之前看到的,我改了一下,多了很多东西
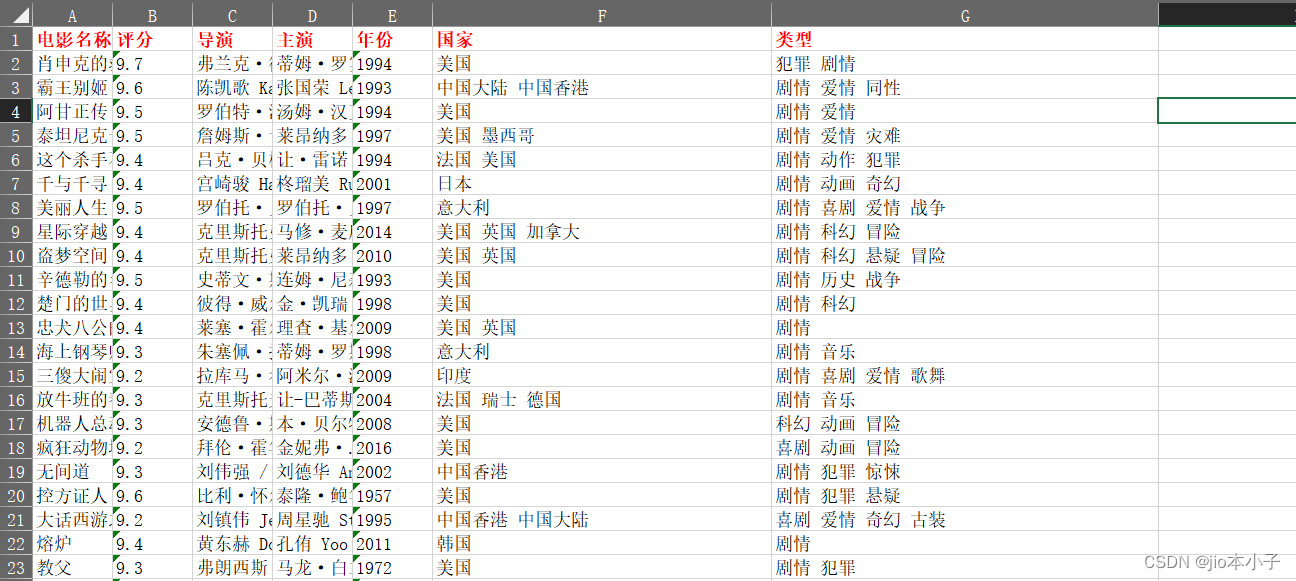
import requests
from bs4 import BeautifulSoup
from openpyxl import Workbook
from openpyxl.styles import Font
import redef extract_movie_info(info):# 使用正则表达式提取信息pattern = re.compile(r'导演: (.*?)\s*主演: (.*?)\s*(\d{4})\s*/\s*(.*?)\s*/\s*(.*)')match = pattern.match(info)if match:director = match.group(1).strip()actors = match.group(2).strip()year = match.group(3).strip()country = match.group(4).strip()genre = match.group(5).strip()return director, actors, year, country, genreelse:return Nonedef douban_top250():url = 'https://movie.douban.com/top250'headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.79'}movies = []for start_num in range(0, 250, 25):page_url = f'{url}?start={start_num}'response = requests.get(page_url, headers=headers)soup = BeautifulSoup(response.text, 'html.parser')for movie in soup.select('.item'):title = movie.select_one('.title').text.strip()rating = movie.select_one('.rating_num').text.strip()# 获取导演、主演和其他信息info = movie.select_one('p').text.strip()movie_info = extract_movie_info(info)if movie_info:director, actors, year, country, genre = movie_infomovies.append((title, rating, director, actors, year, country, genre))return moviesdef create_excel(movies):wb = Workbook()ws = wb.activetitle_font = Font(color='FF0000', bold=True)ws.append(['电影名称', '评分', '导演', '主演', '年份', '国家', '类型'])for cell in ws[1]:cell.font = title_fontfor movie in movies:ws.append(movie)wb.save('豆瓣_top250.xlsx')if __name__ == '__main__':movies = douban_top250()create_excel(movies)print('Excel文件已生成。')