目录
1. 监督学习 (Supervised Learning):
2. 无监督学习 (Unsupervised Learning):
3. 强化学习 (Reinforcement Learning):
4. 半监督学习 (Semi-Supervised Learning):
5. 自监督学习 (Self-Supervised Learning):
6. 迁移学习 (Transfer Learning):
7 机器学习范式应用分析
机器学习(Machine Learning,ML)有不同的范式,这些范式描述了学习算法如何从数据中提取模式和知识。以下是几种常见的机器学习范式:
1. 监督学习 (Supervised Learning):
- 定义: 监督学习是一种机器学习任务,其中算法通过学习从输入到输出的映射关系来进行训练。训练数据包含有标签的样本,即每个输入都与相应的输出相关联。
- 例子: 分类和回归任务是监督学习的例子。例如,手写数字识别和房价预测。
- 代码:
-
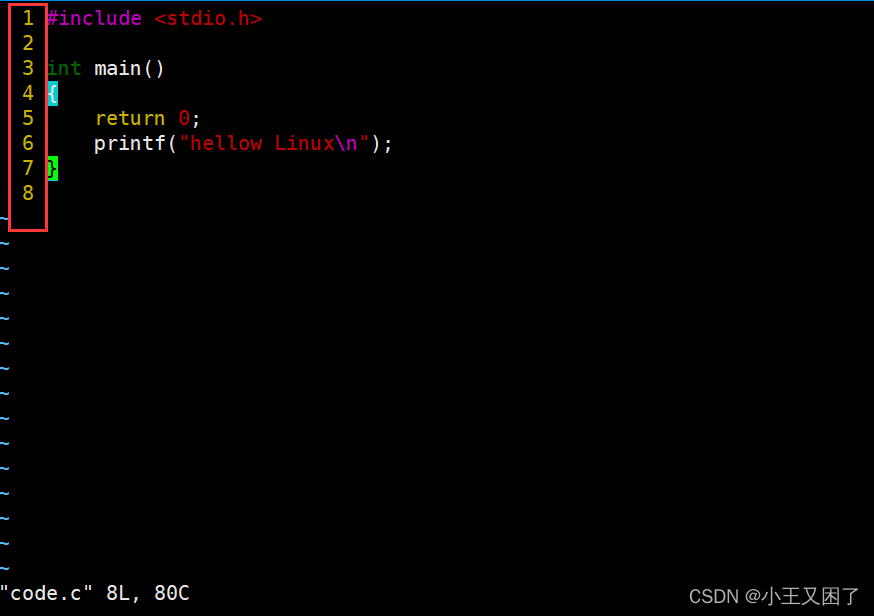
from sklearn.datasets import load_digits from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score# 加载手写数字数据集 digits = load_digits() X, y = digits.data, digits.target# 划分数据集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建并拟合模型 model = LogisticRegression() model.fit(X_train, y_train)# 预测 predictions = model.predict(X_test)# 评估模型 accuracy = accuracy_score(y_test, predictions) print(f'Accuracy: {accuracy}')
2. 无监督学习 (Unsupervised Learning):
- 定义: 无监督学习涉及从未标记的数据中学习数据的结构、模式或分布。训练数据不包含目标变量。
- 例子: 聚类和降维是无监督学习的例子。例如,K均值聚类和主成分分析(PCA)。
- 代码:
-
from sklearn.cluster import KMeans from sklearn.datasets import make_blobs import matplotlib.pyplot as plt# 创建一个带有明显簇结构的合成数据集 X, _ = make_blobs(n_samples=300, centers=4, cluster_std=1.0, random_state=42)# 使用K均值进行聚类 kmeans = KMeans(n_clusters=4) kmeans.fit(X)# 预测每个样本的簇标签 labels = kmeans.predict(X)# 可视化聚类结果 plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis') plt.title('K-Means Clustering') plt.show()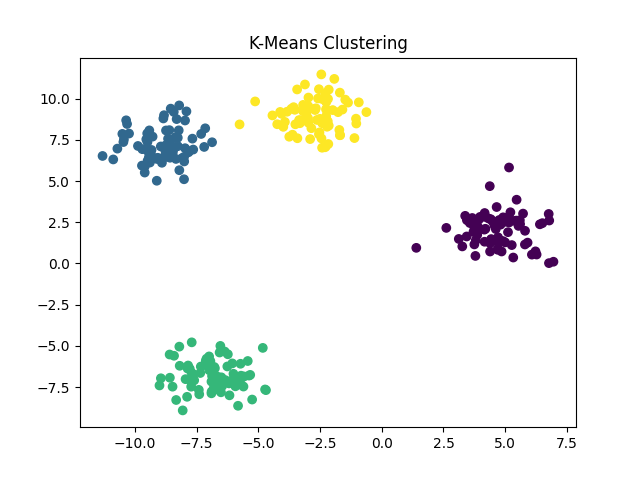
3. 强化学习 (Reinforcement Learning):
- 定义: 强化学习是一种通过观察环境、执行动作并从奖励中学习的学习方式。它旨在使智能体(agent)在环境中学会采取一系列动作,以最大化累积奖励。
- 例子: AlphaGo 是一个著名的强化学习应用,通过与自己下围棋的对局进行训练,最终成为世界冠军。
- 代码:
-
# 强化学习示例代码通常涉及使用专门的库(如TensorFlow、PyTorch)和环境(如OpenAI Gym)。 # 以下是一个简化的伪代码示例:# 伪代码示例 # 创建环境 env = ...# 创建智能体 agent = ...# 迭代训练 for episode in range(num_episodes):state = env.reset()total_reward = 0# 迭代每个时间步while not done:# 智能体选择动作action = agent.choose_action(state)# 执行动作,获取奖励和下一个状态next_state, reward, done, _ = env.step(action)# 智能体学习agent.learn(state, action, reward, next_state)# 更新状态state = next_statetotal_reward += reward# 打印每个周期的总奖励print(f'Episode {episode + 1}, Total Reward: {total_reward}')
4. 半监督学习 (Semi-Supervised Learning):
- 定义: 半监督学习是一种综合了有标签数据和未标签数据的学习方式。模型通过同时使用这两种类型的数据进行训练,以提高性能。
- 例子: 在半监督学习中,可以使用少量带有标签的数据和大量未标签的数据进行模型训练。
- 示例代码:
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score# 加载手写数字数据集
digits = load_digits()
X, y = digits.data, digits.target# 划分数据集,只使用少量带有标签的样本
X_labeled, X_unlabeled, y_labeled, _ = train_test_split(X, y, test_size=0.9, random_state=42)# 创建并拟合模型
model = RandomForestClassifier()
model.fit(X_labeled, y_labeled)# 预测
predictions = model.predict(X_unlabeled)# 评估模型(在半监督学习中,可能需要一些领域专家的帮助来评估性能)# 假设我们有一些手动标记的未标记数据的真实标签
# 在实际应用中,这个步骤可能需要领域专家的帮助
true_labels_for_unlabeled = ...# 评估模型性能(这里简单使用准确度)
accuracy = accuracy_score(true_labels_for_unlabeled, predictions)print(f'Model Accuracy: {accuracy * 100:.2f}%')
在这个例子中,我们假设有一些手动标记的未标记数据的真实标签 (
true_labels_for_unlabeled)。在实际应用中,获取这些标签可能需要领域专家的帮助。评估模型的性能可以使用不同的指标,具体取决于问题的性质。在这里,我们简单地使用准确度作为评估指标。可以根据实际情况选择适当的评估指标。
5. 自监督学习 (Self-Supervised Learning):
- 定义: 自监督学习是一种无监督学习的变体,其中模型通过自动生成标签或任务来学习。这些任务通常是通过对输入数据进行某种变换或转换来生成的。
- 例子: 图像旋转任务是自监督学习的一种示例,模型学会预测图像是否被旋转过。
- 示例代码:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import transforms
from torch.utils.data import DataLoader
from torchvision.datasets import MNIST
import matplotlib.pyplot as plt# 自定义旋转函数
class RotateImage(nn.Module):def __init__(self, degrees):super(RotateImage, self).__init__()self.degrees = degreesdef forward(self, x):return torch.rot90(x, self.degrees, [2, 3])# 构建自监督学习模型
class SelfSupervisedModel(nn.Module):def __init__(self):super(SelfSupervisedModel, self).__init__()self.rescale = nn.functional.rescale_intensityself.rotate = RotateImage(degrees=1)def forward(self, x):x_rotated = self.rotate(x)return torch.cat([x_rotated, x], dim=1)# 超参数
batch_size = 64
learning_rate = 0.001
epochs = 5# 加载MNIST数据集
transform = transforms.Compose([transforms.Grayscale(num_output_channels=1),transforms.ToTensor()])
mnist_dataset = MNIST(root='./data', train=True, download=True, transform=transform)
dataloader = DataLoader(mnist_dataset, batch_size=batch_size, shuffle=True)# 初始化模型、损失函数和优化器
model = SelfSupervisedModel()
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)# 训练模型
for epoch in range(epochs):for data in dataloader:images, _ = data# 梯度清零optimizer.zero_grad()# 前向传播outputs = model(images)# 计算损失loss = criterion(outputs, torch.zeros_like(outputs))# 反向传播loss.backward()# 更新权重optimizer.step()print(f'Epoch [{epoch+1}/{epochs}], Loss: {loss.item()}')# 可视化旋转后的图像
with torch.no_grad():sample = next(iter(dataloader))original_images, _ = samplerotated_images = model.rotate(original_images)plt.figure(figsize=(8, 4))for i in range(4):plt.subplot(2, 4, i + 1)plt.imshow(original_images[i][0], cmap='gray')plt.title('Original')plt.axis('off')plt.subplot(2, 4, i + 5)plt.imshow(rotated_images[i][0], cmap='gray')plt.title('Rotated')plt.axis('off')plt.show()6. 迁移学习 (Transfer Learning):
- 定义: 迁移学习是一种将一个领域中学到的知识应用于另一个领域的学习方式。它通过在源领域上训练的模型或知识来提高在目标领域上的性能。
- 例子: 在自然语言处理中,使用在大型文本语料库上预训练的词嵌入模型(如Word2Vec或GloVe)来改善在特定任务上的性能。
-
代码:使用预训练的词嵌入模型进行情感分析
在自然语言处理中,情感分析是一项常见的任务,涉及判断文本中的情感倾向,如正面、负面或中性。为了提高情感分析任务的性能,可以使用在大型文本语料库上预训练的词嵌入模型,如Word2Vec或GloVe。
import torch
import torch.nn as nn
import torch.optim as optim
from torchtext.vocab import GloVe
from torchtext.data import Field, BucketIterator, TabularDataset# 定义数据处理
TEXT = Field(tokenize='spacy', include_lengths=True)
LABEL = Field(sequential=False, use_vocab=False, dtype=torch.float)# 加载IMDb电影评论数据集(示例数据)
train_data, test_data = TabularDataset.splits(path='./data',train='train.csv',test='test.csv',format='csv',fields=[('text', TEXT), ('label', LABEL)]
)# 构建词汇表,并使用预训练的GloVe词嵌入
TEXT.build_vocab(train_data, vectors=GloVe(name='6B', dim=100))
LABEL.build_vocab(train_data)# 定义神经网络模型
class SentimentClassifier(nn.Module):def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim, n_layers, bidirectional, dropout):super().__init__()self.embedding = nn.Embedding(vocab_size, embedding_dim)self.lstm = nn.LSTM(embedding_dim, hidden_dim, num_layers=n_layers, bidirectional=bidirectional, dropout=dropout, batch_first=True)self.fc = nn.Linear(hidden_dim * 2 if bidirectional else hidden_dim, output_dim)self.dropout = nn.Dropout(dropout)def forward(self, text, text_lengths):embedded = self.embedding(text)packed_embedded = nn.utils.rnn.pack_padded_sequence(embedded, text_lengths, batch_first=True)packed_output, (hidden, cell) = self.lstm(packed_embedded)output, output_lengths = nn.utils.rnn.pad_packed_sequence(packed_output, batch_first=True)hidden = self.dropout(torch.cat((hidden[-2,:,:], hidden[-1,:,:]), dim=1))return self.fc(hidden)# 初始化模型和优化器
model = SentimentClassifier(len(TEXT.vocab), 100, 256, 1, 2, True, 0.5)
model.embedding.weight.data.copy_(TEXT.vocab.vectors)
optimizer = optim.Adam(model.parameters())
criterion = nn.BCEWithLogitsLoss()# 定义数据迭代器
train_iterator, test_iterator = BucketIterator.splits((train_data, test_data),batch_size=64,sort_key=lambda x: len(x.text),sort_within_batch=True,device=torch.device('cuda' if torch.cuda.is_available() else 'cpu')
)# 训练模型
for epoch in range(5):for batch in train_iterator:text, text_lengths = batch.textoptimizer.zero_grad()predictions = model(text, text_lengths).squeeze(1)loss = criterion(predictions, batch.label)loss.backward()optimizer.step()# 在测试集上评估模型
correct_predictions = 0
total_samples = 0with torch.no_grad():for batch in test_iterator:text, text_lengths = batch.textpredictions = model(text, text_lengths).squeeze(1)rounded_predictions = torch.round(torch.sigmoid(predictions))correct_predictions += (rounded_predictions == batch.label).sum().item()total_samples += len(batch.label)accuracy = correct_predictions / total_samples
print(f'Test Accuracy: {accuracy * 100:.2f}%')
这些机器学习范式代表了不同的学习方法和应用领域。在实际应用中,选择适当的学习范式取决于任务的性质、可用的数据以及问题的复杂性。在许多情况下,研究人员和从业者会结合这些范式,以满足特定应用的需求。
7 机器学习范式应用分析
(1) 监督学习(Supervised Learning):
- 应用: 在许多领域中广泛应用,如图像分类、语音识别、自然语言处理等。通过提供带有标签的训练数据,模型学习从输入到输出的映射关系。
- 对比: 需要大量标记数据,对新领域的适应能力有限,对标签噪声敏感。
(2) 无监督学习(Unsupervised Learning):
- 应用: 在聚类、降维、异常检测等任务中有应用。无需标签,模型试图从数据中学到结构、模式或分布。
- 对比: 对于某些任务,无监督学习可能更具通用性,但结果的解释性可能较差。
(3)强化学习(Reinforcement Learning):
- 应用: 在游戏、机器人控制、自动驾驶等领域有应用。智能体通过与环境互动,根据奖励信号学习如何执行动作以达到最大化累积奖励。
- 对比: 需要定义奖励信号,可能需要长时间的训练,对环境的建模和实时决策要求高。
(4)半监督学习(Semi-Supervised Learning):
- 应用: 在当标记数据稀缺时,通过同时使用标记和未标记数据来提高模型性能。在医疗图像分析、网络安全等领域有应用。
- 对比: 比纯监督学习更灵活,但对未标记数据的使用需要谨慎,可能受到未标记数据质量的限制。
(5)自监督学习(Self-Supervised Learning):
- 应用: 在图像、文本等领域中,通过设计任务来生成标签,然后使用这些生成的标签进行训练。在图像领域,如图像旋转任务;在文本领域,如语言模型预训练。
- 对比: 无需人工标签,具有良好的可扩展性和泛化性,适用于大规模数据。
(6) 迁移学习(Transfer Learning):
- 应用: 在一个领域训练的知识被应用到另一个相关领域。在自然语言处理中,使用预训练的词嵌入模型进行情感分析,或在计算机视觉中,使用在大规模图像数据上预训练的卷积神经网络进行图像分类。
- 对比: 可以节省大量训练时间,适用于目标任务数据有限的情况,但前提是源领域和目标领域存在一定的相关性。