本文主要介绍了Rasa中相关Tokenizer的具体实现,包括默认Tokenizer和第三方Tokenizer。前者包括JiebaTokenizer、MitieTokenizer、SpacyTokenizer和WhitespaceTokenizer,后者包括BertTokenizer和AnotherWhitespaceTokenizer。
一.JiebaTokenizer
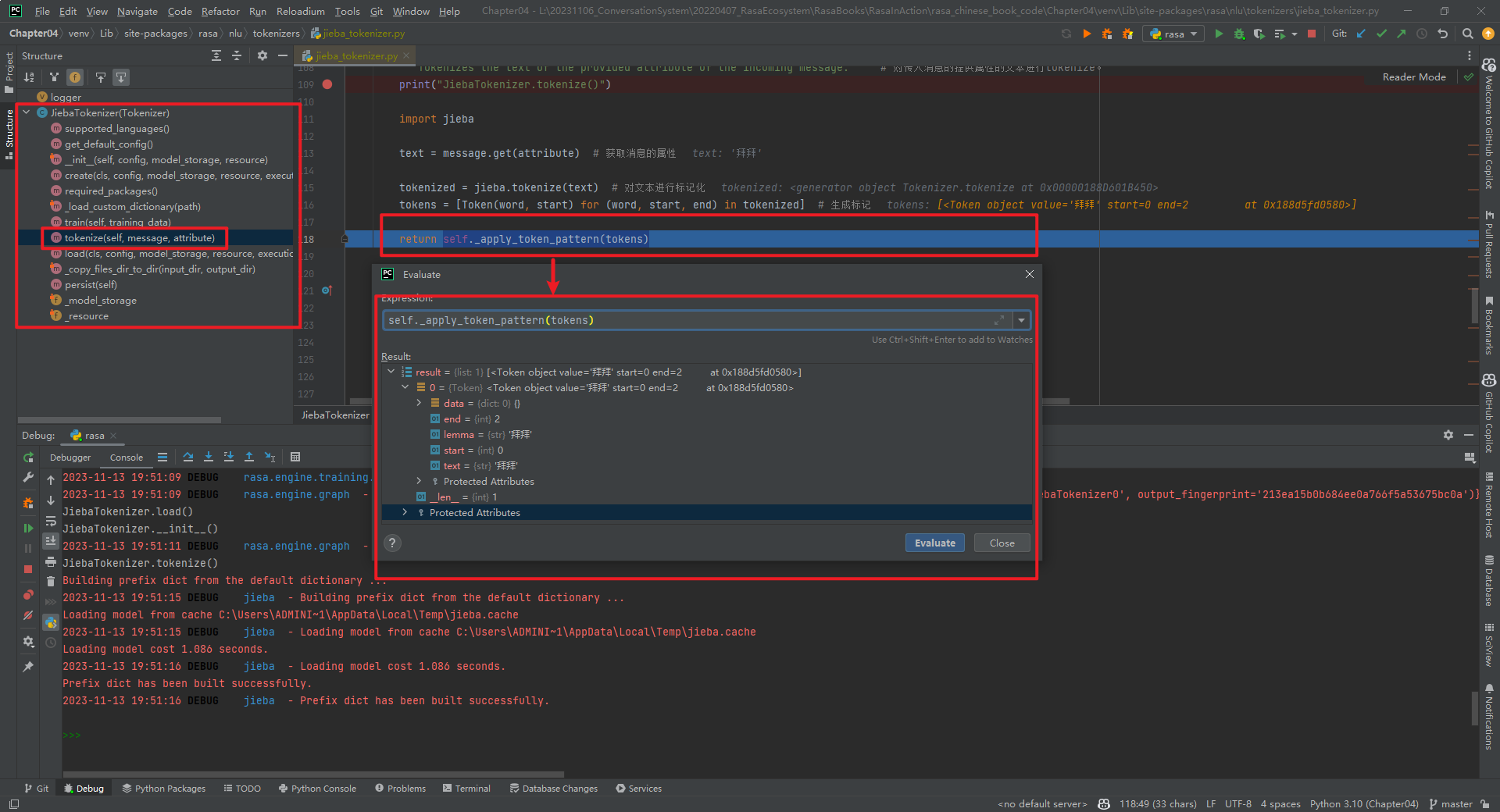
JiebaTokenizer类整体代码结构,如下所示:
加载自定义字典代码,如下所示[3]:
@staticmethod
def _load_custom_dictionary(path: Text) -> None:"""Load all the custom dictionaries stored in the path. # 加载存储在路径中的所有自定义字典。More information about the dictionaries file format can be found in the documentation of jieba. https://github.com/fxsjy/jieba#load-dictionary"""print("JiebaTokenizer._load_custom_dictionary()")import jiebajieba_userdicts = glob.glob(f"{path}/*") # 获取路径下的所有文件。for jieba_userdict in jieba_userdicts: # 遍历所有文件。logger.info(f"Loading Jieba User Dictionary at {jieba_userdict}") # 加载结巴用户字典。jieba.load_userdict(jieba_userdict) # 加载用户字典。
实现分词的代码为tokenize()方法,如下所示:
def tokenize(self, message: Message, attribute: Text) -> List[Token]:"""Tokenizes the text of the provided attribute of the incoming message.""" # 对传入消息的提供属性的文本进行tokenize。print("JiebaTokenizer.tokenize()")import jiebatext = message.get(attribute) # 获取消息的属性tokenized = jieba.tokenize(text) # 对文本进行标记化tokens = [Token(word, start) for (word, start, end) in tokenized] # 生成标记return self._apply_token_pattern(tokens)
self._apply_token_pattern(tokens)数据类型为List[Token]。Token的数据类型为:
class Token:# 由将单个消息拆分为多个Token的Tokenizers使用def __init__(self,text: Text,start: int,end: Optional[int] = None,data: Optional[Dict[Text, Any]] = None,lemma: Optional[Text] = None,) -> None:"""创建一个TokenArgs:text: The token text. # token文本start: The start index of the token within the entire message. # token在整个消息中的起始索引end: The end index of the token within the entire message. # token在整个消息中的结束索引data: Additional token data. # 附加的token数据lemma: An optional lemmatized version of the token text. # token文本的可选词形还原版本"""self.text = textself.start = startself.end = end if end else start + len(text)self.data = data if data else {}self.lemma = lemma or text
特别说明:JiebaTokenizer组件的is_trainable=True。
二.MitieTokenizer
MitieTokenizer类整体代码结构,如下所示:
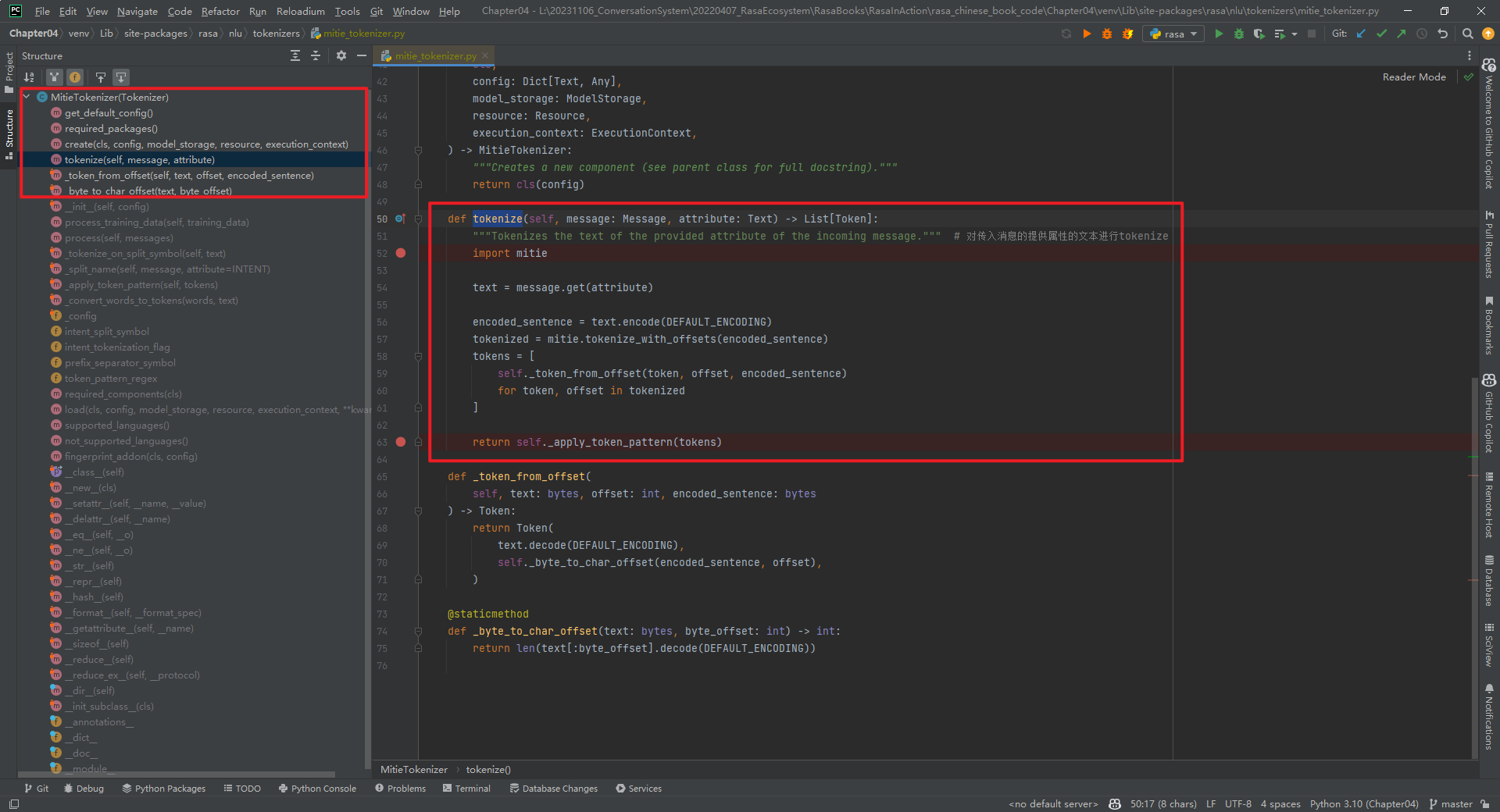
核心代码tokenize()方法代码,如下所示:
def tokenize(self, message: Message, attribute: Text) -> List[Token]:"""Tokenizes the text of the provided attribute of the incoming message.""" # 对传入消息的提供属性的文本进行tokenizeimport mitietext = message.get(attribute)encoded_sentence = text.encode(DEFAULT_ENCODING)tokenized = mitie.tokenize_with_offsets(encoded_sentence)tokens = [self._token_from_offset(token, offset, encoded_sentence)for token, offset in tokenized]return self._apply_token_pattern(tokens)
特别说明:mitie库在Windows上安装可能麻烦些。MitieTokenizer组件的is_trainable=False。
三.SpacyTokenizer
首先安装Spacy类库和模型[4][5],如下所示:
pip3 install -U spacy
python3 -m spacy download zh_core_web_sm
SpacyTokenizer类整体代码结构,如下所示:
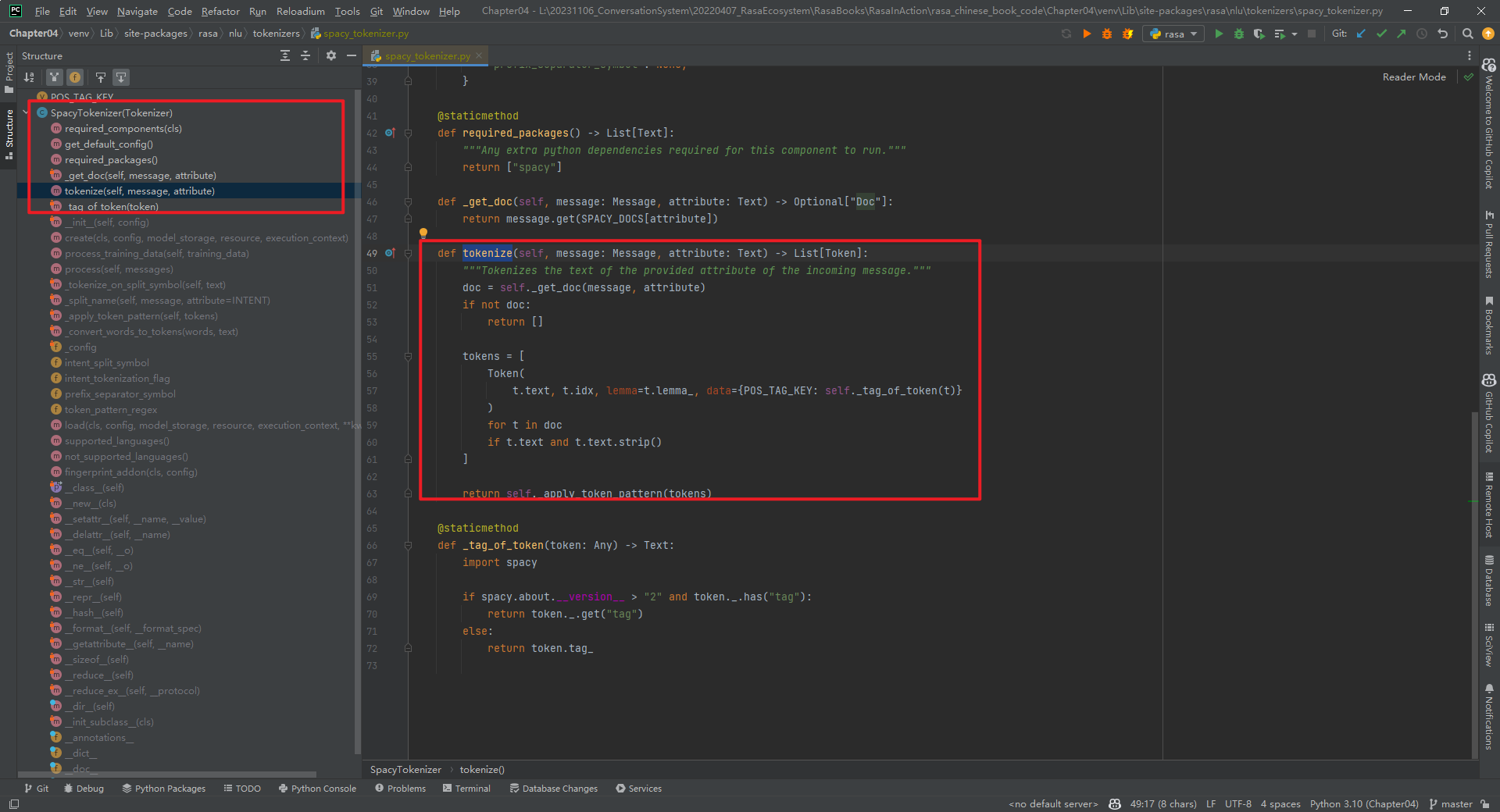
核心代码tokenize()方法代码,如下所示:
def tokenize(self, message: Message, attribute: Text) -> List[Token]:"""Tokenizes the text of the provided attribute of the incoming message.""" # 对传入消息的提供属性的文本进行tokenizedoc = self._get_doc(message, attribute) # doc是一个Doc对象if not doc:return []tokens = [Token(t.text, t.idx, lemma=t.lemma_, data={POS_TAG_KEY: self._tag_of_token(t)})for t in docif t.text and t.text.strip()]
特别说明:SpacyTokenizer组件的is_trainable=False。即SpacyTokenizer只有运行组件run_SpacyTokenizer0,没有训练组件。如下所示:
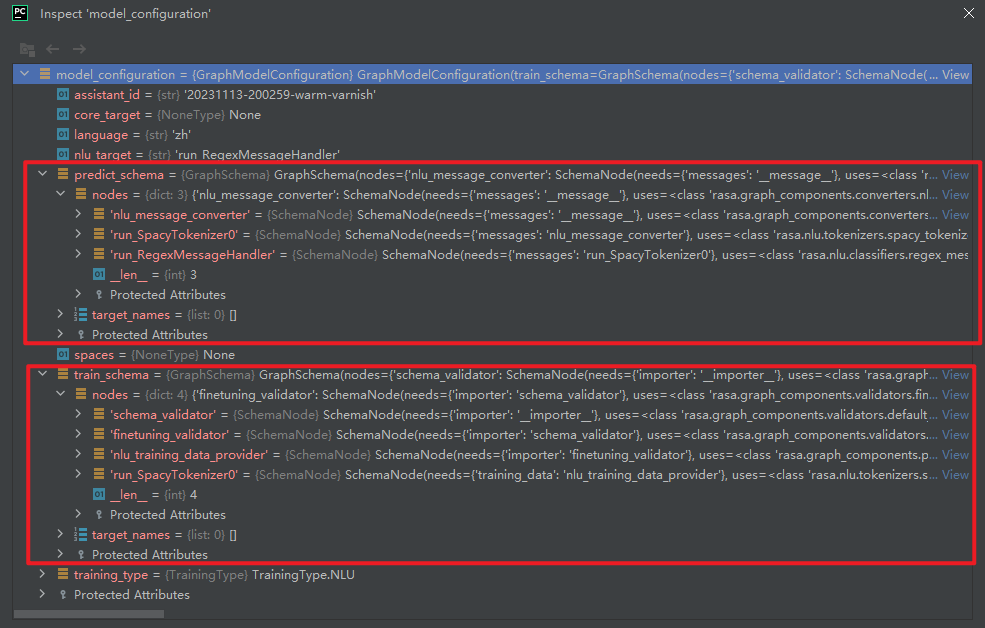
四.WhitespaceTokenizer
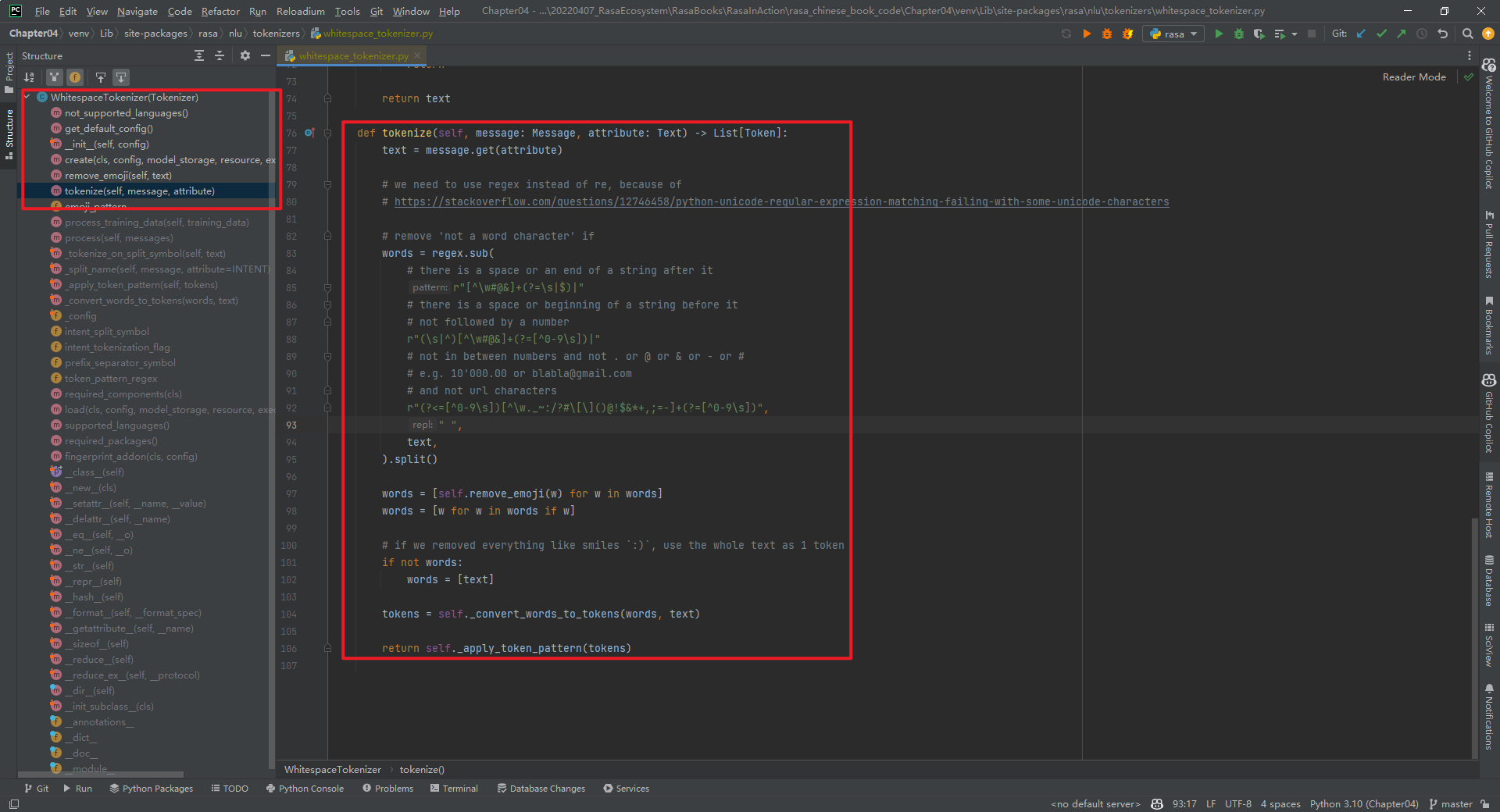
WhitespaceTokenizer主要是针对英文的,不可用于中文。WhitespaceTokenizer类整体代码结构,如下所示:
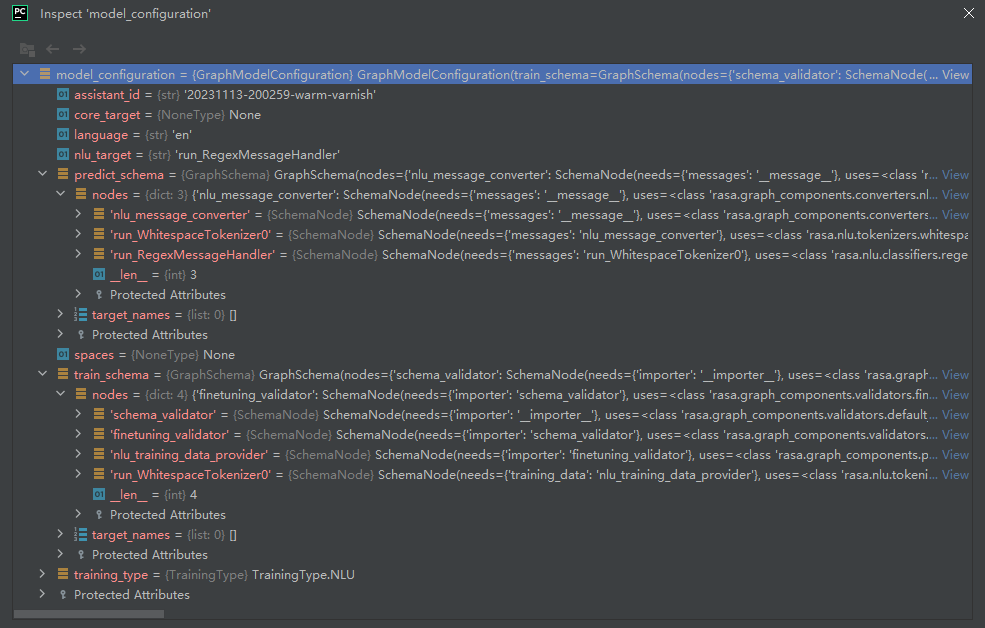
其中,predict_schema和train_schema,如下所示:
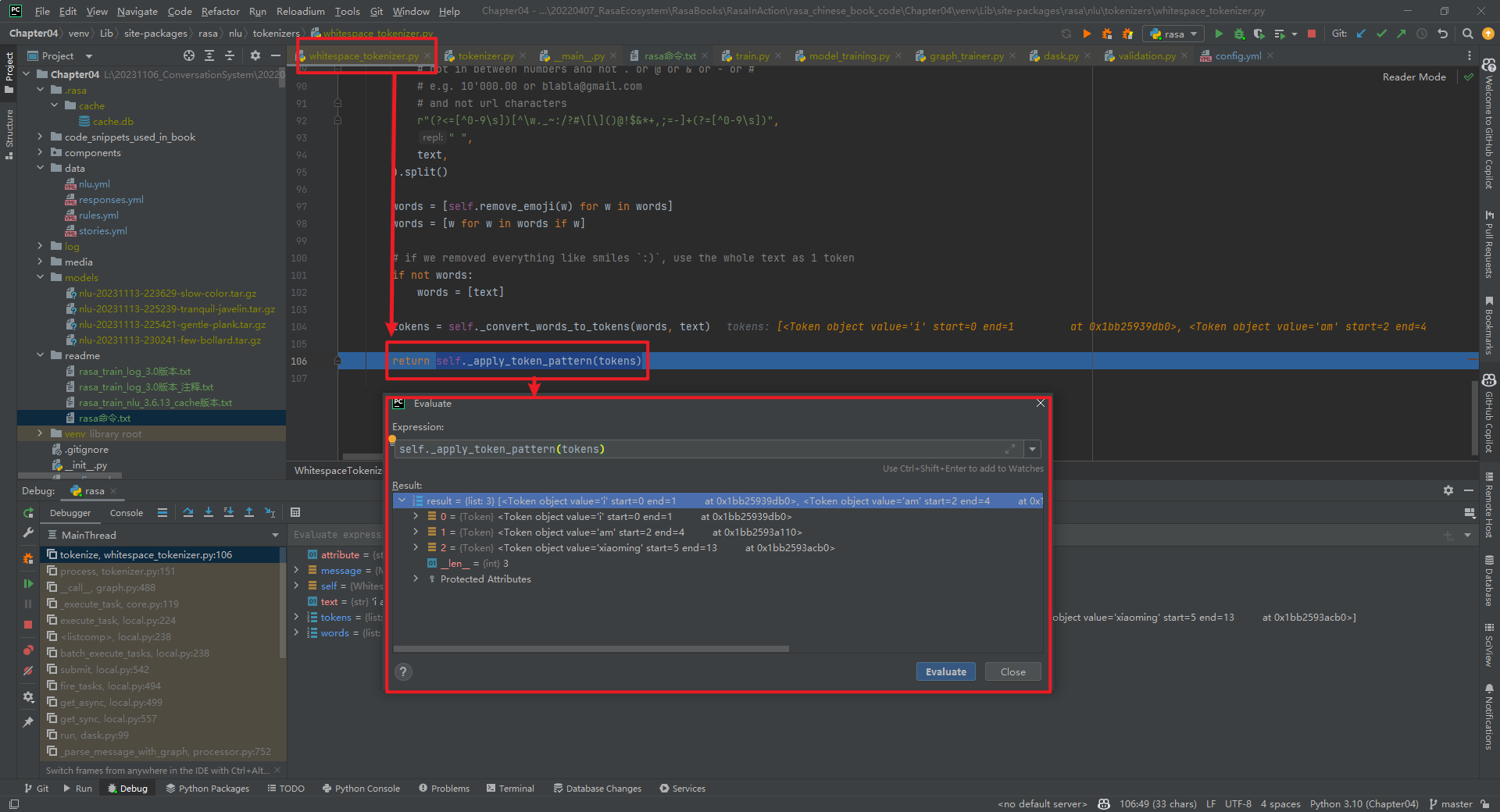
rasa shell nlu --debug结果,如下所示:
特别说明:WhitespaceTokenizer组件的is_trainable=False。
五.BertTokenizer
rasa shell nlu --debug结果,如下所示:
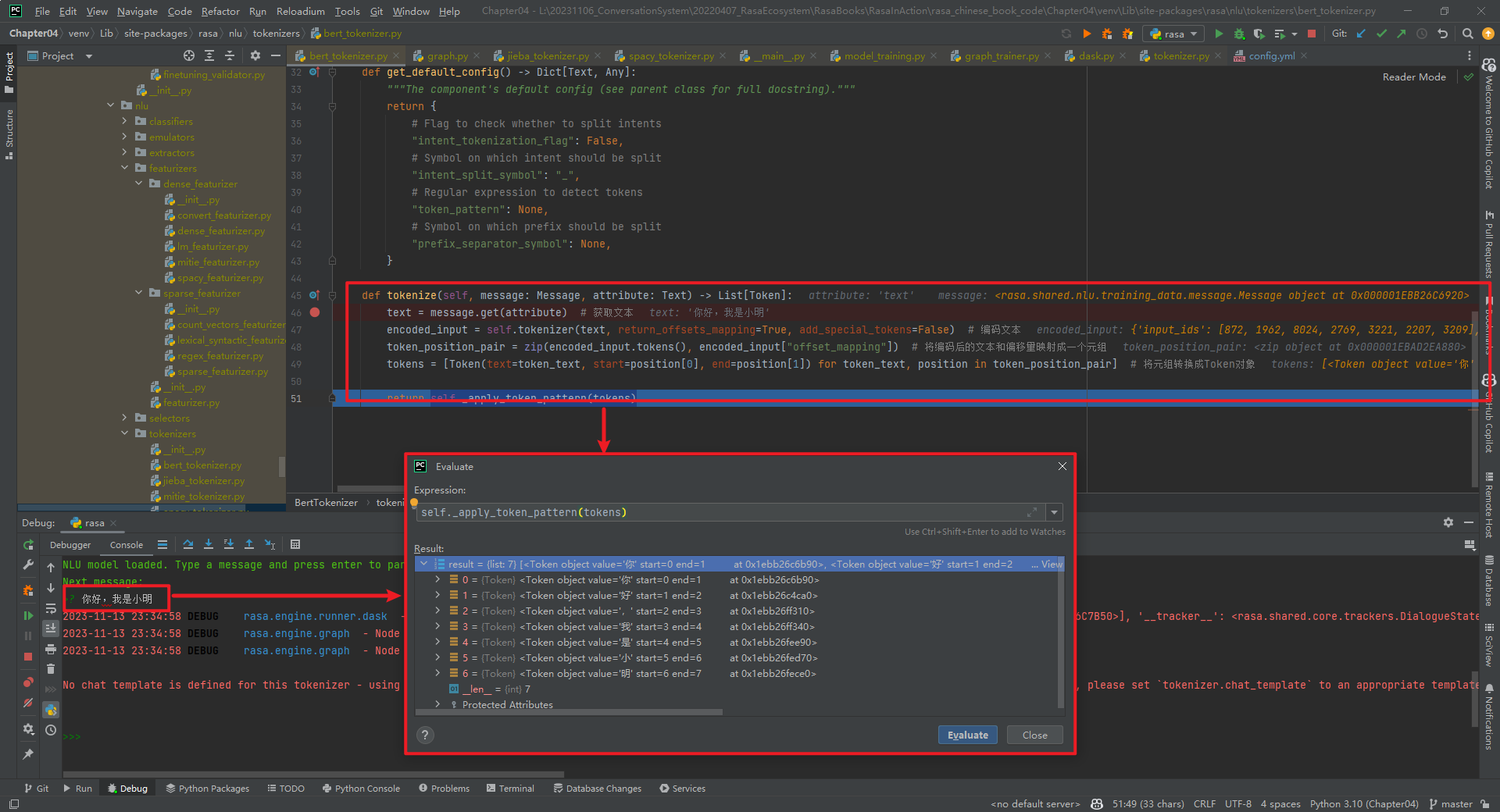
  BertTokenizer代码具体实现,如下所示:
"""
https://github.com/daiyizheng/rasa-chinese-plus/blob/master/rasa_chinese_plus/nlu/tokenizers/bert_tokenizer.py
"""
from typing import List, Text, Dict, Any
from rasa.engine.recipes.default_recipe import DefaultV1Recipe
from rasa.shared.nlu.training_data.message import Message
from transformers import AutoTokenizer
from rasa.nlu.tokenizers.tokenizer import Tokenizer, Token@DefaultV1Recipe.register(DefaultV1Recipe.ComponentType.MESSAGE_TOKENIZER, is_trainable=False
)
class BertTokenizer(Tokenizer):def __init__(self, config: Dict[Text, Any] = None) -> None:""":param config: {"pretrained_model_name_or_path":"", "cache_dir":"", "use_fast":""}"""super().__init__(config)self.tokenizer = AutoTokenizer.from_pretrained(config["pretrained_model_name_or_path"], # 指定预训练模型的名称或路径cache_dir=config.get("cache_dir"), # 指定缓存目录use_fast=True if config.get("use_fast") else False # 是否使用快速模式)@classmethoddef required_packages(cls) -> List[Text]:return ["transformers"] # 指定依赖的包@staticmethoddef get_default_config() -> Dict[Text, Any]:"""The component's default config (see parent class for full docstring)."""return {# Flag to check whether to split intents"intent_tokenization_flag": False,# Symbol on which intent should be split"intent_split_symbol": "_",# Regular expression to detect tokens"token_pattern": None,# Symbol on which prefix should be split"prefix_separator_symbol": None,}def tokenize(self, message: Message, attribute: Text) -> List[Token]:text = message.get(attribute) # 获取文本encoded_input = self.tokenizer(text, return_offsets_mapping=True, add_special_tokens=False) # 编码文本token_position_pair = zip(encoded_input.tokens(), encoded_input["offset_mapping"]) # 将编码后的文本和偏移量映射成一个元组tokens = [Token(text=token_text, start=position[0], end=position[1]) for token_text, position in token_position_pair] # 将元组转换成Token对象return self._apply_token_pattern(tokens)
特别说明:BertTokenizer组件的is_trainable=False。
六.AnotherWhitespaceTokenizer
AnotherWhitespaceTokenizer代码具体实现,如下所示:
from __future__ import annotations
from typing import Any, Dict, List, Optional, Textfrom rasa.engine.graph import ExecutionContext
from rasa.engine.recipes.default_recipe import DefaultV1Recipe
from rasa.engine.storage.resource import Resource
from rasa.engine.storage.storage import ModelStorage
from rasa.nlu.tokenizers.tokenizer import Token, Tokenizer
from rasa.shared.nlu.training_data.message import Message@DefaultV1Recipe.register(DefaultV1Recipe.ComponentType.MESSAGE_TOKENIZER, is_trainable=False
)
class AnotherWhitespaceTokenizer(Tokenizer):"""Creates features for entity extraction."""@staticmethoddef not_supported_languages() -> Optional[List[Text]]:"""The languages that are not supported."""return ["zh", "ja", "th"]@staticmethoddef get_default_config() -> Dict[Text, Any]:"""Returns the component's default config."""return {# This *must* be added due to the parent class."intent_tokenization_flag": False,# This *must* be added due to the parent class."intent_split_symbol": "_",# This is a, somewhat silly, config that we pass"only_alphanum": True,}def __init__(self, config: Dict[Text, Any]) -> None:"""Initialize the tokenizer."""super().__init__(config)self.only_alphanum = config["only_alphanum"]def parse_string(self, s):if self.only_alphanum:return "".join([c for c in s if ((c == " ") or str.isalnum(c))])return s@classmethoddef create(cls,config: Dict[Text, Any],model_storage: ModelStorage,resource: Resource,execution_context: ExecutionContext,) -> AnotherWhitespaceTokenizer:return cls(config)def tokenize(self, message: Message, attribute: Text) -> List[Token]:text = self.parse_string(message.get(attribute))words = [w for w in text.split(" ") if w]# if we removed everything like smiles `:)`, use the whole text as 1 tokenif not words:words = [text]# the ._convert_words_to_tokens() method is from the parent class.tokens = self._convert_words_to_tokens(words, text)return self._apply_token_pattern(tokens)
特别说明:AnotherWhitespaceTokenizer组件的is_trainable=False。
参考文献:
[1]自定义Graph Component:1.1-JiebaTokenizer具体实现:https://mp.weixin.qq.com/s/awGiGn3uJaNcvJBpk4okCA
[2]https://github.com/RasaHQ/rasa
[3]https://github.com/fxsjy/jieba#load-dictionary
[4]spaCy GitHub:https://github.com/explosion/spaCy
[5]spaCy官网:https://spacy.io/
[6]https://github.com/daiyizheng/rasa-chinese-plus/blob/master/rasa_chinese_plus/nlu/tokenizers/bert_tokenizer.py