Abstract
JINA EMBEDINGS构成了一组高性能的句子嵌入模型,擅长将文本输入转换为数字表示,捕捉文本的语义。这些模型在密集检索和语义文本相似性等应用中表现出色。文章详细介绍了JINA EMBEDINGS的开发,从创建高质量的成对(pairwise)和三元组数据集(triplet datasets)开始。它强调了数据清理在数据集准备中的关键作用,深入了解了模型训练过程,并使用Massive Text Embedding Benchmark(MTEB)进行了全面的性能评估。此外,为了提高模型对语法否定的认识,构建了一个新的否定(negated)和非否定(non-negated)语句的训练和评估数据集,并向社区公开。
1.
Jina Embeddings模型集实在T5结构上通过对比学习训练而成。选择使用T5模型作为基础,因为它在一组混合的下游任务上进行了预训练。我们的大规模对比微调方法超越了zero-short T5,并提供了与其他领先的基于T5的句子嵌入模型(如句子-T5和GTR)相当的性能水平。这项工作表明,通过明智地使用资源和创新的训练方法,可以实现高质量的句子嵌入。
2. 数据准备
- 格式
这里的格式分为二元组和三元组,对于未提供不相关信息的数据,用二元组表示为 ( q , p ) ∈ D p a i r s (q, p) \in D_{pairs} (q,p)∈Dpairs, q q q 表示query, p p p 表示之相关的target;对于提供了不相关信息的数据,用三元组表示为 ( q , p , n ) ∈ D t r i p l e t s (q, p, n) \in D_{triplets} (q,p,n)∈Dtriplets,其中 q q q 表示query, p p p 表示与这个query相匹配的正样本, n n n 表示与这个query不匹配的负样本 n n n - 数据提取
用于提取二元组和三元组的方法特定于每个源数据集。例如,给定一个问答数据集,我们将问题用作查询字符串,将答案用作目标字符串。检索数据集通常包含可以作为查询字符串的queries,以及可以作为匹配字符串和非匹配字符串操作的相关和非相关注释文档。 - 训练步骤
训练流程是一个两步的方法,第一步我们使用二元组数据进行训练,第二步使用三元组数据对模型进行微调
2.1 二元组数据准备
许多大型数据集的庞大规模和不一致的质量需要严格的过滤管道。我们应用以下步骤来筛选训练数据:
- 去除重复数据:训练数据中重复的条目可能会对模型性能产生负面影响,并可能导致过度拟合。因此,我们从数据集中删除重复条目。考虑到数据集的体积,我们使用哈希函数来识别和消除映射到重复哈希值的文本对。在检查重复项之前,我们对空白和大写进行规范化。空白pairs和具有相同元素的pairs也会被删除。
- 语言过滤:由于设计的是针对英语的embedding模型,所以使用基于fasttext text 分类方法的fasttext-language-identification模型来移除数据中的非英语项。
- 一致性过滤:一致性过滤是指排除语义相似度较低的训练对。先前的研究表明,使用辅助模型(尽管不太精确)消除低相似性对可以提高性能。本文使用all-MiniLM-L6-v2模型来进行一致性过滤:从 D p a i r s D_{pairs} Dpairs里面随机选取1M的pairs ( q i , p i ) i (q_i, p_i)_i (qi,pi)i,然后生成embeddings。对于数据集里面的每个pair对 ( q , p ) ∈ D p a i r s (q, p) \in D_{pairs} (q,p)∈Dpairs,我们会计算出 p p p 和 q q q 的余弦相似度,同时计算出之前随机选择的1M的文档与 q q q 的余弦相似度,然后验证一下 p p p 与 q q q 的余弦相似度是不是排在前二。
这些预处理步骤的应用将数据集的大小从超过15亿个混合质量pair减少到3.85亿个高质量pair。这种减少使我们能够在不牺牲embedding质量的情况下,用比经典embedding模型少得多的数据来训练我们的模型。
2.2 三元组数据的准备
对于三元组数据集,我们放弃了重复数据消除和语言过滤,并假设这些数据集的质量已经满足我们的质量要求。然而,我们以类似于一致性过滤的方式验证了正样本相对于每个三元组的query的相关性。这里没有像一致性过滤一样拿 q q q 和 p p p 的余弦相似度与 q q q 和一组随机文档的余弦相似度进行比较,而只是将同一个三元组 ( q , p , n ) (q, p, n) (q,p,n) 的 s ( q , p ) s(q, p) s(q,p) 和 s ( q , n ) s(q, n) s(q,n) 进行了比较。 s ( ) s() s() 表示余弦相似度。这是用一个 cross-encoder 模型完成的,该模型直接评估pair,而不生成embedding表示。更具体地说,我们利用ms-marco-MiniLM-L-6-v2模型来验证由该模型确定的检索得分的差异是否超过阈值 r ( q , p ) − r ( q , n ) > κ r(q, p)−r(q, n)>κ r(q,p)−r(q,n)>κ,阈值 κ = 0.2 κ=0.2 κ=0.2,并消除分差没有超过阈值的pairs。
2.3 否定数据的准备
我们观察到,许多嵌入模型难以准确嵌入否定的语义。比如当给下面三个句子进行embedding时,“A couple walks hand in hand down a street.”, “A couple is walking together.”,“A couple is not walking together.”,前两个句子的embedding应该靠近的,第二个句子和第三个句子的embedding应该是远离的。但是有些模型,比如all-MiniLM-L6-v2给前两个句子计算的余弦相似度为0.7,而给第二个和第三个句子计算的余弦相似度为0.86。
本文通过创建自己的否定数据集(negation dataset)来解决这个问题。这个数据集从SNLI数据集里面拿到正样本对,使用GPT-3生成负样本对,组成类似上面例子里面的三元组,其中(anchor, entailment) 组成一个正样本对,而"negative"与"anchor"和"entailment"相对立,同时要保证"negative"和"entailment"在语法上非常相似。该数据集形成了我们前面提到的三元组数据集的子集,第3.3节提供了训练细节。我们对否定数据集的模型评估,包括与其他流行的开源模型的比较分析,如第4.3节所示。
2.4 数据构成
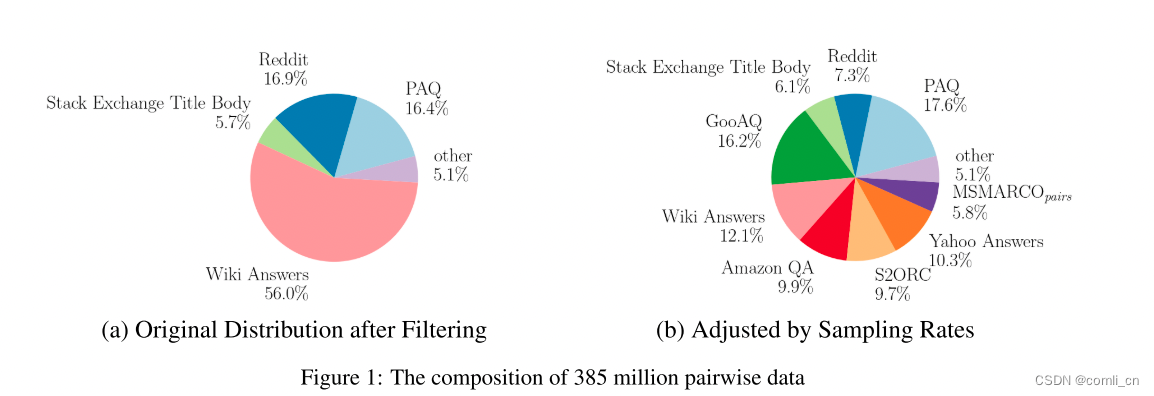
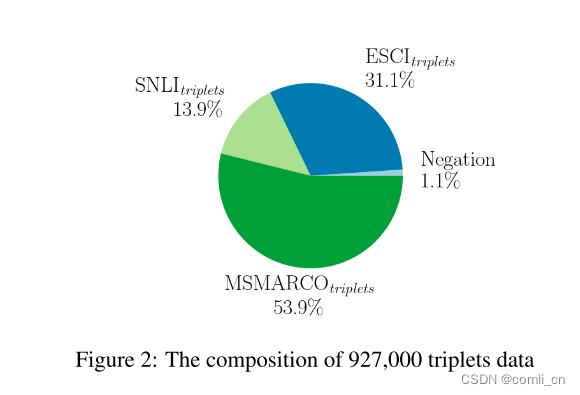
我们的文本对数据集是由32个独立的数据集聚合而成的,表示为 D p a i r s = D 1 ⊔ ⋯ ⊔ D n D_{pairs}=D_1\sqcup \cdots \sqcup D_n Dpairs=D1⊔⋯⊔Dn。在过滤之前规模达到了16亿对,其随后在严格过滤之后被减少到鲁棒的3.85亿个高质量对。相比之下,我们的三元组数据集在过滤前最初共包含113万个条目,过滤后精简为927000个三元组。过滤后数据集的组成如图1a中文本对所示,如图2中三元组所示。这些共同构成了JINA EMBEDINGS模型训练的最终数据集。
3. 训练
训练分为两个阶段。第一阶段的中心是使用大量的二元组文本对训练模型,将整个文本短语的语义整合为一个具有代表性的embedding。第二阶段使用相对较小的三元组数据集,包括一个anchor、一个entailment和一个hard-negative,教它区分相似和不同的文本短语。
3.1 在二元组数据上训练
JINA EMBEDDINGS集合中的每个模型都基于相应尺寸的zero-shot T5模型并使用其进行训练。zero-shot T5模型由encoder-decoder对组成。然而,Ni等人已经证明,与同时部署编码器和解码器相比,仅使用T5模型的编码器组件来计算文本嵌入更有效。因此,JINA embedding models仅使用其各自T5模型的编码器。
在tokenization的时候,INA EMBEDINGS模型使用SentencePiece对输入文本进行分段,并将其编码为WordPiece token。在编码器模型之后,实现了平均池化层(mean pooling layer),以从token embedding生成固定长度的表示。
对于涉及pair的训练过程,我们使用InfoNCE作为对比损失函数。这个函数用于计算 ( q , p ) (q, p) (q,p) 对的的损失,其中 ( q , p ) (q, p) (q,p) 是从B中随机抽取的一个样本对,而B是数据集 D k D^k Dk 的一个batch,batch size为 k k k,函数如下:
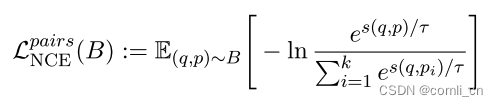
loss是通过比较给定的问题 q q q 和它的目标 p p p 的余弦相似度和 q q q 与同batch里面其他目标 p p p 的余弦相似度给计算出来的。我们发现,计算两个方向的损失可以在训练中得到更大的改善。因此损失函数定义如下:
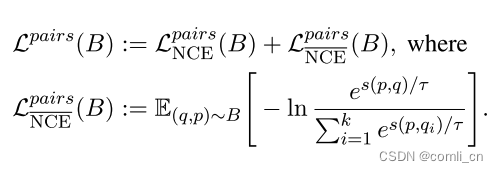
直观地说, L p a i r s N C E \mathcal {L}_{\frac{pairs}{NCE}} LNCEpairs 将目标字符串与所有查询字符串匹配。常数 τ \tau τ 表示温度参数,我们将其设置为 τ = 0.05 τ=0.05 τ=0.05。
3.2 数据采样和二元组训练
我们选择并行方法,同时在所有数据集上进行训练,而不是在单个数据集上顺序训练。我们假设这种并行训练促进了在不同任务中增强的模型泛化。尽管如此,每个训练batch都完全由来自单个数据集的数据组成。这样可以确保在整个批次中执行的损失计算不会将来自不同任务的数据混为一谈。(这里描述的方法在LLM-Embedder里面也用到了。)
我们的数据加载器首先选择一个数据集,然后从中采样必要数量的数据点,为worker(参见第四节)组成一个批次。在训练之前,数据集中的配对会被彻底打乱。对数据集 D i D_i Di 进行采样遵循所有数据集 D i D_i Di 的概率分布 ρ ρ ρ。对 D i D_i Di 的采样概率为 ρ ( D i ) = ∣ D i ∣ s i ∑ j = 1 n ∣ D j ∣ s j ρ(D_i) = \frac {\left|D_i \right|s_i}{\sum^n_{j=1}\left|D_j \right|s_j} ρ(Di)=∑j=1n∣Dj∣sj∣Di∣si ,并且取决于数据集的大小 ∣ D i ∣ |D_i| ∣Di∣和缩放因子 s i s_i si。
考虑到数据集大小的差异,经常从较大的数据集进行采样以防止对较小的数据集过度拟合是至关重要的。此外,我们使用比例因子操纵数据集的采样率,以优先在高质量数据集上进行训练,并实现文本领域之间的平衡。在采样率较高的数据集在训练epoch完成前耗尽其数据的情况下,数据集会被重置,从而使模型能够重新循环其项目。这确保了高采样率数据集在单个训练epoch内贡献多次。
图1b显示了基于采样率使用的每个数据集的比例。在创建了这种调整后的分布后,从较大数据集进行采样的频率显著降低,导致在训练过程中实际使用的对数只有1.8亿对。
3.3 在三元组上的训练
在完成二元组数据集训练后,模型进入下一阶段,该阶段涉及在三元组数据集上进行训练。此阶段使用不同的损失函数,利用负样本来提高模型性能。
我们对各种三元组损失函数进行了实验,发现通过组合多种常用的三元组损失函数可以获得最佳结果。具体来说我们使用infoNCE损失函数的扩展版本 L t r i p l e t s N C E + \mathcal {L}_{\frac{triplets}{NCE+}} LNCE+triplets,如式(2),它利用了额外的负样本,初始训练阶段的反向InfoNCE损失 L t r i p l e t s N C E \mathcal {L}_{\frac{triplets}{NCE}} LNCEtriplets ,如(3) 所示,triplet margin loss函数如(4)所示:
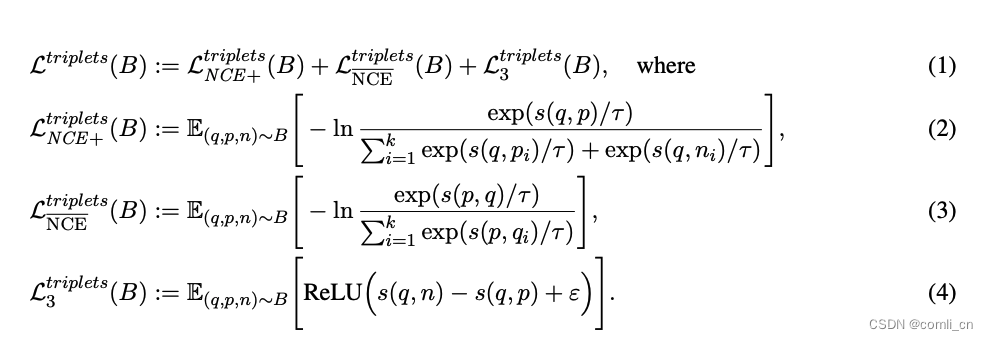
L t r i p l e t s 3 \mathcal {L}_{\frac{triplets}{3}} L3triplets query和target之间的余弦相似度 s ( q , n ) s(q, n) s(q,n),以及query和其对应的负样本 s ( q , n ) s(q, n) s(q,n)。此外,它在这两个值之间建立了最小margin ε = 0.05 ε=0.05 ε=0.05。如果负样本与query更相似,或者违反了margin, L t r i p l e t s 3 \mathcal {L}_{\frac{triplets}{3}} L3triplets将返回一个正值。否则,它的值0,这是通过应用ReLU激活函数来实现的。对于温度参数,我们选择了 τ = 0.05 τ=0.05 τ=0.05 的值。
4. Evaluation
我们进行了全面评估,将我们的模型与其他最先进的模型进行比较(第4.1节),调查我们的过滤管道的影响(第4.2节),并评估模型对否定陈述的敏感性(第4.3节)。第6节提到了训练的细节。为了提供适用于嵌入的各种下游任务的模型性能的全面结果,我们依赖于Muennighoff等人引入的MTEB基准框架。这也包含了BEIR基准测试中包含的所有检索任务。我们还在模型的hugging face页面上发布了在模型上执行它的代码。对于在否定数据集上评估模型,我们使用自己的单独评估工具
4.1 与最先进模型的性能比较
为了衡量JINA embedding集相对于其他类似规模的开源和不开源模型的性能,我们从五个不同的规模类别中选择了具有代表性的模型,如表1所示。此外,我们还对比了包括sentence-t5和gtr-t5 xl和xxl模型,它们分别基于具有30亿和110亿参数的t5模型。这种对比有助于研究这种大规模模型的性能变化。
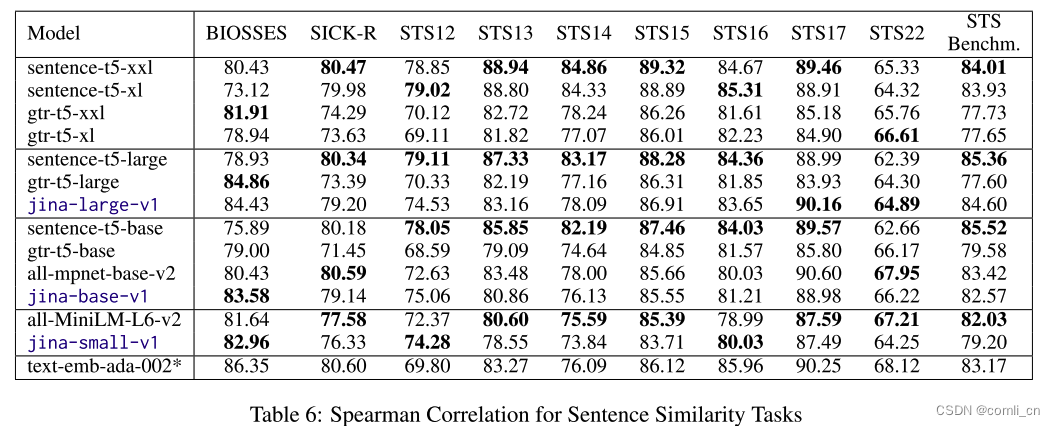
表6显示了MTEB的句子相似性任务的得分,其中JINA EMBEDINGS集合中的模型在许多任务中都超过了类似大小的模型。值得注意的是,jina-large-v1模型始终提供与十亿参数范围内的模型相当(如果不是更好的话)的结果。jina-base-v1和jina-mall-v1在类似尺寸的模型上也表现出出色的性能,在BIOSESS任务上超过了同行。这突出了使用高度多样化的数据源进行训练的好处。
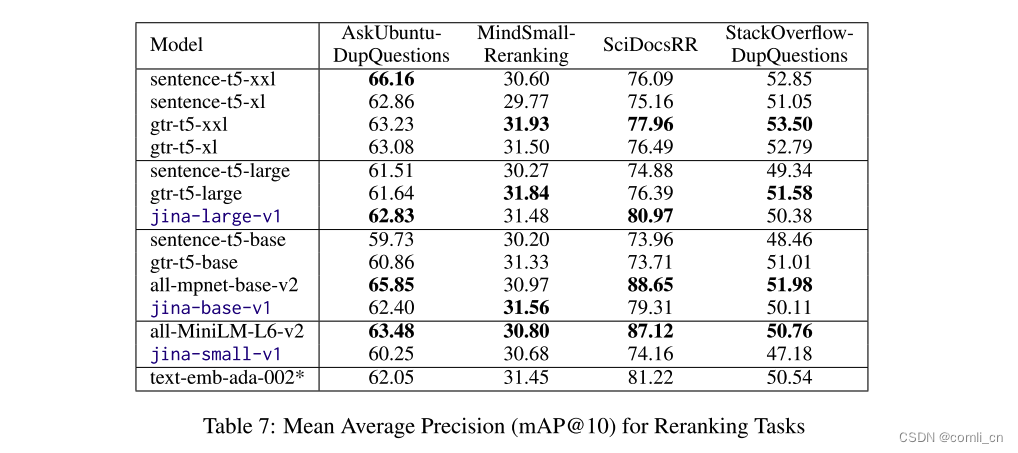
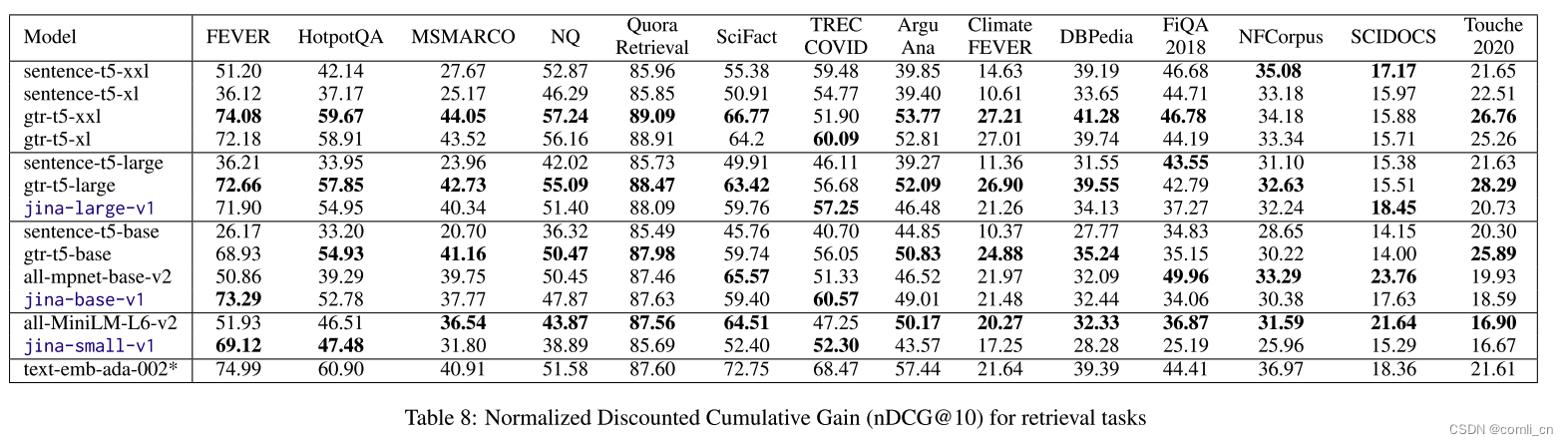
jina-base-v1始终表现出与专门为检索任务训练的gtr-t5-base相似或更好的性能。然而,它很少与在句子相似性任务中训练的sentence-t5-base的分数相匹配。表8所示的模型在检索任务中的性能评估反映了gtr-t5、sentence-t5和JINA EMBEDINGS之间的相似关系。在这里,经过专门训练的gtr-t5模型在相应的模型大小上始终得分最高。JINA EMBEDDING模型紧随其后,而sentence-t5模型明显靠后。JINA EMBEDINGS系列模型能够在这些任务中保持有竞争力的分数,这突出了多任务训练的优势。如表7所示,jina-large-v1在rerank任务上也取得了极高的分数,优于另外两个模型的large版本。
4.2 过滤步骤的影响
我们通过进行消融研究来评估数据集预处理pipeline的有效性。在这项研究中,我们对Reddit数据集上的最小模型进行了微调,其中分别应用了各种预处理步骤。相应的结果如表3所示。
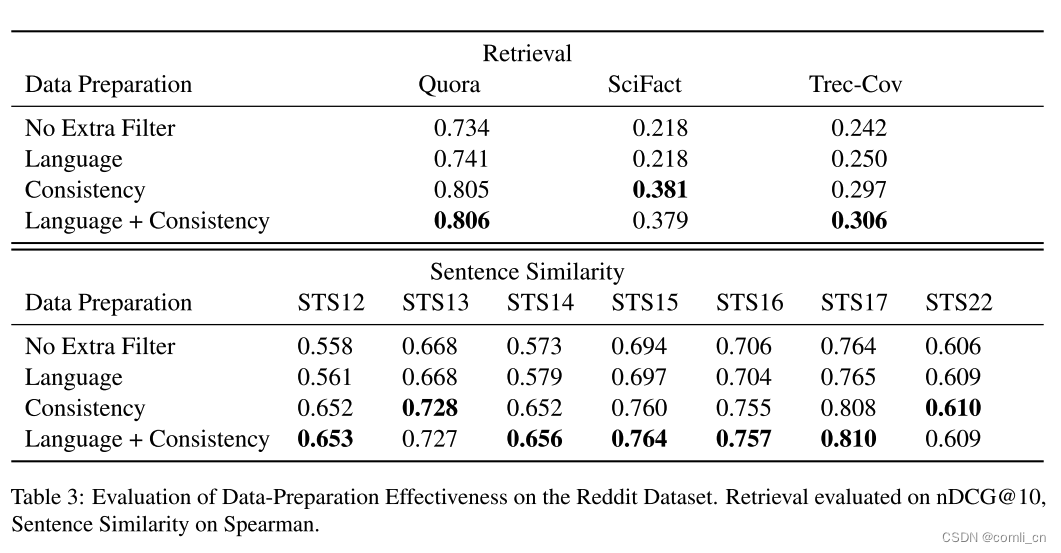
消融研究的结果强调了语言过滤和一致性过滤作为关键预处理步骤的价值。它们的组合应用可在大多数基准测试中获得最高性能。特别是对于Reddit数据集,我们观察到一致性过滤的应用显著提高了性能,而语言过滤仅略微提高了性能。我们可以通过注意到语言过滤器只删除了17.4%的Reddit数据来解释这种差异,而一致性过滤则屏蔽了84.3。Reddit样本主要是英文的,但许多都是正样本pair,相似度很低,这使得一致性过滤比语言过滤更有效。
然而,这些预处理步骤的有效性在不同的数据集之间确实存在差异。
4.3 否定数据的有效性
为了确定我们的模型对否定数据的有效性,我们根据从否定数据集中划分出来的的测试集对它们进行评估,并将结果与其他开源模型进行比较。我们根据两个指标来衡量性能:一种是计算模型将anchor与entailment放置地比anchor与negative更近的百分比(这是一项容易的任务,因为anchor和negative在语法上是不同的),另一种是计算模型将anchor与entailment放置地比entailment与negative更近的百分比(这是一项艰巨的任务,因为entailment和negative在句法上anchor和entailment更相似)。前者表示为EasyNegation,后者表示为HardNegation。这些评估的结果如表4所示。我们在对三元组数据进行微调之前和之后评估我们的模型,分别表示为 < m o d e l > p a i r w i s e <model>_{pairwise} <model>pairwise 和 < m o d e l > a l l <model>_{all} <model>all。从结果中,我们观察到,在所有模型大小中,对三元组数据(包括我们的否定训练数据集)的微调显著提高了性能,尤其是在Hard-Negative任务中。我们的模型在性能方面与其他最先进的开源模型不相上下,而实现这一点只需同行所需的一小部分训练数据。
5. 相关工作
多年来,embedding模型领域取得了重大进展,开发了各种具有不同架构和训练pipelines的模型。比如Sentence-BERT使用BERT来生成句子的embedding。相似的,基于T5模型encoder结构的Sentence-T5在很多测试基准上的表现超过了Sentence-BERT。Muennighoff的论文SGPT: GPT Sentence Embeddings for Semantic Search 强调了编码器对句子嵌入的有效性,并与另一种探索解码器使用的方法进行了对比。知识蒸Distilling the Knowledge in a Neural Network为模型训练提供了一种替代方法。在这种设置中,一个较大的、预先训练过的模型充当导师,在训练期间指导一个较小的模型。这种方法可以与对比损失函数无缝集成,为未来的研究提供了途径。
embedding模型也可以基于其功能来表征。例如,虽然一些模型被设计为仅embed queries,但其他模型被训练为embed queries和特定instructions,从而生成依赖于任务的embeddings。使用基于T5的模型的一个例子是大型双编码器,它针对检索任务进行了微调,并直接计算检索分数。
最近的研究强调了对比预训练与对hard-negative进行微调的好处。这两种方法都在多个基准上取得了SOTA,还将一致性过滤作为其预处理管道的一部分。
6. 训练细节
对于训练,我们使用A100 GPU,并利用DeepSpeed第2阶段的分布式训练策略进行有效的多设备管理。为了训练我们的模型,我们使用AdamW优化器,再加上一个学习率调度器,该调度器在训练的初始阶段调整学习率。表5列出了在整个训练过程中在所有三个模型中使用的超参数。

7. 总结
本文介绍了JINA EMBEDINGS嵌入模型集,表明与具有可比backbone的其他模型相比,可以在大幅减少训练数据量的同时,实现各种任务的竞争性能。通过对MTEB基准的广泛评估,我们表明,与使用更大但质量更低的数据集进行训练相比,采用明智的数据过滤技术可以提高性能。这些发现显著改变了范式,表明为嵌入任务训练大型语言模型可以用比以前假设的更少的数据进行,从而可能节省训练时间和资源。
然而,我们承认当前方法和JINA EMBEDINGS集合性能的局限性。在二元组训练过程中,采样率的选择是基于启发式方法的。鉴于这些采样率的搜索空间很大,我们依靠直觉和对数据集的熟悉程度,将价值较高的数据集优先于价值较低的数据集。然而,这种主观的方法指出为未来的进步需要更客观的方法。
此外,JINA EMBEDINGS套装在一些任务上也有所欠缺。例如,在我们的否定数据集上计算句子相似性(如第4.3节所述)没有达到我们的预期(见表4),也没有在MTEB基准上获得分类和聚类任务的竞争分数。这些性能缺陷表明,在我们的训练数据中,这些类型的任务的表现可能存在缺陷,需要进一步调查。
展望未来,我们的目标是完善我们的训练流程,以提供具有改进性能和更大序列长度的模型。我们未来的努力还包括生成双语训练数据,训练能够在两种语言之间理解和翻译的嵌入模型,从而扩大JINA EMBEDINGS集合的实用性和多功能性。