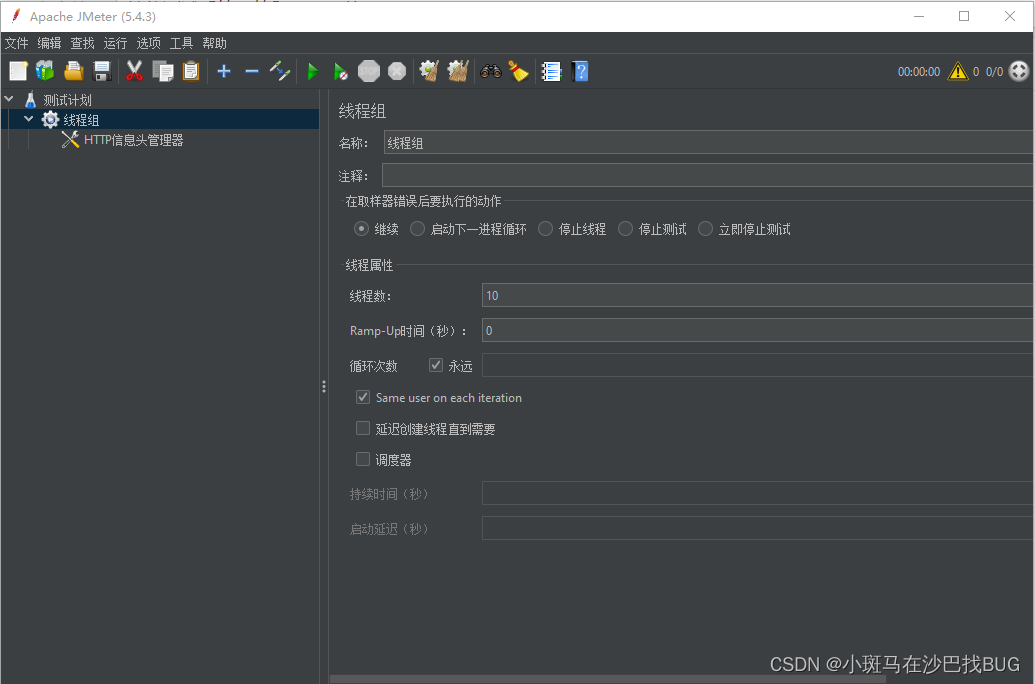
线程数:10 ,设置10个并发
Ramp-Up时间(秒):所有线程在多少时间内启动,如果设置5,那么每秒启动2个线程
循环次数:请求的重复次数,如果勾选"永远"将一直发送请求
持续时间时间:设置场景运行的时间
启动延迟:设置场景延迟启动时间
响应断言
响应断言模式匹配规则
- 包括(Contains):如果响应中包含了指定的字符串,判断为成功,支持正则表达式
- 匹配(Matches):如果响应完全匹配指定的字符串,判断为成功,支持正则表达式
- 相等(Equals):如果响应完全匹配指定的字符串,判断为成功,不支持正则表达式
- 子字符串(Substring):如果响应中包含了指定的字符串,判断为成功,不支持正则表达式
参数化
文件参数化
_csv read:使用场景:比如登录场景,一般从数据库中导入到文件中,再读取文件中的参数
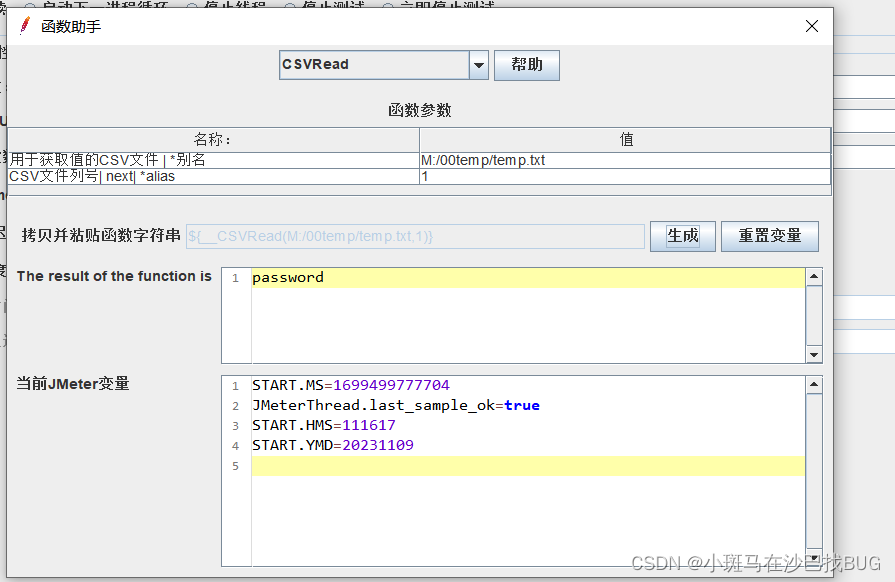
注意:读取数据时,读取顺序:
- 一个接口多线程:多线程顺序取多个数据
- 一个接口一个线程多次循环:一个线程循环多次读取的是相同数据
- 多个接口单线程:读取的是相同数据,适合在:登录-下单场景,使用的都是同一账号
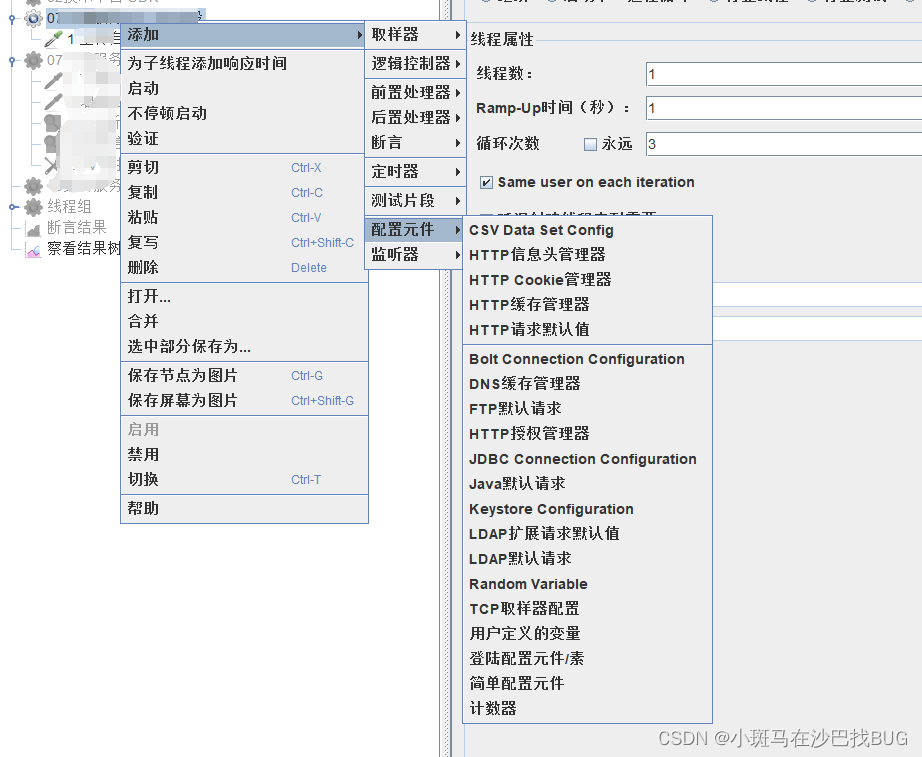
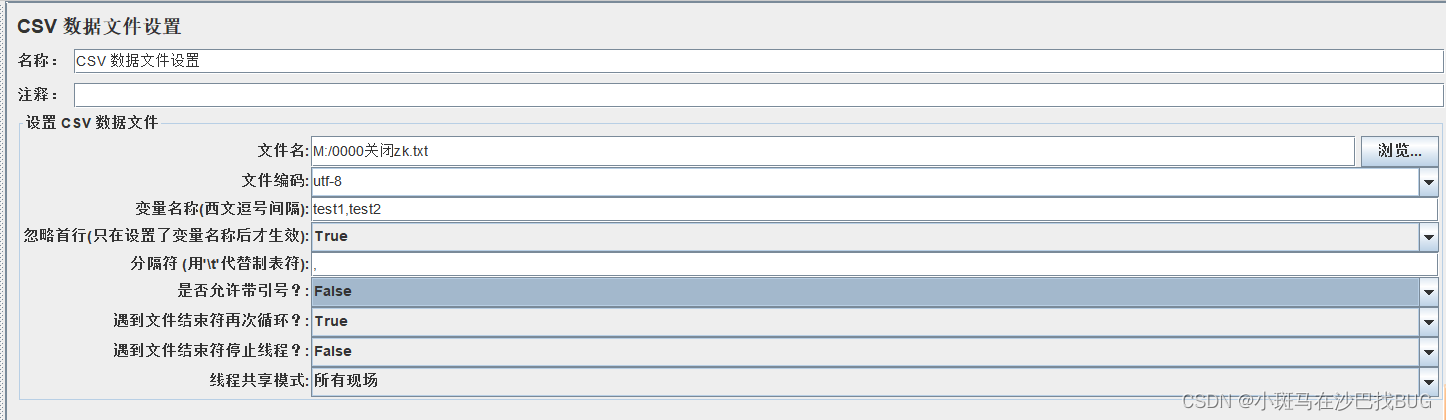
CSV Data Set Config:(工作中用的较多)
添加-配置文件-CSV Data Set Config
时间戳函数:__time
随机数:${__Random(1,100,)}(工作中常用)
生成唯一UUID:${__UUID}
随机字符串:${__RandomString(8,abcdefghigklmnopqrstuvwxyz0123456789,)}
数据关联
实现数据关联的方式有两种
-
Json后置处理器
添加–后置处理器–Json后置处理器
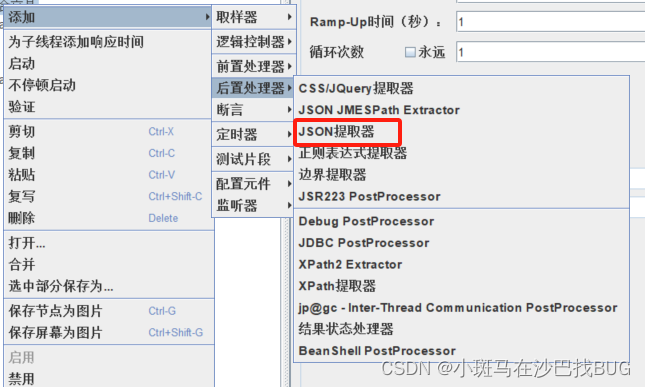
使用提取的变量:
“USER_ID”: “${get_account}”, -
正则表达式提取器
正则表达式:
三步走:
1、拷贝目标数据和左右边界
2、把目标数据用括号括起来
3、把目标数据用.+?代替
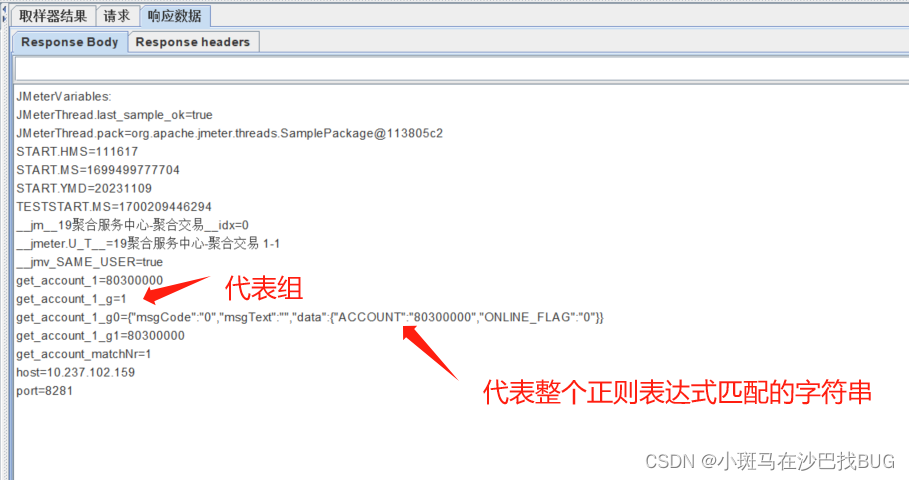
匹配数字:当某组数据中包含多少个参数时,0代表随机,1代表该组的第一个参数,2表示第二
个。。。-1代表获取全部的参数,这个时候,引用名称就变成了参数数组,可以通过param_n来
获取指定的参数,当有多组数据时,第一组为param_1_g1,第二组为param_1_g2
常用正则表达式: