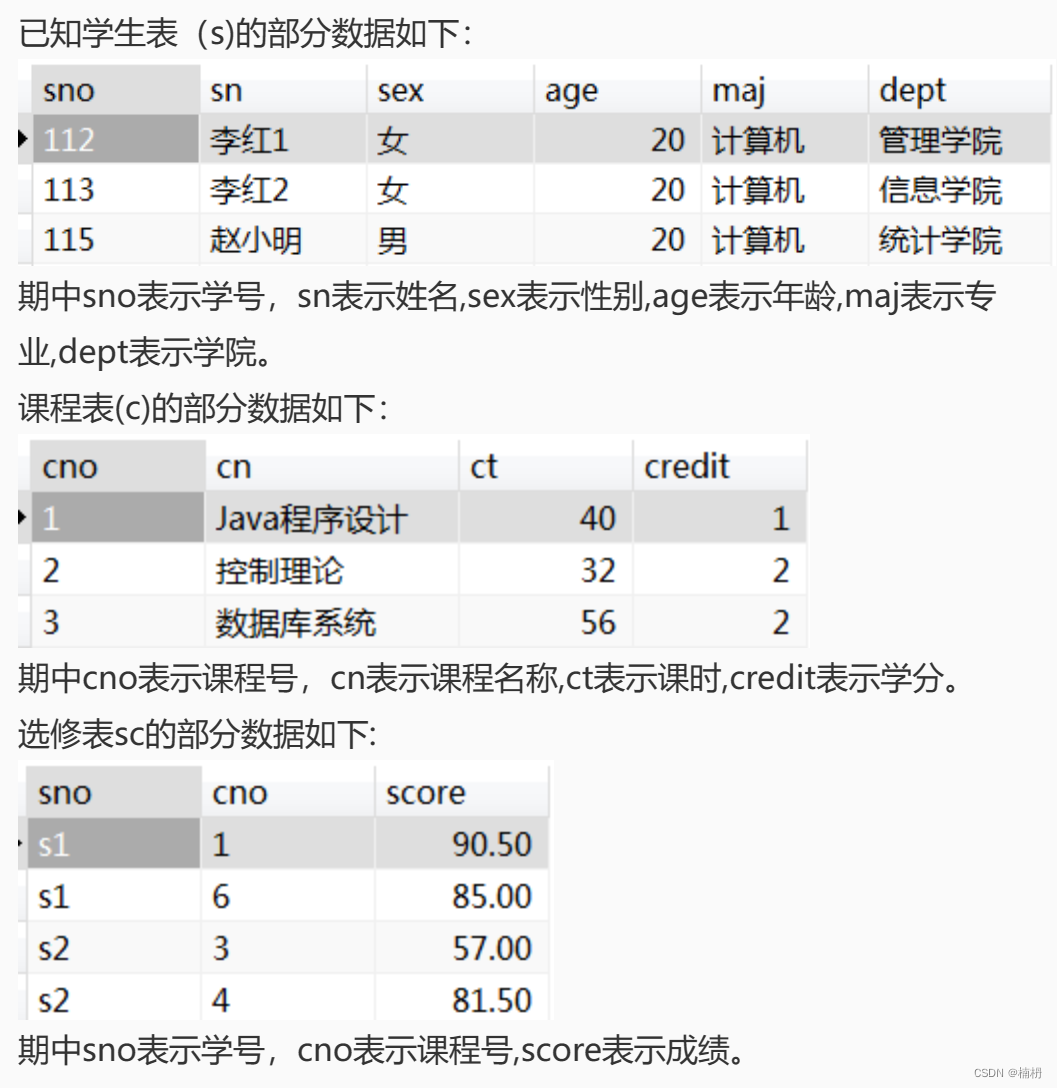
Perl爬虫程序的框架,这个框架可以用来爬取任何网页的内容。
```perl
#!/usr/bin/perl
use strict;
use warnings;
use LWP::UserAgent;
use HTML::TreeBuilder;
# 创建LWP::UserAgent对象
my $ua = LWP::UserAgent->new;
# 设置代理信息
$ua->proxy('http', '');
# 获取网页内容
my $response = $ua->get();
# 如果请求成功,打印网页内容
if ($response->is_success) {
print $response->decoded_content;
} else {
print "请求失败: ", $response->status_line;
}
```
这个爬虫程序的工作原理如下:
1. 首先,我们使用LWP::UserAgent模块创建一个对象。
2. 然后,我们使用get方法向指定的URL发起请求。
3. 如果请求成功,我们打印出网页的内容。否则,我们打印出请求失败的原因。