一、结构

List和Set继承了Collection接口,Collection继承了Iterable
Object类是所有类的根类,包括集合类,集合类中的元素通常是对象,继承了Object类中的一些基本方法,例如toString()、equals()、hashCode()。
Collection的增强for底层就是简化版本的迭代器遍历,可以DEBUG看到过程
对集合的遍历:list - 删除元素 ConcurrentModificationException-CSDN博客
Object常用方法
-
toString():返回对象的字符串表示形式。
-
equals(Object obj):判断两个对象是否相等。
-
hashCode():返回对象的哈希码值。
-
getClass():返回对象的运行时类。
-
clone():创建并返回此对象的副本。
-
finalize(): 该方法用于释放资源。
-
wait():睡眠
-
notify():唤醒
二、List
1、ArrayList
-
线程不安全
-
有序(添加和取出顺序一致),可重复,可以添加多个null
-
默认大小是10,扩容是1.5倍
-
每个元素都有对应的顺序索引,即支持索引。get()体现。
常用方法
-
add()/addAll()
-
set()
-
get()
-
remove()
-
size()
-
isEmpty()
-
indexOf()
-
contains()
-
replaceAll()
-
subList()
底层
-
ArrayList维护一个Object类型的数组elementData,就是一个空数组
-
当创建ArrayList对象时,如果使用的是无参构造器,初始容量是0,第一次添加扩容到10,如果再扩容是1.5倍,用 Arrays.copyOf 方法旧数组数据拷贝进去,再添加新的进去
-
如果是指定大小的构造器,初始是指定大小,再次扩容是1.5倍

transient避免序列化
(1)无参构造




确认最小容量,赋值为10

modCount记录集合被修改的次数,此时minCapacity是10,但是elementData是空,就需要扩容

向右移动一位,就是除以2,比如初始化是个空数组,那么在newCapacity的时候还是0,所以第一次扩容不是直接扩,是在第一个if才扩容赋值为10,copyOf后都是null
(2)有参构造

同上
2、Vector
-
线程安全的,操作方法带有synchronized
-
默认10,扩容是2倍
底层
(1)扩容



确定是否需要扩容


int类型初始化是0,所以newCapacity是两倍
(2)克隆
实现了Cloneable接口
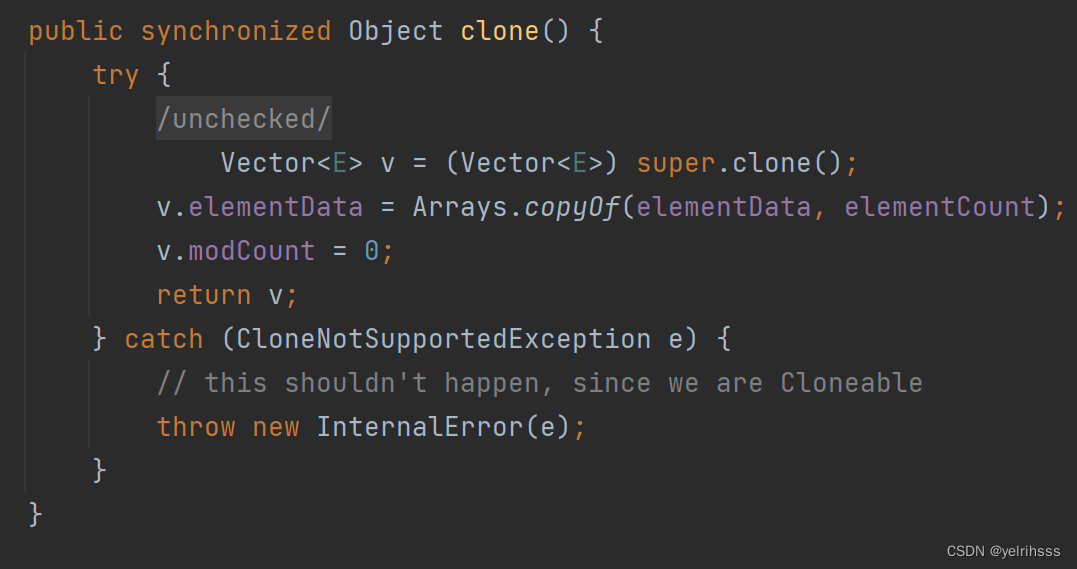
调用 Object 类的 clone 方法,创建一个浅拷贝,对于数组元素,使用 Arrays.copyOf 方法进行深拷贝,重置副本的修改次数
3、LinkedList
-
线程不安全
-
双向链表和双端队列
-
添加元素可重复,可添加null
LinkedList维护了两个属性first和last指向首节点和尾节点,每个节点对象,又维护了prev、next、itm三个属性,通过prev指向前一个,next指向后一个节点,实现双向链表。

常用方法
【带有first和last就是实现了Deque,常用的是实现Queue】
add(E e):实现了List接口。在链表后添加一个元素;
addFirst(E e)/push(E e)、addLast(E e):实现了Deque接口。在链表头部/尾部插入一个元素;
offerFirst(E e)、offerLast(E e):实现了Deque接口。在链表头部插入一个元素,成功返回true,失败false
offer(E e):实现了Queue接口。将指定的元素插入到队列的末尾,成功返回true,失败false
peek():获取第一个元素,但是不移除;
poll():查询并移除第一个元素 ;
remove() :移除链表中第一个元素;
底层:
(1)add

first = null, last = null


第一个节点加入的时候,first和last都指向newNode,prev=next=null
再加入一个节点, l指向第一个节点的last,再将l赋值到newNode的prev,将第一个节点的last指向newNode,此时l指向的是第一个节点不为空,将l的next指向newNode,完成链表,size=modCount=2
(2)removeFirst


4、比较
| ArrayList | LinkedList | Vector | |
|---|---|---|---|
| 底层结构 | 可变数组 | 双向链表 | 可变数组 |
| 线程安全 | 不安全(Collections.synchronizedList) | 不安全 | 安全(synchronized) |
| 初始值 | 10,扩容1.5倍 | 10,扩容2倍 | 空链表 |
| 排序重复 | 有序,可重复,多个null | 有序,可重复,多个null | 有序,可重复,多个null |
| 效率 | 增删较低,查找快(索引) | 增删较高,查找慢(顺序遍历) | 低 |
| 适用 | 大部分 | 频繁插入和删除 |
2、拓展Collections.synchronizedList
Collections.synchronizedList方法接受一个普通的List作为参数,并返回一个具有同步方法的List。可以使用这个同步的List在多线程环境中进行操作。尽管synchronizedList提供了一些基本的同步,但在复合操作(例如迭代和修改)时,仍然需要手动同步以确保线程安全。
https://www.cnblogs.com/jiading/articles/13038607.html
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class ManualSynchronizationExample {public static void main(String[] args) {// 创建一个普通的ArrayListList<String> normalList = new ArrayList<>();
// 使用Collections.synchronizedList方法创建线程安全的ListList<String> synchronizedList = Collections.synchronizedList(normalList);
// 创建两个线程,一个线程向列表中添加元素,另一个线程遍历列表Thread addThread = new Thread(() -> {for (int i = 0; i < 1000; i++) {addElement(synchronizedList, "Element" + i);}});
Thread iterateThread = new Thread(() -> {iterateList(synchronizedList);});
// 启动线程addThread.start();iterateThread.start();
// 等待两个线程执行完成try {addThread.join();iterateThread.join();} catch (InterruptedException e) {e.printStackTrace();}}
// 使用 synchronized 关键字确保对列表的安全添加操作private synchronized static void addElement(List<String> list, String element) {list.add(element);}
// 使用 synchronized 关键字确保对列表的安全遍历操作private synchronized static void iterateList(List<String> list) {for (String element : list) {// 在迭代过程中对列表进行操作System.out.println(element);}}
}
//synchronizedList里的synchronized内部锁,是在并发执行的add/remove的时候,
//不要把多个线程操作的数据实现到一个地方去。
//外部再使用synchronized是保证添加和遍历的时候对线程的安全的保护,两个锁是不同层面的并发问题三、Set
1、HashSet
-
底层是实现的HashMap,数组+链表+红黑二叉树,线程不安全
-
默认大小16,加载因子0.75,扩容到原先的2倍
-
无序,不允许重复,最多一个null、

(1)add
Set s = new HashSet();
set.add("a"); //true
set.add("a"); //false
set.add(new Student("lee")); //true
set.add(new Student("lee")); //true
set.add(new String("lee")); //true
set.add(new String("lee")); //false

如果put返回的是null,相当于是没有这个e,那么才返回true,否则代表已经存在

这里的PRESENT是个占位的目的,也就是add(“a”),这个a是在key上的,value是个空对象

右移16位并且异或,核心目的是为了让hash值的散列度更高,减少hash冲突,将hashCode的高位移动到了低位,使低位包含更多的高位信息
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {//定义辅助变量,table就是HashMap的一个数组,类型是Node[]Node<K,V>[] tab; Node<K,V> p; int n, i;//看下个代码解析,计算如果当前tab是null或者大小是0,此时的tab大小就是16了if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;//计算hash值,应该放在table表的哪个索引位置,并且这个位置的对象赋值给p//如果p是null,表示还没有创建过数据,就放进去//绝大部分情况下,n的值小于2的16次方,所以i的值始终是hash的低16位和n-1取模运算,造成key的散列度不高,大量的key集中存储几个位置,影响性能if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);else {//相同的数据,例如第一次加入A,第二次加入ANode<K,V> e; K k;//p是指向当前索引位置对应的第一个元素,如果和添加的key的hash值一样,并且添加的key是同一个对象,或者不是同一个对象但是内容相同。代表两个数据是相同的,不能加入if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;//p是否是红黑树,走红黑树的算法else if (p instanceof TreeNode)e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);else {//是一个链表,for循环比较for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);//添加后立即判断链表的长度是否达到8,转为红黑树if (binCount >= TREEIFY_THRESHOLD - 1)treeifyBin(tab, hash);break;}if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}//如果已经存在相同的k,但是v不同,那么就会替换vif (e != null) {V oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e);return oldValue;}}++modCount;if (++size > threshold)resize();//这个是为了让HashMap的子类去实现的afterNodeInsertion(evict);return null;}final Node<K,V>[] resize() {Node<K,V>[] oldTab = table;int oldCap = (oldTab == null) ? 0 : oldTab.length;int oldThr = threshold;int newCap, newThr = 0;if (oldCap > 0) {if (oldCap >= MAXIMUM_CAPACITY) {threshold = Integer.MAX_VALUE;return oldTab;}else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&oldCap >= DEFAULT_INITIAL_CAPACITY)newThr = oldThr << 1;}else if (oldThr > 0)newCap = oldThr;else {//static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; 也就是默认16newCap = DEFAULT_INITIAL_CAPACITY;//默认加载因子0.75,使用到12的时候就要扩容newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);}if (newThr == 0) {float ft = (float)newCap * loadFactor;newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?(int)ft : Integer.MAX_VALUE);}threshold = newThr;@SuppressWarnings({"rawtypes","unchecked"})Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];//此时的table的大小就是16了table = newTab; if (oldTab != null) {for (int j = 0; j < oldCap; ++j) {Node<K,V> e;if ((e = oldTab[j]) != null) {oldTab[j] = null;if (e.next == null)newTab[e.hash & (newCap - 1)] = e;else if (e instanceof TreeNode)((TreeNode<K,V>)e).split(this, newTab, j, oldCap);else {Node<K,V> loHead = null, loTail = null;Node<K,V> hiHead = null, hiTail = null;Node<K,V> next;do {next = e.next;if ((e.hash & oldCap) == 0) {if (loTail == null)loHead = e;elseloTail.next = e;loTail = e;}else {if (hiTail == null)hiHead = e;elsehiTail.next = e;hiTail = e;}} while ((e = next) != null);if (loTail != null) {loTail.next = null;newTab[j] = loHead;}if (hiTail != null) {hiTail.next = null;newTab[j + oldCap] = hiHead;}}}}}return newTab;}2、LinkedHashSet
-
继承了HashSet,底层是LinkedHashMap,维护的是 数组+双向链表
-
默认大小是16,扩容为2倍
-
数组是HashMap$Node[],存放节点类型是LinkedHashMap$Entry

继承关系是在静态内部类完成的



同上
3、TreeSet
-
当无参构造的时候是无序的,根据提供的构造器的比较器可以完成有序
-
底层实现TreeMap

TreeSet treeSet = new TreeSet(new Comparator() {@Overridepublic int compare(Object o1, Object o2) {//比较方式return 0;}
});

添加元素时,cpr就是匿名内部类,compare()动态绑定到匿名内部类
第一次添加的时候,比较的是相同的key不接收返回值,所以添加第一个元素时不影响
4、区别
| HashSet | LinkedHashSet | TreeSet | |
|---|---|---|---|
| 底层 | HashMap | HashSet+链表 | TreeMap+红黑树 |
| 是否有序 | 无序 | 有序 | 无参无序,构造器有序 |
| 性能 | O(1),速度快 | O(1),链表有影响 | O(log n),性能较差 |
四、Map
1、HashMap
-
key不能重复,值可以重复,允许为null唯一
-
相同的k,会覆盖原来的kv
-
线程不安全
-
最大容量Integer.MAX_VALUE,2 的 31 次方-1
-
负载因子0.75,扩容为2倍
-
底层=数组+链表+红黑二叉树
(1)put()同理set集合
(2)遍历
存有的K-V结构的数据,一对k-v是放在一个HashMap$Node中的,Node实现了Exntry接口,一对k-v就是一个Entry。


返回是一个HashMap$Node
k-v为了方便遍历,还会创建EntrySet集合,存放的元素类型Entry,而一个Entry对象就有k-v
transient Set<Map.Entry<K,V>> entrySet;这个entrySet保存的kv只是指向了Node的kv
entrySet中定义的是Map.Entry, 但实际上存放的是HashMap$Node,因为后者implements前者
提供了常用方法
-
getKey()
-
getValue()
-
Set set = map.keySet();
-
Collection values = map.values();
(3)1.7和1.8的区别
| JDK1.7 | JDK1.8 | |
|---|---|---|
| 底层 | entry数组+链表 | node数组+链表+红黑树(链表长度>8 && 元素数量>64) |
| 扩容 | 全部按照之前的方法进行重新计算索引 | 按照扩容后的规律计算(扩容后的位置=原位置or原位置+旧容量) |
| 计算hash | 4次位运算 + 5次异或预算 | 1次位运算+1次异或运算 |
| 初始容量 | 0(第一次执行put初始) | 16(put时初始) |
| 插入 | 头插法(造成死循环) | 尾插法 |
(4)问题
1.8后扩容后的规律计算?
扩容后,若hash值新增参与运算的位=0,那么元素在扩容后的位置=原始位置;
扩容后,若hash值新增参与运算的位=1,那么元素在扩容后的位置 =原始位置+扩容后的旧位置;
为什么链表的长度大于8就要转换成红黑二叉树?
最开始使用链表的时候,空间占用较少,对查询速度没有太大的影响,当链表越来越长,就转换为红黑二叉树,保证查询速度。红黑二叉树是平衡二叉树,也避免不平衡二叉树偏向一边导致查询速度慢的问题。
如果 hashCode 分布良好,那么红黑二叉树几乎不会用到,很少出现链表很长的情况。在理想情况下,链表长度符合泊松分布,各个长度的命中概率依次递减,当长度为 8 的时候,概率仅为 0.00000006。因此默认8为转换的阈值。
为什么要右移16位异或?
绝大部分情况下,n的值小于2的16次方,所以i的值始终是hash的低16位和n-1取模运算,造成key的散列度不高,大量的key集中存储几个位置,影响性能。右移16位并且异或,将hashCode的高位移动到了低位,使低位包含更多的高位信息
加载因子为什么是0.75?
扩容因子值越大,触发扩容的元素个数越多,虽然空间利用率高,但是哈希冲突概率增加。
扩容因子值越小,触发扩容的元素个数越少,哈希冲突概率减少,但是占用内存,增加扩容频率。
扩容因子的值的设置,是在统计学中泊松分布有关,再冲突和空间利用率之间的平衡
头插法到尾插法的优化是为什么?
只会在1.7中出现,1.7采用的是数组+链表且是头插法。当有两个线程TA和TB,对HashMap进行扩容,都指向链表头结点NA,而TA和TB的next都是NB,假设TB休眠,TA执行扩容操作,一直到TA完成后,TB被唤醒,TB.next还是NB,但是TA执行成功已经发生了顺序改变,出现一个死循环。
为什么数组容量必须是2次幂? 桶的索引计算公式为 i = (n-1) & hash。效果等于与 hash%n 的计算效果,但是位运算比取余运算要高效的多。如果n为2次幂,那么n-1的低位就全是1,哈希值进行与操作时可以保证低位的值不变,从而保证分布均匀,不会受到与运算对数据的变化影响。
2、HashTable(不使用)
-
k-v都不能为空,否则抛出NullPointException
-
线程安全
-
底层是HashTable$Entry[],初始化大小11,扩容是2倍+1
3、TreeMap
同TreeSet
4、ConCurrentHashMap
| 1.7 | 1.8 | |
|---|---|---|
| 锁结构 | ReentrantLock+Segment+HashEntry | synchronized+CAS+红黑树 |
| 锁力度 | Segment | 节点 |
| size() | 调用的时候才计算。不加锁直接进行统计,最多执行三次,如果前后两次计算的结果一样,则直接返回。若超过了三次,则对每一个Segment进行加锁后再统计 | 已经计算好的预估值。维护一个baseCount属性用来记录结点数量,每次进行put操作之后都会CAS自增baseCount |
| put() | 两次定位,先对Segment定位,再对内部数组下标定位,定位不到会使用自旋锁加锁,自旋超过64次进入阻塞状态 | 一次定位,CAS+synchronized,如果对应下标没有结点,则没有哈希冲突,直接CAS插入,成功返回,不成功使用synchronized加锁插入 |
| get() | 一次hash定位到Segment的位置,然后再hash定位到指定的HashEntry,遍历该HashEntry下的链表 | 使用CAS保证并发安全,因为Node数组是共享的。根据哈希定位到桶,为空返回null,怒为空查找链表/红黑树 |
1.8为什么使用synchronized来代替重入锁ReentrantLock?
因为粒度降低了,在相对而言的低粒度加锁方式,synchronized并不比ReentrantLock差,在粗粒度加锁中ReentrantLock可能通过Condition来控制各个低粒度的边界,更加的灵活,而在低粒度中,Condition的优势就没有了。 synchronized在1.8之后,JVM 使用了锁升级的优化方式,先使用偏向锁尝试获取锁,没有获取到代表锁已经偏向其他线程,升级到自旋锁,达到一定次数后,才升级到重量级锁。
为什么get不加锁可以保证线程安全?
整个get方法使用了大量的volatile关键字,其实就是保证了可见性,get只是读取操作,所以只需要保证读取的是最新的数据。Node的成员val是用volatile修饰,数组用volatile修饰保证数组扩容时的可见性。
使用volatile关键字会强制将修改的值立即写入主存,使用volatile关键字,当线程2进行修改时,会导致线程1的工作内存中缓存变量的缓存行无效,由于线程1的工作内存中缓存变量的缓存行无效,所以线程1再次读取变量的值时会去主存读取。volatile就是强制多线程的情况下读取数据区内存获取最新的值。
五、Collections工具类
-
reverse(List list):反转指定List集合中元素的顺序
-
shuffle(List list):对List中的元素进行随机排序(洗牌)
-
sort(List list):对List里的元素根据自然升序排序
-
sort(List list, Comparator c):自定义比较器进行排序
-
swap(List list, int i, int j):将指定List集合中i处元素和j出元素进行交换
-
rotate(List list, int distance):将所有元素向右移位指定长度
-
binarySearch(List list, Object key):使用二分搜索法,以获得指定对象在List中的索引,前提是集合已经排序
-
max(Collection coll):返回最大元素
-
max(Collection coll, Comparator comp):根据自定义比较器,返回最大元素
-
min(Collection coll):返回最小元素
-
min(Collection coll, Comparator comp):根据自定义比较器,返回最小元素
-
fill(List list, Object obj):使用指定对象填充
-
frequency(Collection Object o):返回指定集合中指定对象出现的次数
-
replaceAll(List list, Object old, Object new):替换
-
emptyXxx():返回一个空的不可变的集合对象
-
singletonXxx():返回一个只包含指定对象的,不可变的集合对象。