创建例子数据
postgres=# create table t_hash as select id,md5(id::text) from generate_series(1,5000000) as id;
SELECT 5000000postgres=# vacuum ANALYZE t_hash;
VACUUMpostgres=# \timing
Timing is on. postgres=# select * from t_hash limit 10;id | md5
----+----------------------------------1 | c4ca4238a0b923820dcc509a6f75849b2 | c81e728d9d4c2f636f067f89cc14862c3 | eccbc87e4b5ce2fe28308fd9f2a7baf34 | a87ff679a2f3e71d9181a67b7542122c5 | e4da3b7fbbce2345d7772b0674a318d56 | 1679091c5a880faf6fb5e6087eb1b2dc7 | 8f14e45fceea167a5a36dedd4bea25438 | c9f0f895fb98ab9159f51fd0297e236d9 | 45c48cce2e2d7fbdea1afc51c7c6ad2610 | d3d9446802a44259755d38e6d163e820
(10 rows)Time: 1.430 mspostgres=# explain analyze select * from t_hash where md5 like '%923820dc%';QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------Gather (cost=1000.00..68758.88 rows=500 width=37) (actual time=1.998..753.217 rows=1 loops=1)Workers Planned: 2Workers Launched: 2-> Parallel Seq Scan on t_hash (cost=0.00..67708.88 rows=208 width=37) (actual time=492.740..742.780 rows=0 loops=3)Filter: (md5 ~~ '%923820dc%'::text)Rows Removed by Filter: 1666666Planning Time: 0.115 msExecution Time: 753.275 ms
(8 rows)Time: 754.916 ms
安装插件pg_trgm
postgres=# create extension pg_trgm ;
CREATE EXTENSIONpostgres=# select show_trgm('c4ca4238a0b923820dcc509a6f75849b');show_trgm
-----------------------------------------------------------------------------------------------------------------------------------------{" c"," c4",09a,0b9,0dc,20d,238,382,38a,423,49b,4ca,509,584,6f7,758,820,849,8a0,923,9a6,"9b ",a0b,a42,a6f,b92,c4c,c50,ca4,cc5,dcc,f75}
(1 row)Time: 12.006 ms
创建gin索引 like操作
#创建gin索引
postgres=# create index idx_gin on t_hash using gin(md5 gin_trgm_ops);
CREATE INDEX
Time: 177973.977 ms (02:57.974)
postgres=# explain analyze select * from t_hash where md5 like '%ce2345d%';QUERY PLAN QUERY PLAN
--------------------------------------------------------------------------------------------------------------------Bitmap Heap Scan on t_hash (cost=239.87..2074.79 rows=500 width=37) (actual time=9.299..9.358 rows=2 loops=1)Recheck Cond: (md5 ~~ '%ce2345d%'::text)Heap Blocks: exact=2-> Bitmap Index Scan on idx_gin (cost=0.00..239.75 rows=500 width=0) (actual time=9.256..9.258 rows=2 loops=1)Index Cond: (md5 ~~ '%ce2345d%'::text)Planning Time: 0.710 msExecution Time: 9.394 ms
(7 rows)gin索引问题
postgres=# explain analyze select * from t_hash where md5 like '%9b%';QUERY PLAN
-------------------------------------------------------------------------------------------------------------------Seq Scan on t_hash (cost=0.00..104167.00 rows=808081 width=37) (actual time=0.035..6246.231 rows=574238 loops=1)Filter: (md5 ~~ '%9b%'::text)Rows Removed by Filter: 4425762Planning Time: 6.721 msExecution Time: 9816.262 ms如果碰到Like 小于两个字符的时候,无法使用gin索引。比如like '%ab%'无法使用索引。但是如果‘%abc%’就可以使用索引。
创建gist索引 like操作
postgres=# CREATE INDEX idx_gist ON t_hash USING gist (md5 gist_trgm_ops);
CREATE INDEX
postgres=# drop index idx_gin;
DROP INDEX
postgres=# DISCARD all;
DISCARD ALL
postgres=# explain analyze select * from t_hash where md5 like '%ce2345d%';QUERY PLAN
------------------------------------------------------------------------------------------------------------------------Bitmap Heap Scan on t_hash (cost=52.29..1887.21 rows=500 width=37) (actual time=808.728..808.738 rows=2 loops=1)Recheck Cond: (md5 ~~ '%ce2345d%'::text)Heap Blocks: exact=2-> Bitmap Index Scan on idx_gist (cost=0.00..52.16 rows=500 width=0) (actual time=808.707..808.708 rows=2 loops=1)Index Cond: (md5 ~~ '%ce2345d%'::text)Planning Time: 0.220 msExecution Time: 808.855 ms
(7 rows)
测试发现,上述测试条件下,gin的效率要高很多。
对于上面gin索引两个字符无法使索引的问题,gist可以使用索引。
索引之=比拼
#gist索引情况
postgres=# explain analyze select * from t_hash where md5 ='1679091c5a880faf6fb5e6087eb1b2dc';QUERY PLAN
--------------------------------------------------------------------------------------------------------------------Index Scan using idx_gist on t_hash (cost=0.41..8.43 rows=1 width=37) (actual time=36.534..77.858 rows=1 loops=1)Index Cond: (md5 = '1679091c5a880faf6fb5e6087eb1b2dc'::text)Planning Time: 0.117 msExecution Time: 77.885 ms
(4 rows)
postgres=# drop index idx_gist;
DROP INDEX
postgres=# create index idx_gin on t_hash using gin(md5 gin_trgm_ops);
CREATE INDEX
postgres=# discard all;
DISCARD ALL#gin索引情况
postgres=# explain analyze select * from t_hash where md5 ='1679091c5a880faf6fb5e6087eb1b2dc';QUERY PLAN
---------------------------------------------------------------------------------------------------------------------Bitmap Heap Scan on t_hash (cost=1560.01..1564.02 rows=1 width=37) (actual time=28.292..28.293 rows=1 loops=1)Recheck Cond: (md5 = '1679091c5a880faf6fb5e6087eb1b2dc'::text)Heap Blocks: exact=1-> Bitmap Index Scan on idx_gin (cost=0.00..1560.01 rows=1 width=0) (actual time=28.275..28.276 rows=1 loops=1)Index Cond: (md5 = '1679091c5a880faf6fb5e6087eb1b2dc'::text)Planning Time: 0.374 msExecution Time: 28.323 ms
(7 rows)# btree索引情况
postgres=# create index idx_dx on t_hash(md5);
CREATE INDEXpostgres=# discard all;
DISCARD ALL
postgres=# explain analyze select * from t_hash where md5 ='1679091c5a880faf6fb5e6087eb1b2dc';QUERY PLAN
----------------------------------------------------------------------------------------------------------------Index Scan using idx_dx on t_hash (cost=0.56..8.57 rows=1 width=37) (actual time=0.034..0.038 rows=1 loops=1)Index Cond: (md5 = '1679091c5a880faf6fb5e6087eb1b2dc'::text)Planning Time: 0.127 msExecution Time: 0.060 ms
(4 rows)测试情况:
gist:77.885 ms
gin:28.323 ms
btree:0.060 ms
测试结果:在=的测试中btree索引吊打。
索引大小比较
postgres=# select pg_size_pretty(pg_total_relation_size('idx_dx'));pg_size_pretty
----------------282 MB
(1 row)postgres=# select pg_size_pretty(pg_total_relation_size('idx_gin'));pg_size_pretty
----------------332 MBpostgres=# select pg_size_pretty(pg_total_relation_size('idx_gist'));pg_size_pretty
----------------885 MB
(1 row)
结论:gist索引更大。
gin索引 VACUUM and autovacuum
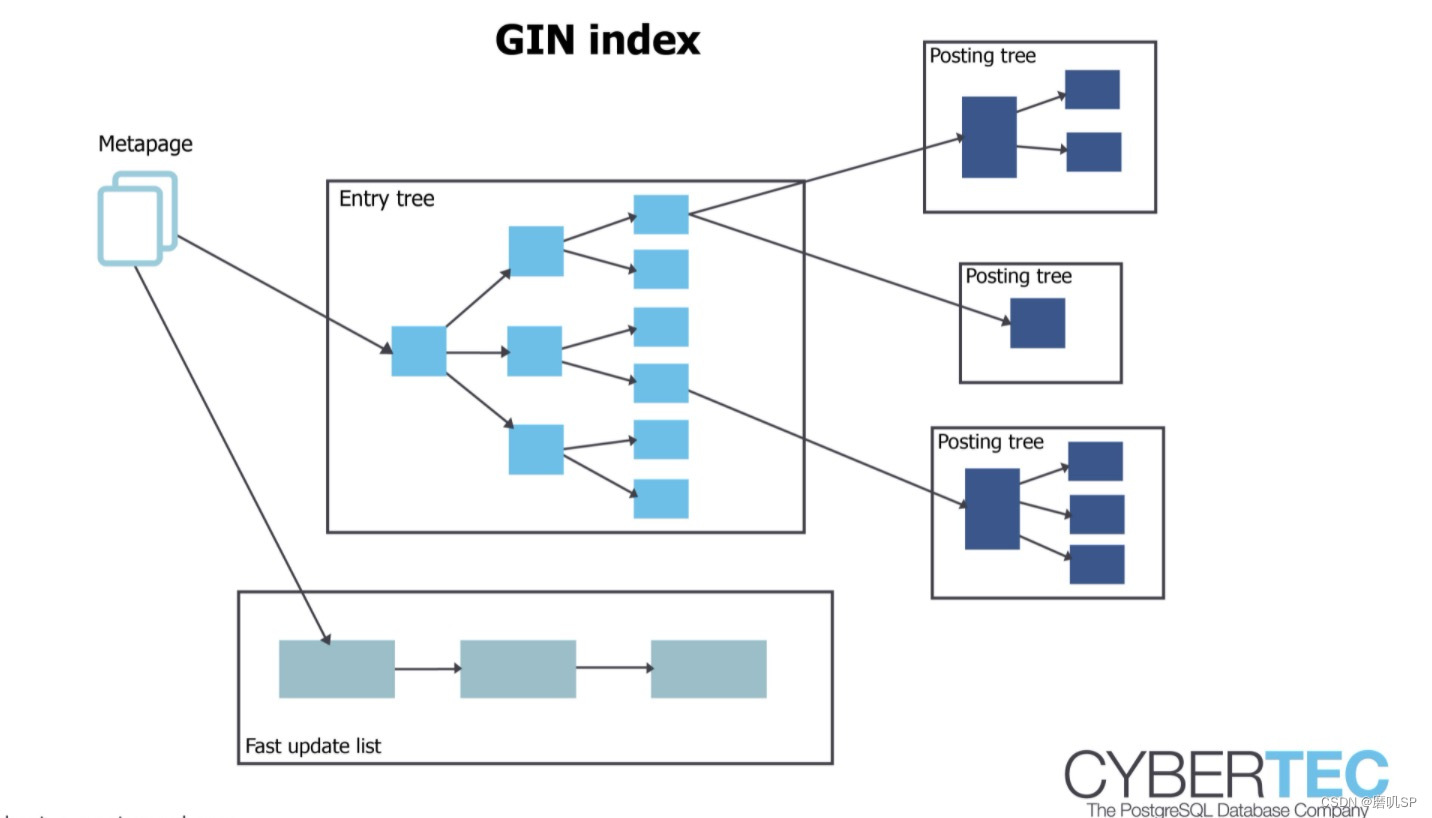
首先gin索引的结构如下:
#创建表
postgres=# CREATE TABLE t_fti (payload tsvector) WITH (autovacuum_enabled = off);
CREATE TABLE
#插入数据
postgres=# INSERT INTO t_fti SELECT to_tsvector('english', md5('dummy' || id)) FROM generate_series(1, 2000000) AS id;
INSERT 0 2000000postgres=# select * from t_fti limit 5;payload
--------------------------------------'8c2753548775b4161e531c323ea24c08':1'c0c40e7a94eea7e2c238b75273087710':1'ffdc12d8d601ae40f258acf3d6e7e1fb':1'abc5fc01b06bef661bbd671bde23aa39':1'20b70cebcb94b1c9ba30d17ab542a6dc':1
(5 rows)#创建索引
postgres=# CREATE INDEX idx_fti ON t_fti USING gin(payload);
CREATE INDEX#使用插件观察索引
postgres=# CREATE EXTENSION pgstattuple;
CREATE EXTENSION#首次没有pending list
postgres=# SELECT * FROM pgstatginindex('idx_fti');version | pending_pages | pending_tuples
---------+---------------+----------------2 | 0 | 0
(1 row)#再次插入数据
postgres=# INSERT INTO t_fti
SELECT to_tsvector('english', md5('dummy' || id))
FROM generate_series(2000001, 3000000) AS id;
INSERT 0 1000000#pendling有数据,说明fastupate有效
postgres=# SELECT * FROM pgstatginindex('idx_fti');version | pending_pages | pending_tuples
---------+---------------+----------------2 | 326 | 50141
(1 row)#vacuum后写入gin树中
postgres=# vacuum t_fti ;
VACUUM
postgres=# SELECT * FROM pgstatginindex('idx_fti');version | pending_pages | pending_tuples
---------+---------------+----------------2 | 0 | 0