开发服务器系统的时候,程序的性能是至关重要的。经过我们前面框架的学习,得知一个请求的处理基本分为接受http请求、数据库处理、返回json数据,而这3个部分中就属链接数据库请求的响应速度最慢,因为数据库操作涉及到数据库服务处理请求,读写硬盘数据
而操作数据库的增、删、改、查中,查询属于读取数据,而删除、修改、增加属于写入数据,我们做缓存也主要是给查询这块的数据做优化
一、缓存的原理
众所周知,从内存中读写数据的速度要比去磁盘中读写的速度要快,而缓存就是先将我们要查询的数据从mysql数据库中读取一份,然后放到内存中,因为避免了从硬盘读取表记录的操作,程序访问内存的速度要比访问数据库快很多,特别是当一个读操作要涉及到多张表的联合查询,或者这些表比较大,就会非常耗时
而做缓存可以使用多种方案,最简单的直接通过python的字典做缓存,但这种方法同时也具有很大的弊端,比如不支持分布式,当业务量大的时候部署到不同主机会造成严重的资源占用问题,并且当有一台主机上的缓存数据需要更新时,要通知其他节点一起更新,比较麻烦, 还要防止 数据同步前 可能不同节点给出的数据不一致的问题,而
Redis和Memcached是目前两种主流的缓存服务方案,我们这里使用redis做缓存
1、redis部署
网上装redis的教程很多我这里不在赘述,为了省事直接用docker部署了
mkdir /apps/demo/redis/{conf,data} -p
cd /apps/demo/redis#拉取镜像
docker pull redis:6.2.7vi conf/redis.conf
bind 0.0.0.0maxmemory 4GB
maxmemory-policy allkeys-lru
maxmemory-samples 10tcp-backlog 511aof-rewrite-incremental-fsync yes
rdb-save-incremental-fsync yes
rdbcompression yes
rdbchecksum yesaof-rewrite-incremental-fsync yesrequirepass 123456
rename-command FLUSHDB ""
rename-command FLUSHALL ""
rename-command CONFIG ""activerehashing yes
dynamic-hz yes
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
list-max-ziplist-entries 512
list-max-ziplist-value 64
set-max-intset-entries 512
zset-max-ziplist-entries 128
zset-max-ziplist-value 64配置说明
bind 0.0.0.0 #允许外部访问## 内存优化
maxmemory 4GB # 设置Redis实例的最大内存限制
maxmemory-policy allkeys-lru # 设置在达到最大内存限制时所采取的淘汰策略为LRU(最近最少使用)
maxmemory-samples 10 # 指定在key的过期删除策略中随机抽取的样本数目## 网络优化
tcp-backlog 511 # 设置内核中由Redis监听的TCP连接的最大长度## 持久化优化
aof-rewrite-incremental-fsync yes # 启用AOF(Append Only File)增量式文件同步
rdb-save-incremental-fsync yes # 使用增量传输来持久化RDB文件
rdbcompression yes # 开启RDB文件的压缩
rdbchecksum yes # 启用RDB文件的校验和## AOF压缩
aof-rewrite-incremental-fsync yes # 启用AOF(Append Only File)增量式文件同步## 安全
requirepass yourpassword # 设置Redis服务器连接密码
rename-command FLUSHDB "" # 重命名FLUSHDB命令
rename-command FLUSHALL "" # 重命名FLUSHALL命令
rename-command CONFIG "" # 重命名CONFIG命令## 性能优化
activerehashing yes # 启用集群环境的rehashing(对已有的键表重新分布)
dynamic-hz yes
hash-max-ziplist-entries 512 # 设置hash结构的压缩阈值
hash-max-ziplist-value 64 # 设置hash结构的压缩阈值
list-max-ziplist-entries 512 # 设置list结构的压缩阈值
list-max-ziplist-value 64 # 设置list结构的压缩阈值
set-max-intset-entries 512 # 设置intset编码的集合的最大元素数量
zset-max-ziplist-entries 128 # 设置zset结构的压缩阈值
zset-max-ziplist-value 64 # 设置zset结构的压缩阈值2、启动服务
vi ./run.sh
docker run -p 36379:6379 --name redis \-v ./data:/data \-v ./conf/redis.conf:/etc/redis/redis.conf \-d redis:6.2.7 \redis-server /etc/redis/redis.conf运行
sh run.sh二、Redis使用
Redis是一个数据仓库服务,这个仓库里面可以存储很多
数据对象存储的每个数据对象都有一个key,根据这个key,可以找到这个对象。
要添加一个数据对象,必须为这个数据对象指定一个key,就像指定一个房间号
Redis key 对应的value支持多种数据对象,可以是字符串、列表、哈希对象

查阅资料的时候发现有一篇同样讲缓存的帖子很不错,这里留个档
https://blog.csdn.net/qq_43745578/article/details/1285690601、登录redis
#登录redis容器
docker exec -it redis bash#通过redis客户端登录数据库
redis-cli -h 127.0.0.1#认证用户
auth 123456 
2、redis数据库切换
redis数据库和mysql一样都是包含很多个数据库的,编号为0-15,通过select 命令切换不同的数据库使用,每个数据库我们可以看作是一个仓库用来存放货物,默认编号为0 ,现在我们切换到1号数据库然后进行下面的仓库,切换完后能看到端口后面跟着个1
select 1 
3、添加数据
上面说了,redis可以存放各种类型的数据,字符串、列表、哈希对象等等,而根据不同类型的数据,redis也有想对应的命令,比如我们要存入的数据是一个字符串,那么新增的命令就是set,而对应的查询命令为 get key名
127.0.0.1:6379[1]> set zhangsan:1 ynby
OK127.0.0.1:6379[1]> get zhangsan:1
"ynby"
4、查询所有的key
很多时候我们是不记得key的名称,就需要模糊查询一下key有那些
127.0.0.1:6379[1]> keys zha*
1) "zhangsan:1"
127.0.0.1:6379[1]>5、删除数据
127.0.0.1:6379[1]> del zhangsan:1
(integer) 1
127.0.0.1:6379[1]> keys *
(empty array)
6、添加哈希值
如果我们要存入 Redis的对象比较复杂,比如用户信息,包括等级、金币、姓名等等,
可以使用哈希(Hash)对象,Redis 哈希对象的每个字段 ,术语称之为
field存入Hashes,就使用客户端命令
hmset或者hset
#添加hash值
127.0.0.1:6379[1]> hmset user:2001 level 10 coin 1977 name 你好
OK#获取单个字段的值hget
127.0.0.1:6379[1]> hget user:2001 coin
"1977"#获取所有字段的值hgetall
127.0.0.1:6379[1]> hgetall user:2001
1) "level"
2) "10"
3) "coin"
4) "1977"
5) "name"
6) "\xe4\xbd\xa0\xe5\xa5\xbd"
上面案例中的name字段的值被utf8编码了,客户端程序在使用时根据需要进行相应解码
7、定义哈希表
既然 Hash 本身就是一个字典,我们通常还会把整个用户表都直接放入
一个hash里面可以给这个hash对应的对象 起一个key名为 usertable
#添加表数据
hmset usertable u2001 id:2001|level:10|coin:1977|name:张三
hmset usertable u2002 id:2002|level:13|coin:1927|name:李四#查询表数据
127.0.0.1:6379[1]> hget usertable u2002
"id:2002|level:13|coin:1927|name:\xe6\x9d\x8e\xe5\x9b\x9b"步骤6、7保存的方法各有个的缺点,方案6是方便修改单个field的值,但是容易出现大量的key,方案7虽然全局查看key较为方便,但没办法修改单个field的值,只能一起修改
三、Django项目缓存配置
1、安装redis库
pip install django-redis2、配置django全局缓存
Django_demo/Django_demo/settings.py
CACHES = {"default": {"BACKEND": "django_redis.cache.RedisCache","LOCATION": "redis://101.43.156.78:36379/1","OPTIONS": {"CLIENT_CLASS": "django_redis.client.DefaultClient",# 密码'PASSWORD': '123456', #没有密码就去掉这行}}
}上面的这段配置可以放在数据库 DATABASES 配置项的下方。LOCATION 配置项最后的数字1 是 DB number,指定redis的数据库号
3、使用缓存配置
不是任何数据库的数据都应该使用缓存,至少满足两个要求(频繁读取的数据 、较少变动的数据)
如果这个数据写入后基本就不会在修改了,但是需要经常性的读取,那么他就是一个值得缓存的数据
举个例子
在前面编写的案例中,属于药品的信息就符合上面的两点要求,我们可以在处理列出药品 的API接口 的代码中,把数据库读出的内容进行缓存,这里我们采用上面的缓存方案二(redis使用-7)把所有的 列出药品都放在一个哈希对象中
首先,我们需要为 列出药品的缓存 创建一个key,名字为 medicinelist因为我们将来会有很多种类型的数据要缓存,它们有不同的key,所以建议统一放在配置文件
settings.py中
Django_demo/Django_demo/settings.py
# 记录全局的缓存key,防止重复
class CK:# 列出药品 的 缓存 keyMedineList = 'list_medicine'# 列出客户 的 缓存 keyCustomerList = 'list_customer'这样的好处是,放在一起,如果有重复的key名,比较容易发现
4、修改查询数据的缓存配置
我们将原先的查询数据库返回的数据,交给redis
Django_demo/mgr/medicine.py
#添加
from Django_demo import settings
import json
import traceback
from django.core.paginator import Paginator, EmptyPage
from django.db.models import Q
from django_redis import get_redis_connection# 获取一个和Redis服务的连接
rconn = get_redis_connection("default")def listmedicine(request):try:# 查看是否有 关键字 搜索 参数keywords = request.params.get('keywords',None)# 要获取的第几页pagenum = request.params['pagenum']# 每页要显示多少条记录pagesize = request.params['pagesize']# 先看看缓存中是否有cacheField = f"{pagesize}|{pagenum}|{keywords}" # 缓存 fieldcacheObj = rconn.hget(settings.CK.MedineList,cacheField)# 缓存中有,需要反序列化if cacheObj:print('缓存命中')retObj = json.loads(cacheObj)# 如果缓存中没有,再去数据库中查询else:print('缓存中没有')# 返回一个 QuerySet 对象 ,包含所有的表记录qs = Medicine.objects.values().order_by('-id')if keywords:conditions = [Q(name__contains=one) for one in keywords.split(' ') if one]query = Q()for condition in conditions:query &= conditionqs = qs.filter(query)# 使用分页对象,设定每页多少条记录pgnt = Paginator(qs, pagesize)# 从数据库中读取数据,指定读取其中第几页page = pgnt.page(pagenum)# 将 QuerySet 对象 转化为 list 类型retlist = list(page)retObj = {'ret': 0, 'retlist': retlist,'total': pgnt.count}# 存入缓存rconn.hset(settings.CK.MedineList,cacheField,json.dumps(retObj))# total指定了 一共有多少数据return JsonResponse(retObj)except EmptyPage:return JsonResponse({'ret': 0, 'retlist': [], 'total': 0})except:print(traceback.format_exc())return JsonResponse({'ret': 2, 'msg': f'未知错误\n{traceback.format_exc()}'})这样,我们就确保了,处理列出药品的请求时,优先从缓存中读取,如果没有再从数据库读取。
并且数据库读取到数据后,存入缓存,这样下次同样的请求就可以从缓存中获取数据了
5、添加缓存数据更新
使用缓存一定要注意缓存数据的更新,我们前面做完了缓存,如果我们后面对药品数据做出了添加、修改、删除的操作,那么缓存里面的数据就和数据库不一致了,如果我们每次都更新缓存是很麻烦的,简单的方法就是直接删除对应的缓存数据,这样下次请求时缓存中没了数据,还是会去数据库中读取的,这样就能拿到最新的数据到缓存中
def addmedicine(request):info = request.params['data']# 从请求消息中 获取要添加客户的信息# 并且插入到数据库中medicine = Medicine.objects.create(name=info['name'] ,sn=info['sn'] ,desc=info['desc'])# 同时删除整个 medicine 缓存数据# 因为不知道这个添加的药品会影响到哪些列出的结果# 只能全部删除rconn.delete(settings.CK.MedineList)return JsonResponse({'ret': 0, 'id':medicine.id})def modifymedicine(request):# 从请求消息中 获取修改客户的信息# 找到该客户,并且进行修改操作medicineid = request.params['id']newdata = request.params['newdata']try:# 根据 id 从数据库中找到相应的客户记录medicine = Medicine.objects.get(id=medicineid)except Medicine.DoesNotExist:return {'ret': 1,'msg': f'id 为`{medicineid}`的药品不存在'}if 'name' in newdata:medicine.name = newdata['name']if 'sn' in newdata:medicine.sn = newdata['sn']if 'desc' in newdata:medicine.desc = newdata['desc']# 注意,一定要执行save才能将修改信息保存到数据库medicine.save()# 同时删除整个 medicine 缓存数据# 因为不知道这个修改的药品会影响到哪些列出的结果# 只能全部删除rconn.delete(settings.CK.MedineList)return JsonResponse({'ret': 0})def deletemedicine(request):medicineid = request.params['id']try:# 根据 id 从数据库中找到相应的药品记录medicine = Medicine.objects.get(id=medicineid)except Medicine.DoesNotExist:return {'ret': 1,'msg': f'id 为`{medicineid}`的客户不存在'}# delete 方法就将该记录从数据库中删除了medicine.delete()# 同时删除整个 medicine 缓存数据# 因为不知道这个删除的药品会影响到哪些列出的结果# 只能全部删除rconn.delete(settings.CK.MedineList)return JsonResponse({'ret': 0})6、测试访问药品表
下面测试一下查询药品表后redis是否缓存成功
vi main.py
import requests,pprint#添加认证
payload = {'username': 'root','password': '12345678'
}
#发送登录请求
response = requests.post('http://127.0.0.1:8000/api/mgr/signin',data=payload)
#拿到请求中的认证信息进行访问
set_cookie = response.headers.get('Set-Cookie')# 构建添加 客户信息的 消息体,是json格式
payload = {'action': 'list_medicine','pagenum': 1,'pagesize' : 3
}url='http://127.0.0.1:8000/api/mgr/medicines/'if set_cookie:# 将Set-Cookie字段的值添加到请求头中headers = {'Cookie': set_cookie}# 发送请求给web服务response = requests.post(url,json=payload,headers=headers)pprint.pprint(response.json())
返回
{'ret': 0,'retlist': [{'desc': 'gmkl', 'id': 6, 'name': 'gmkl', 'sn': '111'}],'total': 1}然后我们登录redis查看有没有我们写入的数据
127.0.0.1:6379[1]> hgetall list_medicine
1) "3|1|None"
2) "{\"ret\": 0, \"retlist\": [{\"id\": 6, \"name\": \"gmkl\", \"sn\": \"111\", \"desc\": \"gmkl\"}], \"total\": 1}"
7、测试添加药品表
vi main1.py
import requests,pprint#添加认证
payload = {'username': 'root','password': '12345678'
}
#发送登录请求
response = requests.post('http://127.0.0.1:8000/api/mgr/signin',data=payload)
#拿到请求中的认证信息进行访问
set_cookie = response.headers.get('Set-Cookie')# 构建添加 客户信息的 消息体,是json格式
payload = {"action":"add_medicine","data":{"name":"lhms","sn":"test","desc":"test",}
}url='http://127.0.0.1:8000/api/mgr/medicines/'if set_cookie:# 将Set-Cookie字段的值添加到请求头中headers = {'Cookie': set_cookie}# 发送请求给web服务response = requests.post(url,json=payload,headers=headers)pprint.pprint(response.json())
返回
{'id': 7, 'ret': 0}我们增加、删除、修改,都会将原先redis中的缓存清理掉
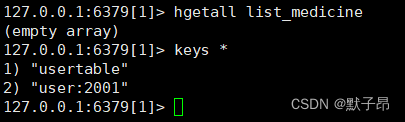
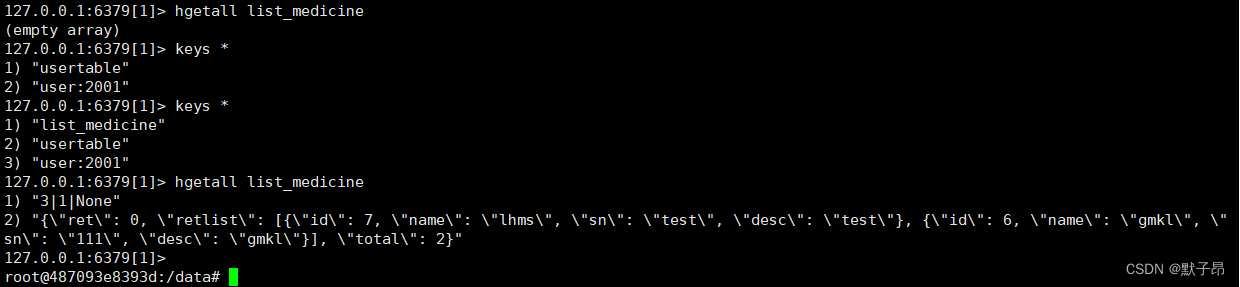
我们在用第6步的访问在查询下,查看redis缓存数据数据
127.0.0.1:6379[1]> hgetall list_medicine
1) "3|1|None"
2) "{\"ret\": 0, \"retlist\": [{\"id\": 7, \"name\": \"lhms\", \"sn\": \"test\", \"desc\": \"test\"}, {\"id\": 6, \"name\": \"gmkl\", \"sn\": \"111\", \"desc\": \"gmkl\"}], \"total\": 2}"




![[Hive] INSERT OVERWRITE DIRECTORY要注意的问题](https://img-blog.csdnimg.cn/4543ec8a5e0d476faf70a9ab57832ba8.jpeg)