✨作者主页:IT毕设梦工厂✨
个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。
☑文末获取源码☑
精彩专栏推荐⬇⬇⬇
Java项目
Python项目
安卓项目
微信小程序项目
文章目录
- 一、前言
- 二、开发环境
- 三、系统界面展示
- 四、部分代码设计
- 五、论文参考
- 六、系统视频
- 结语
一、前言
随着工业化进程的加速和信息化技术的广泛应用,生产大数据平台的建设成为了制造业转型的关键。基于大数据的生产大数据平台,旨在通过数据驱动的决策,提升生产效率,优化资源配置,增强企业的竞争力。本课题源于此背景,旨在构建一个便捷、可靠、实时的生产大数据平台,以满足现代制造业的需求。
尽管现有的生产管理系统在一定程度上可以实现生产统计、生产批次进度管理和生产线作业进度管理等功能,但它们往往存在一些问题。例如,对数据的处理和分析不够准确,无法提供实时的生产信息;系统之间的数据交互不流畅,导致信息孤岛现象严重;另外,缺乏对异常情况的及时处理机制,使得生产过程中的问题无法得到及时解决。这些问题都迫切需要一个更加完善、更加智能的生产大数据平台来解决。
本课题旨在构建一个基于大数据的生产大数据平台,旨在实现以下目标:
提高生产统计的准确性和实时性,为管理层提供可靠的决策依据;
实现生产批次进度和生产线作业进度的实时监控,提高生产效率;
通过对生产数据的分析和挖掘,发现生产过程中的潜在问题,预防和减少生产事故的发生;
提供一个统一的、可扩展的数据管理平台,以实现生产数据的共享和交互。
本课题的研究意义在于通过构建一个基于大数据的生产大数据平台,实现对生产过程的全局把控和精细化管理。这不仅可以提高生产效率,降低生产成本,还可以提高企业的竞争力,推动制造业的数字化转型。同时,该平台也可以为管理层提供更加准确的生产数据分析结果,帮助其制定更加科学、合理的决策。此外,该平台还可以为生产线工人提供更加便捷、实时的生产信息,帮助他们更好地了解和掌握生产进度和生产状况。本课题的研究成果将有助于推动工业4.0的实施和发展。
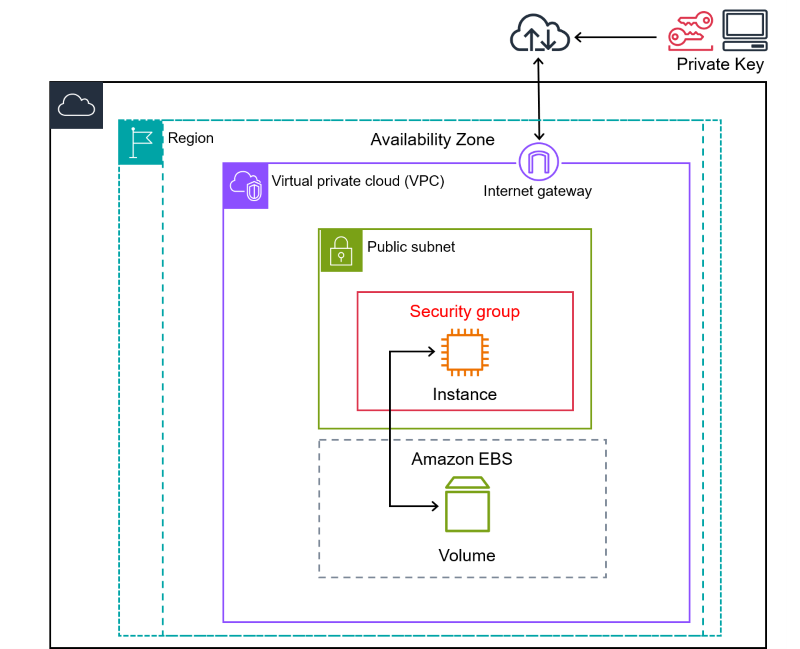
二、开发环境
- 大数据技术:Hadoop、Spark、Hive
- 开发技术:Python、Django框架、Vue、Echarts、机器学习
- 软件工具:Pycharm、DataGrip、Anaconda、VM虚拟机
三、系统界面展示
- 生产大数据平台界面展示:




四、部分代码设计
- 大数据项目实战-代码参考:
def sqliteObject_to_list_h(cur, SQLsatement):hxy = cur.execute(SQLsatement)cmy = []for i in hxy:temp1 = []for ii in i:temp1.append(ii)cmy.append(temp1)return cmydef sqliteObject_to_list_s(cur, r, SQLsatement):hxy = cur.execute(SQLsatement)cmy = []for i in range(r):cmy.append([])for i in hxy:num = 0for ii in i:cmy[num].append(ii)num = num + 1return cmydef sqliteObject_to_list_a(cur, SQLsatement):hxy = cur.execute(SQLsatement)cmy = []for i in hxy:cmy.append(i[0])return cmydef sqliteObject_to_list_n(cur, SQLsatement):hxy = cur.execute(SQLsatement)cmy = ''for i in hxy:cmy = i[0]return cmydef db_open():con = sqlite3.connect(DATABASE_PATH)cur = con.cursor()return con, curdef db_close(con, cur):cur.close()con.close()
def parse1(time):start_time = time[0:10]stop_time = time[10:]table = zfh(start_time, stop_time)time = [start_time, stop_time]return render_template('down_and_fault/parse/template_parse.html', time=time, table=table)@_parse.route('/parse/ajax', methods=['POST'])
def parse2():start_time = request.form['start']stop_time = request.form['stop']table = zfh(start_time, stop_time)return render_template('down_and_fault/parse/parse.html', table=table)def zfh(start_time, stop_time):con, cur = db_open()# 日期范围限制hxy_r = f'''日期 >= "{start_time}" and 日期 <= "{stop_time}"'''# 返回日期横坐标数组time = sqliteObject_to_list_a(cur, f'''select distinct 日期 from parse where {hxy_r}''')# 返回机组数据crew = sqliteObject_to_list_a(cur, f'''select distinct 机组 from parse where {hxy_r}''')# 表格内容顺序,机组编号,成材率,人均吨钢,吨电耗,单位产量,吨备件table = sqliteObject_to_list_h(cur, f'''select 机组,ifnull(ROUND(sum(正品)/sum(原料),2),''),ifnull(ROUND(sum(正品)/sum(人数),2),''),ifnull(ROUND(sum(耗电)/sum(正品),2),''),ifnull(ROUND(sum(正品)/sum(开机),2),''),ifnull(ROUND(sum(备件金额)/sum(正品),2),'')from parse2where {hxy_r}GROUP BY 机组''')# # 图表内容顺序 人均吨钢,吨电耗,单位产量 吨备件和成材率不显示趋势,直接看最上面的总量即可# # 图表的title文字,同时也可用于搜索# pic_name = ['人均吨钢', '吨电耗', '单位产量']# for i in pic_name:# temp = sqliteObject_to_list_h(cur, f'''# select 机组,{i}# from parse1# where {hxy_r}# GROUP BY 机组# ''')###### hxy1 = sqliteObject_to_list_h(cur, f'''# select 机组,ROUND(sum(人均吨钢),2),ROUND(sum(吨电耗),2),ROUND(sum(单位产量),2),ROUND(sum(吨备件),2)# from parse1# where {hxy_r}# GROUP BY 机组# ''')## hxy2 = sqliteObject_to_list_a(cur, f'''# select 机组,ROUND(sum(正品)/sum(原料),2)# from parse# where {hxy_r}# GROUP BY 机组# ''')# 每日趋势区域db_close(con, cur)return table
五、论文参考
- 计算机毕业设计选题推荐-生产大数据平台-论文参考:

六、系统视频
生产大数据平台-项目视频:
大数据毕业设计选题推荐-生产大数据平台-Hadoop
结语
大数据毕业设计选题推荐-生产大数据平台-Hadoop-Spark-Hive
大家可以帮忙点赞、收藏、关注、评论啦~
源码获取:私信我
精彩专栏推荐⬇⬇⬇
Java项目
Python项目
安卓项目
微信小程序项目


![[蓝桥杯复盘] 第 3 场双周赛20231111](https://img-blog.csdnimg.cn/a62c77b8ae9d40a487853bed4375f5d8.png)