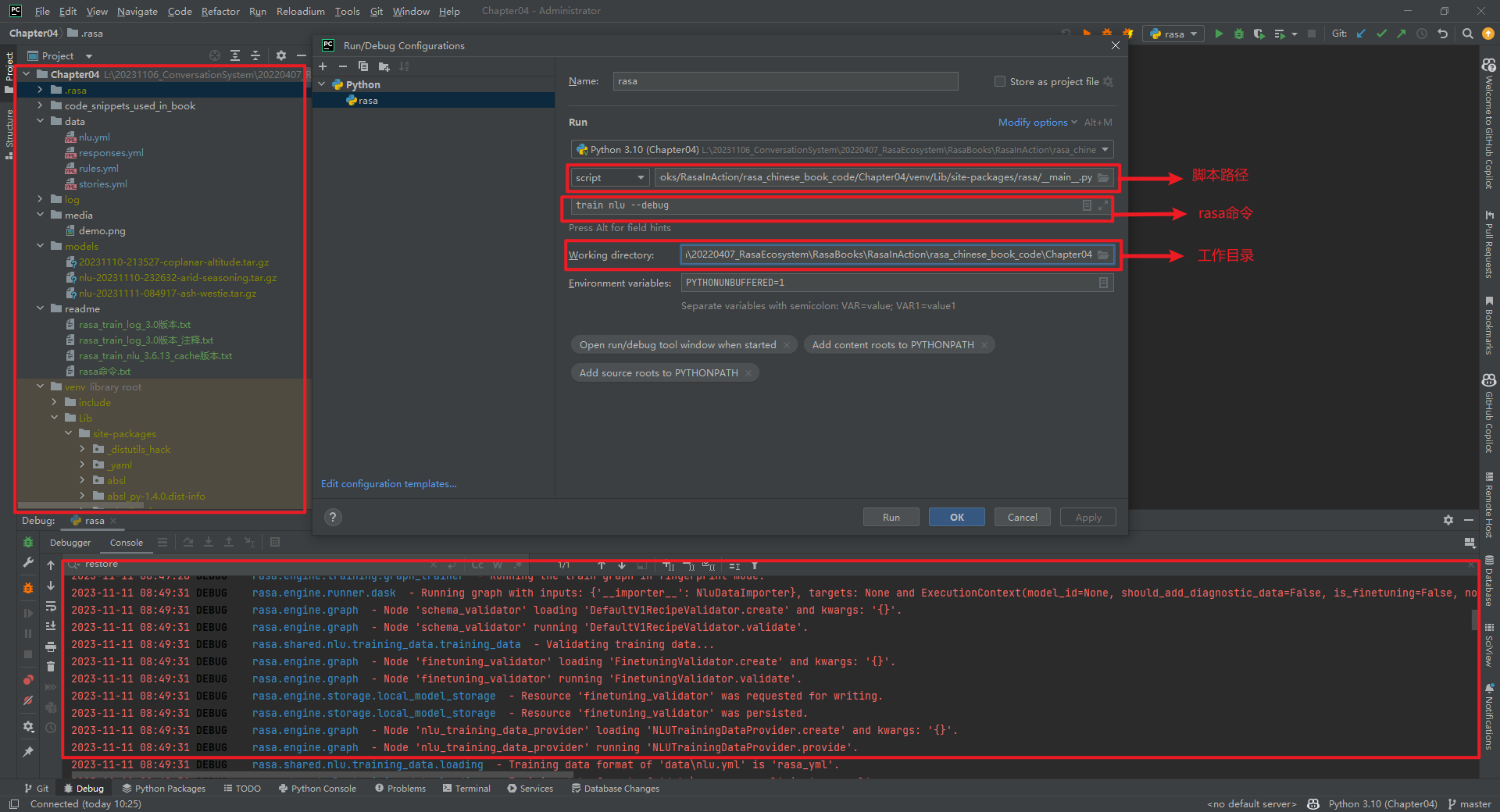
华子目录
- 什么是正则表达式
- 元字符
- 字符集
- 字符集与元字符的综合使用
- 数量规则
- 指定匹配次数
- 边界处理
- 分组匹配
- 贪婪匹配
- 非贪婪匹配
- re.S
- 转义字符
- re.search()
- re.sub()
- 实例
- 常见的匹配模式
什么是正则表达式
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。是对字符串操作的一种逻辑公式,就是用事先定义好的一些特殊字符及这些特定字符的组合,组成一个"规则字符串",这个"规则字符串"用来表达对字符串的一种逻辑过滤。
re.match() 从字符串的起始位置开始匹配,如果起始位置匹配不成功,就返回一个None
re..findall() 在字符串中找到正则表达式所要匹配的所有子串,并返回一个列表
re.search() 扫描整个字符串并返回第一个成功的匹配
re.sub() 替换整个字符串中每一个匹配的字符
match函数参数说明:
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。 |
元字符
匹配单个字符
.表示匹配任意一个字符(默认不包含\n)
import re
print(re.match('.','wed'))
print(re.match('..','wed'))
print(re.match('.','web').group()) # group()提取匹配成功的字符/字符串
<re.Match object; span=(0, 1), match='w'>
<re.Match object; span=(0, 2), match='we'>
w
\d 表示0-9之间的任意一个数字
import re
print(re.match('\d\d','12fde'))
print(re.match('.\d','w2fs'))
print(re.findall('\d','we2e34'))
<re.Match object; span=(0, 2), match='12'>
<re.Match object; span=(0, 2), match='w2'>
['2', '3', '4']
\D 表示非数字
print(re.match('\D','w2ed'))
<re.Match object; span=(0, 1), match='w'>
\s 只能匹配空白字符(空格,\n,\t)
\S 表示非空白字符(非空格,非\n,非\t)
\w 表示匹配数字,字母,下划线
\W 表示非数字,字母,下划线
字符集
只能匹配单个字符,使用[]来表示,表示一个字符的范围。
注:还是匹配一个字符,第一个字符开始匹配看是不是再这个范围内,如果不在,就返回None
import re
print(re.match('[tyer]','er'))
print(re.findall('[erty]','hfseryt'))
print(re.findall('[a-z]','zabc'))
print(re.findall('[A-z]','ghahaAFG'))
print(re.findall('[0-9]','0973khg382'))
print(re.findall('[0-9A-z]','sg34'))
<re.Match object; span=(0, 1), match='e'>
['e', 'r', 'y', 't']
['z', 'a', 'b', 'c']
['g', 'h', 'a', 'h', 'a', 'A', 'F', 'G']
['0', '9', '7', '3', '3', '8', '2']
['s', 'g', '3', '4']
^ 取反,写在字符集里面
print(re.match('[^a-z]','fgs'))
print(re.findall('[^a-z]','ABG'))
None
['A', 'B', 'G']
字符集与元字符的综合使用
print(re.match('[\d\D]','f2f'))
print(re.match('[\w\W][\w\W]','f2f'))
<re.Match object; span=(0, 1), match='f'>
<re.Match object; span=(0, 2), match='f2'>
数量规则
* 匹配前一个字符的任意次数,包括0次
print(re.match('\d*','13289446832'))
print(re.match('\w*','1328944yut6832'))
<re.Match object; span=(0, 11), match='13289446832'>
<re.Match object; span=(0, 14), match='1328944yut6832'>
+ 匹配前一个字符,重复匹配1次以上,0次不行,只要出现1次以上就匹配
print(re.match('\w+','123fs45'))
<re.Match object; span=(0, 7), match='123fs45'>
? 匹配前一个字符出现0次或者1次,只能匹配一个
print(re.match('\d?','a1234'))
print(re.match('\d?','1234'))
<re.Match object; span=(0, 0), match=''>
<re.Match object; span=(0, 1), match='1'>
指定匹配次数
{m} 匹配前一个字符的m次
{m,} 至少匹配m次以上
{m,n} 匹配m次以上,n次以下
print(re.match('\d{3}','1234567'))
print(re.match('\d{3,}','1234567'))
print(re.match('\d{3,6}','1234567'))
<re.Match object; span=(0, 3), match='123'>
<re.Match object; span=(0, 7), match='1234567'>
<re.Match object; span=(0, 6), match='123456'>
边界处理
注:做完边界处理的正则表达式的匹配次数必须与字符串的长度相等,否则会返回None
^ 边界开始
$ 边界结束
实例
匹配电话号码
第一位[1]
第二位[358]
第三位[56789]
后八位任意
print(re.match('^1[358][5-9]\d{8}$','13589446832'))
print(re.match('^1[358][5-9]\d{8}$','135894468aa'))
<re.Match object; span=(0, 11), match='13589446832'>
None
分组匹配
| 或者
() 分组
t = '2022-12-30'
print(re.match('(\d{4})-(0[1-9]|1[0-2])-([0-2][0-9]|3[01])', t))
print(re.match('(\d{4})-(0[1-9]|1[0-2])-([0-2][0-9]|3[01])',t).group(0))
print(re.match('(\d{4})-(0[1-9]|1[0-2])-([0-2][0-9]|3[01])',t).group(1))
print(re.match('(\d{4})-(0[1-9]|1[0-2])-([0-2][0-9]|3[01])',t).group(2))
print(re.match('(\d{4})-(0[1-9]|1[0-2])-([0-2][0-9]|3[01])',t).group(3))
<re.Match object; span=(0, 10), match='2022-12-30'>
2022-12-30 # 取所有
2022 # 取第一组
12 # 取第二组
30 # 取第三组
贪婪匹配
尽可能多的去匹配
import re
# 匹配尽可能多的字符
content = 'Hello 1234567 World_This is a Regex Demo'result = re.match('^He.*(\d+)\s.*Demo$', content)
print(result)
print(result.group(1))
<re.Match object; span=(0, 40), match='Hello 1234567 World_This is a Regex Demo'>
7
非贪婪匹配
尽可能少的去匹配
import re
# 匹配尽可能少的字符
content = 'Hello 1234567 World_This is a Regex Demo'
result = re.match('^He.*?(\d+).*Demo$', content)print(result)
print(result.group(1))
<re.Match object; span=(0, 40), match='Hello 1234567 World_This is a Regex Demo'>
1234567
re.S
匹配包括换行在内的所有字符,多数用于有多行数据时,用re.S会更方便
import re
content = """
Hello 1234567 World_This
is a Regex Demo
"""
result = re.match('^\nHe.*?(\d+).*Demo$', content, re.S)
print(result)
print(result.group())
print(result.group(1))<re.Match object; span=(0, 42), match='\nHello 1234567 World_This \nis a Regex Demo'>Hello 1234567 World_This
is a Regex Demo
1234567
转义字符
import recontent = 'price is $5.00'
result = re.match('price\sis\s$5.00', content)
print(result)
None
import re# \表示转义,加在特殊字符的前面,表示它不是正则里的匹配符号,而是普通文本
content = 'price is $5.00'
result = re.match('price\sis\s\$5\.00', content)
print(result)
print(result.group())
<re.Match object; span=(0, 14), match='price is $5.00'>
price is $5.00
re.search()
扫描整个字符串并返回第一个成功匹配的字符串
import recontent = 'Extroa stings Hello 1234567 World_This is a 66666666 RDemogex Demo Extra stings'result = re.search('He.*?(\d+).*?Wor.*?s$', content)
print(result)
print(result.group(1))
<re.Match object; span=(14, 79), match='Hello 1234567 World_This is a 66666666 RDemogex D>
1234567
re.sub()
替换字符串中每一个匹配的字符,返回替换后的字符串
import recontent = 'Extra stings Hello 1234567 World_This is a Regex Demo Extra stings'
# 第一个参数 正则表达式
# 第二个参数 :要替换的新字符
# 第三个参数:原字符串
content = re.sub('s', '7', content)
print(content)
Extra 7ting7 Hello 1234567 World_Thi7 i7 a Regex Demo Extra 7ting7
import recontent = 'Extra stings Hello 1234567 World_This is a Regex Demo Extra stings'
content = re.sub('\d+', '666', content)
print(content)
Extra stings Hello 666 World_This is a Regex Demo Extra stings
实例
import re
#写的很简洁
content = 'Hello 123 4567 World_Thixs is a Regex'
result = re.match('He.*?Regex',content)#把一整个文本匹配完成 又不想写的复杂,print(result.group()) # 获取匹配内容
print(result.span()) # 获取匹配长度
Hello 123 4567 World_Thixs is a Regex
(0, 37)
常见的匹配模式