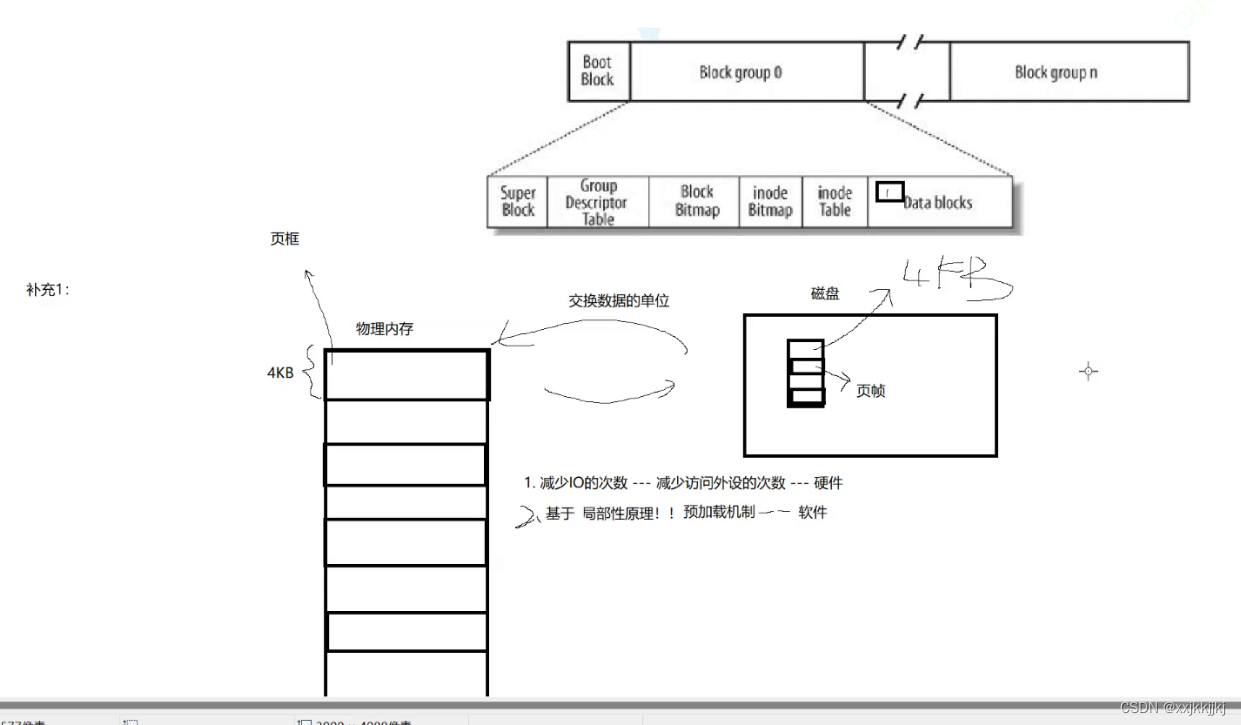
补充1:硬件级别磁盘和内存之间数据交互的基本单位
OS的内存管理
内存的本质是对数据临时存/取,把内存看成很大的缓冲区
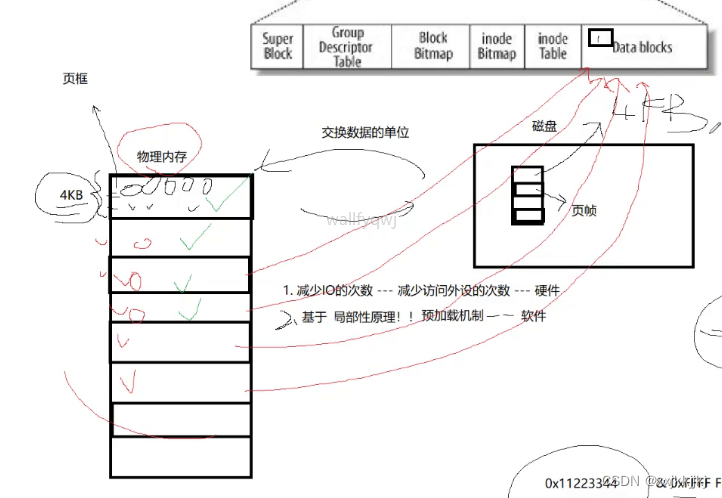
物理内存和磁盘交互的单位是4KB,磁盘中未被打开的文件数据块也是4KB,所以磁盘中页帧也是4KB,内存中叫页框
我这个文件可能没有4KB,就一个字节,但不好意思加载4KB
我这个文件4KB,想修改1字节,也得加载4KB
为什么它不是要多少加载多少,而是一个固定大小4KB呢?
1、和磁盘交互比较慢,一共4KB每次要1KB的效率不如一气直接4KB,因为磁盘只需要定位一次
2、如果4KB文件你只要100字节,你能保证你下一次不用这文件上下文的其他数据吗?反正拿100字节还是4KB效率差不多,因为估摸着你后面的字节大概率也要用
局部性原理:正在访问代码区域附近也大概率会有数据代码被访问
这是一种预加载机制
那系统中向文件写了100字节,实际上保存100字节需要4KB?把数据交换的物理内存也要花4KB?
是的,文件大小从中做了一些事情
不用担心浪费问题,文件特别大前面那些内容把4KB都写满了,只有最后一个块被浪费了,小文件的就更不用说了
补充2:操作系统如何管理内存
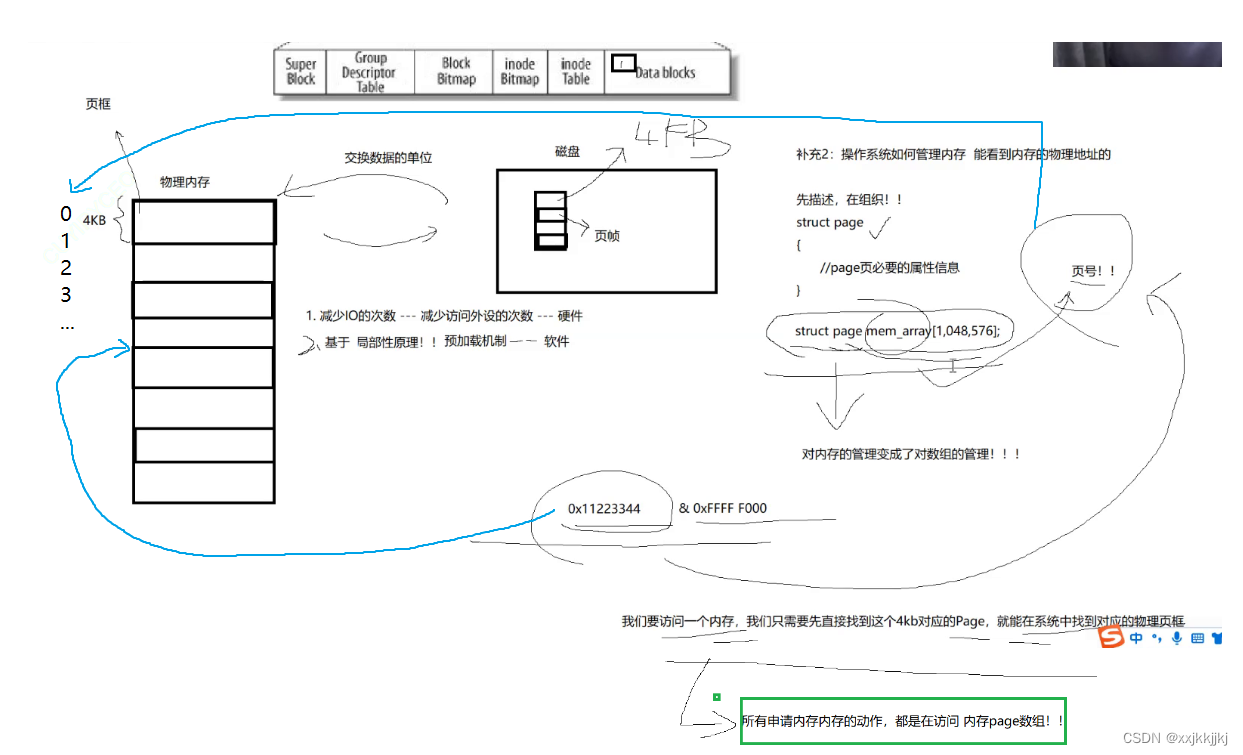
操作系统必须能看到内存的物理地址
操作系统如何管理内存呢?
内存已经是一个一个4KB大小,非常多
我怎么知道哪些4KB被用到了,那些没被用
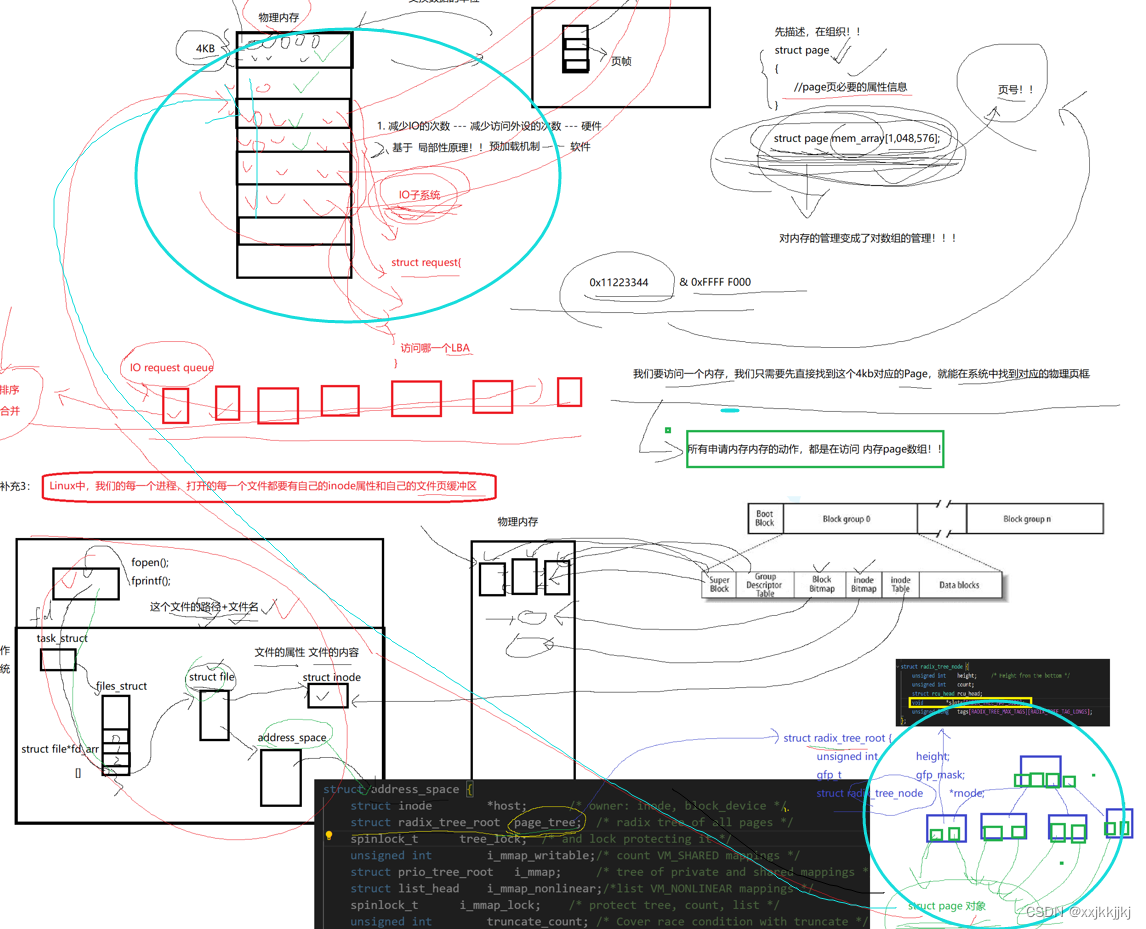
先描述,在组织!
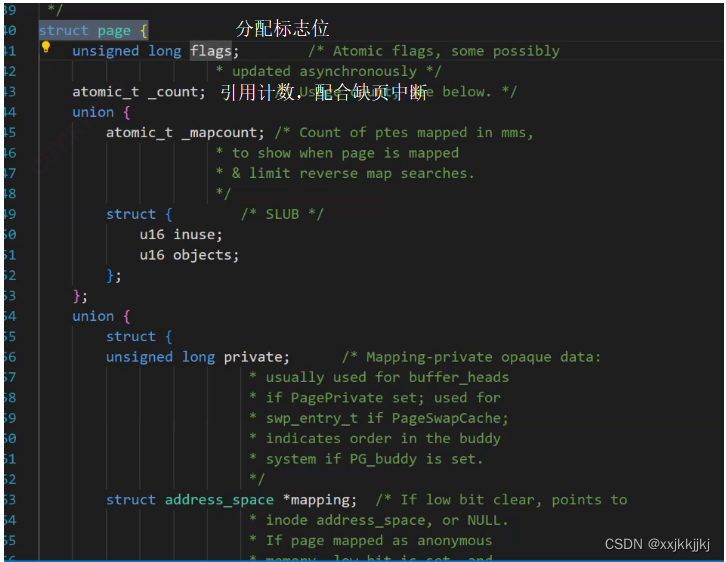
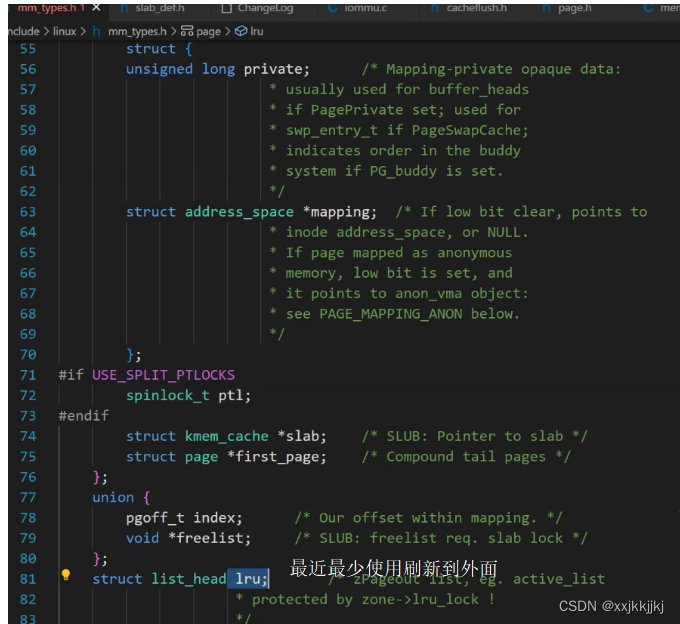
struct page
{
//page页必要的属性信息
}
描述其中一个4KB
物理内存4G B 就有100多万的页

struct page mem_array[1048576];
对内存的管理变成了对数组的管理!!
数组天然是有下标的,所以每一个page天然有了页号的概念
如果此时任意一个地址0x11223344 & 0xFFFF F000,相当于求的是这个页的4KB对齐的起始地址
有了这个任意页的地址,应该就能通过找到对应的page数组对应的下标(我猜就是页地址也就是&完的地址减去第一个Page地址然后除以4就能得到下标)(都拿到地址了还有啥找不到的),进行物理内存管理
结论:
所有申请内存的动作,都是在访问内存page数组,都是对这个数组增删查改
struct page mem_array[1048576] 一定像链表一样有对应的数据结构方法,调算法申请内存
补充3:Linux中,我们的每一个进程、打开的每一个文件都要有自己的inode属性和自己的文件页缓冲区(内核缓冲区)
在开机时,把文件系统中的管理属性已经预加载到内存中了,尤其是super block GDT等文件系统方面的信息
比如这个分区上面就是操作系统文件,都要读,所以OS提前预加载到内存中
每个分区可能用的不同文件系统,OS中存在把所有的super block用双链表链接起来,OS知道每个分区大概在哪,每个分区文件系统什么样
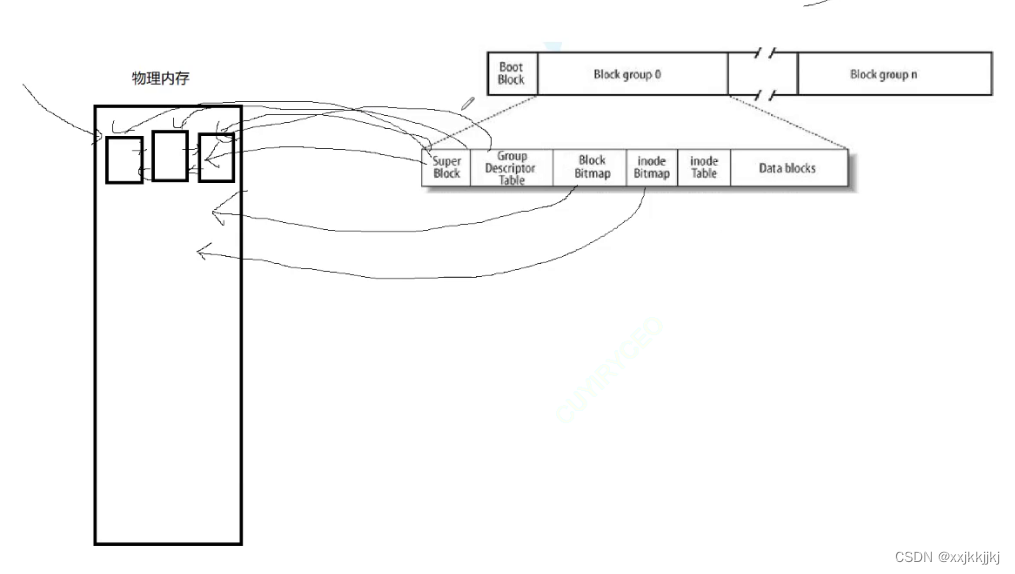
关于打开一个文件时,OS要做什么工作,理解内核文件级缓冲区概念
打开一个文件时,struct file只保存了少数的文件属性,OS要为struct file构建一个数据结构struct inode才会保存文件的大部分属性,当打开文件时,根据对应目录中的数据块文件名映射找到inode编号,在已经预加载到物理内存中 的inode bitmap确认文件存在,然后在inode table 把对应的inode属性填入struct inode里
struct file 通过指针要能找到对应的struct inode,文件属性也就有了
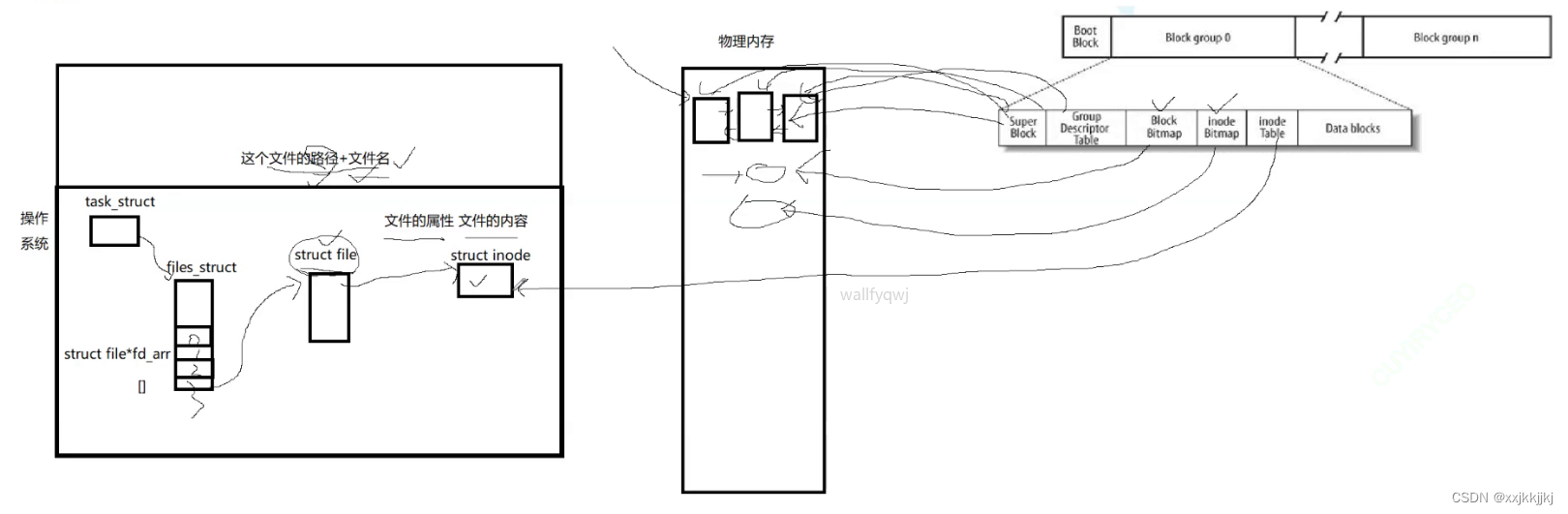
内核中的struct file 与struct inode指针
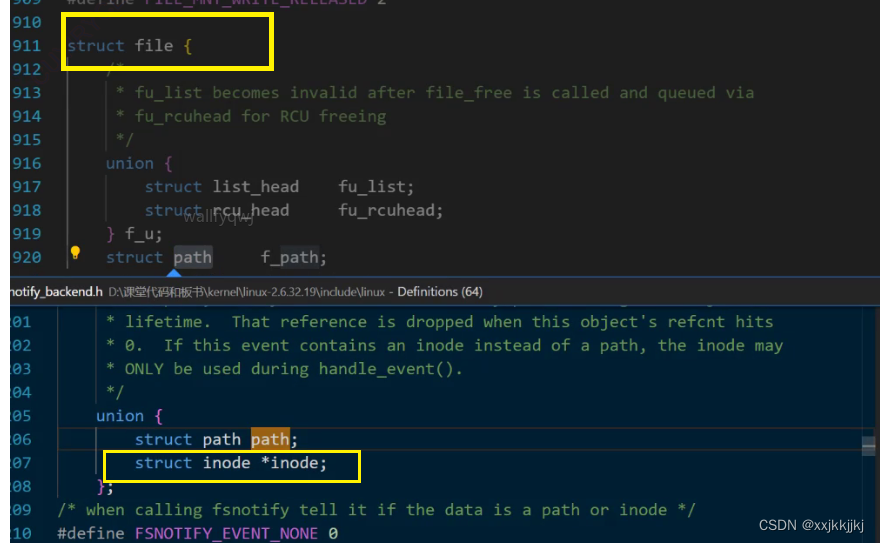
文件属性其实不难找,文件内容呢?
C语言提供缓冲区,通过fprintf把数据写到缓冲区,通过fd我这个进程找到对应文件struct file
最终又怎么把数据写到对应磁盘上呢?
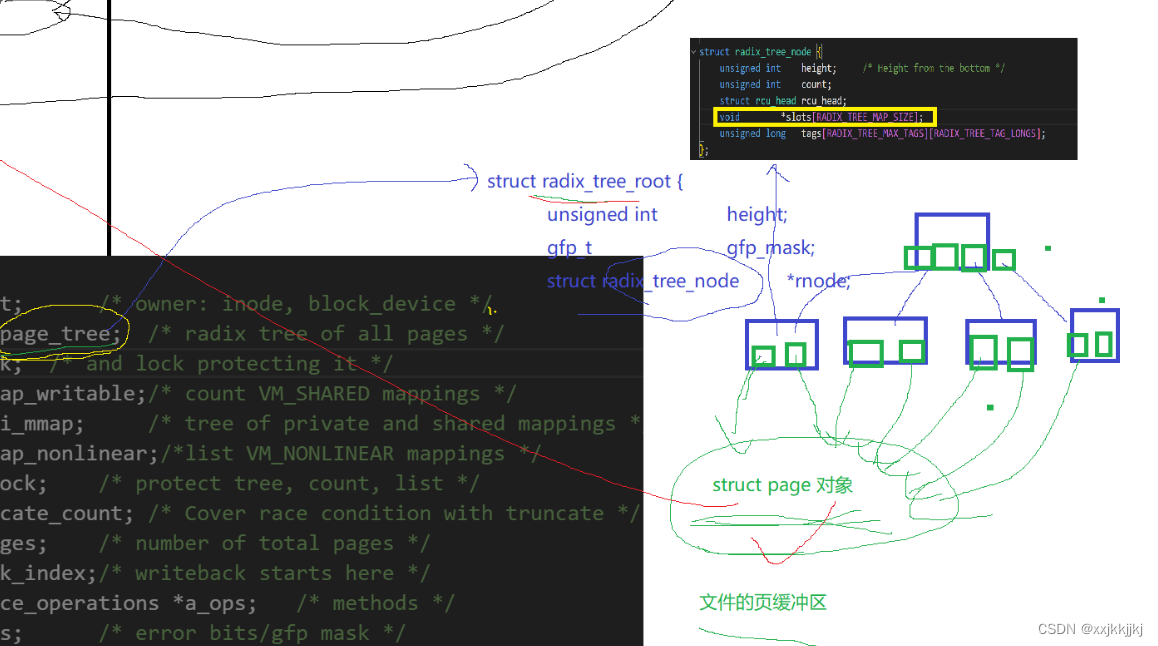
struct file中存在 address_space结构指针,这个结构包含一颗树page_tree,可以想象成一颗多叉树,树的节点中保存了指针数组,在叶子节点中保存了一个一个的struct page对象,而一个struct page对应物理内存4KB大小页框,所以应用层数据按照顺序从用户级缓冲区-> fd -> struct file -> address_space -> page_tree->叶子结点中的struct page然后再往物理内存中4KB中写入,就写到物理内存中了
我们看待物理内存时,只要找到对应的page,就能把数据写到物理内存里了
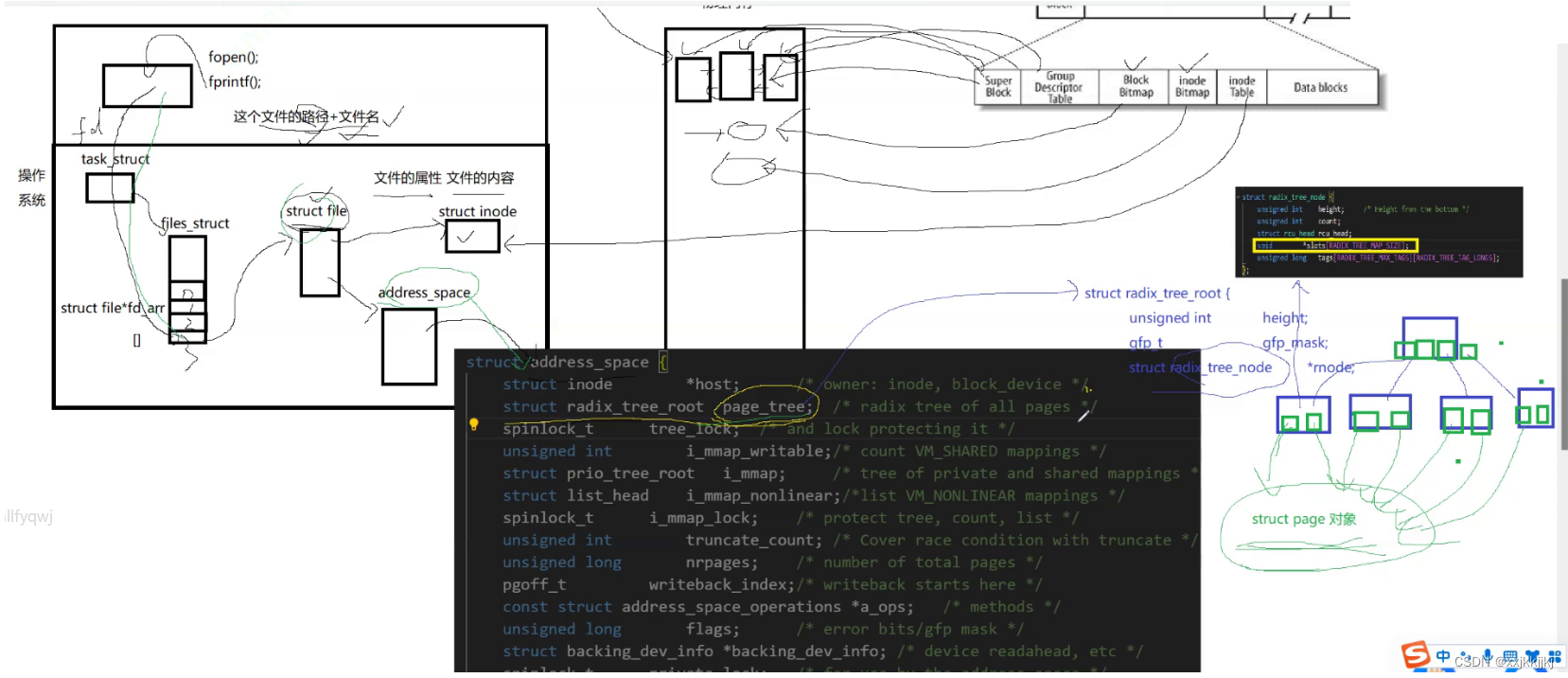
这颗树就叫文件的页缓冲区,此时我们把数据从应用层写到了由page管理的一个个内存中
补充4:
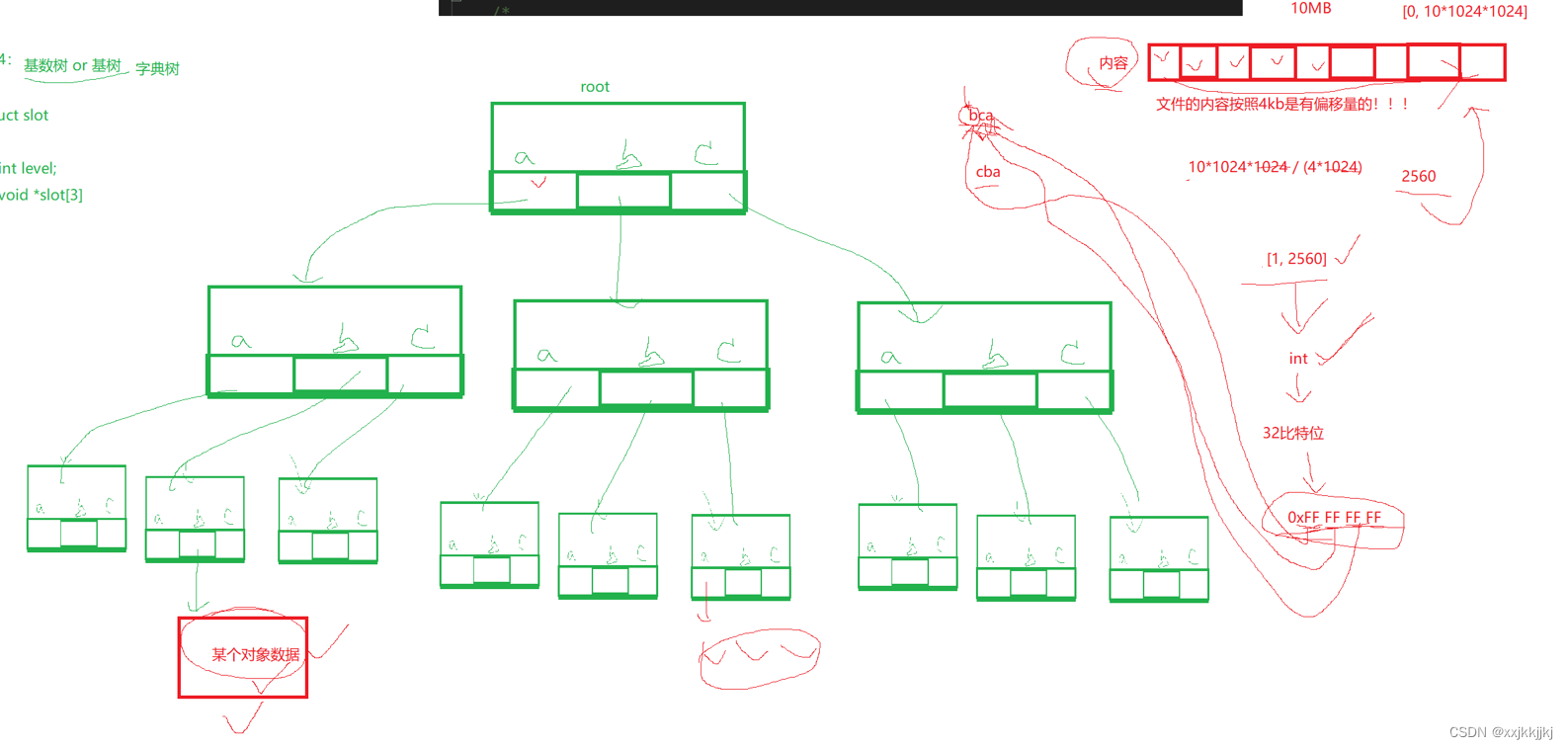
你说这玩意是个树,那是个什么树呢?
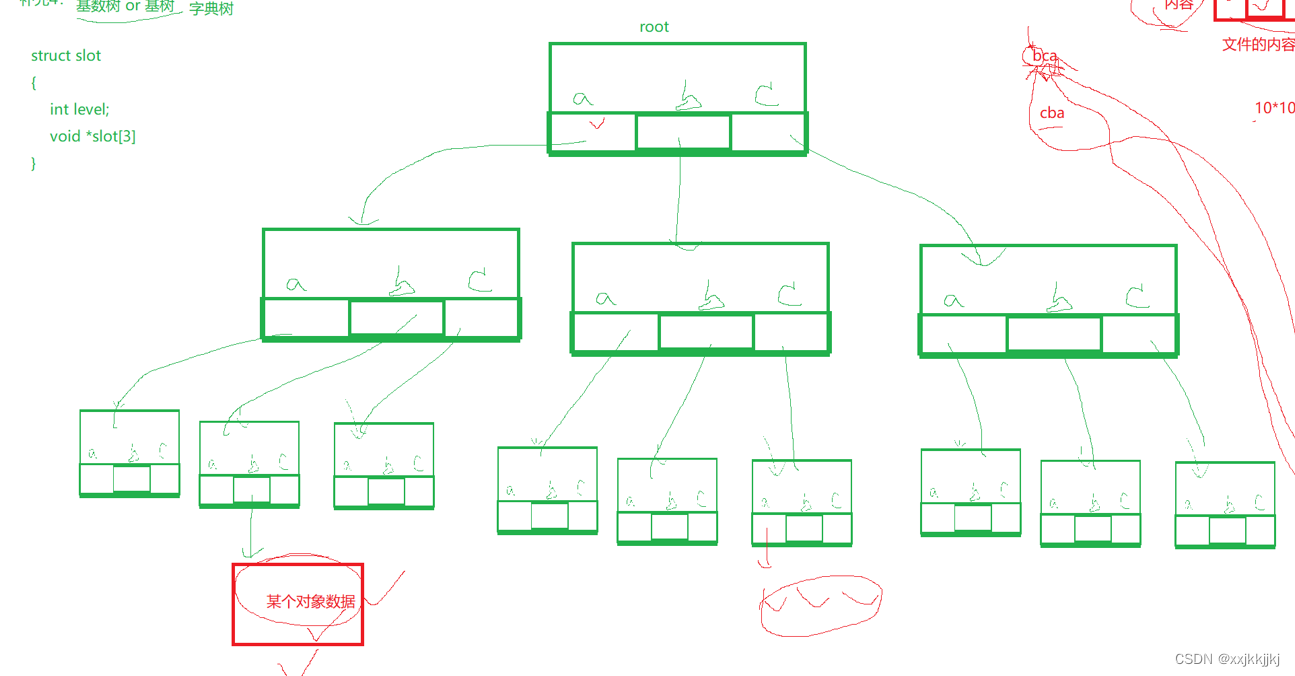
基数树 or 基树 本质是 字典树
数组有3个,那么这颗树就干上3层
void* slot[3]数组下标是数字,当我把他当成字母
每个数组又指向一个节点,就形成了这么一棵树
如果key是bca ,那么按照key的顺序就从根节点从上往下找
各种三个字母的组合就能根据这颗树找到某个底层叶子对象了
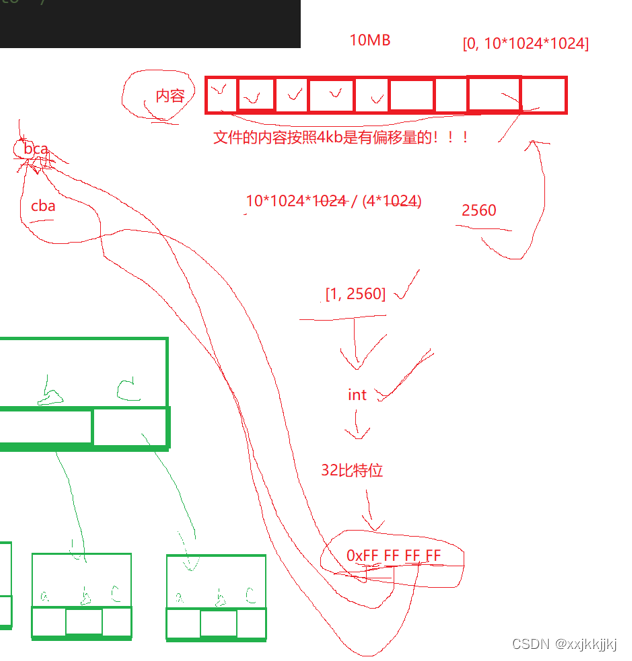
文件的内容是有偏移量的
假设文件大小10MB,也就是10x1024x1024字节
按照[0,1010241024]字节范围空间来看待
按照4KB来划分成一个一个的块
一共有多少个块呢?
1010241024/4*1024 = 2560个块
也就是说整个文件在磁盘上占2560个数据块
磁盘中每个块也就有了编号,从【1,2560】
每个数字乘以4096就是编号对应4KB在原始文件中的偏移量
所以把【1,2560】的编号按照Int来看待,有32bit位
假设0xFF FF FF FF 每八个bit看做一个字母Key = b,c ,a…
如果我们构建出这样的字典树,我们就可以拿着文件内容把文件内容的偏移量按照比特位分成特定的几个区域,八个bit为看成第一个字母b,后面依次类推,然后对应的字典树中就能找到整个文件中的偏移量和内存中page的映射关系
拿着文件的内容偏移量和内存的page建立映射关系,当我进行读写文件时,从开头读,结尾读,读写哪里,每一个读写都有偏移量,有偏移量找这颗树中偏移量对应的内存中某一个page,这样就能把数据保存到page里
其实最终想说的是文件写入把用户缓冲区的数据通过内核数据结构找到对应的Page对象把数据刷新到物理内存中了
接下来的工作就是OS要定期把数据刷到文件系统data blocks里面
此时数据已经写在物理内存中了,树里面的struct page就可以对应到物理内存中的page了
写完进程还管不管心数据刷到磁盘这个过程呢?
他就不关心了
所以这个数据刷新不刷新完全由OS决定,从这开始就往驱动层面走了
总结:
1、一个磁盘对应的文件它在访问之前部分对应文件系统中的属性已经加载内存了
2、进程打开文件时,本质就是把磁盘中的属性往struct inode 放
内容blocks通过struct file也能找到,以page的形式保存好
3、用户层写入时,通过fd-》 struct file-》 address-》 找到管理基树 找到物理内存中对应的page
然后把数据刷新到对应page页里,最后由OS调用IO子系统,把数据通过IO队列刷新到硬件上