如果不利事件或条件导致系统无法正常运行,则它们可能会对有价值的资产造成各种形式的损害。正如我在本系列的前几篇文章中概述的那样,系统韧性很重要,因为没有人想要一个无法克服“不可避免的逆境”的脆弱系统。
在本系列的第一篇文章中,我通过提供以下更详细和微妙的系统韧性定义来解决这些问题:系统的韧性达到了它快速有效地保护其关键能力免受不利事件和条件造成的伤害的程度。
第二篇文章确定了八个次要质量属性,对可能破坏关键系统的不利因素(即不利条件和事件)进行了分类。
第三篇文章介绍了系统韧性需求的工程,以及如何使用它们来推导下级质量属性的相关需求。
第四篇文章提出了一个用于分类韧性技术的本体,并澄清了韧性要求和韧性技术之间的关系。
本文,亦即本系列的第五篇文章将会列出一个相对全面的韧性技术名单,并用它们执行的韧性功能(即阻力、检测、反应和恢复)进行注释。
01
常用韧性技术
理想情况下,系统的需求将推动选择适当的韧性技术。然而,以架构(architecture)和设计约束的形式,授权使用本文中概述的一种或多种韧性技术作为需求可能是适当的。其中一些韧性技术可能更适合在数据中心使用,而不是在网络物理系统中使用,反之亦然。通常都是使用多种技术来解决检测、响应和恢复,并提供足够的深度防御。
尽管并非详尽无遗,但以下是一个相对完整且具有代表性的韧性技术列表(其中的很多技术可以进一步分为韧性技术的更具体的子类):
警报和警告——反应。使用警报和警告通知操作员和管理员不良条件或事件的检测。
防病毒软件——检测/反应。在恶意软件可能造成危害之前,使用防病毒程序扫描、隔离和删除恶意软件。
断言检查——检测。结合验证断言(例如前置条件和后置条件)是否满足的软件,以检测输入错误和输出故障/失败。代码级断言通常与异常处理相结合。
自动缩放——反应。使用计算硬件和软件(例如虚拟机或容器)的自动扩展,以防止在过度需求期间过载。
自主网络安全代理——检测/反应/恢复。结合自主检测不利安全条件和事件并对其做出反应的软件代理。
后退重试算法——检测/反应。使用逐渐增加重试速率的退避算法,以避免服务请求者重试消息造成的网络拥塞。可以添加抖动以防止重试消息集群。
内置测试(BIT)——检测。结合启动BIT、定期BIT或连续BIT来检查故障和失效。
检查点——恢复。从以前的检查点(即恢复)状态重新启动失败的应用程序。各种类型包括用户触发的检查点、不协调的检查点,协调的检查点和基于消息日志的检查点。检查点类型包括用户启动的检查点、未协调的检查点(即流程独立地恢复为检查点)、协调的检查点检查点。
校验和——检测。要检测消息中的错误,请使用消息的校验和,即消息代码字的模算术和。
断路器模式——反应/恢复。使用位于服务使用者和远程服务提供者之间的断路器对象来监视两者之间消息的成功。如果连续失败的尝试次数超过设置的阈值,断路器跳闸,立即阻止所有进一步的尝试,并设置计时器。超时结束后,断路器允许一些服务请求通过,如果它们的数量达到成功阈值,断路器将重置。Netflix Hystrix就是一个例子。
时钟同步——反应。在开发容错实时系统时,使用容错同步算法在投票之前同步复制处理器,以确定正确的输入或输出。
并发技术——检测。大多数系统的软件都是分布式的(例如跨容器、虚拟机、内核、处理器和计算机)。这种分布导致并发行为、缺乏确定性和并发缺陷。在可行的范围内,使用软件设计检查此类缺陷的影响(例如性能降低、消息无序),并适当处理相关的不利条件(例如饥饿、死锁、活锁、优先级反转、竞争条件)和由此产生的不利事件。
容器化——反应/恢复。使用容器来限制故障传播,并使故障恢复变得更容易、更快。结合冗余、实现多样化和投票来限制网络攻击清除所有复制的能力。
内容缓存——反应。在可以接受过时数据的情况下,缓存内容以确保在发生与数据库相关的中断时的服务连续性。为缓存的数据分配生存时间,以便可以替换过期的内容。选择适当的缓存大小,以避免收回缓存的数据。
循环冗余检查——检测。循环冗余检查是附加到数据块的错误检测代码,用于检测数据意外或恶意数据损坏。
数据类型检查——检测。使用强数据类型并验证输入数据的类型是否正确。输入范围检查和合理性检查是特殊情况。
降级模式操作——反应。为了避免完全失败,请优雅地从正常操作切换到定义良好的适当降级操作模式。系统提供的服务可以通过多种方式降级和恢复:
- 性能或容量降低
- 以较低的质量为代价使用具有更高性能的服务变体
- 基于优先级的服务损失(即,不太重要的系统功能的全部或部分损失)
- 基于优先级的服务恢复(即,首先恢复最重要的服务)
拒绝服务监控——检测。监视入站网络流量的大小,以查看拒绝服务攻击的迹象,以便隔离攻击的目标并识别攻击的来源。
数字签名——检测。使用数字签名来检测对数据真实性、机密性和完整性的侵犯。
不一致检测器——检测。使用检查执行冗余组件的输出一致性的软件来检测(但不定位)故障输出。
纠错码——检测/反应。将冗余数据添加到允许检测错误和重建消息的消息中。
弹性负载平衡——检测/反应。使用负载平衡器来防止在过度需求期间过载。
电磁(EM)屏蔽——阻力。屏蔽电子和电气部件免受自然和对抗源的电磁场、静电场和射频电磁辐射的影响。
异常处理——反应。使用编程语言的异常处理机制来通知客户端软件单元故障和失效(例如违反前置条件或后置条件)。在可行的情况下,尽可能接近引发异常的单元来处理引发的异常,因为处理单元离引发单元越远,正确的处理机制就越不明显。
故障转移——反应。在发生故障时,将自动故障切换整合到冗余硬件或软件(例如,虚拟机或容器)。为了通过最小化停机时间来最大限度地提高恢复能力,热故障切换比热故障切换更好,热故障转移比冷故障切换更好。
故障检测和隔离(FDI)——检测。使用检查用于检测和定位故障组件的单个执行组件的输出正确性的软件。
故障/失效通知消息——反应。将故障/故障通知消息的使用与数据库相结合,将通知消息与其相应的故障/故障反应相链接。
火灾探测和灭火系统(FDSS)——检测/反应。添加检测和抑制火灾的子系统。
哈希函数——检测。使用加密哈希函数来生成安全校验和,该校验和可用于验证数据的完整性和真实性(即检测意外或恶意数据损坏)。
健康检查程序——检测。使用健康检查程序(例如作为负载平衡器的一部分)以给定的速率向资源提供程序发送健康检查消息。运行状况检查可以是浅层的(资源提供程序是否可操作?)或深层的(提供程序所依赖的资源是否可操作)。其他类型的运行状况检查器(例如在硬盘驱动器中)可以识别故障。
心跳——检测。使用心跳信号(由硬件或软件组件发送的周期信号)来指示组件仍在运行。未能接收心跳(通常是一行中的几个)表示组件故障。
无效操作——检测。使用幂等操作实现服务(即,可以重复并始终产生相同结果而不会导致故障或失败的操作)。例如,使用唯一的可跟踪请求标识符,以便可以验证请求状态,并且可以正确处理重复的请求(例如,忽略)。
不可变服务器模式——恢复。不是通过应用配置更改来更新/修复服务器,而是销毁服务器并从已知的、经过良好测试的基本映像中重建它,该映像将服务器的元素重置为已知状态。
实现多样性(又名异构冗余)——检测/反应。使用不同的编程语言或不同的编译器、提供相同功能的不同库、操作系统或操作系统版本、计算机硬件、传感器类型和供应商来实现复制的组件。实施多样性与监控/投票相结合可以检测故障、故障和网络安全攻击。它还可以帮助确保没有共同原因故障会导致所有冗余组件实例。
基础设施及代码——恢复。使用配置脚本自动构建软件基础架构(操作系统和中间件)以实现快速恢复。
联锁——检测/反应。使用机械、电气或卡住的钥匙联锁装置来检测危险并防止相关事故。
入侵检测/防御系统(IDS/IPS)——检测/反应。结合一个商业现成的系统来检测和防止入侵。
线路可更换单元(LRU)——恢复。为了实现模块化恢复,包括可以通过仅打开和关闭系统架构(architecture)中的紧固件和连接器(即LRU)在相对较短的时间内更换为更换部件的硬件。
锁定——检测。在lockstep中执行多个冗余组件,并在提交之前比较输出的一致性。
记录——反应/恢复。记录所有不利条件、不利事件、故障和故障,以支持故障隔离和手动恢复。
奇偶校验位——检测。在传输之前,使用奇偶校验位生成器将一个位添加到一组源比特中,以便设置为1的比特数是偶数(或奇数)。在接收到源比特之后,奇偶校验位检查器确认设置比特的数量仍然是偶数(或奇数)。当翻转奇数个比特时,该技术检测翻转的比特。
物理分离——阻力。在本地或地理位置物理分发资产(例如数据、硬件和软件),以便不利事件(例如攻击、火灾或停电)不会中断任何单个资产的所有副本。例如不要同时运行冗余网络布线,以便弹片或炮火不会损坏两条电线。
预测和健康监测(PHM)——检测。将预测和健康监测子系统整合到:
- 提供关于接近寿命终止的硬件组件的预测,以便在故障或失效发生之前更换它们(预防——而不是韧性)
- 监测其他子系统的健康状况,并对不利条件和不良事件做出适当反应(检测)
辐射硬化——抗性。提供屏蔽,以保护集成电路和硬盘驱动器免受电离辐射引起的翻转位的影响。
重新配置——恢复。重新配置系统,以(1)忽略发生故障的部件,如处理器和传感器,或(2)用备用(即备用)部件更换故障部件。
冗余——响应。整合系统各种组件的冗余,以支持故障转移或重新配置。
重复代码——检测/反应。将每个传输的数据块重复指定的次数,并使用最常见块的值作为正确的值。
备用容量——阻力。提供多余的保留处理和内存容量,以处理过多的负载条件和负载峰值事件。
鲁棒性看门狗——检测/反应。结合鲁棒性看门狗来监控(并对)故障和失效做出反应(例如通过终止虚拟机/容器中的故障应用程序并生成其替换程序)。
安全/安保哨兵——检测。结合一个安全哨兵来监控系统安全(例如识别危险、响应事故),并结合一个安保哨兵来监测系统安全性(例如违反安全政策和敏感数据的完整性)。
安全寿命设计——阻力。结合使用寿命过长的硬件,以增加寿命,从而抵抗过度寿命。
传感器验证——检测/反应。检查传感器输出的合理性,并比较冗余传感器的输出,以检测传感器故障,并确定哪些传感器正在提供合理的信息。在某些环境条件下(例如浓雾期间的可见光摄像头和大雨或大雪期间的激光雷达),传感器可能变脏和/或发生物理故障,并提供不充分的信息。
无状态软件应用程序——反应/恢复。为了简化响应和恢复,请使用仅依赖于输入参数而不是某种存储数据的无状态软件应用程序。
电涌保护器——检测/反应。使用电涌保护器保护电气设备免受损坏的电涌。
超时——检测/反应。当服务请求(如数据库查询)需要过多的时间才能完成时,因此请求线程可能会快速超过可用连接的数量,使用超时以便使连接可用于其他请求者。
投票——反应。使用投票来确定哪个冗余组件发生故障,并确定要使用哪个输出。
虚拟化——反应/恢复。使用虚拟机和虚拟机管理程序来限制故障传播,并使故障恢复变得更容易、更快。结合冗余、实现多样化和投票来限制网络攻击清除所有复制的能力。
脆弱性消除——阻力。消除安全和安保漏洞,使危险和威胁不会导致事故和攻击达成。
看门狗计时器(WDT)-检测/恢复。使用看门狗计时器自动重新启动发生故障的计算机。如果计算机不定期重置看门狗计时器(即,如果看门狗超时),则看门狗定时器重置计算机(主要是嵌入式计算机)。
02
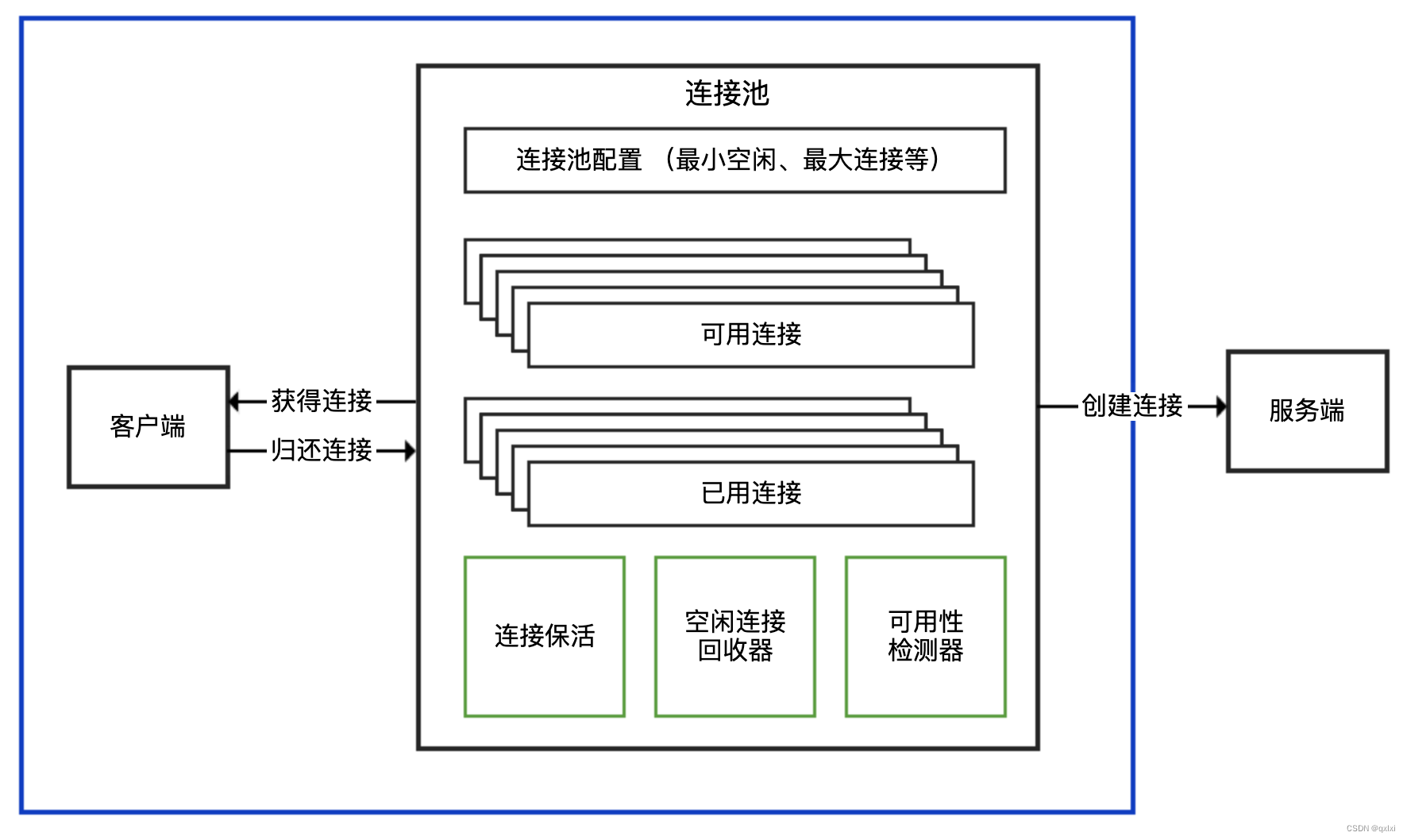
基于冗余的韧性技术
冗余对韧性非常重要。因此,值得研究冗余的类型(和相关的子类型)。下面的UML类图说明了许多支持韧性的最常用冗余技术:

黄色子类。冗余可以根据用于提供冗余的副本或变体的数量进行分类。
橙色子类。冗余可以是同质的(即,产生硬件、操作系统或软件的相同副本的复制)或异构的(即创建不相同的变体,例如不同的硬件、操作制度或编程语言)。
紫色子类。冗余可以是被动的(例如,通过过度设计过多的冗余组件来满足过多的负载或解决组件故障)或主动冗余(即,正确使用冗余需要检测、应对和从逆境中恢复)。
蓝色子类。冗余可以是并行的(如果冗余组件同时执行)或串行的(如果组件按顺序执行)。基于是否通过投票或使用错误检查软件来确定正确处理的标识,可以进一步分解并行冗余。带表决的并行冗余通过冗余组件的数量进一步分类,并对其输出进行比较。相反,串行冗余(也称为时间冗余)通常使用从故障组件到冗余组件的热、热或冷故障切换来实现。为了满足不利的高负载,可以通过根据需要旋转冗余服务器、软件容器或软件虚拟机来实现扩展(例如,在云计算数据中心中)。
粉色子类。冗余可以包括冗余数据、冗余硬件和冗余软件的某种组合(例如,通过容器和虚拟机)。
上面的四个主要冗余分类是正交的,任何特定的实现通常都涉及实例化这些分类层次结构中的每一个。例如,带投票的并行冗余是一种活动冗余形式,通常涉及冗余硬件和软件,每个都可以是同质的或异构的。
03
总结与展望
显然有许多技术可用于实现系统韧性要求。这些技术可以通过多种方式进行分类,其中最重要的两种是按韧性功能和实施方式分类。这种丰富的技术和技术类型为系统架构师和专业工程师在确保足够的韧性方面提供了很大的灵活性,特别是在使用多层纵深防御方法时。另一方面,结合韧性技术会增加系统的复杂性,因此可能会降低系统的韧性。选择正确数量、类型和平衡的韧性技术绝非易事。
下一篇文章亦即本系列的第六篇文章将讨论系统韧性的测试和评估。
敬请期待。

![环境配置 | Git的安装及配置[图文详情]](https://img-blog.csdnimg.cn/bf09e8b40c7d42c6b4e85a1abbc419ce.png)