自回归 (AR) 模型是统计和时间序列模型,用于根据数据点的先前值进行分析和预测。这些模型广泛应用于各个领域,包括经济、金融、信号处理和自然语言处理。
自回归模型假设给定时间变量的值与其过去的值线性相关,这使得它们可用于建模和预测时间相关数据。
自回归 (AR) 模型的定义和意义
自回归模型(通常缩写为 AR 模型)的核心是一种统计和数学框架,用于分析和预测随时间变化的数据。它假设变量在任何给定时间的值都线性依赖于其先前的值。换句话说,自回归模型旨在捕获和量化变量的过去对其现在和未来的影响。
自回归模型的意义在于其通用性和适用性。他们受雇于各个领域,包括经济、金融、气象、工程和自然语言处理。这些模型提供了一种系统的方法来探索时态数据并揭示通过随意观察可能不明显的模式、趋势和关系。
自回归 (AR) 模型的实际应用是什么?
为了理解自回归模型的实际相关性,考虑一些它们发挥关键作用的现实场景会很有帮助:
- 股票市场分析: 金融分析师使用自回归模型根据历史价格走势预测未来股票价格。
- 气候预测: 气象学家根据过去的气候数据,利用这些模型来预测天气状况。
- 经济预测: 经济学家使用自回归模型来预测 GDP、通货膨胀率和失业率等经济指标。
- 自然语言处理: 在 NLP 中,自回归模型通过根据前面的单词预测句子中的下一个单词来生成连贯的文本。

自回归模型用于预测股票价格
在这些应用中,自回归模型是根据历史数据做出明智决策和预测的宝贵工具。
在接下来的部分中,我们将从 AR(p) 模型的基础知识和自回归系数的作用开始,更深入地研究自回归模型的机制。这些基础知识将为更全面地理解这些模型如何工作以及如何在实践中应用奠定基础。
自回归 (AR) 模型的基础知识
现在我们已经确定了自回归模型的重要性及其在各个领域的应用,是时候探索支撑这些模型的基本原理了。
AR(p) 模型
自回归建模的核心是 AR(p) 模型,其中“p”代表模型的阶数。AR(p) 模型将变量的当前值表示为其先前“p”值加上白噪声误差项的线性组合。AR(p)模型的一般公式可以写成如下:
![]()
分解这个方程:
- Xt是时间序列在时间t的值。这是我们想要预测或理解的值。
- c 是常数项,有时包含在内是为了解释非零均值。
- ψ1,ψ2,…,ψp 是表示分配给先前值的权重的自回归系数。这些系数决定了过去的价值观对当前价值观的影响强度和方向。
- ϵt是误差项,通常假设为白噪声,表示时间t时无法解释的方差或随机性。
解释自回归系数 ( phi )
自回归系数 ( phi 1, phi 2,…, phip ) 在 AR(p) 模型中特别重要。这些系数是根据历史数据估计的,并量化先前观察结果对当前值的影响。以下是您应该了解的有关解释这些系数的知识:
- 正phi 值表示过去值在相应滞后 ( Xt −1, Xt −2,…, Xt − p ) 处的增加会增加当前值 ( Xt )。
- 负ψ 值表明过去值的增加会导致当前值的减少。
- Φ 值接近于零表示对过去值的依赖较弱或可以忽略不计。
阶数p和phi 值的选择 对于确定 AR 模型与数据的拟合程度至关重要。准确估计这些参数是有效应用自回归模型的基本步骤。
时间序列数据自回归 (AR) 模型的简单示例
为了说明自回归模型的概念,请考虑金融领域的一个简单示例。假设我们想根据一家公司过去的表现来预测其股价。我们可以构建一个 AR(2) 模型:
StockPrice_t=c+ϕ1⋅StockPrice_t−1+ϕ2⋅StockPrice_t−2+ϵt在此模型中,时间t的股票价格 取决于其在时间t -1 和t -2 的值。通过估计系数(phi 1和phi 2),我们可以对未来的股票价格进行预测。
掌握了这些基础知识后,我们将继续讨论自回归模型的更高级方面,包括估计自回归系数和选择适当的阶数 (p)。理解这些元素对于 AR 模型的实际应用至关重要。
如何估计自回归系数
在上一节介绍了自回归模型的基本结构之后,我们现在将深入研究估计自回归系数 ( phi ) 的关键过程。准确的系数估计是构建可靠的 AR 模型的基础。
估算方法
估计自回归系数的方法有多种,方法的选择取决于数据的性质和所需的模型性能等因素。三种标准方法是:
1. 矩量法:
- 该方法通过将样本矩(例如均值、方差)与其理论对应物相匹配来估计系数。
- 它相对简单,但可能无法产生最准确的估计,尤其是在样本量较小的情况下。
2.最大似然估计(MLE):
- MLE 是一种强大的统计方法,旨在最大化给定模型的数据的似然函数。
- 它提供渐近有效的估计(即随着样本量的增长而达到最佳估计)并在实践中广泛使用。
3.最小二乘估计:
- 该方法最小化观测值与模型预测值之间的平方差之和。
- 它很简单,经常用于线性回归,但对于自回归模型来说,它可能不是最合适的选择,特别是在数据不呈正态分布的情况下。
估计对模型性能的影响
估计方法的选择对自回归模型的性能和可靠性有着深远的影响。以下是估计方法的选择对模型的影响:
- 效率: 最大似然估计是渐近有效的,随着样本量的增加提供最精确的估计。当有大量数据可用时,通常会首选它。
- 偏差: 不同的估计方法可能会给参数估计带来偏差。这种偏差会影响模型的准确性,特别是在处理小样本或非标准数据分布时。
- 假设: 每种估计方法都基于某些假设。例如,MLE 假设数据呈正态分布。违反这些假设可能会导致估计不准确。
模型拟合和迭代
在实践中,拟合自回归模型涉及选择适当的阶数 ( p )、估计自回归系数 ( phi ) 以及评估模型的拟合优度。该过程可能需要迭代,因为不同的顺序和估计方法可能会产生不同的结果。
为了确定模型的阶 ( p ),人们经常采用统计技术,例如赤池信息准则 (AIC) 或贝叶斯信息准则 (BIC)。这些标准有助于在模型复杂性和拟合优度之间取得平衡。
一旦确定了顺序并估计了系数,评估模型的性能就至关重要。您可以使用决定系数 ( R 2) 和残差分析等度量来评估拟合度。
估计自回归系数是构建可准确捕获数据中的时间依赖性的自回归模型的关键步骤。估计方法的选择、模型的阶数以及模型优度的评估都是这个过程中必须考虑的因素。随着我们继续探索自回归模型,我们将更深入地研究这些概念,并为有效地将 AR 模型应用于现实世界的数据分析和预测提供实用的见解。
阶次选择和自回归 (AR) 模型评估
上一节探讨了自回归系数 ( phi )的估计及其在构建自回归模型中的关键作用。现在,我们关注 AR 建模的另一个关键方面 - 选择适当的阶数 ( p ) 并评估模型的性能。
自回归 (AR) 模型中的阶次选择
自回归模型的阶数 ( p ) 确定在预测当前值时考虑多少个先前时间步。选择正确的顺序对于构建有效的 AR 模型至关重要。以下是一些选择订单的方法:
1.目视检查:
- 一种简单的方法是可视化时间序列数据的自相关函数 (ACF) 和偏自相关函数 (PACF) 图。
- 这些图中的峰值可以帮助识别潜在的订单。例如,PACF 中滞后 3 处的显着峰值表明 AR(3) 模型可能合适。
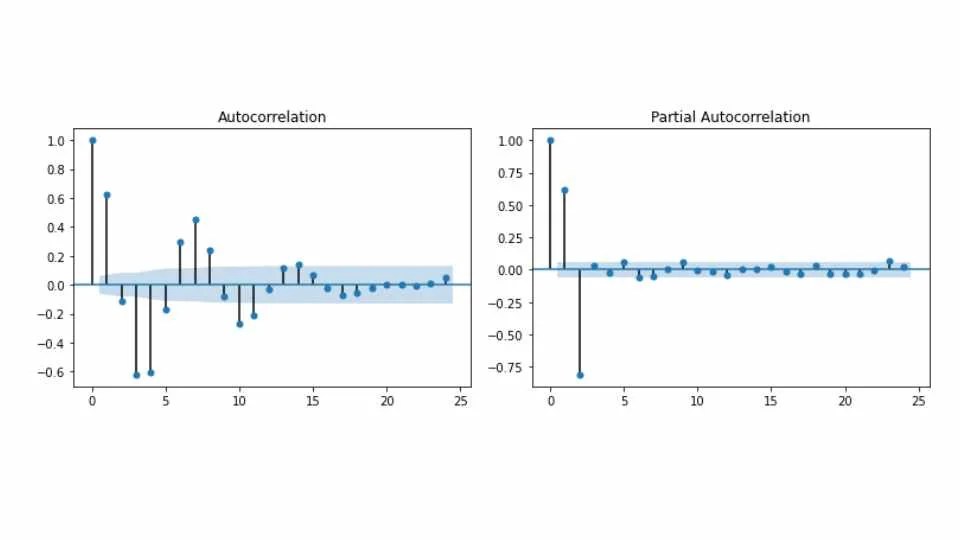
ACF 和 PACF 图
2. 信息标准:
- 赤池信息准则 (AIC) 和贝叶斯信息准则 (BIC) 是用于模型选择的统计度量。
- 这些标准平衡了模型复杂性和拟合优度之间的权衡。AIC 或 BIC 值越低表示模型越好。
3.交叉验证:
- 交叉验证涉及将数据分为训练集和测试集。
- 不同阶数的 AR 模型适合训练数据,并在测试数据上评估其性能。选择具有最佳预测准确性的顺序。
模型评估
选择自回归模型的阶数只是一个开始。模型建立后,评估其性能至关重要。以下是模型评估的关键方面:
1. 决定系数(R 2):
- R 2 衡量模型解释的因变量(时间序列)中方差的比例。
- R 2 值越高表示拟合越好。然而,R 2 应与其他评估措施一起考虑。
2.残差分析:
- 理想情况下,自回归模型的残差应该是白噪声,这意味着它们不表现出显着的模式。
- 对残差图(例如残差直方图或残差相关图)的目视检查可以揭示任何剩余模式或与白噪声的偏差。
3. 预测准确度:
- 许多自回归模型的最终目标是做出准确的预测。
- 可以使用平均绝对误差 (MAE)、均方误差 (MSE) 或均方根误差 (RMSE) 等指标来评估预测准确性。
4. 过拟合和欠拟合的挑战
当您进行订单选择和模型评估时,必须在过度拟合和欠拟合之间取得平衡。当模型过于复杂(高p)时,就会发生过度拟合,拟合数据中的噪声而不是有意义的模式。当模型太简单(低p),无法捕获重要的时间依赖性时,就会发生欠拟合。
实现这种平衡需要仔细考虑数据,选择适当的顺序,并在评估模型性能时始终保持警惕。它可能涉及拟合和评估不同模型的多次迭代。
订单选择和模型评估是开发自回归模型的关键阶段。精心选择的顺序和对模型性能的全面评估对于创建可靠且准确的时间序列分析和预测模型至关重要。在后续部分中,我们将进一步探索自回归模型的实际应用,并提供解决现实场景中模型选择和评估挑战的见解。
自回归 (AR) 模型的实践
现在我们已经介绍了自回归模型的基本概念,是时候探索如何将它们应用于现实场景了。自回归模型在各个领域都有广泛的实际应用。在本节中,我们将深入研究这些实际用途,并讨论有效使用 AR 模型的挑战和细微差别。
1. 金融时间序列分析
自回归模型最突出的应用之一是金融时间序列分析。这些模型预测资产价格,例如股票、商品和货币。AR 模型的作用如下:
- 股价预测: AR模型可以帮助分析师通过考虑历史股价走势、交易量和其他市场指标来预测未来股价。
- 风险管理: 金融机构使用 AR 模型来估计风险参数,例如波动性和风险价值 (VaR),这对于投资组合管理至关重要。
- 算法交易: 高频交易算法通常结合 AR 模型,根据历史价格模式做出瞬间决策。
2. 气象与气候预测
气象学家和气候科学家利用自回归模型进行天气和气候预测。气候系统表现出受过去条件影响的复杂模式,使得 AR 模型适用于以下方式:
- 天气预报: 通过分析历史气候数据,包括温度、降水和风型,气象学家可以做出短期和长期天气预报。
- 气候建模: 了解长期气候趋势和气候变化的影响通常涉及使用 AR 模型来捕获气候数据的时间依赖性。
3. 经济预测
经济学家使用自回归模型来预测经济指标并做出明智的政策决策。主要应用包括:
- 国内生产总值 (GDP) 预测: AR 模型可以根据历史经济数据深入了解未来的 GDP 增长率。
- 通货膨胀率预测: 分析过去的通货膨胀率可以帮助央行和政策制定者预测未来的价格变化。
- 失业率预测: 预测失业率变化对于经济规划和劳动力发展至关重要。
4. 医疗保健中的时间序列数据分析
在医疗保健领域,时间序列数据由各种监控系统生成,提供对患者健康和医疗设备性能的洞察。自回归模型用于:
- 患者监测: AR 模型可应用于生理时间序列数据,以识别心率和血压等生命体征的趋势或异常。
- 医疗设备性能: AR 模型可以根据历史性能数据帮助预测呼吸机或输液泵等设备何时需要维护或更换。
挑战和考虑因素
虽然自回归模型提供了有价值的见解,但它们也面临着一系列挑战:
- 数据质量: AR模型的准确性在很大程度上取决于数据的质量和清洁度。数据丢失或错误可能导致预测不可靠。
- 非平稳性: 许多时间序列是非平稳的,这意味着它们的统计属性随着时间的推移而变化。检测和解决非平稳性对于建模至关重要。
- 模型选择: 选择正确的阶数 ( p ) 和估计方法并不总是那么简单。它通常需要反复试验,而领域专业知识发挥着重要作用。
- 模型验证: 确保模型的预测可靠并且不会过度拟合数据是一项持续的挑战。这涉及严格的测试和验证。
自回归模型对于预测、分析和理解许多领域的时间相关数据至关重要。它们的实际应用范围从金融市场到气象、经济学和医疗保健。尽管面临挑战,AR 模型仍然是在动态、数据驱动的世界中做出明智决策和预测的强大工具。随着我们的前进,我们将更深入地研究有效使用 AR 模型的细微差别,并解决从业者在现实世界中遇到的常见挑战。
自回归 (AR) 模型和预测
自回归模型对于预测时间序列数据集中的未来值特别有价值。本节探讨使用 AR 模型进行预测的复杂性,这是其主要的现实应用之一。
一步预测
在自回归建模中,一步提前预测是一种常见的方法。这意味着根据时间t之前的可用历史数据对下一个时间点 ( t +1) 进行预测。AR 模型通过考虑自回归系数 ( ) 和之前的观测值来估计 t +1时的值。
一步预测的过程包括以下步骤:
- 将 AR 模型与时间t之前的历史数据进行拟合,估计自回归系数和其他模型参数。
- 使用这些估计参数来预测t +1时的值。
- 观察t +1处的实际值后,使用此新数据点更新模型,并在下一个时间步重复该过程。
提前一步预测在实时应用中非常有价值,因为及时预测至关重要。然而,在处理大型数据集时,计算量可能很大,因为模型必须反复重新拟合。
长期预测
虽然自回归模型通常用于短期预测,但它们也可以扩展以进行长期预测。为了预测超过t +1 的时间步的值,可以采用以下方法:
- 迭代预测:在t +1 时进行一步预测,然后使用该预测作为输入来预测t +2 时的值,依此类推。这个迭代过程允许您生成对未来多个时间步长的预测。
- 多步模型: 构建一个修改后的 AR 模型,能够在单个步骤中而不是迭代地直接预测未来各个时间步长( t +1、t +2、t +3 等)的值。
- 季节性和趋势成分: 对于具有强烈季节性或趋势模式的时间序列数据,分解技术可以帮助分离这些成分,使长期预测更易于管理。每个组件都可以单独建模。
预测模型评估
自回归模型预测能力的成功取决于准确的模型选择、参数估计和评估。预测背景下模型评估的关键考虑因素包括:
- 样本外测试: 要评估模型的预测性能,必须在模型开发期间未使用的单独验证数据集上进行测试。这有助于确定模型推广到新数据的效果。
- 预测准确性指标: 利用平均绝对误差 (MAE)、均方误差 (MSE)、均方根误差 (RMSE) 和平均绝对百分比误差 (MAPE) 等指标来定量评估预测的准确性。
- 残差分析: 检查预测的残差以确保它们是白噪声,因为残差中的非随机模式表明模型存在缺陷。
- 回溯测试: 评估模型在多个时间段内的性能,以确保其随着时间的推移保持预测准确性。这有助于发现模型的不稳定性。
限制和扩展
虽然自回归模型用途广泛且有价值,但重要的是要承认它们的局限性以及为解决这些限制而开发的扩展。本节探讨自回归建模的边界,并介绍一些增强其功能的高级方法。
自回归模型的局限性
自回归模型有几个固有的局限性:
- 线性假设: AR 模型假设过去值和当前值之间的关系是线性的。在现实世界的数据中,经常存在非线性依赖性,导致建模不准确。
- 平稳性要求: 许多时间序列数据是非平稳的,这意味着它们的统计属性随着时间的推移而变化。AR 模型需要平稳性,而实现这一点可能具有挑战性。
- 缺乏解释变量: AR 模型主要依赖同一变量的过去值来进行预测。它们自然不会包含额外的解释变量,这可能会限制它们在某些情况下的适用性。
- 对模型阶数的敏感性: 选择适当的阶数 ( p ) 并不总是那么简单,并且可能对数据的变化很敏感。错误的顺序可能会导致模型性能不佳。
扩展和先进技术
为了克服基本自回归模型的局限性,开发了几种扩展和先进技术:
- ARIMA 模型: 自回归积分移动平均 (ARIMA) 模型将自回归和移动平均组件与差分相结合,以处理非平稳数据。ARIMA模型广泛应用于时间序列分析。
- 非线性 AR 模型: 非线性自回归模型,例如自回归条件异方差 (ARCH) 和广义自回归条件异方差 (GARCH) 模型,可以捕获金融时间序列中的非线性依赖性和波动性聚类。
- 指数平滑: 指数平滑模型(包括 Holt-Winters 模型)可以捕获时间序列数据中的季节性和趋势分量。它们对于短期和中期预测特别有效。
- 向量自回归 (VAR): VAR 模型将自回归的概念扩展到多个时间序列变量,允许对它们之间的交互和依赖关系进行建模。
- 机器学习方法: 先进的机器学习技术,例如循环神经网络 (RNN)和长短时记忆(LSTM)网络,可以对复杂的时间依赖性进行建模,并在时间序列预测中受到欢迎。
- 状态空间模型: 状态空间模型为时间序列数据建模提供了灵活的框架,并且可以合并多个组件,包括自回归元素、趋势、季节性和外生变量。
根据问题定制模型
建模技术的选择,无论是基本的自回归模型还是其高级扩展之一,都应根据具体问题和数据特征进行定制。这种定制可确保模型最适合捕获数据中的相关模式和依赖关系。
在实践中,了解自回归模型的局限性并了解各种扩展和替代方案对于实际时间序列分析至关重要。模型的选择应以当前任务的独特要求和数据的性质为指导。
几十年来,自回归模型一直是时间序列分析的基石,提供了宝贵的见解和预测功能。然而,必须认识到它们的局限性以及为这些限制提供解决方案的先进技术的不断发展。通过为问题选择正确的工具,无论是基本的 AR 模型还是更复杂的模型,从业者都可以做出更准确的预测,并从时间序列数据中发现更深入的见解。在我们继续进行的过程中,我们将探索如何针对不同场景选择最合适的模型,并解决实际实施中的复杂问题。
时间序列中的自回归 (AR) 模型 – 自回归积分移动平均线 (ARIMA)
ARIMA(即自回归综合移动平均线)是一种功能强大的时间序列预测模型,它结合了三个主要组成部分:自回归 (AR)、差分(I,表示综合)和移动平均线 (MA)。它是一种广泛使用的用于分析和预测时间序列数据的模型。
以下是 ARIMA 的每个组成部分所代表的含义:
- 自回归 (AR): 自回归组件捕获时间序列的当前值与其过去值之间的关系。AR(p) 模型将当前值表示为过去 p 值的线性组合。顺序 p 表示考虑了多少个过去的值。
- 积分(I): 积分分量代表差分,这使得时间序列平稳。非平稳数据具有随时间变化的统计特性,这使得建模具有挑战性。差分涉及取连续观测值之间的差异,直到数据变得平稳。
- 移动平均 (MA): 移动平均组件对当前值和过去的白噪声误差项之间的关系进行建模。MA(q) 模型将当前值表示为过去 q 个误差项的线性组合。阶数 q 表示考虑了多少个过去的误差项。
ARIMA模型方程
ARIMA 模型通常表示为 ARIMA(p, d, q),其中:
- p 是自回归分量的阶数。
- d 是使数据平稳所需的差分阶数。
- q 是移动平均分量的阶数。
ARIMA 模型非常灵活,可以处理各种时间序列模式,包括趋势、季节性和自相关。它经常用于经济、金融、气象等领域的时间序列预测和分析。
ARIMA 模型选择涉及确定最适合数据的 p、d 和 q 值。这通常是使用自相关和部分自相关图、模型评估标准(例如 AIC、BIC)和样本外测试等技术来完成的。此外,通过引入季节性差分以及季节性 AR 和 MA 分量,该模型可以扩展到季节性数据,从而形成季节性 ARIMA (SARIMA) 模型。
如何在 Python 中实现自回归 (AR) 模型
要在 Python 中创建自回归 (AR) 模型,您可以使用 statsmodels 或 scikit-learn等库。在此示例中,我们将使用 statsmodels 创建一个简单的自回归模型。
您需要 安装statsmodels ,您可以使用 pip 来完成此操作:
pip install statsmodels 以下是使用 Python 创建 AR 模型的分步指南:
import numpy as np
from statsmodels.tsa.arima.model import ARIMA
import matplotlib.pyplot as plt# Generate some example time series data (you can replace this with your own data)
np.random.seed(0)
n = 100
time = np.arange(n)
data = 0.5 * time + 5 * np.random.randn(n)# Plot the data
plt.plot(time, data)
plt.title("Example Time Series Data")
plt.xlabel("Time")
plt.ylabel("Value")
plt.show()# Create an AR model with an order of 1 (AR(1))
model = ARIMA(data, order=(1, 0, 0))
results = model.fit()# Print the model summary
print(results.summary())# Get the model parameters
phi = results.params[1]# Make predictions for the next time step
next_value = phi * data[-1]print(f"Predicted Value for Next Time Step: {next_value}")
数据图
输出:
SARIMAX Results
==============================================================================
Dep. Variable: y No. Observations: 100
Model: ARIMA(1, 0, 0) Log Likelihood -333.053
Date: Wed, 25 Oct 2023 AIC 672.107
Time: 10:15:54 BIC 679.922
Sample: 0 HQIC 675.270- 100
Covariance Type: opg
==============================================================================coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
const 25.8478 6.431 4.020 0.000 13.244 38.451
ar.L1 0.9024 0.048 18.627 0.000 0.807 0.997
sigma2 44.9859 6.254 7.193 0.000 32.727 57.244
===================================================================================
Ljung-Box (L1) (Q): 19.47 Jarque-Bera (JB): 0.50
Prob(Q): 0.00 Prob(JB): 0.78
Heteroskedasticity (H): 0.85 Skew: 0.17
Prob(H) (two-sided): 0.64 Kurtosis: 3.09
===================================================================================Predicted Value for Next Time Step: 46.48017777245969在此代码中:
我们导入必要的库,包括 numpy、 statsmodels和 matplotlib。
我们生成示例时间序列数据(您可以将其替换为您的数据)。在此示例中,我们创建了与一些随机噪声的简单线性关系。
我们使用ARIMA(data)创建 AR(1) 模型 ,并使用model.fit() 将模型拟合到我们的数据 。
我们打印模型的摘要,其中包括有关模型参数的信息。
我们从模型参数中提取自回归系数 ( phi )。
我们使用自回归系数对下一时间步进行一步预测。
您可以修改此代码以使用时间序列数据或尝试不同的 AR 顺序。AR 模型通常用于更复杂的时间序列数据,您可以扩展此示例以处理更高级的场景。
深度学习中的自回归模型 (AR)
深度学习中的自回归是指应用深度神经网络对序列数据进行建模和预测,其中序列中的当前值取决于先前的值。深度学习方法,特别是循环神经网络 (RNN) 及其变体,通常用于自然语言处理 (NLP)、时间序列分析和语音识别等各个领域的自回归任务。

在深度学习中,隐藏状态有效地实现了模型的自回归方面。来源:谷歌 Deepminds
以下是深度学习中自回归的实现方式:
- 循环神经网络 (RNN):RNN 是专门为序列数据设计的深度学习模型。它们维护隐藏状态,捕获先前时间步骤的信息并使用它来预测序列的下一个值。隐藏状态有效地实现了模型的自回归方面。
- 长短期记忆 (LSTM) 网络:LSTM 是一种 RNN,旨在解决传统 RNN 经常遇到的梯度消失问题。LSTM 具有更复杂的存储单元,使它们能够捕获长程依赖性,并且在自回归至关重要的任务中特别有效。
- 门控循环单元 (GRU) 网络:GRU 是 RNN 的另一种变体,与 LSTM 类似,但架构更简单。它们的计算效率更高,并且适用于许多自回归任务。
- Transformer架构:Transformer 架构主要因其在机器翻译的《Attention Is All You Need》论文中的使用而闻名,在自回归任务中也很受欢迎。Transformer 不依赖于循环连接,而是使用自注意力机制来捕获不同序列部分之间的依赖关系。
自然语言处理 (NLP) 中的自回归 (AR) 模型
自回归模型通常用于自然语言处理 (NLP) 中的各种任务。这些模型旨在生成文本序列或分析本质上具有时间或顺序结构的文本数据。NLP 中自回归模型的一个突出例子是循环神经网络 (RNN) 及其变体的使用,例如 LSTM(长短期记忆)和 GRU(门控循环单元)。NLP 中的自回归模型主要旨在建模和生成序列数据,例如文本、语音和时间序列语言。
以下是 NLP 中使用自回归模型的一些方法:
- 语言建模:自回归模型通常用于构建语言模型,该模型根据先前单词或字符的上下文来预测单词或字符的可能性。语言模型对于机器翻译、语音识别和文本完成等各种 NLP 任务至关重要。
- 文本生成:自回归模型可以生成连贯且上下文相关的文本。例如,OpenAI 的 GPT(生成式预训练变压器)模型是自回归的,并且在文本生成、聊天机器人和内容生成等任务中取得了显着的成功。
- 语音识别:自回归模型可应用于语音识别系统,其中模型根据先前识别的单元预测下一个音素或语音单元。
- 机器翻译:在机器翻译中,自回归模型可以在给定源语言的上下文的情况下预测目标语言中的下一个单词或子序列。
- NLP 中的时间序列分析:在 NLP 中,时间序列数据通常表示顺序文本数据,例如新闻文章、社交媒体帖子或用户对话。自回归模型可以帮助分析和预测此类数据中的趋势、情绪变化或主题转移。
- 语音合成:自回归模型,特别是 Tacotron 和 WaveNet,已用于文本到语音合成。给定先前的样本,他们通过一次预测一个音频样本来生成语音波形。
- NLP中的强化学习:自回归模型被集成到强化学习框架中,用于对话生成或玩游戏等任务,其中代理根据先前的动作和环境生成一系列动作或响应。
在许多此类应用中,可以通过注意机制增强自回归模型,以提高其捕获较长序列之间的依赖性的能力。这些模型(例如 Transformer 架构)在处理文本数据中的远程依赖关系方面特别有效。
自回归模型及其架构选择取决于特定的 NLP 任务和数据集。研究人员和从业者在该领域不断创新,导致自回归模型取得进步,使其在各种 NLP 应用中越来越有效。
结论
总之,自回归模型是一类功能强大且用途广泛的模型,可在广泛的领域中找到应用。这些模型的典型特征是能够捕获时间依赖性和顺序模式,是时间序列分析、预测和自然语言处理 (NLP) 的基本工具。
关于自回归模型的讨论的主要要点包括:
- 基本原则: 自回归模型(例如 AR(p) 和 ARIMA)建立在变量的当前值取决于其过去重要性的理念之上。它们广泛用于时间序列分析、经济预测等。
- 估计和模型选择: 估计自回归系数和选择适当的模型阶数对于构建准确的自回归模型至关重要。最大似然估计和信息标准等技术有助于此过程。
- 预测: 自回归模型是预测时间序列数据未来值的宝贵工具。它们提供领先一步和长期的预测能力,使从业者能够预测趋势并做出明智的决策。
- 实践应用: 自回归模型应用于各个领域,从金融和经济到气象和自然语言处理。它们在股市预测、天气预报、语言建模和语音合成等任务中发挥着至关重要的作用。
- 局限性和扩展: 虽然自回归模型很强大,但它们也有局限性,包括线性假设和对模型阶数的敏感性。ARIMA、LSTM、GRU 和基于 Transformer 的模型等高级模型的开发就是为了解决这些限制。
- 实际考虑: 在实践中应用自回归模型需要仔细的数据预处理、模型选择和评估。模型的选择应符合数据和手头任务的具体特征和要求。
- 未来方向: 自回归建模领域随着不断的研究和创新而不断发展。研究人员正在探索结合自回归和其他模型类型优势的混合模型和高级架构。
总体而言,自回归模型是时间序列分析和 NLP 的基本概念,为理解、预测和生成序列数据提供了强大的工具。通过了解其原理、局限性和实际考虑因素,从业者可以在广泛的现实应用中发挥数据分析、预测和决策的潜力。