【操作系统内核】线程
为什么需要线程
比如我要做一个视频播放器,就需要实现三个功能:
① 从磁盘读取视频数据
② 对读取到的视频数据进行解码
③ 对解码的数据进行播放
- 如果串行执行(通过一个进程来执行):

那么播放一会就需要等待数据从磁盘加载(读磁盘很慢,会使得这个进程阻塞,CPU空置),然后通过CPU解码,就会一卡一卡的
- 如果三个进程来执行,分别负责IO的读写、CPU解码以及播放
进程1读磁盘内容,然后传递给进程2解码,再传递给进程3播放,这样就产生了两个问题:
- 创建了三个进程,实现一个简单的功能却耗费过多的系统资源
- 进程间的内存空间不一致,数据时独立,进程之间传递数据,需要操作系统协调(频繁陷入内核)完成,效率低
线程解决进程开销大的问题
① 线程直接共享进程的所有资源 (比如 mm_struct),所以线程就变轻了,创建线程比创建进程要快到 10 ~ 100 倍
② 线程之间共享相同的地址空间 (mm_struct),这样利于线程之间数据高效的传输
③ 可以在一个进程中创建多个线程,实现程序的并发执行
什么是线程:进程中的一条执行流(函数调用链),用于执行不同路径的代码指令,每个进程一开始都有一个主线程
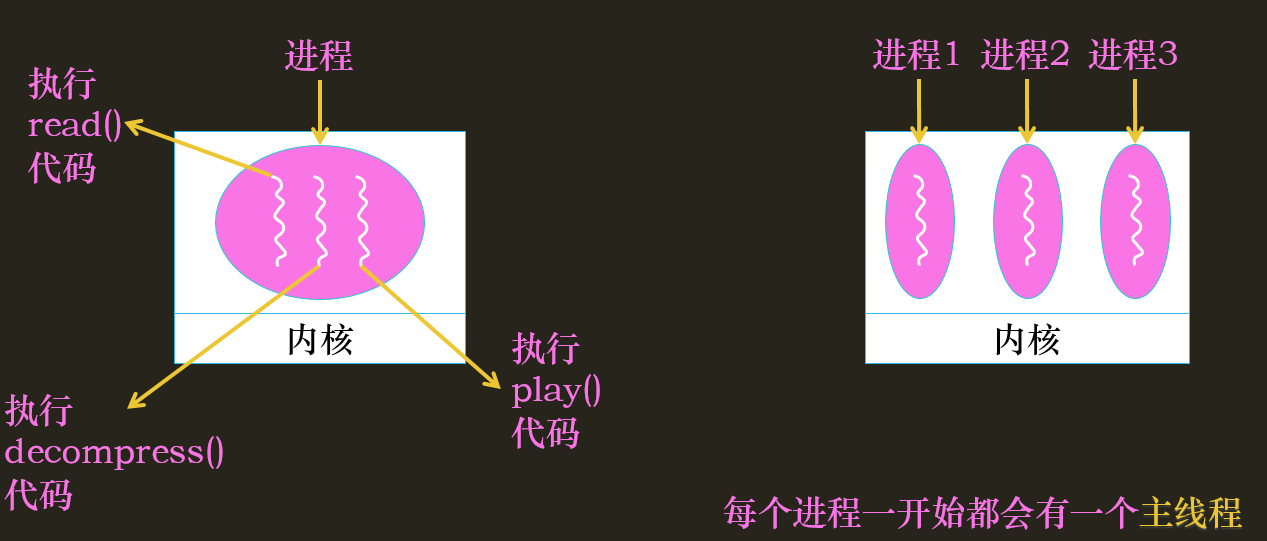
因此,进程可视为由两部分组成:资源平台(地址空间、磁盘、网络资源等)、线程
线程可访问的三类数据
线程共享mm_struct,所以其执行的代码指令是存放在进程地址空间的代码段中
- 线程栈
前文说了线程就是一条函数调用链,所以每个线程需要有自己私有的线程栈,存放在当前进程的堆中
而主线程(如main函数)的栈则使用进程的栈

线程栈从高地址向低地址生长
-
全局变量(读/写数据段)
-
线程私有变量
线程创建代码实例 pthread_create():

线程私有数据设置:
- 创建一个私有数据key:pthread_key_create(“key”)
- 设置私有数据:线程 1:pthread_setspecific(“key”, 22)
- 获取私有数据:线程 1:pthread_getspecific(“key”)

pthread_create详细过程
由于一个进程会有多个线程栈,可以用两个链表来管理这些线程栈:
- stack_used: 还未退出的线程的线程栈
- stack_cache: 退出的线程的线程栈,缓存在堆中,下次其他线程启动时直接可以用
pthread创建线程是由内核态和用户态合作实现的,也就是先在用户态创建一个线程(pthread实例),然后在切换到内核态再创建一个线程(task_struct实例):
用户态(创建一个用户态的线程):
- 调用pthread_create()
- 根据设置栈的大小,从stack_cache中找到相应大小的线程栈;如果没有,申请堆空间创建线程栈
- 创建pthread实例(包含了线程私有数据、栈大小、入口函数等),将之放在线程栈栈底位置
- 调用create_thread()
clone()系统调用:将子线程要执行的函数代码起始指令位置、参数写入寄存器(很重要) => 到此为止都是主线程在执行
内核态(创建一个内核态的线程管理用户态的线程):
-
将主线程的寄存器信息保存到主线程内核栈中
-
调用do_fork()(创建进程也是用的do_fork(),所以进程线程的创建都差不太多)
-
创建task_struct以及对应的内核栈
-
创建进程时,需要复制复制父进程的实例,但线程时资源共享的,不需要复制主线程的实例,直接将线程task_struct的实例指针指向进程的实例指针即可
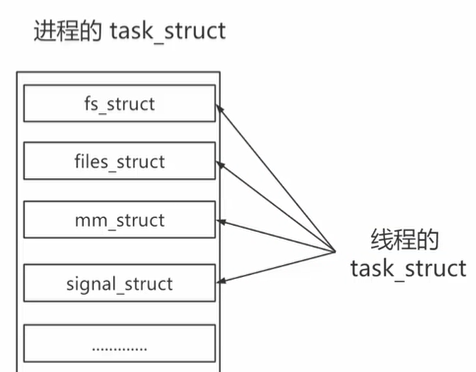
-
-
维护线程的亲缘关系,主要是维护线程和所属进程的关系
- 进程的pid等于其tgid,其中tgid表示所属进程的id,据此操作系统可区分一个task是进程还是线程
- 另外group_leader表示task所属的进程组
-
将task_stuct加入链表队列
在内核的角度,线程和进程的区别并不大,只是进程需要多一份资源管理
Tip:
- pthread创建用户线程需要内存创建用户态线程栈,内核创建内核线程需要内存分配(slab分配器)创建内核态线程栈,所以线程的数量不是无限的,会耗尽内存
- 不管是创建用户态的线程,还是内核态的线程,开销都很小,消耗性能的动作主要是系统调用,会发生CPU上下文切换
所以,为减少CPU的上下文切换,可以建立线程池,当线程执行完后,把线程还给线程池(在用户态阻塞),而非操作系统,后续再重用这个线程,同时,设置最大线程数量,防止内存不足
主线程的CPU上下文恢复
- 线程创建完成后,将从主线程的内核栈获取CPU上下文切换到用户态,对比进程创建完成后切换到内核态,此时:
用户态的栈就是父进程的栈,栈顶指针也指向父进程的栈,指令指针也是指向父进程的代码
那么切回到用户态将会进入主线程
- 但clone()这个系统调用不一样,它在进入内核态之前,就把要执行的函数代码起始地址(也就是入口函数的地址)写入寄存器,进入内核后,存入内核栈的自然是子线程的下一条指令,此时:
用户态的线程栈就是创建线程A的栈,栈顶指针也指向线程A的栈,指令指针也是指向线程A的代码
然后执行start_tread(),执行线程函数
- 那么问题又来了,子线程倒是能顺利执行,那主线程怎么办,主线程的CPU上下文都没了:
但其实在内核拿到子线程CPU上下文,准备返回用户态的那一刻,主线程和子线程进行了一次线程切换参考链接,主线程的CPU上下文信息写入了其内核栈,等下次调度主线程时,就可以顺利运行了
用户级线程和内核级线程
PCB与TCB:
操作系统每创建一个进程,都会在内核态创建一个进程管理器PCB: Process Control Block,存入进程表
操作系统每创建一个线程,都会创建一个线程管理器TCB: Thread Control Block(如果是创建用户级线程,则TCB必须存放在用户态),存入线程表
用户级线程
用户级线程:由一些应用程序中的线程库来实现,应用程序可以调用线程库的 API 来完成线程的创建、线程的结束等操作
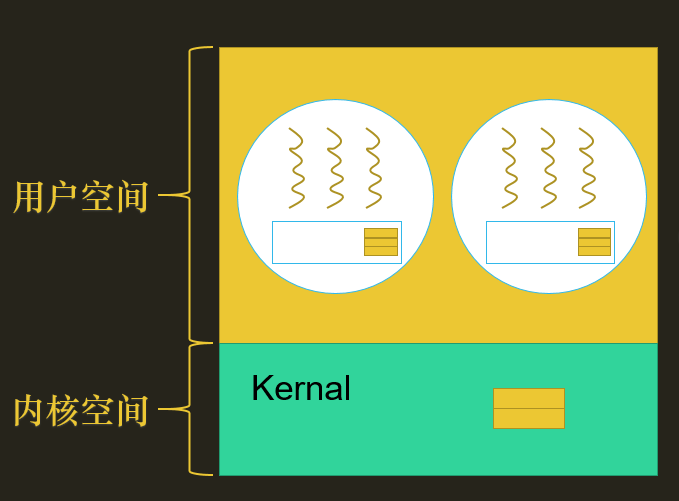
用户级线程优点:
- 快,线程的创建、销毁、切换都非常快,不需要陷入内核态
- 可以自定义调度算法,比较灵活
缺点:
- 一个线程不让出CPU,其他的线程永远执行不到了,因此只有线程主动让出cpu,线程库才有切换线程的权力(如果有内核管理的话,会进行时钟中断)
- 如果一个线程被阻塞,那么这个线程所有的线程都会被阻塞。
- 比如我一个进程中的一个子线程A需要调用系统资源,则需要陷入内核找到对应的PCB去访问资源,这个过程中,子线程A被阻塞,其他线程也拿不到CPU的执行权,就整个进程都阻塞了
- 操作系统看不到线程,只能以进程的视角调用,很可能分配的执行时间太少
内核级线程
内核级线程:在内核空间实现的线程,由操作系统管理的线程;内核级线程管理的所有工作都是由操作系统内核完成,比如内核线程的创建、结束、是否占用 CPU 等都是由操作系统内核来管理。

在支持内核线程的操作系统中,由内核来维护进程和线程的上下文信息 (PCB 和 TCB),一个进程的 PCB 会管理这个进程中所有线程的 TCB,当一个线程阻塞,那么内核可以选择另一个线程继续运行。=> 比如Linux
在Linux中,pthread_create会创建一个用户级线程 + 一个内核级线程,pthread_create创建一个TCB,内核会创建一个内核级线程(task_struct)来管理这个用户态线程
Tip: 这里的内核级线程也叫轻量级进程LWP
内核级线程的优点:
- 内核级线程的创建、终止和切换都是由内核来完成的,所以应用程序如果想用内核级线程的话,需要通过系统调用来完成内核级线程的创建、终止和切换,这里会涉及到用户态和内核态的转换,因此相对于前面用户级线程,系统开销较大
缺点:
-
在一个进程中,如果某个内核级线程因为发起系统调用而被阻塞,并不会影响其他内核线程的运行。因为内核级线程是被操作系统管理,受操作系统调度的
-
因为内核级线程是调度单位,所以操作系统将整个时间片是分配给线程的,多线程的进程获得更多的 CPU 时间
用户级线程和内核级线程的关系
不管怎样,线程的实现都需要用户态和内核态的相互配合,因此产生了如下几种关系:
- 用户级线程 to 内核级线程: n to 1
线程的TCB存放在用户态,通过一个task_struct访问系统资源,也就是用户级线程,这种线程模式线程切换快,开销小

- 用户级线程 to 内核级线程: 1 to 1
线程的TCB存放在内核态,也就是内核态线程,如上文讲的pthread, 这种线程模式并发能力强

- 用户级线程 to 内核级线程: m to n
比如Go中的协程,需要根据自定义的调度器进行切换

内核线程
不管是创建进程(fork)还是创建线程(clone),都需要在内核调用do_fork()
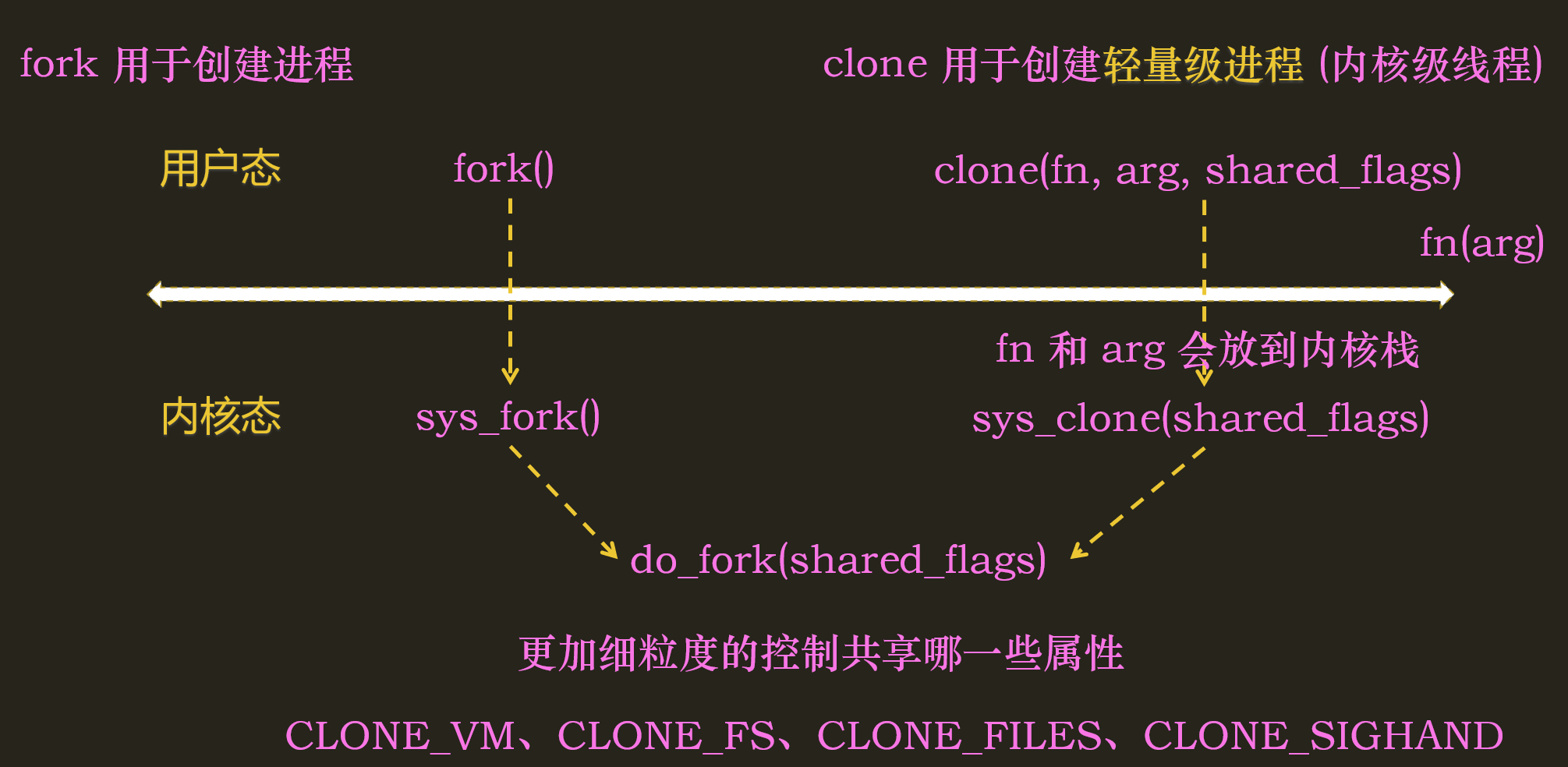
而内核线程也可以通过kernel_thread()调用dofork()来创建
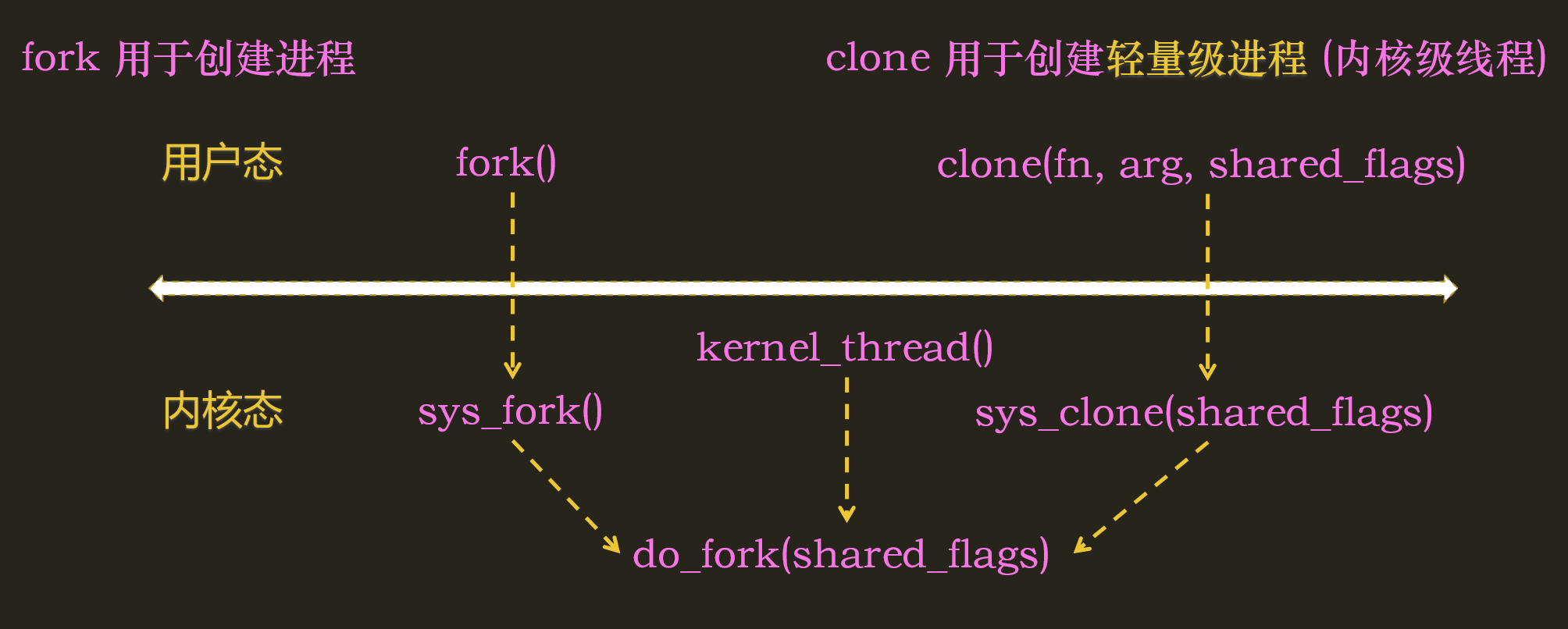
与内核级线程不同,内核线程不能访问用户态内存空间
- active_mm:用于指向进程所处的虚拟地址空间 (用户态或者内核态)
- mm: 用户态虚拟地址空间
- init_mm: 内核态虚拟地址空间,全局只有一个
当进程处于内核态时,指向内核态的地址空间active_mm=mm;当进程处于用户态时,指向用户态的地址空间;active_mm=init_mm
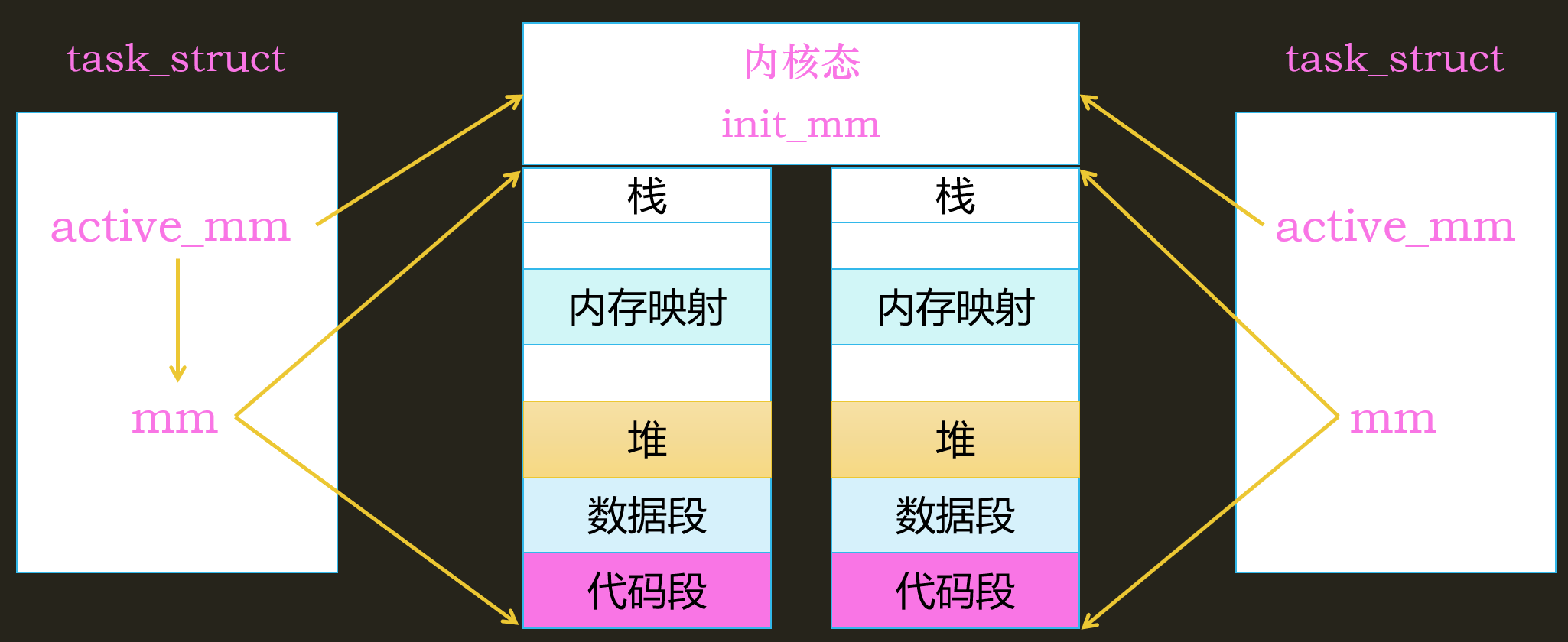
而内核线程的mm=null,因此不能访用户态虚拟地址空间
Tip:1号进程如何从内核进程转变为普通进程?
- 先加载可执行文件,设置mm
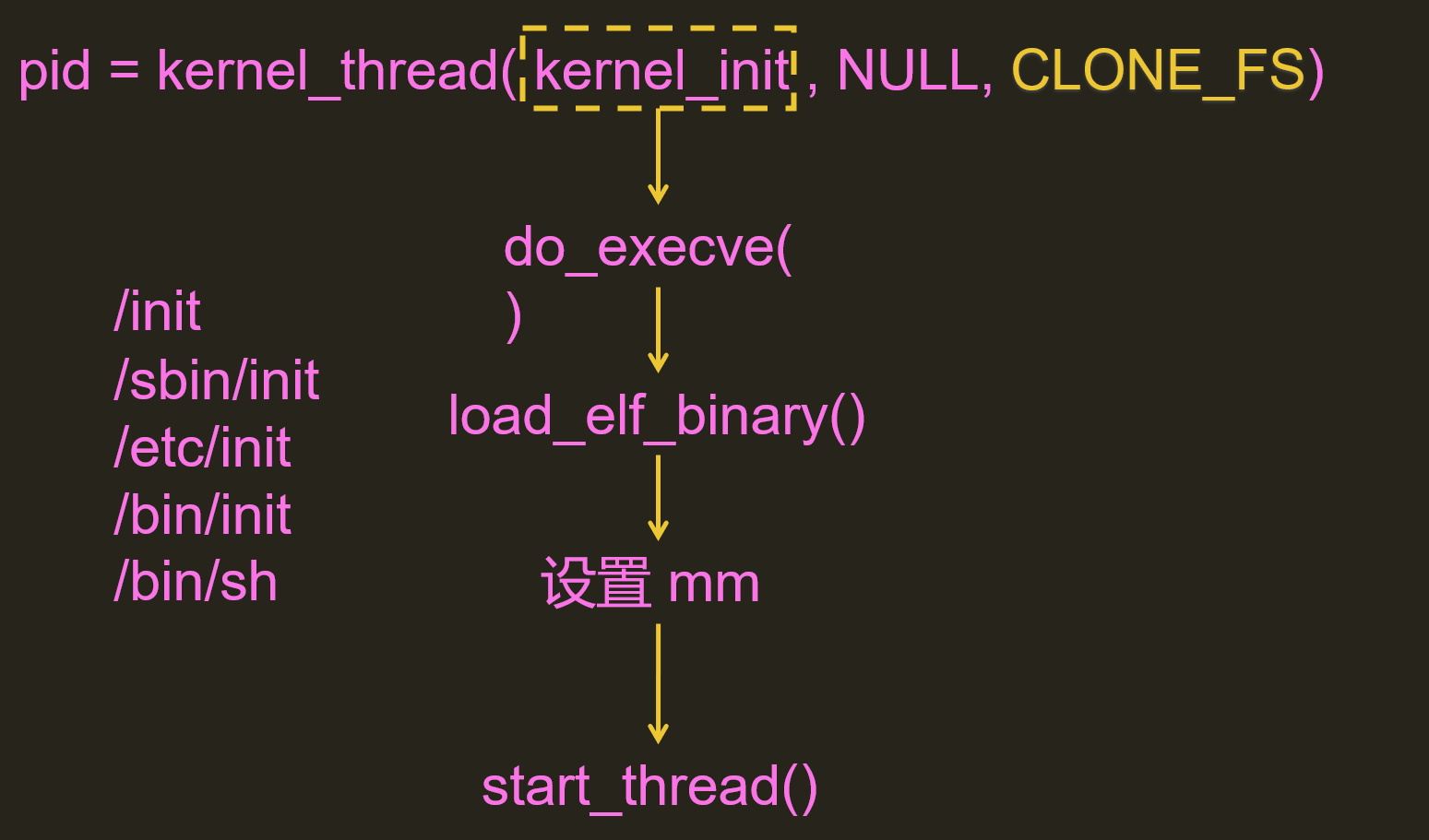
- 设置寄存器,切换到用户态(为数不多从内核态切到用户态的)

线程的状态
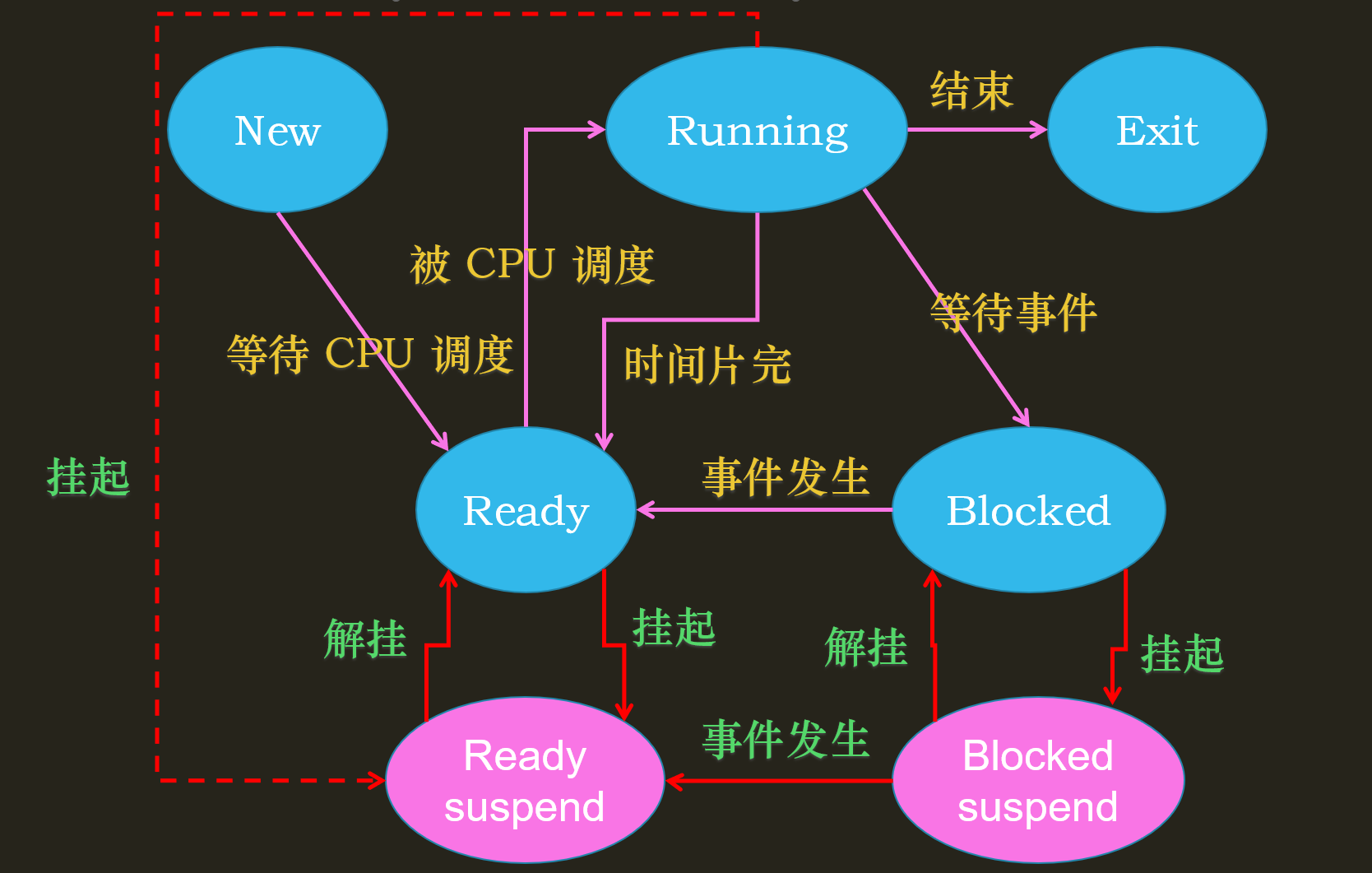
在工作中,线程池是肯定会遇到的,会经常遇到线程的状态的变化,一般线程的状态为:创建、就绪、运行、阻塞、结束

还是一个状态很重要:挂起
阻塞挂起:当一个线程处于阻塞时,而其他运行中的线程需要的内核又很多,系统会把这个阻塞线程的内存交换到磁盘,即使等待的事件到达了,也只能转变为就绪挂起状态
阻塞解挂:当磁盘中的数据加载到内存后,线程的状态就从阻塞挂起变成了阻塞
同理,就绪状态的线程也可能会挂起
而处于运行中的线程,如果也因为内存不够,就会转变为就绪挂起状态
Linux线程的状态
- task_running: Linux线程没有就绪状态,或者说就绪状态和运行状态的值都是task_running,但Linux会把一个专门用来指向当前运行任务的指针 current 指向它,以表示它是一个正在运行的线程。
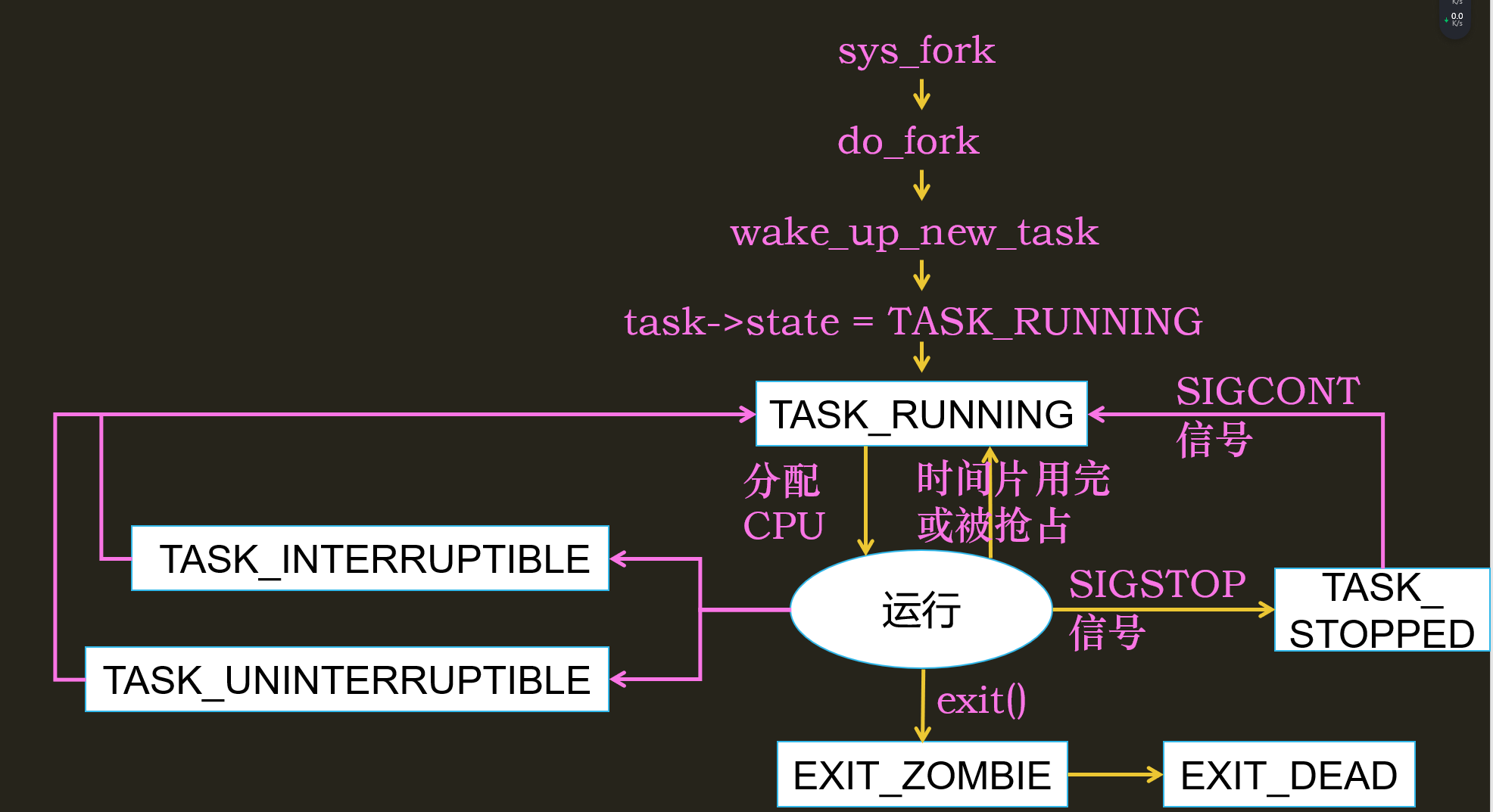
- TASK_INTERRUPTIBLE/TASK_UNINTERRUPTIBLE:阻塞状态(可中断和不可中断)
正常来说,一个线程需要进行IO操作,此时将会阻塞,等待IO操作完成后,再继续执行

但现在,在阻塞的时候,其他线程发了一个kill- 9的命令,如果是可中断的阻塞,需要响应这个信号,杀死自己;而如果是不可中断,则不会响应这个信号
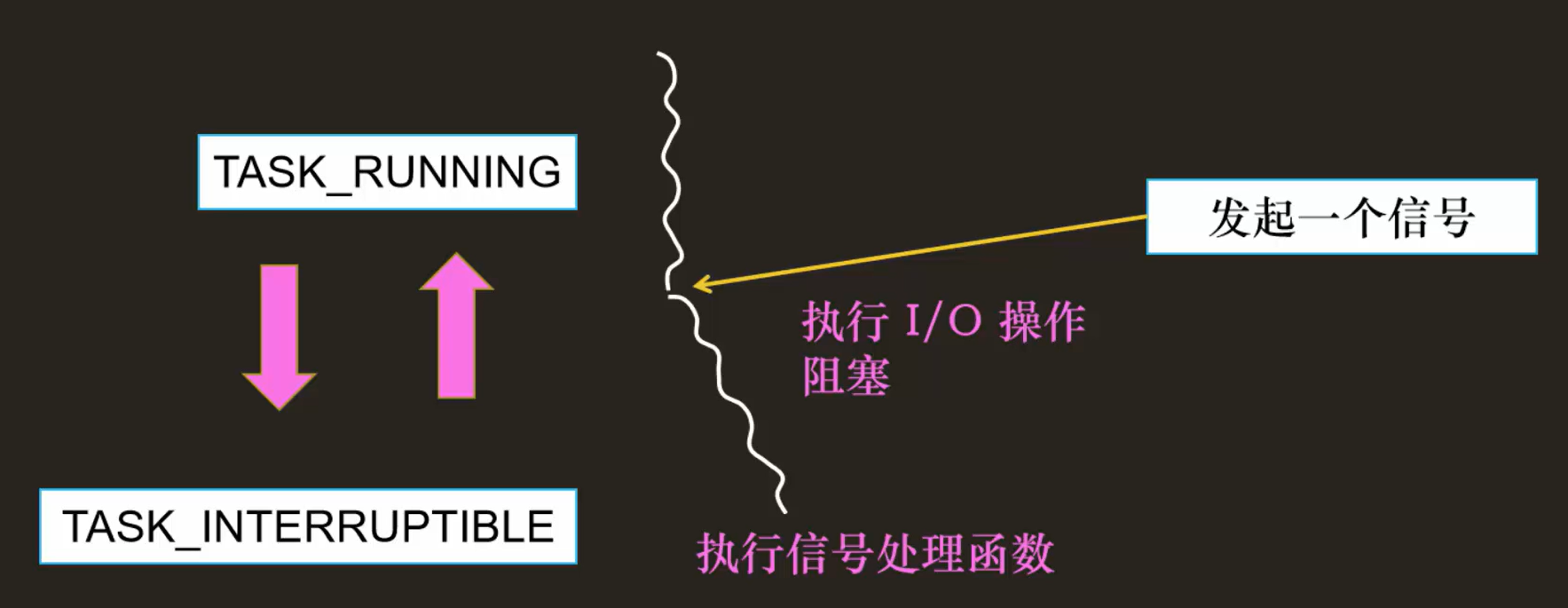
不可中断的阻塞是个很危险的事情,一旦 I/O 操作因为特殊原因不能完成,这个时候,谁也叫不醒这个进程了;所以一般只有内核线程才会设置这个状态,比如执行磁盘IO(DMA搬运数据被打断可能会产生严重问题)时
总结下线程的执行效率比进程高
- 线程创建直接重用进程的资源即可,不需要额外维护,线程释放也不需要考虑资源释放的问题
- 线程间数据共享,不需要切内核就可以访问共享数据
- 线程切换要快,进程的切换需要切换进程对应的页表,需要 flush TLB,而刷新TLB后页表项都不会命中LTB,需要去内存查找页表,而线程共享页表