TreeMap 是一个基于 key 有序的 key value 散列表。
- map 根据其键的自然顺序排序,或者根据 map 创建时提供的 Comparator 排序
- 不是线程安全的
- key 不可以存入null
- 底层是基于红黑树实现的
TreeMap 的类结构图:
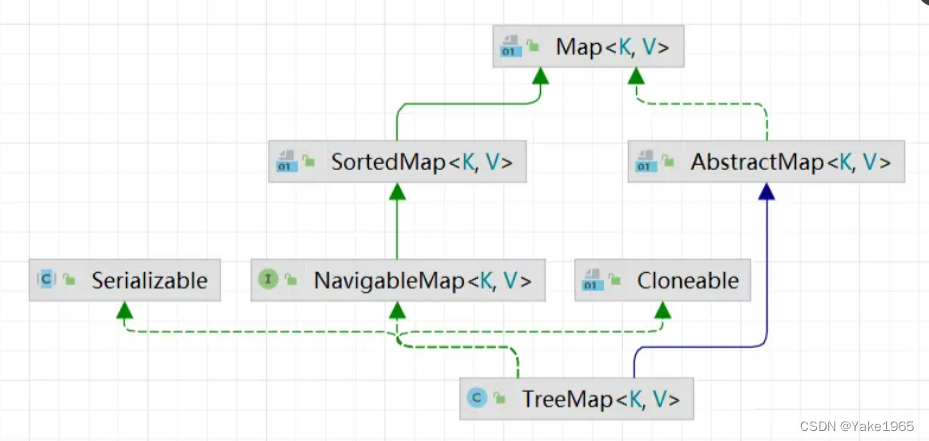
- 实现了 NavigableMap 接口,NavigableMap 又实现了Map接口,提供了导航相关的方法。
- 继承了 AbstractMap,该方法实现 Map 操作的骨干逻辑。
- 实现了 Cloneable 接口,标记该类支持 clone 方法复制
- 实现了 Serializable 接口,标记该类支持序列化
构造方法
TreeMap() // 使用键的自然排序构造一个新的空树映射。
TreeMap(Comparator<? super K> comparator) // 构造一个新的空树映射,根据给定的比较器排序。
TreeMap(Map<? extends K,? extends V> m) // 构造一个新的树映射,包含与给定映射相同的映射,按照键的自然顺序排序。
TreeMap(SortedMap<K,? extends V> m) // 构造一个新的树映射,包含相同的映射,并使用与指定排序映射相同的顺序。
关键方法
SortedMap 接口:
Comparator<? super K> comparator() // 返回用于排序此映射中的键的比较器,如果此映射使用其键的自然排序,则返回 null。
Set<Map.Entry<K,V>> entrySet() // 返回此映射中包含的映射的 Set 视图。
K firstKey() // 返回当前映射中的第一个(最低)键。
K lastKey() // 返回当前映射中的最后(最高)键。
NavigableMap 接口:
Map.Entry<K,V> ceilingEntry(K key) 返回与大于或等于给定键的最小键相关联的键值映射,如果没有这样的键则返回 null。
K ceilingKey(K key) 返回大于或等于给定键的最小键,如果没有这样的键,则返回 null。
NavigableMap<K,V> descendingMap() 返回此映射中包含的映射的倒序视图。
Map.Entry<K,V> firstEntry() 返回与该映射中最小的键关联的键值映射,如果映射为空,则返回 null。
Map.Entry<K,V> floorEntry(K key) 返回与小于或等于给定键的最大键相关联的键值映射,如果没有这样的键则返回 null。
SortedMap<K,V> headMap(K toKey) 返回该映射中键严格小于 toKey 的部分的视图。
Map.Entry<K,V> higherEntry(K key) 返回与严格大于给定键的最小键关联的键值映射,如果没有这样的键,则返回 null。
Map.Entry<K,V> lastEntry() 返回与此映射中最大键关联的键值映射,如果映射为空,则返回 null。
Map.Entry<K,V> lowerEntry(K key) 返回与严格小于给定键的最大键关联的键值映射,如果没有这样的键,则返回 null。
Map.Entry<K,V> pollFirstEntry() 删除并返回与该映射中最小的键关联的键值映射,如果映射为空,则返回 null。
Map.Entry<K,V> pollLastEntry() 删除并返回与此映射中最大键关联的键值映射,如果映射为空,则返回 null。
SortedMap<K,V> subMap(K fromKey, K toKey) 返回该映射中键范围从 fromKey(包含)到 toKey(独占)的部分的视图。
SortedMap<K,V> tailMap(K fromKey) 返回该映射中键大于或等于 fromKey 的部分的视图。
验证顺序性
@Testpublic void test1() {Map<Integer, String> treeMap = new TreeMap<>();treeMap.put(16, "a");treeMap.put(1, "b");treeMap.put(4, "c");treeMap.put(3, "d");treeMap.put(8, "e");// 遍历System.out.println("默认排序:");treeMap.forEach((key, value) -> {System.out.println("key: " + key + ", value: " + value);});// 构造方法传入比较器Map<Integer, String> tree2Map = new TreeMap<>((o1, o2) -> o2 - o1);tree2Map.put(16, "a");tree2Map.put(1, "b");tree2Map.put(4, "c");tree2Map.put(3, "d");tree2Map.put(8, "e");// 遍历System.out.println("倒序排序:");tree2Map.forEach((key, value) -> {System.out.println("key: " + key + ", value: " + value);});}
验证不能存储 null
@Testpublic void test2() {Map<Integer, String> treeMap = new TreeMap<>();treeMap.put(null, "a");}
验证 NavigableMap 相关方法
@Testpublic void test3() {NavigableMap<Integer, String> treeMap = new TreeMap<>();treeMap.put(16, "a");treeMap.put(1, "b");treeMap.put(4, "c");treeMap.put(3, "d");treeMap.put(8, "e");// 获取大于等于 5 的 keyInteger ceilingKey = treeMap.ceilingKey(5);System.out.println("ceilingKey 5 is " + ceilingKey);// 获取最大的 keyInteger lastKey = treeMap.lastKey();System.out.println("lastKey is " + lastKey);}
核心机制
实现原理
TreeMap 的底层是如何维护 key 的顺序呢?答案就是基于红黑树实现的。
红黑树是一颗 自平衡 的 排序二叉树。
二叉树 很容易理解,就是一棵树分俩叉。
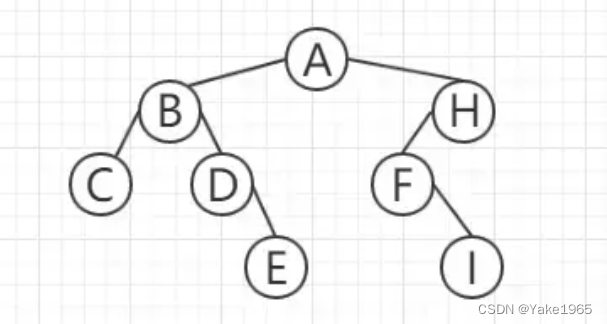
上面这颗就是一颗最普通的二叉树。但是你会发现看起来不那么美观,因为你以 H 为根节点,发现左右两边高低不平衡,高度相差达到了 2。于是出现了平衡二叉树,使得左右两边高低差不多。
平衡二叉树
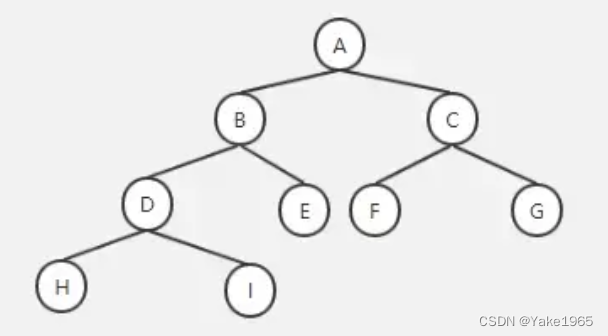
不管是从任何一个字母为根节点,左右两边的深度差不了 2,最多是 1。这就是平衡二叉树。把字母变成数字,还要保持这种特性怎么办呢?于是又出现了平衡二叉排序树。
平衡二叉排序树
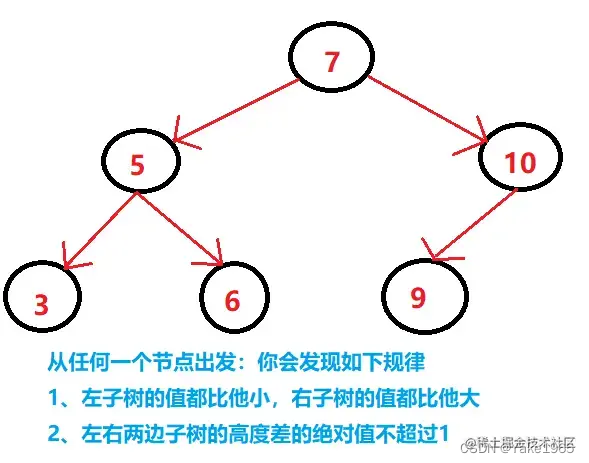
不管是从长相(平衡),还是从规律(排序)感觉这棵树超级完美。但是有一个问题,那就是在增加删除节点的时候,你要时刻去让这棵树保持平衡,需要做太多的工作了,旋转的次数超级多,于是乎出现了红黑树。
红黑树
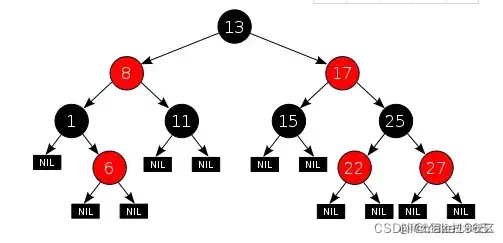
这就是传说中的红黑树,和平衡二叉排序树的区别就是每个节点涂上了颜色,他有下列五条性质:
每个节点都只能是红色或者黑色
根节点是黑色
每个叶节点(NIL节点,空节点)是黑色的。
如果一个结点是红的,则它两个子节点都是黑的。也就是说在一条路径上不能出现相邻的两个红色结点。
从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
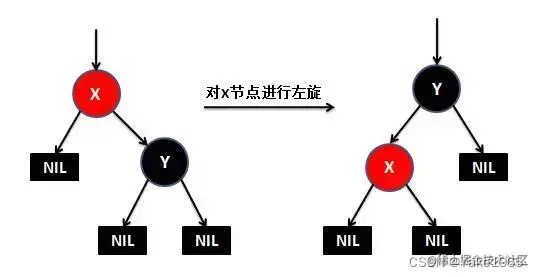
这些性质有什么优点呢?就是插入效率超级高。因为在插入一个元素的时候,最多只需三次旋转,O(1)的复杂度,但是有一点需要说明他的查询效率略微逊色于平衡二叉树,因为他比平衡二叉树会稍微不平衡最多一层,也就是说红黑树的查询性能只比相同内容的avl树最多多一次比较。如何去旋转呢?如下图所示。
首先是左旋:
然后是右旋:
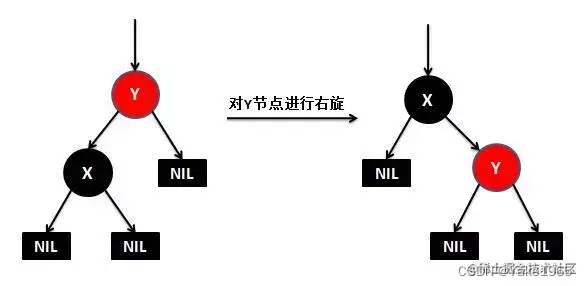
红黑树更详细的内容可以参考这篇文章:segmentfault.com/a/119000001…
源码解析
成员变量
//这是一个比较器,方便插入查找元素等操作
private final Comparator<? super K> comparator;
//红黑树的根节点:每个节点是一个Entry
private transient Entry<K,V> root;
//集合元素数量
private transient int size = 0;
//集合修改的记录
private transient int modCount = 0;
comparator是一个排序器,作为key的排序规则
root是红黑树的根节点,说明的确底层用的红黑树作为数据结构。
static final class Entry<K,V> implements Map.Entry<K,V> {K key;V value;//左子树Entry<K,V> left;//右子树Entry<K,V> right;//父节点Entry<K,V> parent;//每个节点的颜色:红黑树属性。boolean color = BLACK;Entry(K key, V value, Entry<K,V> parent) {this.key = key;this.value = value;this.parent = parent;}public K getKey() {return key;}public V getValue() {return value;}public V setValue(V value) {V oldValue = this.value;this.value = value;return oldValue;}public boolean equals(Object o) {if (!(o instanceof Map.Entry))return false;Map.Entry<?,?> e = (Map.Entry<?,?>)o;return valEquals(key,e.getKey()) && valEquals(value,e.getValue());}public int hashCode() {int keyHash = (key==null ? 0 : key.hashCode());int valueHash = (value==null ? 0 : value.hashCode());return keyHash ^ valueHash;}public String toString() {return key + "=" + value;}}
查找get方法
TreeMap基于红黑树实现,而红黑树是一种自平衡二叉查找树,所以 TreeMap 的查找操作流程和二叉查找树一致。二叉树的查找流程是这样的,先将目标值和根节点的值进行比较,如果目标值小于根节点的值,则再和根节点的左孩子进行比较。如果目标值大于根节点的值,则继续和根节点的右孩子比较。在查找过程中,如果目标值和二叉树中的某个节点值相等,则返回 true,否则返回 false。TreeMap 查找和此类似,只不过在 TreeMap 中,节点(Entry)存储的是键值对<k,v>。在查找过程中,比较的是键的大小,返回的是值,如果没找到,则返回null。TreeMap 中的查找方法是get。
public V get(Object key) {//调用 getEntry方法查找Entry<K,V> p = getEntry(key);return (p==null ? null : p. value);
}final Entry<K,V> getEntry(Object key) {/ 如果比较器为空,只是用key作为比较器查询if (comparator != null) return getEntryUsingComparator(key);if (key == null)throw new NullPointerException();Comparable<? super K> k = (Comparable<? super K>) key;// 取得root节点Entry<K,V> p = root;//核心来了:从root节点开始查找,根据比较器判断是在左子树还是右子树while (p != null) {int cmp = k.compareTo(p.key );if (cmp < 0)p = p. left;else if (cmp > 0)p = p. right;elsereturn p;}
插入put方法
我们来看下关键的插入方法,在插入时候是如何维护key的。
public V put(K key, V value) {Entry<K,V> t = root;// 1.如果根节点为 null,将新节点设为根节点if (t == null) {compare(key, key); // type (and possibly null) checkroot = new Entry<>(key, value, null);size = 1;modCount++;return null;}//如果root不为null,说明已存在元素 int cmp;Entry<K,V> parent;// split comparator and comparable pathsComparator<? super K> cpr = comparator;//如果比较器不为null 则使用比较器if (cpr != null) {//找到元素的插入位置do {parent = t;cmp = cpr.compare(key, t.key);//当前key小于节点key 向左子树查找if (cmp < 0)t = t.left;//当前key大于节点key 向右子树查找else if (cmp > 0)t = t.right;else//相等的情况下 直接更新节点值return t.setValue(value);} while (t != null);}//如果比较器为null 则使用默认比较器else {//如果key为null 则抛出异常if (key == null)throw new NullPointerException();@SuppressWarnings("unchecked")Comparable<? super K> k = (Comparable<? super K>) key;//找到元素的插入位置do {parent = t;cmp = k.compareTo(t.key);if (cmp < 0)t = t.left;else if (cmp > 0)t = t.right;elsereturn t.setValue(value);} while (t != null);}Entry<K,V> e = new Entry<>(key, value, parent);//根据比较结果决定插入到左子树还是右子树if (cmp < 0)parent.left = e;elseparent.right = e;//保持红黑树性质,进行红黑树的旋转等操作fixAfterInsertion(e);size++;modCount++;return null;}
比较关键的就是fixAfterInsertion方法, 看懂这个方法需要你对红黑树的机制比较了解。
private void fixAfterInsertion(Entry<K,V> x) {// 将新插入节点的颜色设置为红色x. color = RED;// while循环,保证新插入节点x不是根节点或者新插入节点x的父节点不是红色(这两种情况不需要调整)while (x != null && x != root && x. parent.color == RED) {// 如果新插入节点x的父节点是祖父节点的左孩子if (parentOf(x) == leftOf(parentOf (parentOf(x)))) {// 取得新插入节点x的叔叔节点Entry<K,V> y = rightOf(parentOf (parentOf(x)));// 如果新插入x的父节点是红色if (colorOf(y) == RED) {// 将x的父节点设置为黑色setColor(parentOf (x), BLACK);// 将x的叔叔节点设置为黑色setColor(y, BLACK);// 将x的祖父节点设置为红色setColor(parentOf (parentOf(x)), RED);// 将x指向祖父节点,如果x的祖父节点的父节点是红色,按照上面的步奏继续循环x = parentOf(parentOf (x));} else {// 如果新插入x的叔叔节点是黑色或缺少,且x的父节点是祖父节点的右孩子if (x == rightOf( parentOf(x))) {// 左旋父节点x = parentOf(x);rotateLeft(x);}// 如果新插入x的叔叔节点是黑色或缺少,且x的父节点是祖父节点的左孩子// 将x的父节点设置为黑色setColor(parentOf (x), BLACK);// 将x的祖父节点设置为红色setColor(parentOf (parentOf(x)), RED);// 右旋x的祖父节点rotateRight( parentOf(parentOf (x)));}} else { // 如果新插入节点x的父节点是祖父节点的右孩子和上面的相似Entry<K,V> y = leftOf(parentOf (parentOf(x)));if (colorOf(y) == RED) {setColor(parentOf (x), BLACK);setColor(y, BLACK);setColor(parentOf (parentOf(x)), RED);x = parentOf(parentOf (x));} else {if (x == leftOf( parentOf(x))) {x = parentOf(x);rotateRight(x);}setColor(parentOf (x), BLACK);setColor(parentOf (parentOf(x)), RED);rotateLeft( parentOf(parentOf (x)));}}}// 最后将根节点设置为黑色root.color = BLACK;
}
删除remove方法
删除remove是最复杂的方法。
public V remove(Object key) {// 根据key查找到对应的节点对象Entry<K,V> p = getEntry(key);if (p == null)return null;// 记录key对应的value,供返回使用V oldValue = p. value;// 删除节点deleteEntry(p);return oldValue;
}
private void deleteEntry(Entry<K,V> p) {modCount++;//元素个数减一size--;// 如果被删除的节点p的左孩子和右孩子都不为空,则查找其替代节if (p.left != null && p. right != null) {// 查找p的替代节点Entry<K,V> s = successor (p);p. key = s.key ;p. value = s.value ;p = s;}Entry<K,V> replacement = (p. left != null ? p.left : p. right);if (replacement != null) { // 将p的父节点拷贝给替代节点replacement. parent = p.parent ;// 如果替代节点p的父节点为空,也就是p为跟节点,则将replacement设置为根节点if (p.parent == null)root = replacement;// 如果替代节点p是其父节点的左孩子,则将replacement设置为其父节点的左孩子else if (p == p.parent. left)p. parent.left = replacement;// 如果替代节点p是其父节点的左孩子,则将replacement设置为其父节点的右孩子elsep. parent.right = replacement;// 将替代节点p的left、right、parent的指针都指向空p. left = p.right = p.parent = null;// 如果替代节点p的颜色是黑色,则需要调整红黑树以保持其平衡if (p.color == BLACK)fixAfterDeletion(replacement);} else if (p.parent == null) { // return if we are the only node.// 如果要替代节点p没有父节点,代表p为根节点,直接删除即可root = null;} else {// 如果p的颜色是黑色,则调整红黑树if (p.color == BLACK)fixAfterDeletion(p);// 下面删除替代节点pif (p.parent != null) {// 解除p的父节点对p的引用if (p == p.parent .left)p. parent.left = null;else if (p == p.parent. right)p. parent.right = null;// 解除p对p父节点的引用p. parent = null;}}}
最终还是落到了对红黑树节点的删除上,需要维持红黑树的特性,做一系列的工作。