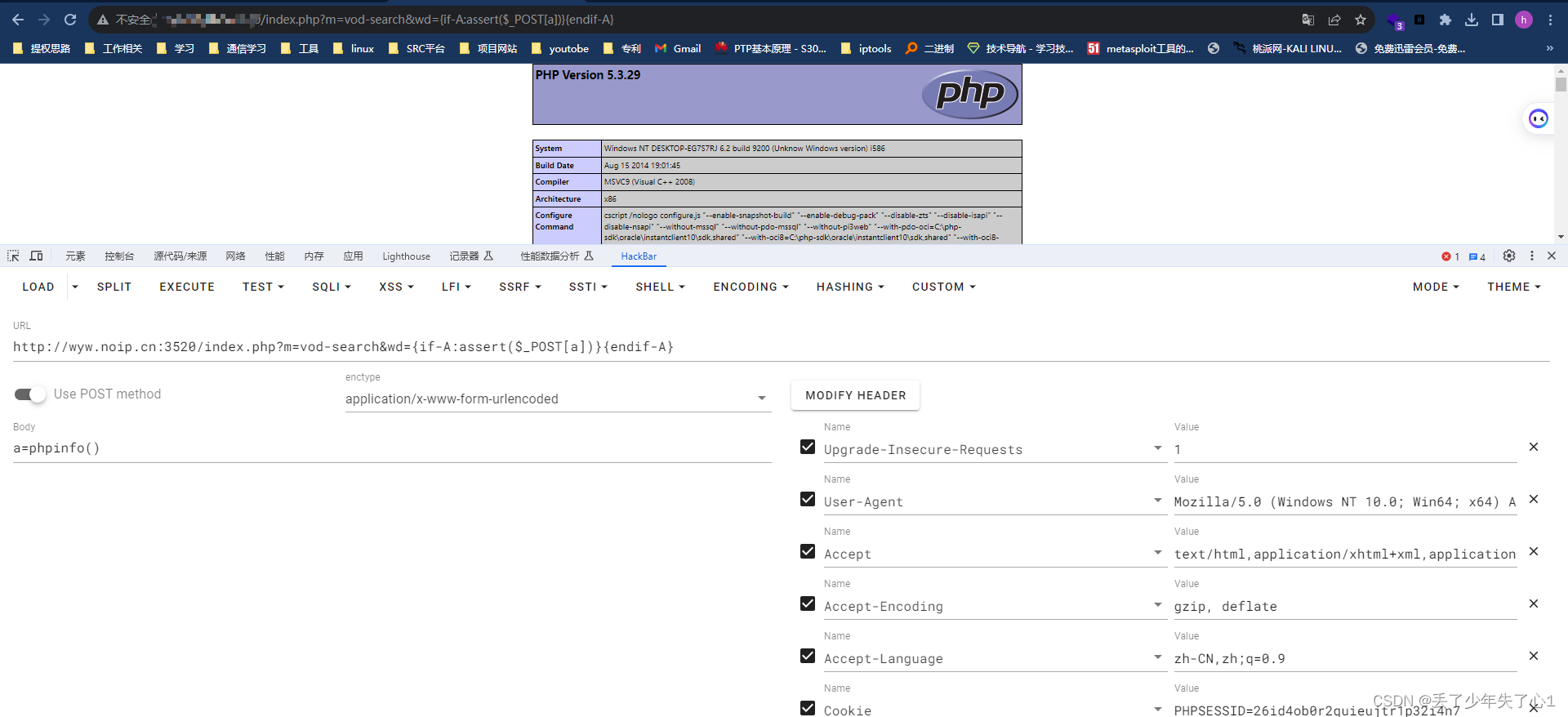
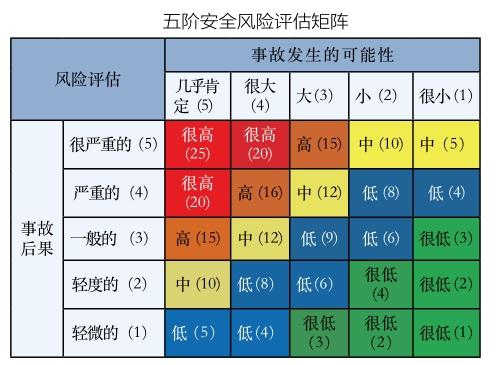
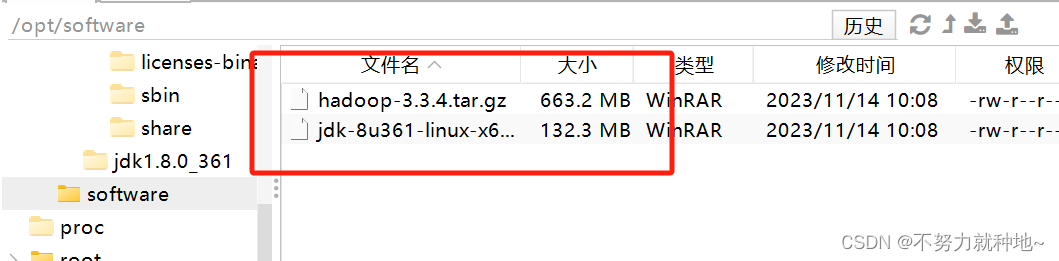
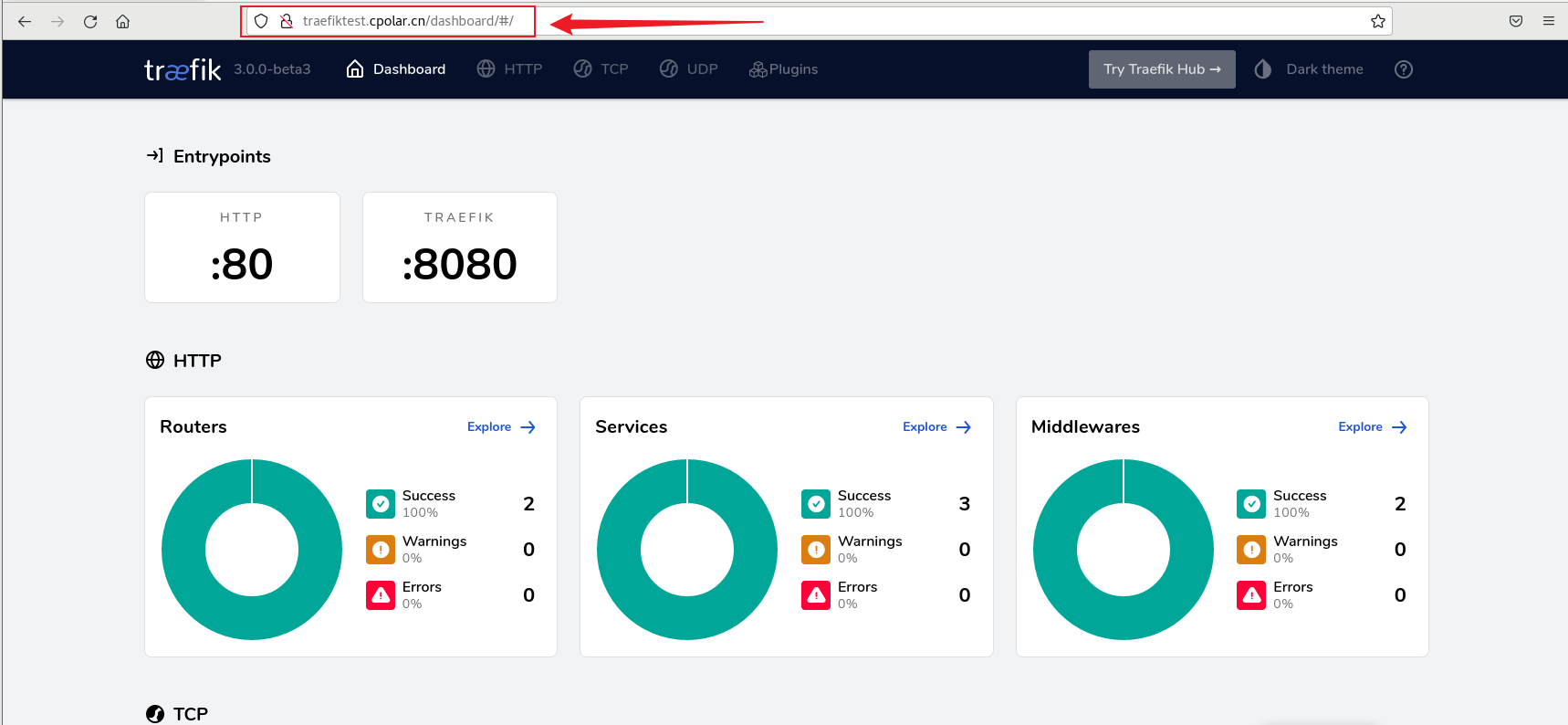
Scikit-Learn 以其提供的多个经过验证的聚类算法而著称。尽管如此,其中大多数都是参数化的,并需要设置集群的数量,这是聚类中最大的挑战之一。
通常,使用迭代方法来决定数据的最佳聚类数量,这意味着你需要多次进行聚类,每次使用不同数量的聚类,并评估相应的结果。尽管这种技术是有用的,但它确实存在一些局限性。
无论使用的是哪一种软件包,数据集大小都会带来另一个问题。在处理大型数据集时,资源消耗问题可能妨碍你有效地在广泛的集群范围内进行迭代。如果是这种情况,考虑探索诸如 MiniBatchKMeans 之类的技术,它可以进行并行聚类。
今天我跟大家介绍一个 kscorer 包,该包简化了这些技术,提供了一种更强大和有效的确定最佳聚类数量的方法。该包具备如下技术:
-
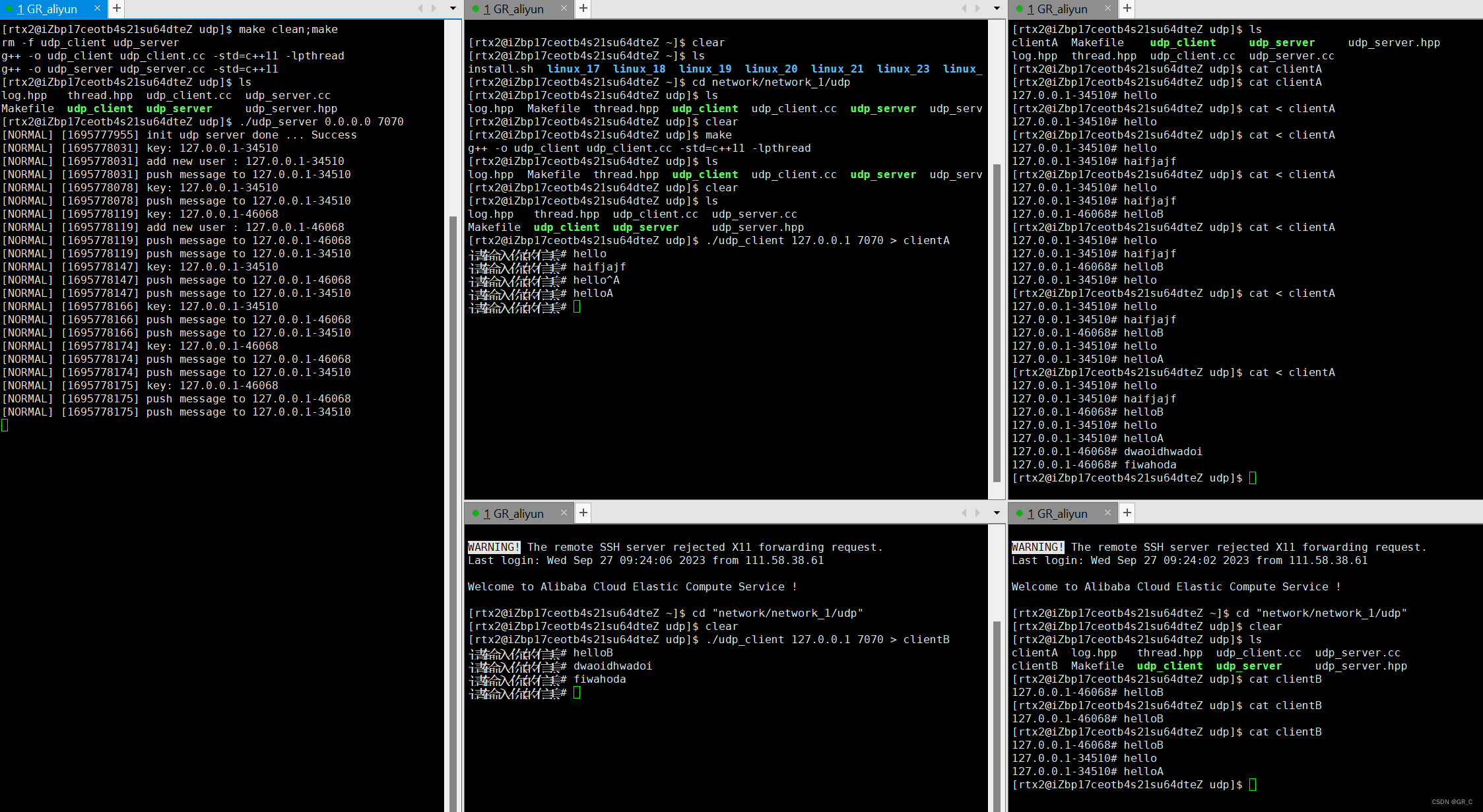
降维: 在应用聚类算法之前对数据进行主成分分析(PCA)可能是有益的。这将减少数据干扰,从而导致更可靠的聚类过程。
-
余弦相似度: 通过对数据应用欧几里得归一化,可以简单地(近似)在K均值中使用余弦距离。这样,您无需预先计算距离矩阵,就可以执行凝聚聚类等操作。
-
多度量: 为了找到最佳聚类数量,应依赖多度量评估,而不是依赖单个度量。
-
数据抽样: 为了解决资源消耗问题并改善聚类结果,可以从数据中获取随机样本进行聚类操作和评估度量。从多次迭代中平均分数可以减小随机性的影响,产生更一致的结果。
技术交流
技术要学会分享、交流,不建议闭门造车。一个人可以走的很快、一堆人可以走的更远。
本文由粉丝群小伙伴总结与分享,如果你也想学习交流,资料获取,均可加交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、添加微信号:dkl88194,备注:来自CSDN + 加群
方式②、微信搜索公众号:Python学习与数据挖掘,后台回复:加群
下图展示了这个工作流程。
幸运的是,现在无需从头构建整个流程,因为 kscorer 包中已经提供了实现。
此外,kscorer 包提供了一套全面的指标来评估聚类的质量,这些指标为我们提供了有关已识别的簇之间分离程度的宝贵见解:
-
轮廓系数: 通过计算数据点到不属于其最近簇的平均距离与每个数据点的平均簇内距离之间的差异,它量化了簇的分离程度。结果经过标准化,并表示为两者之间的比率,较高的值表示更好的簇分离。
-
Calinski-Harabasz指数: 它计算了簇间散布与簇内散布之比。Calinski-Harabasz测试的较高分数表示更好的聚类性能,表明定义良好的簇。
-
Davies-Bouldin指数: 它测量了簇间离散度与簇内离散度之比,较低的值表示更好的聚类性能和更明显的簇。
-
Dunn指数:它通过比较簇间距离(任意两个簇中心之间的最小距离)与簇内距离(簇中任意两点之间的最大距离)来评估簇的质量。较高的Dunn指数表示更明确的簇。
使用 kscorer 亲身体验
我们有一些用于聚类的数据。在这种情况下,我们假装不知道确切的簇数。
import numpy as np
import pandas as pd
from sklearn import datasets
from sklearn.preprocessing import normalize
from sklearn.metrics import balanced_accuracy_score
from sklearn.model_selection import train_test_split
from kscorer.kscorer import KScorer
from prosphera.projector import ProjectorX, y = datasets.load_digits(return_X_y=True)
X.shape
接下来,我们将将数据集分为训练集和测试集,并拟合一个模型来检测最优簇数。该模型将自动在3到15之间搜索最优簇数,可以轻松实现如下:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.15, random_state=1234)
ks = KScorer()
labels, centroids, _ = ks.fit_predict(X_train, retall=True)
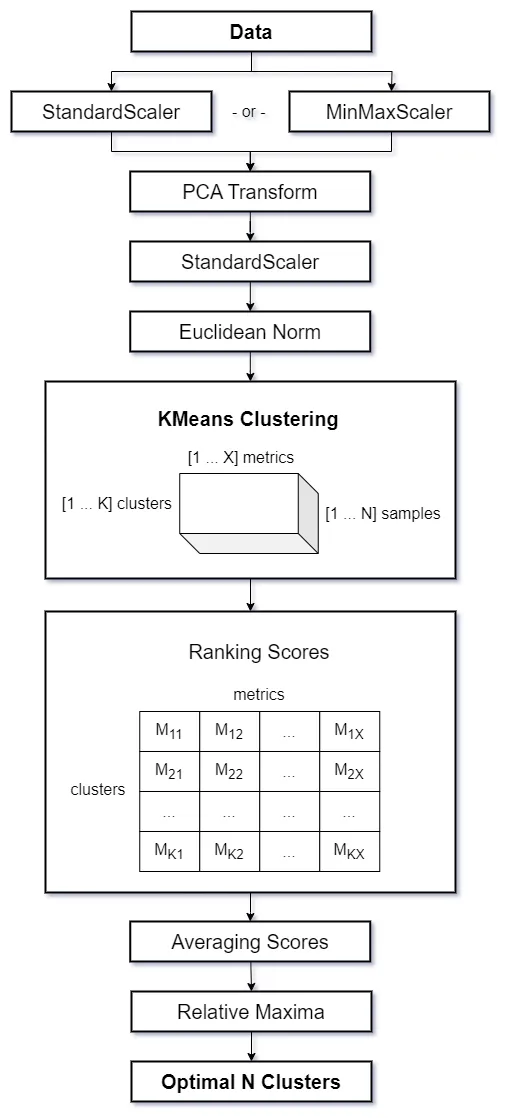
在完成拟合过程后,我们可以查看所有应用指标的标准化分数,这将帮助我们确定我们的可用数据的最佳簇数。
在检查图表时,您会注意到一些簇以相应的分数突出显示,这些带有标签的点对应于所有指标中平均分数的局部最大值,因此代表选择最佳簇数的最佳选项。
ks.show()
现在,我们可以评估我们的新簇标签与真实标签的匹配程度。请确保在实际业务场景中通常无法使用此选项 😉
labels_mtx = (pd.Series(y_train).groupby([labels, y_train]).count().unstack().fillna(0))# match arbitrary labels to ground-truth labels
order = []for i, r in labels_mtx.iterrows():try:left = [x for x in np.unique(y) if x not in order]order.append(r.iloc[left].idxmax())except ValueError:breakconfusion_mtx = labels_mtx[order]
confusion_mtx
在聚类中,尝试对之前未见过的数据进行聚类是一种不同寻常的做法。但请注意,这不是典型的聚类任务。一个不同且通常更有用的策略是使用簇标签创建一个分类器,将簇标签用作目标。这样可以更容易地为新数据分配簇标签。
# to make vectors precisely normalized
centroids = normalize(centroids)
labels_unseen = ks.predict(X_test, init=centroids)y_clustd = pd.Series(labels).replace(dict(enumerate(order)))
y_unseen = pd.Series(labels_unseen).replace(dict(enumerate(order)))balanced_accuracy_score(y_train, y_clustd)
balanced_accuracy_score(y_test, y_unseen)
最后,对我们的数据进行新鲜的交互式视角。
visualizer = Projector(renderer='colab')visualizer.project(data=X_train,labels=y_clustd,meta=y_train)
因此,通过使用 kscorer 包,我们深入了解了K均值聚类,该包简化了寻找最佳聚类数量的过程。由于其复杂的指标和并行处理,它已被证明是数据分析的实用工具。

![[Linux] ssh远程访问及控制](https://img-blog.csdnimg.cn/4a2e4ebfc4ce4f4691698fcd442a9f75.png)