大家好,我是邵奈一,一个不务正业的程序猿、正儿八经的斜杠青年。
1、世人称我为:被代码耽误的诗人、没天赋的书法家、五音不全的歌手、专业跑龙套演员、不合格的运动员…
2、这几年,我整理了很多IT技术相关的教程给大家,爱生活、爱分享。
3、如果您觉得文章有用,请收藏,转发,评论,并关注我,谢谢!
博客导航跳转(请收藏):邵奈一的技术博客导航
| 公众号 | 微信 | CSDN | 掘金 | 51CTO | 简书 | 微博 |
教程目录
- 0x00 教程内容
- 1. 引入相关依赖的包
- 2. 定义函数并生成决策树
- 3. 定义函数并保存生成的树图
- 4. 定义函数用于生成向量化数据
- 5. 调用函数进行预测
- 6. 预测新样本
- 0xFF 总结
0x00 教程内容
背景说明:
使用的数据集为tennis.txt,其中包含了14个样本,每个样本都包含了与天气相关的特征以及是否适合打球的相关信息。具体数据如下:
| 序号 | 天气 | 气温 | 湿度 | 风 | 类别 |
|---|---|---|---|---|---|
| 1 | 晴 | 热 | 高 | 无 | N |
| 2 | 晴 | 热 | 高 | 有 | N |
| 3 | 多云 | 热 | 高 | 无 | Y |
| 4 | 雨 | 适中 | 高 | 无 | Y |
| 5 | 雨 | 冷 | 正常 | 无 | Y |
| 6 | 雨 | 冷 | 正常 | 有 | N |
| 7 | 多云 | 冷 | 正常 | 有 | Y |
| 8 | 晴 | 适中 | 高 | 无 | N |
| 9 | 晴 | 冷 | 正常 | 无 | Y |
| 10 | 雨 | 适中 | 正常 | 无 | Y |
| 11 | 晴 | 适中 | 正常 | 有 | Y |
| 12 | 多云 | 适中 | 高 | 有 | Y |
| 13 | 多云 | 热 | 正常 | 无 | Y |
| 14 | 雨 | 适中 | 高 | 有 | N |
1. 引入相关依赖的包
# 导入pandas库,用于数据处理和分析
import pandas as pd
# 导入numpy库,用于数值计算
import numpy as np
# 导入sklearn库中的tree模块,用于构建决策树模型
from sklearn import tree
# 导入pydotplus库,用于绘制决策树图形
import pydotplus
如果提示:
ModuleNotFoundError: No module named 'pydotplus'
使用以下命令安装pydotplus:
方式一:直接在jupyter notebook中安装
!pip install pydotplus
如下图所示:
执行完重新引入一下库即可。
方式二:直接在pip命令行中安装
pip install pydotplus
效果如图:
(base) C:\Users\shaonaiyi>pip install pydotplus
WARNING: Retrying (Retry(total=4, connect=None, read=None, redirect=None, status=None)) after connection broken by 'ProtocolError('Connection aborted.', ConnectionResetError(10054, '远程主机强迫关闭了一个现有的连接。', None, 10054, None))': /simple/pydotplus/
Collecting pydotplusDownloading pydotplus-2.0.2.tar.gz (278 kB)━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 278.7/278.7 kB 58.8 kB/s eta 0:00:00Preparing metadata (setup.py) ... done
Requirement already satisfied: pyparsing>=2.0.1 in c:\users\shaonaiyi\anaconda3\lib\site-packages (from pydotplus) (3.0.9)
Building wheels for collected packages: pydotplusBuilding wheel for pydotplus (setup.py) ... doneCreated wheel for pydotplus: filename=pydotplus-2.0.2-py3-none-any.whl size=24554 sha256=dc6225242106622dbd9d9e581bff72da1217c2b2a5048a2d712a0778536353ddStored in directory: c:\users\shaonaiyi\appdata\local\pip\cache\wheels\89\e5\de\6966007cf223872eedfbebbe0e074534e72e9128c8fd4b55eb
Successfully built pydotplus
Installing collected packages: pydotplus
2. 定义函数并生成决策树
# 生成决策树
def createTree(trainingData):# 从训练数据中提取特征矩阵和标签data = trainingData.iloc[:, :-1] # 获取特征矩阵(除了最后一列)labels = trainingData.iloc[:, -1] # 获取标签(即最后一列)# 创建一个分类决策树模型,使用信息熵作为划分标准trainedTree = tree.DecisionTreeClassifier(criterion="entropy") # 分类决策树# 使用特征矩阵和标签训练决策树模型trainedTree.fit(data, labels) # 训练# 返回训练好的决策树模型return trainedTree
createTree是一个函数,它接受一个参数trainingData。这个参数预期是一个数据集,其中每一行是一个样本,每一列是一个特征,最后一列是目标标签。data = trainingData.iloc[:, :-1]这行代码从trainingData中取出所有的行(即所有的样本)和除最后一列之外的所有列。这是为了获取决策树训练所需的特征数据。labels = trainingData.iloc[:, -1]这行代码取出trainingData的最后一列,这是为了获取决策树训练所需的目标标签。trainedTree = tree.DecisionTreeClassifier(criterion="entropy")这行代码创建一个DecisionTreeClassifier对象,这个对象将会用于创建决策树。这里,criterion="entropy"指定了决策树的建立基于信息增益率(也称为交叉熵),这是在决策树的每个划分中,选择最优划分特征的标准。trainedTree.fit(data, labels)这行代码调用fit方法,使用前面获取的特征和标签来训练决策树模型。- 最后,函数返回训练好的决策树模型
trainedTree。
3. 定义函数并保存生成的树图
def showtree2pdf(trainedTree,finename):# 将训练好的决策树导出为Graphviz格式的数据dot_data = tree.export_graphviz(trainedTree, out_file=None)# 从Graphviz格式的数据中创建一个图形对象graph = pydotplus.graph_from_dot_data(dot_data)# 将图形对象保存为PDF文件,文件名为finenamegraph.write_pdf(finename)
- 这个Python函数
showtree2pdf的目的是将一个通过Graphviz格式导出的树形结构保存为PDF文件。 - 函数接受两个参数:
trainedTree,表示需要导出的树形结构;finename,表示导出PDF文件的名字。 - 在函数体中,首先使用
tree.export_graphviz方法将trainedTree导出为Graphviz格式的字符串dot_data。然后,使用pydotplus.graph_from_dot_data方法将dot_data转换为一个PyDotPlus图形对象graph。 - 最后,使用
graph.write_pdf方法将图形保存为PDF文件,文件名为finename。 - 这个函数需要三个库:
tree,pydotplus和networkx。其中tree和networkx是用于创建和处理树形结构的库,而pydotplus是用于处理Graphviz格式的库。
4. 定义函数用于生成向量化数据
定义一个 data2vector 函数,其作用是将非数值型的特征转换为分类编码,以便在机器学习模型中使用。这个函数在数据预处理阶段非常有用,可以帮助我们处理非数值型数据,并为后续的分析和建模提供更便利的数据形式。
def data2vector(data):# 获取数据中除最后一列之外的所有列名names = data.columns[:-1]# 遍历每一列for i in names:# 将当前列转换为分类数据类型col = pd.Categorical(data[i])# 将当前列的分类编码替换为原始值data[i] = col.codes# 返回处理后的数据return data
col = pd.Categorical(data[i])表示将当前所遍历的列转换为分类数据类型。pd.Categorical 函数将每个唯一的类别分配一个整数编码,比如编码可以为0、1、2等等。- 接着使用代码data[i] = col.codes将当前所遍历的列的分类编码覆盖掉原本的初始值,完成替换操作。
- 函数中,通过
pd.Categorical(list).codes可以得到原始数据对应的序号列表,从而将类别信息转化成数值信息。
为了便于理解,补充说明例子如下:
import pandas as pd
data = pd.DataFrame({'A': ['apple', 'banana', 'apple', 'orange'],'B': ['red', 'green', 'red', 'yellow'],'C': [10, 20, 30, 40],'Label': ['positive', 'negative', 'positive', 'positive']
})
print("原始数据:")
print(data)
transformed_data = data2vector(data)
print("转换后的数据:")
print(transformed_data)
输出结果为:
原始数据:A B C Label
0 apple red 10 positive
1 banana green 20 negative
2 apple red 30 positive
3 orange yellow 40 positive
转换后的数据:A B C Label
0 0 1 0 positive
1 1 0 1 negative
2 0 1 2 positive
3 2 2 3 positive
其中 ‘apple’ 对应编码 0,‘banana’ 对应编码 1,‘orange’ 对应编码 2,执行完后,可以发现已经将A、B、C列都已经进行了编码,将非数值型的特征转换为了分类编码。pd.Categorical 函数和 col.codes 是 pandas 库中常用的函数。
这种非数值型数据到分类编码的转换有几个优点:
- 保留类别关系:分类编码将不同类别之间的顺序关系保留下来。例如,在某些情况下,类别 ‘apple’ 编码为 0,类别 ‘banana’ 编码为 1,这样的编码反映了它们在原始数据中的相对顺序。
- 适应机器学习算法:大多数机器学习算法和统计模型只能处理数值型数据。通过将非数值型数据转换为分类编码,我们可以在这些算法中使用这些特征,而无需进一步处理。
- 节省内存:分类数据类型在内存中占用的空间通常比字符串或对象类型要少。这在处理大型数据集时尤为重要,可以降低内存占用和提高计算效率。
需要注意的是,分类编码并不适用于所有情况。在某些情况下,我们可能需要使用其他编码方式,例如独热编码(One-Hot Encoding)或特征哈希(Feature Hashing),以满足特定的数据需求。
5. 调用函数进行预测
data = pd.read_table("tennis.txt",header=None,sep='\t') #读取训练数据
trainingvec=data2vector(data) #向量化数据
decisionTree=createTree(trainingvec) #创建决策树
showtree2pdf(decisionTree,"tennis.pdf") #图示决策树
说明:如果没有tennis.txt文件,可以观注公中号私发tennis.txt自动获取。
执行后,可能会报错:
InvocationException: GraphViz's executables not found
首先,先安装graphviz库,命令如下:
!pip install graphviz
然后,直接在网址:https://graphviz.org/download/中下载软件,我下载的版本是2.50.0版本:
下载后,需要安装,我直接安装在Anaconda安装目录的Library\bin目录下即可,比如我的地址为:D:\SmallTools\Anaconda3\Library\bin,因为我的Anaconda已经配置了环境变量了,所以无需再单独配置环境变量(安装时,也有是否配置环境变量选项,也可以选中它),选择则不需要单独配置环境变量路径,否则需要将Graphviz\bin路径配置到环境变量里。当然也可以在代码中配置,即在notebook中加入以下代码:
import os
os.environ["PATH"] += os.pathsep + "D:/SmallTools/Anaconda3/Library/bin/graphviz/bin/"
参考教程如下:https://blog.csdn.net/weixin_36407399/article/details/87890230
如果没有问题,重新执行代码,此时会在本地生成决策树图,名称为“tennis.pdf”:
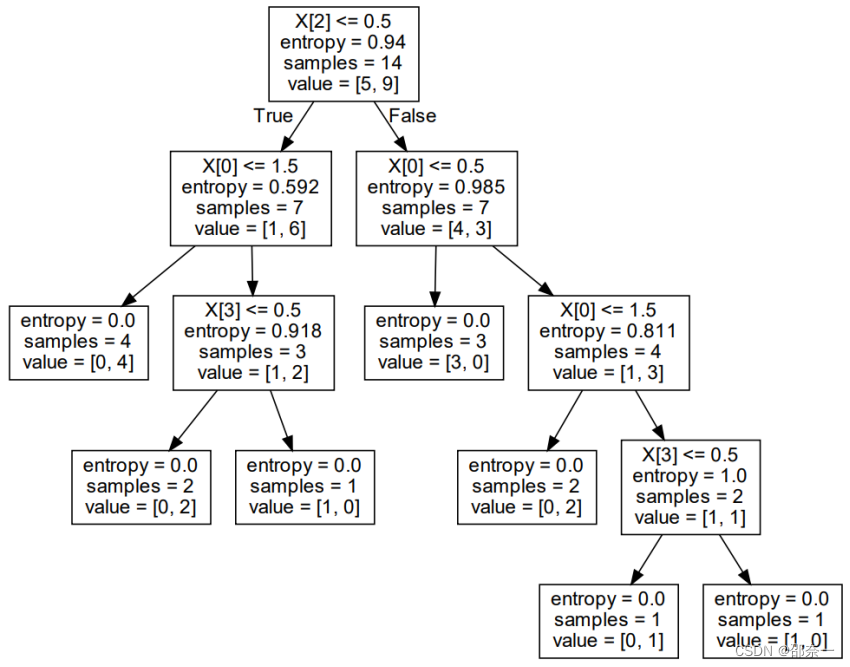
可以看到里面的内容就是决策树的可视化呈现。字段分别为:天气、气温、湿度、风、类别,其中X[2]就表示第3个特征变量:湿度,X[0]则表示第1个特征变量:天气,X[3]则表示第4个特征变量:风力;entropy则表示该节点的熵值;samples则表示该节点中的样本数,比如说第一个节点,也即根节点中的14就是训练集中的样本数量;value则表示不同种类所占的个数,比如说根节点中value左边的5表示“否”的数量,9则表示“是”的数量。
6. 预测新样本
输入:
testVec = [0,0,1,1] # 天气晴、气温冷、湿度高、风力强
print(decisionTree.predict(np.array(testVec).reshape(1,-1))) #预测
输出:
['否']
由此可以知道,天气晴、气温冷、湿度高、风力强,预测不会出来打网球。
0xFF 总结
- 这是决策树预测的典型例子,变种还有很多,但大体相似,本例子的亮点是绘制了决策树图,更加直观。
- 请继续关注我,我将更新更多使用教程。
邵奈一 原创不易,如转载请标明出处,教育是一生的事业。