文章目录
- 前言
- Operator Model And Iterator Model
- 系统组成
- Connector
- 数据模型
- 查询执行模型
- Statement
- Stage
- Task
- Split
- Driver
- Operator
- Exchange
- PipeLine
- 总结

前言
Presto(PrestoDB)是一个FaceBook开源的分布式MPP SQL引擎,旨在处理大规模数据的查询和分析问题。传统数据库系统(eg:Hive)在面对大规模数据和复杂查询需求时存在限制,如数据规模限制、查询速度慢、数据源集成困难等问题。
本文主要介绍下Presto基本的核心概念。
Operator Model And Iterator Model
MPP核心的迭代器模型;操作模块化;执行计划等模型与实现框架设计,可参考最早的1995年Goetz Graefe发布的encapsulation-volcano论文:
http://daslab.seas.harvard.edu/reading-group/papers/encapsulation-volcano.pdf
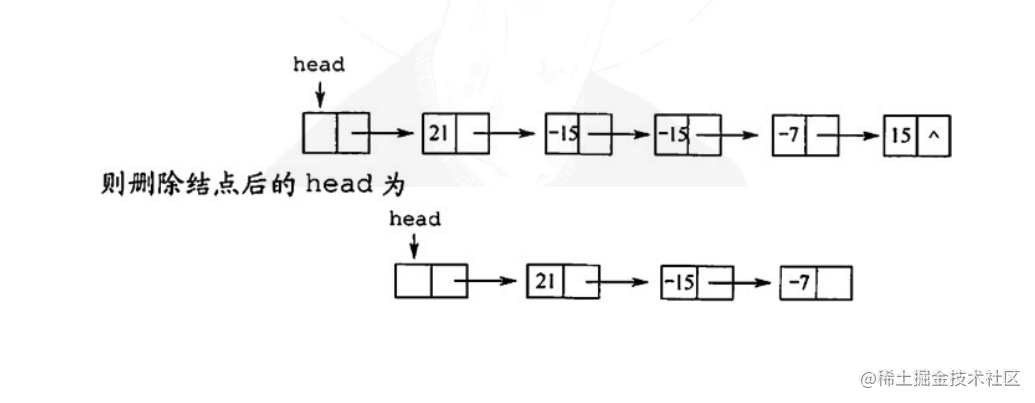
论文中首次提出了一种并行SQL的设计,即通过各种Operator(如TableScan、Project、Filter、Aggregate、Exchange、Join等)组成一棵树,树的根节点产生SQL输出,树的叶子节点是各种TableScan,数据从叶子节点流入,一步步被加工直至产生最终结果。这个模型称为Operator Model,这棵树我们称之为执行计划(Plan,在传统数据库里又分为逻辑计划和物理计划)。
在Operator Model执行的过程中,各节点有三种基本状态(或者说要实现三个接口):Open、GetNext、Close。父节点的接口调用一般会递归调用子节点对应的接口。SQL执行时就从根节点Open开始,然后不断调其GetNext接口得到一行输出(后续演变为得到RowBatch),直到没有结果为止,最后调Close。这个模型称为Iterator Model。

系统组成
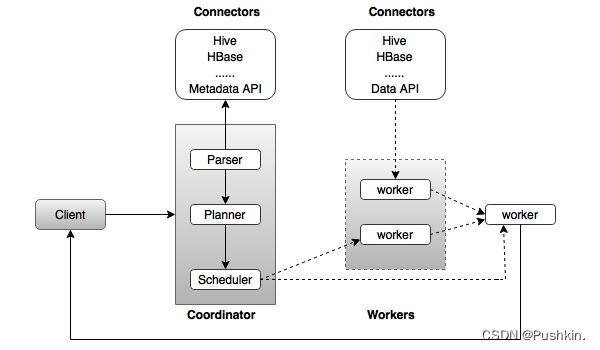
Presto是典型的M/S架构的系统,由一个Coordinator节点和多个Worker节点组成。 Coordinator负责如下工作:
● 接收用户查询请求,解析并生成执行计划,下发Worker节点执行。
● 监控Worker节点运行状态,各个Worker节点与Coordinator节点保持心跳连接,汇报节点状态。
● 维护MetaStore数据。
Worker节点负责执行下发到任务,通过连接器读取外部存储系统到数据,进行处理,并将处理结果发送给Coordinator节点。
Presto最初不支持高可用架构, 后面FaceBook提出了一个新的设计:一个分解的协调器(disaggregated coordinator),允许 coordinator 在单个 workers pool 中横向扩展。
Connector
Presto通过内置的各种Connector来接入多种外部数据源。Presto提供了一套标准的SPI接口,您可以使用这套接口开发自己的Connector,以便访问自定义的数据源。
通常,一个Catalog会绑定一种类型的Connector,并在Catalog的Properties文件中进行设置。
数据模型
数据模型即数据的组织形式。Presto使用Catalog、Schema和Table三层结构来管理数据。
● Catalog:一个Catalog可以包含多个Schema,物理上指向一个外部数据源,可以通过Connector访问该数据源。一次查询可以访问一个或多个Catalog。
● Schema:相当于一个数据库实例,一个Schema包含多张数据表。
● Table:数据表,与一般意义上的数据库表相同。
查询执行模型
Presto执行SQL语句,并将这些语句转换为coordinators和workers的分布式集群执行的查询。
Statement
Presto执行ANSI兼容的SQL语句,该标准由子句、表达式和谓词组成。
Query
解析一条语句时,它将其转换为一个查询,并创建一个分布式查询计划,然后将其实现为在Presto worker上运行的一系列相互连接的阶段。语句和查询之间的区别很简单。一条语句可以被认为是传递给Presto的SQL文本(Statement),而查询则是指为执行该语句而实例化的配置、组件、查询执行计划和优化信息等。一个查询执行包括Stage、Task、Driver、Split、Operator、DataSource组成,这些组件之间通过内部联系共同组成一个查询执行,从而得到SQL语句表述的查询,并得到相应的结果集。
Stage
Presto执行查询时,通过将执行分解为阶段层次结构来执行。例如需要聚合Hive中存储的十亿行的数据,它会创建一个根阶段来聚合其他几个阶段的输出,所有这些阶段都是为了实现分布式查询计划的不同部分而设计的。组成查询的阶段层次结构类似于树。每个查询都有一个根阶段,负责聚合来自其他阶段的输出。阶段是协调器用来建模分布式查询计划,但是阶段本身并不在Presto worker上运行。
Presto 中Stage共分为4种:
- Coordinator_Only: 用于执行DDL或者DML语句中最终的表结构创建或者更改
- Single: 用于聚合子Stage的输出是数据,并将最终数据输出给终端用户
- Fixed: 用于接受其子Stage产生的数据并在集群中对这些数据进行分布式的聚合或者分组计算
- Source: 用于直接连接数据源,从数据源读取数据,在读取数据的时候,该阶段也会根据Presto对查询计划执行的优化完成相关的断言下发(Predicate PushDown)和条件过滤
按照数据的流向,我们可以约定越靠近数据源的Stage越处于上游,越远离数据源的Stage越处于下游
create table xxx as select

Task
Stage对分布式查询计划的特定部分建模,但Stage本身并不在Presto Worker上执行。Task是Presto体系结构中的工作项,因为分布式查询计划被分解为一系列Stage,然后转换为Task,然后这些Task作用于或处理Split。Presto Task有输入和输出,就像一个Stage可以由一系列Task并行执行一样,一个Task也可以与一系列驱动程序并行执行。
Split
Split分片,一个分片其实就是一个大的数据集中的一个小的子集,Driver是作用于一个分片上的一系列操作的集合,而每个节点上运行的Task,又包含多个Driver,从而一个Task可以处理多个Split。当Presto执行一个查询时,首先会从Coordinator得到一个表对应的所有的Split,然后Presto就会根据查询执行计划,选择合适的节点运行响应的task处理Split。
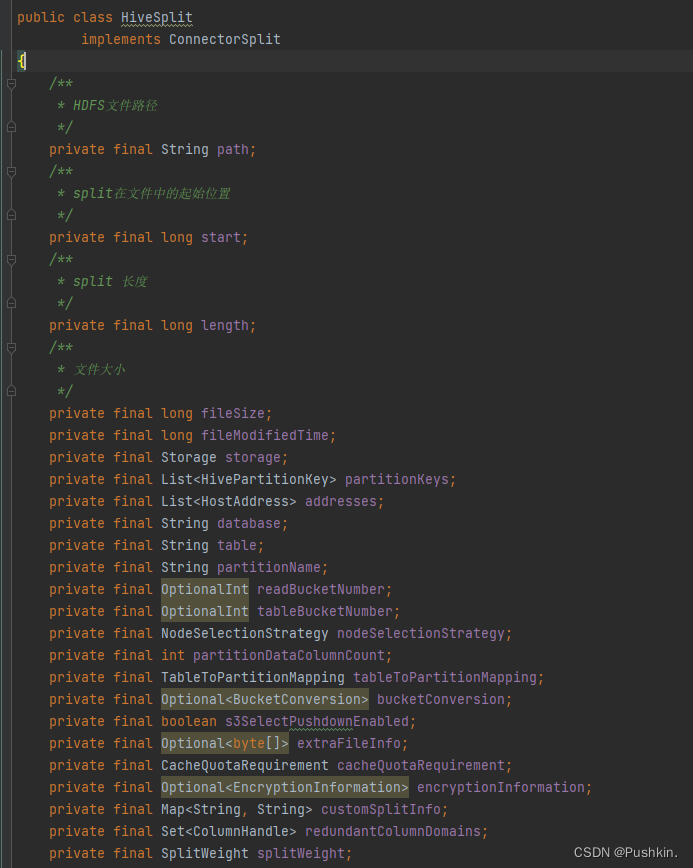
这里来看下在HiveConnector中HiveSplit的定义:

Driver
Task包含一个或多个并行Driver。Driver作用于数据并结合Operator以产生输出,然后由一个Task聚合,然后交付给另一个Stage的另一个Task。Driver是操作符实例的序列,它是Presto体系结构中并行度的最低级别。Driver有一个输入和一个输出。
Operator
Operator过滤、加权、消费、转换和生成数据。例如,TableScan从Connector获取数据并生成可被其他Operator使用的数据,筛选Opertaor使用数据并通过对输入数据应用谓词来生成子集。
Exchange
交换在Presto节点之间为查询的不同阶段传输数据。任务将数据生成到输出缓冲区,并使用交换客户机使用来自其他任务的数据。
PipeLine
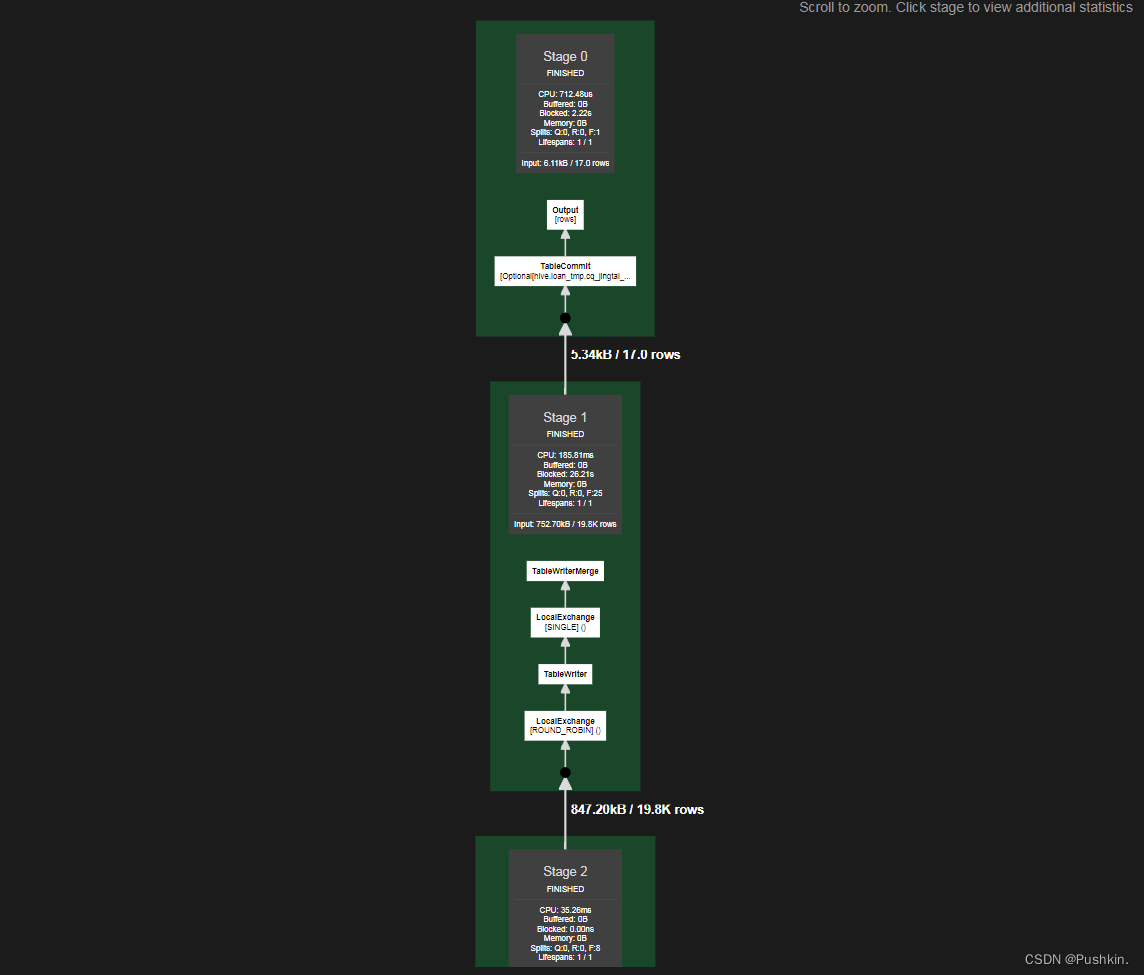
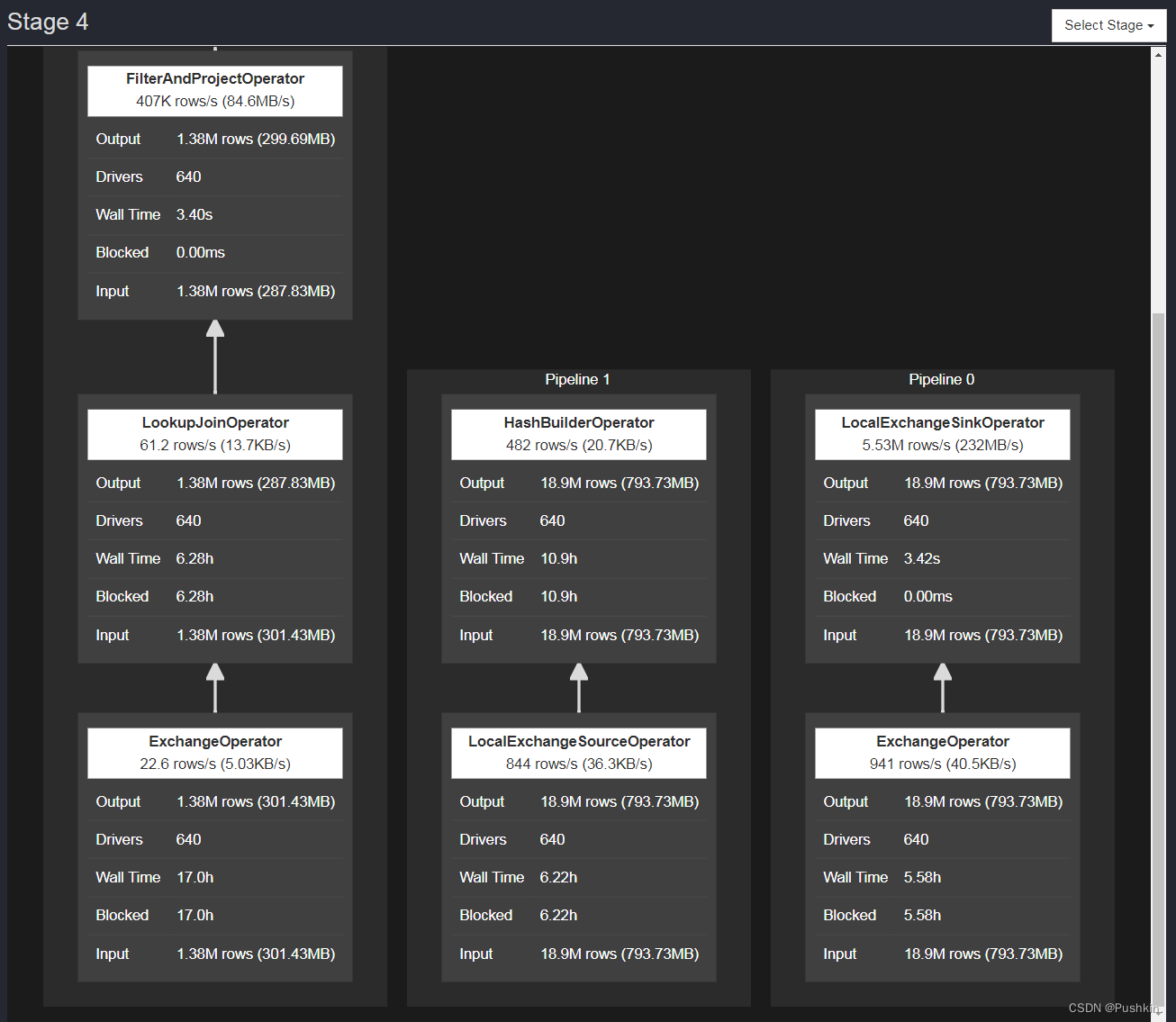
每个Task执行一个Stage的逻辑,也可以说就是执行一个PlanFragment里的Operator,这些Operator的最佳并行度可能是不同的。比如说做Tablescan的并发可以很大,但做Final Aggregation(如Sort)的并发度只能是一。基于这个考虑,一个PlanFragment又会被切分为若干Pipeline,每个Pipeline由一组Operator组成,这些Operator被设置同样的并行度。Pipeline之间会通过LocalExchangeOperator来传递数据。
在Presto的Web UI里可以看到下面的Pipeline图。Driver的数目就是这个Pipeline的并行度。
总结
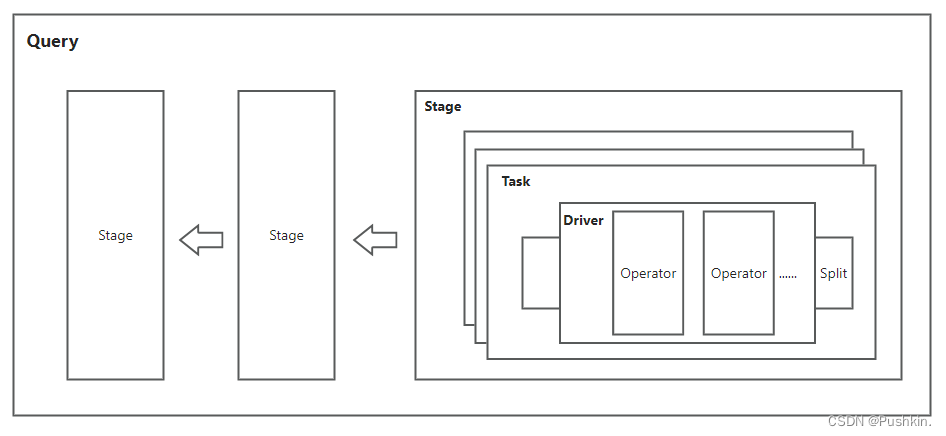
如图 Presto的一次执行查询会被分解为多个Stage, Stage之间具有依赖关系,每个Stage由一列的Task组成,每个Stage的task被均分为在每个worker上并行执行,每个Task又由多个Driver组成,每个Driver只能处理一个Split, 且每个Driver由一系列前后相连的operator组成,每个Operator都代表对于一个Split的操作