【python自动化】Playwright基础教程(六)事件操作③单击&双击&计数&过滤&截图&JS注入
本文目录
文章目录
- 【python自动化】Playwright基础教程(六)事件操作③单击&双击&计数&过滤&截图&JS注入
- playwright系列回顾
- 前文代码
- 点击 - click
- 官方示列
- 点击常用实战
- 双击 - dblclick
- 双击实战
- 计数 - count
- 计数使用实战
- 过滤 - filter
- 过滤实战
- 截图 - screenshot
- 截图实战
- 执行js - evaluate
- JS注入实战
- JS注入实战
playwright系列回顾
playwright连接已有浏览器操作
selenium&playwright获取网站Authorization鉴权实现伪装requests请求
【python自动化】playwright长截图&切换标签页&JS注入实战
【python自动化】Playwright基础教程(二)快速入门
【python自动化】Playwright基础教程(三)定位操作
【python自动化】Playwright基础教程(四)事件操作①元素高亮&元素匹配器
【python自动化】Playwright基础教程(五)事件操作②悬停&输入&清除精讲
前文代码
直接定位指定浏览器
class Demo05:def __init__(self):"""使用playwright连接谷歌浏览器:return:"""self.playwright = sync_playwright().start()# 连接已经打开的浏览器,找好端口browser = self.playwright.chromium.connect_over_cdp("http://127.0.0.1:9223")self.default_context = browser.contexts[0]self.page = self.default_context.pages[0]
启动新的浏览器
class Demo06:def __init__(self, url):playwright = sync_playwright().start()browser = playwright.chromium.launch(headless=False)context = browser.new_context()self.page = context.new_page()self.page.goto(url)if __name__ == '__main__':mwj = Demo05(url="指定的url")mwj.Locator_testid()
点击 - click
单击一个元素
使用方法
page.get_by_role("button").click()
参数
| 参数 | 类型 | 释义 |
|---|---|---|
| button | List[“left”, “middle”, “right”] | 左、中、右可选,默认是左left |
| click_count | int | 默认值为1,具体看:https://developer.mozilla.org/en-US/docs/Web/API/UIEvent/detail |
| delay | float | 按下按键和松开按键之间时间(单位为毫秒),默认为0毫秒。 |
| force | bool | 是否绕过可操作性检查。默认值为 false |
| modifiers | List[“Alt”, “Control”, “Meta”, “Shift”] | 要按下的修饰键,有四个可供选择。 |
| position | Dict | {x: float, y: float},相对于元素填充框的左上角的点,如果没有指定,则使用元素的某个可见点。 |
| trial | bool | 设置后,此方法仅执行可操作性检查并跳过操作。默认值为 false 。等到元素可以执行操作时再执行。 |
| no_wait_after | bool | 可以通过设置此标志来选择退出等待,只有在特殊情况下(例如导航到无法访问的页面)才需要此选项。默认值为 false 。 |
| timeout | float | 最长等待时间,单位毫秒,默认值为30000(30秒)。 |
官方示列
要求:按住Shift键再右键点击画布的特定位置。
page.locator("canvas").click(button="right", modifiers=["Shift"], position={"x": 23, "y": 32}
)
点击常用实战
案列需求
- 在搜索框输入
梦无矶小仔,点击百度一下。
代码
def click_demo01(self):# 在搜索框中输入 梦无矶小仔self.page.locator("//input[@id='kw']").fill("梦无矶小仔")# 点击百度一下(id="su")self.page.locator("//input[@id='su']").click()
效果展示

双击 - dblclick
双击一个元素
使用方法
locator.dblclick()
locator.dblclick(**kwargs)
参数
| 参数 | 类型 | 释义 |
|---|---|---|
| button | List[“left”, “middle”, “right”] | 左、中、右可选,默认是左left |
| delay | float | 按下按键和松开按键之间时间(单位为毫秒),默认为0毫秒。 |
| force | bool | 是否绕过可操作性检查。默认值为 false |
| modifiers | List[“Alt”, “Control”, “Meta”, “Shift”] | 要按下的修饰键,有四个可供选择。 |
| position | Dict | {x: float, y: float},相对于元素填充框的左上角的点,如果没有指定,则使用元素的某个可见点。 |
| trial | bool | 设置后,此方法仅执行可操作性检查并跳过操作。默认值为 false 。等到元素可以执行操作时再执行。 |
| no_wait_after | bool | 可以通过设置此标志来选择退出等待,只有在特殊情况下(例如导航到无法访问的页面)才需要此选项。默认值为 false 。 |
| timeout | float | 最长等待时间,单位毫秒,默认值为30000(30秒)。 |
双击实战
实战测试网址:https://cps-check.com/cn/double-click-test
代码
def dblclick(self):for i in range(5):self.page.locator("#clicker").dblclick()
这里我们循环点击五次双击。
效果展示
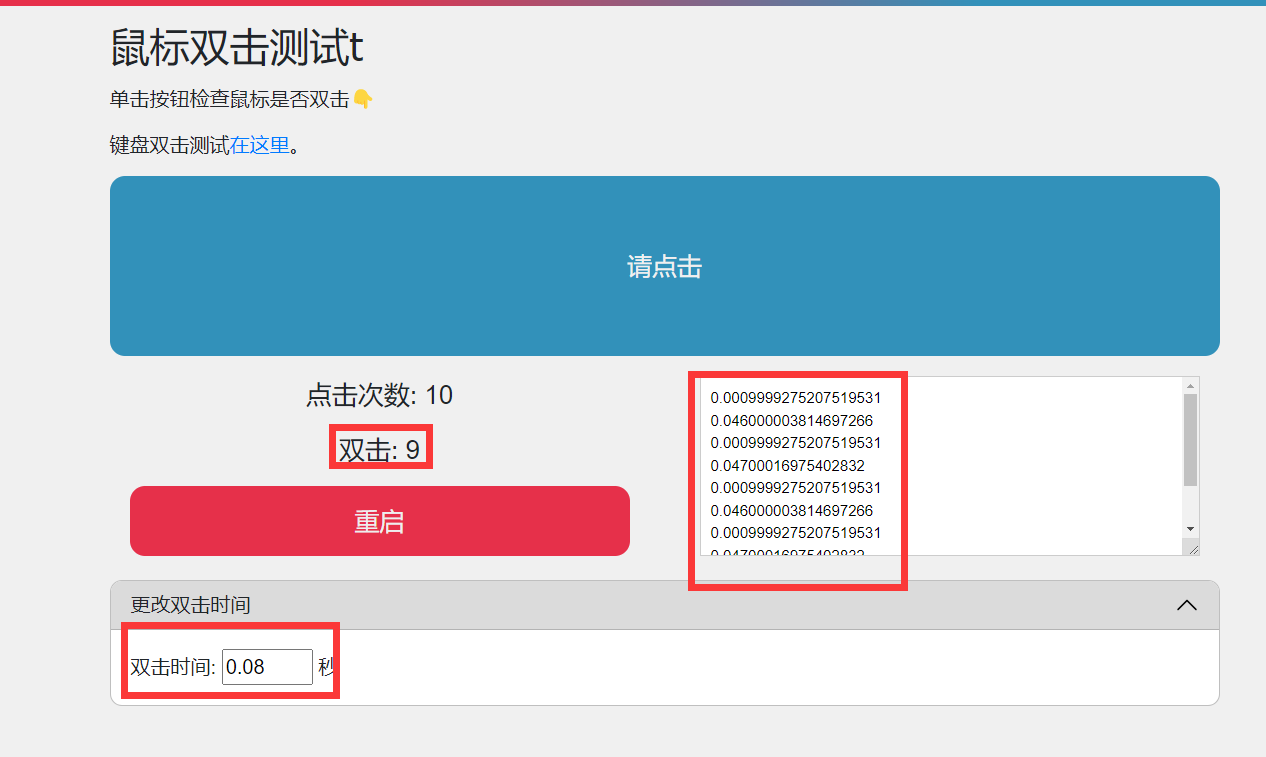
网页显示说点了九次双击,大于我们设定的5次,这是因为我们的playwright太快啦!
如果只运行一次双击,那这里显示的双击就是一次。
计数 - count
返回与定位方式匹配的元素个数。(在之前的highlight中我们展示梦无矶元素的时候就能看到后面的计数。)
使用方法
count = page.get_by_role("listitem").count()
返回值
返回一个int类型的数值。
计数使用实战
- 统计搜索页面上有多少个
梦无矶
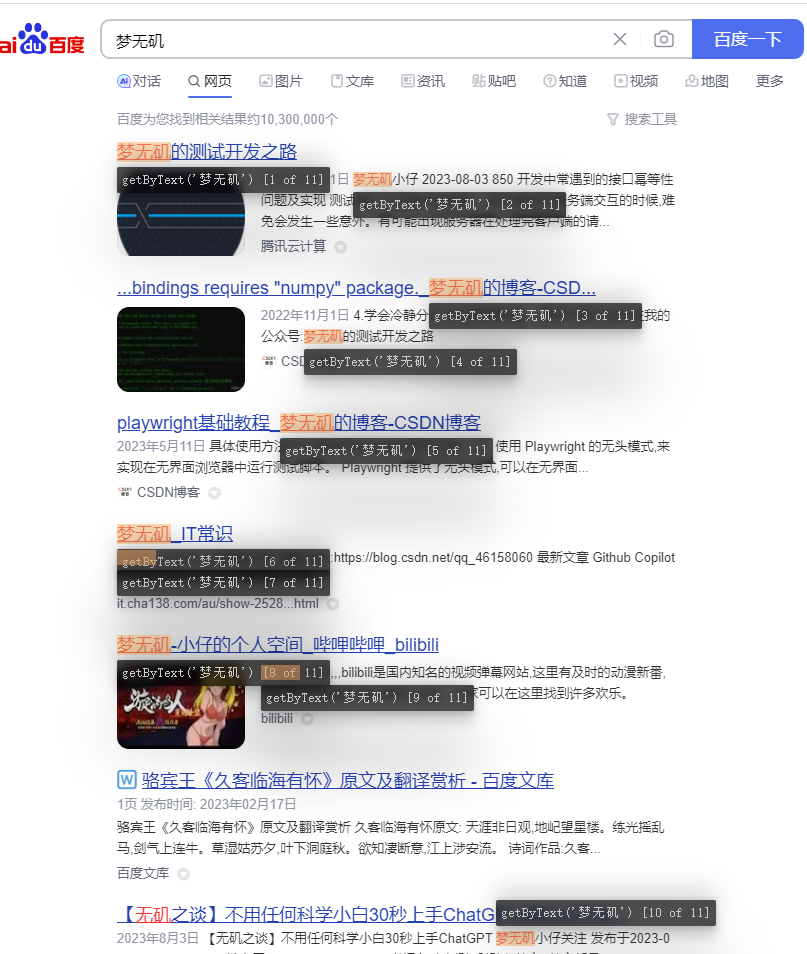
代码展示
def count_operate(self):self.page.get_by_text("梦无矶").highlight()mwj_count = self.page.get_by_text("梦无矶").count()print(mwj_count)
输出结果
11
过滤 - filter
根据选项缩小现有定位方式的定位范围(如文本过滤),并且可以多级过滤。
使用方法
row_locator = page.locator("tr")
# ...
row_locator.filter(has_text="text in column 1").filter(has=page.get_by_role("button", name="column 2 button")
).screenshot()
参数
| 参数 | 类型 | 释义 |
|---|---|---|
| has | Locator | 匹配包含与内部定位器匹配的元素的元素。根据外部定位器查询内部定位器。例如, article 有 text=Playwright 匹配 <article><div>Playwright</div></article> 项。 |
| has_not | Locator | 和上面的相反,匹配不存在某个元素。 |
| has_not_text | str | 匹配不包含指定文本的元素,这些元素可能包含子元素或后代元素。传递 [string] 时,匹配不区分大小写并搜索子字符串。 |
| has_text | str | 匹配包含指定文本的元素,这些元素可能包含子元素或后代元素。传递 [string] 时,匹配不区分大小写并搜索子字符串。例如,“Playwright” 匹配 <article><div>Playwright</div></article> . |
返回值
返回一个定位器,Locator
实用场景
- 有时候我们遇到的元素不好一步到位定位,我们就可以使用过滤一步步进行定位。
- 有多个相同定位的元素,但是某个属性不同,我们可以通过过滤进行定位需要的元素。
- 在翻页操作中,最后一页的
>箭头一般是置灰不可操作,有is-disabled类似的属性,可以通过过滤该元素是否有次属性,从而判断我们现在是否翻页到了最后一页。
过滤实战
案列需求:悬浮到产品,显示后定位悬浮框中计算的云服务器ECS。(我强行写的案列,实际操作可以一步到位。)

元素定位
产品的网页源码
<a class="global-menu-item" href="https://www.aliyun.com/product/list" target="_self" data-spm-anchor-id="5176.28055625.J_4VYgf18xNlTAyFFbOuOQe.2"><span>产品</span><i class="navIconfont icon-topnavput_away"></i></a>
-
这里我们看到
class="global-menu-item",但是和产品同一行的这些文字,都有相同的class属性(有九个),通过高亮显示得知,这个是第一个,所以我们使用如下定位。 -

-
self.page.locator('[class="global-menu-item"]').nth(0)
计算源码

-
同理,计算这一列所有元素都有
class="menu-type-title",我们可以进行过滤计算这个文本进行定位。(这里是为了演示filter,如果用xpath会更简单,抬杠的自己从30楼倒立走到1楼,我都会给你秀一遍) -
以下定位方式,都可以定位到
计算 -
self.page.locator('[class="menu-type-title"]').filter(has_text="计算").first.highlight()# Xpath 删除 计算 前后的空白字符进行匹配 self.page.locator('//a[normalize-space()="计算"]').highlight() # Xpath文本匹配 self.page.locator('//a[text()="计算"]').highlight() # Xpath 多级匹配 self.page.locator('//div[@class="menu-left-content"]//a[text()="计算"]').highlight() -

云服务器ECS的网页源码

这里和计算的定位方式一样,这里就不赘述了。
完整代码
def filter_operate(self):# 本案例url= 'https://www.aliyun.com/'# 鼠标悬浮到 产品self.page.locator('[class="global-menu-item"]').nth(0).hover()self.page.wait_for_timeout(500)# 再悬浮到 计算self.page.locator('[class="menu-type-title"]').filter(has_text="计算").first.hover()# Xpath 删除 计算 前后的空白字符进行匹配# self.page.locator('//a[normalize-space()="计算"]').highlight()# Xpath文本匹配# self.page.locator('//a[text()="计算"]').highlight()# Xpath 多级匹配# self.page.locator('//div[@class="menu-left-content"]//a[text()="计算"]').highlight()# 再高亮云服务器ECSself.page.locator('//a[@class="menu-item-title"]').filter(has_text="云服务器 ECS").nth(0).highlight()
效果展示

截图 - screenshot
截取与定位器匹配的元素的屏幕截图
使用方法
page.get_by_role("link").screenshot()
参数
| 参数 | 类型 | 含义 |
|---|---|---|
| timeout | Union[float, None] | 最大等待时间,以毫秒为单位。默认为30000(30秒)。传入0以禁用超时。browser_context.set_default_timeout()或page.set_default_timeout()方法更改默认值。 |
| type | Union[“jpeg”, “png”, None] | 指定截图的类型,默认为png。 |
| path | Union[pathlib.Path, str, None] | 图像保存的文件路径。截图类型将根据文件扩展名进行推断。如果path是相对路径,则相对于当前工作目录解析。如果不提供路径,则图像将不会保存到磁盘。 |
| quality | Union[int, None] | 图像的质量,介于0到100之间。不适用于png图像。 |
| omit_background | Union[bool, None] | 隐藏默认的白色背景,允许使用透明度进行截图。不适用于jpeg图像。默认为false。 |
| animations | Union[“allow”, “disabled”, None] | 设置为"disabled"时,停止CSS动画、CSS过渡和Web动画。动画的处理方式取决于其持续时间:有限动画将快进到完成状态,因此它们会触发transitionend事件。 无限动画将取消到初始状态,然后在截图后重新播放。默认为"allow",即保持动画不变。 |
| caret | Union[“hide”, “initial”, None] | 设置为"hide"时,截图将隐藏文本插入符。设置为"initial"时,文本插入符的行为不会改变。默认为"hide"。 |
| scale | Union[“css”, “device”, None] | 设置为"css"时,截图上每个CSS像素将具有一个实际像素。对于高DPI设备,这将使截图保持较小的大小。使用"device"选项将使每个设备像素有一个实际像素,因此高DPI设备的截图将是两倍或更大。默认为"device"。 |
| mask | Union[List[Locator], None] | 指定在截图时应隐藏的定位符。被隐藏的元素将被叠加一个粉色框#FF00FF(由maskColor自定义),完全覆盖其边界框。 |
| mask_color | Union[str, None] | 指定被隐藏元素的覆盖框的颜色,以CSS颜色格式表示。默认颜色为粉色#FF00FF。 |
截图实战
参考之前的文章【截图】部分:【python自动化】playwright长截图&切换标签页&JS注入实战
执行js - evaluate
在页面中执行 JavaScript 代码,将匹配元素作为参数。
使用方法
tweets = page.locator(".tweet .retweets")
assert tweets.evaluate("node => node.innerText") == "10 retweets"
参数
| 参数 | 类型 | 释义 |
|---|---|---|
| expression | str | 在浏览器上下文中运行的 JavaScript 表达式。如果表达式的计算结果为函数,则会自动调用该函数。 |
| arg | Evaluation Argument | 参数参考JS:https://playwright.dev/python/docs/next/evaluating#evaluation-argument |
| timeout | float | 最长等待时间,单位毫秒,默认值为30000(30秒)。 |
另外一个执行js的方法是evaluate_handle
page.evaluate() 和 page.evaluate_handle() 之间的唯一区别是 page.evaluate_handle() 返回 JSHandle。
JS注入实战
参考之前的文章【JS注入】部分:【python自动化】playwright长截图&切换标签页&JS注入实战
和 page.evaluate_handle() 之间的唯一区别是 page.evaluate_handle() 返回 JSHandle。
JS注入实战
参考之前的文章【JS注入】部分:【python自动化】playwright长截图&切换标签页&JS注入实战











![[CANN训练营]UART通信笔记](https://img-blog.csdnimg.cn/56f8c29731854dc89400f5d27db07133.png)