一、介绍
机器学习算法已在各个行业得到广泛采用,在自动化流程、制定数据驱动决策和提高效率方面发挥着关键作用。然而,他们也面临着挑战,其中一个重要的问题是偏见。机器学习模型中的偏差可能会导致不公平和歧视性的结果,并对现实世界产生影响。偏差的一个特别具有挑战性的方面是“偏差漂移”,即模型的行为随着时间的推移而变化。在本文中,我们将探讨偏差漂移的概念、其原因、后果以及缓解偏差的策略。
维护机器学习的公平性是一个持续的过程。偏见的漂移就像流沙一样提醒我们,保持警惕和持续适应对于维持人工智能领域的公正和公平至关重要。挑战不断出现,但通过正确的缓解策略,我们可以应对这些不断变化的形势,并确保技术仍然是一股向善的力量,尊重人类经验的多样性。
二、理解偏差漂移
当机器学习模型的性能随着时间的推移而下降时,就会出现偏差漂移,导致其预测偏差增加。与其他形式的模型漂移(例如概念漂移或数据漂移)不同,偏差漂移特别与不公平和歧视相关。偏差漂移的原因可能是多方面的,但它们通常源于数据分布的变化或社会规范的变化。
三、偏差漂移的原因
- 数据分布变化:偏差漂移的常见原因之一是用于训练和评估模型的数据分布的变化。随着时间的推移,收集或用于训练模型的数据可能不再代表现实世界的人口,从而导致差异。
- 社会规范和法规:不断变化的社会规范和法规可能会影响机器学习模型的公平性要求。由于不断变化的社会和道德标准,在特定时间点被认为公平的模式可能会变得不公平。
- 反馈循环:现实系统中部署的模型通常会做出影响用户行为的预测。这种用户反馈可以创建反馈循环,从而强化和放大偏差,从而导致偏差漂移。
四、偏差漂移的后果
偏差漂移的后果可能是严重而深远的:
- 歧视:偏见漂移可能导致金融、刑事司法、医疗保健和招聘等各个领域的不公平待遇、歧视和差异,从而影响个人和社区。
- 法律和道德问题:当组织的模型表现出偏见漂移、违反反歧视法和道德准则时,组织可能会面临法律后果和声誉损害。
- 信任丧失:偏差漂移削弱了用户对机器学习系统的信任,使得维持用户对人工智能驱动应用程序的采用和信心变得具有挑战性。
五、减轻偏差漂移
解决偏差漂移需要采取多方面的方法:
- 持续监控:定期监控模型性能和公平性指标,以尽早发现偏差漂移。FairML 和 Aequitas 等工具和框架可以帮助解决这一问题。
- 定期再训练:使用更新的数据重新评估和再训练模型,以适应不断变化的分布和社会规范。确保再培训是一个持续的过程,而不是一次性的事件。
- 道德审查委员会:在组织内建立道德审查委员会或委员会,以评估和解决潜在的偏见漂移问题,使人工智能部署与道德标准保持一致。
- 算法公平性:将公平感知机器学习技术纳入模型开发中,以确保公平性并减少偏见。其中包括预处理、处理中和后处理方法。
- 透明度和可解释性:提高机器学习模型的透明度和可解释性,使用户和利益相关者能够了解如何做出预测并在必要时质疑决策。
- 反馈循环:设计系统纳入反馈循环,根据用户交互纠正和调整模型,从而降低偏见强化和放大的风险。
六、代码
解决机器学习中的偏差漂移是一个复杂且不断发展的领域,通常需要根据特定上下文和数据集定制解决方案。偏差漂移检测和缓解通常不能通过简单的代码和绘图来解决,因为它们涉及持续的监控、干预和模型再训练。不过,我可以提供一个基本的 Python 代码示例,演示如何使用公平性度量来测量数据集中的偏差,并使用绘图将其可视化。在实践中,您需要将其合并到更全面的偏差检测和缓解系统中。
WriteGongdiwudu
Get unlimited access to the best of Medium for less than $1/week.
Become a memberBias Drift in Machine Learning: Challenges and Mitigation
Everton Gomede, PhD
Everton Gomede, PhD·
Follow7 min read
·
5 days ago
30Introduction
Machine learning algorithms have gained widespread adoption across various industries, playing a pivotal role in automating processes, making data-driven decisions, and enhancing efficiency. However, they are not without their challenges, and one significant concern is bias. Bias in machine learning models can lead to unfair and discriminatory outcomes, with real-world implications. A particularly challenging aspect of bias is “bias drift,” where the model’s behavior changes over time. In this essay, we will explore the concept of bias drift, its causes, consequences, and strategies to mitigate it.Safeguarding the fairness of machine learning is an ongoing journey. Bias drift, like shifting sands, reminds us that vigilance and continuous adaptation are essential to maintain a just and equitable landscape in the realm of AI. Challenges arise, but with the right mitigation strategies, we can navigate these evolving terrains and ensure that technology remains a force for good, respecting the diversity of human experience.I. Understanding Bias Drift
Bias drift occurs when the performance of a machine learning model degrades over time, leading to increased bias in its predictions. Unlike other forms of model drift, such as concept drift or data drift, bias drift specifically relates to unfairness and discrimination. The causes of bias drift can be multifaceted, but they often stem from shifts in the data distribution or changing societal norms.II. Causes of Bias Drift
Data Distribution Changes: One common cause of bias drift is changes in the distribution of data used to train and evaluate models. Over time, the data collected or used to train a model may no longer be representative of the real-world population, leading to disparities.
Societal Norms and Regulations: Changing societal norms and regulations can impact the fairness requirements of machine learning models. A model deemed fair at a particular point in time may become unfair due to evolving social and ethical standards.
Feedback Loops: Models deployed in real-world systems often make predictions that influence user behavior. This user feedback can create feedback loops that reinforce and amplify biases, leading to bias drift.
III. Consequences of Bias Drift
The consequences of bias drift can be severe and far-reaching:Discrimination: Bias drift can result in unfair treatment, discrimination, and disparities in various domains, including finance, criminal justice, healthcare, and hiring, affecting individuals and communities.
Legal and Ethical Concerns: Organizations may face legal consequences and reputational damage when their models exhibit bias drift, violating anti-discrimination laws and ethical guidelines.
Loss of Trust: Bias drift erodes user trust in machine learning systems, making it challenging to maintain user adoption and confidence in AI-driven applications.
IV. Mitigating Bias Drift
Addressing bias drift requires a multifaceted approach:Continuous Monitoring: Regularly monitor model performance and fairness metrics to detect bias drift early. Tools and frameworks such as FairML and Aequitas can help with this.
Regular Retraining: Reassess and retrain models using updated data to adapt to changing distributions and societal norms. Ensure that retraining is an ongoing process, not a one-time event.
Ethical Review Boards: Establish ethical review boards or committees within organizations to assess and address potential bias drift issues, aligning AI deployment with ethical standards.
Algorithmic Fairness: Incorporate fairness-aware machine learning techniques into model development to ensure fairness and mitigate bias. These include pre-processing, in-processing, and post-processing methods.
Transparency and Explainability: Promote transparency and explainability in machine learning models, allowing users and stakeholders to understand how predictions are made and to challenge decisions when necessary.
Feedback Loops: Design systems to incorporate feedback loops that correct and adjust models based on user interactions, reducing the risk of reinforcement and amplification of bias.
Code
Addressing bias drift in machine learning is a complex and evolving field that often requires customized solutions depending on the specific context and dataset. Bias drift detection and mitigation are typically not addressed with simple code and plots, as they involve ongoing monitoring, intervention, and model retraining. However, I can provide a basic Python code example that demonstrates how to measure bias in a dataset using a fairness metric and visualize it using plots. In practice, you would need to incorporate this into a more comprehensive bias detection and mitigation system.import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, f1_score
from imblearn.under_sampling import RandomUnderSampler# Load the Breast Cancer Wisconsin dataset
data = load_breast_cancer(as_frame=True)
X = data.data
y = data.target# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# Balance the training dataset using RandomUnderSampler
rus = RandomUnderSampler(random_state=42)
X_train_balanced, y_train_balanced = rus.fit_resample(X_train, y_train)# Train a logistic regression model on the balanced training data
model = LogisticRegression(solver='liblinear')
model.fit(X_train_balanced, y_train_balanced)# Evaluate the model on the test set
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)print(f"Accuracy: {accuracy}")
print(f"F1 Score: {f1}")Accuracy: 0.9736842105263158
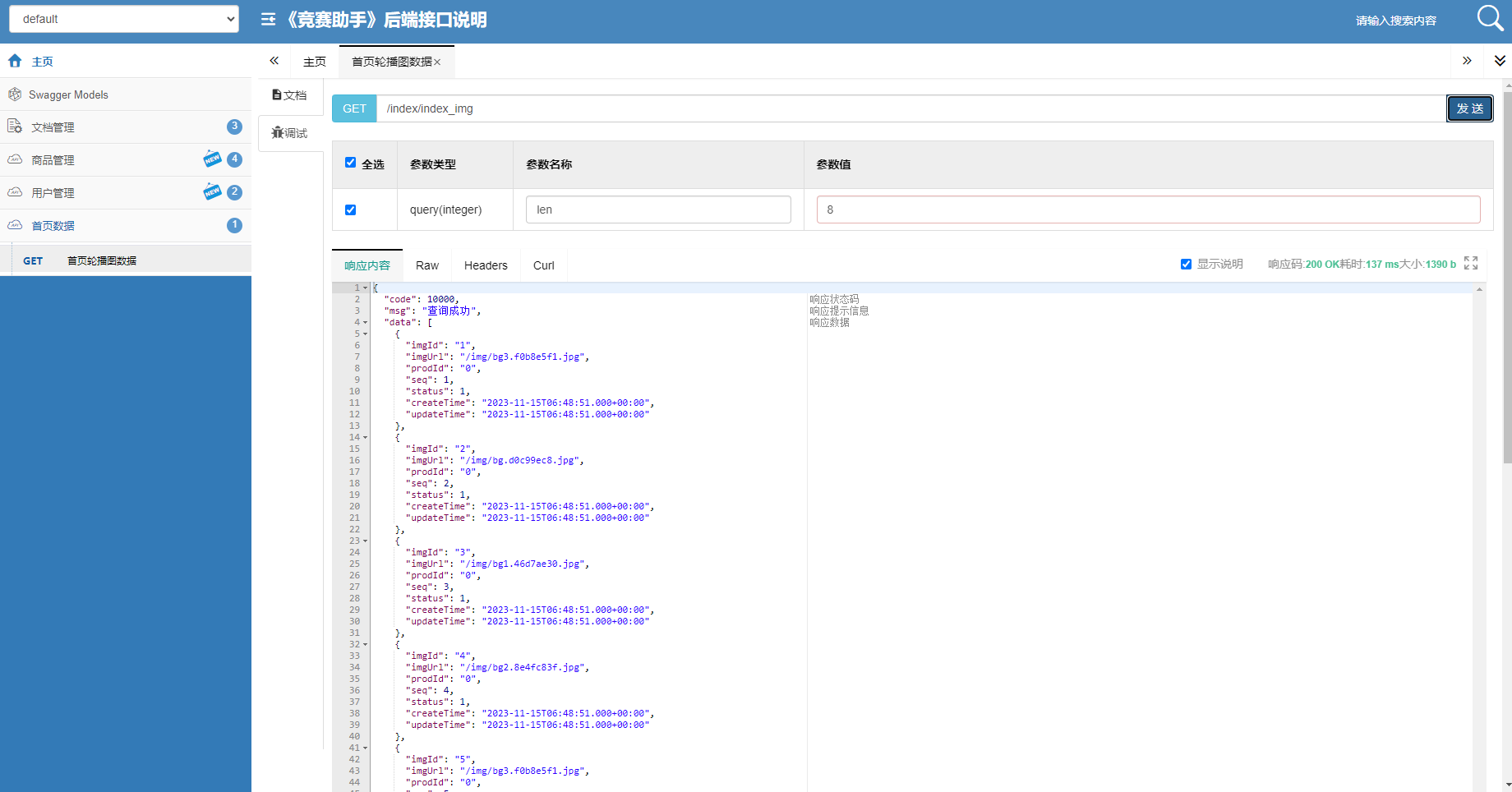
F1 Score: 0.979020979020979 为了可视化模型的结果,您可以创建分类评估指标图,例如混淆矩阵和 ROC 曲线。matplotlib以下是使用 Python 库(如和 )执行此操作的方法scikit-learn:
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix, roc_curve, auc# Calculate the confusion matrix
cm = confusion_matrix(y_test, y_pred)# Calculate the ROC curve
fpr, tpr, _ = roc_curve(y_test, model.predict_proba(X_test)[:, 1])
roc_auc = auc(fpr, tpr)# Create subplots for the confusion matrix and ROC curve
plt.figure(figsize=(12, 5))# Confusion Matrix
plt.subplot(121)
plt.imshow(cm, interpolation='nearest', cmap=plt.cm.Blues)
plt.title('Confusion Matrix')
plt.colorbar()
tick_marks = [0, 1]
plt.xticks(tick_marks, ["Benign", "Malignant"], rotation=45)
plt.yticks(tick_marks, ["Benign", "Malignant"])
for i in range(2):for j in range(2):plt.text(j, i, format(cm[i, j], 'd'), horizontalalignment="center", color="white" if cm[i, j] > cm.max() / 2 else "black")plt.xlabel('Predicted Label')
plt.ylabel('True Label')# ROC Curve
plt.subplot(122)
plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC curve (area = {:.2f})'.format(roc_auc))
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic')
plt.legend(loc='lower right')plt.tight_layout()
plt.show()此代码将生成一个显示混淆矩阵和 ROC 曲线的图。混淆矩阵可帮助您了解模型在真阳性、真阴性、假阳性和假阴性方面的表现如何。ROC 曲线通过显示真阳性率和假阳性率之间的权衡,提供有关模型区分两类(良性肿瘤和恶性肿瘤)的能力的信息。

请确保您拥有所需的库,包括matplotlib已安装的库,并运行此代码以可视化分类模型的结果。
在数据集中绘制偏差有点复杂,通常需要分析特征来识别和可视化任何偏差。数据集中的偏差可以通过多种方式表现出来,例如某些群体的不公平或代表性不足。下面是一个简单的示例,说明如何使用该matplotlib库创建可视化来识别受保护属性(例如性别)中的偏见:
import matplotlib.pyplot as plt# Assuming you have a dataframe 'data_encoded' with protected attribute 'sex'
# Define the protected attribute and privileged/unprivileged groups
protected_attribute = 'sex'
privileged_group = 1
unprivileged_group = 0# Count the number of instances for each group
privileged_count = data_encoded[data_encoded[protected_attribute] == privileged_group].shape[0]
unprivileged_count = data_encoded[data_encoded[protected_attribute] == unprivileged_group].shape[0]# Create a bar chart to visualize the bias
groups = ['Privileged Group', 'Unprivileged Group']
counts = [privileged_count, unprivileged_count]plt.bar(groups, counts, color=['blue', 'red'])
plt.title('Bias in Protected Attribute')
plt.xlabel('Groups')
plt.ylabel('Number of Instances')
plt.show() 在此示例中,我们假设您有一个名为“sex”的受保护属性的 DataFrame data_encoded。我们计算并绘制特权组和非特权组中的实例数量,以可视化任何潜在的偏差。
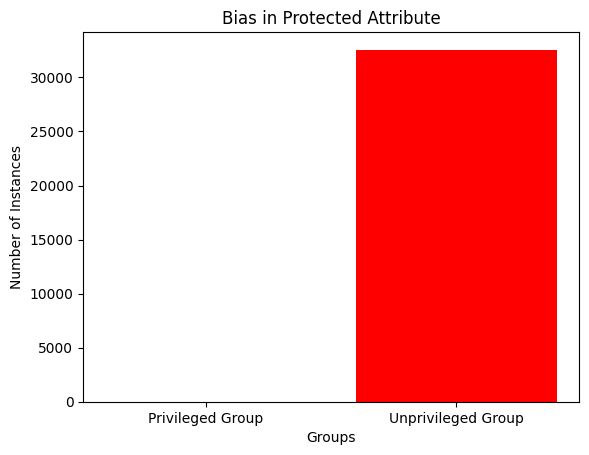
请调整此代码以适应您的特定数据集和受保护的属性。此外,您可能需要使用更先进的技术来全面分析和可视化偏见,例如人口平等、机会均等或不同影响分析,具体取决于您的具体用例和数据集。
在实践中,您需要更复杂的方法和持续的监控流程来全面解决偏差漂移问题。此外,您可能需要应用偏差缓解技术(例如重新权重或对抗性去偏差)来减少模型预测中的偏差。
七、结论
偏差漂移在机器学习和人工智能领域提出了重大挑战。随着社会越来越意识到人工智能偏见的道德和法律影响,解决偏见漂移已成为部署机器学习模型的组织的当务之急。通过持续监控、再培训和集成公平意识技术,组织可以减轻与偏见漂移相关的风险,并促进更加道德和公平的人工智能应用。对人工智能公平性的追求仍在继续,当我们面对偏见漂移的挑战时,我们离更加公正和公平的数字未来又近了一步。