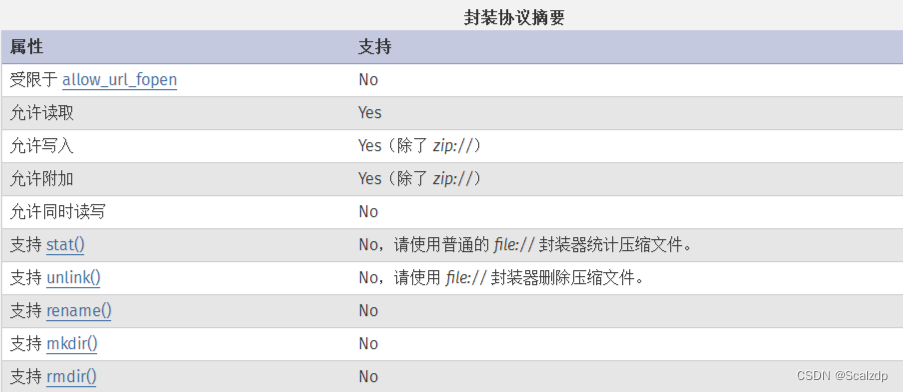
文章目录
- 一、程序地址空间
- 1.内存的分布
- 2.static修饰后为什么不会被释放
- 3.一个奇怪的现象
- 二、进程地址空间
- 1.前面现象的原因
- 2.地址空间究竟是什么?
- 3.为什么要有进程地址空间
- 4.页表
- 5.什么叫进程?
- 6.进程具有独立性。为什么?怎么做到呢?
- 三、命令行参数的地址
一、程序地址空间
1.内存的分布
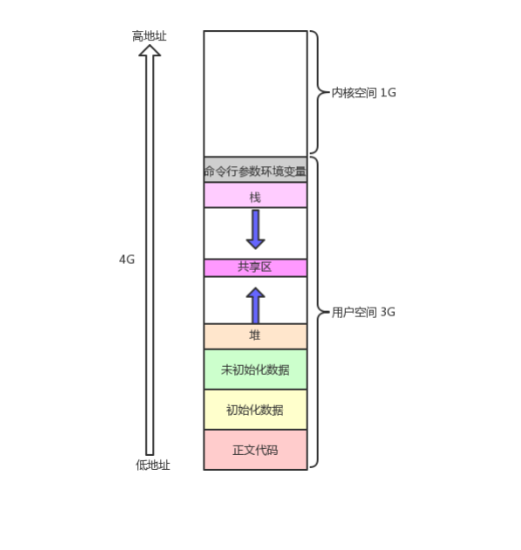
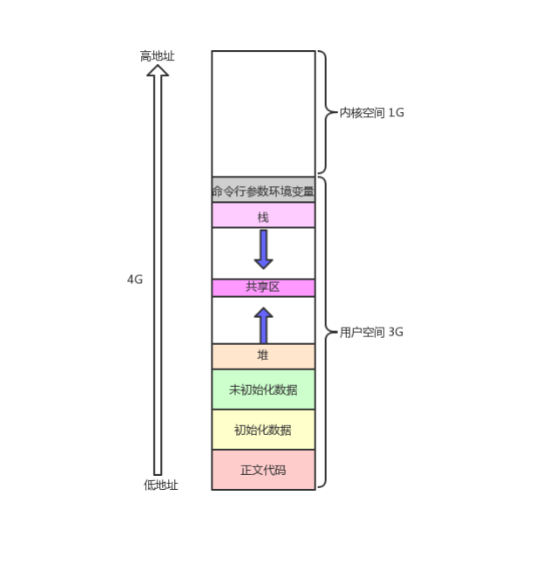
如下图所示,是我们之前的所熟知的内存分布
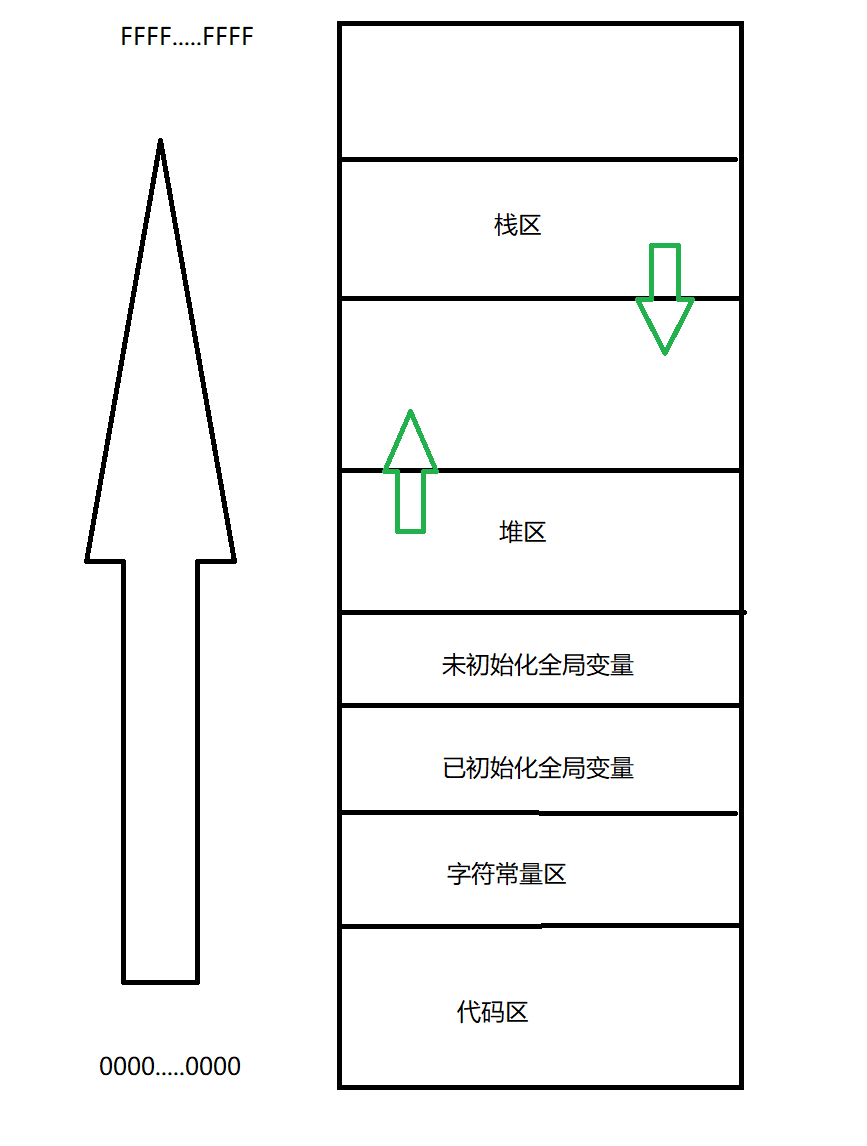
我们也知道,如果是32位机器的话,它的空间就是4GB,那么这个东西是内存吗?
其实把它叫做内存是不对的。
我们将这个东西叫做地址空间
我们先使用如下代码
#include<stdio.h>
#include<stdlib.h> int g_val_1;
int g_val_2 = 100; int main()
{ printf("code addr:%p\n ",main); const char* str = "hello world"; printf("read only string addr:%p\n",str); printf("init global value addr:%p\n",&g_val_2); printf("uninit global value addr:%p\n",&g_val_1); char* mem = (char*)malloc(100); printf("heap:%p\n",mem); printf("stack:%p\n",&str); return 0;
}
最终运行结果如下所示
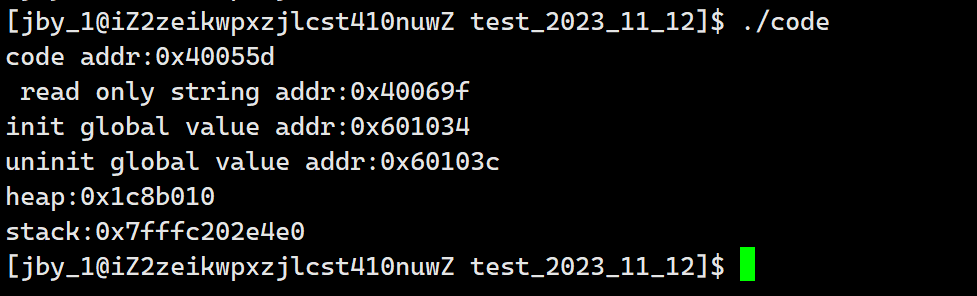
我们发现了这批地址就正好就是依次底层,正好满足我们上面的地址空间分布
我们现在再来验证一下,栈区的地址是一直减小的,而堆区的是增大的,用如下代码
#include<stdio.h>
#include<stdlib.h>int g_val_1;
int g_val_2 = 100; int main()
{ printf("code addr:%p\n ",main); const char* str = "hello world"; printf("read only string addr:%p\n",str); printf("init global value addr:%p\n",&g_val_2); printf("uninit global value addr:%p\n",&g_val_1); char* mem = (char*)malloc(100); printf("heap addr:%p\n",mem); printf("stack addr:%p\n",&str); printf("stack addr:%p\n",&mem); int a; int b; int c; printf("stack addr:%p\n",&a); printf("stack addr:%p\n",&b); printf("stack addr:%p\n",&c); return 0;
}
运行结果如下,我们发现确实是地址逐渐递减的
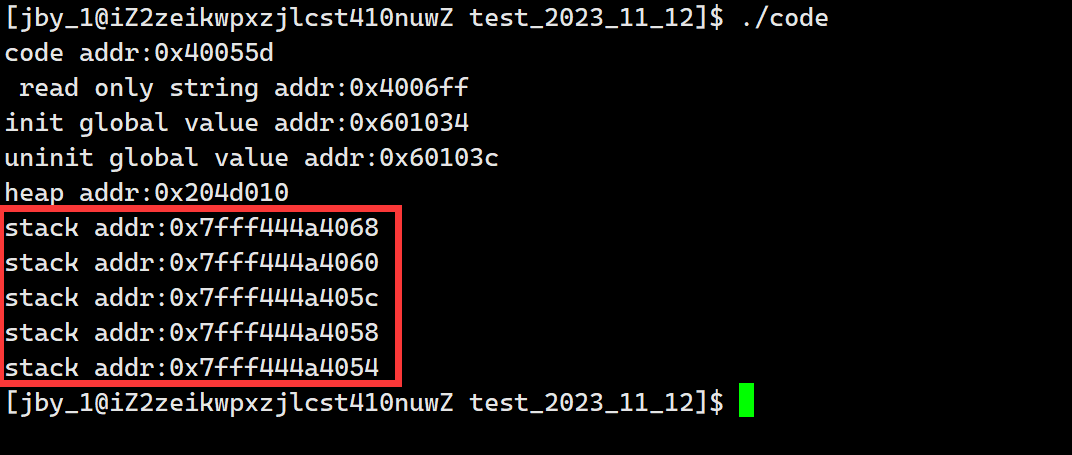
我们再来验证一下堆区是向着地址增大的方向生长
#include<stdio.h>
#include<stdlib.h> int g_val_1;
int g_val_2 = 100; int main()
{ printf("code addr:%p\n ",main); const char* str = "hello world"; printf("read only string addr:%p\n",str); printf("init global value addr:%p\n",&g_val_2); printf("uninit global value addr:%p\n",&g_val_1); char* mem = (char*)malloc(100); char* mem1 = (char*)malloc(100); char* mem2 = (char*)malloc(100); printf("heap addr:%p\n",mem); printf("heap addr:%p\n",mem1); printf("heap addr:%p\n",mem2); printf("stack addr:%p\n",&str); printf("stack addr:%p\n",&mem); int a; int b; int c; printf("stack addr:%p\n",&a); printf("stack addr:%p\n",&b); printf("stack addr:%p\n",&c); return 0;
}
运行结果如下所示,可以看到确实是地址逐渐增大
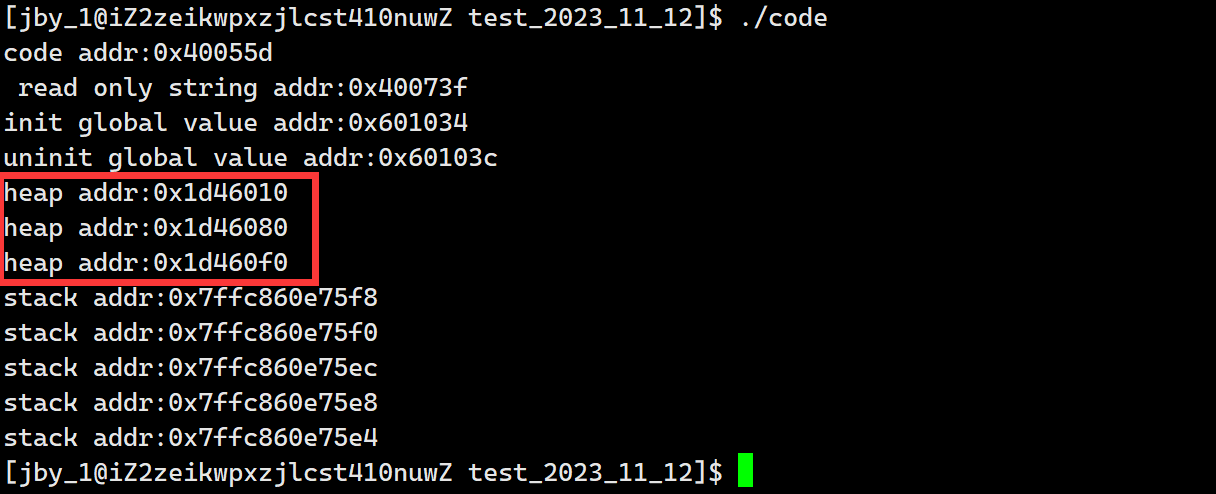
我们同时也可以发现,堆栈之间的地址差距很大,中间有很大一块空间是镂空的。后面我们在细谈这块
2.static修饰后为什么不会被释放
我们之前说过,static修饰后的局部变量就不会随着函数的结束而释放了,那么这是为什么呢?
我们可以去打印一下它的地址
运行结果为
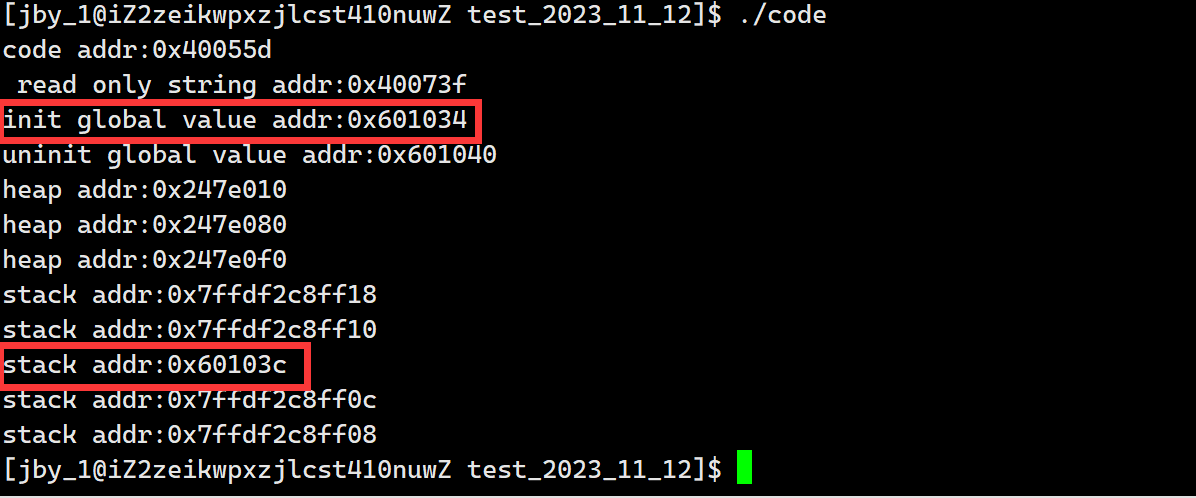
我们就可以看到,在编译的时候,static修饰的变量已经被编译到了全局数据区了,所以它就不会随着函数的调用而释放的,因为它已经相当于全局变量了
3.一个奇怪的现象
当我们运行下面代码时候
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
int g_val = 100; int main()
{ pid_t id = fork(); if(id == 0) { while(1) { printf("i am child,pid: %d,ppid: %d,g_val = %d,&g_val = %p\n",getpid(),getppid(),g_val,&g_val); sleep(1); } } else { while(1) { printf("i am parent,pid: %d,ppid: %d,g_val = %d,&g_val = %p\n",getpid(),getppid(),g_val,&g_val); sleep(1); } } return 0;
}
运行结果如下所示
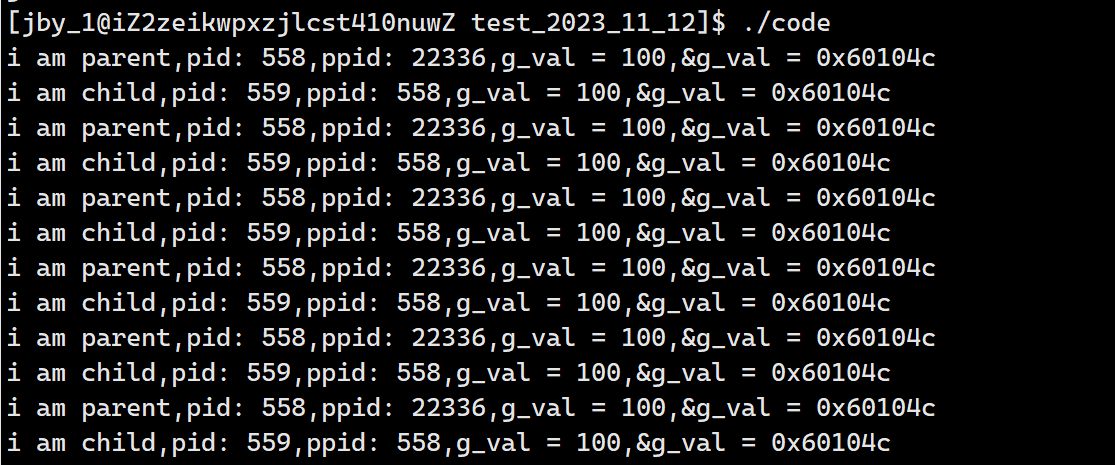
这个现象我们并没有发现什么不对劲
但是当我们将代码改为如下的时候
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
int g_val = 100;int main()
{pid_t id = fork();if(id == 0){int cnt = 5;while(1){printf("i am child,pid: %d,ppid: %d,g_val = %d,&g_val = %p\n",getpid(),getppid(),g_val,&g_val);sleep(1);if(cnt) cnt--;else{g_val = 200;printf("子进程:change g_val 100 --> 200");cnt--;}}}else{while(1){ printf("i am parent,pid: %d,ppid: %d,g_val = %d,&g_val = %p\n",getpid(),getppid(),g_val,&g_val);sleep(1);}}return 0;
}运行结果为下面所示
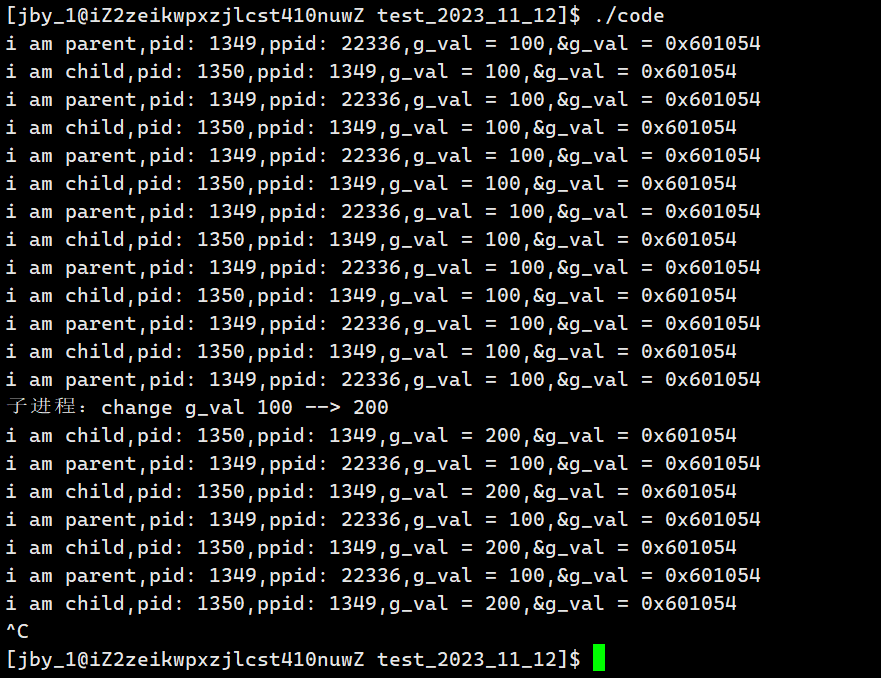
此时我们发现了一个很奇怪的现象,那就是当子进程的数据从100改为了200的时候。
子进程的值确实是200,父进程的值还是100,但是不同的值居然在同一块空间?
按照我们的常识,怎么可能同一个变量,同一个地址,同时读取,读到了不同的内容呢?!!!难道不应该写时拷贝吗?
所以我们可以想到:如果变量的地址,是物理地址,就不可能存在上面的现象!!
所以这个地址绝对不是物理地址,这个地址我们其实一般叫做线性地址或虚拟地址
其实像我们平时写的C/C++,用的指针,指针里面的地址,全都不是物理地址!!!
二、进程地址空间
1.前面现象的原因
我们已经知道,当我们运行一个程序的时候,会创建它的PCB,即task_struct结构体。其实除此之外,还会创建一个进程地址空间
如下图所示
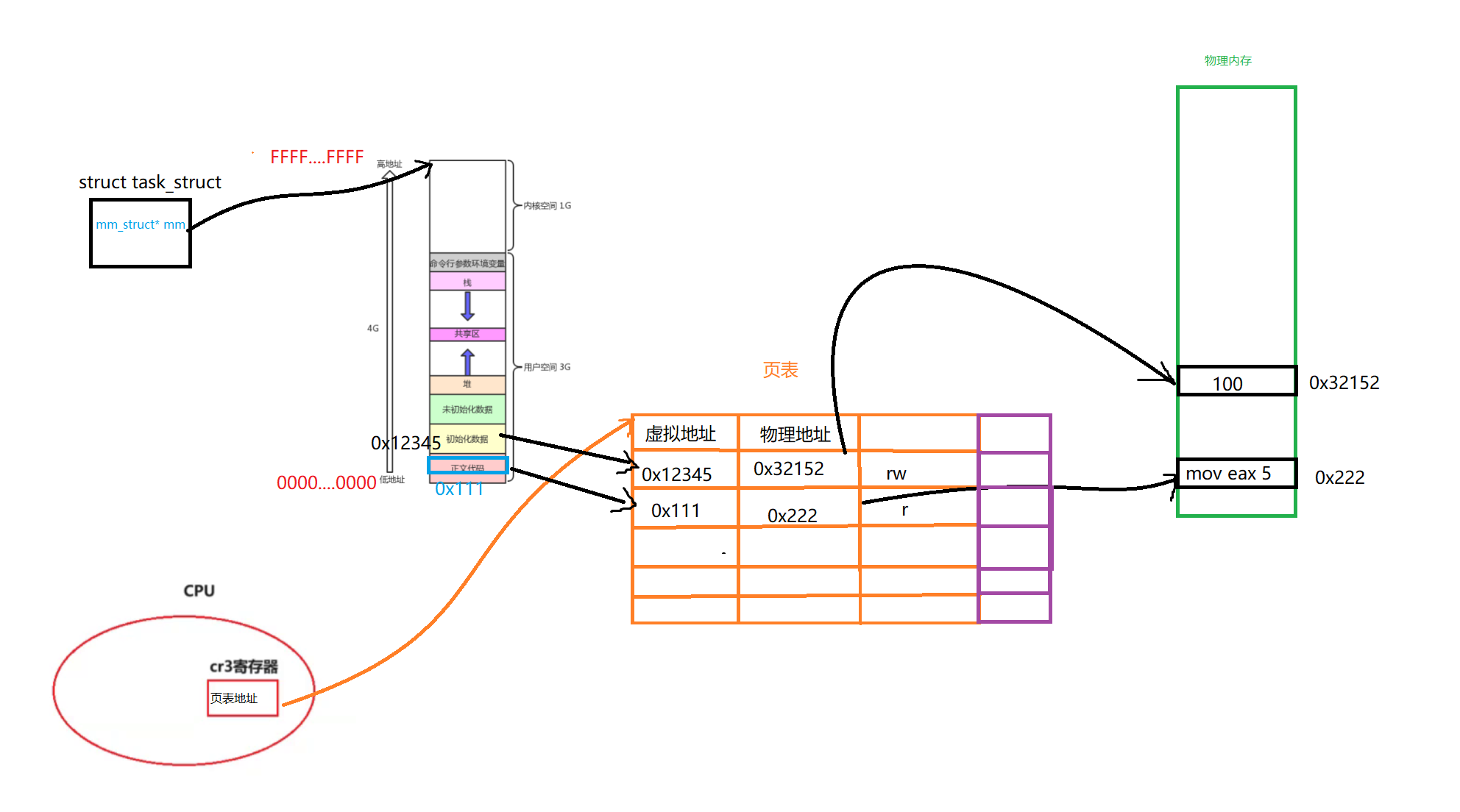
其实,在我们的task_struct中会有一个指针指向这个进程地址空间,它会通过一个页表与实际的物理内存建立映射关系
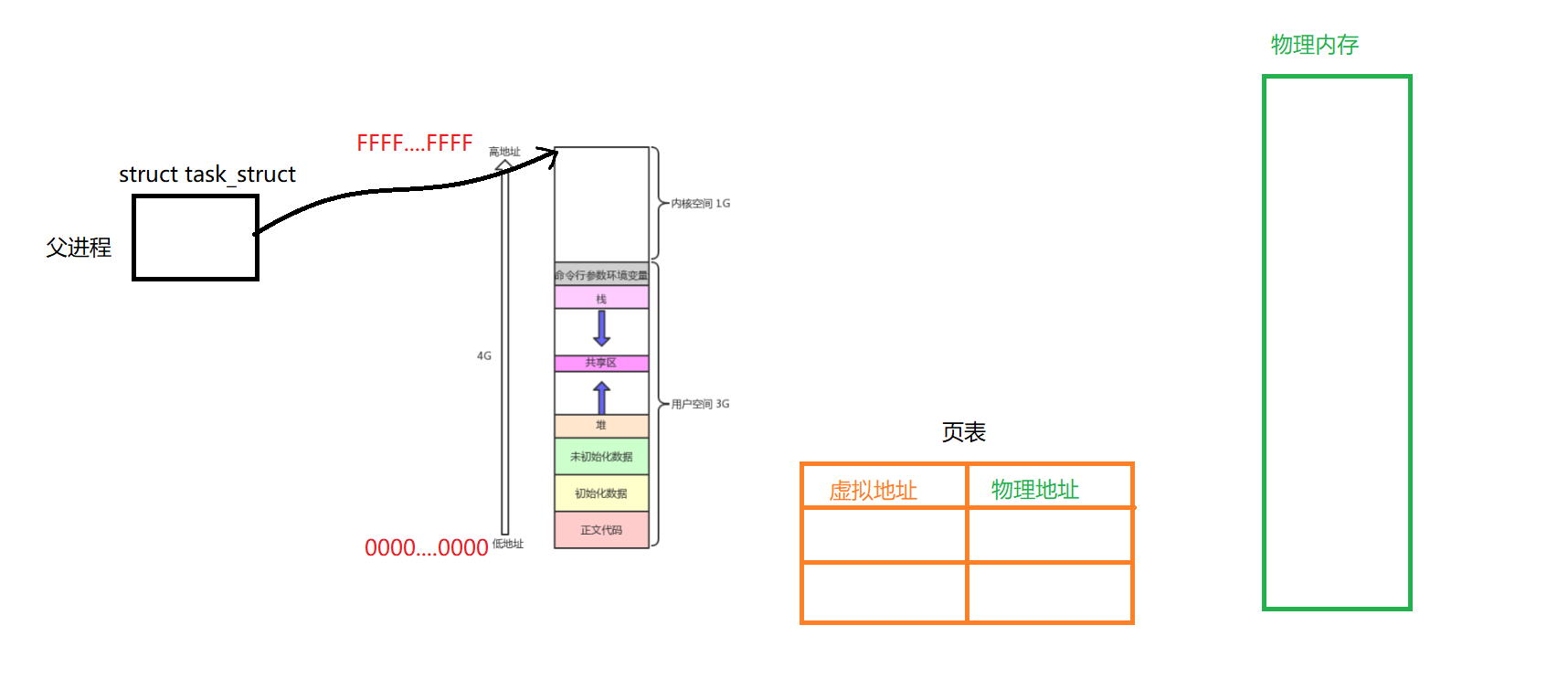
假如说,我们前面的一个已初始化的全局变量,它的虚拟地址就是0x601054,那么它会通过页表,从而找到实际的物理地址
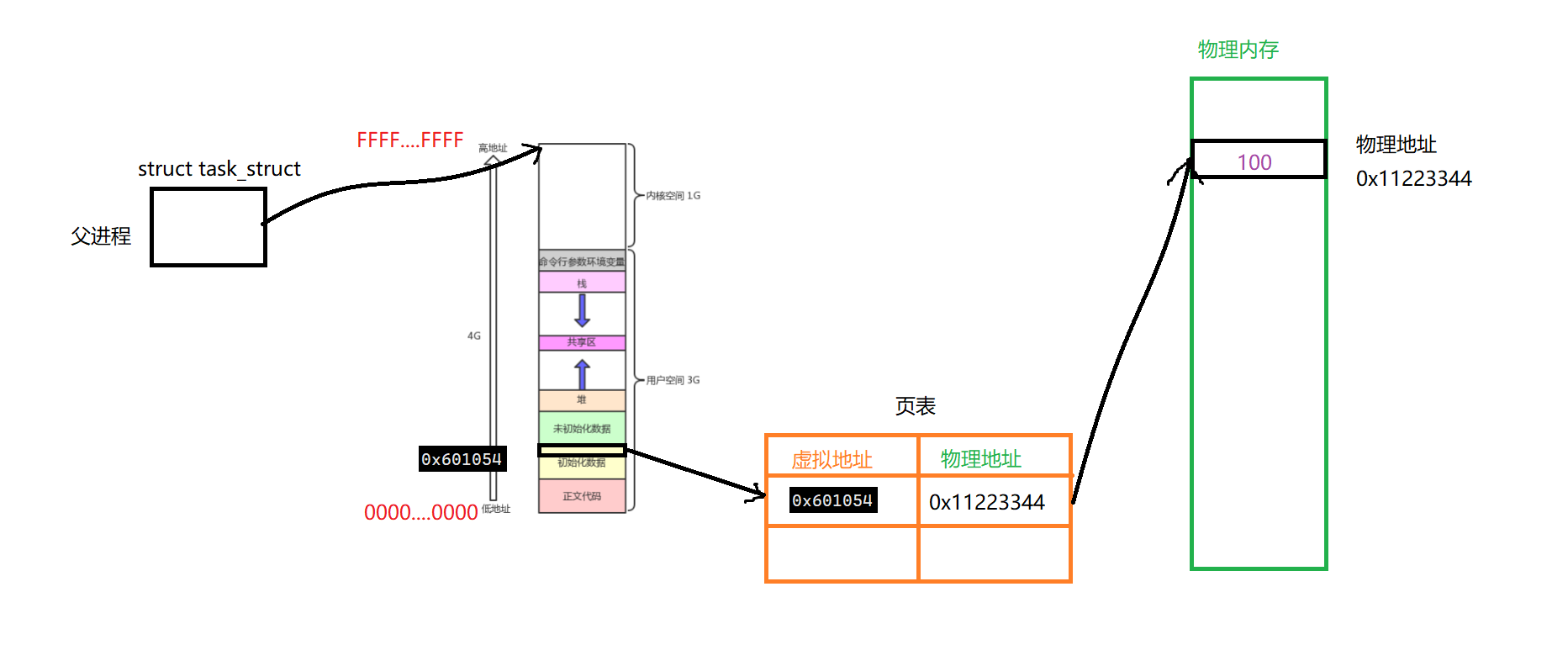
当一个子进程创建出来的时候,由于进程具有独立性,它也要创建自己的PCB、进程地址空间、和页表。我们可以理解为这个页表是直接拷贝父进程的一份
如下所示,它会拷贝一份页表,或者用同一份页表,总之只要内容一样即可,就可以建立映射关系,将所有的虚拟地址映射为物理地址。这样就可以共享代码和数据了
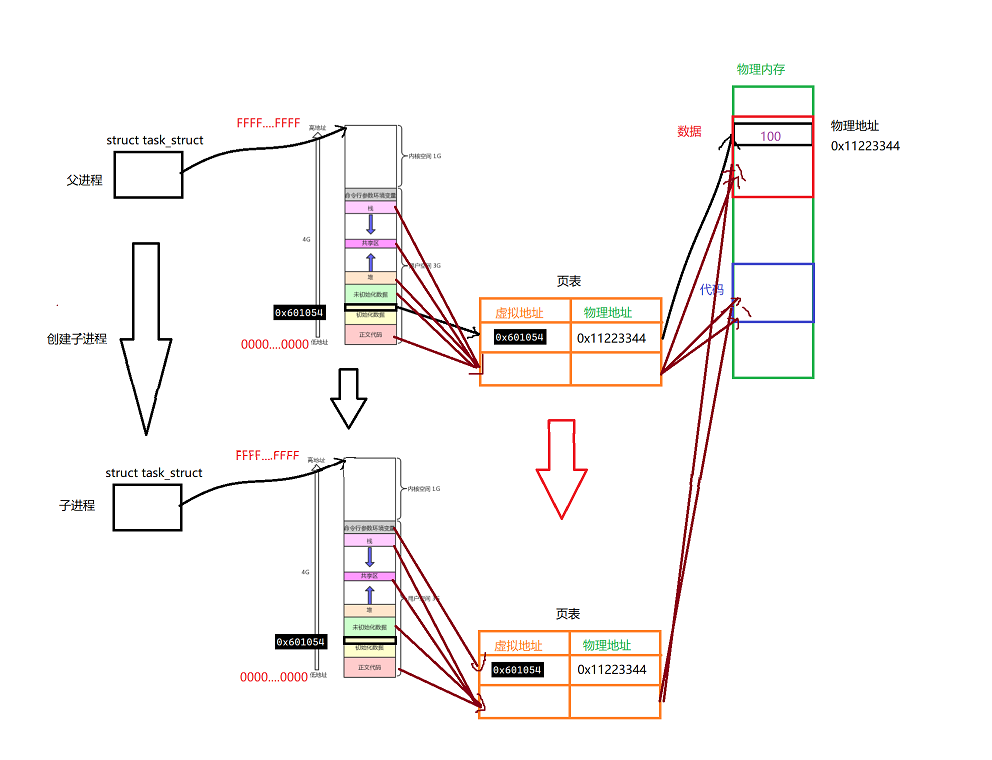
当我们子进程执行g_val = 200的操作的时候,物理物理内存将会重新开辟一块空间,拷贝原来的该数据,然后改变页表即可。
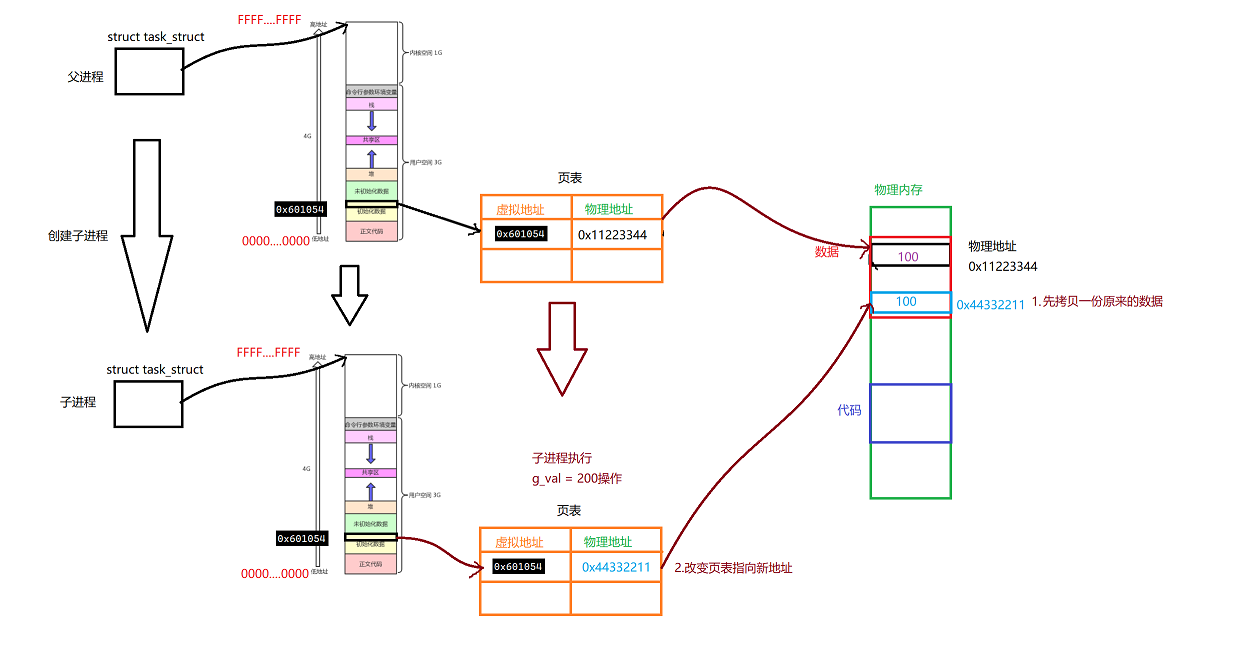
最后直接修改新的物理内存的数据
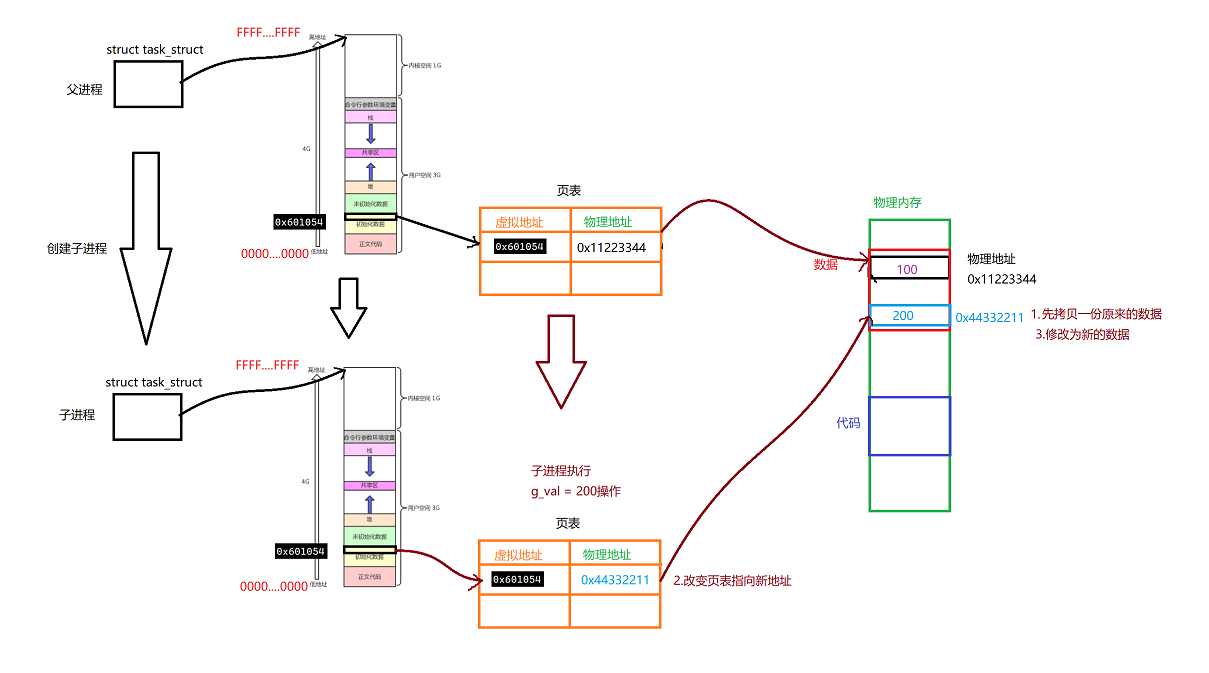
这就是写时拷贝。是操作系统自动完成的
写时拷贝是重新开辟空间的,但是在这个过程中,左侧的虚拟地址是0感知的,不关心,不会影响它的
所以现在,我们就回答了前面的问题,为什么打印出来的是同一个地址,但是却是两个不同的值
2.地址空间究竟是什么?
-
什么叫地址空间
我们知道,在32位计算机中,有32位的地址和数据总线
而每一根总线只有0,1两种状态,而32根,就是2^32种
所以2^32 * 1byte = 4GB
所以我们的地址总线排列组合形成的地址范围[0,2^32)就是地址空间
-
如何理解地址空间上的区域划分?
我们可以举一个例子
就好比我们小学时候的同桌,我们经常会划分区域,我们一般称它为38线。
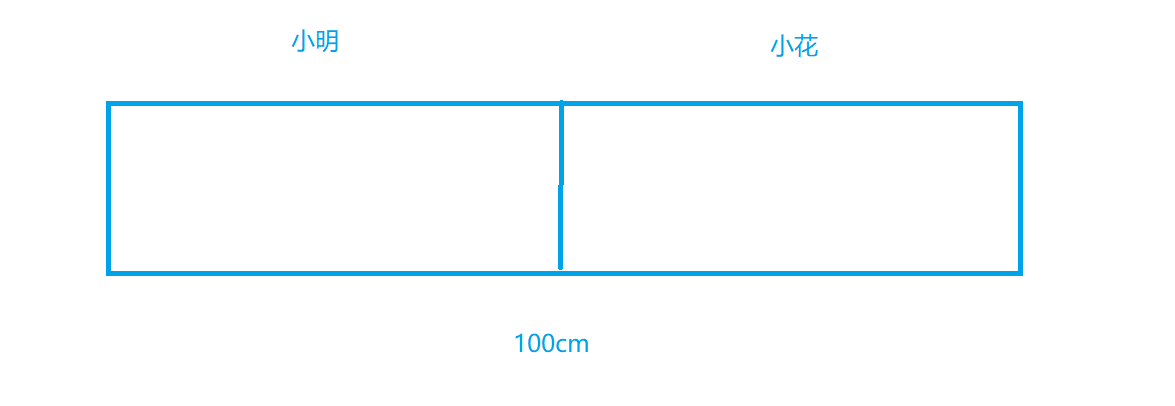
而这个所谓的38线,本质其实就是区域划分
我们可以用一个结构体去描述它们
struct area {int start;int end; }; struct destop_area//约定最大范围是100 { struct area xiaoming; struct area xiaohua; }; int main() { struct destop_area line_area = {{1,50},{51,100}}; }或者我们可以直接用一个结构体来描述
struct destop_area {int start_xiaoming;int end_xiaoming;int start_xiaohua;int end_xiaohua; };
那么所谓的空间区域调整,变大,或者变小,如何理解呢???
我们仍然用前面的例子,当有一条小明越界了,小花揍了一顿小明,还要让小明割地赔偿的时候,这就是空间区域的调整
line_area.xiaoming.end -= 10; line_area.xiaohua.start -= 10;这样的话,就是空间区域的调整了
那么现在他们有了自己的空间,比如说小明的区域就是[1,50]
假设现在小明有强迫症,它将它的区域划分为了50份,每一份都放着固定的东西。
比如说铅笔放在2号区域
当有人像他借铅笔的时候,就可以直接去该区域内找到目标的东西。
所以不仅仅要给小明划分地址空间的范围,在这个范围内,连续的空间中,每一个最小单位都可以有地址,这个地址可以直接被小明直接使用!!!
所以**所谓的进程地址空间,本质是一个描述进程可视范围的大小,地址空间内一定要存在各种区域划分,对线性地址进行start和end即可**
所以地址空间的本质是内核的一个数据结构对象,类似PCB一样,地址空间也是要被操作系统管理的:先描述,在组织
struct mm_struct //默认的划分区域就是4GB {long code_start;long code_end;long read_only_start;long read_only_end;long init_start;long init_end;long uninit_start;long uninit_end;long heap_start;long heap_end;long stack_start;long stack_end; }所以如下所示,每一个对应的task_struct都有一个指针,指向这个其对应的划分区域。利用这个结构体划分好进程地址空间
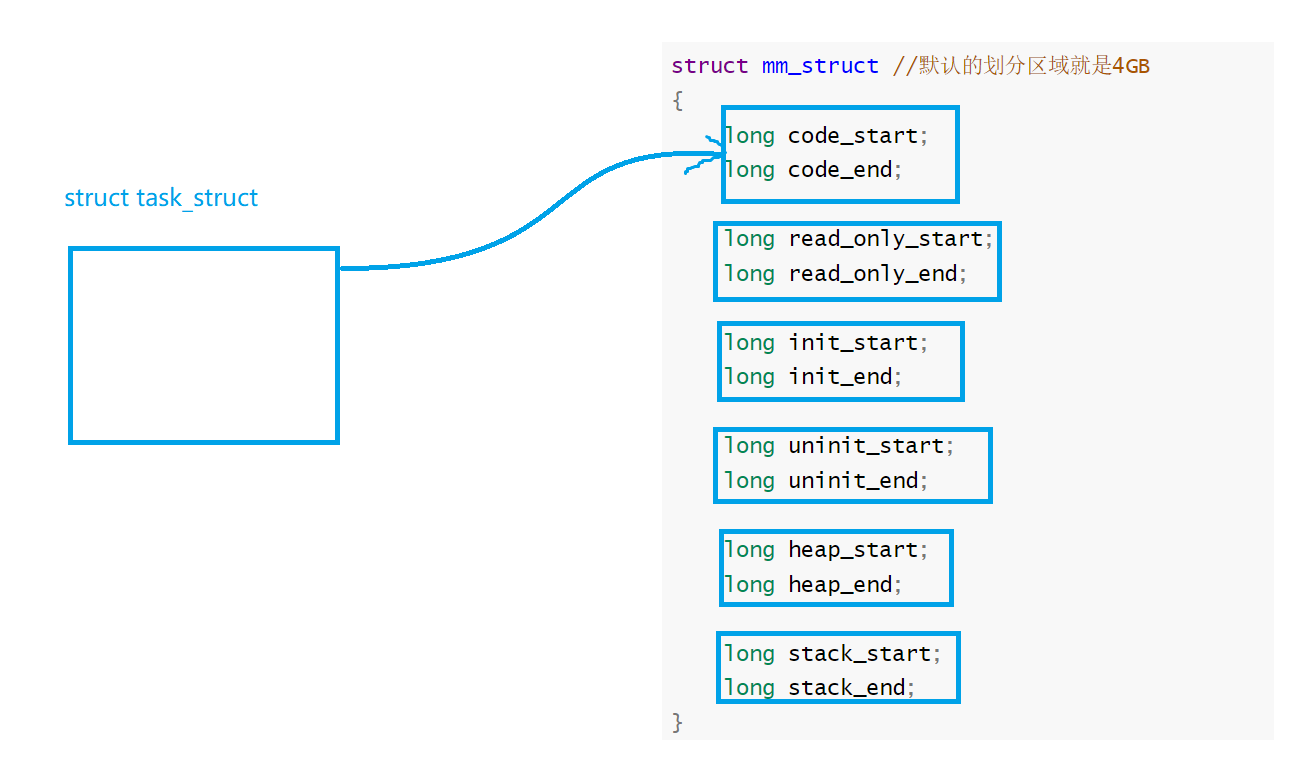
这就是进程地址空间
3.为什么要有进程地址空间
我们举一个例子
如下图所示,假设有一个老美,它是一个大富翁,它有10亿美金
现在它有四个私生子,每一个人都不知道对方的存在。它给每一个私生子都画了一个大饼,说我死后这10亿就给你们继承了。所以每一个都认为自己未来会具有十亿的家产。
而私生子的日常的一些小开销,这个大富翁都会给的。
但是如果私生子一下子要全部的钱,那么大富翁一定会骂一顿私生子,然后也不给钱。不过私生子被拒绝后仍然相信这钱未来还是自己的。
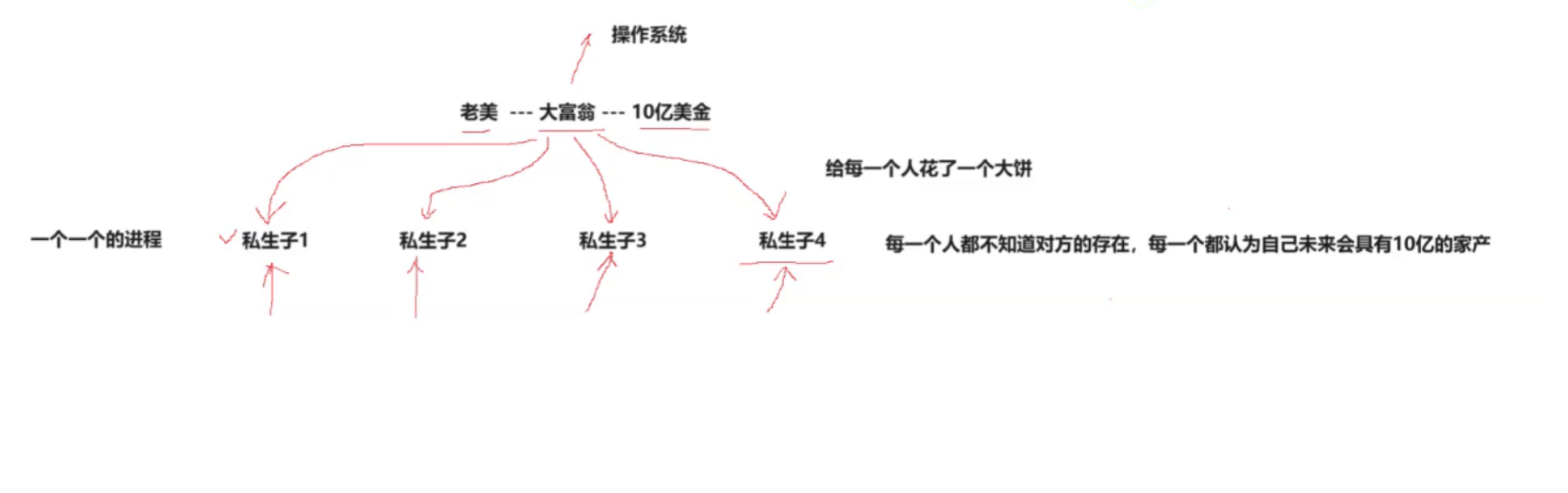
在这个例子中,大富翁就是操作系统,这些私生子就是一个一个的进程。
而这个大饼,就是进程地址空间
所以每一个进程都有一个进程地址空间,它能看到全部的内存。就类似于一个大饼
那么为什么要有进程地址空间呢?
让所有进程以统一的视角看待内存结构(比如说当未来需要挂起的时候,要将代码和数据给换出,此时实际的物理地址要发生改变,如果要让我们所看到的内存也要变化,那就太麻烦了。有了进程地址空间以后,我们就不关心实际的物理地址了。整体以进程地址空间的视角来看待内存)
增加进程虚拟地址空间可以让我们访问内存的时候,增加一个转换的过程,在这个转化的过程中,可以对我们的寻址请求进行审查,所以一旦异常访问,直接拦截,该请求不会到达物理内存,保护物理内存。(类似于,当我们小时候拿到压岁钱以后,妈妈为了防止我们被无良商家所坑钱,所以它会去保管这个钱,当需要花钱的时候,从妈妈哪里取出来即可,可以增加一层保护。)
因为有地址空间和页表的存在,将进程管理模块和内存管理模块进行解耦合!(下文详解)
4.页表
如下所示
在我们的CPU中,其实有一个cr3寄存器,这个寄存器时刻保存着页表的地址(物理地址)
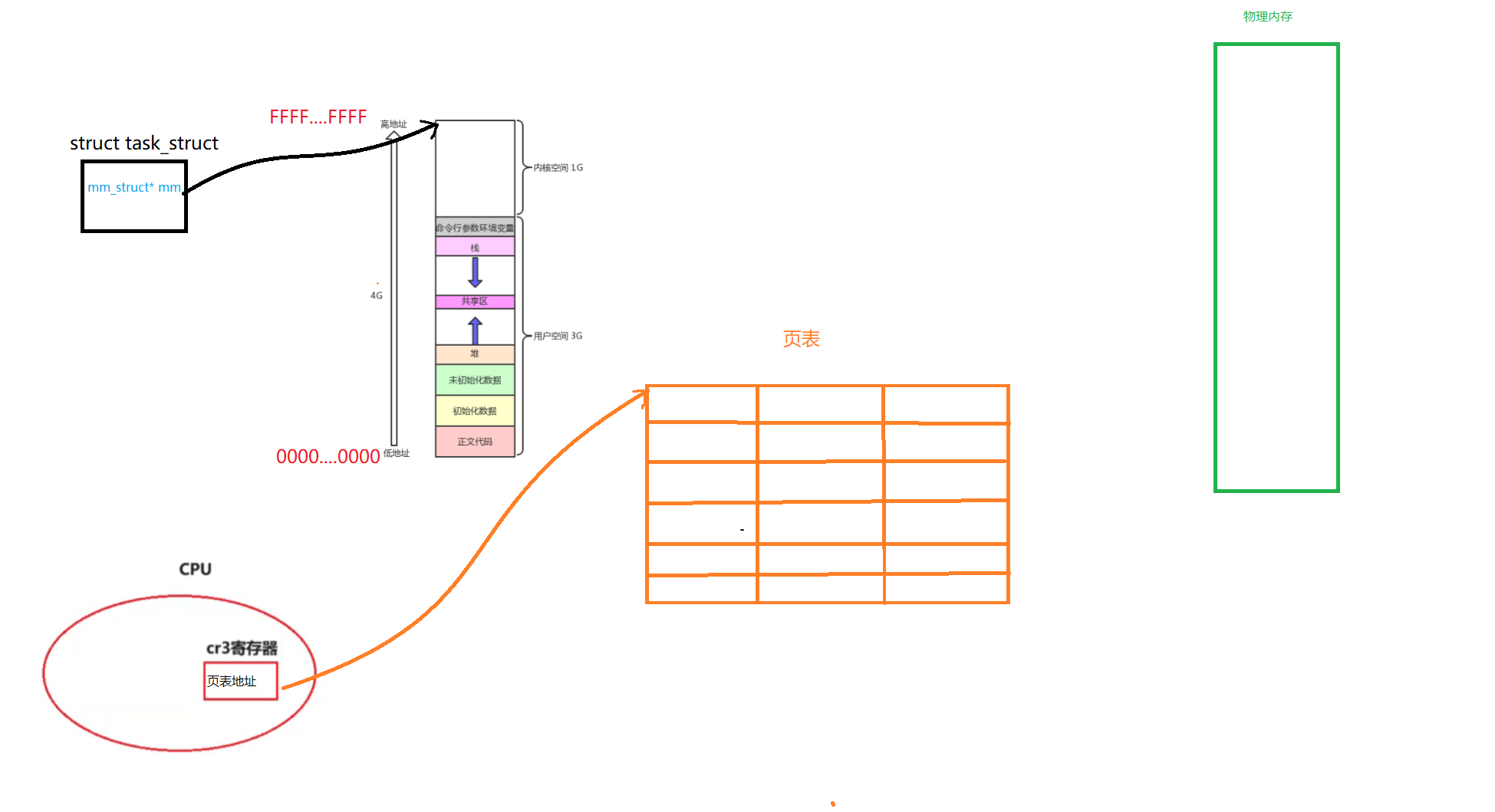
所以当我们当前这个进程如果被切换走了,我们在未来也不担心找不到这个页表
因为i这个页表地址是当前进程的临时数据,本质上属于进程的上下文。所以当未来这个进程切换的时候,会将这个地址带走。当未来在回来的时候,又会把这个数据恢复回来。所以自始至终都可以找到这个页表。
如下所示,当未来我们有一个数据的时候,必然要建立这样的映射关系
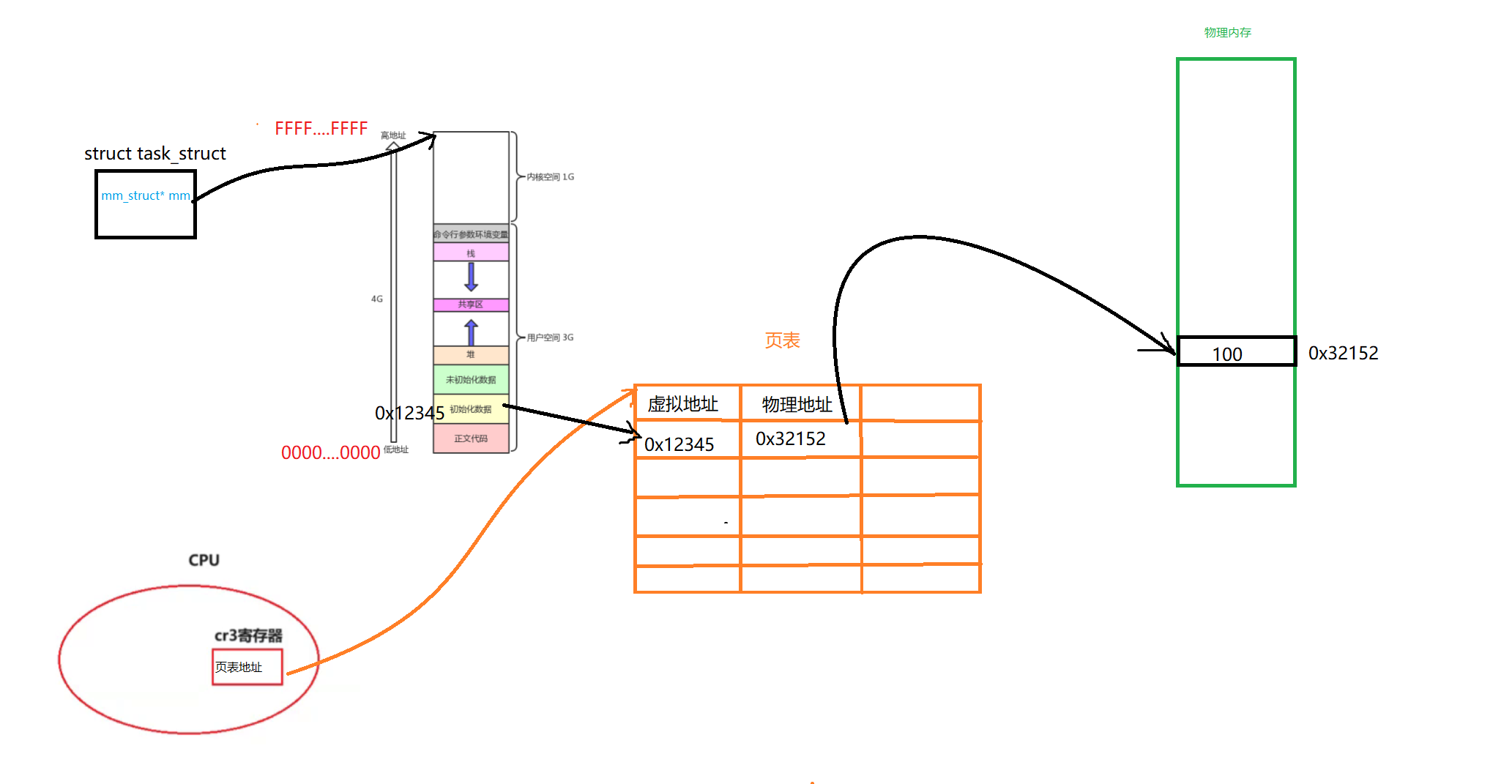
不过我们现在的问题是,我们知道字符串常量区,代码区都是只读的。不过操作系统是如何知道这个数据是只读的还是可以被写入的呢?,它是如何知道我们该物理内存是否可以被修改呢?
所以其实页表还有一个标志位。这个标志位可以确认是否被修改
如下所示,对于全局已初始化变量,它的权限是可读可写
而对于代码区的数据就是只读的了
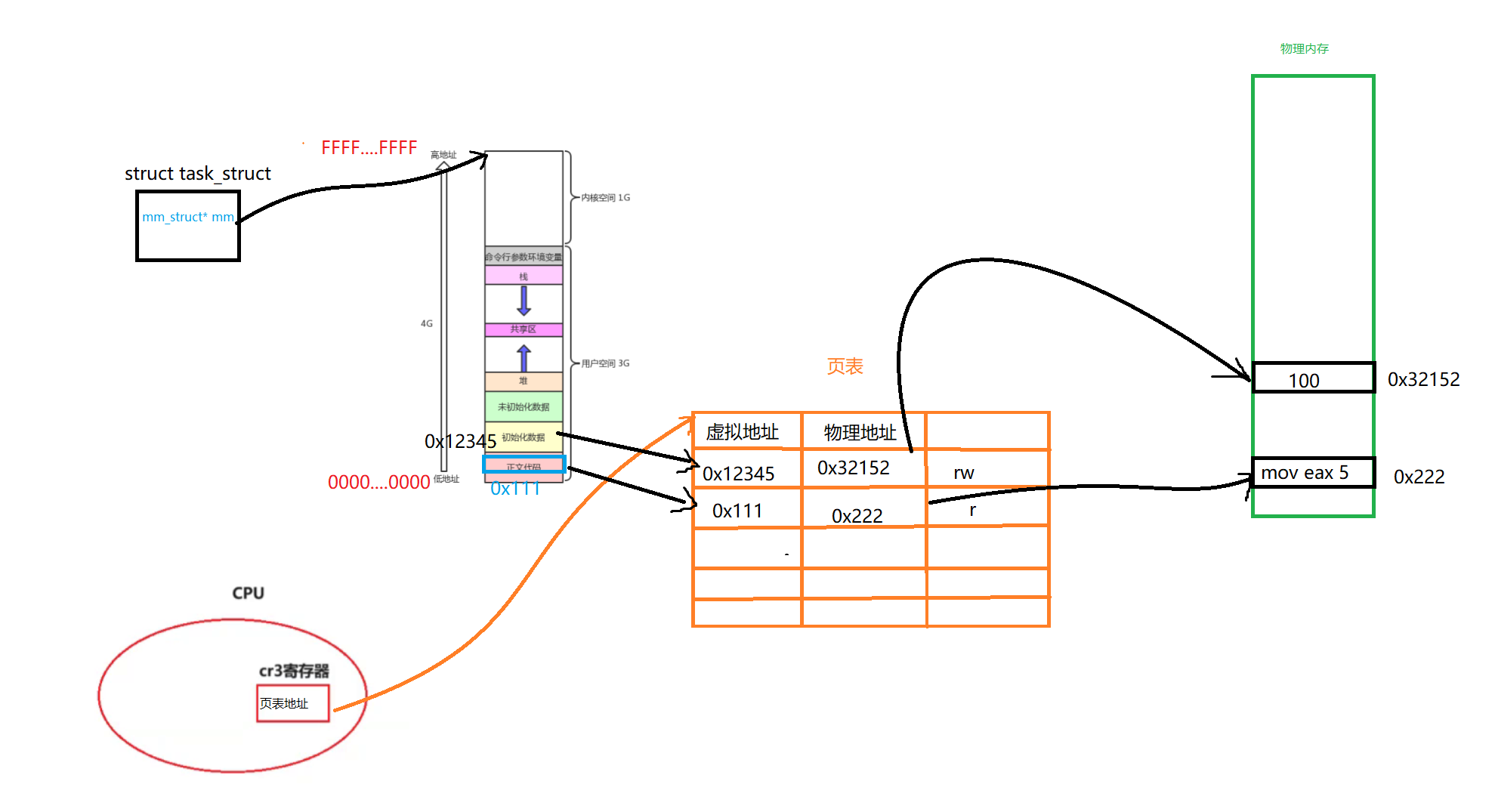
所以说页表可以提供很好的权限管理,物理内存没有权限管理的,是想写就写,想读就读的。都是由于页表在设置了权限
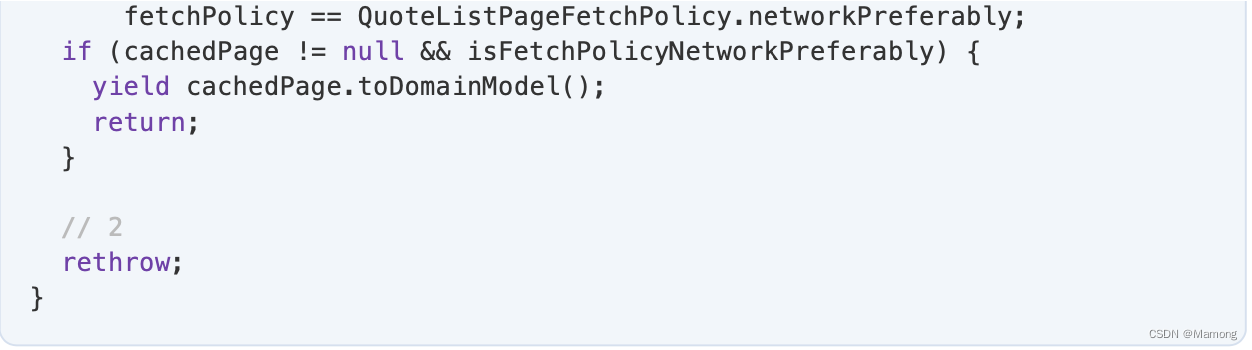
所以说对于这段代码
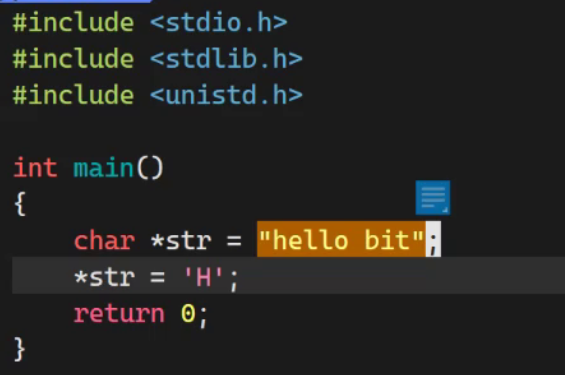
我们就知道了为什么这段代码不会被通过了
因为字符常量是只读的,在页表的权限全是只读。所以操作系统会拦截我们,所以代码就会挂掉。原因就在这里了
我们知道进程是可以被挂起的,那么我们如何知道进程已经被挂起了呢?我们怎么知道我们的进程代码数据,在不在内存呢?
这里有一个共识
现代操作系统,几乎不做任何浪费空间和浪费时间的事情
我们知道,当我们在加载原神的时候,内存肯定是塞不下的,所以操作系统一定可以对大文件实现分批加载。所以就可以加载一些比较大的文件。
所以我们操作系统加载的方式就是惰性加载的方式。(比如500MB的代码,操作系统不会上来就全部加载,只会加载5MB,因为后面很多代码暂时是用不到的)
所以有可能在页表中,虽然虚拟地址是有的,但是物理地址有可能是暂时不填的,而且页表中除了前面三个之外,还有一个字段标记位标记的该地址指向的是磁盘中的特定的地址还是内存中的地址。即对应的代码和数据是否已经被加载到内存。
所以这样的话,我们在访问页表的时候,先看该虚拟地址对应的该标记位,即查看代码和数据是否已经被加载到内存中。如果已经加载了,那么直接读取。如果没有被加载,此时我们的操作系统要发生一个缺页中断,先找到对应的可执行程序的数据,然后把这些数据加载到内存中。然后将这个内存的地址填到物理地址当中。然后再恢复到当时访问的过程。此时就可以正常访问了。
所以在极端情况下,即便我们创建好了进程,但是数据和代码完全可以一个都不加载,可以慢慢的惰性加载,此时就是边使用边加载了。但是实际上是不会这样的,一般来说总会加载一部分的。
所以进程在创建的时候,是先创建内核数据结构呢?还是先加载对应的程序呢?
这个问题我们也有了答案了,答案就是先创建内核数据结构。然后才慢慢加载可执行程序。
不过在前面说了这么多关于内存的呢,那么申请哪方面的内存呢?在哪申请内存呢?加载的时候加载的是可执行程序的那一部分呢?加载多少呢?加载到物理内存的什么位置呢?物理地址如何填到页表中呢?什么时候填呢?
这些都是谁来做呢?都是内存在做的!以上都是Linux的内存管理模块,这里我们后序再谈!
对于我们的进程而言,整个的申请内存、释放内存、包括缺页中断,重新申请…整个过程,都不关心,它也不知道,不需要去管。
所以正是由于页表的存在。我们就可以将他分为了进程管理和内存管理!
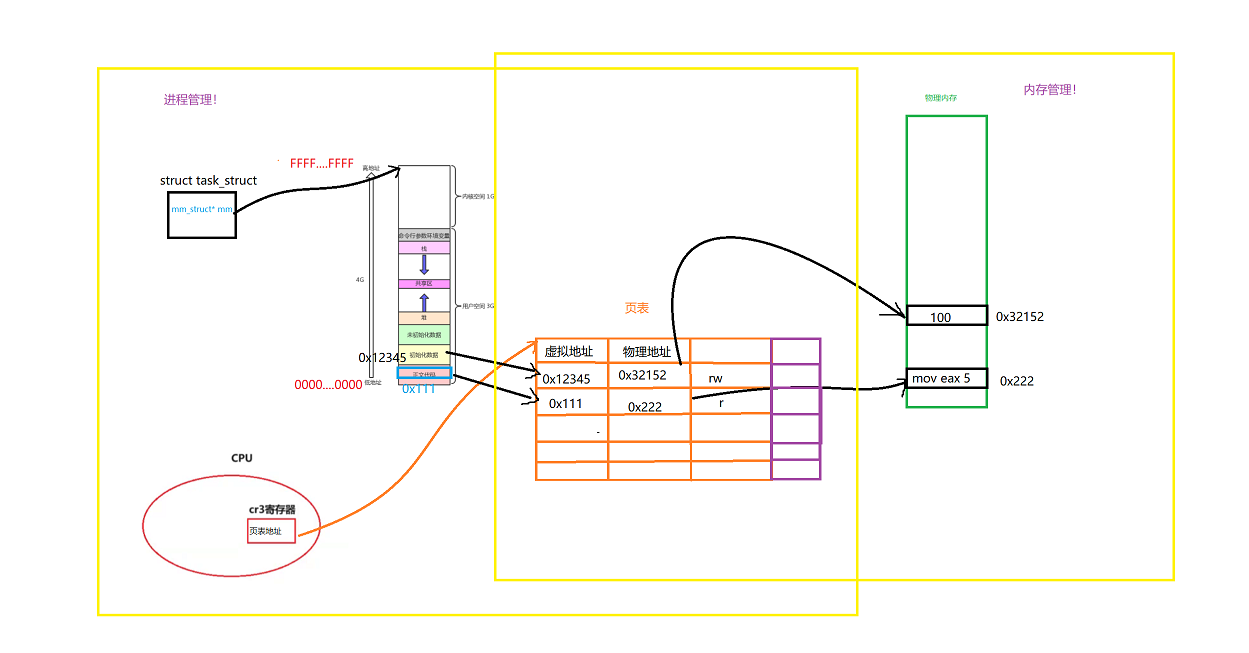
正是由于有了页表的存在,进程就可以不用再关心内存了!
所以虚拟进程地址空间的存在,将进程管理和内存管理实现了软件层面的解耦合!
这样的话,什么时候加载到物理内存,加载到物理内存哪里,这都不重要了,因为有页表映射,物理内存完全可以乱序,左侧照样可以以线性的方式呈现给用户。无序直接变有序
5.什么叫进程?
现在我们就对进程有了更深的理解了
进程 = 内核数据结构(task_struct && mm_struct && 页表) + 程序的代码和数据
只要切换了进程的PCB,进程地址空间自动被切换。因为PCB指向这个进程地址空间。又因为cr3寄存器属于进程的上下文,所以进程上下文被切换,页表自动切换。
6.进程具有独立性。为什么?怎么做到呢?
其一:因为每一个进程都有PCB表、进程地址空间、页表,所以内核数据结构是独立的。
所以父子进程都有独立的内核数据结构。
其二:还体现在曾经加载的内存和数据。只需要在页表的虚拟地址上完全一样,但是物理地址上不一样,只需要让页表映射到物理内存的不同区域,代码和数据就互相解耦合了。即便是父子关系,只需要让代码区指向一样,数据区不一样,也是在数据层面上解耦了。这样的话自己释放自己的,就不会影响别人了。
三、命令行参数的地址
我们使用如下代码
#include <stdio.h>
#include <stdlib.h>int g_val_1;
int g_val_2 = 100;int main(int argc, char* argv[], char* env[])
{printf("code addr:%p\n ",main);const char* str = "hello world";printf("read only string addr:%p\n",str);printf("init global value addr:%p\n",&g_val_2);printf("uninit global value addr:%p\n",&g_val_1); char* mem = (char*)malloc(100); char* mem1 = (char*)malloc(100); char* mem2 = (char*)malloc(100); printf("heap addr:%p\n",mem); printf("heap addr:%p\n",mem1); printf("heap addr:%p\n",mem2); printf("stack addr:%p\n",&str); printf("stack addr:%p\n",&mem); static int a = 0; int b; int c; printf("stack addr:%p\n",&a); printf("stack addr:%p\n",&b); printf("stack addr:%p\n",&c); int i = 0; for(; argv[i]; i++) { printf("argv[%d]:%p\n",i,argv[i]); } for(i = 0; env[i]; i++) { printf("env[%d]:%p\n",i,env[i]); } return 0;
}
运行结果如下
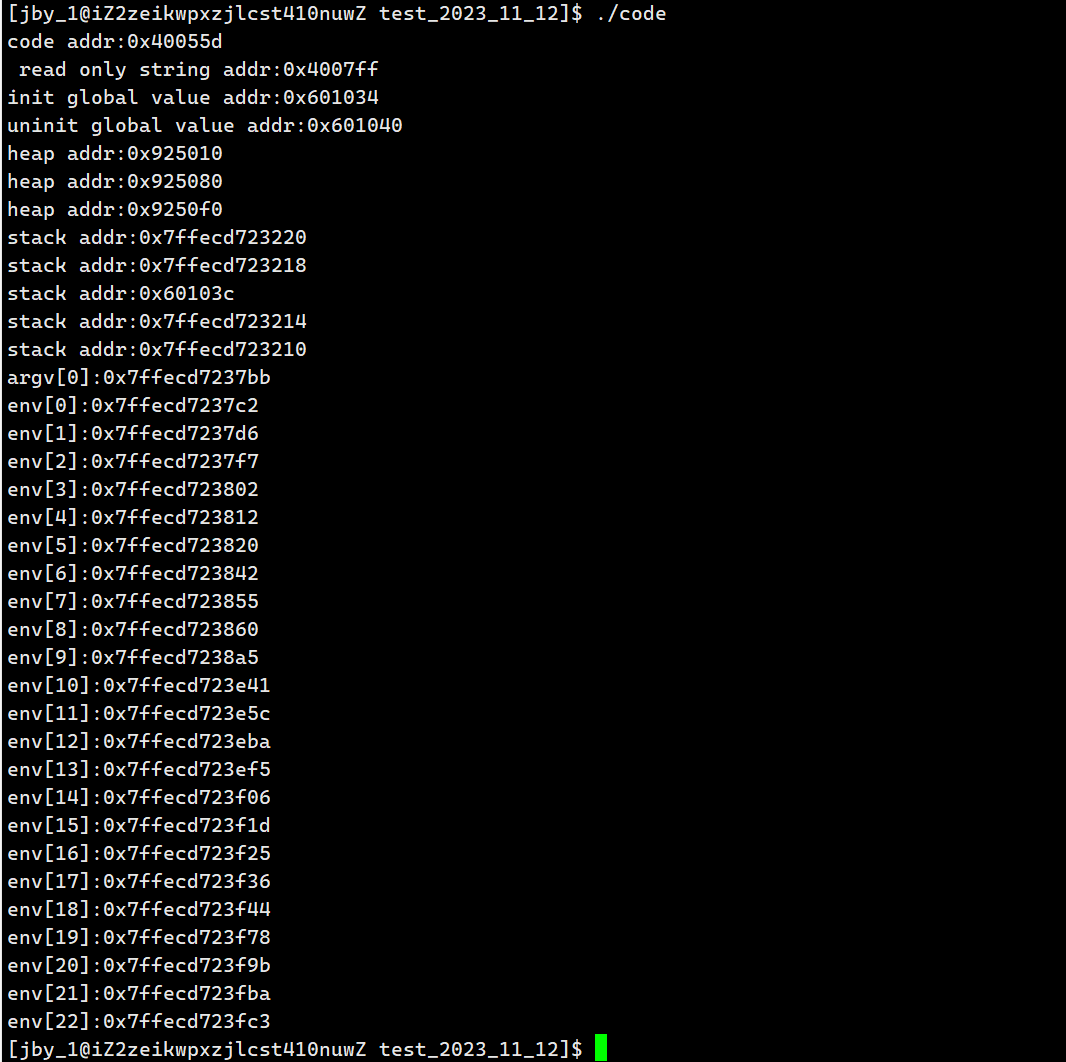
我们可以看到命令行参数的地址都在栈的上面。
所以命令行参数既不在代码区,又不在数据区,是有自己独立的区域的,在栈区之上。
当创建子进程的时候,子进程为什么能够继承父进程的环境变量呢?
因为当子进程启动的时候,父进程已经将环境变量加载了。
父进程的环境变量也是父进程地址空间的数据
父进程那里必定有页表从虚拟到物理地址的映射
所以在创建子进程的时候,子进程也已经将这个映射建立好了
所以即便不穿,对应的参数,子进程也照样可以获得对应的环境变量的信息。
这就是环境变量为什么具有全局属性,会被子进程继承下去的原因,因为它的数据是可以通过页表直接让子进程找到的
其次我们也可以看到,在地址空间中,用户是3GB,还有1GB是内核空间,是给操作系统的
所以我们的PCB,包括进程地址空间这些数据结构对象将来都要在物理内存中放的,这批数据结构是操作系统的数据结构,要映射进内核空间的这1GB.
所以我们上面所说的都是用户的空间