大家好,我是微学AI,今天给大家讲一下大模型的实践应用6-百度文心一言的基础模型ERNIE的详细介绍,与BERT模型的比较说明。在大规模语料库上预先训练的BERT等神经语言表示模型可以很好地从纯文本中捕获丰富的语义模式,并通过微调的方式一致地提高各种NLP任务的性能。然而,现有的预训练语言模型很少考虑融入知识图谱(KGs),知识图谱可以为语言理解提供丰富的结构化知识。我们认为知识图谱中的信息实体可以通过外部知识增强语言表示。在这篇论文中,我们利用大规模的文本语料库和知识图谱来训练一个增强的语言表示模型(ERNIE),它可以同时充分利用词汇、句法和知识信息。实验结果表明,ERNIE在各种知识驱动任务上都取得了显著的进步,同时在其他常见的NLP任务上,ERNIE也能与现有的BERT模型相媲美。
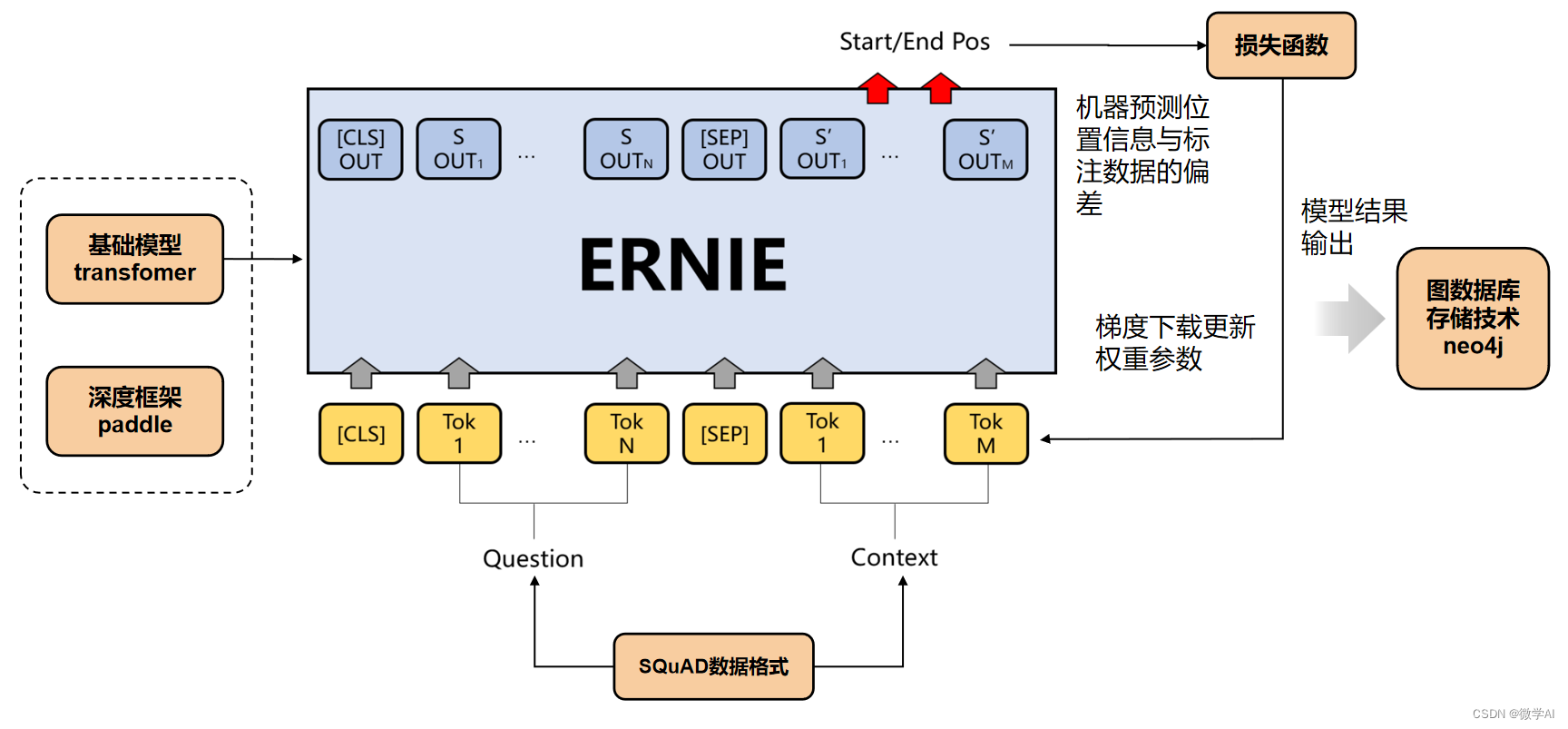
一、ERNIE和BERT的比较
首先,百度的ERNIE和BERT都是基于Transformer的预训练语言模型,但它们在模型架构和训练方式上有一些区别。
-
模型架构上的区别:
- BERT是谷歌在2018年提出的预训练深度双向语言模型。BERT的特点是通过遮挡一部分输入词汇(Masked Language Model)然后让模型预测这些被遮挡的词汇,以及下一句预测(Next Sentence Prediction)来进行模型的预训练。
- ERNIE(Enhanced Representation through kNowledge IntEgration)是百度在2019年提出的预训练深度语言模型。ERNIE的创新点在于它采用了基于知