进程的创建有fork,进程的退出有main函数的return,exit,_exit函数
而进程的退出中,一个进程的退出只能有三种情况,退出成功结果对/不对,或者是运行异常收到信号终止
但是我们发现我们用代码创建的子进程它是与父进程共同执行一套代码,在不发生写时拷贝的情况下还会使用同一套数据
那有没有可能让父子进程执行不同的代码,拥有不同的数据呢?
答案是可以的!这就是我将要介绍的——进程程序替换
文章目录
- 1.初步认识程序替换函数
- 2.多进程下的程序替换
- 3.从系统层面理解程序替换
- 4.程序替换的使用
- 延伸
- 5.程序替换函数
- a. 程序替换与环境变量
- b. 程序替换函数与环境变量
- c. 库函数与系统调用
1.初步认识程序替换函数
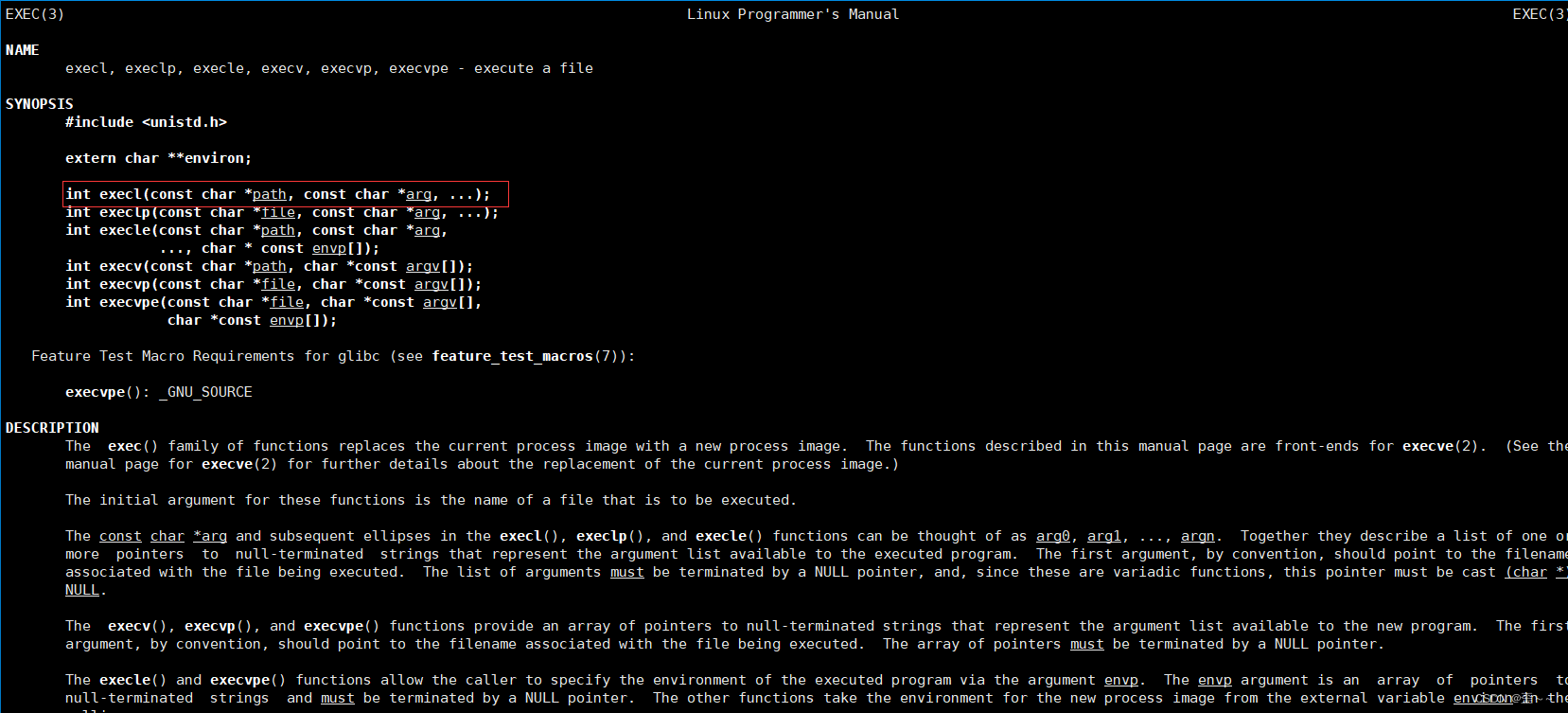
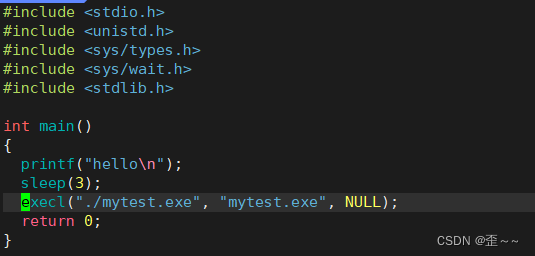
我们直接上代码展示程序替换需要用到的一个函数execl:
我们直接使用它:
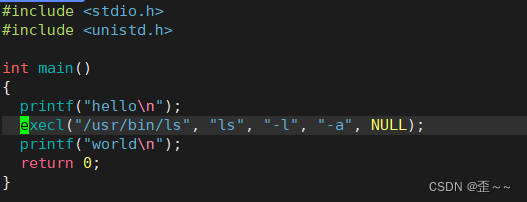
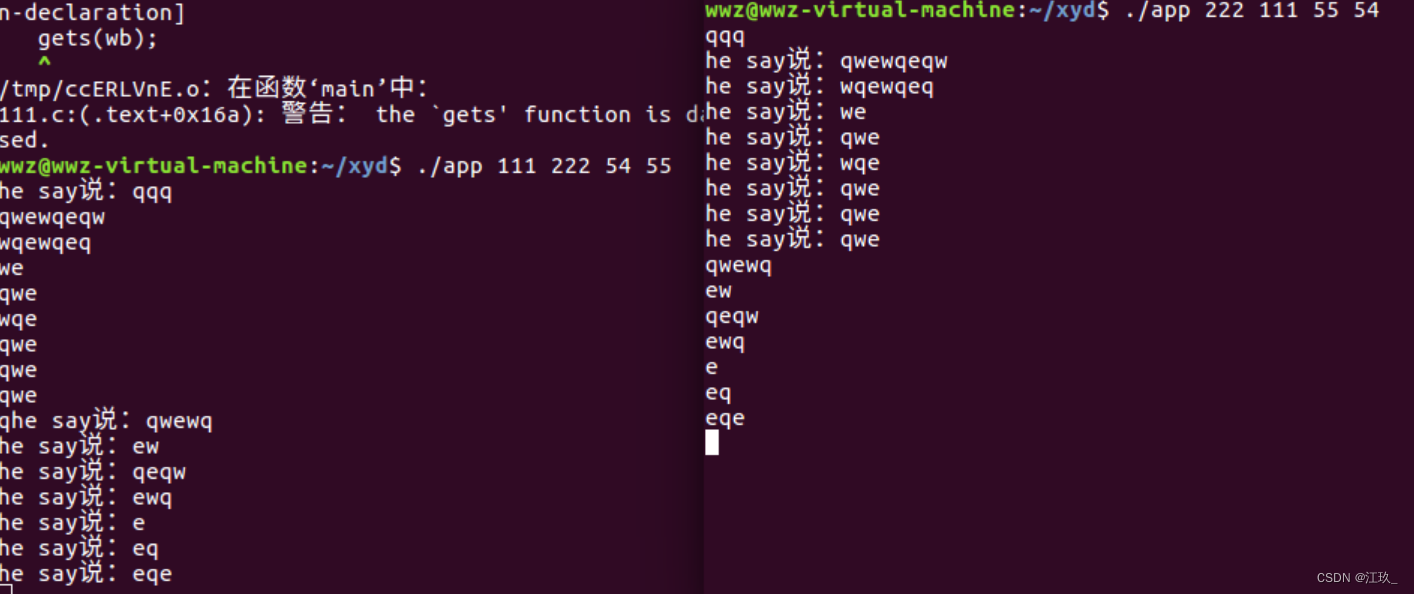
代码运行结果:
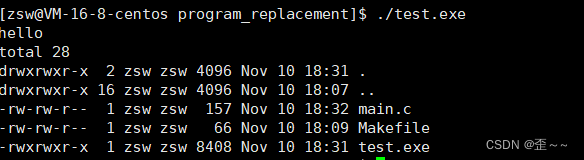
我们能发现到两个现象,这个代码帮我们运行了一条指令:ls -l -a,并且在上面程序中,并没有执行return的上一句代码。
可见execl确实能够帮我们执行其他程序。我来介绍一下函数的参数:
path:很明显是一个路径,这个路径是我们想要执行程序的路径 + 可执行程序文件名
arg:我们可以看到它后面有三个点,这三个点代表的意思是可变参数列表,而包括arg这个参树,我们在命令行怎么用这个程序,我们就用字符串怎么包含命令行中空格分隔的每段字符函数的结尾必须以NULL结尾
2.多进程下的程序替换
接下来我们就用代码来展示多进程下的程序替换:
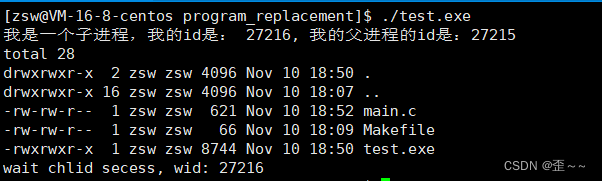
可以看到,使用起来跟单进程没有什么大的区别,并且也没有打印hello world。
3.从系统层面理解程序替换
下面我就用ls命令的文件来代替替换的程序
首先我们要了解的第一个是使用exel进程程序替换后,是否又创建进程了呢?有的话它应该会有pcb和自己的地址空间、页表,没有的话那又是如何实现的呢?这里先说一下单进程程序替换的原理:
我们知道一个程序跑起来之后会形成一个进程,创建自己的的pcb、进程地址空间、页表等。
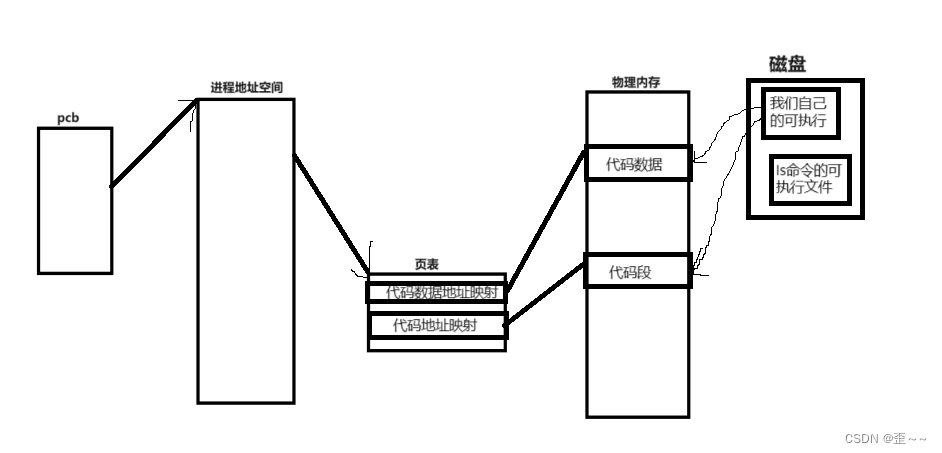
当我们在执行自己的可执行程序的之后,先将可执行程序加载到内存中,然后操作系统使用相关的数据结构体来将它管理起来,当执行到execl函数的时候,操作系统会根据execl中提供的路径将ls的可执行文件加载到内存中,覆盖我们可执行的代码段和代码数据的区域,然后开始执行ls中的代码:
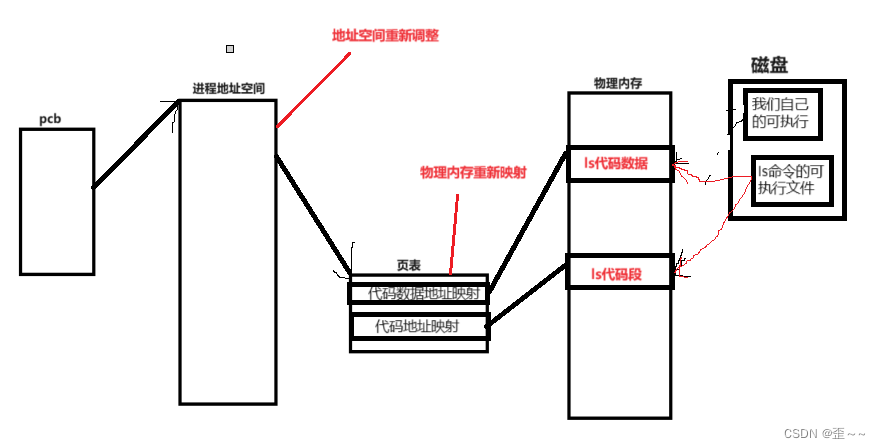
有人可能就会说了,重新覆盖之后操作系统哪知道它该从哪里开始执行呢?其实这里就有两个小知识点:
在Linux中可执行程序文件中不只有代码段和代码数据还有开头会存储一个地址这个地址记录了程序从哪里开始执行(可执行文件的内部布局遵循ELF的规则),而cpu中又有一个寄存器eip,他会记录下一条将要执行代码的地址。所以才能够如此丝滑的进行程序切换。而这也解决了我们的疑问:
首先,程序替换并不会产生新的进程,其次为什么上面不会执行execl后的代码,原代码和代码数据被覆盖,那么自然只会执行覆盖后的代码了
那么多进程下的程序替换又是怎么样的呢?
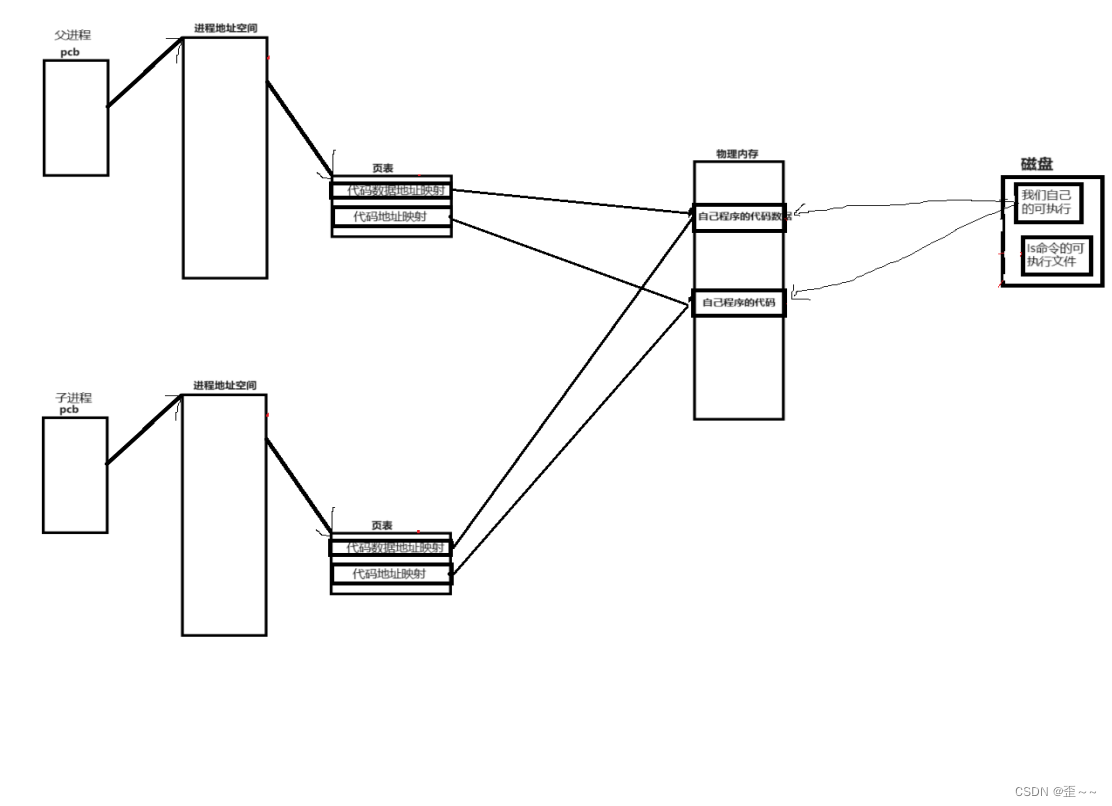
当执行到execl之后,ls文件要覆盖物理内存中的原有数据,但是内存中的数据不知一个进程有,所以会触发写时拷贝机制,然后子进程映射到新的物理内存:
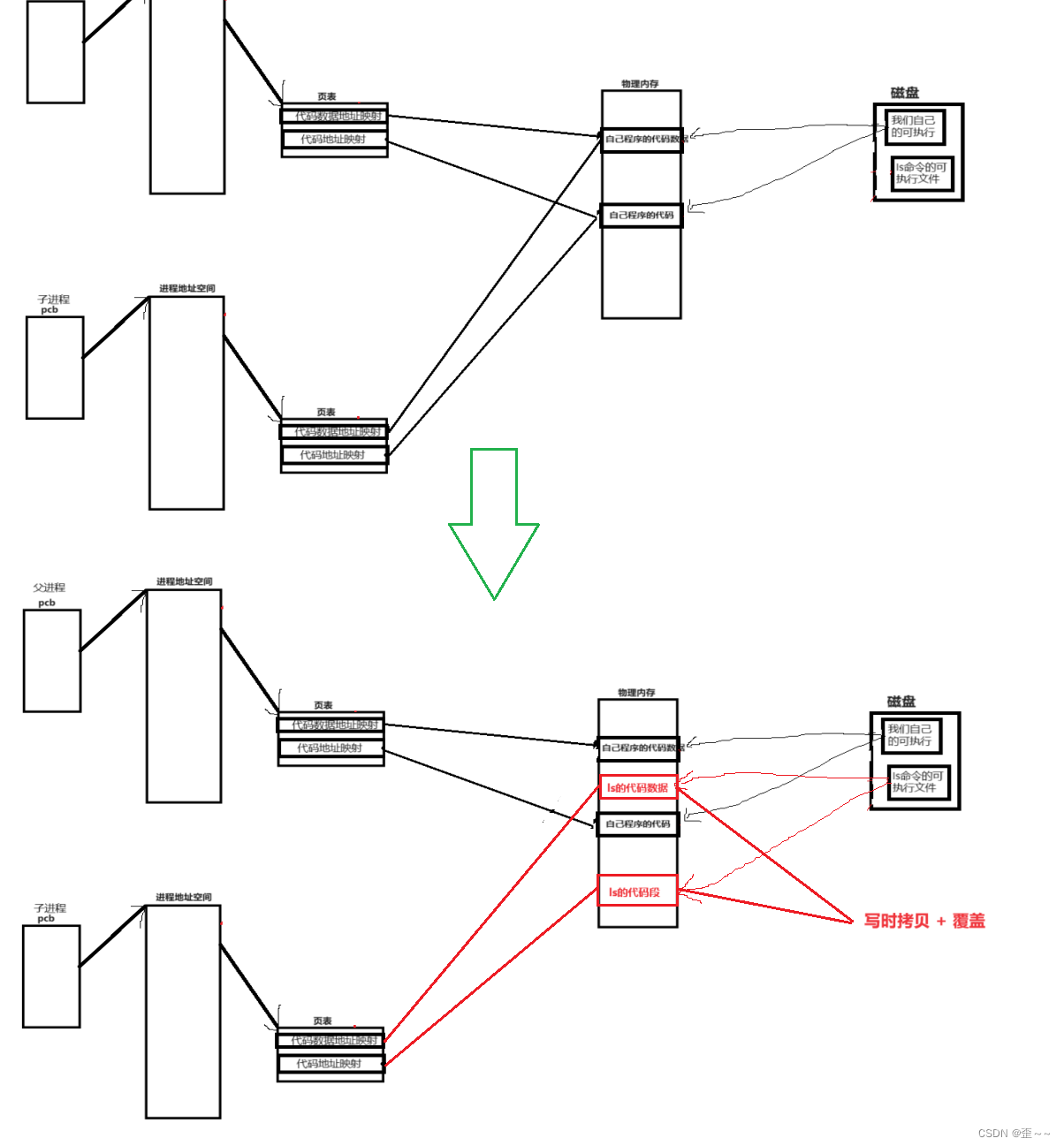
4.程序替换的使用
我们上面说了程序替换能够使用命令ls,那能不能用我们自己的程序呢?
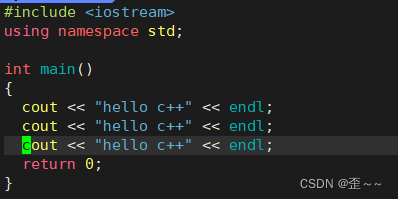
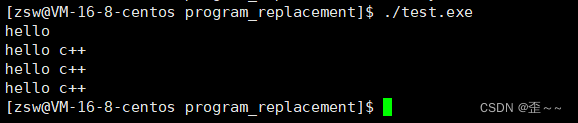
调用c++程序
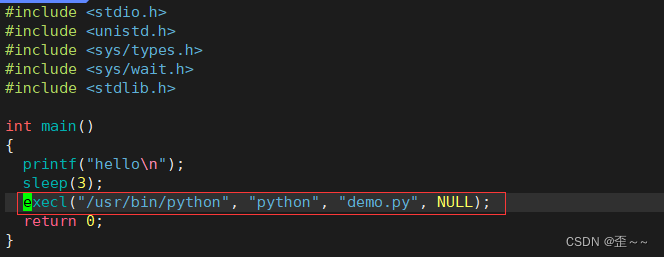
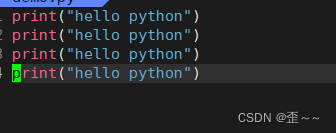
调用python脚本:
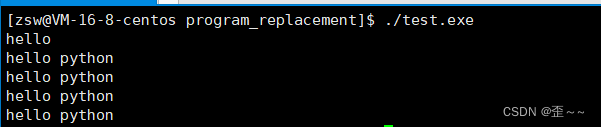
ls命令是用C语言写的,我们能切换,我们也能切换c++程序,我们还能调用python脚本,当然其它比如shell脚本、Java脚本也能切换。我们现在就明白为什么在一个工程中会出现多种语言的协同开发了。那由此就产生一个问题,为什么能够切换呢?一个是C语言一个是python脚本完全不搭边啊。
那我们就需要更为底层的理解这个现象了,不论是c++形成的可执行程序被执行还是python脚本被解释器解释执行,本质都是启动了一个进程,那都是进程了,还分什么c++,python吗?那肯定是不分了,不都是内核数据结构 + 代码 + 代码数据吗?那我用C语言这个进程切换执行本应该是另一个进程执行的的东西肯定是可以的了。所以就有系统高于一切的说法。
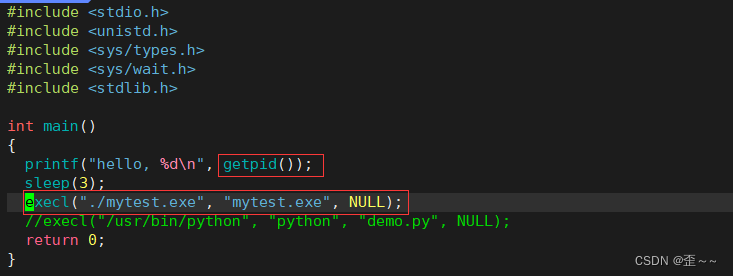
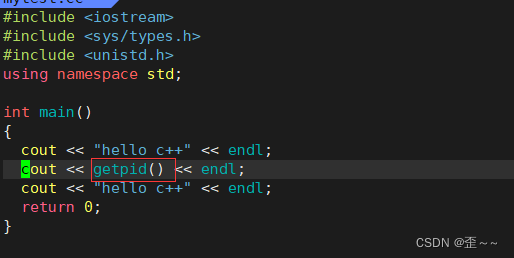

这里也说明了程序替换的时候没有产生新进程。
延伸
现在我们再理解一下运行一个程序。
我们说运行一个程序首先就是把它加载到内存中。
那为什么要加载到内存中呢?
这是由于计算机的体系结构决定的,cpu不跟外设直接交互。
如何加载?
我们发现execl函数切换了代码段和代码数据,这不就是把ls可执行程序文件加载到了内存中吗?也说明execl也充当着将文件加载到内存中的加载器的功能。
那在程序加载到内存中的时候也会生成pcb、虚拟地址空间、页表等等内核数据结构,那创建内核数据结构和加载可执行到内存那个先执行呢?
我们在创建进程的时候有没有可能不调度这个进程,因为操作系统太“忙”了,没有多余的内存了,而又从上面的情况来说,我们创建好一个子进程后执行一条代码后,切换程序,它的pid没有改变,这可不可以说明在切换程序(新的程序加载到内存时)就已经有内核数据结构了(因为有进程pid)。所以创建内核数据结构,和加载可执行文件到内存,一定是先创建好内核数据结构。
5.程序替换函数
关于程序替换相关的函数不止上面的一个execl还有很多:
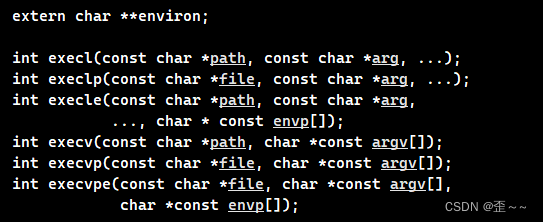
在这里简单介绍一下exec*系列的函数
带l的意思是传的参数是可变参数列表的形式传
带p的意思是,第一个参数不用写绝对路径 + 文件名,只要文件名就可以
带v的意思是vector,数组的意思,就是以数组的形式传
带e的意思是,传的参数的第三个参数是环境变量数组
a. 程序替换与环境变量
我们在这里要着重说一下参数中有环境变量的函数。
我们知道子进程会继承父进程中的环境变量,这一点的验证很简单,并且方法多种,我们只用其中一种:
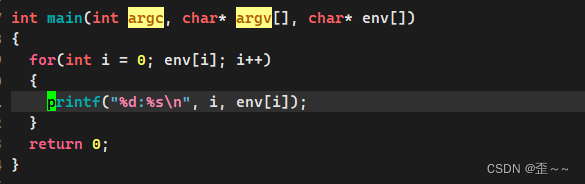
这样可以查看该进程中的所有环境变量:
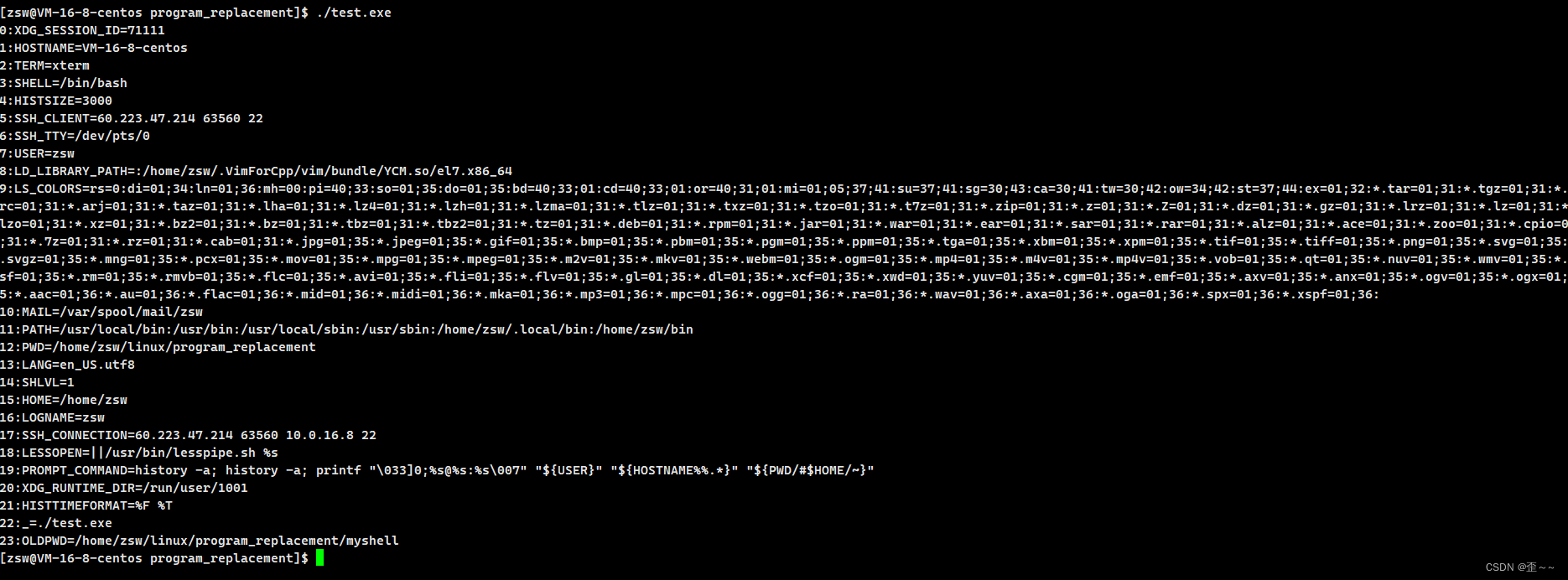
我们知道在命令行中启动的进程都是shell的子进程,那么我们在shell中添加一个环境变量我们再来看该程序中的环境变量:
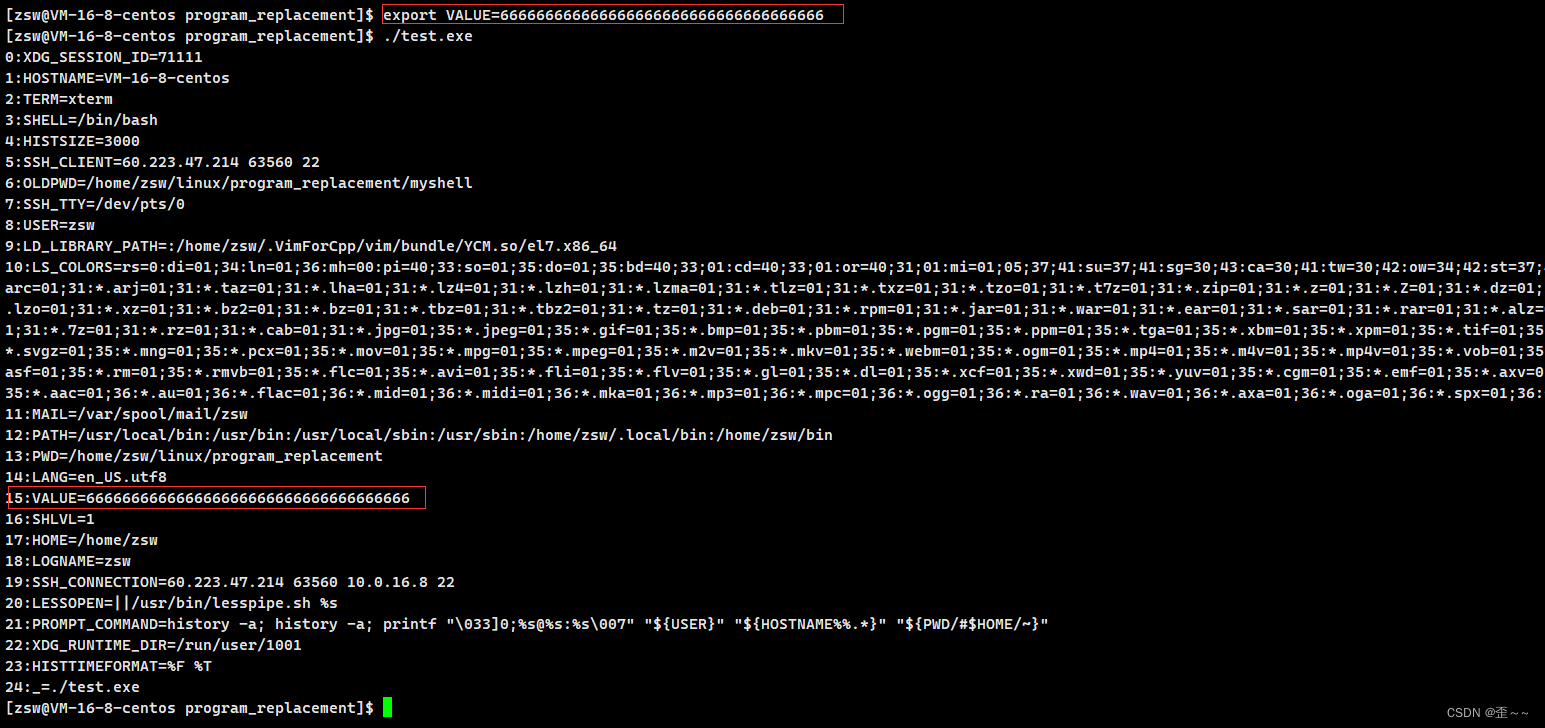
我们看到是这样的结果,那我们在我们自己的进程中添加的子进程中的环境变量是什么情况呢?
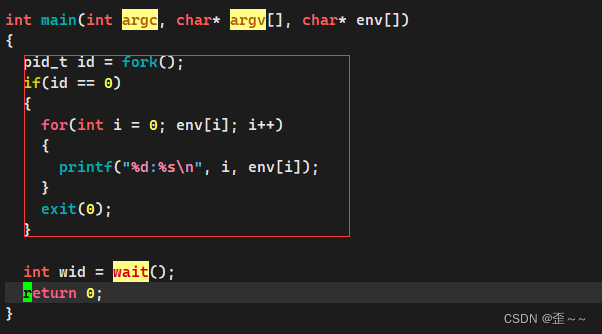
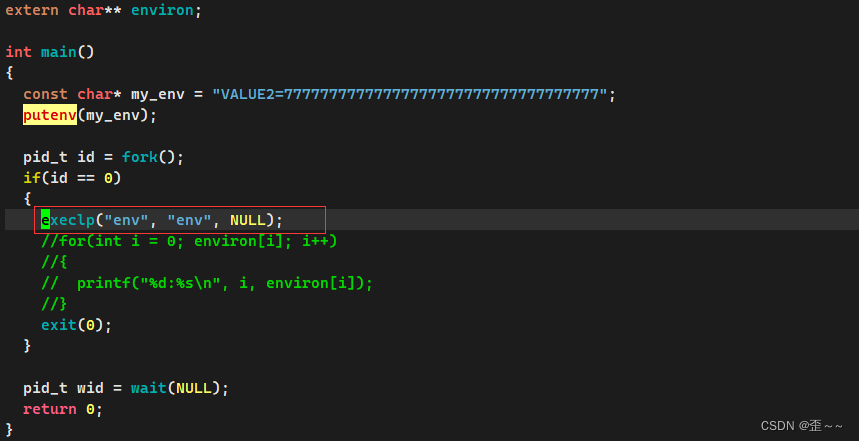
在这里我们介绍一个函数putenv:
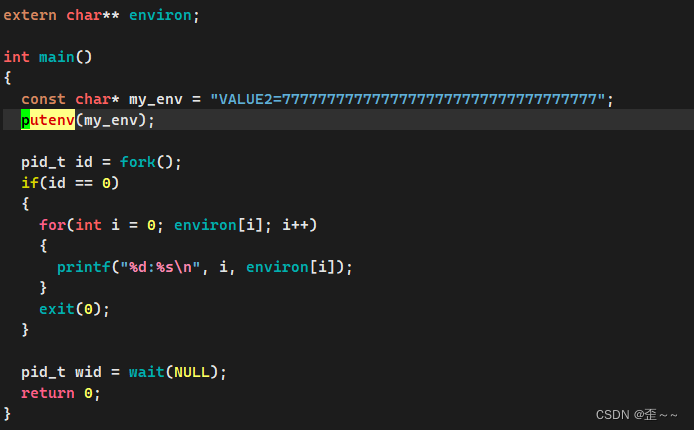
很明显它可以为在代码中该进程添加 一个环境变量:
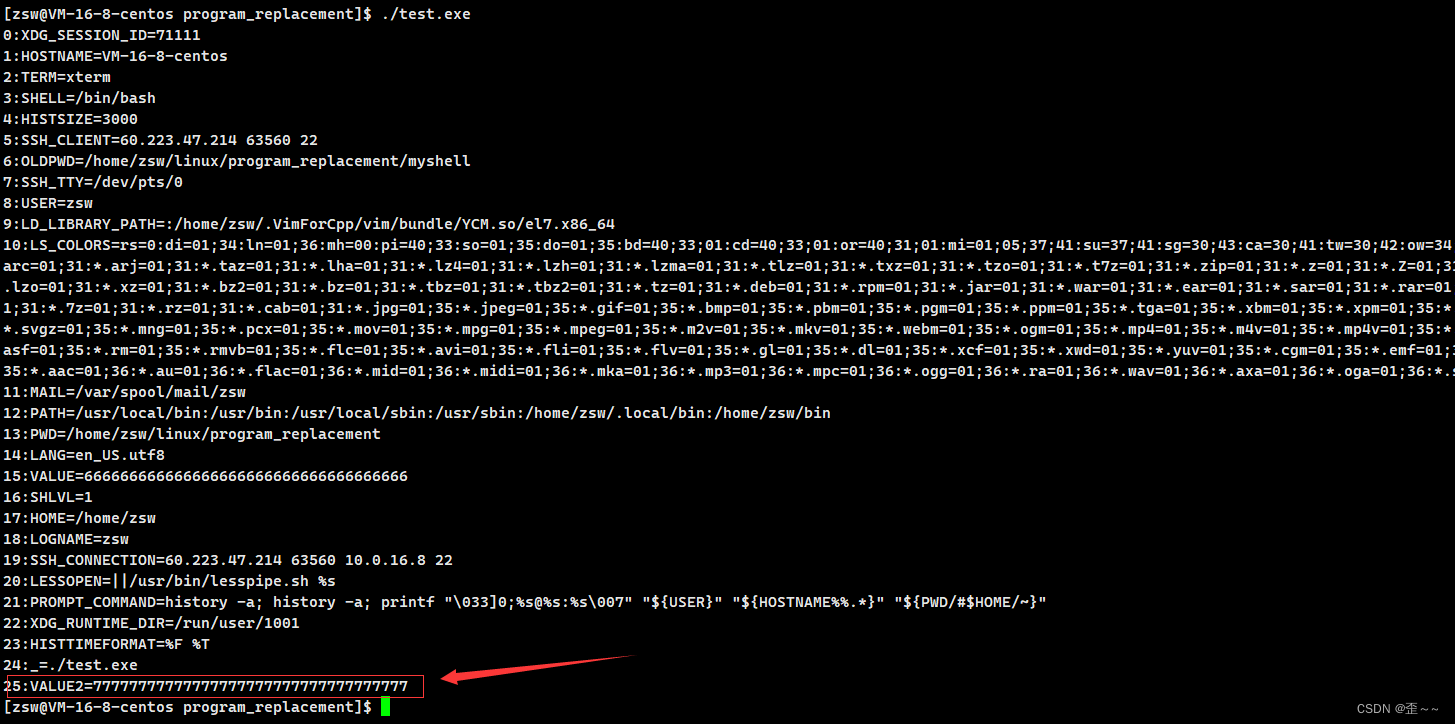
我们可以看到,父进程确实会将环境变量传递给子进程。那么我们知道当使用程序替换函数的时候,物理内存中的代码数据将会被覆盖重写,页表也重新映射,那子进程中的环境变量也肯定在内存中,那当子进程程序替换后环境变量还在不在呢?
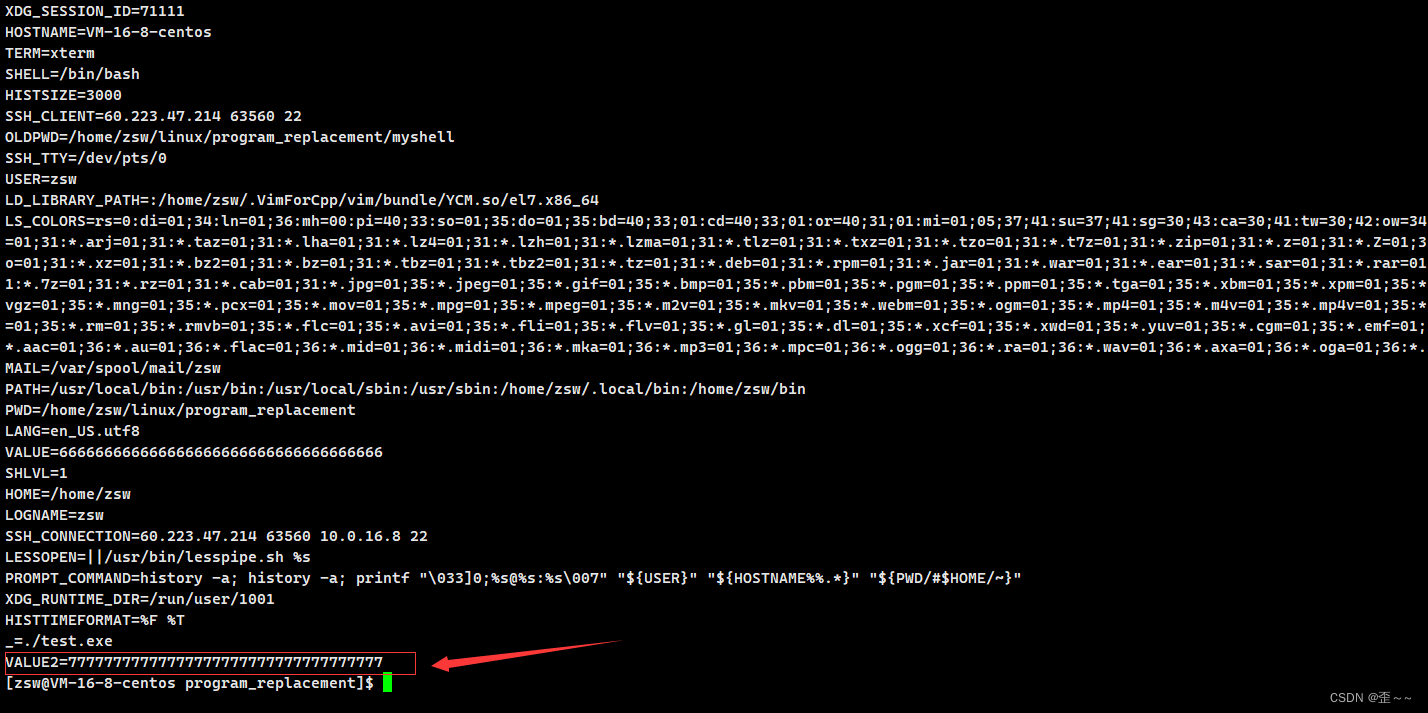
我们发现它也是在的,这是为什么呢?我们需要从底层来认识:
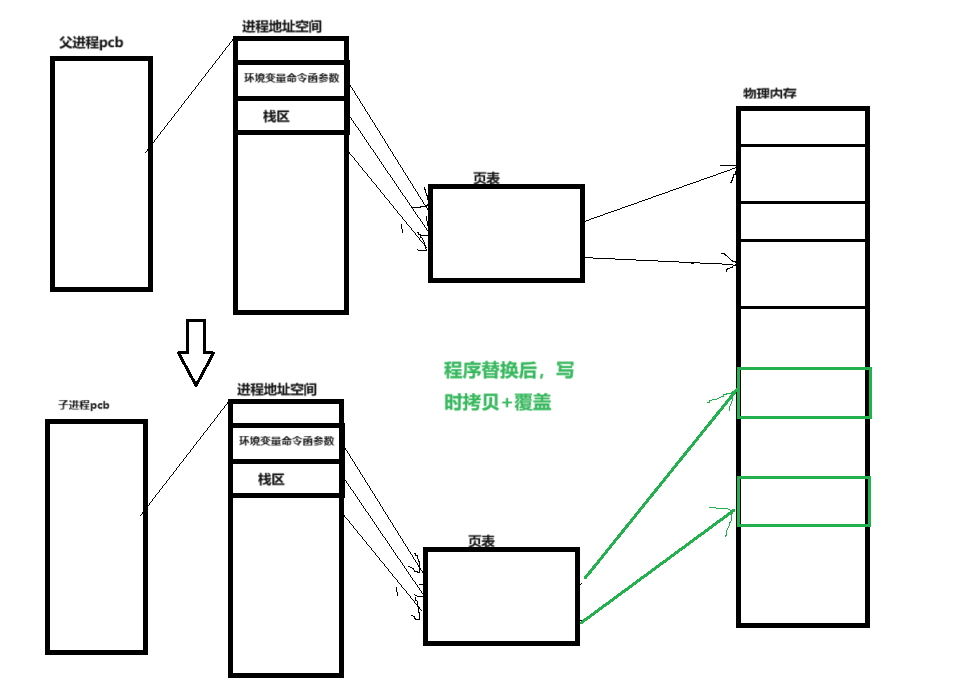
环境变量在栈区之上通过地址空间可以让子进程继承父进程的环境变量,所以我们可以得出程序替换只会替换新程序的代码和数据,环境变量并不会被替换
b. 程序替换函数与环境变量
我们现在来用一下这个带有环境变量参数的函数:
test.c:
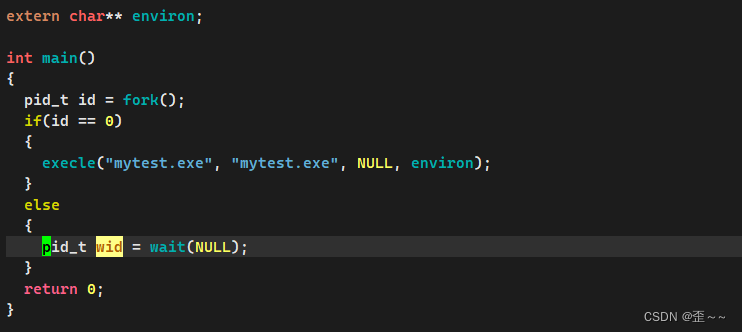
mytest.cc:
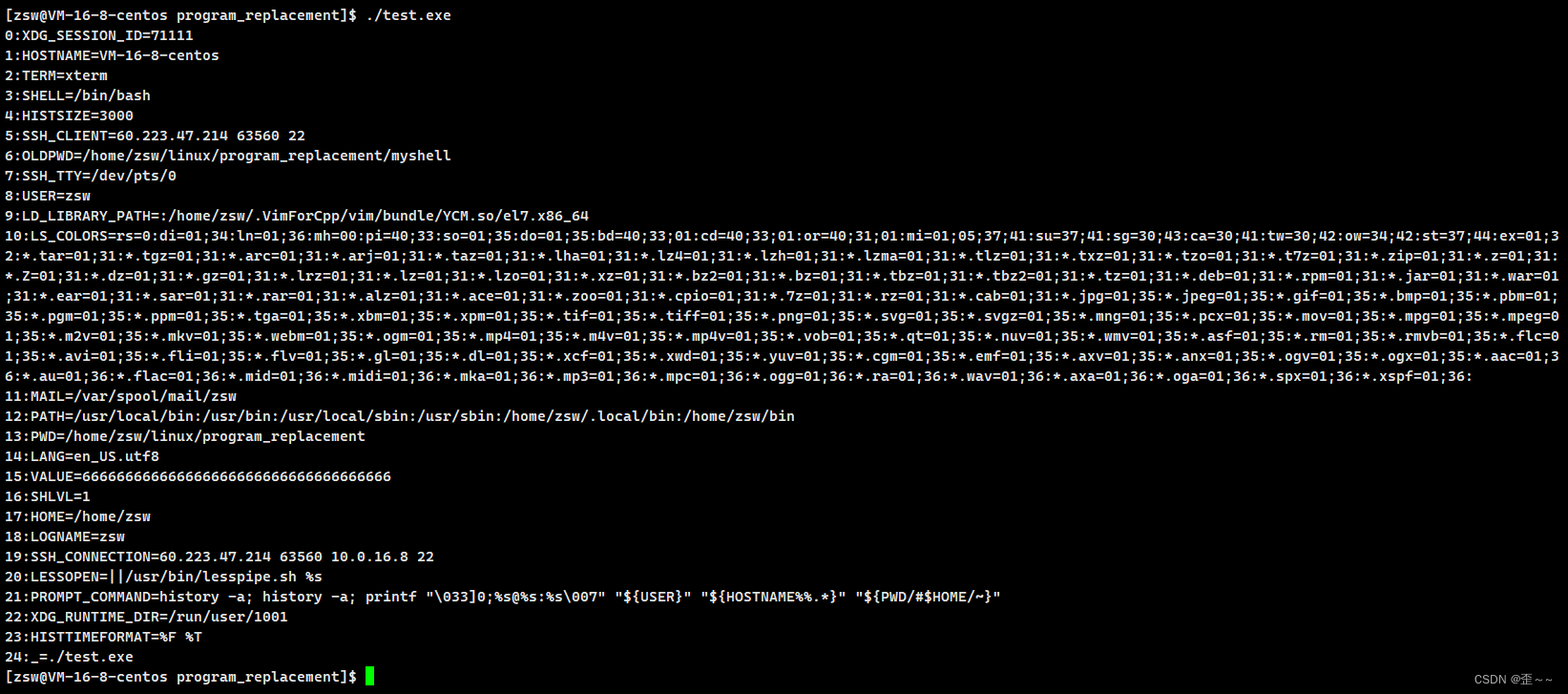
假如我们变化函数的参数,传的是我们自己的数组呢?
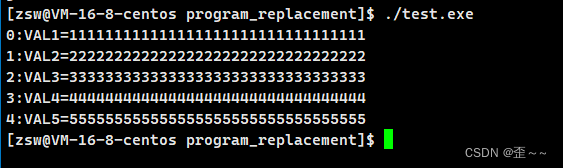
我们看到它会发生覆盖!所以程序替换函数中的环境变量传参是覆盖式传递。那我们想要用父进程给子进程添加环境变量呢?也很简单,在父进程中用putenv就可以了。
至此我们就可以知道程序替换函数可以将命令行参数与环境变量传递给被替换换的程序中。
c. 库函数与系统调用
由上图就可以知道,库函数中这么多的程序替换函数必然是封装了右边的系统调用,那为什么一个函数要被封装成这么多的接口呢?那自然也是为了在实际使用中能够更加的灵活。