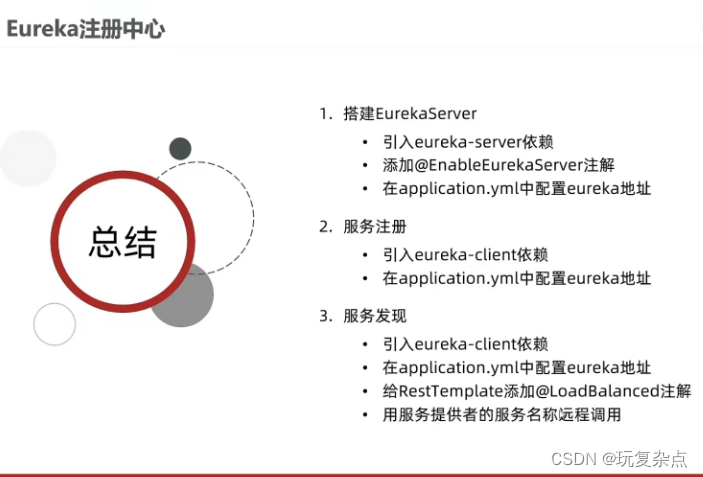
文章目录
- 前言
- 一、原始代码
- 二、对每一行代码的解释:
- 总结
前言
这是该系列原型网络的最后一段代码及其详细解释,感谢各位的阅读!
一、原始代码
if __name__ == '__main__':##载入数据labels_trainData, labels_testData = load_data() # labels_trainData是字典,是key:value形式class_number_train = max(list(labels_trainData.keys())) #963class_number_test = max(list(labels_testData.keys())) #658wide = labels_trainData[0][0].shape[0] # 105 #二维张量,shape[0]代表行数,shape[1]代表列数length = labels_trainData[0][0].shape[1] # 105for label in labels_trainData.keys():labels_trainData[label] = np.reshape(labels_trainData[label], [-1, 1, wide, length])for label in labels_testData.keys():labels_testData[label] = np.reshape(labels_testData[label], [-1, 1, wide, length])##初始化模型protonets = Protonets((1, wide, length), 10, 5, 5, 60, './log/', 50) # '''根据需求修改类的初始化参数,参数含义见protonets_net.py'''##训练prototypical_networkfor n in range(100): ##随机选取x个类进行一个episode的训练protonets.train(labels_trainData, class_number_train)if n % 2 == 0 and n != 0: # 每5次存储一次模型,并测试模型的准确率,训练集的准确率和测试集的准确率被存储在model_step_eval.txt中torch.save(protonets.model, './log/model_net_' + str(n) + '.pkl')protonets.save_center('./log/model_center_' + str(n) + '.csv')test_accury = protonets.evaluation_model(labels_testData, class_number_test)print(test_accury)str_data = str(n) + ',' + str(' test_accury ') + str(test_accury) + '\n'with open('./log/model_step_eval.txt', "a") as f:f.write(str_data)print(n)
二、对每一行代码的解释:
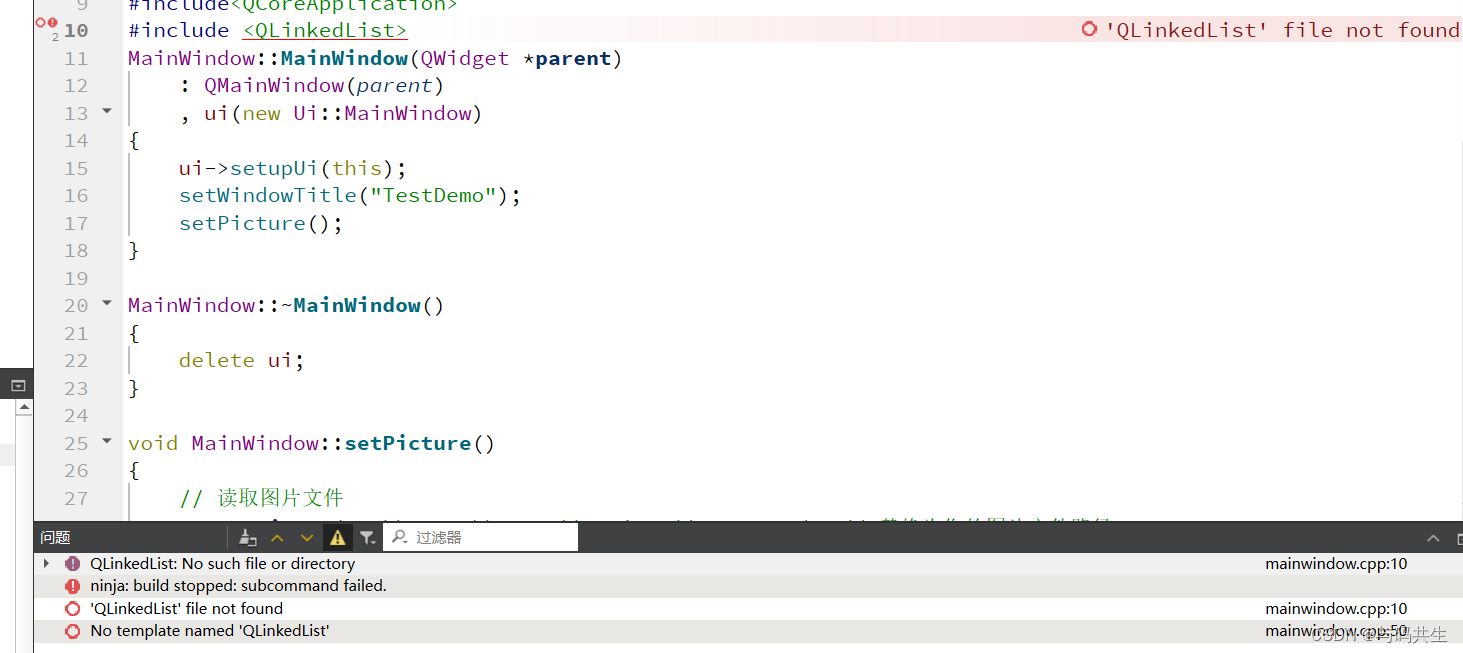
-
if __name__ == '__main__':
这是一个Python的惯用写法,表示当脚本直接被运行时(而不是被作为模块导入时),才会执行下面的代码块。 -
labels_trainData, labels_testData = load_data()
调用load_data()函数加载数据,并将返回的标签训练数据和标签测试数据保存到labels_trainData和labels_testData变量中。 -
class_number_train = max(list(labels_trainData.keys()))
获取标签训练数据中的最大键(即最大类别数),并将其保存到class_number_train变量中。 -
class_number_test = max(list(labels_testData.keys()))
获取标签测试数据中的最大键(即最大类别数),并将其保存到class_number_test变量中。 -
wide = labels_trainData[0][0].shape[0]
获取标签训练数据中第一个样本的宽度,并将其保存到wide变量中。 -
length = labels_trainData[0][0].shape[1]
获取标签训练数据中第一个样本的长度,并将其保存到length变量中。 -
for label in labels_trainData.keys():
遍历标签训练数据中的所有键。 -
labels_trainData[label] = np.reshape(labels_trainData[label], [-1, 1, wide, length])
对每个标签训练数据进行重塑,将其形状改为[-1, 1, wide, length],其中-1表示自动计算维度大小。 -
for label in labels_testData.keys():
遍历标签测试数据中的所有键。 -
labels_testData[label] = np.reshape(labels_testData[label], [-1, 1, wide, length])
对每个标签测试数据进行重塑,将其形状改为[-1, 1, wide, length]。 -
protonets = Protonets((1, wide, length), 10, 5, 5, 60, './log/', 50)
创建一个Protonets类的实例,传入模型的初始化参数。 -
for n in range(100):
从0到99的循环中,执行以下代码块。 -
protonets.train(labels_trainData, class_number_train)
调用protonets实例的train()方法进行模型训练,传入标签训练数据和类别数。 -
if n % 2 == 0 and n != 0:
如果n是偶数且不为0,则执行以下代码块。 -
torch.save(protonets.model, './log/model_net_' + str(n) + '.pkl')
保存模型到'./log/model_net_' + str(n) + '.pkl'的文件路径。 -
protonets.save_center('./log/model_center_' + str(n) + '.csv')
调用protonets实例的save_center()方法,将模型的中心点保存到'./log/model_center_' + str(n) + '.csv'。 -
test_accury = protonets.evaluation_model(labels_testData, class_number_test)
调用protonets实例的evaluation_model()方法,对模型进行评估并返回测试准确率,将其保存到test_accury变量中。 -
print(test_accury)
打印测试准确率。 -
str_data = str(n) + ',' + str(' test_accury ') + str(test_accury) + '\n'
构建一个字符串以保存到文件中。 -
with open('./log/model_step_eval.txt', "a") as f:
打开一个文件,以追加模式写入。
总结
原型网络(Prototypical Network)是一种用于小样本学习的模型,由Jake Snell等人于2017年提出。它是一种基于元学习(meta-learning)的方法,主要用于解决在具有少量标记样本的情况下进行分类任务的问题。
传统的深度学习模型在处理小样本学习时通常表现不佳,因为它们需要大量的标记样本来进行训练。然而,在现实世界中,我们往往只有少量标记样本可用。原型网络通过引入一个用于表示类别的中心向量(原型)的概念,解决了这个问题。
原型网络的功能和优势如下:
-
小样本学习:原型网络适用于具有少量标记样本的分类任务,可以在只有几个样本可用时进行准确的分类。 -
元学习能力:原型网络通过学习类别的原型向量,能够在遇到新类别时进行快速学习,从而实现元学习的目标。 -
欧氏距离度量:原型网络使用欧氏距离来度量样本与原型之间的相似性,从而进行分类推断。这种度量方式非常直观和可解释,使得模型更易于理解




![[nlp] 损失缩放(Loss Scaling)loss sacle](https://img-blog.csdnimg.cn/7a1a6f1924374a3eb4c0b1ce649bab0b.png)