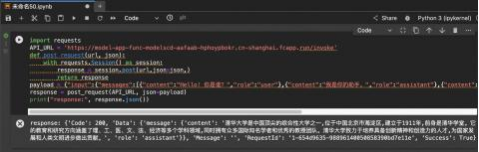
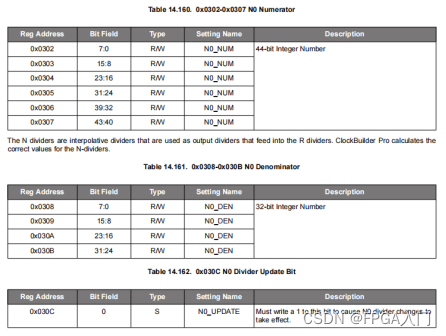
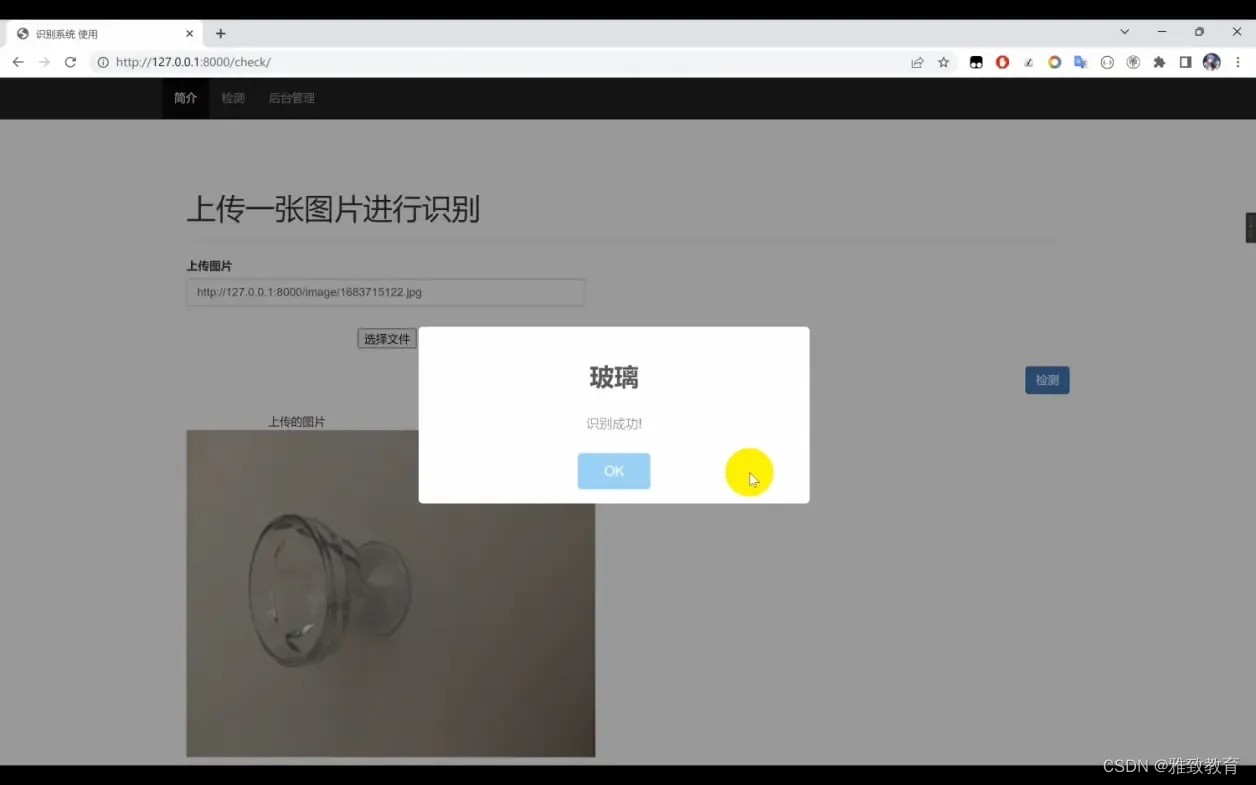
从本文开始,按照AI策略开发的完整流程(共七步),上手在BigQuant平台上快速构建AI策略。本文首先介绍如何使用证券代码模块指定股票范围和数据起止日期。重要的事情说三遍:模块的输入端口有提示需要连线的上游数据类型,两个模块之间的接口不能随意连接,否则会报错!
如下图所示,训练集和预测集数据的构建需要首先通过代码列表模块指定数据起止时间和标的范围。
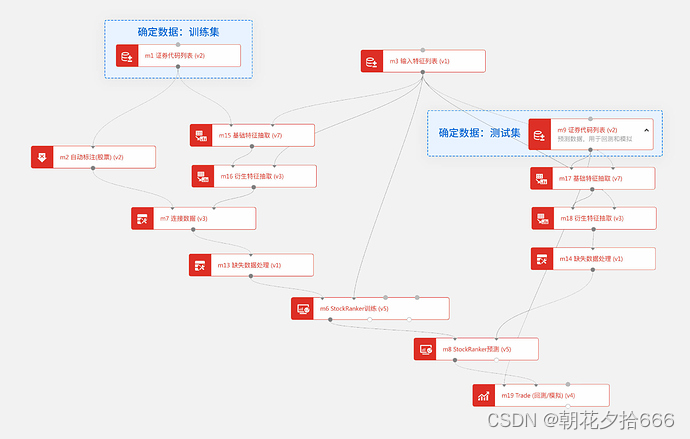
一、设置数据集
新建策略
第一步:新建空白可视化AI策略。
添加模块
第二步:添加模块:在模块列表的 数据输入输出 下找到 代码列表 模块并拖入画布。

模块参数设置
第三步:选中模块,在右侧属性栏中可修改参数。

-
开始时间:训练集的开始时间设置,格式“yyyy-mm-dd”。
-
结束时间:训练集的结束时间设置,格式“yyyy-mm-dd”。
-
交易市场:目前支持种类有
-
CN_STOCK_A – A股
-
CN_FUND – 场内基金
-
CN_FUTURE – 期货
-
如图所示,我们设置训练集数据时间范围是2013-01-01日至2016-12-31日,股票范围为A股所有股票
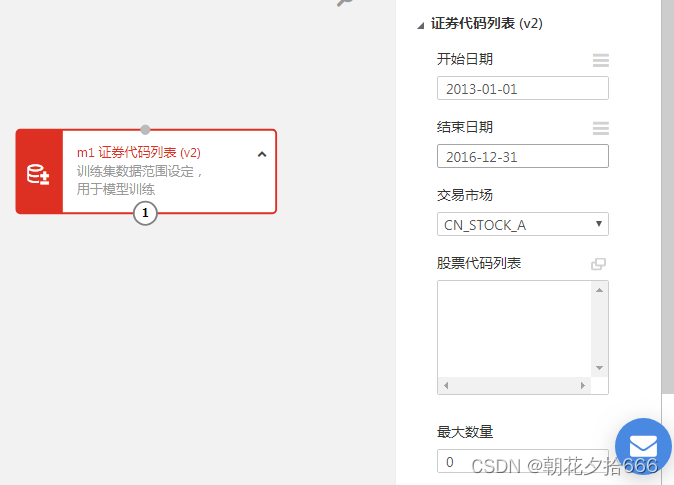
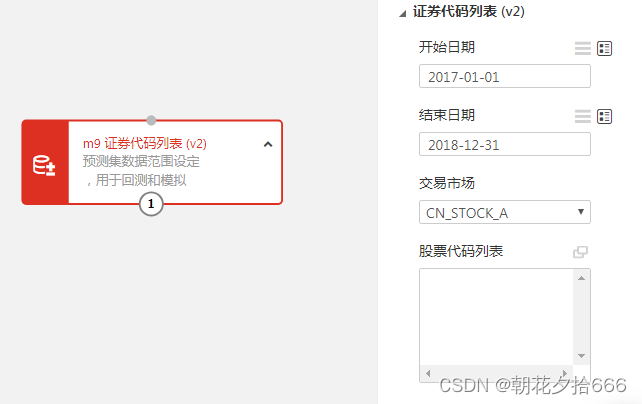
测试集的模块设置与训练集类似,只需要将“开始时间”和“结束时间”设置为“2017-01-01”和“2018-12-31”即可。
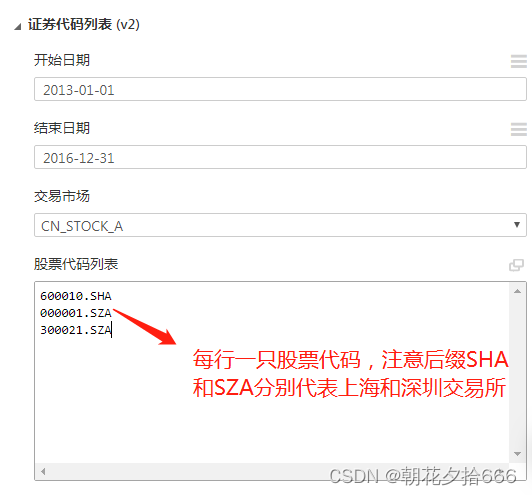
如果我们想指定一个股票池训练或预测,那么只要在股票代码列表中加入相应的股票代码即可,如下图所示:
小结:至此,完成了训练集和预测集数据的起止时间和股票范围设置,接下来会进行目标确定、数据标注部分。
二、数据标注
在上文已经完成了训练集和预测集数据范围的设置。接下来在第二步中,学习如何使用数据标注模块来设置训练目标。
数据标注是有监督学习算法的关键,标注是否能够准确描述问题的目标直接影响模型的有效性。

添加模块
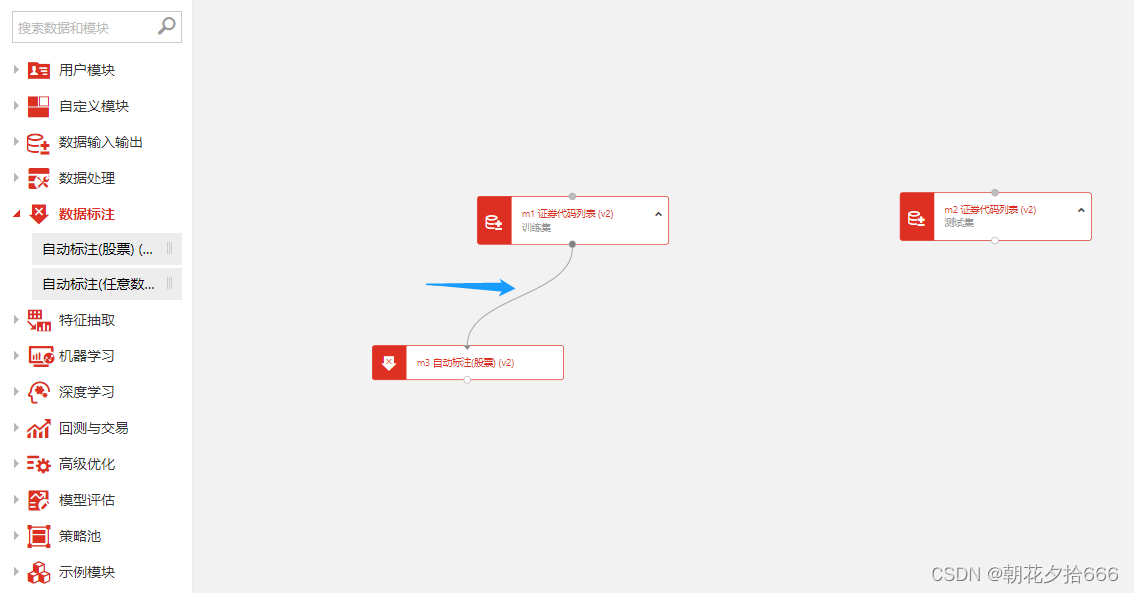
第一步:在模块列表的数据标注下找到自动标注(股票)模块,并拖入画布中。
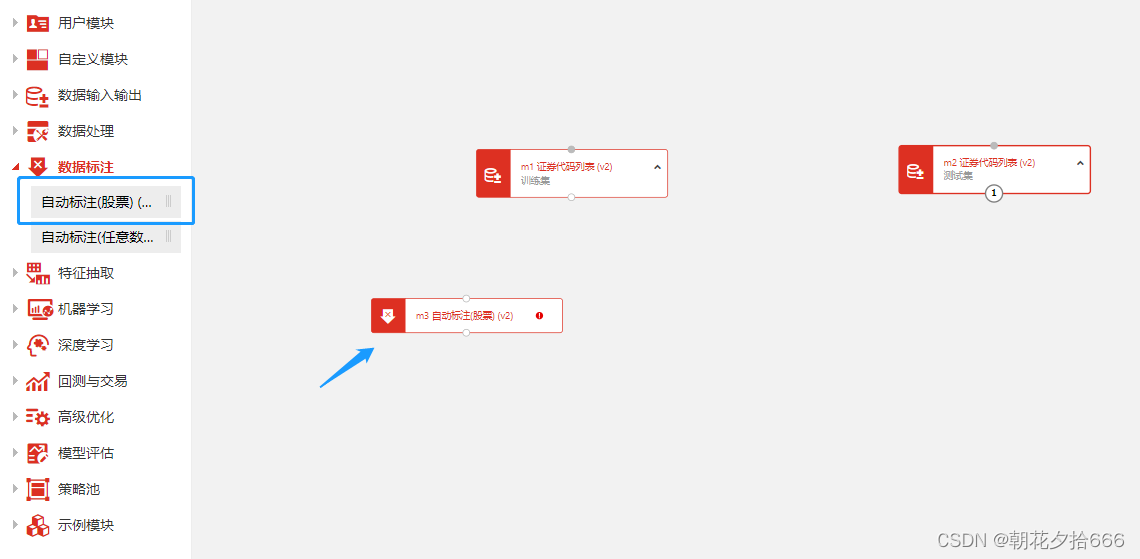
连接模块
第二步:将训练集的证券代码列表模块的输出端连接至自动标注(股票)模块输入端。
这里提示一下,所有的模块上边界的 ○ 为数据连接点,下边界的 ○ 为数据输出连接点。
参数设置
第三步:设置模块参数。点击选中该模块,在右侧属性栏可设置参数。
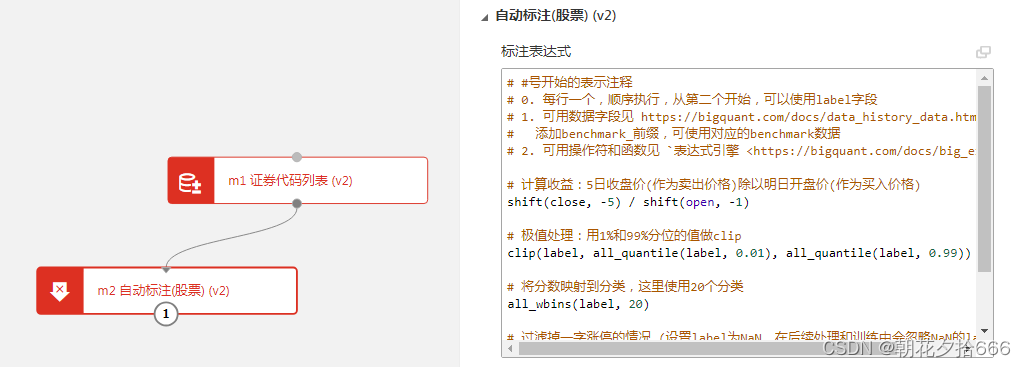
标注表达式:单击标注表达式文本框右上角的 图标,可打开独立的表达式编辑窗口,在编辑窗口内,可根据自己关注的指标条件组合。表达式的类型及语法学习可见站内文档-表达式引擎。
本例中计算未来五日收益率,去掉1%以下和99%以上的极值数据,并离散为20档分数,作为评估股票好坏的标准。同时对于一字板股票当日数据进行了剔除过滤。模块运行后会得到的一个DataFrame表,其中有一个标注列(默认为label列),代表的是每只股票未来五日收益率这个目标的得分,得分越高表示目标值未来五日收益率越大。
开始日期和结束日期:这里两个日期节点可不填,直接继承证券代码列表模块的时间范围
基准指数:指数的代码可查阅文档-指数成分中instrument字段的结果,获取需要的基准指数代码。
小结:至此,确定目标的数据标注步骤就完成了。想知道如何实现更加复杂的标注的小伙伴可以移步学习自定义标注 。下一步就是AI模型构建中非常关键的步骤:怎么选择因子组合,这直接关系到一个策略模型的性能质量。
三、找因子
在第一步中我们通过证券代码列表模块确定好训练集和预测集的股票范围以及数据起止时间,本文介绍如何获取和计算因子数据。
如下图所示,找因子的步骤大致需要两个小步骤:一是先确定符合自己需求的特征组合列表,二是进行特征的抽取计算。

特征列表模块
确定了股票集后和目标条件之后,现在需要通过特征列表模块把策略的关注的数据指标输入到策略中,下面我们就介绍如何添加特征列表并传入其他关联的模块中。
添加模块
第一步: 在模块列表的 数据输入输出 下找到“ 输入特征列表 “ 模块并拖入画布。

编辑特征公式
第二步:点击选中输入特征列表,在属性栏特征数据文本框中编辑特征公式。
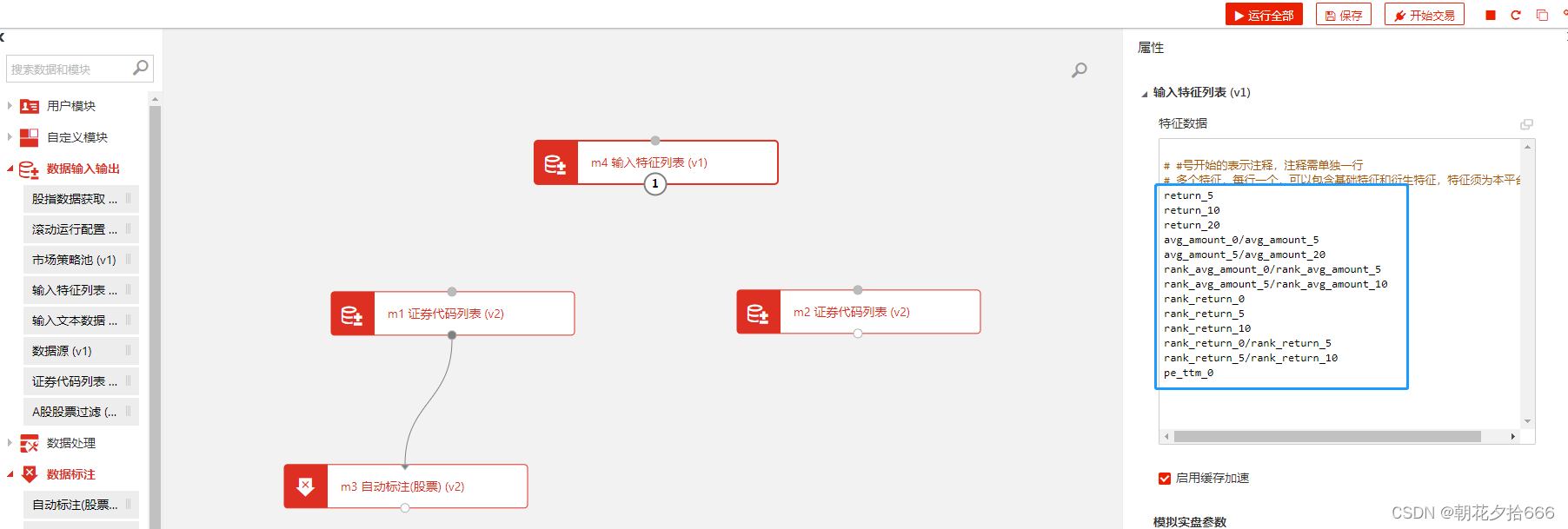
默认封装好的模块里初始化了13个特征条件:
-
return_n-表示“近n日收益率”;
-
avg_amount_0/avg_amount_5-表示“当日平均成交额和5日平均成交额比值”;
-
rank_avg_amount_0/rank_avg_amount_5-表示“当日平均成交额排名和5日平均成交额排名比值”;
-
rank_return_0-表示“当日收益率排名”;
-
rank_return_0/rank_return_5-表示“当日收益率和5日收益率比值”;
-
pe_ttm_0-表示“当日市盈率”。
更多特征条件的表达式见文档-因子
输入因子
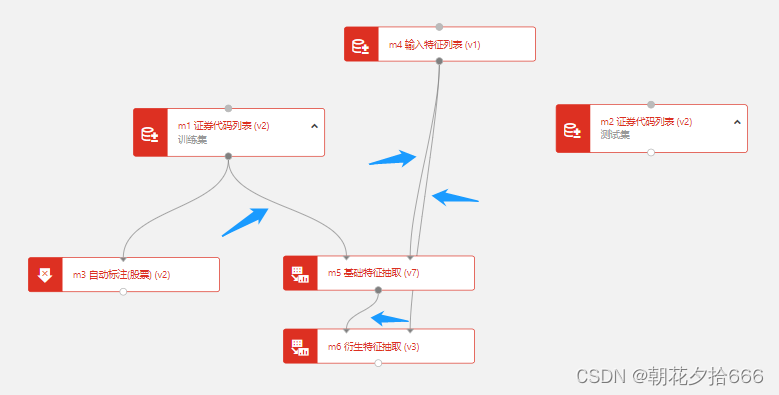
第三步:通过模块之间的连线,将输入特征列表模块中的因子列表传入到训练集和预测集的特征抽取模块中,如下图示。
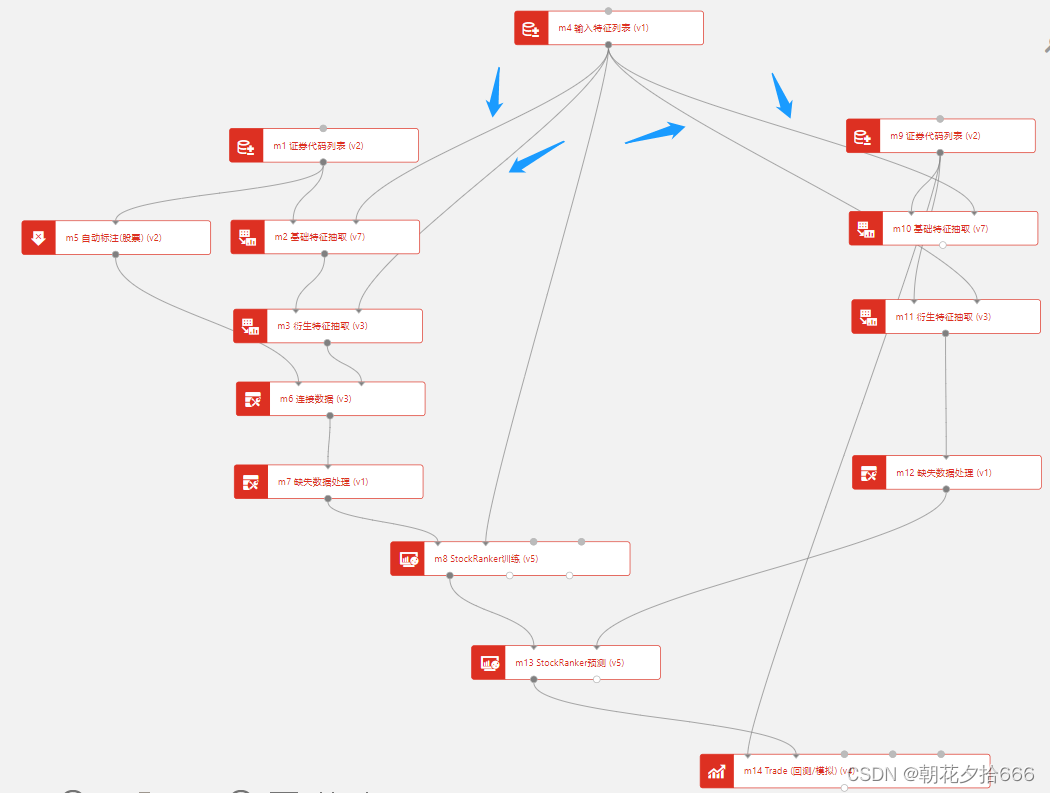
基础特征和衍生特征模块
这两个模块之间可直接进行串联,作为一组特征抽取模块。基础特征模块会解析特征列表模块中传入的基础因子并进行数据抽取,而衍生特征抽取模块则会根据抽取的基础因子对复杂的表达式进行运算求值。例如,我们在输入特征列表中输入’return_0+1’这个因子,那么首先会由基础特征模块解析并抽取return_0这个因子的数据,随后由衍生特征抽取模块计算return_0+1这个表达式的值作为因子值,最终返回列名为‘return_0+1‘的因子数据。
对于训练集与测试集而言,由于证券代码列表模块的时间段设置不同,因此各需要一组特征抽取模块。以训练集因子数据抽取流程为例:
添加模块
第一步: 在模块列表的 特征抽取 下找到“ 基础特征抽取 “ 模块并拖入画布。

连接模块
第二步: 将“输入特征列表”模块和“证券代码列表”模块的输出端与“基础特征抽取”模块的输入端连接,“基础特征抽取”模块和“输入特征列表”的输出端与“衍生特征抽取”模块的输入端连接。
配置编辑
第三步:点击选中“基础特征抽取”,在属性栏中对相应的配置进行编辑。
-
“开始日期”与“结束日期”,保持与前面对应的训练集一致,也可以不填写,自动继承上游代码列表的时间
-
“向前取数据天数”,可根据自己需求更改天数,例如:
要计算5日的收盘价之和因子sum(close_0,5)那我们至少要有5个交易日的close_0基础数据才能计算这个因子的值,考虑到这里填入的是自然日天数,可能会跨假期,那么这里可以填入20以保证因子计算能够得到有效的结果。

配置保持
第四步:点击选中“衍生特征抽取”,在属性栏中保持默认配置即可。
结语:因子的构建在机器学习中也称为特征工程,对模型构建的效果至关重要。根据定义目标的不同,因子的选择与组合是各不相同。在金融市场中,单个的因子统计量也被认为是市场的一个信息流,根据因子值的变化进行投资也看做为一个投资策略。市场中能够持续稳定获取超额收益的因子也称为alpha因子,而无法产生持续稳定超额收益的因子一般也称为风险beta因子。优秀的因子通过组合可以实现预测效果的提升,因此说找到优秀的因子是AI策略质量的关键。
拓展学习:如何开发一个好策略
四、数据连接+缺失数据处理
本文将详细介绍数据处理中的“数据连接”、“缺失数据处理”两大模块操作、原理。
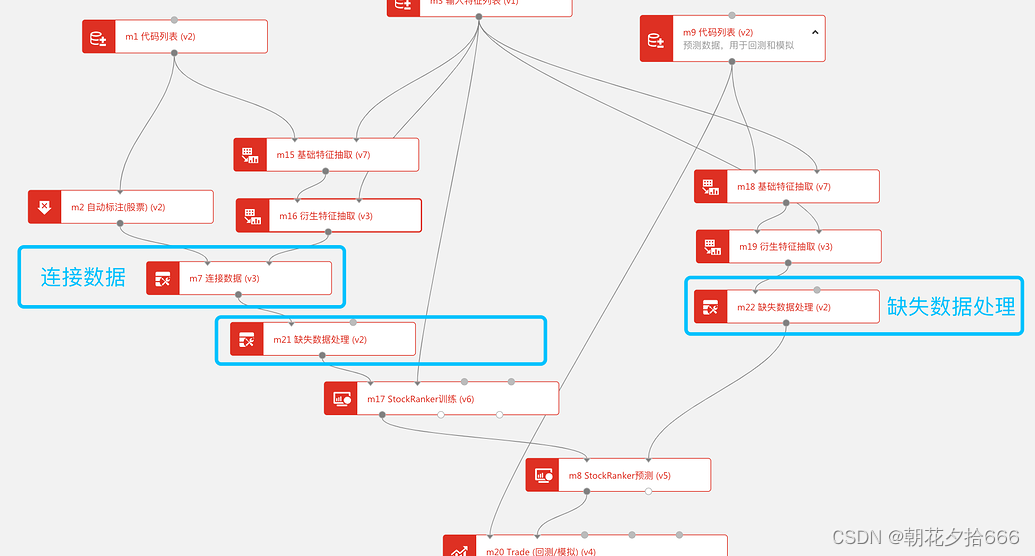
如下图所示,完成数据标注和特征数据计算后需经过简单的数据处理,我们才能利用AI算法训练模型并预测数据。
-
对于训练集数据而言,我们需要将标注数据和特征数据连接以形成完整的训练集数据供模型使用。此外,数据在训练前通常还需要进行缺失值数据处理以防止训练过程出错。
-
对于预测集数据而言,我们通常只需要缺失值处理。
数据连接模块
完成了标注数据和计算特征数据后,需要将这两部分数据DataFrame按日期和股票为索引横向拼接才能构成完整的训练集数据传递给AI模型进行训练。因此在训练模型前,需先连接数据,步骤如下:
添加模块
第一步:在模块列表的 数据处理 下找到“ 连接数据“ 模块并拖入画布
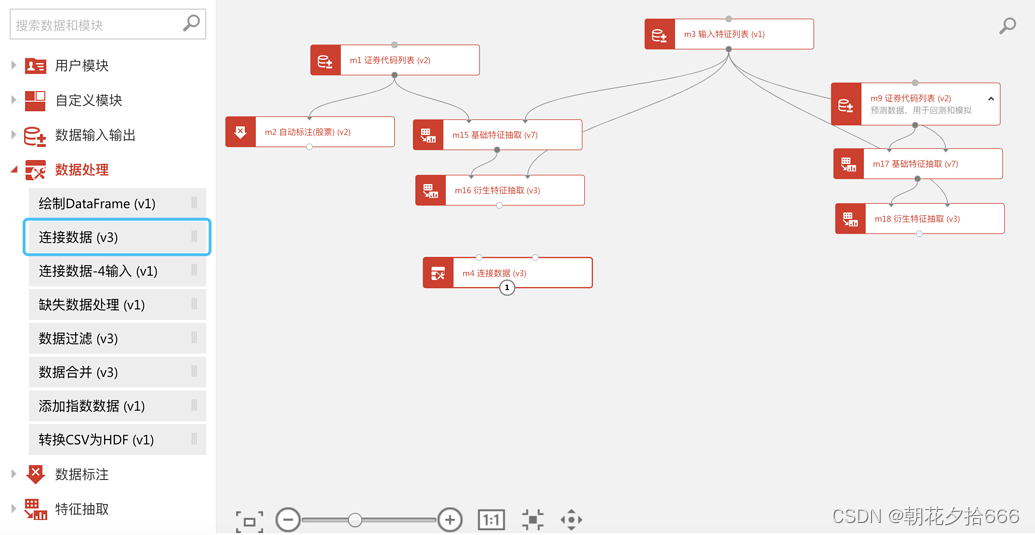
连接模块
第二步:分别将 “自动标注 ”和“衍生特征抽取” 模块的输出端连接至 连接数据 模块的两个输入端。

数据连接
第三步:选中模块,在右侧的属性栏中可以看到关联列和连接方式,我们先保留默认设置。

模块属性说明
数据连接模块将两个DataSource(数据内容格式为DataFrame表)通过关联列,将左表的行与右表的行一一对应并返回。故在关联列(可多列)中,每一行的值都是唯一的。各输入及参数说明如下:
输入数据:如本例的标注数据和特征数据,格式DataFrame,一般为其他模块的输出。
关联列:数据连接时使用的主键,默认使用date和instrument两列为索引,将每只股票每天的标注和特征因子值横向拼接。
连接方式:分为inner, outer, left, right,默认使用inner。
inner:左表和右表均包含关联列的值,才返回对应行。
outer:左表或右表中有一个包含关联列的值,则返回对应行。不包含关联列的表,对应行返回NULL。
right:右表中包含关联列的值,则返回对应行。左表不包含,则对应行返回NULL。
left:左表中包含关联列的值,则返回对应行。右表不包含,则对应行返回NULL。
对结果排序:选中则对连接后的数据按关联列进行排序。默认不选中。
输出数据:连接好的数据表运行模块
第四步:右键 运行选中模块
再右键 查看结果1 ,可发现我们将之前的标注数据和因子数据合并到了一张表。

缺失数据处理
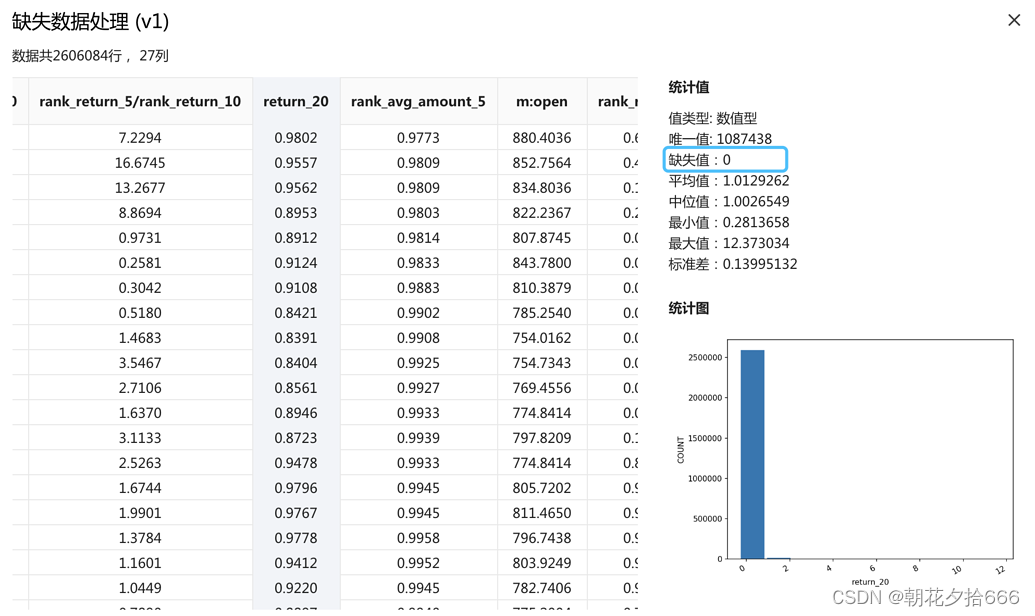
如下图所示,从连接数据模块的输出可看出,某些因子列的缺失值较多。为了确保训练能够正常进行可删除/填充含有缺失值的数据行,模板策略中采用删除的方式来处理缺失值。

添加缺失值处理模块
第一步:在模块列表的数据处理下找到缺失数据处理模块并拖入画布,由于训练集和预测集数据需要分别处理缺失值,因此我们拖入两个缺失值处理模块。

训练集
第二步:将训练集区域的连接数据模块的输出连线至缺失数据处理模块的输入,完成训练集的缺失值处理。将测试集区域的衍生特征抽取模块的输出连线至缺失数据处理模块的输入,完成测试集的缺失值处理。

模块属性说明
缺失数据处理模块是将表中含缺失值的行删除
输入数据:数据表,如本例中的标注+特征数据。
输出数据:删除缺失值所在行的数据表运行模块
第三步:右键缺失数据处理模块后选中运行选中模块即可运行模块,再右键缺失数据处理模块后选中“查看结果1“,可发现所有列已无缺失值。
小结:至此,以上完成了训练前的基本数据准备工作,接下来进入模型训练和股票预测部分。当然,也可进行更复杂的数据处理,如合并自己的数据,过滤停牌、过滤ST股票等。更多数据操作,请查阅专题教程:BigQuant新版数据API详解
(未完待续)