Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例
14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性
15、Flink 的table api与sql之流式概念-详解的介绍了动态表、时间属性配置(如何处理更新结果)、时态表、流上的join、流上的确定性以及查询配置
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及FileSystem示例(1)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Elasticsearch示例(2)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Kafka示例(3)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及JDBC示例(4)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Hive示例(6)
17、Flink 之Table API: Table API 支持的操作(1)
17、Flink 之Table API: Table API 支持的操作(2)
18、Flink的SQL 支持的操作和语法
19、Flink 的Table API 和 SQL 中的内置函数及示例(1)
19、Flink 的Table API 和 SQL 中的自定义函数及示例(2)
19、Flink 的Table API 和 SQL 中的自定义函数及示例(3)
19、Flink 的Table API 和 SQL 中的自定义函数及示例(4)
20、Flink SQL之SQL Client: 不用编写代码就可以尝试 Flink SQL,可以直接提交 SQL 任务到集群上
21、Flink 的table API与DataStream API 集成(1)- 介绍及入门示例、集成说明
21、Flink 的table API与DataStream API 集成(2)- 批处理模式和inser-only流处理
21、Flink 的table API与DataStream API 集成(3)- changelog流处理、管道示例、类型转换和老版本转换示例
21、Flink 的table API与DataStream API 集成(完整版)
22、Flink 的table api与sql之创建表的DDL
24、Flink 的table api与sql之Catalogs(介绍、类型、java api和sql实现ddl、java api和sql操作catalog)-1
24、Flink 的table api与sql之Catalogs(java api操作数据库、表)-2
24、Flink 的table api与sql之Catalogs(java api操作视图)-3
24、Flink 的table api与sql之Catalogs(java api操作分区与函数)-4
25、Flink 的table api与sql之函数(自定义函数示例)
26、Flink 的SQL之概览与入门示例
27、Flink 的SQL之SELECT (select、where、distinct、order by、limit、集合操作和去重)介绍及详细示例(1)
27、Flink 的SQL之SELECT (SQL Hints 和 Joins)介绍及详细示例(2)
27、Flink 的SQL之SELECT (窗口函数)介绍及详细示例(3)
27、Flink 的SQL之SELECT (窗口聚合)介绍及详细示例(4)
27、Flink 的SQL之SELECT (Group Aggregation分组聚合、Over Aggregation Over聚合 和 Window Join 窗口关联)介绍及详细示例(5)
27、Flink 的SQL之SELECT (Top-N、Window Top-N 窗口 Top-N 和 Window Deduplication 窗口去重)介绍及详细示例(6)
27、Flink 的SQL之SELECT (Pattern Recognition 模式检测)介绍及详细示例(7)
28、Flink 的SQL之DROP 、ALTER 、INSERT 、ANALYZE 语句
29、Flink SQL之DESCRIBE、EXPLAIN、USE、SHOW、LOAD、UNLOAD、SET、RESET、JAR、JOB Statements、UPDATE、DELETE(1)
29、Flink SQL之DESCRIBE、EXPLAIN、USE、SHOW、LOAD、UNLOAD、SET、RESET、JAR、JOB Statements、UPDATE、DELETE(2)
30、Flink SQL之SQL 客户端(通过kafka和filesystem的例子介绍了配置文件使用-表、视图等)
32、Flink table api和SQL 之用户自定义 Sources & Sinks实现及详细示例
33、Flink 的Table API 和 SQL 中的时区
35、Flink 的 Formats 之CSV 和 JSON Format
36、Flink 的 Formats 之Parquet 和 Orc Format
41、Flink之Hive 方言介绍及详细示例
42、Flink 的table api与sql之Hive Catalog
43、Flink之Hive 读写及详细验证示例
44、Flink之module模块介绍及使用示例和Flink SQL使用hive内置函数及自定义函数详细示例–网上有些说法好像是错误的
文章目录
- Flink 系列文章
- 一、Orc Format
- 1、maven 依赖
- 2、Flink sql client 建表示例
- 1)、增加ORC文件解析的类库
- 2)、生成ORC文件
- 3)、建表
- 4)、验证
- 3、table api建表示例
- 1)、源码
- 2)、运行结果
- 3)、maven依赖
- 4、Format 参数
- 5、数据类型映射
- 二、Parquet Format
- 1、maven 依赖
- 2、Flink sql client 建表示例
- 1)、增加parquet文件解析类库
- 2)、生成parquet文件
- 3)、建表
- 4)、验证
- 3、table api建表示例
- 1)、源码
- 2)、运行结果
- 3)、maven依赖
- 4、Format 参数
- 5、数据类型映射
本文介绍了Flink 支持的数据格式中的ORC和Parquet,并分别以sql和table api作为示例进行了说明。
本文依赖flink、kafka、hadoop(3.1.4版本)集群能正常使用。
本文分为2个部分,即ORC和Parquet Format。
本文的示例是在Flink 1.17版本(flink 集群和maven均是Flink 1.17)中运行。
一、Orc Format
Apache Orc Format 允许读写 ORC 数据。
1、maven 依赖
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-orc</artifactId><version>1.17.1</version>
</dependency>下面的依赖视情况而定,有些可能会出现guava的冲突,如果出现冲突可能需要把下面的maven依赖。
<dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>32.0.1-jre</version></dependency>
2、Flink sql client 建表示例
下面是一个用 Filesystem connector 和 Orc format 创建表格的例子
1)、增加ORC文件解析的类库
需要将flink-sql-orc-1.17.1.jar 放在 flink的lib目录下,并重启flink服务。
该文件可以在链接中下载。
2)、生成ORC文件
该步骤需要借助于原hadoop生成的文件,可以参考文章:21、MapReduce读写SequenceFile、MapFile、ORCFile和ParquetFile文件
测试数据文件可以自己准备,不再赘述。
特别需要说明的是ORC文件的SCHEMA 需要和建表的字段名称和类型保持一致。
struct<id:string,type:string,orderID:string,bankCard:string,ctime:string,utime:string>
源码
import java.io.IOException;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.apache.orc.OrcConf;
import org.apache.orc.TypeDescription;
import org.apache.orc.mapred.OrcStruct;
import org.apache.orc.mapreduce.OrcOutputFormat;/*** @author alanchan* 读取普通文本文件转换为ORC文件*/
public class WriteOrcFile extends Configured implements Tool {static String in = "D:/workspace/bigdata-component/hadoop/test/in/orc";static String out = "D:/workspace/bigdata-component/hadoop/test/out/orc";public static void main(String[] args) throws Exception {Configuration conf = new Configuration();int status = ToolRunner.run(conf, new WriteOrcFile(), args);System.exit(status);}@Overridepublic int run(String[] args) throws Exception {// 设置SchemaOrcConf.MAPRED_OUTPUT_SCHEMA.setString(this.getConf(), SCHEMA);Job job = Job.getInstance(getConf(), this.getClass().getName());job.setJarByClass(this.getClass());job.setMapperClass(WriteOrcFileMapper.class);job.setMapOutputKeyClass(NullWritable.class);job.setMapOutputValueClass(OrcStruct.class);job.setNumReduceTasks(0);// 配置作业的输入数据路径FileInputFormat.addInputPath(job, new Path(in));// 设置作业的输出为MapFileOutputFormatjob.setOutputFormatClass(OrcOutputFormat.class);Path outputDir = new Path(out);outputDir.getFileSystem(this.getConf()).delete(outputDir, true);FileOutputFormat.setOutputPath(job, outputDir);return job.waitForCompletion(true) ? 0 : 1;}// 定义数据的字段信息
//数据格式
// id ,type ,orderID ,bankCard,ctime ,utime
// 2.0191130220014E+27,ALIPAY,191130-461197476510745,356886,,
// 2.01911302200141E+27,ALIPAY,191130-570038354832903,404118,2019/11/30 21:44,2019/12/16 14:24
// 2.01911302200143E+27,ALIPAY,191130-581296620431058,520083,2019/11/30 18:17,2019/12/4 20:26
// 2.0191201220014E+27,ALIPAY,191201-311567320052455,622688,2019/12/1 10:56,2019/12/16 11:54private static final String SCHEMA = "struct<id:string,type:string,orderID:string,bankCard:string,ctime:string,utime:string>";static class WriteOrcFileMapper extends Mapper<LongWritable, Text, NullWritable, OrcStruct> {// 获取字段描述信息private TypeDescription schema = TypeDescription.fromString(SCHEMA);// 构建输出的Keyprivate final NullWritable outputKey = NullWritable.get();// 构建输出的Value为ORCStruct类型private final OrcStruct outputValue = (OrcStruct) OrcStruct.createValue(schema);protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {// 将读取到的每一行数据进行分割,得到所有字段String[] fields = value.toString().split(",", 6);// 将所有字段赋值给Value中的列outputValue.setFieldValue(0, new Text(fields[0]));outputValue.setFieldValue(1, new Text(fields[1]));outputValue.setFieldValue(2, new Text(fields[2]));outputValue.setFieldValue(3, new Text(fields[3]));outputValue.setFieldValue(4, new Text(fields[4]));outputValue.setFieldValue(5, new Text(fields[5]));context.write(outputKey, outputValue);}}}
将生成的文件上传至hdfs://server1:8020/flinktest/orctest/下。
至此,准备环境与数据已经完成。
3)、建表
需要注意的是字段的名称与类型,需要和orc文件的schema保持一致,否则读取不到文件内容。
CREATE TABLE alan_orc_order (id STRING,type STRING,orderID STRING,bankCard STRING,ctime STRING,utime STRING
) WITH ('connector' = 'filesystem','path' = 'hdfs://server1:8020/flinktest/orctest/','format' = 'orc'
);Flink SQL> CREATE TABLE alan_orc_order (
> id STRING,
> type STRING,
> orderID STRING,
> bankCard STRING,
> ctime STRING,
> utime STRING
> ) WITH (
> 'connector' = 'filesystem',
> 'path' = 'hdfs://server1:8020/flinktest/orctest/',
> 'format' = 'orc'
> );
[INFO] Execute statement succeed.
4)、验证
Flink SQL> select * from alan_orc_order limit 10;
+----+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+
| op | id | type | orderID | bankCard | ctime | utime |
+----+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+
| +I | 2.0191130220014E+27 | ALIPAY | 191130-461197476510745 | 356886 | | |
| +I | 2.01911302200141E+27 | ALIPAY | 191130-570038354832903 | 404118 | 2019/11/30 21:44 | 2019/12/16 14:24 |
| +I | 2.01911302200143E+27 | ALIPAY | 191130-581296620431058 | 520083 | 2019/11/30 18:17 | 2019/12/4 20:26 |
| +I | 2.0191201220014E+27 | ALIPAY | 191201-311567320052455 | 622688 | 2019/12/1 10:56 | 2019/12/16 11:54 |
| +I | 2.01912E+27 | ALIPAY | 191201-216073503850515 | 456418 | 2019/12/11 22:39 | |
| +I | 2.01912E+27 | ALIPAY | 191201-072274576332921 | 433668 | | |
| +I | 2.01912E+27 | ALIPAY | 191201-088486052970134 | 622538 | 2019/12/2 23:12 | |
| +I | 2.01912E+27 | ALIPAY | 191201-492457166050685 | 622517 | 2019/12/1 0:42 | 2019/12/14 13:27 |
| +I | 2.01912E+27 | ALIPAY | 191201-037136794432586 | 622525 | | |
| +I | 2.01912E+27 | ALIPAY | 191201-389779784790672 | 486494 | 2019/12/1 22:25 | 2019/12/16 23:32 |
+----+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+
Received a total of 10 rows3、table api建表示例
通过table api建表,参考文章:
17、Flink 之Table API: Table API 支持的操作(1)
17、Flink 之Table API: Table API 支持的操作(2)
为了简单起见,本示例仅仅是通过sql建表,数据准备见上述示例。
1)、源码
下面是在本地运行的,建表的path也是用本地的。
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;/*** @author alanchan**/
public class TestORCFormatDemo {static String sourceSql = "CREATE TABLE alan_orc_order (\r\n" + " id STRING,\r\n" + " type STRING,\r\n" + " orderID STRING,\r\n" + " bankCard STRING,\r\n" + " ctime STRING,\r\n" + " utime STRING\r\n" + ") WITH (\r\n" + " 'connector' = 'filesystem',\r\n" + " 'path' = 'D:/workspace/bigdata-component/hadoop/test/out/orc',\r\n" + " 'format' = 'orc'\r\n" + ")";public static void test1() throws Exception {// 1、创建运行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment tenv = StreamTableEnvironment.create(env);// 建表tenv.executeSql(sourceSql);Table table = tenv.from("alan_orc_order"); table.printSchema();tenv.createTemporaryView("alan_orc_order_v", table);tenv.executeSql("select * from alan_orc_order_v limit 10").print();;
// table.execute().print();env.execute();}public static void main(String[] args) throws Exception {test1();}}
2)、运行结果
(`id` STRING,`type` STRING,`orderid` STRING,`bankcard` STRING,`ctime` STRING,`utime` STRING
)+----+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+
| op | id | type | orderID | bankCard | ctime | utime |
+----+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+
| +I | 2.0191130220014E+27 | ALIPAY | 191130-461197476510745 | 356886 | | |
| +I | 2.01911302200141E+27 | ALIPAY | 191130-570038354832903 | 404118 | 2019/11/30 21:44 | 2019/12/16 14:24 |
| +I | 2.01911302200143E+27 | ALIPAY | 191130-581296620431058 | 520083 | 2019/11/30 18:17 | 2019/12/4 20:26 |
| +I | 2.0191201220014E+27 | ALIPAY | 191201-311567320052455 | 622688 | 2019/12/1 10:56 | 2019/12/16 11:54 |
| +I | 2.01912E+27 | ALIPAY | 191201-216073503850515 | 456418 | 2019/12/11 22:39 | |
| +I | 2.01912E+27 | ALIPAY | 191201-072274576332921 | 433668 | | |
| +I | 2.01912E+27 | ALIPAY | 191201-088486052970134 | 622538 | 2019/12/2 23:12 | |
| +I | 2.01912E+27 | ALIPAY | 191201-492457166050685 | 622517 | 2019/12/1 0:42 | 2019/12/14 13:27 |
| +I | 2.01912E+27 | ALIPAY | 191201-037136794432586 | 622525 | | |
| +I | 2.01912E+27 | ALIPAY | 191201-389779784790672 | 486494 | 2019/12/1 22:25 | 2019/12/16 23:32 |
+----+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+
10 rows in set
3)、maven依赖
<properties><encoding>UTF-8</encoding><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><maven.compiler.source>1.8</maven.compiler.source><maven.compiler.target>1.8</maven.compiler.target><java.version>1.8</java.version><scala.version>2.12</scala.version><flink.version>1.17.0</flink.version></properties><dependencies><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-common</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-java-bridge</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-sql-gateway --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-sql-gateway</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-csv</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-json</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table-planner --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner_2.12</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table-api-java-uber --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-java-uber</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table-runtime --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-runtime</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-jdbc</artifactId><version>3.1.0-1.17</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.38</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-hive --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-hive_2.12</artifactId><version>1.17.0</version></dependency><dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>32.0.1-jre</version></dependency> <!-- flink连接器 --><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-kafka --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId><version>${flink.version}</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-sql-connector-kafka --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-sql-connector-kafka</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><!-- https://mvnrepository.com/artifact/org.apache.commons/commons-compress --><dependency><groupId>org.apache.commons</groupId><artifactId>commons-compress</artifactId><version>1.24.0</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.2</version><!-- <scope>provided</scope> --></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-orc</artifactId><version>1.17.1</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>3.1.4</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.1.4</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>3.1.4</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-parquet</artifactId><version>1.17.1</version></dependency></dependencies>
4、Format 参数

Orc 格式也支持来源于 Table properties 的表属性。
举个例子,你可以设置 orc.compress=SNAPPY 来允许spappy压缩。
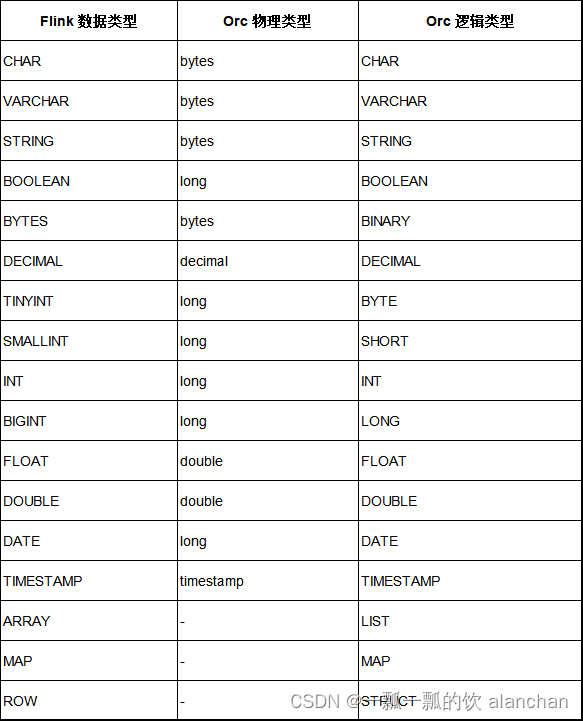
5、数据类型映射
Orc 格式类型的映射和 Apache Hive 是兼容的。
下面的表格列出了 Flink 类型的数据和 Orc 类型的数据的映射关系。
二、Parquet Format
Apache Parquet 格式允许读写 Parquet 数据.
1、maven 依赖
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-parquet</artifactId><version>1.17.1</version>
</dependency>2、Flink sql client 建表示例
以下为用 Filesystem 连接器和 Parquet 格式创建表的示例
1)、增加parquet文件解析类库
需要将flink-sql-parquet-1.17.1.jar 放在 flink的lib目录下,并重启flink服务。
该文件可以在链接中下载。
2)、生成parquet文件
该步骤需要借助于原hadoop生成的文件,可以参考文章:21、MapReduce读写SequenceFile、MapFile、ORCFile和ParquetFile文件
测试数据文件可以自己准备,不再赘述。
import java.io.IOException;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.apache.parquet.example.data.Group;
import org.apache.parquet.example.data.simple.SimpleGroupFactory;
import org.apache.parquet.hadoop.ParquetOutputFormat;
import org.apache.parquet.hadoop.example.GroupWriteSupport;
import org.apache.parquet.hadoop.metadata.CompressionCodecName;
import org.apache.parquet.schema.MessageType;
import org.apache.parquet.schema.OriginalType;
import org.apache.parquet.schema.PrimitiveType.PrimitiveTypeName;
import org.apache.parquet.schema.Types;
import org.springframework.util.StopWatch;/*** @author alanchan**/
public class WriteParquetFile extends Configured implements Tool {static String in = "D:/workspace/bigdata-component/hadoop/test/in/parquet";static String out = "D:/workspace/bigdata-component/hadoop/test/out/parquet";public static void main(String[] args) throws Exception {StopWatch clock = new StopWatch();clock.start(WriteParquetFile.class.getSimpleName());Configuration conf = new Configuration();int status = ToolRunner.run(conf, new WriteParquetFile(), args);System.exit(status);clock.stop();System.out.println(clock.prettyPrint());}@Overridepublic int run(String[] args) throws Exception {Configuration conf = getConf();// 此demo 输入数据为2列 city ip//输入文件格式:https://www.win.com/233434,8283140// https://www.win.com/242288,8283139MessageType schema = Types.buildMessage().required(PrimitiveTypeName.BINARY).as(OriginalType.UTF8).named("city").required(PrimitiveTypeName.BINARY).as(OriginalType.UTF8).named("ip").named("pair");System.out.println("[schema]==" + schema.toString());GroupWriteSupport.setSchema(schema, conf);Job job = Job.getInstance(conf, this.getClass().getName());job.setJarByClass(this.getClass());job.setMapperClass(WriteParquetFileMapper.class);job.setInputFormatClass(TextInputFormat.class);job.setMapOutputKeyClass(NullWritable.class);// 设置value是parquet的Groupjob.setMapOutputValueClass(Group.class);FileInputFormat.setInputPaths(job, in);// parquet输出job.setOutputFormatClass(ParquetOutputFormat.class);ParquetOutputFormat.setWriteSupportClass(job, GroupWriteSupport.class);Path outputDir = new Path(out);outputDir.getFileSystem(this.getConf()).delete(outputDir, true);FileOutputFormat.setOutputPath(job, new Path(out));ParquetOutputFormat.setOutputPath(job, new Path(out));
// ParquetOutputFormat.setCompression(job, CompressionCodecName.SNAPPY);job.setNumReduceTasks(0);return job.waitForCompletion(true) ? 0 : 1;}public static class WriteParquetFileMapper extends Mapper<LongWritable, Text, NullWritable, Group> {SimpleGroupFactory factory = null;protected void setup(Context context) throws IOException, InterruptedException {factory = new SimpleGroupFactory(GroupWriteSupport.getSchema(context.getConfiguration()));};public void map(LongWritable _key, Text ivalue, Context context) throws IOException, InterruptedException {Group pair = factory.newGroup();//截取输入文件的一行,且是以逗号进行分割String[] strs = ivalue.toString().split(",");pair.append("city", strs[0]);pair.append("ip", strs[1]);context.write(null, pair);}}
}
将生成的文件上传至hdfs://server1:8020/flinktest/parquettest/下。
3)、建表
需要注意的是字段的名称与类型,需要和parquet文件的schema保持一致,否则读取不到文件内容。
- schema
MessageType schema = Types.buildMessage()
.required(PrimitiveTypeName.BINARY).as(OriginalType.UTF8).named("city")
.required(PrimitiveTypeName.BINARY).as(OriginalType.UTF8).named("ip")
.named("pair");// 以下是schema的内容
[schema]==message pair {required binary city (UTF8);required binary ip (UTF8);
}- 建表
CREATE TABLE alan_parquet_cityinfo (city STRING,ip STRING
) WITH ('connector' = 'filesystem','path' = 'hdfs://server1:8020/flinktest/parquettest/','format' = 'parquet'
);Flink SQL> CREATE TABLE alan_parquet_cityinfo (
> city STRING,
> ip STRING
> ) WITH (
> 'connector' = 'filesystem',
> 'path' = 'hdfs://server1:8020/flinktest/parquettest/',
> 'format' = 'parquet'
> );
[INFO] Execute statement succeed.4)、验证
Flink SQL> select * from alan_parquet_cityinfo limit 10;
+----+--------------------------------+--------------------------------+
| op | city | ip |
+----+--------------------------------+--------------------------------+
| +I | https://www.win.com/237516 | 8284068 |
| +I | https://www.win.com/242247 | 8284067 |
| +I | https://www.win.com/243248 | 8284066 |
| +I | https://www.win.com/243288 | 8284065 |
| +I | https://www.win.com/240213 | 8284064 |
| +I | https://www.win.com/239907 | 8284063 |
| +I | https://www.win.com/235270 | 8284062 |
| +I | https://www.win.com/234366 | 8284061 |
| +I | https://www.win.com/229297 | 8284060 |
| +I | https://www.win.com/237757 | 8284059 |
+----+--------------------------------+--------------------------------+
Received a total of 10 rows3、table api建表示例
通过table api建表,参考文章:
17、Flink 之Table API: Table API 支持的操作(1)
17、Flink 之Table API: Table API 支持的操作(2)
为了简单起见,本示例仅仅是通过sql建表,数据准备见上述示例。
1)、源码
下面是在本地运行的,建表的path也是用本地的。
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;/*** @author alanchan**/
public class TestParquetFormatDemo {static String sourceSql = "CREATE TABLE alan_parquet_cityinfo (\r\n" + " city STRING,\r\n" + " ip STRING\r\n" + ") WITH (\r\n" + " 'connector' = 'filesystem',\r\n" + " 'path' = 'D:/workspace/bigdata-component/hadoop/test/out/parquet',\r\n" + " 'format' = 'parquet'\r\n" + ");";public static void test1() throws Exception {// 1、创建运行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment tenv = StreamTableEnvironment.create(env);// 建表tenv.executeSql(sourceSql);Table table = tenv.from("alan_parquet_cityinfo");table.printSchema();tenv.createTemporaryView("alan_parquet_cityinfo_v", table);tenv.executeSql("select * from alan_parquet_cityinfo_v limit 10").print();// table.execute().print();env.execute();}public static void main(String[] args) throws Exception {test1();}}
2)、运行结果
(`city` STRING,`ip` STRING
)+----+--------------------------------+--------------------------------+
| op | city | ip |
+----+--------------------------------+--------------------------------+
| +I | https://www.win.com/237516 | 8284068 |
| +I | https://www.win.com/242247 | 8284067 |
| +I | https://www.win.com/243248 | 8284066 |
| +I | https://www.win.com/243288 | 8284065 |
| +I | https://www.win.com/240213 | 8284064 |
| +I | https://www.win.com/239907 | 8284063 |
| +I | https://www.win.com/235270 | 8284062 |
| +I | https://www.win.com/234366 | 8284061 |
| +I | https://www.win.com/229297 | 8284060 |
| +I | https://www.win.com/237757 | 8284059 |
+----+--------------------------------+--------------------------------+
10 rows in set3)、maven依赖
<properties><encoding>UTF-8</encoding><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><maven.compiler.source>1.8</maven.compiler.source><maven.compiler.target>1.8</maven.compiler.target><java.version>1.8</java.version><scala.version>2.12</scala.version><flink.version>1.17.0</flink.version></properties><dependencies><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-common</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-java-bridge</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-sql-gateway --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-sql-gateway</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-csv</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-json</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table-planner --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner_2.12</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table-api-java-uber --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-java-uber</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table-runtime --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-runtime</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-jdbc</artifactId><version>3.1.0-1.17</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.38</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-hive --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-hive_2.12</artifactId><version>1.17.0</version></dependency><dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>32.0.1-jre</version></dependency> <!-- flink连接器 --><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-kafka --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId><version>${flink.version}</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-sql-connector-kafka --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-sql-connector-kafka</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><!-- https://mvnrepository.com/artifact/org.apache.commons/commons-compress --><dependency><groupId>org.apache.commons</groupId><artifactId>commons-compress</artifactId><version>1.24.0</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.2</version><!-- <scope>provided</scope> --></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-orc</artifactId><version>1.17.1</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>3.1.4</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.1.4</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>3.1.4</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-parquet</artifactId><version>1.17.1</version></dependency></dependencies>
4、Format 参数
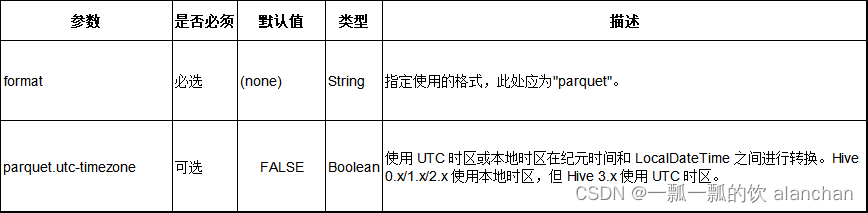
Parquet 格式也支持 ParquetOutputFormat 的配置。
例如, 可以配置 parquet.compression=GZIP 来开启 gzip 压缩。
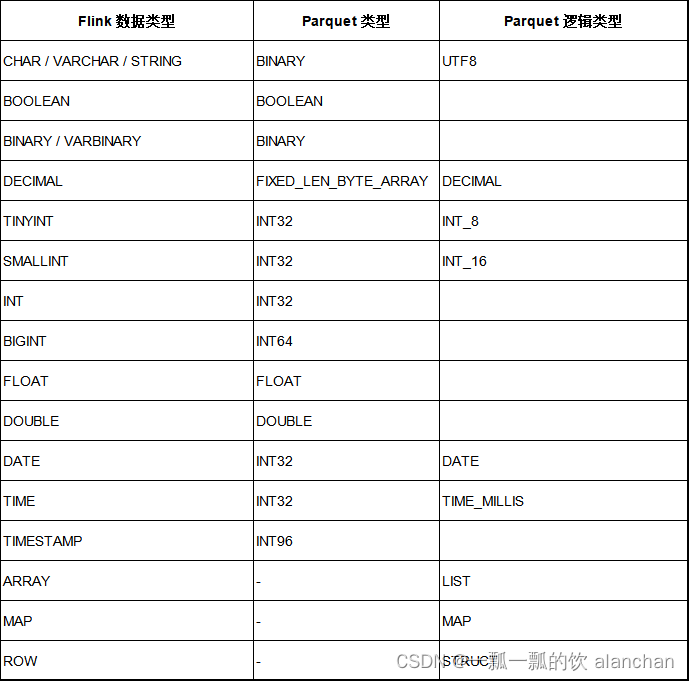
5、数据类型映射
截至Flink 1.17 版本 ,Parquet 格式类型映射与 Apache Hive 兼容,但与 Apache Spark 有所不同:
- Timestamp:不论精度,映射 timestamp 类型至 int96。
- Decimal:根据精度,映射 decimal 类型至固定长度字节的数组。
下表列举了 Flink 中的数据类型与 JSON 中的数据类型的映射关系。
以上,介绍了Flink 支持的数据格式中的ORC和Parquet,并分别以sql和table api作为示例进行了说明。
![DocCMS keyword SQL注入漏洞复现 [附POC]](https://img-blog.csdnimg.cn/3691cd38256d47f9afbb3dfaedfb1c97.png)