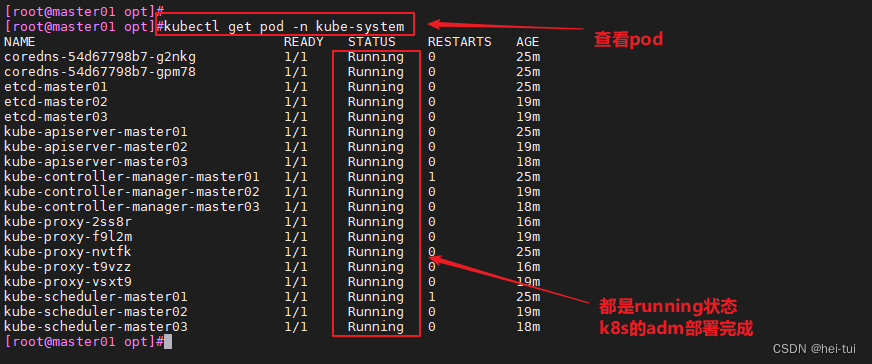
- 一、自然语言处理基基本任务和应用
- 1、自然语言处理的基本任务
- 2、搜索引擎的基本工作原理
- 3、知识图谱的构建
- 4、应用
- 二、词表示与语言模型
- 1、词表示
- 2、上下文
- 3、语言模型
- 4、神经网络在语言模型的应用
- 三、神经网络
- 1、神经网络基本组成元素
- 2、如何训练神经网络
- 3、计算图的概念
- 4、word2vec
一、自然语言处理基基本任务和应用
1、自然语言处理的基本任务
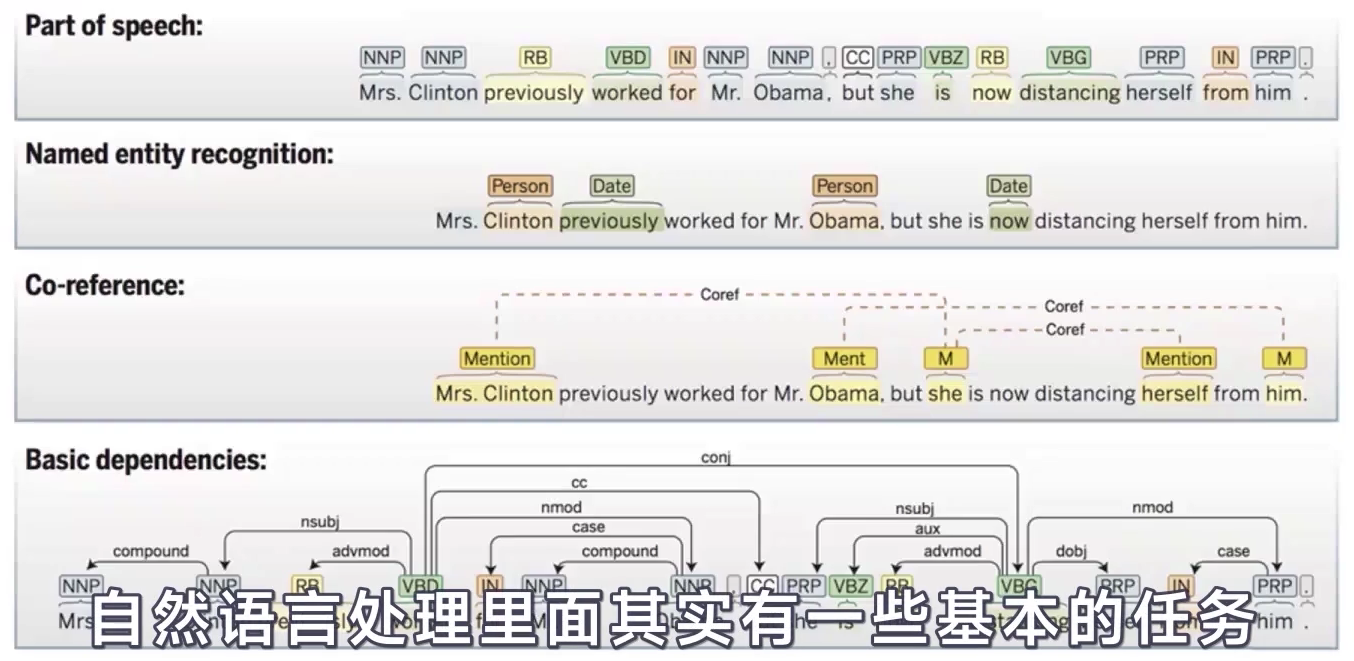
自然语言处理里面其实有一些基本的任务:
- 1、词性标注:将给定话的每一个词的词性进行标注,到底是名词、动词还是形容词。
- 2、命名实体识别:进一步识别出这句话里面名词当中还有哪些是具体的指的是现实世界当中的一些实体。(人名、地名、日期等)
- 3、共体消解:我们要知道这个代词和前面的哪个实体是指向现实世界当中的同一个实体。
- 4、依赖关系:不同成分之间相互依存的关系。
- 由于中文的字与字之间没有空格,因此机器首先要把词分出来,因此需要一个专门的自然语言处理任务——中文的自动分词。
2、搜索引擎的基本工作原理
搜索引起的基本技术:
- 1、匹配用户的query(查询),与所有文档之间的相关度。即:如何匹配query和ducument,匹配之间的语义相似度,能够算出来这个document有多大程度上能够满足这个query的需求。
- 搜索引擎的盈利手段:给定query之后,还可以反馈一些可能需要的广告,一旦用户点击广告,则这个广告商就需要给这个搜索引擎去付费。
- 2、利用互联网之间的链接信息进行评估——涉及数据挖掘与信息检索。
3、知识图谱的构建
- 知识图谱是把全世界一些相关的,关于现实世界的一些实体的关系组成一个大的网络,当用户去做查询的时候,会把匹配到的实体的结构化信息直接呈现给用户。——2012年google推出
- 知识图谱涉及到的关于自然语言处理的问题:(1)用户的查询query如何去匹配或寻找最相关的一些实体和相关的知识。(2)构建图谱需要从大规模的文本里面去挖掘相关的信息。
- 构建好知识图谱以后就可以去回答一些问题。
4、应用
- 指:让机器去自动的阅读大规模文本,从而挖掘出相关的一些结构化知识。
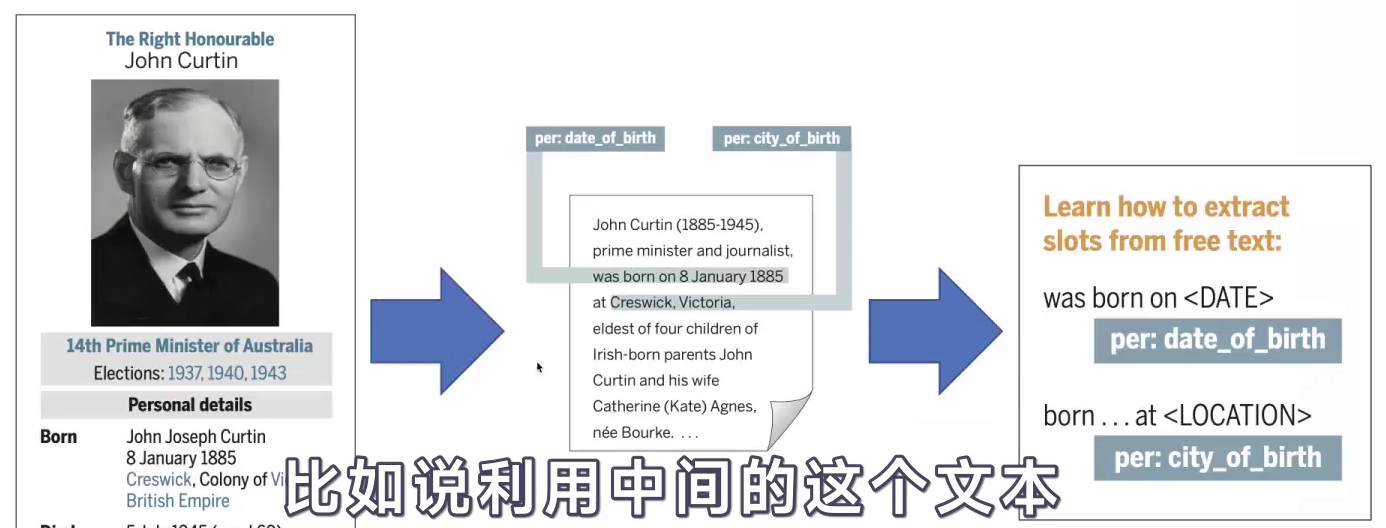
- 从一段文本当中找出三元组
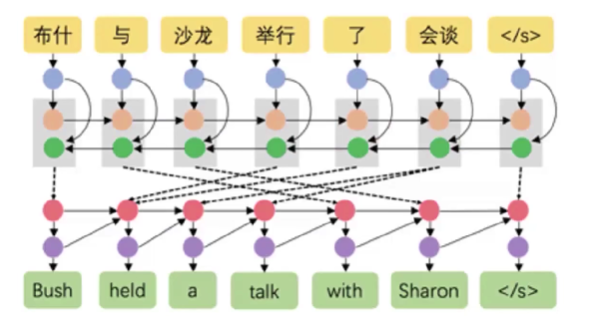
- 机器翻译

- 情感粒度区分(情感分类与意见挖掘)
二、词表示与语言模型
1、词表示
- 词表示:把自然语言里面最基本的语言单位(词),转换成我们机器可以理解的词的含义。即让机器能够理解这个词到底是什么意思。
- 词表示的目标:(1)词之间的相似度计算。(2)知道并发现词和词之间的语义关系。

- 例如:在解释Good这个词的含义的时候,可以用和Good的近义词和反义词去解释。

以上方法存在的问题:
- 1、相近意思的词语无法区分,需要人工标注。
- 2、一些词语有了新的含义:比如苹果(一种水果–>一家公司)
- 3、相近意义的词语受到主观因素
- 4、需要大量的人工来去构建词典。
因此,需要把词表示成一个独立的符号——独热编码。

- 向量的维度和词表的长度是相当的。因此就可以独一无二的把每一个词都表示出来。
- 从而去完成两个文档之间的相似度计算。
又存在什么问题呢?
- 在表示词的时候会存在问题,因为它会假设词和词之间的向量互相之间都是正交的,就会造成任意两个词之间的相似度计算都是零。
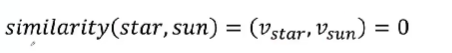
2、上下文
- 利用一个词的上下文的词来表示这个词。


又存在哪些问题? - 1、当这个词表变得越来越大的时候,其实存储的需求就会变得特别大。
- 2、对于出现频率特别少的词,它的整个向量因为它出现的次数少,所以上下文就会比较少。导致上下文出现语境的词会变得很稀疏。导致这个词的表示效果没有那么好。
针对上面的问题,接下来提到的就是深度学习、大语言模型所做的word embedding。
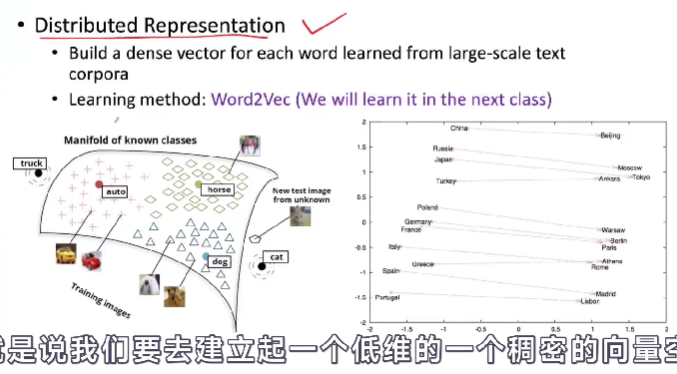 - 提出了一种分布式的表示。我们要去建立起一个低维的一个稠密的向量空间。我们要尝试去把每一个词都学到这个空间里面。用这个空间里面所对应的一个向量来去表示这个词。
- 提出了一种分布式的表示。我们要去建立起一个低维的一个稠密的向量空间。我们要尝试去把每一个词都学到这个空间里面。用这个空间里面所对应的一个向量来去表示这个词。
- 因此前面我们的需求:利用词表示去计算词和词之间的信任度,以及词和词之间的相关关系,都可以利用这种低维的向量来去完成。这种低维的向量可以利用大规模的数据自动去学习的。而在这方面具有代表性的工作就是Word2Vec。
3、语言模型
-
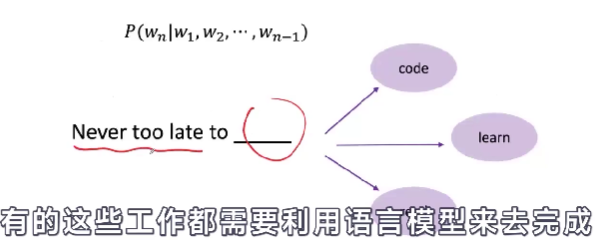
语言模型有能力根据前文去预测下一个词到底是什么。
-
语言模型主要完成的两个工作:1、是能够计算一个词的序列,它成为一句话的概率是多少,即联合概率。看已经有的一个序列,成为合法的一句话的概率是多少?2、根据前面已经说过的这些话,预测它的下一个词是什么?

- 这里还涉及到语言模型的一个基本的假设:我后面产生哪个词只受到前面词的影响。因此我们可以把一个句子的联合概率,拆解成一个一个的条件概率。
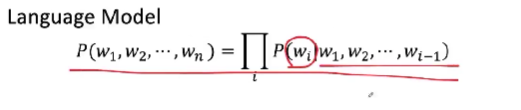
- 因此语言模型的写法:一个句子的联合概率=它里面的每一个词基于它前面的已经出现的词的条件概率之积。
那么接下来需要如何去进行语言模型的构建呢?
- 一个非常典型的做法叫做N-gram:N-gram去统计到底前面出现了几个词之后,后面出现的那个词的频度到底是怎么样。

- 例如上面这个4-gram就可以得到to late to后面跟W_j的概率是多少。
- 其实这个N-gram就是去统计连续出现的序列的频度,利用频度可以去估计前面的词和后面的词出现的概率。(N里面也包含要预测的当前词。因此2gram就是只考虑历史有限的一个长度。)
N-gram的问题
- N-gram的N一般都是2或者3,因为如果N太大就会导致统计结果非常稀疏,同时存储的量会越大。
- N-gram的背后还是独热编码,假设所有的词都是相互独立的。统计都是基于上下文来去进行统计的,没有办法理解上下文的这些词互相之间的相似度是什么。
4、神经网络在语言模型的应用
因此就用到了神经语言模型

- N-gram里面的每一个词都是一个符号,而在Neural Language Model里面每一个词都是一个低维的向量,因此相似的词它们对应的向量也会比较相似。因此会在语境里面发挥相似的作用。
三、神经网络
- 大模型其中的一个能力:具有很强的小样本或者少次学习的能力,可以在大规模的无标注数据上进行模型学习,学完之后模型具备很多知识。这样在解决具体任务的时候,就不太需要很多的样本,只需要少量的样本去告诉模型要做什么任务,以及去引导模型把它的知识,跟这个任务相关的知识给摘取出来,去解决这个问题。
- 当大模型知识量足够大之后,能够直接去从头开始学习的方法。
1、神经网络基本组成元素
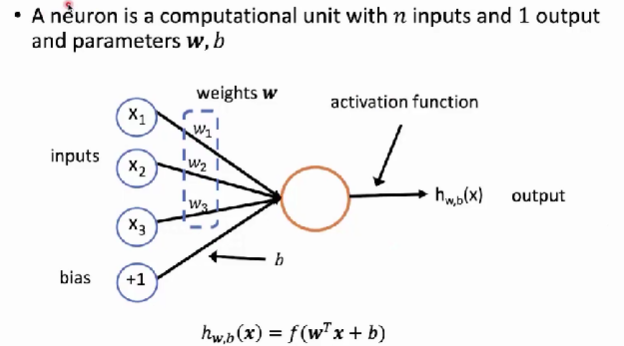
- 神经元接受n个数作为输入,然后产生一个数的输出,它由参数w和b以及激活函数f来构成。
- X 1 X_1 X1, X 2 X_2 X2, X 3 X_3 X3是三个数,作为输入。
- W 1 W_1 W1, W 2 W_2 W2, W 3 W_3 W3是三个权重。
- 偏置,这个维度的输入恒定为1,边的权重为b。这样偏置可以统一到和前面的输入一样的维度当中。
- f是非线性的激活函数。
h w , b ( X ) = f ( w T X + b ) h_{w,b}(X)=f(w^TX+b) hw,b(X)=f(wTX+b)
- 其中 w T X w^TX wTX是向量,在上述例子当中表示的是长度为3的向量。
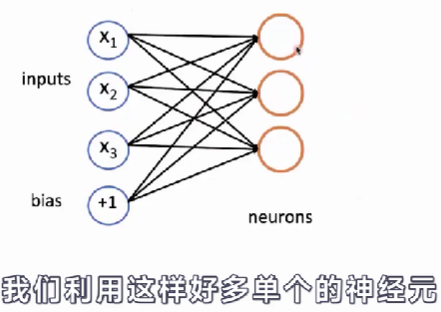
- 我们利用这样的好多单个的神经元,应用到输入的上面,就可以构成一个只有一层的神经网络。

a = f ( W x + b ) a=f(Wx+b) a=f(Wx+b)
- 在上述式子当中,权重从向量变成了一个矩阵,偏置从一个标量变成了一个向量。
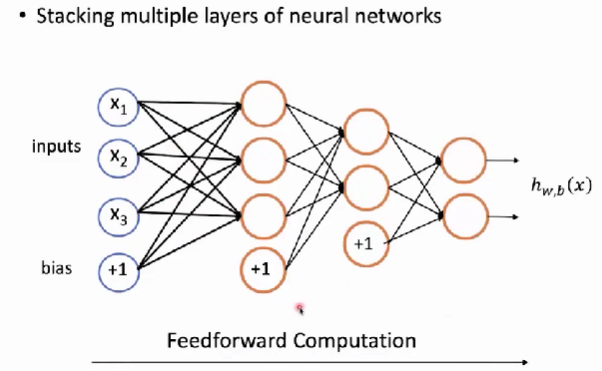
- 将单层的神经网络变成多层的神经网络。
- 通常把这些在输入之上添加的多层网络称之为隐层。
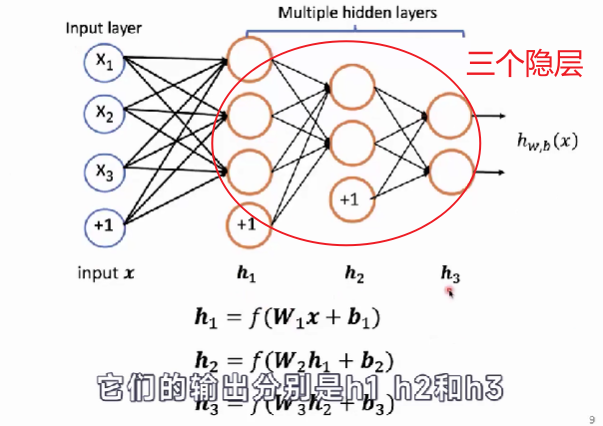
激活函数是干嘛的?
-
如果假设神经网络当中没有激活函数,也就是每一层的操作只是对上一层的输出,运用一个线性变换。那么多层的神经网络其实可以被转化为单层的神经网络。【即多层网络和单层网络的表达能力是一致的。】
-
因此我们需要引入非线性的激活函数,防止多层神经网络坍塌成单一的神经网络。我们也可以增加激活函数的表达能力,来拟合更复杂的函数。

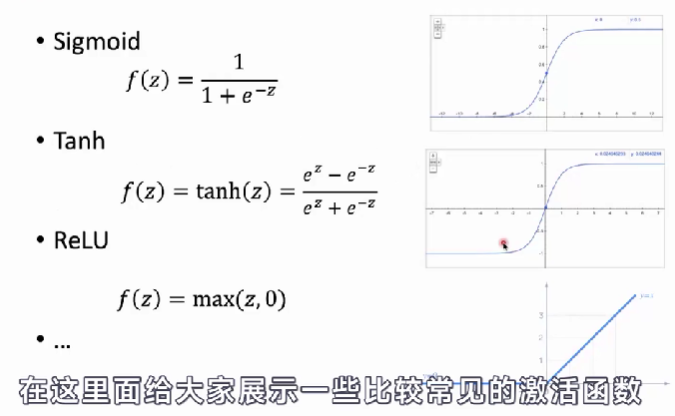
- Sigmoid:可以把一个从负无穷到正无穷的输入,转化为一个0-1之间的数。
- Tanh:把从负无穷到正无穷的输入数据,转化成一个从-1到1之间的数。【特点,如果原来的值是0,则通过激活函数之后的结果也是0。】
- ReLU:对于正数的输入的结果仍然为原来的数,负数输出的结果为0。
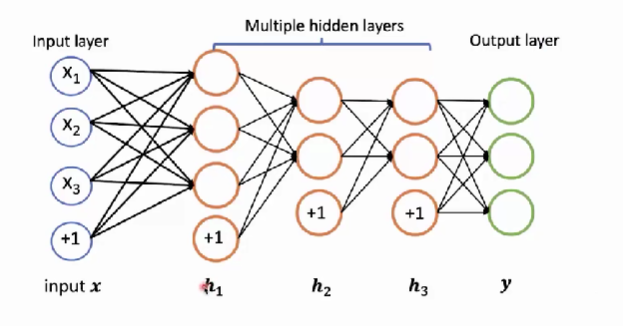
- 在构建神经网络的时候,通过叠加若干个隐层,我们可以提升网络的表达能力。那么我们如何得到我们想要的输出结果?这个时候我们需要添加网络的最后一层,也就是输出层。

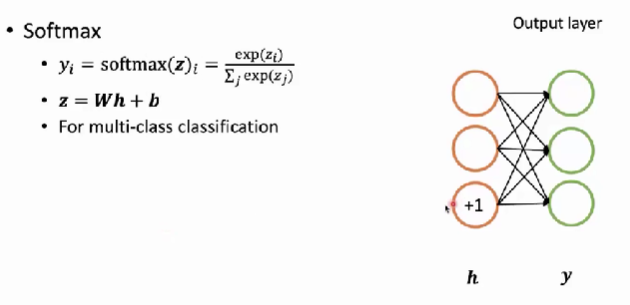
- 输出层有多种形态,取决于你想让模型去输出什么样子的数据。
- linear output:线性输出,这样的输出层直接在我们最后的隐层后面再加一个线性层,从而输出得到一个值。这样的输出层适用于回归问题,也就是运用神经网络去预测一个具体的连续的值。此时可以使用线性的输出层。
- sigmoid:可以让输出的值在0-1之间。通常用来解决二分类问题。
- softmax:用来解决多分类的问题,即分类者的这个类别的数量大于2的情况。比如我们要解决三分类的问题,就让它设置3个输出。
2、如何训练神经网络

-
训练神经网络首先需要一个训练目标。
-
假设我们有若干条训练数据,其中的输入是某个电脑里面的一些属性,比如说它的一些配置之类的,我们希望能够预测出电脑的价格y。这是一个回归问题,希望神经网络根据输入的数据来拟合一个具体的值。在这种情况下,可以以降低均方差【MSE】作为我们的训练目标。

- MSE越小则神经网络的学习越准确。因此我们的目标就是最小化这个值,我们也可以把这个均方差称为我们的损失函数。
- 我们训练损失函数的目标就是去减少我们损失函数的值。

- 如果是文本分类的任务:输入的数据可能是一段文本。我们希望模型去预测比如情感标签这样的东西。情感可以是正面、负面或者中型的。
- 这种时候我们一般使用最小化交叉熵作为我们的训练目标。这里就可以把最小化交叉熵称为我们的损失函数。
- 交叉熵其实是衡量模型正确分类的概率。

- 上面这个输出层当中使用了softmax得到了一个概率分布,分别代表了三个类别的一个概率。
- 损失函数越小,正确类别的预测概率越大,即模型预测越准确。
总结,为了达到我们的训练目标,我们通常是希望最小化一个损失函数。
如何去最小化一个损失函数?
- 通常我们使用的是梯度下降法。把整个优化步骤拆分成若干个步骤。每一步去缩小这个损失函数一点。
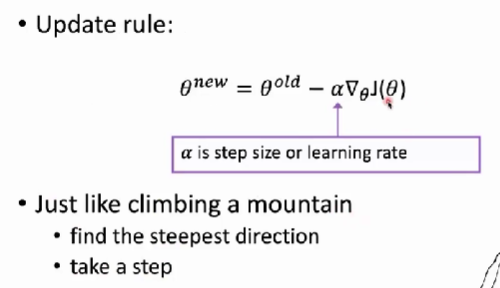
我们如何去调整参数,才能在每一步去缩小这个损失函数?
- 首先要求出:损失函数对于模型参数的梯度。损失函数对于模型参数的梯度代表了对这个参数进行单位大小的改动之后,损失函数变化最快的一个方向。
3、计算图的概念
- 计算图可以让我们把神经网络的计算公式画成一个图。在图里面,原节点代表网络的输入,内部节点代表计算操作。有向边起到传递出来计算的值的作用。
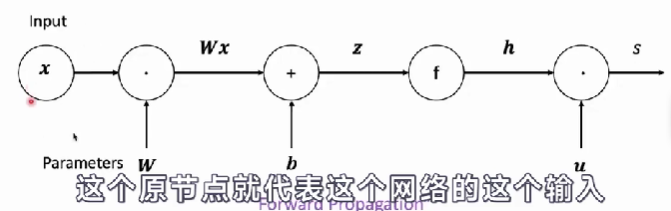 - 在反向传播的过程当中,我们可以使用链式法则。通过本地梯度和上游梯度相乘,然后就可以得到下游梯度,然后向下游进行传播。然后得到这个梯度之后,我们就可以通过梯度下降法,来训练我们的神经网络。
- 在反向传播的过程当中,我们可以使用链式法则。通过本地梯度和上游梯度相乘,然后就可以得到下游梯度,然后向下游进行传播。然后得到这个梯度之后,我们就可以通过梯度下降法,来训练我们的神经网络。
4、word2vec
利用非常简单的神经网络进行训练,就可以得到词向量。即词的一个低维的表示。

word2vec得到的词向量可以反映一些语言的规律:
- 以第一张图片为例:queen-king得到的向量和woman-man得到的向量可以近似平行。也就是我们可以推导出:queen的向量=king-man+woman的向量
- 第二张图片:warking和worked与swiming和swam的关系也是构成了一个近似平行的关系。
- 第三张图片:国家和首都之间的关系都是近似平行的。
word2vec其实只靠非常简单的神经网络就实现了词向量:
word2vec的两类模型:
- CBOW
- Skip-Gram
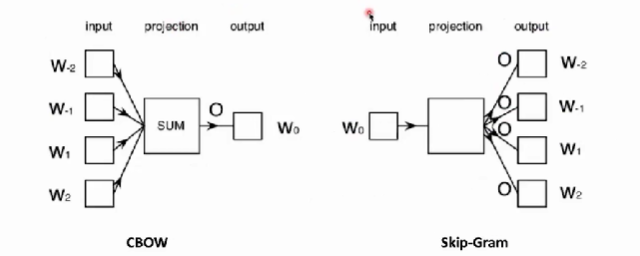
- word2vec使用了滑动窗口来构造训练数据。一个滑动窗口是在一段文本当中连续出现了几个单词,这样的单词构成了一个所谓的窗口。最中间的词叫做Target,即目标词。其他词叫做Context,就是上下文的词。
- CBOW模型就是根据context词来预测目标词这个模型。
- Skip-Gram模型是根据目标词来去预测context词的模型。

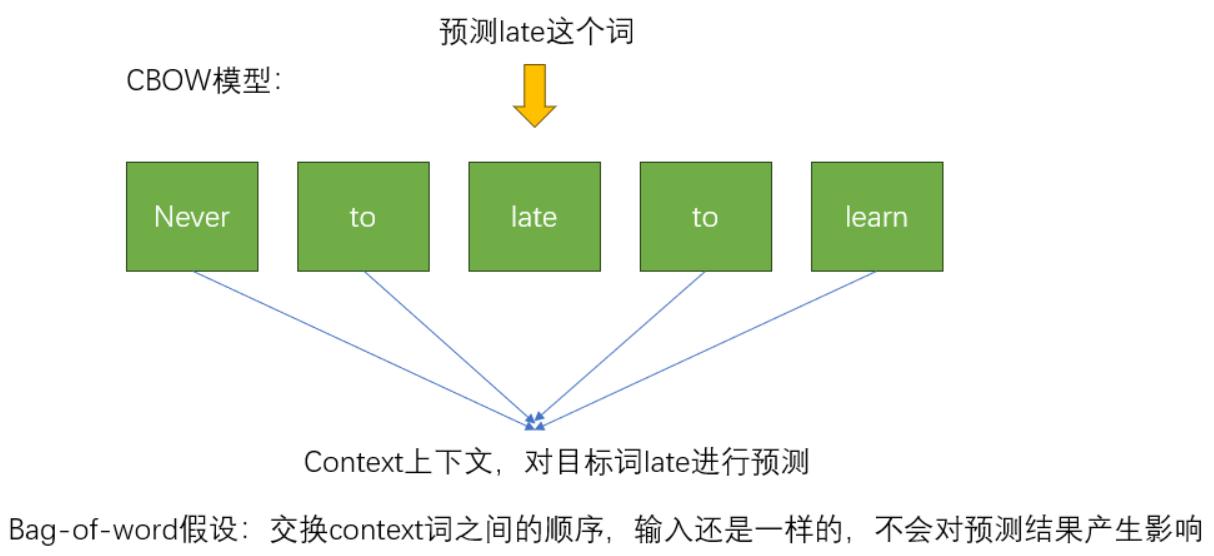
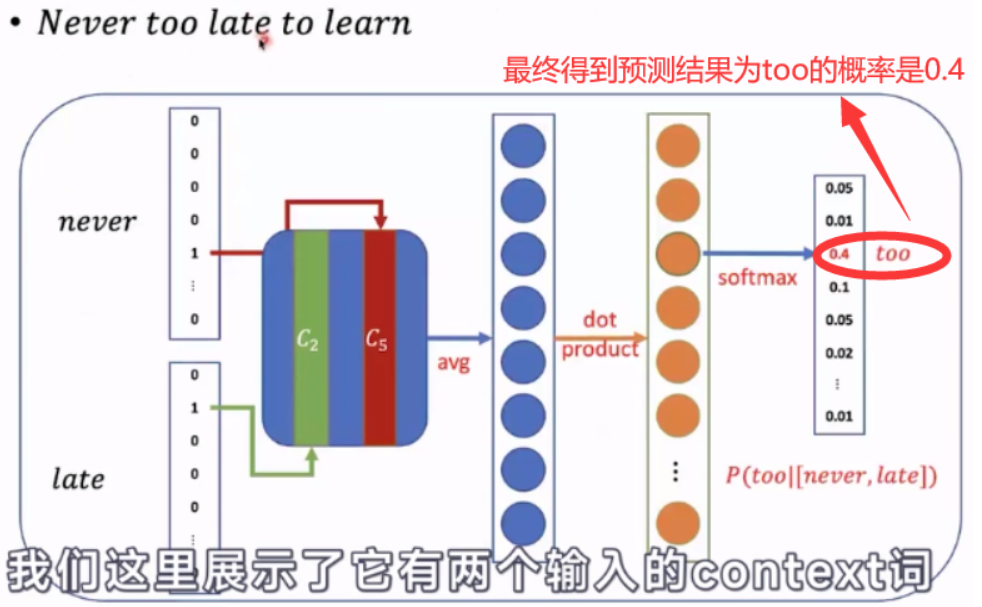
- 上面这张图展示了使用never和late这两个词来去预测too这个词。输入词的数量是根据窗口大小来决定的。
- 通过线性变换把词向量大小维度的向量转化为词表大小,之后在上面使用一个softmax层,之后最终得到的结果是词表大小的概率分布的向量。每一个维度加起来的值是1。

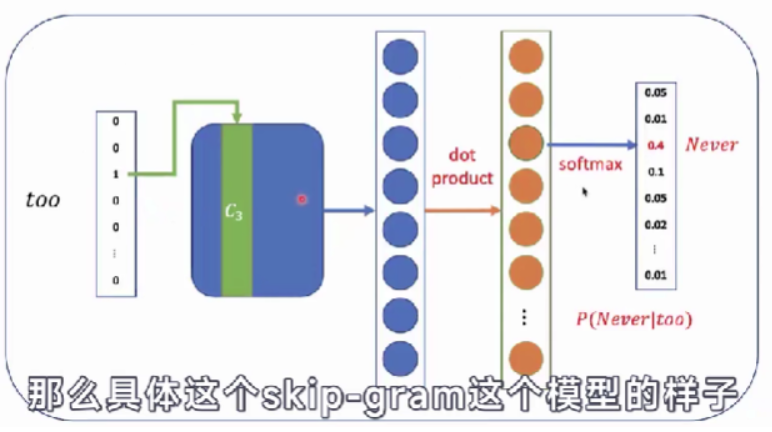
- 对于skip-gram这个模型,通过target去预测输出context。这对于神经网络来说是较难的问题。
- 如果never是target的话,就先让模型去预测输出too,再预测输出late。
如何提高计算效率?
- 实际上词表大小可能是非常大的,这样我们进行全部的softmax,再进行反向传播和梯度下降之后,我们的计算量就会非常大,因此我们需要想办法来提高计算效率。
- 具体来说有两种方法可以提高计算效率:(1)负采样。(2)分层softmax。
负采样:指的是我们不把整个词表做softmax,只采样一小部分作为我们的负例。【不是我们需要预测的词称作负例。】