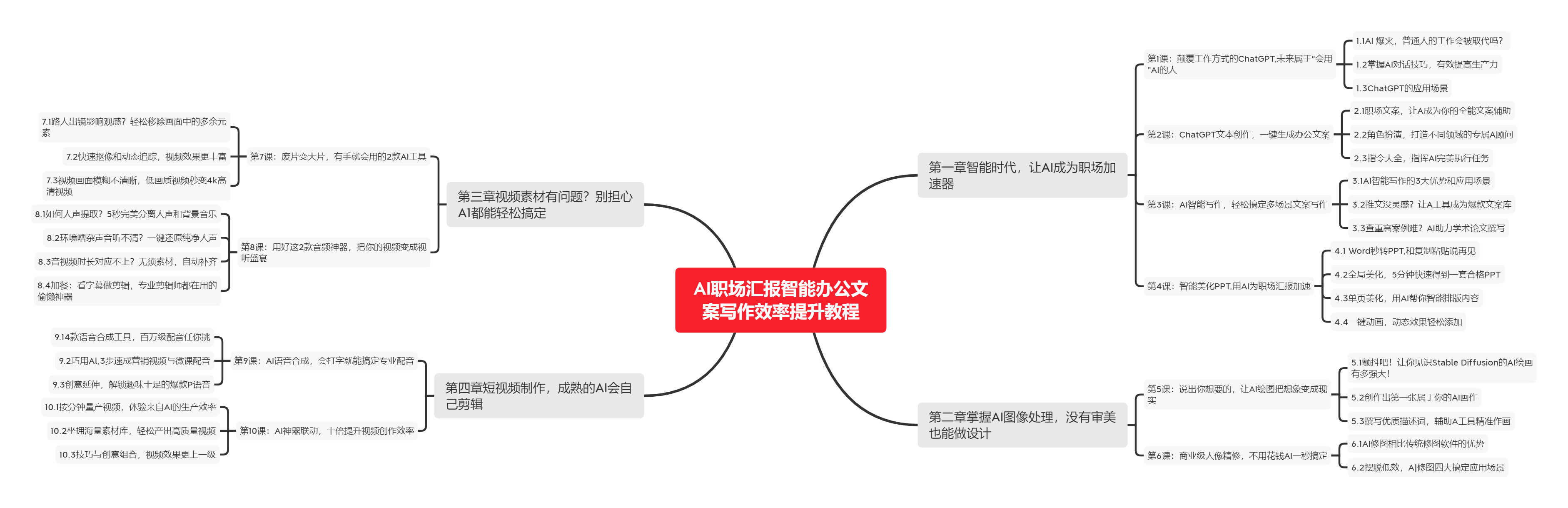
🧡AI职场汇报智能办公文案写作效率提升教程 🧡 专注于AI+职场+办公方向。
下图是课程的整体大纲

下图是AI职场汇报智能办公文案写作效率提升教程中用到的ai工具

🚀 优质教程分享 🚀
- 🎄可以学习更多的关于人工只能/Python的相关内容哦!直接点击下面颜色字体就可以跳转啦!
| 学习路线指引(点击解锁) | 知识定位 | 人群定位 |
|---|---|---|
| 🧡 AI职场汇报智能办公文案写作效率提升教程 🧡 | 进阶级 | 本课程是AI+职场+办公的完美结合,通过ChatGPT文本创作,一键生成办公文案,结合AI智能写作,轻松搞定多场景文案写作。智能美化PPT,用AI为职场汇报加速。AI神器联动,十倍提升视频创作效率 |
| 💛Python量化交易实战 💛 | 入门级 | 手把手带你打造一个易扩展、更安全、效率更高的量化交易系统 |
| 🧡 Python实战微信订餐小程序 🧡 | 进阶级 | 本课程是python flask+微信小程序的完美结合,从项目搭建到腾讯云部署上线,打造一个全栈订餐系统。 |