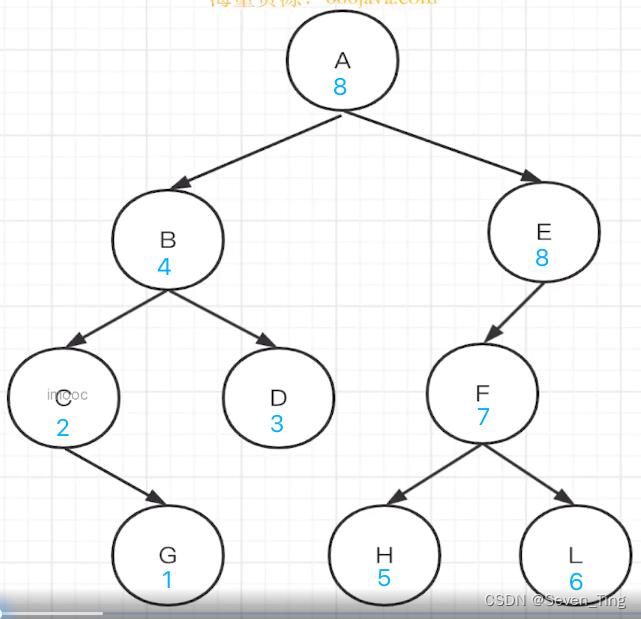
Panda3d 场景管理
文章目录
- Panda3d 场景管理
- 有关分层场景图的重要信息
- NodePath
- NodePath 以及 Node 的函数调用
- 模型文件
- 文件格式
- 加载模型文件
- 将模型放置在场景图中
- 模型缓存
- 压缩模型
- 异步加载模型
- 通过回调函数进行
- 常见的状态变化
- 修改节点的位置和姿态
- 改变父级节点
- 改变颜色
- 隐藏和显示
- 存储自定义信息
- 删除节点
- 操纵模型的一部分
- 动画(骨骼动画)模型
- 非动画(环境)模型
- 对场景图进行查找
- 实例化
- 高级实例化
- 实例化:一个重要的警告
- NodePath:指向节点的指针加上唯一的实例 ID
- 模型的详细程度
许多简单的 3D 引擎维护一个 3D 模型列表,然后在每一帧对这些模型进行渲染。在这些简单的引擎中,必须分配一个3D模型(或从磁盘加载它),然后将其插入到要渲染的模型列表中。模型在插入到列表中之前对渲染器不“可见”。
Panda3D稍微复杂一些。它不是维护要呈现的对象列表,而是维护要呈现的对象树。对象在插入树之前对渲染器不可见。
该树由PandaNode的类对象组成。这实际上是许多其他类的父类:ModelNode,GeomNode,LightNode等。在本手册中,我们通常将这些类的对象称为简单的节点,由这些节点组成的树称为场景图。
应用程序中可能有许多场景图。事实上,从技术上讲,任何存在的节点树都是一个独立的场景图。但是为了渲染3D模型,我们通常谈论标准的3D场景图,其根部是一个称为render的节点。
Panda3D还创建了一个用于渲染2D对象的场景图。这用于将文本、图像和 GUI 元素放在 3D 场景的顶部。此场景图位于名为 render2d 的根下,但这将在后面的部分中进一步解释。
有关分层场景图的重要信息
-
可以控制对象在树中的位置。将对象插入树时,可以指定插入对象的位置。您可以移动树的分支。你可以让树尽可能深或尽可能浅。
-
对象的位置是相对于其在树中的父对象指定的。例如,如果您有一顶帽子的 3D 模型,您可能希望指定它始终保持在某个人头部的 3D 模型上方五个单位。将帽子作为头部的子项插入,并将帽子的位置设置为 (0,0,5)。
-
当模型排列在树中时,分配给节点的任何渲染属性都将传播到其子节点。例如,如果指定应使用深度雾渲染给定节点,则其子节点也将使用深度雾渲染,除非您在子级别显式覆盖。
-
Panda3D为树中的每个节点生成边界框。良好的组织层次结构可以加速视锥体和遮挡剔除。如果整个分支的边界框位于视锥体之外,则无需检查子项。
初学者通常选择使他们的树完全平坦——所有东西都直接插入根部下方。这实际上是一个很好的初始设计。最终,您会找到想要为层次结构添加更多深度的理由。但是,在你有明确、具体的理由之前,不要将这个树变得复杂是一个比较明智的行为。
NodePath
场景图的大多数操作都是使用NodePath类执行的。这是一个非常小的对象,包含指向节点的指针以及一些管理信息。现在,您可以忽略管理信息;这将在手册的后面部分进行解释。Panda3D设计师的意图是,你应该将NodePath视为节点的句柄。创建节点的任何函数都会返回引用新创建的节点的NodePath。
NodePath并不完全是指向节点的指针;它是节点的“句柄”。从概念上讲,这几乎是一个没有区别的区别。但是,某些 API 函数要求您传入 NodePath,而其他 API 函数则要求您传入节点指针。正因为如此,尽管它们之间在概念上几乎没有区别,但您仍然需要知道两者都存在。
您可以随时通过调用 nodePath.node() 将 NodePath 转换为“常规”指针。但是,没有明确的方法可以转换回来。这很重要:有时你需要一个NodePath,有时你需要一个节点指针。因此,建议您存储NodePath,而不是节点指针。传递参数时,可能应该传递 NodePath,而不是节点指针。如果需要,被调用方始终可以将 NodePath 转换为节点指针。
NodePath 以及 Node 的函数调用
您可以在 NodePath 上调用许多函数,这些函数适用于任何类型的节点。专用节点类型(如 LODNode 和 Camera)提供了仅适用于该类型的节点的其他方法,您必须在节点本身上调用这些方法。以下是一些各种示例:
# NODEPATH METHODS:myNodePath.setPos(x, y, z)myNodePath.setColor(banana)# LODNODE METHODS:myNodePath.node().addSwitch(1000, 100)myNodePath.node().setCenter(Point3(0, 5, 0))# CAMERA NODE METHODS:myNodePath.node().setLens(PerspectiveLens())myNodePath.node().getCameraMask()永远记住:当你调用NodePath的方法时,你实际上是在它指向的节点上执行一个操作。
在上面的例子中,我们通过首先将 NodePath 转换为节点,然后调用节点方法,这是推荐的做法。
模型文件
在场景中放置几何体的最常见方法是从文件加载几何体。模型文件包含一个节点树,类似于场景图,其下存储了Panda3D可以渲染到屏幕上的实际几何体。
模型文件可以包含静态几何体,但它们也可以包含用于对模型进行动画处理的信息,以及有关模型材质的信息,即。材质是什么颜色,以及这种颜色在照明的影响下如何变化。
Panda3d不区分大模型和小模型。例如,如果虚拟世界在桌子上包含一个咖啡杯,并且桌子位于一个小岛的中间,那么咖啡杯、桌子和岛都是模型:每个都是一块静态的非动画几何体。模型文件还可以包含整个岛屿以及其中包含的所有较小模型。
但是,Panda3D确实区分了动画和非动画几何体。从这个意义上说,“动画”意味着几何形状会改变形状;飞球不会被认为是有生命的,因为它仍然是一个球体。动画模型在动画模型部分有进一步说明;本节仅介绍如何加载非动画几何体。
从文件加载模型并不是将几何图形放在屏幕上的唯一方法。许多引擎提供用于创建地形的工具,并将该地形存储到高度图图像中。Panda3D可以为一种高度图地形生成几何图形;有关详细信息,请参阅地形部分。但是,对于许多简单的场景,使用从文件加载的静态模型比使用动态生成的高度图地形更简单。
文件格式
模型可以以多种文件格式存储。Panda3D自己用于存储模型的原生格式是EGG。这是一种人类可读的格式,包含几何图形及其动画和材质的文本描述。Panda3D提供了多种工具,可以将模型文件从其他格式转换为EGG格式,并以各种方式操作EGG文件。
Panda3D的另一种原生格式是BAM格式,它是Panda3D内部对象结构的二进制表示。因此,加载非常有效。因此,这也是将游戏交付给最终用户时的首选格式。Panda3D 会自动将您的模型转换为 BAM 以进行缓存,或在打包完成的游戏进行分发时。
有一系列插件可用于加载其他格式的模型,例如 glTF 格式,这是行业中广泛使用的格式。有关支持的格式的详细信息,请参阅支持的模型格式。支持常见的格式文件为 .bam, .egg, .gltf, .obj, .dae, .x 等格式文件,并且有 gltf 和 Assimp 相关的插件可以使用。
加载模型文件
加载模型可以使用以下代码:
myNodePath = loader.loadModel("path/to/models/myModel.egg")
此调用可以采用绝对路径或相对路径,但强烈建议仅使用相对路径。这些相对路径使用“模型路径”进行解析,默认情况下设置为主 Python 文件的路径。
请注意,路径始终使用正斜杠(“/”),即使在 Windows 上也是如此。有关文件名的更多信息,请参阅 Panda 文件名语法。
所有调用 Panda3D API 时使用的路径必须遵守 Panda3D 的文件名约定。为了便于移植,Panda3D使用Unix风格的路径名,即使在Microsoft Windows上也是如此。这意味着目录分隔符始终是正斜杠,而不是 Windows 反斜杠字符,并且没有前导驱动器号前缀。(Panda 不是前导驱动器号,而是使用初始单字母目录名称来表示驱动器。
从Windows文件名到 Panda3d 文件名有一个相当简单的转换。在使用 Panda3D 库函数或其中一个 panda 实用程序时,请务必使用 Panda 文件名语法:
# 错误写法loader.loadModel("c:\\Program Files\\My Game\\Models\\Model1.egg")# 正确写法loader.loadModel("/c/Program Files/My Game/Models/Model1.egg")
将 Windows 的文件名格式变成 Panda3d 的文件名路径:
from panda3d.core import Filenamewinfile = "c:\\MyGame\\Model1.egg"pandafile = Filename.fromOsSpecific(winfile)print(pandafile)
将 Panda3d 的文件名格式变成 Windows 的文件名路径:
from panda3d.core import Filenamepandafile = Filename("/c/MyGame/Model1.egg")winfile = pandafile.toOsSpecific()print(winfile)
从 Python 3.6 开始,Filename类与 Python 标准库中的文件系统操作函数完全可互操作。相反,pathlib 路径将在所有接受文件名对象的 Panda3D 调用中无缝工作。
例如,假设您要加载一个模型,并且该模型位于与程序主文件位于同一目录中的“model”目录中。
以下是加载模型的方法:
import sys, osimport direct.directbase.DirectStartfrom panda3d.core import Filename# Get the location of the 'py' file I'm running:mydir = os.path.dirname(os.path.abspath(__file__))# Convert that to panda's unix-style notation.mydir = Filename.fromOsSpecific(mydir)# Now load the model:model = loader.loadModel(mydir / "models/mymodel.egg")
系统或编程语言运行时提供的标准库函数使用特定于操作系统的路径。因此,在使用这些内置函数时,不要忘记将Panda3d路径转换为特定于操作系统的路径。但是,如果Panda的API通过Filename或 VirtualFileSystem类提供等效的功能,建议改用这些功能,因为它们将原生地理解Panda文件名。
首次对特定模型进行此调用时,将读取该模型并将其保存在内存中的表中;在每次后续调用中,模型只是从表中复制,而不是读取文件。
此调用返回一个 NodePath 对象,该对象表示模型的节点树的根。此对象用于进一步操作模型并将其放置在场景图中。
在许多示例中,您将看到省略了扩展名。在这种情况下,Panda3D将自动查找扩展名为.egg的文件。
将模型放置在场景图中
最重要的操作是更改节点的父节点。默认情况下,模型在没有父模型的情况下加载,但需要将其放置在活动的场景图中,以便Panda3D能够找到模型的几何图形并将其渲染到屏幕上。
默认的 3D 场景图称为render,以下是将模型重新设置为此场景图的方法:
myModel.reparentTo(render)
可以将模型重新设置为任何节点(甚至到另一个模型,或不同模型的子部分),而不仅仅是render!重要的是,它被父级化到一个节点,而这个节点本身就是场景图的父级节点,这样Panda3D就可以找到它。否则,模型将保持不可见。
反之则是从场景图中删除模型,可以按如下方式完成:
myModel.detachNode()
模型缓存
第一次加载 EGG 文件时,加载速度很慢。但是,第二次使用相同的 EGG 文件时,它会加载速度很快。这是可能的,因为Panda3D正在悄悄地将EGG文件转换为性能优化的BAM文件。它将这些 BAM 文件存储在称为模型缓存的目录中。下次尝试加载 EGG 文件时,如果磁盘上没有修改,Panda3D 会改为从模型缓存中加载相应的优化 BAM 文件。
此缓存的存储位置取决于您的操作系统。在Windows上,它通常在 C:Users\YourUser\AppData\Local\Panda3D-x.xx(对应安装的版本号) 中找到,而在Linux上,它可以在 ~/.cache/panda3d 中找到。可以使用 Config.prc 文件中的 model-cache-dir 变量控制该位置,也可以通过将此变量设置为空字符串来禁用该位置。或者,也可以通过将 noCache=True 参数传递给 loader.loadModel 函数,来强制模型绕过模型缓存。
压缩模型
由于 EGG 文件是基于文本的,因此它们的大小可能会变得相当大。通常需要以压缩方式存储它们,以便它们占用更少的空间。这可以使用Panda3D附带的pzip实用程序来完成:
pzip model.egg
这将把它变成一个名为“model.egg.pz”的文件,它会小得多。Panda3D将能够在没有任何额外步骤的情况下加载此模型。
要撤消此步骤并将其恢复为原始形式,只需通过punzi程序运行它。
异步加载模型
加载非常大的模型时,有时可能需要一些时间才能完成模型加载。如果在用户与程序交互时执行此操作,则会产生不希望的滞后。为了缓解这种情况,Panda3D可以在后台加载模型,而不会破坏用户体验。
我们已经看到了一种使用 loader.loadModel() 在模型文件中加载模型的基本方法。此调用的主要问题是它在加载模型时阻塞了主线程,这意味着主线程上的所有其他任务(包括 Panda 的渲染任务)都会被阻塞,直到模型完成加载。用户认为这是一个不和谐的滞后,尤其是当应用程序冻结较长时间时。
以下示例演示了加载场景模型的简单方法:
class Game(ShowBase):def __init__(self):ShowBase.__init__(self)self.loadScene()def loadScene(self):text = OnscreenText("Loading…")self.terrainModel = loader.loadModel("terrain")self.terrainModel.reparentTo(render)self.cityModel = loader.loadModel("city")self.cityModel.reparentTo(render)text.destroy()
您可能会注意到Loading…屏幕永远不会出现,因为Panda3D永远没有机会渲染它!我们可以强制Panda3D在创建text对象后渲染框架,但是,任何需要重新渲染的操作(例如调整窗口大小,或alt-tabb切换到另一个应用程序)都会导致窗口变黑,甚至可能提示操作系统警告应用程序没有响应。
显然,这并不能提供良好的用户体验。因此,建议在单独的执行线程中以异步方式加载模型,以便在后台执行加载操作时应用程序可以继续呈现。Panda3D提供了几种方法。
通过回调函数进行
实现异步加载的方法之一是使用 loader.loadModel() 的回调参数。如果回调不是None,则将异步执行模型加载。在这种情况下,loadModel() 将启动后台加载并立即返回。返回值将是一个对象,您可以调用 .cancel() 来取消异步请求。稍后,当请求的模型完成加载时,将使用作为其参数列表传递的 n 个加载模型来调用回调函数。回调可能会立即被调用,甚至在 loadModel() 返回之前。
如果使用回调,还可以指定优先级,该优先级指定此模型相对于所有其他异步加载请求的相对重要性(首先加载较大的数字)。
下面的示例演示如何使用此功能。
class Game(ShowBase):def __init__(self):ShowBase.__init__(self)self.accept('escape', self.quit)self.loadRequest = Noneself.startLoading()def startLoading(self):self.loadingText = OnscreenText("Loading…")self.loadRequest = loader.loadModel(["terrain", "city"], callback=self.finishLoading)def finishLoading(self, models):# Get rid of temporary objectsself.loadRequest = Noneself.loadingText.destroy()del self.loadingText# Process the models that finished loadingself.terrainModel, self.cityModel = modelsself.terrainModel.reparentTo(render)self.cityModel.reparentTo(render)def quit(self):if self.loadRequest:self.loadRequest.cancel()sys.exit()
常见的状态变化
本段中列出了可以对 3D 节点进行的一些最常见的更改。
修改节点的位置和姿态
最常见的两个变化是位置和方向。
myNodePath.setPos(X, Y, Z)myNodePath.setHpr(Yaw, Pitch, Roll)
默认情况下,在 Panda3D 中,X 轴指向右侧,Y 轴指向前方,Z 轴指向上方。对象的旋转通常使用称为 Heading、Pitch 和 Roll(有时在其他包中称为 Yaw、Pitch 和 Roll)的欧拉角来描述 - 这些以度为单位指定角度旋转。(如果您更习惯使用四元数,则setQuat()可以使用该方法将旋转指定为四元数。)
另外也可以统一更改对象的大小,也可以使用不同的 x、y 和 z 值。
myNodePath.setScale(S)
有时单独调整单个方向也会很方便:
myNodePath.setX(X)myNodePath.setY(Y)myNodePath.setZ(Z)myNodePath.setH(H)myNodePath.setP(P)myNodePath.setR(R)myNodePath.setSx(SX)myNodePath.setSy(SY)myNodePath.setSz(SZ)
或者同时进行:
myNodePath.setPosHprScale(X, Y, Z, H, P, R, SX, SY, SZ)
您还可以查询以上任意一项的当前转换信息:
myNodePath.getPos()myNodePath.getX()myNodePath.getY()myNodePath.getZ()
作为一项更高级的功能,您还可以设置或查询特定 NodePath 相对于另一个 NodePath 的位置(或任何上述变换属性)。为此,请将相对 NodePath 指定为第一个参数:
myNodePath.setPos(otherNodePath, X, Y, Z)myNodePath.getPos(otherNodePath)
将 NodePath 作为任何转换 setPos 或 getPos 的第一个参数使其成为相对操作。上面的setPos() 意思是将 myNodePath 设置为相对于 otherNodePath 的位置 (X, Y, Z),也就是说,如果 myNodePath 是 otherNodePath 的子级并且其位置设置为 (X, Y, Z),则 myNodePath 所处的位置。getPos() 如果 myNodePath 是 otherNodePath 的子级,则该调用将返回其位置。
lookAt()方法旋转模型以面向另一个对象;也就是说,它旋转第一个对象,使其 +Y 轴指向第二个对象。请注意,特定模型可能会或可能不会在 +Y 轴向前的情况下生成,因此这不一定使模型“lookAt”给定对象。
myNodePath.lookAt(otherObject)
在场景中导入两个模型, 左边的为self.person, 右边的为 self.person1。

self.person1.lookAt(self.person)
调用lookAt指令如下图所示,self.person1从 -x 轴指向self.person 变成了 +y 轴。

提示
如果您在放置、缩放或旋转节点时遇到困难,您可以使用该 place()功能调出一个小型 GUI,这将为您提供帮助。您需要安装 Tkinter 才能使用它。
可能需要安装以下两个库可能正常使用place功能。
pip3 install tkpip3 install pmw
myNodePath.place()

从上图中可以看出, 在选择好对象,以及对应的父节点之后,就可以对选定的对象进行位置、姿态、比例的调整。另外也可以在上面的菜单栏中中的placer选择Zero ALL 或者Reset ALL 选择复位原先的参数设置。
改变父级节点
最基本的场景图操作之一是更改节点的父节点。加载模型后,您需要至少执行一次此操作,将其置于渲染下以供查看:
myModel.reparentTo(render)
随着您对场景图操作越来越熟悉,您可能会发现自己越来越多地利用深度嵌套的场景图,并且您可能开始将模型作为其他节点的父节点,而不仅仅是render。有时为此目的创建一个空节点很方便,例如,将多个模型分组在一起:
dummyNode = render.attachNewNode("Dummy Node Name")myModel.reparentTo(dummyNode)myOtherModel.reparentTo(dummyNode)
由于节点从其父节点继承其位置信息,因此当您在场景图中重新设置节点的父级时,您可能会无意中更改其在世界中的位置。如果您需要避免这种情况,可以使用特殊变体 wrtReparentTo():
myModel.wrtReparentTo(newParent)
“wrt”前缀代表“相对于”。这种特殊方法的工作方式类似于 reparentTo(),不同之处在于它会自动重新计算 myModel 上的局部变换,以补偿新父级下变换的变化,以便节点最终处于相对于世界的相同位置。
请注意,需要执行的计算 **wrtReparentTo()**是浮点矩阵计算,因此本质上是不精确的。这意味着,如果您 **wrtReparentTo()**在同一节点上重复使用数千次,最终可能会积累足够的数值误差,从而在对象上引入轻微的比例(例如,比例为 1, 1, 0.99999);如果不加以控制,这种误差累计的规模最终可能会变得越来越大。
请注意:初学者往往会过度使用这种方法;wrtReparentTo()除非有真正的理由使用它,否则不应使用它。
改变颜色
颜色变化是另一种常见的改变。颜色值是从 0 到 1 的浮点数,0 为黑色,1 为白色。
myNodePath.setColor(R, G, B, A)
如果模型具有纹理,则它们在某些颜色设置下可能无法区分甚至可见。将颜色设置为白色可能会恢复纹理的可见性,但最好简单地清除当前颜色设置。
myNodePath.clearColor()
请注意,颜色的第四个分量是 Alpha。这通常用来表示透明度,通常为1.0表示对象不透明。如果将 Alpha 设置为 0 到 1 之间的值,则可以使对象淡入不可见。但是,为了尊重 alpha 值,您必须首先启用透明度:
myNodePath.setTransparency(TransparencyAttrib.MAlpha)
setTransparency()的参数通常为 TransparencyAttrib.M_alpha,即普通透明度。您还可以使用显式关闭透明度 TransparencyAttrib.M_none。(其他透明度模式也是可能的,但这是一个更高级的主题。一些较旧的代码可能只为此参数传递 0 或 1,但最好为该模式命名。)如果您没有首先显式启用透明度,则 alpha颜色的分量可以被忽略。确保不要启用不必要的透明度,因为它确实会启用更昂贵的渲染模式。
设置对象的颜色完全替换顶点上的任何颜色。但是,如果您创建了具有每个顶点颜色的模型,您可能更愿意在不丢失每个顶点颜色的情况下调制对象的颜色。为此,有一个setColorScale()变体,它将指示的颜色值乘以对象的现有颜色:
myNodePath.setColorScale(R, G, B, A)
一种用途setColorScale()是将其应用在场景图的顶部(例如渲染)以使整个场景均匀变暗,例如实现淡入黑色效果。
由于 alpha 如此重要,因此还有一种方法可以在不影响其他颜色分量的情况下对其进行缩放:
myNodePath.setAlphaScale(SA)
隐藏和显示
要暂时阻止在所有相机上绘制对象,请使用 hide()和show():
myNodePath.hide()myNodePath.show()
如果您想隐藏一个摄像机的对象而不是另一个摄像机的对象,可以将 hide()和show()命令与以下函数结合使用Camera.
camera1.node().setCameraMask(BitMask32.bit(0))camera2.node().setCameraMask(BitMask32.bit(1))myNodePath.hide(BitMask32.bit(0))myNodePath.show(BitMask32.bit(1))# Now myNodePath will only be shown on camera2...
请注意,使用不带参数的show/hide会弄乱任何带参数的show/hide,要从所有摄像机中隐藏对象,请使用 nodepath.hide(BitMask32.all_on()).
要设置默认相机的相机遮罩,请使用 base.cam,而不是base.camera,因为 base.camera不是实际相机,而是用于容纳相机的虚拟节点。有关如何设置多个摄像头的信息,请参阅相机控制部分。
任何作为隐藏对象的父对象的对象也将被隐藏。但是,您可以调用showThrough()嵌套元素以强制其显示,即使其父节点被隐藏也是如此。
隐藏模型只会导致其停止渲染,但其他操作(例如检查碰撞)仍将继续进行。要完全停用节点及其子节点,您可以调用**stash()和unstash()**方法。
存储自定义信息
此外,通过使用这些函数setTag(), **getTag()**您可以将自己的信息存储在键值对中。例如:
myNodePath.setTag("Key", "value")
您还可以使用**setPythonTag()**具有相同参数的函数将 Python 对象存储为标签。
删除节点
要从场景图中完全删除节点,您可以调用以下命令,它具有清空节点并释放节点占用的内存的效果。仅当您不再使用该节点时才使用它:
myModel.removeNode()
但请注意,这实际上只是调用detachNode()并删除myModel变量而已。如果模型仍然从其他地方引用,比如模型池,它仍然会占用内存。如果需要从内存中释放模型,请使用以下代码:
ModelPool.releaseModel("path/to/model.egg")
操纵模型的一部分
每个模型在加载时都会成为ModelNode场景图中的一个。每一个ModelNode都是有一个或多个GeomNodes组成的,其包含多个多边形的区域。如果您想要操作模型的一部分,例如,如果您想要更改模型的一部分的纹理,则需要一个指向相关 GeomNode 的指针。
为了获得这样的指针,您必须首先确保相关几何图形位于GeomNode中(并且不与所有其他几何图形相交)。换句话说,您必须确保 panda 的优化机制不会导致几何图形与模型其余部分的几何图形合并。虽然通常这种优化是一件好事,但如果您想更改模型特定部分的纹理(例如,只是角色的脸部),您将需要将此几何体分开。
根据模型的类型,您应该使用两种不同的方法来执行此操作。
动画(骨骼动画)模型
如果您的模型通过 3DSMax 或 Maya 等包中的关键帧动画进行动画处理(即您希望通过Actor界面加载的模型类型),那么 Panda 将所有几何体组合成尽可能少的节点是有可能的。为了标记要保持独立的特定几何图形,您应该使用该egg-optchar 程序。
“optchar”这个名称是“optimize character(优化特征)”的缩写,因为 Egg-optchar 程序旨在通过删除未使用和不需要的关节来优化动画角色的运行时性能。然而,除了这种优化之外,它还允许您标记模型的一部分以供以后操作。一旦标记了一个几何体,Panda 的优化机制就不会将其折叠到模型的其余部分中。
第一步是记下建模程序中对象的名称。例如,假设您想要控制模型头部的纹理,并假设该头部在建模程序中标记为“Sphere01”。使用egg-optchar告诉panda“Sphere01”值得分开并标记:
egg-optchar -d outputDir -flag Sphere01=theHead modelFile.egg anim1.egg anim2.egg
请注意,您必须始终同时向 Egg-optchar 提供模型文件及其所有动画文件。这样它就可以检查所有关节并确定哪些关节实际上是动画的;它可以通过一次操作所有文件来去除关节。Egg-optchar 的输出被写入“-d”参数指定的目录中。
“-flag”开关将确保 panda 不会重新排列指定多边形集的几何形状,将其折叠到整个模型中。它还为多边形指定了一个有意义的名称。一旦标记了相关的几何图形,您就可以使用以下find()方法获取指向它的指针:
myModelsHead = myModel.find("**/theHead")
使用此 NodePath,您可以将头部与模型的其余部分分开操作。例如,您可以使用 移动该片段setPos(),或使用 更改其纹理setTexture(),或者就此而言,您可以对任何其他场景图节点执行任何操作。
非动画(环境)模型
其他类型的模型(不包含任何骨架或动画的模型)不会被 Panda 加载器优化,假设模型的层次结构是有意构建的,以最大化剔除。因此,只有某些节点与其他节点组合在一起,因此当您在建模包中作为单独节点建模的对象很可能在您将其加载到 Panda 中时仍然可以使用相同的名称。但 Panda 并不承诺它永远不会将它认为需要组合以达到优化目的的节点折叠在一起,除非你告诉它不要这样做。
在非动画模型的情况下,保护特定节点的方法是将标志插入特定组内的egg文件中。执行此操作的方法取决于您的建模包(并且仍然需要编写此文档)。
对场景图进行查找
获取场景图中深处的特定节点的句柄通常很有用,特别是获取从单个文件加载的模型的子部分。有许多方法专门用于查找固定节点并返回 NodePath。
首先,也是最有用的是ls()命令:
myNodePath.ls()
这只是列出了指定 NodePath 的所有子节点及其所有子节点,依此类推,直到打印出整个子图。它还列出了每个节点上的变换和渲染属性。当您与 Python 交互运行时,这是一个特别有用的命令;这是检查场景图是否符合您的预期的好方法。
find()和findAllMatches()分别返回 NodePath和NodePathCollection。这些方法需要路径字符串作为参数。搜索可以基于名称或类型。在最简单的形式中,该路径由一系列用斜杠分隔的节点名称组成,就像目录路径名一样。创建字符串时,每个组件可以选择包含以下特殊名称之一,而不是节点名称。
| 符号 | 含义 |
|---|---|
| * | 精确匹配任意名称的一个节点 |
| ** | 匹配零个或多个节点的任何序列 |
| +typename | 匹配给定类型或派生给定类型的任何节点 |
| -typename | 完全匹配给定类型的任何节点 |
| =tag | 匹配具有指定标签的任何节点 |
| =tag=value | 匹配标签与指示值匹配的任何节点 |
此外,节点名称本身可能包含标准文件名通配字符,例如 、? 和 [az],这些字符将被视为部分匹配。(事实上,“”特殊名称可以被视为只是这种情况的一种特殊情况。)通配符不能与类型名匹配或标签匹配一起使用,但它们可以用于匹配标签中的标签值。 =标签=值语法。
出现在节点名称开头的特殊字符“@@”表示已经停用的节点。通常,查找不会返回已经停用的节点(但请参阅下面的特殊标志),但如果使用前导 @@ 字符显式命名,则可以找到停用的节点。通过扩展,“@@*”可用于标识任何停用的节点。
例子:
"room//graph"将查找名为“graph”的节点,该节点是未命名节点的子节点,而未命名节点是名为“room”的节点的子节点,而“room”节点是起始路径的子节点。
"**/red*"将查找树中任何位置(起始路径下方)名称以“red”开头的任何节点。
"/+PartBundleNode//head"将在树中任意位置的 PartBundleNode 下面查找名为“head”的节点。
该参数后面还可以跟一个或多个可选控制标志。要使用控制标志,请在参数后添加一个分号,后跟至少一个特殊标志,不带额外的空格或标点符号。
| 符号 | 含义 |
|---|---|
| -h | 不返回隐藏节点 |
| +h | 返回隐藏节点 |
| -s | 除非使用 @@ 显式引用,否则不要返回停用的节点 |
| +s | 即使没有任何明确的 @@ 字符也返回停用的节点 |
| -i | 节点名称比较不区分大小写:大小写必须完全匹配 |
| +i | 节点名称比较不区分大小写:大小写并不重要。这仅影响节点名称的匹配;节点类型和标签字符串始终区分大小写 |
默认标志是+h-s-i.
该**find()**方法搜索与给定路径字符串匹配的单个节点。如果有多个匹配项,该方法将返回最短的匹配项。如果找不到匹配项,它将返回一个空的 NodePath。另一方面,**findAllMatches()**将返回找到的所有 NodePath,最短的优先。
myNodePath.find("<Path>")myNodePath.findAllMatches("<Path>")
一些例子:
myNodePath.find("house/door")
这将查找名为“door”的节点,该节点是名为“house”的节点的子节点,而“house”节点是起始路径的子节点。
myNodePath.find("**/red*")
这将查找树中任何位置(起始路径下方)名称以“red”开头的任何节点。
shipNP.findAllMatches("**/=type=weaponMount")
这将使用标签/值递归搜索shipNP。标签名称为“type”,标签值为“weaponMount”。所有找到的匹配项都将被返回。
除此之外还有方法**getParent()**和 getChildren()。**getParent()**返回父节点的 NodePath。**getChildren()**将当前节点的子节点返回为NodePathCollection。
NodePathCollection 可以像任何 Python 序列一样对待:
for child in myNodePath.getChildren():print(child)
有关详细信息和 NodePath 函数的完整列表,请参阅 NodePathAPI 参考中的页面。
实例化
在音乐剧《合唱队》中,最著名的场景是大约50名长相一模一样的年轻女子在舞台上从左到右排成一排,她们齐声左踢右踢。要在 Panda3D 中实现此功能,您可以这样做:
for i in range(50):dancer = Actor.Actor("chorus-line-dancer.egg", {"kick":"kick.egg"})dancer.loop("kick")dancer.setPos(i*5,0,0)dancer.reparentTo(render)
这是我们刚刚创建的场景图:

这个效果很好,但是有点耗费资源。模型动画涉及大量的逐顶点矩阵计算。在本例中,我们使用 50 个完全相同的动画副本来制作 50 个完全相同模型的动画副本。这是很多多余的计算。看来必须有某种方法来避免计算完全相同的值 50 次。这种技术称为实例化。
这个想法是这样的:不创建 50 个独立的dancer,而只创建一个dancer,这样引擎只需更新她的动画一次。通过将她插入到场景图中的 50 个不同位置,使引擎渲染她 50 次。这是如何完成的:
dancer = Actor.Actor("chorus-line-dancer.egg", {"kick":"kick.egg"})dancer.loop("kick")dancer.setPos(0,0,0)for i in range(50):placeholder = render.attachNewNode("Dancer-Placeholder")placeholder.setPos(i*5, 0, 0)dancer.instanceTo(placeholder)
这是我们刚刚创建的场景图的图表:

它不再是一棵树,而是一个有向无环图。但渲染器仍然使用递归树遍历算法来遍历图形。结果,它最终遍历了dancer节点 50 次。下面是渲染器对图形进行深度优先遍历的图表。请注意,这不是场景图的图表—它是渲染器通过场景图的路径的图表:

换句话说,渲染器访问dancer 50 次。它甚至没有注意到它访问了同一个dancer 50 次,而不是访问了 50 个不同的dancer。对于渲染器来说都是一样的。
舞台上排列着 50 个placeholder节点。这些称为虚拟节点。它们不包含任何多边形,它们是主要用于组织的小物体。在本例中,使用每个placeholder作为舞者可以站立的平台。
舞者的位置是(0,0,0)。但这是相对于父节点而言的。当渲染器遍历 placeholder 1 的子树时,舞者的位置被视为相对于placeholder 1。当渲染器遍历placeholder 2的子树时,舞者的位置被视为相对于placeholder 1。因此,尽管舞者的位置固定为(0,0,0),它出现在场景中的多个位置(在每个placeholder的顶部)。
通过这种方式,可以多次渲染模型,而无需多次存储和动画化它。
高级实例化
现在,让我们更进一步:
dancer = Actor.Actor("chorus-line-dancer.egg", {"kick":"kick.egg"})dancer.loop("kick")dancer.setPos(0,0,0)chorusline = NodePath('chorusline')for i in range(50):placeholder = chorusline.attachNewNode("Dancer-Placeholder")placeholder.setPos(i*5,0,0)dancer.instanceTo(placeholder)
这与之前的代码完全相同,只是没有将 50 个placeholder放在下方,而是将它们放在名为chorusline的虚拟节点下方 。所以dancer还不是场景图的一部分。现在,可以这样做:
for i in range(3):placeholder = render.attachNewNode("Line-Placeholder")placeholder.setPos(0,i*10,0)chorusline.instanceTo(placeholder)
这是我刚刚创建的场景图:

但是,当渲染器使用递归树遍历算法遍历它时,它将看到 3 个主要子树(以line-placehold为根),每个子树将包含 50 个placehold和 50 个dancer,总共 150 个dancer。
实例化:一个重要的警告
在对模型进行动画处理时,实例化可以为 panda 节省大量 CPU 时间。但这并不能改变渲染器仍然需要渲染模型 150 次的事实。如果dancer是 1000 个多边形模型,那仍然是 150,000 个多边形。
请注意,每个实例都有自己的边界框,每个边界框都是单独进行遮挡剔除和视锥体剔除的。
NodePath:指向节点的指针加上唯一的实例 ID
如果有一个指向合唱队舞者模型的指针,并且我试图问“舞者在哪里”这个问题,那么就不会有明确的答案。舞者不在一个地方,她在150个地方。因此,指向节点的数据类型指针没有检索网络变换的方法。
这是非常不方便的。能够询问“这个物体位于哪里”是基础。还有其他非常有用的查询,由于实例化而无法执行。例如,您无法获取节点的父节点。您无法确定其全局颜色或任何其他全局属性。所有这些查询都是不明确定义的,因为单个节点可以有许多位置、许多颜色、许多父节点。然而这些询问是必不可少的。因此,Panda3D 设计人员有必要想出某种方法来执行这些查询,即使一个节点可以同时位于多个位置。
该解决方案基于以下观察:如果我有一个指向合唱排舞者模型的指针,并且我还有一个唯一标识符,可以将 150 个实例之一与所有其他实例区分开来,那么我可以有意义地请求网络变换该节点的特定实例。
早些时候,人们注意到 NodePath 包含指向节点的指针以及一些管理信息。该管理信息的目的是唯一地标识其中一个实例。Panda3d 没有提供 PandaNode.get_net_transform(),但是提供了NodePath.getNetTransform()。
要了解 NodePath 如何得名,请考虑唯一标识实例所需的条件。上图中的 150 个舞者中的每一个都对应于场景图中的一条路径。对于从根到舞者的每一条可能的路径,场景中都存在一个舞者实例。换句话说,为了唯一地标识一个实例,您需要一个从叶开始一直到根的节点列表。
NodePath 中的管理信息是节点列表。您可以使用该方法获取列表中的任何节点NodePath.node(i)。第一个 node(0)是 NodePath 指向的节点。
模型的详细程度
为了使场景看起来尽可能好,建模者通常喜欢将它们制作得非常复杂,这需要模型由大量多边形组成。然而,如果场景中的每个模型都如此详细,Panda3D 将花费大量时间对每一帧进行动画和渲染场景,从而导致性能下降。
防止这种情况的常用技术是为模型创建多个细节级别。当模型靠近相机时,使用高度详细的模型版本,而如果模型距离相机很远,则使用较低分辨率的版本,因为无论如何在很远的距离处都无法辨别细节。
另一种用途是将多个小对象组合成一个简化的单个对象,或者应用在更远的距离处渲染成本更低的着色器。LOD 还可用于隐藏远处的对象。
要创建LODNodeand NodePath:
lod = LODNode('my LOD node')lod_np = NodePath(lod)lod_np.reparentTo(render)
要向 LODNode 添加详细级别:
lod.addSwitch(50.0, 0.0)my_model.reparentTo(lod_np)
my_model 可以是您喜欢的任何 NodePath。
请注意,第一个参数是该 LOD 将消失的“远”距离,第二个参数是它出现的“近”距离。
继续此模式可以添加任意数量的细节级别。对于最低级别的细节,最远的距离将是模型消失的地方。如果您希望即使在很远的地方它也保持可见,那么对于远距离使用足够大的数字。
请注意,添加开关的顺序必须与将 LOD 重新设置为 LODNode 的 NodePath 的父级的顺序相同。如果您在添加开关后不立即重新设置 LOD 的父级,请务必记住这一点。