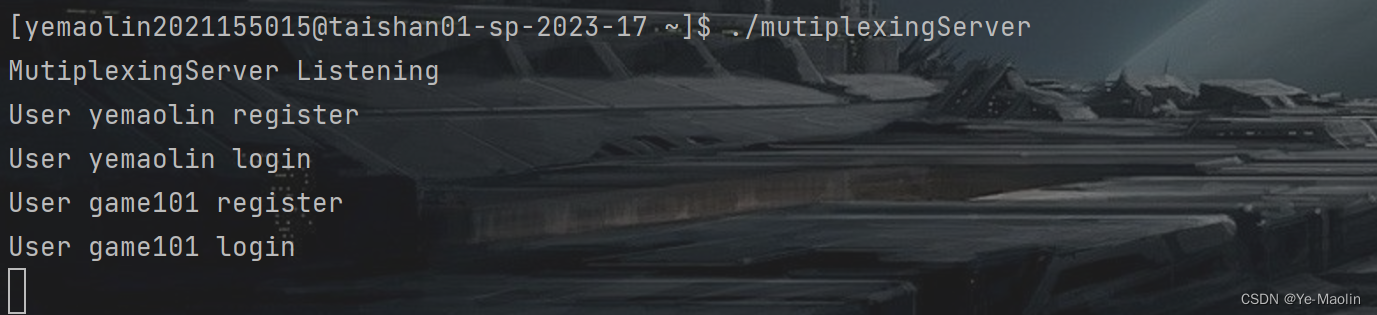
内容预告
learn X in 5 系列第一篇. 本篇主要介绍进程时延统计方式和 rawtracepoint.
runqlat
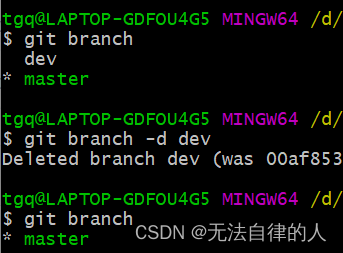
"高负载场景下应用为何卡顿", "进程 A 为什么得不到调度". 当我们在工作生活中产生这样的疑问, 目标进程的调度时延是一个不错的观测切入点. runqlat 可以帮我们完成这项统计, 以下是父子线程通过 pipe 通信, 通过 runqlat.bt 统计得到双方的时延信息:
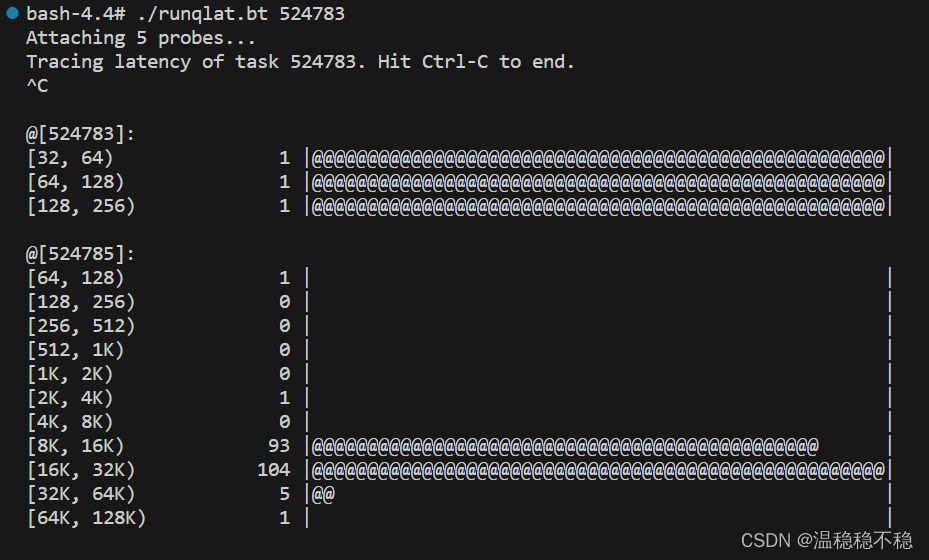
我们做了些手脚, 让线程 524785 运行条件更为恶劣, 通过上图可以发现双方调度时延有着显著的区别. 采集数据使用的 runqlat.bt 是使用 bpftrace 重写的 bcc/tools/runqlat, bpftrace 语法参考上篇文章:
$ wget -qO - https://raw.githubusercontent.com/lilstaz/perf-tool-examples/main/bpftrace/runqlat.bt
BEGIN
{if (!$1) // 1{printf("Specify the pid of the task first\n");exit();}@pid = $1;printf("Tracing latency of task %d. Hit Ctrl-C to end.\n", @pid);
}rt:sched_wakeup, // 2
rt:sched_wakeup_new
{$wakee = (struct task_struct*)arg0;if ($wakee->tgid == @pid) // 3{@qt[$wakee->pid] = nsecs;}
}rt:sched_switch // 4
{$prev = (struct task_struct*)arg1;$next = (struct task_struct*)arg2;if ($prev->tgid == @pid && $prev->state == TASK_RUNNING) // 5{@qt[$prev->pid] = nsecs;}if ($next->tgid == @pid && @qt[$next->pid]) // 6{@[@pid] = hist((nsecs - @qt[$next->pid]) / 1000);delete(@qt[$next->pid]);}
}
# 运行效果
$ wget -qO - https://raw.githubusercontent.com/lilstaz/perf-tool-examples/main/bpftrace/runqlat.bt| bpftrace - // 7
Attaching 5 probes...
Tracing latency of task 524783. Hit Ctrl-C to end.@[524783]:
[128, 256) 2 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|@[524785]:
[8K, 16K) 79 |@@@@@@@@@@@@@ |
[16K, 32K) 307 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[32K, 64K) 28 |@@@@ |
该脚本实现统计指定进程中所有线程的调度时延(从加入运行队列到进程实际运行), 其中:
-
强制用户输入待观测的进程号, 将用户输入的进程号赋值给全局变量
@pid; -
通过
,分隔挂载点, 可以将该段代码段挂在多个挂载点上. 这里rt是rawtracepoint的缩写, 会在下一节介绍; -
该挂载点第一个参数是被唤醒进程的 PCB, 该结构体保存了进程的
tgid(对应用户态的进程 ID),pid(对应用户态的线程 ID),comm进程名等信息. 当满足条件$wakee->tgid == @pid, 则说明目标进程的某线程进入了唤醒逻辑, 即将被放置在运行队列上, 我们使用线程号作为@qt哈希表的键, 将此时系统纳秒数保存下来; -
进程发生切换时会执行以下代码段;
-
我们使用
$prev标志被剥夺运行权的进程, 使用$next标志即将获得运行权的进程. 在 linux 中, 运行中以及在队列等待的进程状态都为TASK_RUNNING. 若$prev进程状态为TASK_RUNNING, 说明它将重新入队. 我们需要更新它的入队时间为当前时间; -
$next线程终于在运行队列熬到头, 即将拥有 CPU 的运行权, 通过计算当前时间和入队时间之间的差值, 我们就可以得到该线程的调度时延. 通过hist()函数, bpftrace 可以帮忙把数据统计成直方图; -
如果无法运行请下载最新版本的 bpftrace.
rawtracepoint
tracepoints 是内核内置静态的事件源, 接口稳定, 且包含了大部分子系统, 是优质的信息来源, 例如对于调度子系统有以下可用的 tracepoint:
$ grep sched: /sys/kernel/debug/tracing/available_events
...
sched:sched_migrate_task
sched:sched_switch
...
tracepoint 本质是内核中的打印语句, 它们以固定的格式被打印, 可以通过 /sys/kernel/debug/tracing/events/<子系统>/<名称>/format 文件查看打印格式. 以 sched:sched_switch 为例:
$ cat /sys/kernel/debug/tracing/events/sched/sched_switch/format
name: sched_switch
ID: 313
format:field:unsigned short common_type; offset:0; size:2; signed:0;field:unsigned char common_flags; offset:2; size:1; signed:0;field:unsigned char common_preempt_count; offset:3; size:1; signed:0;field:int common_pid; offset:4; size:4; signed:1;field:char prev_comm[16]; offset:8; size:16; signed:1;field:pid_t prev_pid; offset:24; size:4; signed:1;field:int prev_prio; offset:28; size:4; signed:1;field:long prev_state; offset:32; size:8; signed:1;field:char next_comm[16]; offset:40; size:16; signed:1; // 1field:pid_t next_pid; offset:56; size:4; signed:1;field:int next_prio; offset:60; size:4; signed:1;print fmt: "prev_comm=%s prev_pid=%d prev_prio=%d prev_state=%s%s ==> next_comm=%s next_pid=%d next_prio=%d", ...) :
假设我们对即将获得运行权的进程名感兴趣, 我们可以用以下语句打印标号 1 处定义的信息:
$ bpftrace -e 't:sched:sched_switch {printf("%s\n", args->next_comm)}'
swapper/5
pthread_pipe
pthread_pipe
...
tracepoint 很完美, 它总是在代码关键路径出现. 对于理解内核代码, 抑或调试都非常好用. 但在以下场景:
-
对观测脚本的性能有要求;
-
希望从原数据结构获取更丰富的信息. 使用 rawtracepoint 或许是更合适的.
那么 rawtracepoint 是什么? 它可以理解为 tracepoint 的另一面, /sys/kernel/debug/tracing/available_events 中可用的事件, rawtracepoint 都可以使用, 但相对 tracepoint 提供特定的值, rawtracepoint 直接提供内核数据结构. 即更接近内核的 '第一手数据'. 再次以 sched:sched_switch 为例, 相关代码(include/trace/events/sched.h)如下:
TRACE_EVENT(sched_switch,TP_PROTO(bool preempt, struct task_struct *prev, struct task_struct *next), // 1TP_fast_assign(memcpy(__entry->next_comm, next->comm, TASK_COMM_LEN);__entry->prev_pid = prev->pid; // 2__entry->prev_prio = prev->prio;__entry->prev_state = __trace_sched_switch_state(preempt, prev);memcpy(__entry->prev_comm, prev->comm, TASK_COMM_LEN);__entry->next_pid = next->pid; // 3__entry->next_prio = next->prio;),TP_printk("prev_comm=%s prev_pid=%d prev_prio=%d prev_state=%s%s ==> next_comm=%s next_pid=%d next_prio=%d", ...)
);
根据标号 1 的定义, 该 tracepoint 接受调度子系统给它传递的三个参数 preempt, prev, next, 并通过 TP_printk() 打印到环形缓冲区. 在第一节 runqlat 中, 为了过滤特定进程的调度时延, 我们需要获取进程切换时两个进程的 tgid 以及 pid. 但根据标号 2 和 3, tracepoint 只能获取到 pid. 为了直接使用 preempt, prev, next 三个变量, 我们可以使用 rawtracepoint, 在 bpftrace 中简写为 rt. 回顾第一节的代码:
rt:sched_switch
{$prev = (struct task_struct*)arg1;$next = (struct task_struct*)arg2;
...
这里 $prev $next 其实是获取了该 tracepoint 中 TP_PROTO 定义的第 2 和第 3 个参数. 因为只获取参数, 不需要构建 context 结构体, 使得 rawtracepoint 比 tracepoint 的效率更高.
后记
在 bpftrace git 仓库其实有另一个版本的 runqlat.bt , 但没有提供追踪特定进程的功能. 当年用它查问题写了相当绕且丑的逻辑. 知道有 rawtracepoint 之后, 对调度子系统的追踪观测明显方便了几个数量级.
在 tracepoint 无法满足你的场景, 记得翻代码看看它 TP_PROTO, rawtracepoint 总能给你惊喜.
ref
-
Frequently asked questions about using raw tracepoint with ebpf/libbpf programs[1]



![[PHP]Kodexplorer可道云 v4.47](https://img-blog.csdnimg.cn/532b538062ec407b85784c9884eef039.png)