目录
分布式和集群的概念:
hadoop架构的三大组件:Hdfs,MapReduce,Yarn
1.hdfs 分布式文件存储系统 Hadoop Distributed File System
2.MapReduce 分布式计算框架
3.Yarn 资源调度管理框架
三个组件的依赖关系是:
hive数据仓库处理工具
hive的大体流程:
Apache hive的两大组件:
任务:
1.确认hadoop,hive环境搭建完成
2.确认能使用hadoop,hive启动服务的命令,datagrip连接hive服务操作
3.背诵/流畅表达 hadoop的架构,各组件之间的关系
4.说明hive的流程,元数据的概念
分布式和集群的概念:
分布式:将一个大任务分解成多个不同的子任务,由每个服务器来工作单独1个子任务,
并且每台服务器都缺一不可,如果某台服务器故障,则网站部分功能缺失,或导致整体无法运行。存在的主要作用是大幅度的提高效率,缓解服务器的访问和存储压力。
集群:将几台服务器集中在一起,运行同一个任务.每台服务器并不是缺一不可,存在的作用主要是缓解并发压力和单点故障转移问题,当一个服务器宕机后,另一个服务器可以直接衔接工作。分布式是以缩短单个任务的执行时间来提升效率的,而集群则是通过提高单位时间内执行的任务数来提升效率。
分布式存储:一台计算机无法进行存储,则由多台计算机来存储
分布式计算:一台计算机的性能无法达到计算的要求,则用多台计算机来进行计算
hadoop架构的三大组件:Hdfs,MapReduce,Yarn
1.hdfs 分布式文件存储系统 Hadoop Distributed File System解决大数据的海量存储问题
HDFS 由三个组件构成:NameNode(NN)、DataNode(DN)、SecondaryNameNode(SNN),他们的职责分别是
1.由namenode作为主节点,为从节点分配存储任务以及管理,NameNode是HDFS的核心,集群的主角色,被称为Master。
2.Secondary NameNode(次要名称节点)是一个辅助节点,它的作用是帮助主要的NameNode 执行一些重要的管理任务,以提高HDFS的可靠性和性能。当发生故障时,例如NameNode宕机或数据损坏,HDFS需要恢复到故障发生前的状态。这时,Secondary NameNode就发挥作用了,但只能恢复部分。
3.datanode作为从节点,进行数据的存储,DataNode负责将实际数据存储在HDFS中。是集群的从角色,被称为Slave。
2.MapReduce 分布式计算框架
'分散,汇总'模式的分布式计算框架,解决海量数据计算
MapReduce的核心思想: 分而治之,map负责分解,reduce负责合并,将任务分解成若干个map任务和reduce任务当启动一个 MapReduce 任务时,Map 端会读取 HDFS 上的数据,将数据映射成所需要的键值对类型并传到 Reduce 端。Reduce 端接收 Map 端传过来的键值对类型的数据,根据不同键进行分组,对每一组键相同的数据进行处理,得到新的键值对并输出到 HDFS,这就是 MapReduce 的核心思想。
3.Yarn 资源调度管理框架MapReduce是基于yarn运行的,没有yarn一般就无法运行MapReduce程序
资源调度的作用:对于资源的利用,有规划,有管理的调度资源使用,是效率最高的方式
对程序进行资源调度的重要性:服务器会运行多个程序,每个程序对资源的使用都不同,
程序没有节省的概念,有多少就会用多少,所以为了提高资源利用率,调度是必须的
YARN主要有RM和NM等组件组成,他们的职责分别是:
ResourceManager: 接收用户的计算请求任务,
监控NodeManager,
资源分配和调度
NodeManager: 负责执行主节点分配的任务(给MR的计算程序提供资源),管理单个节点上的资源,
处理来自ResourceManager的命令
三个组件的依赖关系是:
MapReduce的计算所用的数据,是来自于HDFS中存储的数据
MapReduce 的计算所用的资源,是来自于YARN所调度分配的
hive数据仓库处理工具
hive是基于hadoop的数据仓库工具,可以对于存储在hadoop文件中的数据集进行数据整理,特殊查询和分析处理
Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类 SQL 查询功能。Hive的本质:将SQL语句转化成MapReduce程序
Hive处理的数据存储在HDFS Hive分析数据底层实现的是MR 执行程序运行在Yarn上
MapReduce支持程序开发,但不支持SQL开发.
在大数据中使用SQL语言是最方便的,但MapReduce又不支持sql,所以有了Apache Hive这样的分布式SQL计算工具,可以将sql语句翻译成MapReduce程序运行
什么是分布式SQL计算?
以分布式的形式,执行SQL语句,进行数据统计分析
hive的大体流程:
流程表达1:用户编写sql语句 --- hive进行翻译.解析.优化.--- 语句底层在MapReduce运行--得到结果
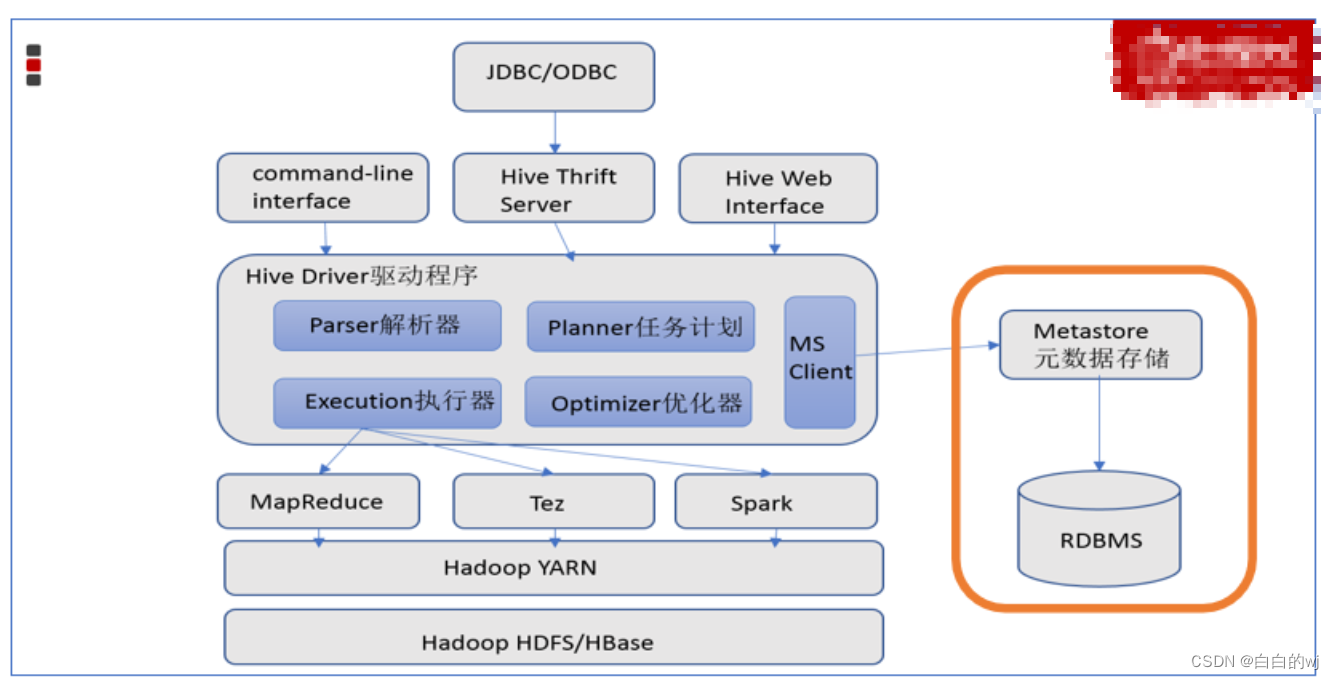
流程表达2:Hive通过用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的Driver,结合元数据(Metastore),将这些指令翻译成MR,提交到Hadoop中执行,最后,将执行返回的结果输出到用户交互接口。
问题:那么不用hive来翻译,直接写MapReduce语句来处理大数据可以吗?
回答:可以,但需要掌握java,python等编程语言,成本太大
使用hive的好处:操作接口采用类SQL语法,提供快速开发的能力(简单,容易上手)
底层执行Mapreduce,可以完成分布式海量数据的sql处理.

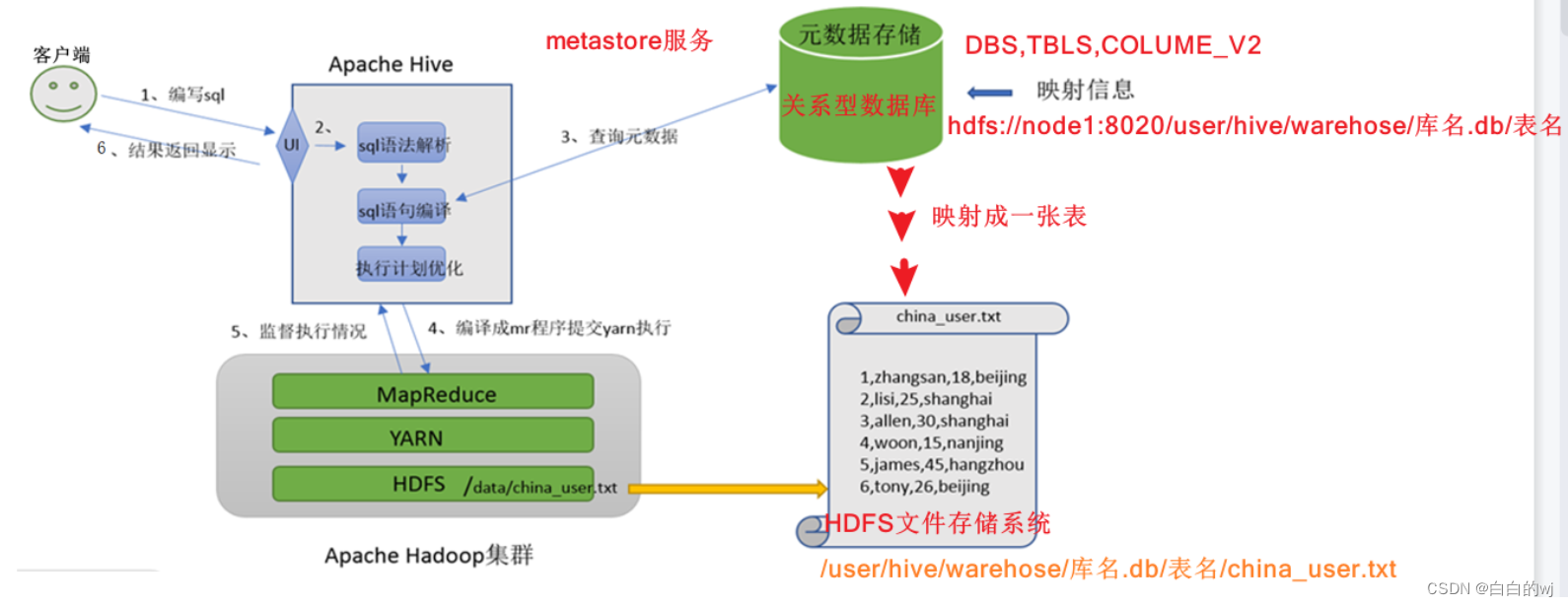
元数据概念:为了描述数据而存在的数据
SQL语句翻译成分布式的MapReduce中需要拥有两个核心功能,也是
Apache hive的两大组件:
1.元数据管理:数据的位置,数据的结构:等对数据的描述(比如为什么beijing在city这一列),帮助记录各类元数据
2.SQL解析器:实现SQL语句的分析,底层优化,到MR程序的转换,提交mr程序运行并收集执行结果






![[LeetCode]-225. 用队列实现栈-232. 用栈实现队列](https://img-blog.csdnimg.cn/6fe972f020854c14b111f172f0196d4e.png)