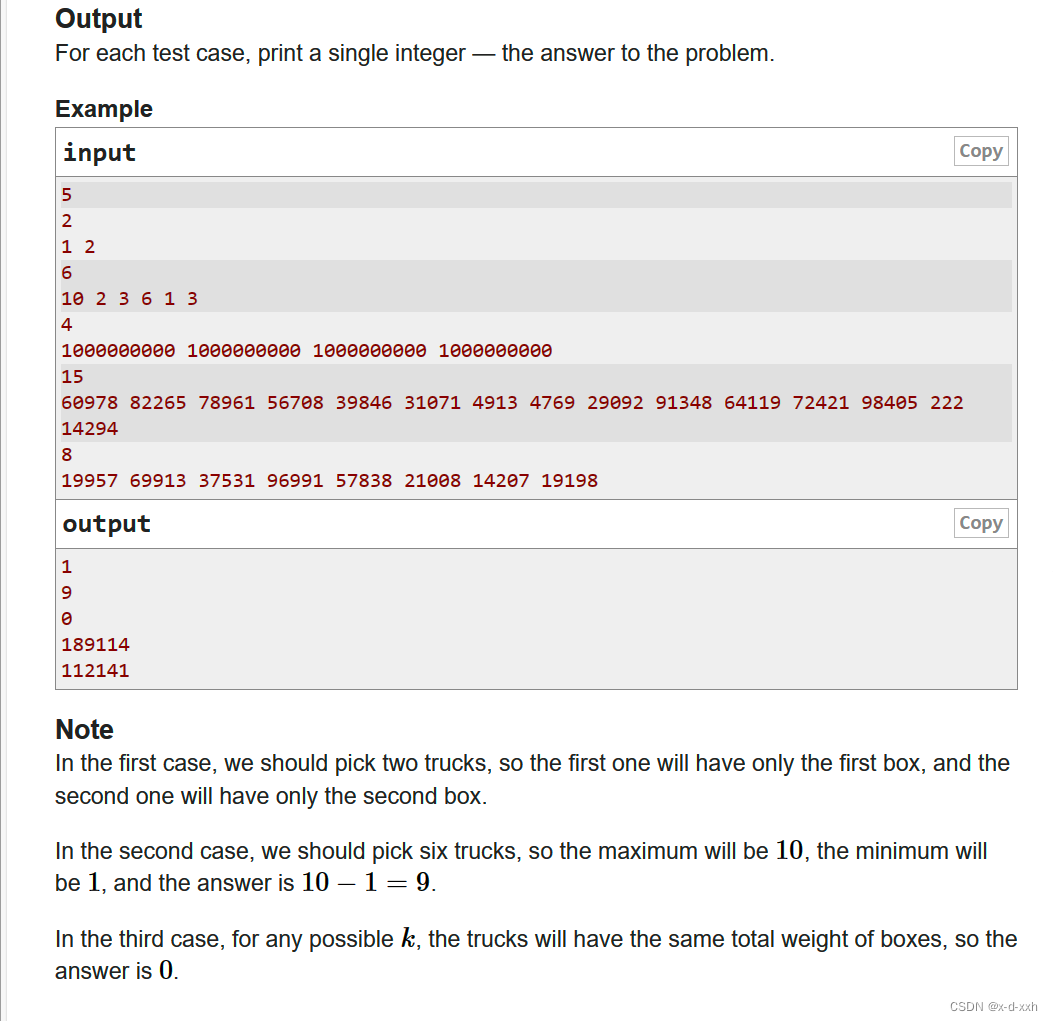
R语言本身并不适合用来爬取数据,它更适合进行统计分析和数据可视化。而Python的requests,BeautifulSoup,Scrapy等库则更适合用来爬取网页数据。如果你想要在R中获取网页内容,你可以使用rvest包。

以下是一个简单的使用rvest包爬取百度图片的例子:
# 安装rvest包
install.packages("rvest")
# 加载rvest包
library(rvest)
# 定义要爬取的网页链接
url <- "目标网站"
# 使用rvest包的read_html函数获取网页内容
webpage <- read_html(url)
# 使用html_nodes函数获取网页中的所有图片链接
image_links <- html_nodes(webpage, "img")
# 使用html_attr函数获取图片链接中的src属性
image_src <- html_attr(image_links, "src")
# 打印出所有的图片链接
print(image_src)注意,以上代码只能爬取百度图片的前10张图片。如果你想要爬取更多图片,你需要修改网页链接中的参数,如start、end等。此外,百度图片的网页内容可能会经常变化,所以你需要根据实际的网页内容来调整代码。
另外,使用爬虫ip是爬虫的常见做法,以避免被目标网站封IP。在Python中,你可以使用requests.get(url, proxies={‘duoip_proxy_host:your_proxy_port’})来设置爬虫ip。在R中,我不清楚是否可以直接设置爬虫ip,但你可以在requests库的文档中查找相关信息。