微信公众号上线,搜索公众号小灰灰的FPGA,关注可获取相关源码,定期更新有关FPGA的项目以及开源项目源码,包括但不限于各类检测芯片驱动、低速接口驱动、高速接口驱动、数据信号处理、图像处理以及AXI总线等

1、语音压缩编码
语音压缩编码可以分为三类:波形编码、参量编码和混合编码,均属于有损压缩编码
对波形编码的要求是保持语音不变,或使波形失真尽量小
对参量编码和混合编码的性能要求是保证语音的可懂度和清晰度尽量高
2、语音参量编码
语音参量编码是将语音的主要参量提取处理编码
参量编码的原理是首先分析语音的短时频谱特性,提取出语音的频谱参量,然后再用这些参量合成语音波形。这种压缩编码方法是一种合成/分析编码方法
(1)发音器官和发音原理
发音器官包括次声门系统、声门和声道。次声门系统包括肺、支气管、气管,是产生语音的能量来源。声门即喉部两侧的声带及声带间的区域。声道包括咽腔、鼻腔、口腔及其附属器官。
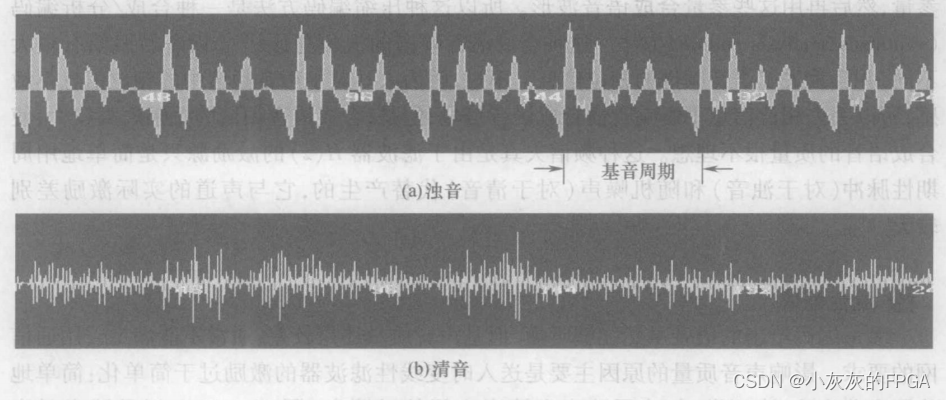
从次声门送来的气流,在经过声门时,若声带振动,则产生浊音;反之,则产生清音。浊音具有周期性,周期取决于声带的振动。深度振动的频谱中包含一些列频率,其中最低的频率成分为基音,基音频率决定了声音的音调;其他频率为基音的谐波,与声音的音色有关。发清音时,声带不振动。清音仅是次声门产生的准平稳气流声,它的波形很像随机起伏的噪声。
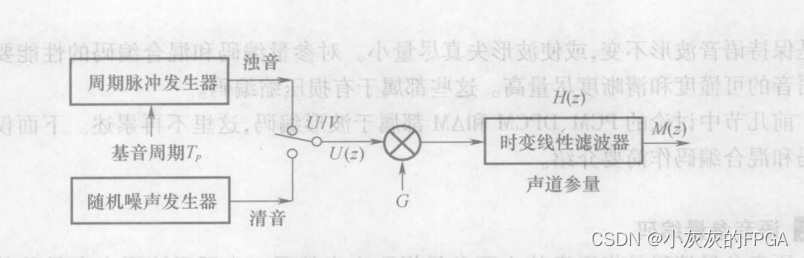
(2)语音产生模型
在语音产生模型中,当发浊音是,用周期性脉冲表示声带振动产生的声波。当发清音时,用随机噪声表示经过声门发送的准平稳气流。从声门送出的声波U(z)用G加权,G表示声音强度,然后送入一个时变线性滤波器,最后产生语音输入M(z)。
在短时间间隔内(20ms),语音产生模型中的所有参量都是恒定的,即浊音或清音(U/V)判决、浊音的基音周期(Tp)、声门输出的强度(U(z))、音量(G)以及声道参量(滤波器传输函数H(z))等5个参量都是不变的
在发送端,在每隔一段时间间隔(20ms)内,从语音中提取出5个参量加以编码,然后传输;在接收端,对接收信号解码后,用5个参量就可以恢复出原语音信号。
按照上述原理对语音信号编码,利用语音产生模型慢变化的特性,使编码速率大大降低,可达到2.4kb/s,这种参量编码器称为声码器
3、混合编码
影响声音质量的主要原因是送入时变线性滤波器的激励过于简单化,简单地将语音分为浊、清两类,忽略了浊音与清音直接的过渡音,以及浊音时在20ms内的激励脉冲波形和周期不变,清音时的随机噪声也不变
合成/分析法改进的途径主要是改进线性滤波器的激励
混合编码除了采用时变线性滤波器作为其核心外,还在激励源中加入了语音波形的某种信息,从而改进其合成语音的质量。由于既采用了语音参量又包括了部分语音波形信息,称为混合编码
通信原理板块——语音压缩编码
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/191170.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章
接口开放太麻烦?试试阿里云API网关吧
前言
我在多方合作时,系统间的交互是怎么做的?这篇文章中写过一些多方合作时接口的调用规则和例子,然而,接口开放所涉及的安全、权限、监控、流量控制等问题,可不是简简单单就可以解决的,这一般需要专业的…
高通SDX12:ASoC 音频框架浅析
一、简介
ASoC–ALSA System on Chip ,是建立在标准ALSA驱动层上,为了更好地支持嵌入式处理器和移动设备中的音频Codec的一套软件体系。 本文基于高通SDX12平台,对ASoC框架做一个分析。
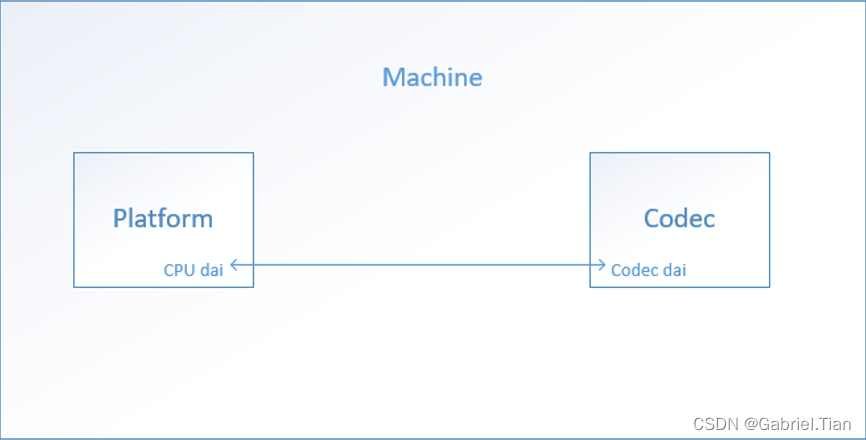
二、整体框架
1. 硬件层面
嵌入式Linux设备的Audio subsystem可以划分为Machine(板…

高效攻略各类BOSS,成为真正的剑侠!
逆水寒作为一款备受瞩目的国产武侠游戏,其精美的画面和真实的剑术体验吸引了众多玩家。在这篇实用干货分享中,我们将详细介绍一些攻略各类BOSS的技巧和策略,帮助你在游戏中轻松击败强大的对手,成为真正的剑侠大师。 首先ÿ…

【机器学习基础】机器学习入门(1)
🚀个人主页:为梦而生~ 关注我一起学习吧! 💡专栏:机器学习 欢迎订阅!后面的内容会越来越有意思~ 💡专栏介绍: 本专栏的第一篇文章,当然要介绍一下了~来说一下这个专栏的开…
【已解决】vscode 配置C51和MDK环境配置
使用命令 gcc -v -E -x c - 看自己gcc 有没有安装好
也可以在自己的vscode中新建一个终端
gcc -v
g -v 首先把自己的C51 和MDK 路径 设置好
vscode 中设置 C51 和 MDK 的路径 这是你keil 中写 51单片机和 STM32 的 如果你出现什么include 的什么波浪线,那估计…
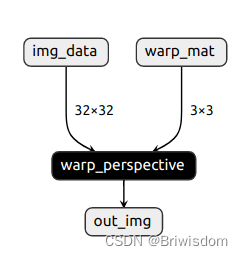
记录pytorch实现自定义算子并转onnx文件输出
概览:记录了如何自定义一个算子,实现pytorch注册,通过C编译为库文件供python端调用,并转为onnx文件输出
整体大概流程:
定义算子实现为torch的C版本文件注册算子编译算子生成库文件调用自定义算子
一、编译环境准备…
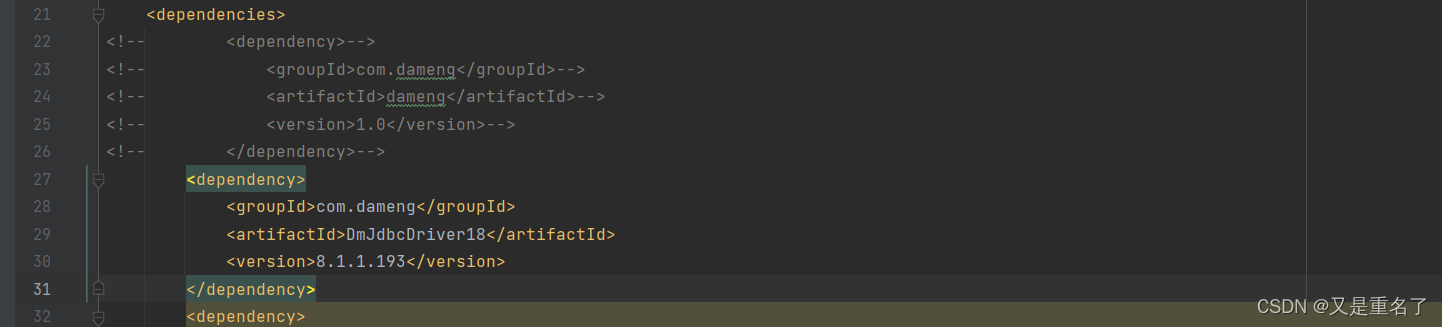
dameng数据库数据id decimal类型,精度丢失
问题处理
这一次也是精度丢失,但是问题呢还是不一样,这一次所有的id都被加一了,只有id字段被加一,还有的查询查出来封装成对象之后对象的id字段被减一了,数据库id字段使用的decimal(20,6)&…

sass 封装媒体查询工具
背景
以往写媒体查询可能是这样的:
.header {display: flex;width: 100%;
}media (width > 320px) and (width < 480px) {.header {height: 50px;}
}media (width > 480px) and (width < 768px) {.header {height: 60px;}
}media (width > 768px) …
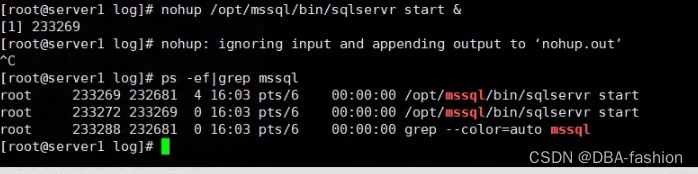
Linux下MSSQL (SQL Server)数据库无法启动故障处理
有同事反馈一套CentOS7下的mssql server2017无法启动需要我帮忙看看,启动报错情况如下 检查日志并没有更新日志信息 乍一看mssql-server服务有问题,检查mssql也确实没有进程 既然服务有问题,那么我们用一种方式直接手工后台启动mssql引擎来…
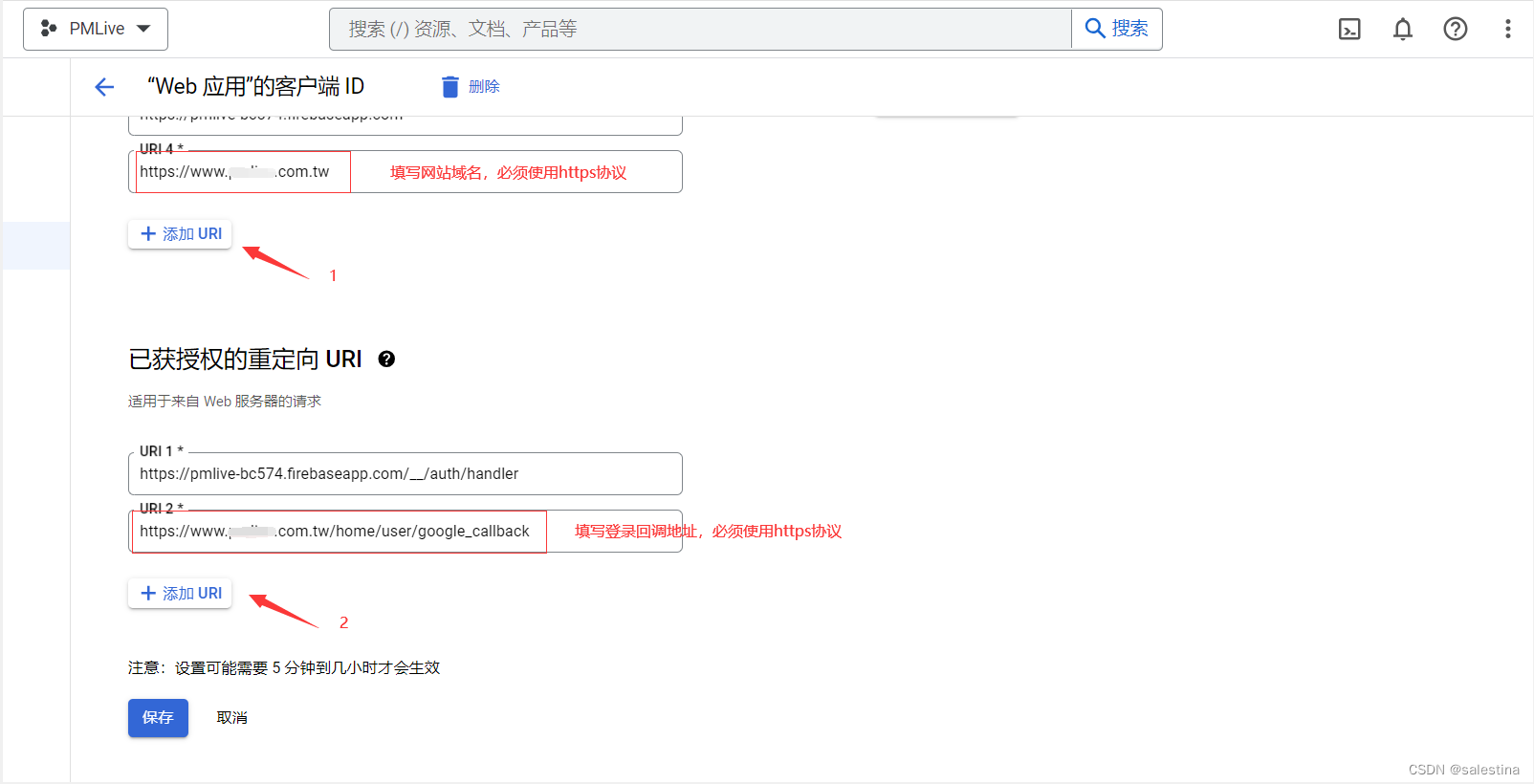
集成Line、Facebook、Twitter、Google、微信、QQ、微博、支付宝的三方登录sdk
下载地址:
https://githubfast.com/anerg2046/sns_auth
安装方式建议使用composer进行安装
如果linux执行composer不方便的话,可以在本地新建个文件夹,然后执行上面的composer命令,把代码sdk和composer文件一起上传到项目适当位…
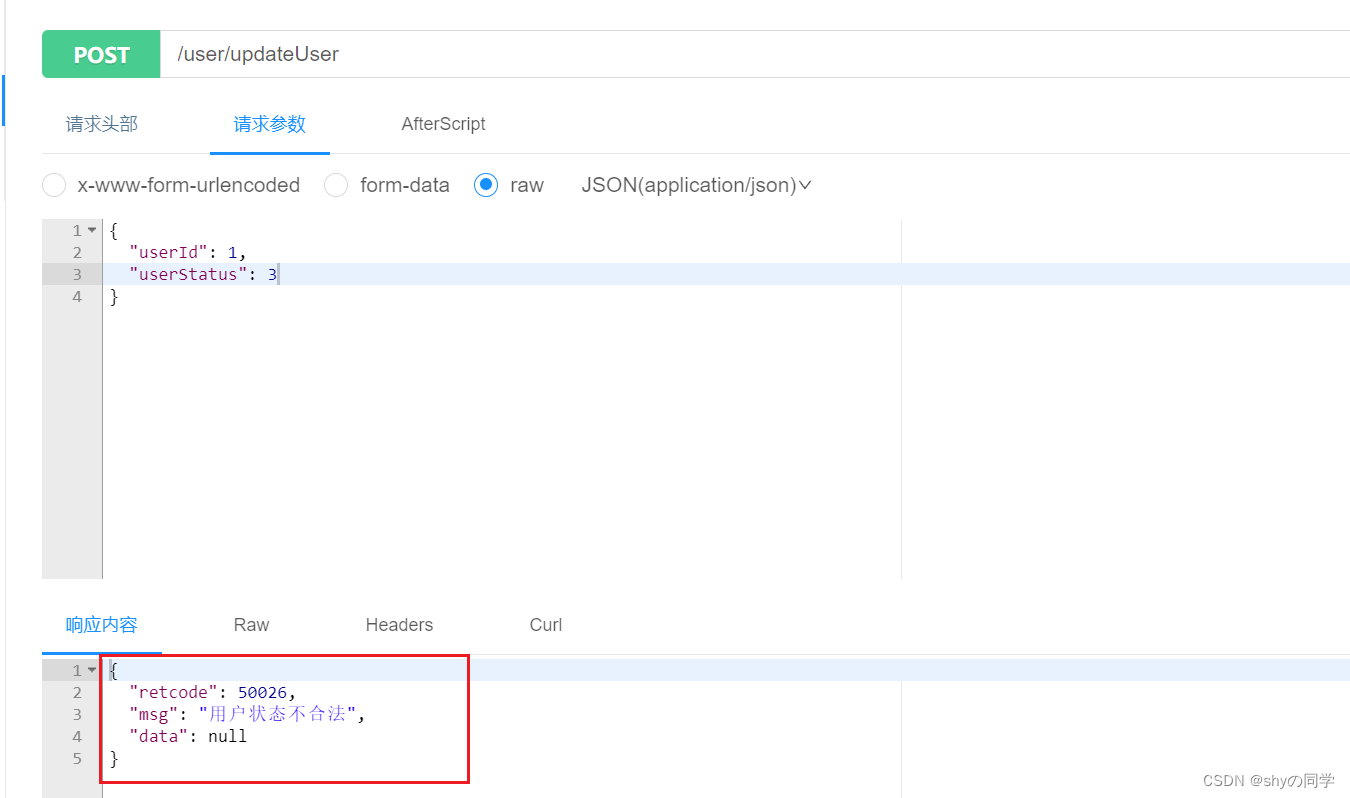
使用validator实现枚举类型校验
使用validator实现枚举类型校验
前言: 在前端调用后端接口传递参数的过程中,我们往往需要对前端传递过来的参数进行校验,比如说我们此时需要对用户的状态进行更新,而用户的状态只有正常和已删除,并且是在代码中通过枚…
点大商城V2版 2.5.3全插件开源独立版 百度+支付宝+QQ+头条+小程序端+unipp开源端安装测试教程
点大商城V2是一款采用全新界面设计支持多端覆盖的小程序应用,支持H5、微信公众号、微信小程序、头条小程序、支付宝小程序、百度小程序,本程序是点大商城V2独立版,包含全部插件,代码全开源,并且有VUE全端代码。
适用范…

使用Python和requests库的简单爬虫程序
这是一个使用Python和requests库的简单爬虫程序。我们将使用代理来爬取网页内容。以下是代码和解释:
import requests
from fake_useragent import UserAgent
# 每行代理信息
proxy_host "jshk.com.cn"
# 创建一个代理器
proxy {http: http:// proxy_…

Clickhouse学习笔记(10)—— 查询优化
单表查询
Prewhere 替代 where
prewhere与where相比,在过滤数据的时候会首先读取指定的列数据,来判断数据过滤,等待数据过滤之后再读取 select 声明的列字段来补全其余属性
简单来说就是先过滤再查询,而where过滤是先查询出对应…
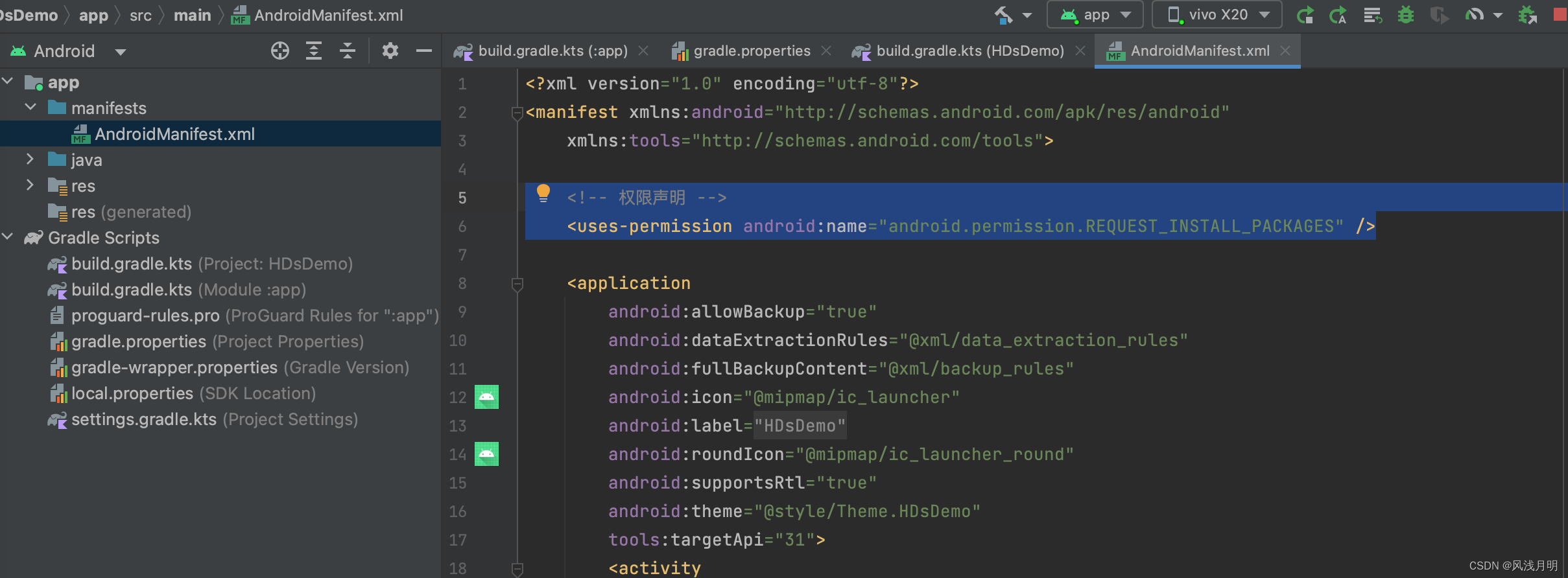
Android Studio真机运行时提示“安装失败”
用中兴手机真机运行没问题,用Vivo运行就提示安装失败。前提,手机已经打开了调试模式。 报错
Android Studio报错提示:
Error running app
The application could not be installed: INSTALL_FAILED_TEST_ONLY 手机报错提示: 修…

专访|OpenTiny 社区 Mr 栋:结合兴趣,明确定位,在开源中给自己一些技术性挑战
前言
OpenTiny 开源之夏项目终于迎来了圆满的结局。借此机会,我们采访了 TinyReact 的共建者 Mr 栋同学。 Mr 栋同学是一位热衷于前端技术的开发者,对前端开发充满了激情和热爱。同时他也是一位即将毕业的大四在校生。在 OpenTiny 开源项目中࿰…

Window安装MongoDB
三种NOSQL的一种,Redis MongoDB ES
应用场景:
1.社交场景:使用Mongodb存储用户信息,以及用户发表的朋友圈信息,通过地理位置索引实现附近的人,地点等功能
2.游戏场景:使用Mongodb存储游戏用户信息,用户的装备,积分等直接以内嵌文档的形式存储,方便查询,高效率存储和访问…

软路由R4S+iStoreOS实现公网远程桌面局域网内电脑
软路由R4SiStoreOS实现公网远程桌面局域网内电脑 文章目录 软路由R4SiStoreOS实现公网远程桌面局域网内电脑简介 一、配置远程桌面公网地址配置隧道 二、家中使用永久固定地址 访问公司电脑具体操作方法是:2.1 登录页面2.2 再次配置隧道2.3 查看访问效果 简介
上篇…

EDA实验-----3-8译码器设计(QuartusII)
目录
一. 实验目的
二. 实验仪器
三. 实验原理及内容
1.实验原理
2.实验内容
四.实验步骤
五. 实验报告
六. 注意事项 七. 实验过程
1.创建Verilog文件,写代码
编辑
2.波形仿真
3.连接电路图
4.烧录操作 一. 实验目的
学会Verilog HDL的…