一、概述
PG到Oracle的同步方案使用debezium + kafka + kafka-connect-jdbc。debezium是一款开源的变更捕获软件,它以kafka的connector形式运行,可以捕获PostgreSQL、MySQL、Oracle中的变更数据,保存到kafka。kafka-connect-jdbc是confluent公司的一款开源软件,以connector形式运行,可以从kafka读取变更数据,转换为PostgreSQL、MySQL、Oracle、SQLServer、DB2等数据库的SQL语句,通过JDBC连接到数据库。
本方案用到的软件都是从开源代码编译而来,编译过程在第6章节。
二、kafka和kafka connect
概述
kafka是一个分布式消息队列服务器。从逻辑角度讲,消息存储在称为topic的对象里(可以理解为一个topic就是一个消息队),kafka的客户端读/写消息时,需要指定topic名称。
可以用命令或代码创建topic、配置/查看属性、消息数。topic中的消息被读取后并没有删除,其它客户端仍可读取。客户端读取topic时,除了名称还需指定group id对象,它用于保存此客户端已经读到的消息的位置(offset)。kafka是通过group id中的offset,来管理不同客户端对同一topic消费的不同进度。kafka把所有group id的offset保存在名为__consumer_offset的topic下。可以通过命令修改某个group id的offset。消息可以设置保存时间,超时自动删除,但无法用命令删除。topic中的消息只能以先进先出(FIFO)方式读取。
kafka的启动和配置
kafka的运行依赖zookeeper,集群中需要有zookeeper服务器,zookeeper是一个分布式数据库,一般用来存储集群中需要各节点共享的信息,保证信息的一致性,也可以用来实现分布式锁。
我下载的二进制kafka中包含了zookeeper服务器,在配置文件config/zookeeper.properties中,设置一下dataDir,作为实验其它参数默认即可:

注意,zookeeper服务器默认监听端口是2181。
zookeeper和kafka都是java程序,注意配置一下java运行环境,我使用的是Java HotSpot 1.8,只要配置好JAVA_HOME和PATH两个环境变量即可,JAVA_HOME指向JDK解压后的目录,启动脚本会优先到JAVA_HOME里去找Java运行环境。

启动zookeeper,在kafka根目录下执行:
bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
kafka的配置文件是config/server.properties,设置log.dirs,这是kafka存消息数据的目录,会占用较大磁盘,作为实验其它参数默认:

启动kafka,在kafka根目录下执行:
bin/kafka-server-start.sh -daemon config/server.properties
注意,kafka服务器默认监听端口是9092,kafka和zookeeper,客户端和kafka直接都是通过网络读写数据的。
我们用到的关于zookeeper、kafka、connect的脚本都在kafka的bin目录下:
消息的读写:topic和group id 相关命令
创建topic:
bin/kafka-topics.sh --create --topic my-test-topic --bootstrap-server 127.0.0.1:9092 --partitions 1 --replication-factor 1
查看指定topic属性:
bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 -describe --topic my-test-topic
修改topic属性:
bin/kafka-configs.sh --bootstrap-server 127.0.0.1:9092 --entity-type topics --alter --entity-name my-test-topic --add-config retention.ms=1000
bin/kafka-configs.sh --bootstrap-server 127.0.0.1:9092 --entity-type topics --alter --entity-name my-test-topic --delete-config retention.ms
列出所有topic:
bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --list
删除topic:
bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --delete --topic my-test-topic
查看topic中有几条消息:
bin/kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list 127.0.0.1:9092 --topic my-test-topic
查看有哪些消费者组:
./bin/kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --list
查看消费者组的偏移信息:
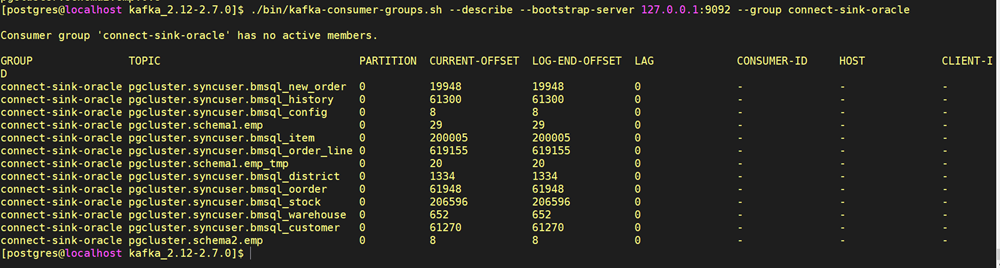
./bin/kafka-consumer-groups.sh --describe --bootstrap-server 127.0.0.1:9092 --group connect-sink-oracle
可以看到connect-sink-oracle中记录了多个topic的偏移量信息,LOG-END-OFFSET表示这个topic中总共有多少消息,CURRENT_OFFSET表示消费者当前已读取的消息偏移量,LAG就是还剩多少条消息没读,这个命令可以查看同步的进度。
设置某个topic的CURRENT_OFFSET:
./bin/kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --group connect-sink-oracle --topic my-test-topic --execute --reset-offsets --to-earliest
可以使用bin目录下的kafka-console-producer.sh和kafka-console-consumer.sh,向kafka收发消息:
./bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic <topic-name>
./bin/kafka-console-consumer.sh --from-beginning --bootstrap-server localhost:9092 --topic <topic-name>
--from-beginning表示从topic的第一条消息开始读,否则只读最后一条消息之后的。
常用于调试,例如查看debezium在PG上做snapshot或捕获数据的状态:
./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic connect-offsets
kafka connect
kafka connect是kafka的一个组件,是一个独立于kafka服务器的Java程序,它可以统一管理多个connector(注意connect和connector不同),connector用于连接不同数据库,读取数据库写到kafka,或将kafka中的消息写到数据库。一个connector是kafka的生产者或消费者客户端,是jar形式的java程序,放在kafka的libs目录下。从编程角度讲connector实现了kafka connect的sink和source接口,kafka connect启动时会加载它们。用户可以通过kafka connect的REST API接口配置connector的参数。
实现source接口的connector,是kafka的生产者,连接源数据库,从源数据库获取数据写到kafka。
实现sink接口的connector,是kafka的消费者,连接目标数据库,从kafka读取数据,写入目的数据库。
connector写到kafka前,数据可以序列化(压缩),从kafka读出后再反序列化(解压),以降低网络和存储开销,这个工作由称为converter的Java程序来做,它以jar形式被connect加载。
一个kafka connect进程称为一个worker,source connector和sink connector都运行在这个进程中。
配置和启动kafka connect
kafka connect的配置文件在config/connect-distributed.properties,作为实验参数使用默认值就行。
注意:
- bootstrap.servers是kafka服务器的IP:PORT
- group.id是connect worker作为消费者所使用的group id不能与sink connector的group id相同。
- plugin.path指定了connect到哪些目录下寻找jar。jdbc、connector、converter都是jar形式的程序。为了实验简单,只指定kafka根目录下的libs,把所有用到的jar都复制到这里,建议使用绝对路径。
启动connect:
./bin/connect-distributed.sh -daemon config/connect-distributed.properties
配置和启动connector
kafka connect启动时connctor和converter的jar已被加载,还需要通过REST API配置和启动connector。
下面的命令创建/启动了一个connector:
curl -H "Content-Type: application/json" -X POST http://127.0.0.1:8083/connectors -d '@sink-oracle-156.json'
connect启动以后在8083端口监听REST API命令,向这个端口以http post发送json格式的配置数据,'@sink-oracle-156.json'指定了文件路径为当前目录下sink-oracle-156.json文件,是json格式文本,内容如下:

是source类型还是sink类型,取决于connector.class指向的类是实现source接口还是sink接口。这个connector的名称是sink-oracle,实现了sink接口(类io.confluent.connect.jdbc.JdbcSinkConnector实现了sink类),key.converter和value.converter设定所使用的的converter。
删除/停止名为sink-oracle的connector:
curl -X DELETE http://127.0.0.1:8083/connectors/sink-oracle
查看所有connector:
curl -X GET http://127.0.0.1:8083/connectors
查看某个connector状态:
curl -X GET http://127.0.0.1:8083/connectors/<connector name>/status|jq
配置和部署avro-converter和schema-registry
源数据库的每一条变更记录,默认被转换成了json字符串,包含了元数据和数据,然后发送到kafka,下面就是update emp set ename = 'TOMAS', job = 'ENGINEER' where empno=2 and ename='SMITH' 对应的json字符串:
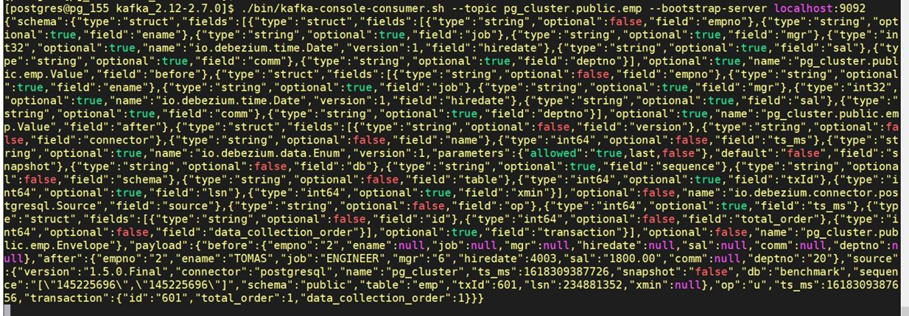
这样有很大冗余,有两个办法可以降低冗余:
一、使用压缩的序列化格式;
二、使用元数据服务器共享元数据,用key值获得某个表的元数据,消息只携带数据和key值,消费者使用key值查询完整的元数据来解析消息。
avro-converter和schema-registry共同完成这个工作。本方案的使用的avro-converter和schema-registry来自是confluentinc公司的开源代码,编译过程见后面章节。
![[Linux] ssh远程访问及控制](https://img-blog.csdnimg.cn/4a2e4ebfc4ce4f4691698fcd442a9f75.png)