论文解读
InceptionV1
前言
论文题目: Going Deeper with Convolutions
Googlenet论文原文地址:https://arxiv.org/pdf/1409.4842.pdf
之前看过VGG的论文(VGG精读直达)。当时VGG获得了 2014 ILSVRC 图像分类的第二名,今天来看一下第一名,也就是大名鼎鼎的 Googlenet,,并且这篇论文还是后续各种神经网络模型改版的基础,比如inception V2V3V4,inception-resnet,xception等等。
Googlenet的错误率都达到了人类的水平,5%-10%的错误率。
在查资料的时候,发现一个彩蛋,论文原名 GoogLeNet LN都是大写 最后是LeNet,据说是为了向LeNet致敬?
还有一个彩蛋就是 这篇论文的关键点 inception,其灵感来源于NiN网络 和 盗梦空间(inception) 并且引用了其中的台词,可以在参考文献的第一个条目中看到这个表情包:

第1页
摘要与引言
摘要提出了这篇论文的核心 inception,定义为一个特殊网络的代号。并说了一下主要特点是提高了网络内部计算资源的利用率,在增加了网络的深度和宽度的情况下使网络计算资源不变(或减少)。
GoogLeNet 是作者在 2014年ILSVRC 提交中应用的一个特例。
GoogLeNet 网络深度达到22层,加上池化有27层,算上inception内部 有100层。
虽然层数比VGG多了很多,但是参数量却变少了, GoogLeNet 500万个(5M),VGG16参数是138M,AlexNet参数大约60M。
摘要中有一句话 the architectural decisions were based on the Hebbian principle and the intuition of multi-scale processing.
这里的 Hebbian principle (赫布理论) :神经科学上的概念,简单讲就是 神经元突触的‘用进废退’,两个神经元,如果总是同时兴奋,就会形成一个组合,其中一个神经元的兴奋会出尽另一个的兴奋。反映在inception上就是把相关性强的特征汇聚的一起。
还有一个词: multi-scale processing (多尺度处理): 不同尺度卷积核并行处理。
引言的最后夸了夸自己,· on which it significantly outperforms the current state of the art. 我吊打你们
第2页
文献综述
作者简单的介绍了一下他设计出的inception的灵感来源,一个是从前人的研究内容(一系列固定的不同大小的卷积核来处理多尺度)。
还有一个灵感来源是 从NiN网络中的 1 * 1卷积核,这个卷积核之前在VGG里详细的理解了一下,在这作用是降维,增加网络深度,减少运算量(但是在VGG里没有升降维的作用,仅增加深度作用)。
第三个灵感是从R-CNN中,改进了R-CNN的两阶段方法(1.框出候选区域,2.每个区域卷积) 运用到自己的模型中了。
第3-4页
说了一下训练网络的问题,一个是数据不好准备(and 数据量过大造成的过拟合问题),还有一个是精度和计算效率之间的平衡问题。
解决这些问题的一个重要手段: 用稀疏连接代替密集连接
其中两点:
- 第一点就是开头提到的那个赫布理论,开头已经说到过了,就是汇总同时或者强关联激活的各部分。在神经网络中,比如有只狗。当识别出来这是只狗的时候,一定是狗的腿啊眼睛啊身体啊这些部位一起组合识别的,也就是这些特征一起激活 融合判断。
- 第二点就是 GPU和CPU都是密集计算优势,通过赫布学习法则用稀疏代替密集,如何又利用硬件的密集计算优势,又能设计稀疏的模型结构呢?
论文中给了一张图,用来说明数据标注是很麻烦的事:
就是这两狗。我一看,好家伙这不是俩二哈吗?哈哈
用知云翻译了一下, 左边:西伯利亚雪橇犬 。右边:爱斯基摩狗

这种图片一般人难以分辨,需要找对应领域专家的话,天天去标注这个玩意,确实是比较麻烦的事。
第4-5页
inception模块细节
inception的结构主要设计思想是: 用密集模块去近似局部稀疏结构 ,聚合高相关性的特征输入到下一层。这样既达到了稀疏连接 又可以一定程度上的利用硬件计算优势。
设计出了最初的inception版本:
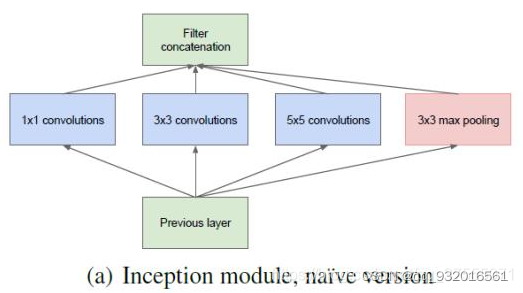
可以看到,最初的版本由 11卷积,33卷积,55卷积,33最大池化组成,特征图先被复制成4份并分别被传至接下来的4个部分,然后利用大小不同的卷积核实现不同尺度的感知,最后进行融合。
在对上面这四个小块进行融合的时候,要保证输出的长和宽都是一样的,这样才方便融合,用padding就行了。
四个途径的池化结果合并后会导致特征通道数变大,数据量逐层大量增加。为了减少参数量,作者在NiN里受到启发,使用了 1 * 1的卷积核进行卷积,达到降维,减少参数的作用,于是有了后续版本。
使用 1 * 1 卷积核的思想 也称为Pointwise Conv,简称PW。
改进后的inception:
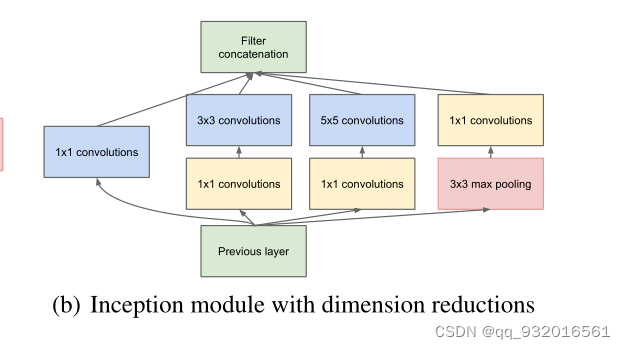
相比于最初的版本就是增加了一层 1 * 1卷积核,降低一波参数。
inception的位置: 网络开始使用普通卷积层,之后再堆叠inception模块,因为使用了改进版, 加入了 1 * 1卷积,所以并没有使参数爆炸,这样就达到了多尺度并行信息处理再融合的目的。
第5-7页
GoogLeNet
开头第一句就是呼应LeNet的那个彩蛋。
作者使用了inception的组合堆叠 开发出了一个新的网络,就叫Googlenet。
给出了Googlenet的详细图:
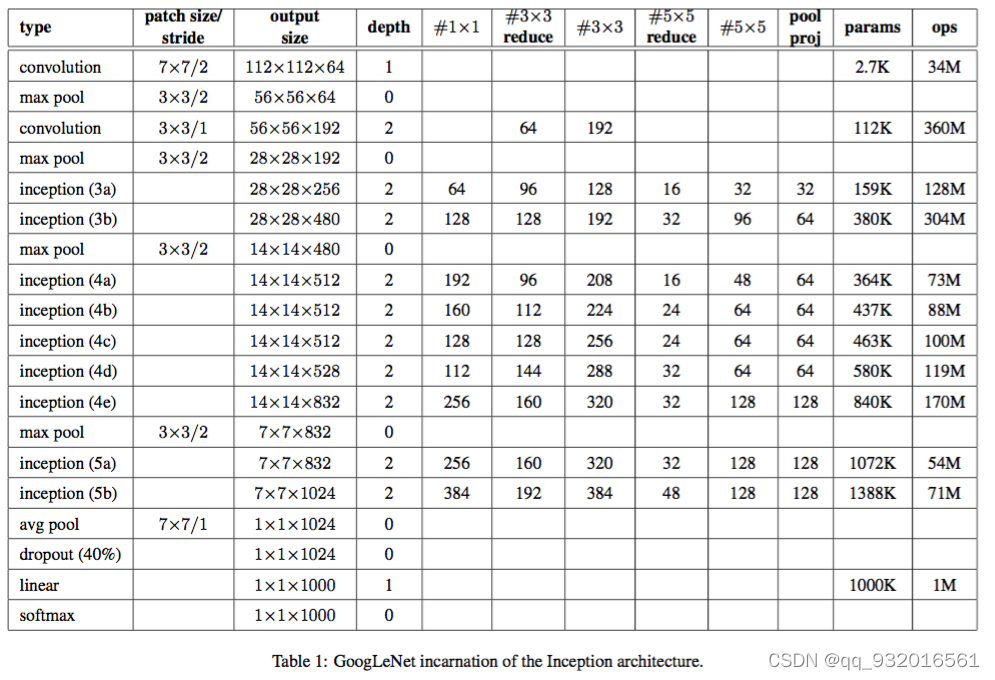
最左侧可以看到,Googlenet的结构:
卷积 -> 池化 ->卷积 ->池化 -> 9个inception堆叠 (中间两个池化) -> 池化 -> dropout -> 线性层 -> softamx
- 其中所有的卷积和1 * 1 之后都使用Relu作为激活函数。
- 将fully-connected layer用avg pooling layer代替后,top-1 accuracy 提高了大约0.6%,之前的VGG Alex等这里都是三个全连接层。
- 最后一层依旧使用dropout防止过拟合。
- 为了在浅层使特征更加有区分性,增加了两个辅助分类器 L=L(最后)+0.3xL(辅1)+0.3xL(辅2),测试阶段去掉辅助分类器。
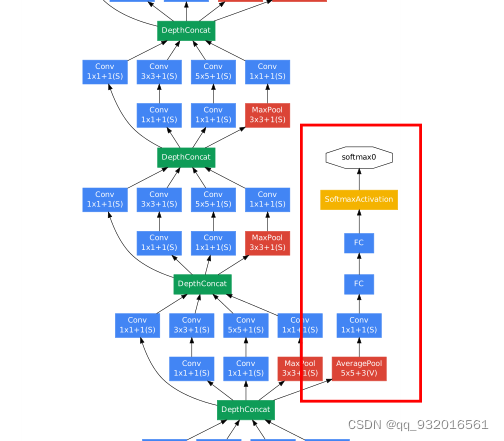
整体结构图比较大我就不截图上来了,我选取了带辅助分类器的那一小部分:
左边枝干就是一个又一个的 inception,右边我框出来的那一块就是辅助分类器,会得到一个预先的分类,按照上面的公式加权获得最终结果。
第8页
训练细节
这里说了两段参数设置还有预处理的方法。
第六节部分,最后作者说 so we could not tell definitely whether the final results were affected positively by their use.
看过沐神的都知道,这一部分叫:玄学调参 哈哈。
他说的具体数到后面代码复现的时候再说把,这段略了略了。
第8-10页
ILSVRC 2014
这部分主要说了一下 ILSVRC 2014 的细节。
训练使用了7个模型融合。每个模型使用相同的初始化方法甚至相同的初始值,相同的学习率策略,仅在图像采样和输入顺序有区别。
数据增强方面,将一张图变成144张图进行训练。将原图缩放为短边长度256,288,320,352的四个尺度,每个尺度裁出左中右(或上中下)三张小图,每张小图取四个角和中央的五张224x224的patch以及每张小图缩放至224x224,一共是六个patch,同时取其镜像。综上一共4x3x6x2=144个。最后结果取平均。
然后给了一张结果图:
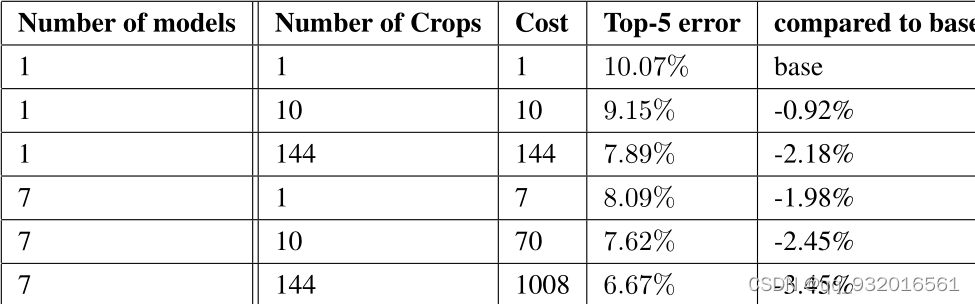
可以看到 模型集成越多,图片剪裁-数据增强的越多,计算量越大,准确率越高,不过作者也说了如此激进的方法在平常并不适用,只不过作者在比赛。。。
最后说了一下检测标准。
评判标准:如果算法给出的框分类正确且与正确标签框的交并比IOU(Jaccard相似度)>0.5,就认为这个框预测正确
使用map(所有ap求平均值)作为模型评估指标,每个类别不同阈值下precison-recall曲线围成的面积–AP(0-100,越高越好)
Jaccard相似度:
Jaccard相似系数 ( Jaccard similarity coefficient )又称 Jaccard系数 ( Jaccar Index )。 两个集合A和B的交集元素在A,B的并集中所占的比例,称为两个集合的Jaccard相似系数,用符号J (A,B)表示。
这里的集合就是检测的时候画的那个框框的重合度。
InceptionV2
前言
论文题目:Batch Normalization: Accelerating Deep Network Training by
Reducing Internal Covariate Shift
论文下载地址:https://arxiv.org/pdf/1502.03167.pdf
这篇论文是google团队2015年提出的,一般也叫他inceptionV2或者BN-inception。
摘要 (Abstract):
作者提出了深度神经网络的复杂性在于每一层的训练都依赖于前一层的结果。前一层发生较大变化将对后面的训练产生较大影响,要降低学习率,使用饱和非线性激活函数很难(Sigmoid和tanh饱和,Relu非饱和),因为会产生梯度消失问题。
提出了一个概念:internal covariate shift google翻译为:内部协变量转移。
关于 internal covariate shift:
各层输入数据分布的变化阻碍了深度网络的训练。这使得训练过程中要设置更低的学习速率,从而减慢了模型的训练;同时使得使用饱和非线性激活函数的模型变得极度难训练。作者将这种现象称为内部协方差变换。
机器学习领域有个很重要的假设:IID独立同分布假设,就是假设训练数据和测试数据是满足相同分布的,这是通过训练数据获得的模型能够在测试集获得好的效果的一个基本保障。
什么叫数据分布?
同样大白话,假如要识别猫,有两个数据集,白天拍摄的猫和晚上拍摄的猫。那么这俩的数据集分布差异较大。
更进一步的使用数值举例,比如 范围x1 = [0.1,1],而x2=[100,10000] 显然两者的取值范围分布差异较大。
这会造成什么问题呢?
这就是作者在Abstract里所说的深度神经网络的复杂之处,使用上述例子假设有全连接神经网络,第一层输入为x1,训练完一轮后输入x2,此时的w将拟合x2,由于其前面拟合的是x1,所以这里为了拟合x2将造成w的较大波动导致此后的所有层都产生较大改变(上一层的输出,即下一层的输入数据分布发生较大变化),层数越深复杂性越高,所以不能调较大的学习率(使得训练变慢),其他参数的初始化也要更加小心。
然后作者提出了Batch Normalization,应用在每一个mini_batch,各种参数的调整变的不那么谨慎,还可以充当正则器(可免去dropout)。最后解决了上述问题,并且计算的很快,结果很好。
引言(Introduction)
引言的开始作者首先相对于 One Example SGD 夸赞了一波mini_batch SGD,梯度的更新方向更准,并行速度更快,然后又说了一下SGD的缺点,就是对参数比较敏感。作者言下之意就是 BN可以解决这些问题,至于夸mini_batch, 毕竟BN是基于mini_batch嘛。
第三段提到的一个名词domain adaptation (领域自适应):
领域自适应(Domain Adaptation)是迁移学习中的一种代表性方法,指的是利用信息丰富的源域样本来提升目标域模型的性能。
领域自适应问题中两个至关重要的概念:源域(source domain)表示与测试样本不同的领域,但是有丰富的监督信息;目标域(target domain)表示测试样本所在的领域,无标签或者只有少量标签。源域和目标域往往属于同一类任务,但是分布不同。
作者也在这里正式提出 Internal Covariate Shift (ICS)的含义: 我们将深层网络内部节点分布在训练过程中的变化称为内部协变量转移(ICS)。
这也与我们在开头对于ICS的理解差不多,就是数据(input)分布的变化。
然后就说出了解决办法就是 Batch Normalization ,BN通过修正输入的均值和方差减少了ICS问题,加快训练速度,减小网络对参数的敏感程度,减少对dropout的需求,还可以使用饱和非线性激活函数了。
为什么在BN之前深层网络不建议使用饱和非线性激活函数?
当采用饱和非线性激活函数的时候,比如用sigmoid:
放一张sigmoid导数图像:
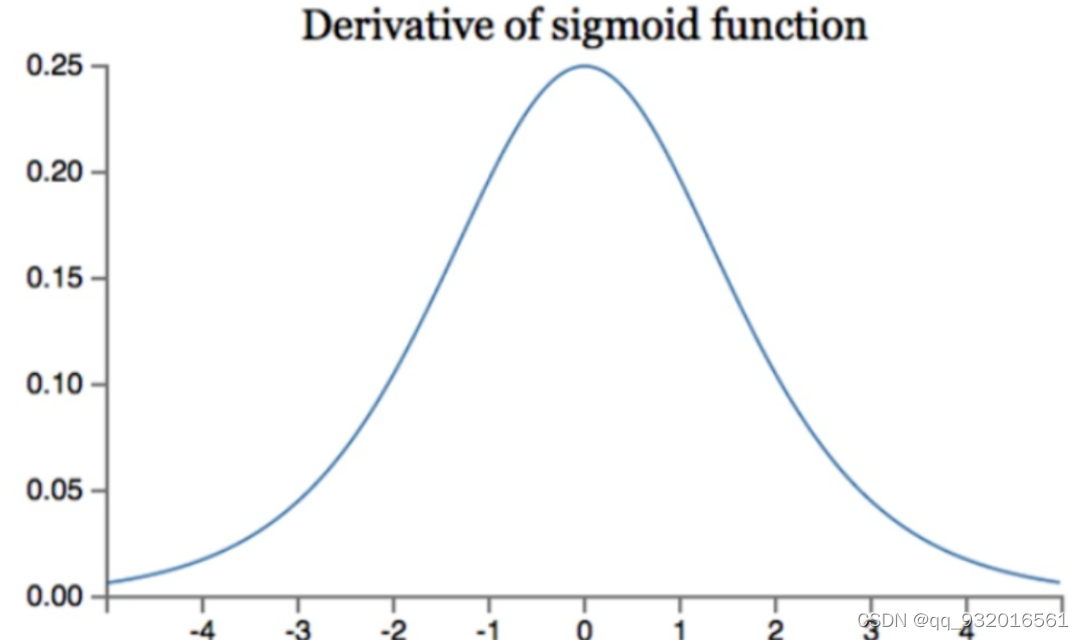
可以看出来,input值必须接近于0,否则input绝对值越大,则其导数越接近0,使得参数权重无法更新,学习效率变低,产生梯度消失的现象。而在深层网络中ICS现象会让数据分布发生变化,让input值的分布不可控,从而更易产生梯度消失现象(使用Relu激活函数+谨慎的参数可以在一定程度上解决梯度消失现象)。
解决方向(Towards Reducing Internal Covariate Shift)
这一章主要是讲解决ICS问题的方向,首先第一段提出了一个可能解决办法,就是在每一层应用白化数据策略。
关于白化数据:
白化的目的是去除输入数据的冗余信息。假设训练数据是图像,由于图像中相邻像素之间具有很强的相关性,所以用于训练时输入是冗余的;白化的目的就是降低输入的冗余性。
假设输入数据集X,经过白化处理后,新的数据X’满足两个性质:
(1)特征之间相关性较低;
(2)所有特征具有单位方差,均值为0。
通过对每一层的输入数据进行白化,对消除ICS问题提起到一定进步作用,且网络训练的更快。
作者提到了两种白化数据的方法:
- 直接修改网络。
- 根据网络的激活函数的输出值修改参数。
随后作者说了一下缺点,用了示例并附公式推导。这一块公式简单的说就是 发现每层的输入和输出相等,损失值不变,导数不变,而偏置b和权重w将叠加,最后导致模型参数爆炸。
作者对上述的原因分析:
在更新损失或者导数的时候,并给有将每层的参数和normalization 考虑进去。
作者给出了新的公式:
右边的是导数, 要求其覆盖normalization 和之前的参数。

还没给出具体的式子,就直接分析了一波缺点,计算量太大成本太高,且有的地方无法求导,然后又去寻求新的方法了。
解决办法(Normalization via Mini-BatchStatistics)
作者为了解决上一章遗留的问题(计算成本和不可微问题),提出了一个公式:

- 平均值为0,方差为1.
- 一个维度一个维度的进行normalization
其中的均值和方差var是根据整个数据样本得到的,这种方法加速了收敛,虽然没有使特征去相关。
为了避免normalized改变每层的input信息,normalized必须经过identity 变形。
但这样的方法可能会限制激活函数的非线性能力,所以引入了两个变量gamma和beta,用来缩放(scale)和平移(shift)normalized的值 ,这两个参数可以帮助我们还原normalized的值,保留 模型的表达能力。并且这两个参数也随着网络的训练而学习。
论文核心
随后贴出了算法公式图:

步骤如下
- 对某一激活层的input做BN
- 取一个mini_batch
- 求该batch均值
- 求该batch方差
- 求内部normalized。分布有一个固定值就是像小e一样的那个字母,为了防止分母为0.
- 加入gamma和beta(对原有的normalized做缩放和平移) 与内部normalized结合得到最后输出的值作为layer input 给下一层。
显然此时的BN考虑了整个的mini_batch样本。
在其中的 内部normalized最好的保持是(若数据分布相同) mean为0 var为1,若下一次的mini_batch不再具有相同分布,则通过gamma和beta来调整输出的y值。
从这里就可以看出 这里的步骤已经解决了文章开始提出的ICS问题。规范了数据分布。
后续作者给了BN完整的求导公式,以此证明BN解决了第二章的那个并非处处可导的问题。
3.1节就是在介绍将BN应用在训练和测试的步骤,
训练时就是上面说的那个过程去计算每一个mini_batch,得到输出y。
在测试的时候,由于不适用mini_batch了,所以没法得到maen和var了,所以要保存下训练时每一个mini_batch的maen和var,然后取出所有的maen和var取均值,最后计算y值的公式:

3.2节介绍将BN应用在卷积神经网络里。
这一小节说明了几个问题。
结论1:BN设置在 线性和非线性计算的中间。
为什么不对本层的输入做normalizing ?
因为本层的输入是上一层的非线性输出,经过了非线性计算,数据分布可能已经改变,在这里加入BN,将使其抑制ICS问题的效果变差。
为什么对线性输出做normalizing? :
线性计算能产生对称,非稀疏的分布,对这样的结果做BN,更容易获得稳定的分布。
结论2:BN计算中的bias偏置参数被忽略了,因为被beta取代了(职能取代)。
结论3 BN可以应用在卷积神经网络中。
input输入为(x,y) 则BN作用于每一个x到y的值。
CNN 中输入为(B,C,W,H),则BN作用于一个qxp的平面空间(这块原文没看懂)。
第3.3小节:
结论1 BN能让模型接受更大的学习率(lr)。
在前面的章节已经用sigmoid的那个图说过了,BN会防止梯度困在激活函数的sigmoid或者tanh的0的位置。
结论2: BN能保证模型训练的稳定性,增加对参数值规模的鲁棒性。
论文给出了三个公式用于支撑结论:


第一个公式: 参数值大小没有改变input的导数值。
第二个公式: 参数值变大,会让其导数值等比例缩小,从而控制参数增长防止梯度爆炸。
第三个公式是说:参数规模大小对结构没影响(公式中后者放大了a倍)。
3.4节,这一节就在解释摘要中说到的,为什么BN可以在一定程度上舍弃dropout的使用。
原因:BN让模型不再为特定的样本生成特定的值,所以一定程度上防止过拟合。
实验(Experiments)
这一大章节都是在说实验,我觉得不必要细看。
总结几个点:
-
可以放大学习率。
-
免去使用dropout。
-
大幅降低L2,且提高精准度。
-
加速lr衰减。
-
不必用LRN。
-
更彻底的shuffling,相当于正则,提高精准度。
inceptionV3
Abstract(摘要)
作者在摘要部分提到,2014年卷积神经网络开始做的又大又深,这里不就是暗示2014年的imagenet竞赛冠亚军 VGG和自己家的googleV1,尤其是庞然大物VGG嘛。。额 谁都拿VGG做例子,反面教材VGG实锤了。
提到了宽而深网络的痛点,计算复杂度高,无法在移动场景(边缘计算)和大数据场景下使用。
之后说出本篇论文的主旨:通过分解卷积+正则化提高计算效率
Introduction(引言)
第一段一句话总结: 卷积模型可以应用在各种领域。
第二段一句话总结: 好的学习模型更利于其他领域做迁移学习,作者得到一个启发:用深度学习做目标检测中的提取候选框任务。
第三段一句话总结:在参数上对比其他模型展现googlenet的优势(参数量-Alexnet:6000W,Googlenet:500W,VGG16:1.3E)
第四段一句话总结:模型计算量比PRelu低,可以在移动设备和大数据场景下使用,且各种加速优化方法都可以用在inception上(毕竟inception模块里面就是一堆的卷积和池化)。
最后一段一句话总结:一味的堆叠inception模块将使得计算量爆炸,换来的精准度并不划算,同时说了一下自己家的V1版本没有说明提高准确率的具体原因,所以—深度学习=炼丹炉 玄学了~
General Design Principles(通用设计原则)
这一章主要是介绍了作者想到的四种设计原则,开头的时候作者也说了,这几种设计原则你要大致上遵守,虽然没有严格的证明或者实验加持,但是可以表明的是,如果你背离这几个原则太多,则必然会造成较差的实验结果。(顺我者昌逆我者亡?)
原则一
避免过度的降维或者收缩特征 尤其在网络浅层。
- 前馈网络相当于一个有向无环图结构。
- feature map 长宽大小应随网络加深缓缓减小(不能猛减)。
- 过度的降维或者收缩特征将造成一定程度的信息丢失(信息相关性丢失)。
原则二
特征越多,收敛越快。
- 相互独立的特征越多,输入信息分解的越彻底。
- 就是inceptionV1里说的那个赫布理论。
原则三
3 * 3和5 * 5的卷积核卷积之前可以用1 * 1 的卷积核降维,信息不会丢失。
- 开头的单词 Spatial aggregation(空间聚集)也就是用大的感受野感受更多的信息,聚集在一起,即使用大尺寸的卷积核。
- 使用1 * 1 卷积可以降低维度,降低计算量,加速训练。
- inceptionV1中使用的模块里有 3 * 3 和 5 * 5的卷积,并且在他们之前有使用1 * 1 的卷积,这样的降维操作对于邻近单元的强相关性中损失的特征信息很少。
原则四
均衡网络中的深度和宽度。
- 深度就是指层数的多少,宽度指每一层中卷积核的个数,也就是提取到的特征数。
- 让深度和宽度并行提升,成比例的提升,能提高性能和计算效率。
- 可以让计算量在每一层上均匀分配,VGG那第一层全连接层的数据堆积就属于不均匀分配的情况。
Factorizing Convolutions with Large Filter Size(分解大卷积核 )
之前在Googlenet里面已经看到了inception模块使用1 * 1 的卷积核了。作者也在这里提到Googlenet的inception成功原因大部分得益于使用1 * 1 的卷积核,1 * 1 卷积核可以看作一个特殊的大卷积核分解过程,它不仅减少了计算量,还增加了网络的表达能力。
由上面的原则三也知道了,在使用大卷积核之前先用1 * 1卷积核,feature map信息不会丢失很多,因为感受野相邻的元素相关性很强,他们在卷积的过程中重合度很高,仅相差一个步长,所以feature map基本上不会丢失特征信息(元素特征相关性不变)。
inception模块为全卷积网络(可能有池化层,但没有全连接层),所以权重个数越多,计算量越大。所以就 -使用小卷积核–降维–参数量减少–计算量减小–节约内存–加速训练–节省出来的用于计算更多的卷积核组。‘
分解方法一:
简单说一下论文中第三页开头给出的这张图:
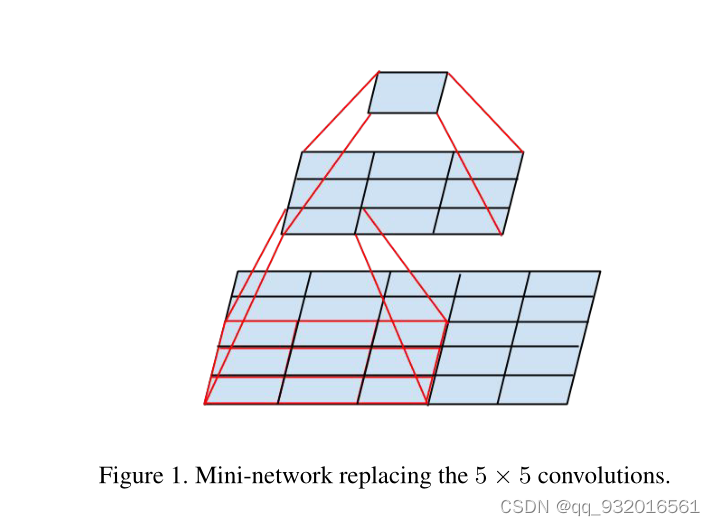
这图在之前论文复现里说过好多次了,其实就是讲大卷核用小卷积核替代的过程。
假设对于原图5 * 5 使用 5 * 5的卷积核去卷积(相当于一个全连接),只能得到一个1 * 1的feature map,而按照这个图,原图为5 * 5 ,现使用3 * 3 先卷积一次(步长为1),得到一个 3 * 3 的feature map,然后再使用一个3 * 3 的卷积核对刚才获得的feature map进行卷积,就同样得到了一个1 * 1的feature map。
5 * 5 卷积分解成两个 3 * 3卷积核。同理7 * 7分解成三个 3 * 3卷积核。
作者在3.1小节中提到:相同卷积核个数核feature map尺寸的情况下,5 * 5 卷积核比3 * 3卷积核计算量高了2.78倍。
相邻感受野的权值共享(共享卷积核,即卷积核内的数值都是一样的,用同一个卷积核),所以减少了很多计算量。
举个例子
在5 * 5的卷积核中: (H* W C) (5 * 5 * C) = 25 H W C 2 HWC^2 HWC2
在3 * 3的卷积核中: 2 * (H* W C) (3 * 3 * C) = 18 H W C 2 HWC^2 HWC2
由此作者得到了 28%的参数量减少。
对于分解后的激活函数,作者通过实验证明,保留对于原图的第一次3 * 3卷积的激活函数有较好效果(一层卷积变成两层了,增加了非线性变换,增强模型非线性表达能力),用BN后效果更好。
1 * 1卷积后接Relu有类似效果,(毕竟1 * 1 卷积也是一个卷积层)。
原来GoogleNet里的inceptionV1结构:
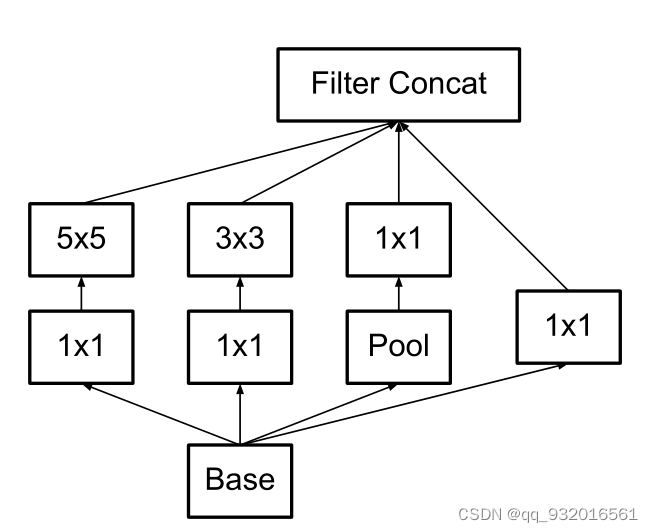
改进之后的inception结构:
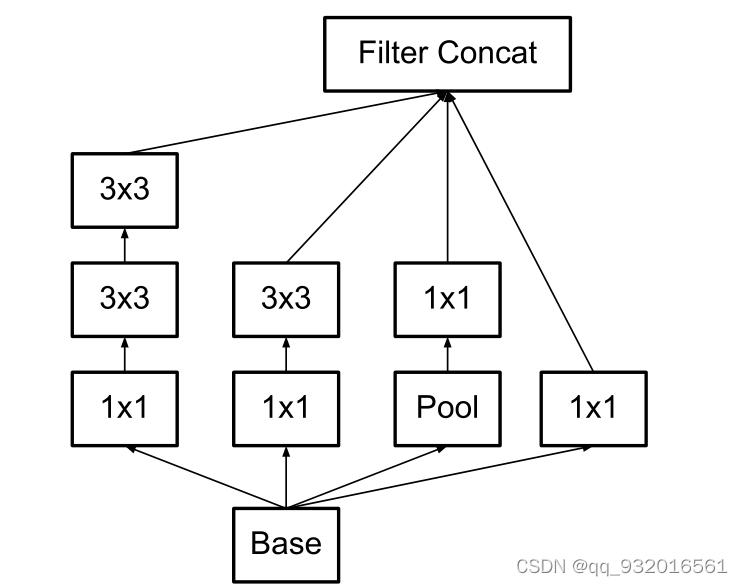
分解方法二:
上面的一个方法是 5 * 5分解成了 两个3* 3卷积。
3.2这一小节方法是,将3*3的卷积分解成 1 * 3和 3 * 1的两个不对称卷积(空间可分离卷积)。
具体卷积方法论文中给出了图:
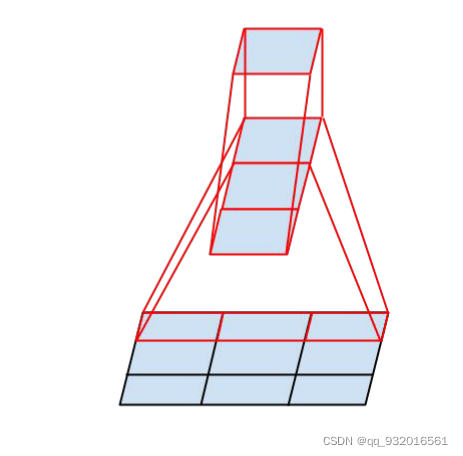
简单解释一下上面的图,假设原始为3 * 3的图,使用3 * 1的卷积核去卷积,得到一个feature map,然后再用 1* 3 的卷积核对刚才得到的feature map做卷积得到1 * 1的feature map。
实际上这里直接用线代里的矩阵乘法更好理解,我在网上找了张图。
对于3 * 3矩阵的分解:分解成 3 * 1 和1 * 3的俩矩阵

实际上在到这之前我就在想,为啥不继续分解3 * 3卷积变成更小的,就像5 * 5 分解成两个 3 * 3那样,3 * 3也可以分解成两个2 * 2卷积,为啥非要弄成这种 3* 1 和1 * 3的不对称卷积?
作者在后面给出了原因,通过实验计算,将3 * 3 分解成两个2 * 2可以减少11%的参数量,而分解成3 *1 和1 * 3 可以减少33%的参数量(所以上面的5 * 5 分解也可以使用非对称分解喽?)。
两个小结论:
- 这种分解 (n *n 分解成了 n * 1 和1 * n) n 越大节省的运算量越大。
- 这种分解在前面的层效果不好,使用feature map大小在12-20之间。
将3 * 3用不对称分解之后的结构变成下面这样:
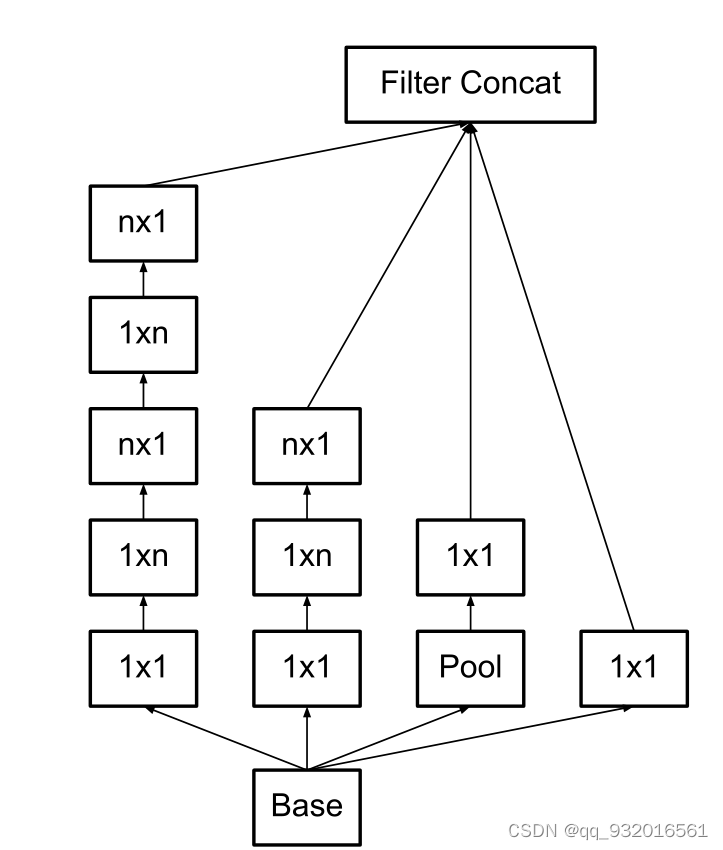
还有一个变种,可以理解成上面这个是在深度上分解,而下面这个是在宽度上分解。
应用在最后的输出分类层之前,用该模块扩展特征维度生成高维稀疏特征(增加特征个数,符合原则二)。
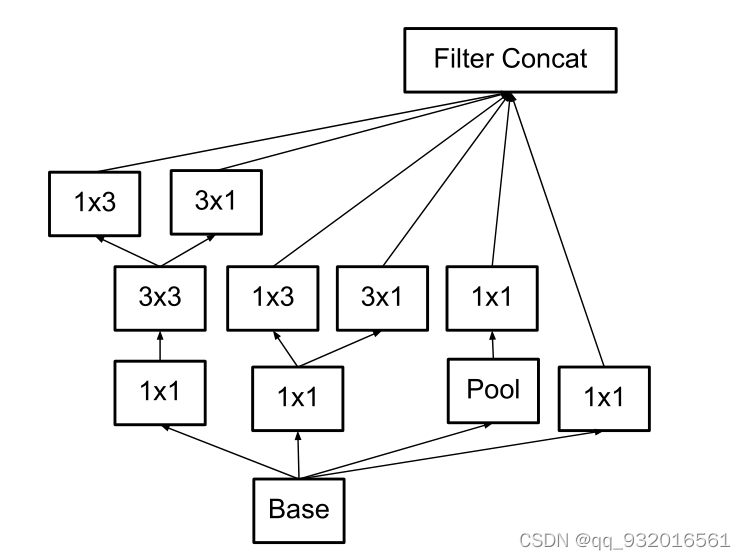
Utility of Auxiliary Classifiers(辅助分类器)
首先回顾一下在GooglenetV1里面的辅助分类器。
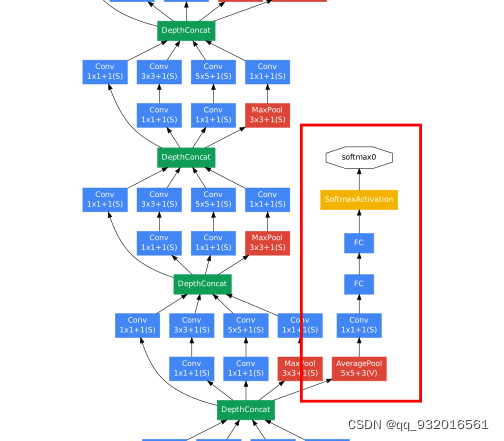
就是上面这样的辅助分类器,在浅层的时候直接输出一个分类结果,为了是让浅层使特征更加有区分性(让浅层学到区分性的特征),加速收敛,防止梯度消失,辅助分类器一个在浅层一个在中层,最终结果:L=L(最后)+0.3xL(辅1)+0.3xL(辅2),测试阶段去掉辅助分类器。
然后在这篇论文中,这一章作者直接说了 辅助分类器并没有加速收敛,但结果显示,带有辅助分类器的网络精度确实比没有辅助分类器的高,只高一点,移除了浅层的分类器对网络没有什么太大的影响。
Efficient Grid Size Reduction(减小feature map尺寸)
这章作者主要介绍了更高效的下采样方案。
传统的两种方法减小feature map的方法:先池化再升维,则丢失了过多信息,先升维再池化,则计算量复杂度变大。
为了解决上面的问题,提出了inception的并行模块。
inception并行模块结构图:
左边两路卷积,右边池化。最后再叠加,可以在不丢失信息的情况下减小参数量。
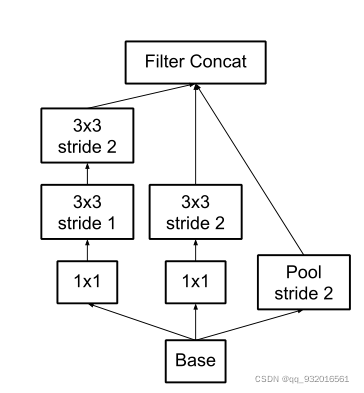
Inception-v2
我在开头的时候说到,这篇论文应该是inceptionV3,V2是BN那一篇,但是写这篇论文的时候作者就是把他叫成V2了,所以这一章作者起了这么个标题。
这一章主要就是汇总了上面所有的改进方法模块。
看一下作者给出的网络:
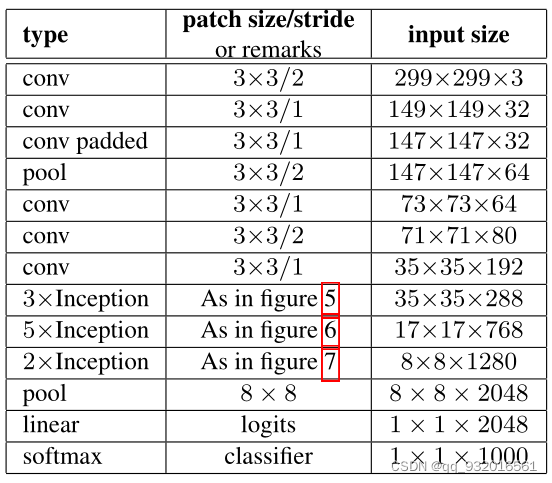
这里面的
- figure 5 ------ 5 * 5 卷积分解成两个3 * 3 卷积
- figure 6------ 应用的那个不对称卷积
- figure 7------ 用在输出分类前的那个扩展组合
作者说这个网络是符合上面说的设计的四大原则的, 网络有42层深,计算量是googlenet的2.5倍(仍比VGG高效)。
Model Regularization via Label Smoothing(LSR)
作者在这章提出了一种正则化方法 LSR,我尝试看了一下这一章,奈何水平不够,只能从表层理解没法深入原理。
Label Smoothing Regularization(LSR)标签平滑正则化,机器学习中的一种正则化方法,是一种通过在输出y中添加噪声,实现对模型进行约束,降低模型过拟合(overfitting)程度的一种约束方法(regularization methed)。
标签平滑的基本原理
在传统的分类任务中,我们通常使用硬标签(例如,对于一个10类分类问题,正确类别的标签是1,其余类别的标签是0)。这种表示方式在一定程度上可能导致模型过于自信,过拟合于训练数据中的特定样本,而不是学习更一般的模式。
标签平滑通过调整这些硬标签,给每个类别分配一个小的非零概率,即使是错误的类别也是如此。例如,对于10类分类问题,真实类别可能被标记为0.9而不是1,而其他类别则被均匀分配剩余的0.1概率(每个类别0.01)。
如何实现标签平滑
假设我们有一个分类问题,其中共有 ( C ) 个类别,对于给定的训练样本,其真实类别标签为 ( y ),标签平滑将这个标签转换为:
y ′ = ( 1 − ϵ ) ⋅ y + ϵ C y' = (1 - \epsilon) \cdot y + \frac{\epsilon}{C} y′=(1−ϵ)⋅y+Cϵ
其中,( \epsilon ) 是一个小的正数(例如0.1)。这样,真实类别的标签会被稍微降低,而其他类别的标签则会略微升高。
标签平滑的优势
-
防止模型过于自信:通过防止网络对训练样本的预测过于自信(即防止过拟合),标签平滑有助于提高模型的泛化能力。
-
更平滑的决策边界:标签平滑促使模型学习更平滑的决策边界,这对于模型的泛化是有益的。
-
减少标签噪声影响:在存在标签噪声的情况下,标签平滑可以减轻噪声标签对模型训练的不利影响。
使用场景
标签平滑在大型神经网络,尤其是在图像分类(如使用CNN)和自然语言处理(如使用Transformer模型)任务中特别有用。它是一种有效的正则化策略,尤其在训练复杂模型或使用大型数据集时非常有效。
Performance on Lower Resolution Input(小分辨率输入性能)
到八章主要介绍了一些训练细节,就不说了。
第九章作者思考了一下模型在小分辨率图像输入的时候的性能。
首先说了一下模型在大分辨率图像输入下更高效的原因,一个是浅层的感受野大,因为输入分辨率大,所以卷积核大。
第二个原因是模型的深度大。
然后作者保持模型复杂度不变(对小分辨率图像减小前两层的步长,或者移除第一个池化层),单纯的提升输入图像分辨率做实验得到结果:

可以看到当分辨率提高之后正确率确实提高了,但是提高的微乎其微,三种情况几乎持平,且不能根据输入的分辨率变小而减少网络的大小,那样网络的性能会变得很差。
Experimental Results and Comparisons(inceptionV3出炉)
inceptionV3出炉过程直接看这张图:
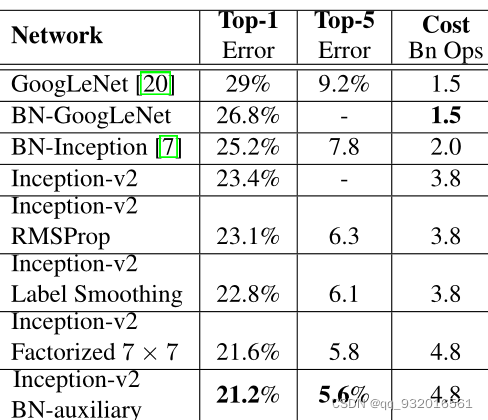
从上面章节中提出的的inceptionV2结构开始改进:
- inceptionV2 加入RMSProp(一种计算梯度的方法,详细原理)
- 在上面的基础上加入Label Smoothing(LSR,标签平滑正则化)
- 在上面的基础上再加入 7 * 7的卷积核分解(分解成3 * 3)
- 在上面的基础上再加入含有BN的辅助分类器
所以本文最终提出的inceptionV3 = inceptionV2+RMSProp+LSR+BN-aux
这里说的inceptionV2是本论文中的inceptionV2并不是BN那一篇。
小总结
- 四大设计原则
- 在浅层不要过度降维或收缩特征
- 特征越多,收敛越快。
- 大卷积核之前用1 * 1卷积降维,信息不丢失
- 均衡网络中的深度和宽度
- 不对称卷积核分解
- 直接打脸V1中的辅助分类器,并造了新的带BN的辅助分类器
- 使用新的 inception并行模块解决了传统采样层的问题
- inceptionV3 = inceptionV2+RMSProp+LSR+BN-aux
InceptionV4
前言
本篇论文主要介绍inceptionV3的改进版本inceptionV4,以及将inception和resnet结合的俩版本 inception-resnetV1和inception-resnetV2。
Abstract (摘要)
摘要部分作者主要说,现如今深层的神经网络已经变成了CV领域的主流,已经有inception这样的高效结构,并且在写这篇论文的时候,Resnet横空出世,作者考虑是否可以将inception和ResNet相结合,作者在后续实验中证明,残差连接可以显著的加快inception的训练速度,且准确率也比没有残差模块的网络高一点,设计了三个模型,有残差连接的Inception-ResNetV1和V2版本 还有一个没有残差连接的InceptionV4。
在摘要的最后作者发现一个方法,将残差输出缩小(乘以一个缩小因子),可以防止网络不稳定现象。
Introduction (引言)
这一章介绍行业现状,就提了一堆的CV领域产业,这些产业都是可以得益于图像分类系统的发展。
然后提到残差连接,残差连接在深层网络中非常重要,而他们的inception模块堆叠的网络往往都比较深,然后作者就想着能不能将两者结合,就提出一个方法,将concatennate合并层替换成残差加法merge层。
残差连接没有引入额外的参数,但又加快了训练,可以让较深的inception得益。
后面就是作者说他设计的几个模型,有残差的和没有残差的在计算量复杂度上基本保持一致。
引言的最后作者提到了一个结论: 对于single frame(对输入图片不做处理,直接整个喂给模型) 多模型融合对比单模型并没有很大的性能提升。
Related Work (文献综述)
这一章开头又是介绍了一下当时前人的研究工作,并且对 ‘残差连接是深层网络所必不可少的’ 观点提出了质疑,这块作者质疑就是打个铺垫把,方便后面提出他自己的没有残差连接的inceptionV4。
随后作者给出的两张图,顺便可以回顾一下ResNet结构。
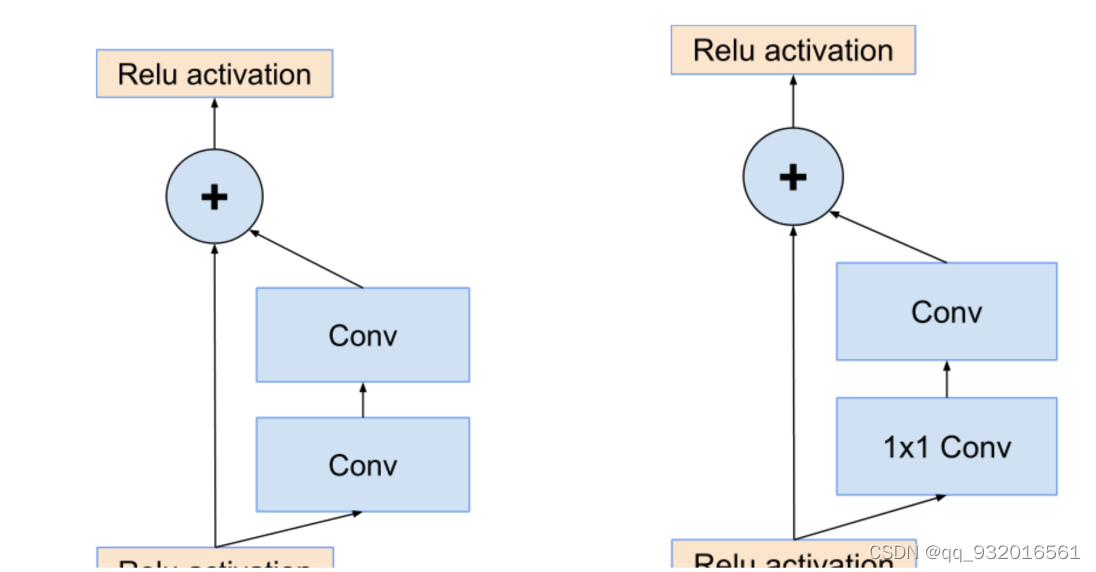
左边的图 就是原生的残差结构,输入进来的数据分成两路,一路不变,另一路去卷积训练,最后的输出就是两者的相加。
而右边这个图是对左边残差结构的优化,他在卷积之前使用 1 * 1卷积进行降维,减少了计算量和参数量。
Architectural Choices(架构选择)
本章节主要介绍了带残差的inception和不带残差的inception。
不带残差的inception:
因为之前没有tensorflow 所以在调试网络参数的时候需要每个inception模块内的每一个小网络都要很谨慎,因为内存有限,当出现了tf之后,因为tf有很好的内存管理机制,所以可以不用那么谨慎的对待每一个参数了,就用整个网络整体的去调整,
带残差的inception:
inception模块处理之后,使用不带激活函数的1 * 1 的卷积进行升维,扩展维度和通道数用来匹配输入维度,因为残差结构里最后需要相加嘛,所以维度和通道数要匹配上。
一般情况下BN应用在每一层的后面,但是在这里作者不在残差后面应用BN,只在传统层后面用BN,怕内存爆炸。(这里简单回顾一下 BN需要记录每一个神经元的方差和均值,所以会占用大量的内存)
所用模块架构图:
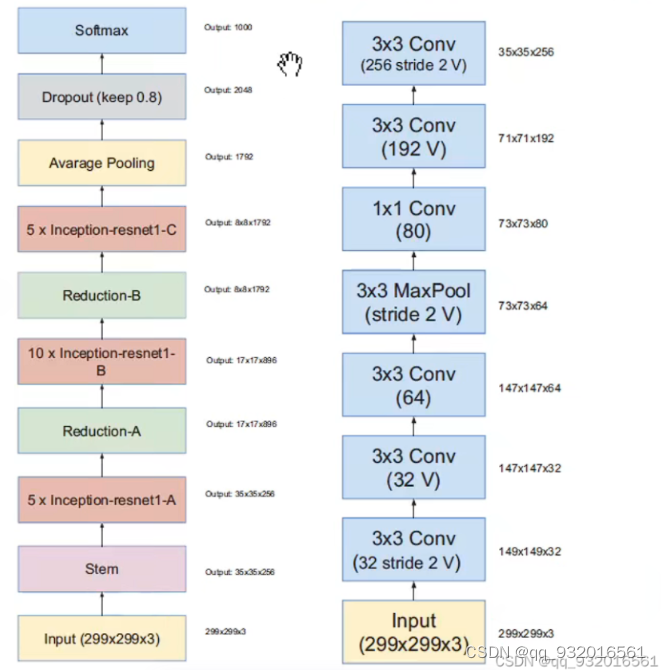
作者给出了inceptionV4和主干网络结构图(左)。
其中的stem层展开之后就是右边这个图了,其中带V的表示不使用padding,不带V的使用padding(使得输入输出feature map 大小长宽保持一致 的padding)。
右边这个图是 inceptionV4和Inception-Resnet V2的stem展开结构。(Inception-Resnet V2的主干图在后面)
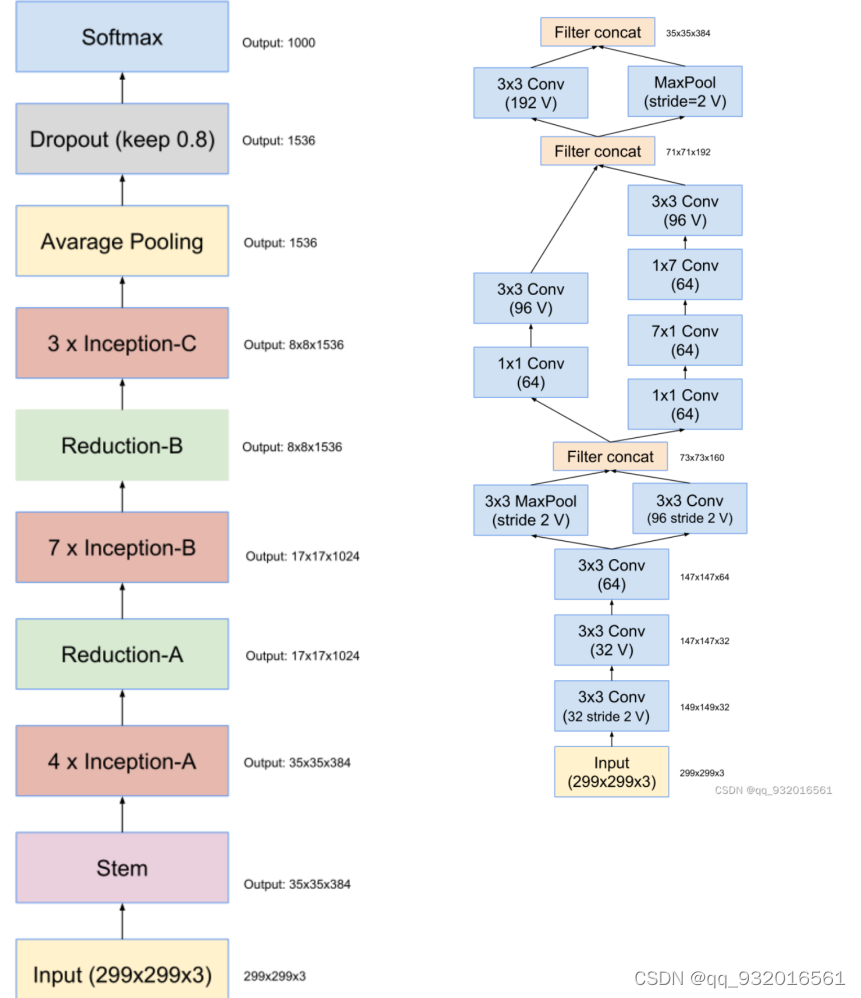
可以看到右边这个图 也就是左图中的stem展开的结构,主要工作就是长宽通道的变换,从299 *299 *3 -> 35 * 35 *384。
其中用到的各种inception模块:
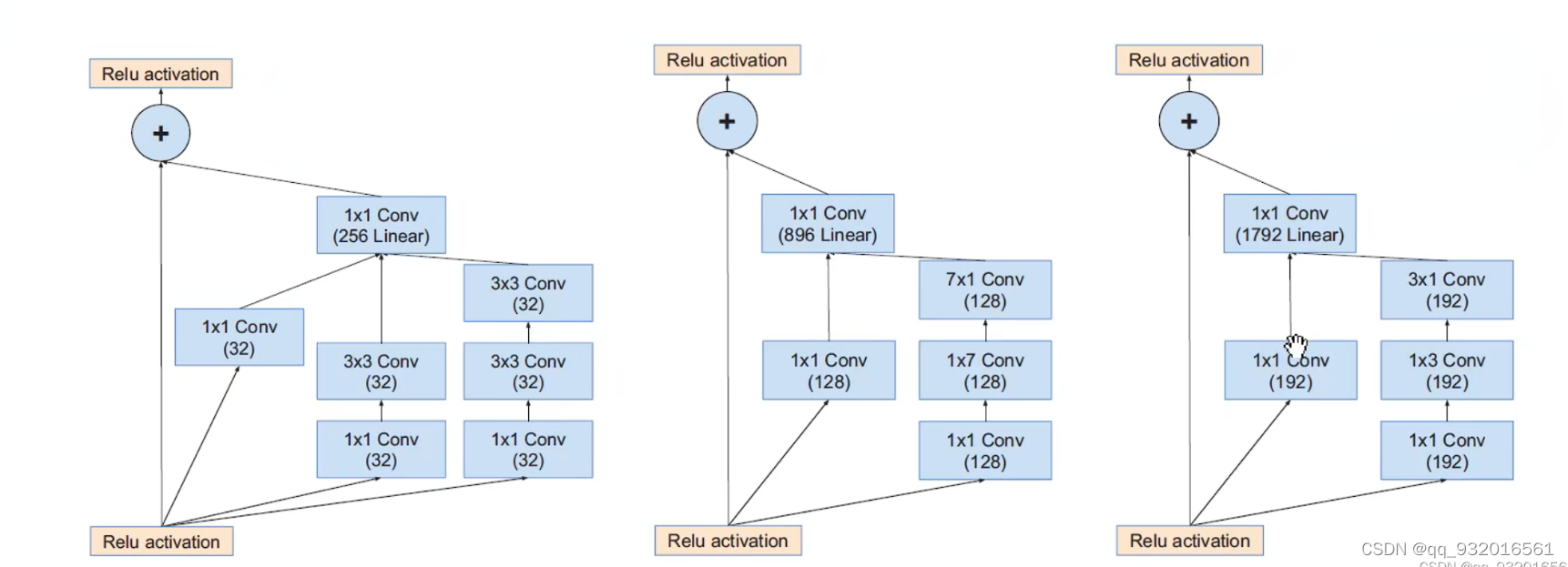
inception-A模块:
5 * 5卷积 -> 3 * 3卷积
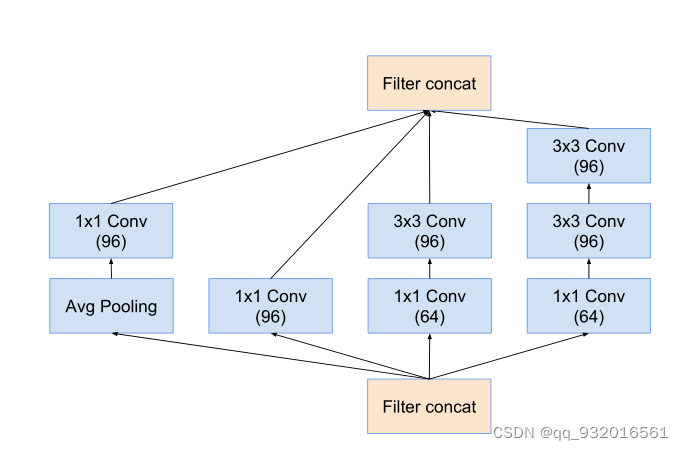
inception-B模块:
7 * 7 卷积 -> 7 * 1 和 1 * 7
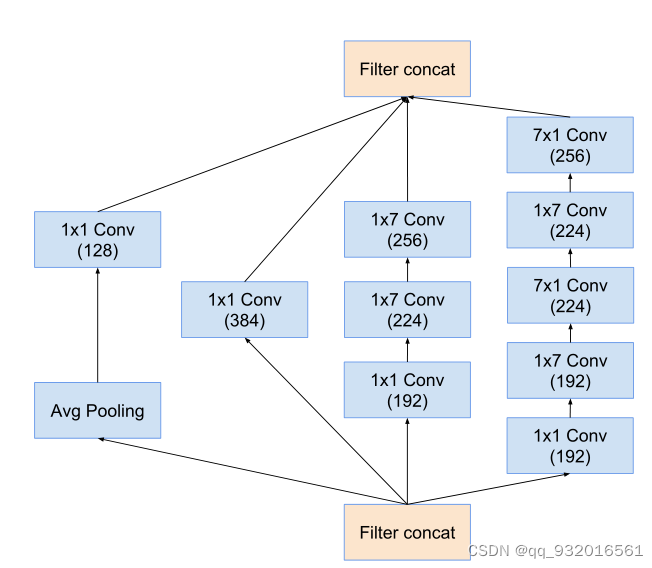
inception-C模块:
在宽度进行不对称卷积 扩展维度 通道数。
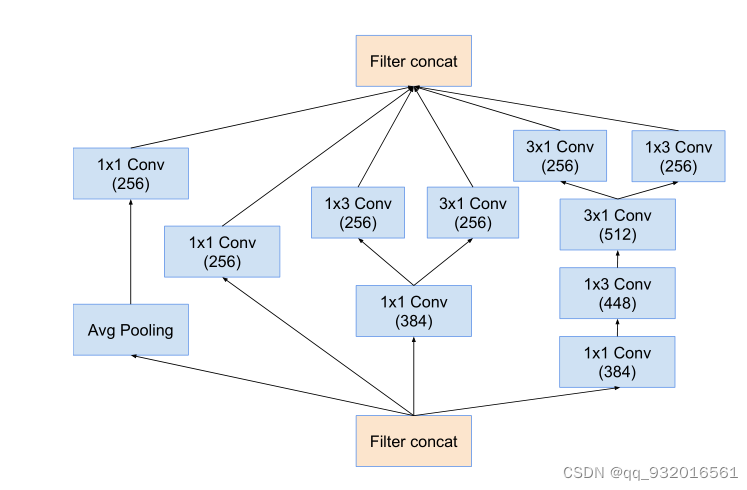
Reduction-B模块:
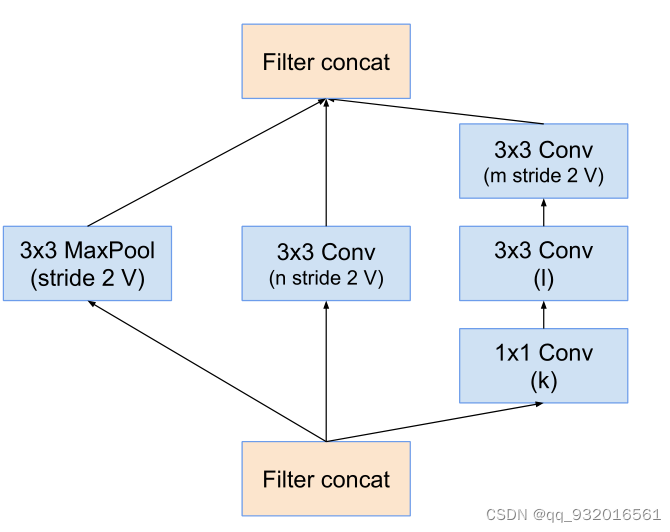
Reduction-C模块:
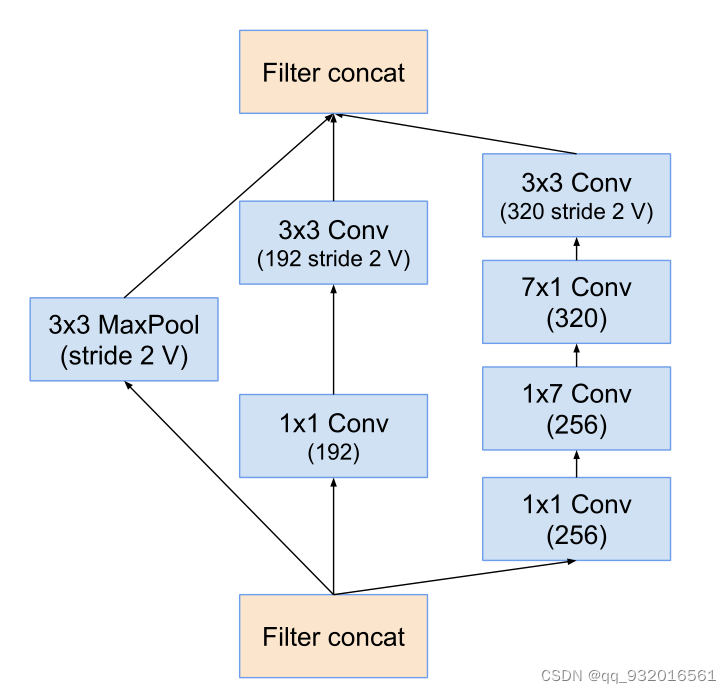
下面这个是Inception-Resnet V1的:
左起依次 inceptionA -> inceptionB -> inceptionC:
下面这个是Inception-Resnet V2的:

左边是inception-Resnet V1 和V2的主干网络,右边是 inception-Resnet V1的stem结构展开图。
残差块幅度(Scaling of the Residuals)
这一章主要介绍如何对残差块输出的幅度进行减小。
若卷积核的个数超过1000个,则残差模块会变得不稳定,这也在开头提到过,就是在训练早期的时候会有一些块‘死亡’,这里作者说死亡应该是其神经元的输出是0。在最后的全局平均池化层之前 feature map里有很多0,且作者说加入了BN和很小的lr后仍然不能解决这个问题。
后面作者提出了这个问题的解决办法,就是在残差映射做加法融合之前先乘以幅度缩小系数,该系数在0.1-0.3之间,层数越深该系数越小。
后一段作者说何凯明的那篇论文就是ResNet最开始的那篇论文中也有这种不稳定现象,但是他们的解决办法是先用超小学习率热身一边,然后再用大学习率,不过本篇论文作者打脸了这种方法,通过实验证明了他的无效,说明了自己的缩小幅度系数比较可靠。
幅度缩小方法结构图:
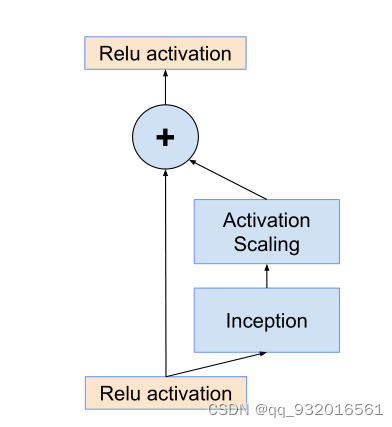
可以看到在inception之后经历了一个幅度缩小步骤然后再相加得到结果。
其实也就是输入进来的数据是前面很多层网络学习后的结果,如果我们想修改这些结果,则乘以一个缩小系数,让他小幅度的修改学习,一点一点的调整,防止网络训练不稳定的情况出现。
实验结果(Experimental Results)
后面作者介绍了一下他模型的超参数,其中基本都和inceptionV3一样,然后说了一下实验结果,总之就是非常好~
作者说他在测试集上表现不错,说明模型没有过拟合,然后还强调只提交了两次,一次是带BN的,一次不带。我在查资料的时候看到一个博主说这一块的一个小插曲就是,百度参加了2015年的 imagenet竞赛,但是提交的次数太多被判无效了(恶意刷榜 或者在猜验证集的数据?),我笑喷了,这果然很百度~~~~(我觉得我这篇文章可能会被和谐~~)。
实验结论:
- inceptionV3 和inception-Resnet V1的准确率差不多,但有残差模块的收敛更快。
- inceptionV4 和inception-ResnetV2的准确率差不多,同样的有残差模块的收敛更快。
最终性能 :
作者最后的也是用了多模型融合(包含144数据增强)的技术,3个inception-ResnetV2 加上1个inceptionV4 ,top-1 :16.4% top-5 :3.1%。
思考和总结
含有ResNet的模型为什么可以加速收敛?
作者也在他的最后一章节的实验记录了带残差模块和不带残差模块的区别,发现带残差模块的模型可以加速训练,我个人理解就是,实际上残差模块是两条路嘛,一条路不变(恒等映射);一条路负责拟合相对于原始网络的残差,去纠正原始网络的偏差,而不是让整体网络去拟合全部的底层映射,这样网络只需要纠正偏差,所以比以前更快了。
实验中的Crops144怎么来的?
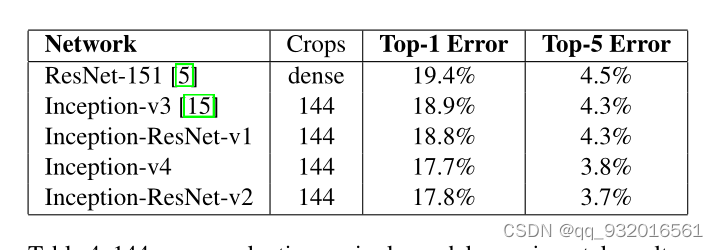
这是在实验那一章放出来的一张图,其中的crops是144,就是将一张图变成144张图,相当于数据增强,这个技术在googlenet 也就是inceptionV1的那篇论文里头出现的,我记着是吧哈哈,而且我在当时复现论文的时候也所过这个144是怎么来的,他们是为了打比赛搞的这种数据增强技术。
对于一张输入的 224 * 224 的图片进行如下操作:(224是Googlenet里,该论文中是299 * 299)
- 将原图缩放为256 288 320 352的四个尺度。
- 每个尺度裁剪出 左中右 或 上中下 的三张图。
- 每个图取四个角或者中央的 224 * 224 尺寸的五张图片。
- 取其水平镜像。
4 * 3 * 6 * 2 = 144个图片,最后融合144个图的结果作为这一张原图的最终结果。相当于为了准确率牺牲了大量的计算力。
小总结
- 对原残差模块的改造,卷积时先加入1 * 1的卷积降维减少运算量。
- 残差结构对于深层网络并非必不可少,比如inceptionV4。
- 通过实验表明之前的使用两段训练(小→大学习率)的方法并不能很好的解决残差块不稳定现象。
- 提出了缩小因子解决残差块的不稳定现象(在inception之后先乘以缩小因子,然后和恒等映射相加)。
- 残差结构对于网络训练的加速效果还不错。
- 最终Inception-ResNetV2模型效果最好。
复现:
InceptionV1
网络搭建
卷积+Relu组合类
论文在介绍Googlenet的那一节中说到了卷积后跟激活函数的结构,所以这里创建一个类将卷积和激活函数放在一起。
class BasicConv2d(nn.Module): def __init__(self, in_channels, out_channels, **kwargs):super(BasicConv2d, self).__init__()self.BC1 = nn.Sequential( nn.Conv2d(in_channels, out_channels, **kwargs),nn.ReLU(inplace=True))def forward(self, x):x = self.BC1(x)return x
这里再定义函数的时候用了 **kwargs,因为后面还要定义inception,inception里的卷积层有不同尺寸的卷积核和padding,所以这里定义了 **kwargs用于接收这些参数,
在调用的时候直接就可以 (输入通道,输出通道,**kwargs),函数会自动解析 **kwargs。
其余代码应该没什么好解释的,都是基础代码,定义了一个卷积层和一个Relu激活函数层放到了Sequential组合里,然后再forward向前传播一下。
辅助分类器类
根据论文给的图,辅助分类器长这样:

从下往上走, 平均池化 -> 卷积(含Relu) -> 全连接 ->全连接。
将细节都加进去就是 平均池化 -> 卷积(含Relu) -> 展平成向量 -> dropout -> 线性层1 -> Relu -> dropout ->线性层2。
同样用Sequential进行组合:
class InceptionAux(nn.Module):def __init__(self, in_channels, num_classes):super(InceptionAux, self).__init__()self.IA1 = nn.Sequential(nn.AvgPool2d(kernel_size=5, stride=3),BasicConv2d(in_channels, 128, kernel_size=1),nn.Flatten(),nn.Dropout2d(p=0.5),nn.Linear(2048, 1024),nn.ReLU(True),nn.Dropout2d(0.5),nn.Linear(1024, num_classes),)def forward(self, x):x = self.IA1(x)return x
inception结构类
论文中给出的inception结构图,输入在下,且整个googlenet的inception都是一样的结构,所以只需要定义一个类,分块操作然后合并就行了。
这里需要注意的是每一个卷积后面都跟着一个池化。

所有卷积操作和池化操作的步长都定义为1,卷积核为3 * 3 的padding = 1,卷积核为 5 * 5的 padding为2。
这里注意要定义好每一个卷积之后的输出通道数,因为后面还要继续卷积。
class Inception(nn.Module): def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj):super(Inception, self).__init__()self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1) #第一个分支。self.branch2 = nn.Sequential( #第二个分支BasicConv2d(in_channels, ch3x3red, kernel_size=1),BasicConv2d(ch3x3red, ch3x3, kernel_size=3, padding=1) )self.branch3 = nn.Sequential( # 第三个分支BasicConv2d(in_channels, ch5x5red, kernel_size=1),BasicConv2d(ch5x5red, ch5x5, kernel_size=5, padding=2) )self.branch4 = nn.Sequential( nn.MaxPool2d(kernel_size=3, stride=1, padding=1),BasicConv2d(in_channels, pool_proj, kernel_size=1))def forward(self, x):branch1 = self.branch1(x) branch2 = self.branch2(x)branch3 = self.branch3(x)branch4 = self.branch4(x)outputs = [branch1, branch2, branch3, branch4]return torch.cat(outputs, 1)
def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj):
这里定义了在inception中每一个块所输出的通道数,表示为: ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj。
torch.cat:
张量拼接。
然后按照上面inception的结构图罗列代码就行了。
最后的outputs列表组合了四个分支的结果,用torch.cat拼接四个分支得到的结果返回。
初始化权重与偏置
文章并没有重点说初始化权重等这些参数,仅在最后参加比赛的时候采用了七模型融合的激进做法时提了一下,所以我觉得这里可加可不加把,加的话就是下面这段代码。
def _initialize_weights(self):for m in self.modules(): if isinstance(m, nn.Conv2d): # 采用凯明初始化nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')if m.bias is not None:# 偏置初始化为0nn.init.constant_(m.bias, 0)elif isinstance(m, nn.Linear): # 如果是全连接层# 权重均值为0, 标准差为0.01nn.init.normal_(m.weight, 0, 0.01)# 偏置为0nn.init.constant_(m.bias, 0)
GoogLeNet模型类
最后一块就是总的模型类了。
# 模型类
class GoogLeNet(nn.Module):def __init__(self, num_classes=1000):super(GoogLeNet, self).__init__()self.Main = nn.Sequential(BasicConv2d(3, 64, kernel_size=7, stride=2, padding=3),nn.MaxPool2d(3, stride=2, ceil_mode=True), # ceil_mode=true代表向上取整BasicConv2d(64, 64, kernel_size=1),BasicConv2d(64, 192, kernel_size=3, padding=1),nn.MaxPool2d(3, stride=2, ceil_mode=True),Inception(192, 64, 96, 128, 16, 32, 32),Inception(256, 128, 128, 192, 32, 96, 64),nn.MaxPool2d(3, stride=2, ceil_mode=True),Inception(480, 192, 96, 208, 16, 48, 64))self.Main2 = nn.Sequential(Inception(512, 160, 112, 224, 24, 64, 64),Inception(512, 128, 128, 256, 24, 64, 64),Inception(512, 112, 144, 288, 32, 64, 64),)self.Main3 = nn.Sequential(Inception(528, 256, 160, 320, 32, 128, 128),nn.MaxPool2d(3, stride=2, ceil_mode=True),Inception(832, 256, 160, 320, 32, 128, 128),Inception(832, 384, 192, 384, 48, 128, 128),# 辅助分类器nn.AdaptiveAvgPool2d((1, 1)),nn.Flatten(),nn.Dropout(0.4),nn.Linear(1024, num_classes),)self.aux1 = InceptionAux(512, num_classes)self.aux2 = InceptionAux(528, num_classes)# 初始化权重self._initialize_weights()# 前向传播def forward(self, x):x = self.Main(x)aux1 = self.aux1(x)x = self.Main2(x)aux2 = self.aux2(x)x = self.Main3(x)# N x 1000 (num_classes)# 在训练模式并且采用辅助分类器的情况下,返回主分类结果和两个辅助分类器的结果return x, aux2, aux
在最后向前传播的时候,分类辅助器和主结果一起返回。
训练集
训练集没啥好说的都是之前那一套,这里唯一的变动就是之前都是返回一个主训练结果,而这里由于多了两个分类器,所以是三个分类结果,按照论文要求,三个分类结果加权求和。
最终的LOSS = L主+0.3 * L辅 + 0.3 * L辅
所以在之前的训练集上稍作改动。
之前的:
y_pre = model(x)
loss = criterion(y_pre, y)
改动之后:
log,aux1,aux2 = model(x)
# 分别计算损失
loss0 = criterion(log, y)
loss1 = criterion(aux1, y)
loss2 = criterion(aux2, y)
# 加权求和
loss = loss0 + loss1 * 0.3 + loss2 * 0.3
程序结果
使用CIFAR10数据集,由于实在跑的慢,懒得看结果了(想去追剧了。。。),直接测试运行了一下 没啥问题。
完整代码一
import torch.nn as nn
import torch
import torch.nn.functional as F
import torchvision
from torch import optim
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn as nn
import matplotlib.pyplot as plt
from torch.utils.tensorboard import SummaryWriter
import cv2batch_size = 4
transform = transforms.Compose([transforms.Resize(224),transforms.ToTensor (),transforms.Normalize((0.4915, 0.4823, 0.4468,), (1.0, 1.0, 1.0)),
])train_dataset = datasets.CIFAR10(root='../data/', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.CIFAR10(root='../data/', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)print("训练集长度",len(train_dataset))
print("测试集长度",len(test_dataset))
# 模型类
from torch import optim# 模型类
class GoogLeNet(nn.Module):def __init__(self, num_classes=1000):super(GoogLeNet, self).__init__()self.Main = nn.Sequential(BasicConv2d(3, 64, kernel_size=7, stride=2, padding=3),nn.MaxPool2d(3, stride=2, ceil_mode=True), # ceil_mode=true代表向上取整BasicConv2d(64, 64, kernel_size=1),BasicConv2d(64, 192, kernel_size=3, padding=1),nn.MaxPool2d(3, stride=2, ceil_mode=True),Inception(192, 64, 96, 128, 16, 32, 32),Inception(256, 128, 128, 192, 32, 96, 64),nn.MaxPool2d(3, stride=2, ceil_mode=True),Inception(480, 192, 96, 208, 16, 48, 64))self.Main2 = nn.Sequential(Inception(512, 160, 112, 224, 24, 64, 64),Inception(512, 128, 128, 256, 24, 64, 64),Inception(512, 112, 144, 288, 32, 64, 64),)self.Main3 = nn.Sequential(Inception(528, 256, 160, 320, 32, 128, 128),nn.MaxPool2d(3, stride=2, ceil_mode=True),Inception(832, 256, 160, 320, 32, 128, 128),Inception(832, 384, 192, 384, 48, 128, 128),# 辅助分类器nn.AdaptiveAvgPool2d((1, 1)),nn.Flatten(),nn.Dropout(0.4),nn.Linear(1024, num_classes),)self.aux1 = InceptionAux(512, num_classes)self.aux2 = InceptionAux(528, num_classes)# 初始化权重self._initialize_weights()# 前向传播def forward(self, x):x = self.Main(x)aux1 = self.aux1(x)x = self.Main2(x)aux2 = self.aux2(x)x = self.Main3(x)return x, aux2, aux1def _initialize_weights(self):for m in self.modules():if isinstance(m, nn.Conv2d):# 采用凯明初始化nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')if m.bias is not None:# 将偏置初始化为0nn.init.constant_(m.bias, 0)elif isinstance(m, nn.Linear): # 如果是全连接层# 权重均值是0, 标准差是0.01nn.init.normal_(m.weight, 0, 0.01)# 偏置是0nn.init.constant_(m.bias, 0)class Inception(nn.Module):def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj):super(Inception, self).__init__()self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1) # 第一个分支self.branch2 = nn.Sequential( # 第二个分支BasicConv2d(in_channels, ch3x3red, kernel_size=1),BasicConv2d(ch3x3red, ch3x3, kernel_size=3, padding=1))self.branch3 = nn.Sequential( # 第三个分支BasicConv2d(in_channels, ch5x5red, kernel_size=1),BasicConv2d(ch5x5red, ch5x5, kernel_size=5, padding=2))self.branch4 = nn.Sequential(nn.MaxPool2d(kernel_size=3, stride=1, padding=1),BasicConv2d(in_channels, pool_proj, kernel_size=1))def forward(self, x):branch1 = self.branch1(x)branch2 = self.branch2(x)branch3 = self.branch3(x)branch4 = self.branch4(x)outputs = [branch1, branch2, branch3, branch4]return torch.cat(outputs, 1)class InceptionAux(nn.Module):def __init__(self, in_channels, num_classes):super(InceptionAux, self).__init__()self.IA1 = nn.Sequential(nn.AvgPool2d(kernel_size=5, stride=3),BasicConv2d(in_channels, 128, kernel_size=1),nn.Flatten(),nn.Dropout2d(p=0.5),nn.Linear(2048, 1024),nn.ReLU(True),nn.Dropout2d(0.5),nn.Linear(1024, num_classes),)def forward(self, x):x = self.IA1(x)return xclass BasicConv2d(nn.Module):def __init__(self, in_channels, out_channels, **kwargs):super(BasicConv2d, self).__init__()self.BC1 = nn.Sequential( # 第四个分支nn.Conv2d(in_channels, out_channels, **kwargs),nn.ReLU(inplace=True))def forward(self, x):x = self.BC1(x)return xmodel = GoogLeNet().cuda()
# 损失函数
criterion = torch.nn.CrossEntropyLoss().cuda()
# 优化器
optimizer = optim.Adam(model.parameters(),lr=0.01)def train(epoch):runing_loss = 0.0i = 1for i, data in enumerate(train_loader):x, y = datax, y = x.cuda(), y.cuda()i +=1if i % 10 == 0:print("运行中,当前运行次数:",i)# 清零 正向传播 损失函数 反向传播 更新optimizer.zero_grad()# y_pre = model(x)# loss = criterion(y_pre, y)log,aux1,aux2 = model(x)loss0 = criterion(log, y)loss1 = criterion(aux1, y)loss2 = criterion(aux2, y)loss = loss0 + loss1 * 0.3 + loss2 * 0.3loss.backward()optimizer.step()runing_loss += loss.item()# 每轮训练一共训练1W个样本,这里的runing_loss是1W个样本的总损失值,要看每一个样本的平均损失值, 记得除10000print("这是第 %d轮训练,当前损失值 %.5f" % (epoch + 1, runing_loss / 782))return runing_loss / 782def test(epoch):correct = 0total = 0with torch.no_grad():for data in test_loader:x, y = datax, y = x.cuda(), y.cuda()pre_y = model(x)# 这里拿到的预测值 每一行都对应10个分类,这10个分类都有对应的概率,# 我们要拿到最大的那个概率和其对应的下标。j, pre_y = torch.max(pre_y.data, dim=1) # dim = 1 列是第0个维度,行是第1个维度total += y.size(0) # 统计方向0上的元素个数 即样本个数correct += (pre_y == y).sum().item() # 张量之间的比较运算print("第%d轮测试结束,当前正确率:%d %%" % (epoch + 1, correct / total * 100))return correct / total * 100if __name__ == '__main__':plt_epoch = []loss_ll = []corr = []for epoch in range(1):plt_epoch.append(epoch+1) # 方便绘图loss_ll.append(train(epoch)) # 记录每一次的训练损失值 方便绘图corr.append(test(epoch)) # 记录每一次的正确率plt.rcParams['font.sans-serif'] = ['KaiTi']plt.figure(figsize=(12,6))plt.subplot(1,2,1)plt.title("训练模型")plt.plot(plt_epoch,loss_ll)plt.xlabel("循环次数")plt.ylabel("损失值loss")plt.subplot(1,2,2)plt.title("测试模型")plt.plot(plt_epoch,corr)plt.xlabel("循环次数")plt.ylabel("正确率")plt.show()
总结
GoogleNet是之后学习各种网络变种的基础,他提出了很多新颖的点的。
- 使用了赫布理论和多尺度处理方法,提出了inception结构,既占了稀疏的优势,又利用了硬件计算密集数据的优势,改善了VGG数据量巨大,嫉妒耗费资源的问题。
- 将1 * 1 卷积核应用到里面了,再次提升了对 1 * 1的认识。
- 提出使用辅助分类器在浅层或者中层提前出一波分类结果,然后和整体结果加权作为最后结果。
- 最后提出了七模型融合 + 1图变 144图的激进方法用于比赛。
最后在复现代码的时候,一定要注意辅助分类层放的位置,就这个辅助分类层和上一个inception层前后顺序错了 导致调试了一个多小时(我太菜了,pytorch不熟.开摆!),整个程序从VGG改成Googlenet都没用一个小时,就离谱,明后天可能弄一下resnet吧。
完整代码二
import torch
import torch.nn as nn
import torch.nn.functional as F
# noinspection PyUnresolvedReferences
from torchsummary import summary #torchsummary功能:查看网络层形状、参数'''-------------------------第一步:定义基础卷积模块(卷积+ReLU+前向传播函数)--------'''
class BasicConv2d(nn.Module):# init():进行初始化,申明模型中各层的定义def __init__(self, in_channels, out_channels, **kwargs):''':param in_channels: 输入特征矩阵的深度:param out_channels:输出特征矩阵的深度:param kwargs:*args代表任何多个无名参数,返回的是元组;**kwargs表示关键字参数,所有传入的key=value,返回字典;'''super(BasicConv2d, self).__init__()#BasicConv2d():卷积激活'''卷积层'''self.conv = nn.Conv2d(in_channels, out_channels, **kwargs)'''Relu层'''self.relu = nn.ReLU(inplace=True) # ReLU(inplace=True):将tensor直接修改,不找变量做中间的传递,节省运算内存,不用多存储额外的变量'''前向传播函数'''def forward(self, x):x = self.conv(x)x = self.relu(x)return x'''-------------------------第二步:定义Inception模块----------------------------'''
class Inception(nn.Module):def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj):super(Inception, self).__init__()'''branch1——单个1x1卷积层'''#使用1*1的卷积核,将(Hin,Win,in_channels)-> (Hin,Win,ch1x1),特征图大小不变,主要改变的是通道数得到第一张特征图(Hin,Win,ch1x1)。self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)'''branch2——1x1卷积层后接3x3卷积层'''#先使用1*1的卷积核,将(Hin,Win,in_channels)-> (Hin,Win,ch3x3red),特征图大小不变,缩小通道数,减少计算量,然后在使用大小3*3填充1的卷积核,保持特征图大小不变,改变通道数为ch3x3,得到第二张特征图(Hin,Win,ch3x3)。self.branch2 = nn.Sequential(BasicConv2d(in_channels, ch3x3red, kernel_size=1),# 保证输出大小等于输入大小BasicConv2d(ch3x3red, ch3x3, kernel_size=3, padding=1))'''branch3——1x1卷积层后接5x5卷积层'''#先使用1*1的卷积核,将(Hin,Win,in_channels)-> (Hin,Win,ch5x5red),特征图大小不变,缩小通道数,减少计算量,然后在使用大小5*5填充2的卷积核,保持特征图大小不变,改变通道数为ch5x5,得到第三张特征图(Hin,Win,ch5x5)。self.branch3 = nn.Sequential(BasicConv2d(in_channels, ch5x5red, kernel_size=1),# 保证输出大小等于输入大小BasicConv2d(ch5x5red, ch5x5, kernel_size=5, padding=2))'''branch4——3x3最大池化层后接1x1卷积层'''#先经过最大池化层,因为stride=1,特征图大小不变,然后在使用大小1*1的卷积核,保持特征图大小不变,改变通道数为pool_proj,得到第四张特征图(Hin,Win,pool_proj)。self.branch4 = nn.Sequential(nn.MaxPool2d(kernel_size=3, stride=1, padding=1),BasicConv2d(in_channels, pool_proj, kernel_size=1))# forward():定义前向传播过程,描述了各层之间的连接关系def forward(self, x):branch1 = self.branch1(x)branch2 = self.branch2(x)branch3 = self.branch3(x)branch4 = self.branch4(x)# 在通道维上拼接输出最终特征图。(Hin,Win,ch1x1+ch1x1+ch5x5+pool_proj)outputs = [branch1, branch2, branch3, branch4]# cat():在给定维度上对输入的张量序列进行连接操作return torch.cat(outputs, 1)'''---------------------第三步:定义辅助分类器InceptionAux----------------------'''
class InceptionAux(nn.Module):def __init__(self, in_channels, num_classes):super(InceptionAux, self).__init__()'''均值池化'''# nn.AvgPool2d(kernel_size=5, stride=3):平均池化下采样。核大小为5x5,步长为3。self.averagePool = nn.AvgPool2d(kernel_size=5, stride=3)'''1×1卷积'''self.conv = BasicConv2d(in_channels, 128, kernel_size=1)'''全连接输出'''# nn.Linear(2048, 1024)、nn.Linear(1024, num_classes):经过两个全连接层得到分类的一维向量。# 上一层output[batch, 128, 4, 4],128X4X4=2048self.fc1 = nn.Linear(2048, 1024)self.fc2 = nn.Linear(1024, num_classes)# 前向传播过程:即如何根据输入x计算返回所需要的模型输出def forward(self, x):# 输入:aux1: N x 512 x 14 x 14, aux2: N x 528 x 14 x 14x = self.averagePool(x)# 输入:aux1: N x 512 x 4 x 4, aux2: N x 528 x 4 x 4x = self.conv(x)# 输入:N x 128 x 4 x 4x = torch.flatten(x, 1)#torch.flatten(x, 1):从深度方向对特征矩阵进行推平处理,从三维降到二维。# 设置.train()时为训练模式,self.training=Truex = F.dropout(x, 0.5, training=self.training)# 输入:N x 2048x = F.relu(self.fc1(x), inplace=True)x = F.dropout(x, 0.5, training=self.training)# 输入:N x 1024x = self.fc2(x)# 返回值:N*num_classesreturn x'''-------------------------第四步:GoogLeNet网络----------------------'''
class GoogLeNet(nn.Module):def __init__(self, num_classes=2, aux_logits=True, init_weights=False):'''init():进行初始化,申明模型中各层的定义:param num_classes: 需要分类的类别个数:param aux_logits: 训练过程是否使用辅助分类器,init_weights:是否对网络进行权重初始化:param init_weights:初始化权重'''super(GoogLeNet, self).__init__()# aux_logits: 是否使用辅助分类器(训练的时候为True, 验证的时候为False)self.aux_logits = aux_logits'''第一部分:一个卷积层+一个最大池化层'''self.conv1 = BasicConv2d(3, 64, kernel_size=7, stride=2, padding=3)# 最大池化层类MaxPool2d()参数含义:kernel_size :表示做最大池化的窗口大小,stride :步长, padding :填充,dilation :控制窗口中元素步幅,return_indices :布尔类型,返回最大值位置索引,# ceil_mode :布尔类型,为True,用向上取整的方法,计算输出形状;默认是向下取整。self.maxpool1 = nn.MaxPool2d(3, stride=2, ceil_mode=True)'''第二部分:两个卷积层+一个最大池化层'''self.conv2 = BasicConv2d(64, 64, kernel_size=1)self.conv3 = BasicConv2d(64, 192, kernel_size=3, padding=1)self.maxpool2 = nn.MaxPool2d(3, stride=2, ceil_mode=True)'''第三部分:3a层和3b层+最大池化层'''self.inception3a = Inception(192, 64, 96, 128, 16, 32, 32)'''# Inception(192, 64, 96, 128, 16, 32, 32)中参数分别代表输入深度为192的特征矩阵,第一层卷积核数量为64,输出深度64。第二层卷积核数量为96,输出深度96。第三层卷积核数量为128,输出深度128。第四层卷积核数量为16,输出深度16。第五层卷积核数量为32,输出深度32。第六层最大池化输出深度32不变。'''self.inception3b = Inception(256, 128, 128, 192, 32, 96, 64)self.maxpool3 = nn.MaxPool2d(3, stride=2, ceil_mode=True)'''第四部分:4a层、4b层、4c层、4d层、4e层+最大池化层'''self.inception4a = Inception(480, 192, 96, 208, 16, 48, 64)self.inception4b = Inception(512, 160, 112, 224, 24, 64, 64)self.inception4c = Inception(512, 128, 128, 256, 24, 64, 64)self.inception4d = Inception(512, 112, 144, 288, 32, 64, 64)self.inception4e = Inception(528, 256, 160, 320, 32, 128, 128)self.maxpool4 = nn.MaxPool2d(3, stride=2, ceil_mode=True)'''第五部分:5a层和5b层'''self.inception5a = Inception(832, 256, 160, 320, 32, 128, 128)self.inception5b = Inception(832, 384, 192, 384, 48, 128, 128)# 如果为真,则使用辅助分类器if self.aux_logits:self.aux1 = InceptionAux(512, num_classes) # aux1传入的深度是来自于inception4a的输出深度,所以为512.即为4a提供分类服务self.aux2 = InceptionAux(528, num_classes) # aux2传入的深度是来自于inception4d的输出深度,所以为528.即为4d提供分类服务'''均值池化 '''# AdaptiveAvgPool2d:自适应平均池化,指定输出(H,W)self.avgpool = nn.AdaptiveAvgPool2d((1, 1))self.dropout = nn.Dropout(0.4)'''全连接输出 '''self.fc = nn.Linear(1024, num_classes)# 如果为真,则对网络参数进行初始化if init_weights:self._initialize_weights()# forward():定义前向传播过程,描述了各层之间的连接关系def forward(self, x):# N x 3 x 224 x 224x = self.conv1(x)# N x 64 x 112 x 112x = self.maxpool1(x)# N x 64 x 56 x 56x = self.conv2(x)# N x 64 x 56 x 56x = self.conv3(x)# N x 192 x 56 x 56x = self.maxpool2(x)# N x 192 x 28 x 28x = self.inception3a(x)# N x 256 x 28 x 28x = self.inception3b(x)# N x 480 x 28 x 28x = self.maxpool3(x)# N x 480 x 14 x 14'''在4a层和4b层、4d和4e层之间会有一个判断:如果使用辅助分类器会调用辅助分类器aux1并返回一个分类结果'''x = self.inception4a(x)# N x 512 x 14 x 14# 设置.train()时为训练模式,self.training=Trueif self.training and self.aux_logits:aux1 = self.aux1(x)x = self.inception4b(x)# N x 512 x 14 x 14x = self.inception4c(x)# N x 512 x 14 x 14x = self.inception4d(x)# N x 528 x 14 x 14if self.training and self.aux_logits:aux2 = self.aux2(x)x = self.inception4e(x)# N x 832 x 14 x 14x = self.maxpool4(x)# N x 832 x 7 x 7x = self.inception5a(x)# N x 832 x 7 x 7x = self.inception5b(x)# N x 1024 x 7 x 7'''最终分类部分''''''由平均池化层+dropout+全连接层输出x,如果使用到辅助分类器就输出x, aux2, aux1。其中采用了平均池化层来代替全连接层,事实证明这样可以提高准确率0.6%。最后还是加了一个全连接层,主要是为了方便对输出进行灵活调整。'''x = self.avgpool(x)# N x 1024 x 1 x 1x = torch.flatten(x, 1)# N x 1024x = self.dropout(x)x = self.fc(x)'''最后在全连接层之后还会有一个判断:判断模型若处于训练状态并且调用辅助分类器则返回3个结果:主分类结果,分类器1和分类器2生成的分类结果。'''# N x 1000 (num_classes)if self.training and self.aux_logits:return x, aux2, aux1return x'''-------------------------------网络结构参数初始化---------------------------'''#目的:使网络更好收敛,准确率更高def _initialize_weights(self):# 将各种初始化方法定义为一个initialize_weights()的函数并在模型初始后进行使用。# 遍历网络中的每一层for m in self.modules():# isinstance(object, type),如果指定的对象拥有指定的类型,则isinstance()函数返回True'''如果是卷积层Conv2d'''if isinstance(m, nn.Conv2d):# Kaiming正态分布方式的权重初始化nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')'''判断是否有偏置:'''# 如果偏置不是0,将偏置置成0,对偏置进行初始化if m.bias is not None:# torch.nn.init.constant_(tensor, val),初始化整个矩阵为常数valnn.init.constant_(m.bias, 0)'''如果是全连接层'''elif isinstance(m, nn.Linear):# init.normal_(tensor, mean=0.0, std=1.0),使用从正态分布中提取的值填充输入张量# 参数:tensor:一个n维Tensor,mean:正态分布的平均值,std:正态分布的标准差nn.init.normal_(m.weight, 0, 0.01)nn.init.constant_(m.bias, 0)if __name__ == '__main__':# 随机输入,测试网络结构是否通net = GoogLeNet(num_classes=2).cuda()summary(net, (3, 224, 224))
InceptionV3
第一步:定义基础卷积模块
卷积模块较上次多了BN层
BatchNorm2d()函数:
**作用:**卷积层之后总会添加BatchNorm2d进行数据的归一化处理,这使得数据在进行Relu之前不会因为数据过大而导致网络性能的不稳定
举例:
BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
1.num_features:一般输入参数的shape为batch_sizenum_featuresheight*width,即为其中特征的数量,即为输入BN层的通道数;
*2.eps:*分母中添加的一个值,目的是为了计算的稳定性,默认为:1e-5,避免分母为0;
*3.momentum:*一个用于运行过程中均值和方差的一个估计参数(可以理解是一个稳定系数,类似于SGD中的momentum的系数);
*4.affine:*当设为true时,会给定可以学习的系数矩阵gamma和beta
class BasicConv2d(nn.Module):def __init__(self, in_channels, out_channels, **kwargs):super(BasicConv2d, self).__init__()self.conv = nn.Conv2d(in_channels, out_channels, bias=False, **kwargs)self.bn = nn.BatchNorm2d(out_channels, eps=0.001)def forward(self, x):x = self.conv(x)x = self.bn(x)return F.relu(x, inplace=True)
第二步:定义Inceptionv3模块
PyTorch提供的有六种基本的Inception模块,分别是InceptionA——InceptionE。
InceptionA

得到输入大小不变,通道数为224+pool_features的特征图。
假如输入为**(35, 35, 192)**的数据:
第一个branch:
经过branch1x1为带有64个11的卷积核,所以生成第一张特征图(35, 35, 64);
第二个branch:
首先经过branch5x5_1为带有48个11的卷积核,所以第二张特征图(35, 35, 48),
然后经过branch5x5_2为带有64个55大小且填充为2的卷积核,特征图大小依旧不变,因此第二张特征图最终为(35, 35, 64);
第三个branch:
首先经过branch3x3dbl_1为带有64个11的卷积核,所以第三张特征图(35, 35, 64),
然后经过branch3x3dbl_2为带有96个33大小且填充为1的卷积核,特征图大小依旧不变,因此进一步生成第三张特征图(35, 35, 96),
最后经过branch3x3dbl_3为带有96个33大小且填充为1的卷积核,特征图大小和通道数不变,因此第三张特征图最终为(35, 35, 96);
第四个branch:
首先经过avg_pool2d,其中池化核33,步长为1,填充为1,所以第四张特征图大小不变,通道数不变,第四张特征图为(35, 35, 192),
然后经过branch_pool为带有pool_features个的11卷积,因此第四张特征图最终为(35, 35, pool_features);
最后将四张特征图进行拼接,最终得到**(35,35,64+64+96+pool_features)**的特征图。
'''---InceptionA---'''
class InceptionA(nn.Module):def __init__(self, in_channels, pool_features, conv_block=None):super(InceptionA, self).__init__()if conv_block is None:conv_block = BasicConv2dself.branch1x1 = conv_block(in_channels, 64, kernel_size=1)self.branch5x5_1 = conv_block(in_channels, 48, kernel_size=1)self.branch5x5_2 = conv_block(48, 64, kernel_size=5, padding=2)self.branch3x3dbl_1 = conv_block(in_channels, 64, kernel_size=1)self.branch3x3dbl_2 = conv_block(64, 96, kernel_size=3, padding=1)self.branch3x3dbl_3 = conv_block(96, 96, kernel_size=3, padding=1)self.branch_pool = conv_block(in_channels, pool_features, kernel_size=1)def _forward(self, x):branch1x1 = self.branch1x1(x)branch5x5 = self.branch5x5_1(x)branch5x5 = self.branch5x5_2(branch5x5)branch3x3dbl = self.branch3x3dbl_1(x)branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)branch3x3dbl = self.branch3x3dbl_3(branch3x3dbl)branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)branch_pool = self.branch_pool(branch_pool)outputs = [branch1x1, branch5x5, branch3x3dbl, branch_pool]return outputsdef forward(self, x):outputs = self._forward(x)return torch.cat(outputs, 1)
InceptionB

得到输入大小减半,通道数为480的特征图,
假如输入为**(35, 35, 288)**的数据:
第一个branch:
经过branch1x1为带有384个33大小且步长2的卷积核,(35-3+20)/2+1=17所以生成第一张特征图(17, 17, 384);
第二个branch:
首先经过branch3x3dbl_1为带有64个11的卷积核,特征图大小不变,即(35, 35, 64);
然后经过branch3x3dbl_2为带有96个33大小填充1的卷积核,特征图大小不变,即(35, 35, 96),
再经过branch3x3dbl_3为带有96个33大小步长2的卷积核,(35-3+20)/2+1=17,即第二张特征图为(17, 17, 96);
第三个branch:
经过max_pool2d,池化核大小3*3,步长为2,所以是二倍最大值下采样,通道数保持不变,第三张特征图为(17, 17, 288);
最后将三张特征图进行拼接,最终得到**(17(即Hin/2),17(即Win/2),384+96+288(Cin)=768)**的特征图。
'''---InceptionB---'''
class InceptionB(nn.Module):def __init__(self, in_channels, conv_block=None):super(InceptionB, self).__init__()if conv_block is None:conv_block = BasicConv2dself.branch3x3 = conv_block(in_channels, 384, kernel_size=3, stride=2)self.branch3x3dbl_1 = conv_block(in_channels, 64, kernel_size=1)self.branch3x3dbl_2 = conv_block(64, 96, kernel_size=3, padding=1)self.branch3x3dbl_3 = conv_block(96, 96, kernel_size=3, stride=2)def _forward(self, x):branch3x3 = self.branch3x3(x)branch3x3dbl = self.branch3x3dbl_1(x)branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)branch3x3dbl = self.branch3x3dbl_3(branch3x3dbl)branch_pool = F.max_pool2d(x, kernel_size=3, stride=2)outputs = [branch3x3, branch3x3dbl, branch_pool]return outputsdef forward(self, x):outputs = self._forward(x)return torch.cat(outputs, 1)
InceptionC

得到输入大小不变,通道数为768的特征图。
假如输入为**(17,17, 768)**的数据:
第一个branch:
首先经过branch1x1为带有192个1*1的卷积核,所以生成第一张特征图(17,17, 192);
第二个branch:
首先经过branch7x7_1为带有c7个11的卷积核,所以第二张特征图(17,17, c7),
然后经过branch7x7_2为带有c7个17大小且填充为03的卷积核,特征图大小不变,进一步生成第二张特征图(17,17, c7),
然后经过branch7x7_3为带有192个71大小且填充为30的卷积核,特征图大小不变,进一步生成第二张特征图(17,17, 192),因此第二张特征图最终为(17,17, 192);
第三个branch:
首先经过branch7x7dbl_1为带有c7个11的卷积核,所以第三张特征图(17,17, c7),
然后经过branch7x7dbl_2为带有c7个71大小且填充为30的卷积核,特征图大小不变,进一步生成第三张特征图(17,17, c7),
然后经过branch7x7dbl_3为带有c7个17大小且填充为03的卷积核,特征图大小不变,进一步生成第三张特征图(17,17, c7),
然后经过branch7x7dbl_4为带有c7个71大小且填充为30的卷积核,特征图大小不变,进一步生成第三张特征图(17,17, c7),
然后经过branch7x7dbl_5为带有192个17大小且填充为03的卷积核,特征图大小不变,因此第二张特征图最终为(17,17, 192);
第四个branch:
首先经过avg_pool2d,其中池化核33,步长为1,填充为1,所以第四张特征图大小不变,通道数不变,第四张特征图为(17,17, 768),
然后经过branch_pool为带有192个的11卷积,因此第四张特征图最终为(17,17, 192);
最后将四张特征图进行拼接,最终得到**(17, 17, 192+192+192+192=768)**的特征图。
'''---InceptionC---'''
class InceptionC(nn.Module):def __init__(self, in_channels, channels_7x7, conv_block=None):super(InceptionC, self).__init__()if conv_block is None:conv_block = BasicConv2dself.branch1x1 = conv_block(in_channels, 192, kernel_size=1)c7 = channels_7x7self.branch7x7_1 = conv_block(in_channels, c7, kernel_size=1)self.branch7x7_2 = conv_block(c7, c7, kernel_size=(1, 7), padding=(0, 3))self.branch7x7_3 = conv_block(c7, 192, kernel_size=(7, 1), padding=(3, 0))self.branch7x7dbl_1 = conv_block(in_channels, c7, kernel_size=1)self.branch7x7dbl_2 = conv_block(c7, c7, kernel_size=(7, 1), padding=(3, 0))self.branch7x7dbl_3 = conv_block(c7, c7, kernel_size=(1, 7), padding=(0, 3))self.branch7x7dbl_4 = conv_block(c7, c7, kernel_size=(7, 1), padding=(3, 0))self.branch7x7dbl_5 = conv_block(c7, 192, kernel_size=(1, 7), padding=(0, 3))self.branch_pool = conv_block(in_channels, 192, kernel_size=1)def _forward(self, x):branch1x1 = self.branch1x1(x)branch7x7 = self.branch7x7_1(x)branch7x7 = self.branch7x7_2(branch7x7)branch7x7 = self.branch7x7_3(branch7x7)branch7x7dbl = self.branch7x7dbl_1(x)branch7x7dbl = self.branch7x7dbl_2(branch7x7dbl)branch7x7dbl = self.branch7x7dbl_3(branch7x7dbl)branch7x7dbl = self.branch7x7dbl_4(branch7x7dbl)branch7x7dbl = self.branch7x7dbl_5(branch7x7dbl)branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)branch_pool = self.branch_pool(branch_pool)outputs = [branch1x1, branch7x7, branch7x7dbl, branch_pool]return outputsdef forward(self, x):outputs = self._forward(x)return torch.cat(outputs, 1)
InceptionD

得到输入大小减半,通道数512的特征图,
假如输入为**(17, 17, 768)**的数据:
第一个branch:
首先经过branch3x3_1为带有192个11的卷积核,所以生成第一张特征图(17, 17, 192);
然后经过branch3x3_2为带有320个33大小步长为2的卷积核,(17-3+20)/2+1=8,最终第一张特征图(8, 8, 320);
第二个branch:
首先经过branch7x7x3_1为带有192个11的卷积核,特征图大小不变,即(17, 17, 192);
然后经过branch7x7x3_2为带有192个17大小且填充为03的卷积核,特征图大小不变,进一步生成第三张特征图(17,17, 192);
再经过branch7x7x3_3为带有192个71大小且填充为30的卷积核,特征图大小不变,进一步生成第三张特征图(17,17, 192);
最后经过branch7x7x3_4为带有192个3*3大小步长为2的卷积核,最终第一张特征图(8, 8, 192);
第三个branch:
首先经过max_pool2d,池化核大小3*3,步长为2,所以是二倍最大值下采样,通道数保持不变,第三张特征图为(8, 8, 768);
最后将三张特征图进行拼接,最终得到**(8(即Hin/2),8(即Win/2),320+192+768(Cin)=1280)**的特征图。
'''---InceptionC---'''
class InceptionC(nn.Module):def __init__(self, in_channels, channels_7x7, conv_block=None):super(InceptionC, self).__init__()if conv_block is None:conv_block = BasicConv2dself.branch1x1 = conv_block(in_channels, 192, kernel_size=1)c7 = channels_7x7self.branch7x7_1 = conv_block(in_channels, c7, kernel_size=1)self.branch7x7_2 = conv_block(c7, c7, kernel_size=(1, 7), padding=(0, 3))self.branch7x7_3 = conv_block(c7, 192, kernel_size=(7, 1), padding=(3, 0))self.branch7x7dbl_1 = conv_block(in_channels, c7, kernel_size=1)self.branch7x7dbl_2 = conv_block(c7, c7, kernel_size=(7, 1), padding=(3, 0))self.branch7x7dbl_3 = conv_block(c7, c7, kernel_size=(1, 7), padding=(0, 3))self.branch7x7dbl_4 = conv_block(c7, c7, kernel_size=(7, 1), padding=(3, 0))self.branch7x7dbl_5 = conv_block(c7, 192, kernel_size=(1, 7), padding=(0, 3))self.branch_pool = conv_block(in_channels, 192, kernel_size=1)def _forward(self, x):branch1x1 = self.branch1x1(x)branch7x7 = self.branch7x7_1(x)branch7x7 = self.branch7x7_2(branch7x7)branch7x7 = self.branch7x7_3(branch7x7)branch7x7dbl = self.branch7x7dbl_1(x)branch7x7dbl = self.branch7x7dbl_2(branch7x7dbl)branch7x7dbl = self.branch7x7dbl_3(branch7x7dbl)branch7x7dbl = self.branch7x7dbl_4(branch7x7dbl)branch7x7dbl = self.branch7x7dbl_5(branch7x7dbl)branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)branch_pool = self.branch_pool(branch_pool)outputs = [branch1x1, branch7x7, branch7x7dbl, branch_pool]return outputsdef forward(self, x):outputs = self._forward(x)return torch.cat(outputs, 1)
InceptionE

最终得到输入大小不变,通道数为2048的特征图。
假如输入为**(8,8, 1280)**的数据:
第一个branch:
首先经过branch1x1为带有320个11的卷积核,所以生成第一张特征图(8, 8, 320);
第二个branch:
首先经过branch3x3_1为带有384个11的卷积核,所以第二张特征图(8, 8, 384),
经过分支branch3x3_2a为带有384个13大小且填充为01的卷积核,特征图大小不变,进一步生成特征图(8,8, 384),
经过分支branch3x3_2b为带有192个31大小且填充为10的卷积核,特征图大小不变,进一步生成特征图(8,8, 384),
因此第二张特征图最终为两个分支拼接(8,8, 384+384=768);
第三个branch:
首先经过branch3x3dbl_1为带有448个11的卷积核,所以第三张特征图(8,8, 448),
然后经过branch3x3dbl_2为带有384个33大小且填充为1的卷积核,特征图大小不变,进一步生成第三张特征图(8,8, 384),
经过分支branch3x3dbl_3a为带有384个13大小且填充为01的卷积核,特征图大小不变,进一步生成特征图(8,8, 384),
经过分支branch3x3dbl_3b为带有384个31大小且填充为10的卷积核,特征图大小不变,进一步生成特征图(8,8, 384),
因此第三张特征图最终为两个分支拼接(8,8, 384+384=768);
第四个branch:
首先经过avg_pool2d,其中池化核33,步长为1,填充为1,所以第四张特征图大小不变,通道数不变,第四张特征图为(8,8, 1280),
然后经过branch_pool为带有192个的11卷积,因此第四张特征图最终为(8,8, 192);
最后将四张特征图进行拼接,最终得到**(8, 8, 320+768+768+192=2048)**的特征图。
'''---InceptionE---'''
class InceptionE(nn.Module):def __init__(self, in_channels, conv_block=None):super(InceptionE, self).__init__()if conv_block is None:conv_block = BasicConv2dself.branch1x1 = conv_block(in_channels, 320, kernel_size=1)self.branch3x3_1 = conv_block(in_channels, 384, kernel_size=1)self.branch3x3_2a = conv_block(384, 384, kernel_size=(1, 3), padding=(0, 1))self.branch3x3_2b = conv_block(384, 384, kernel_size=(3, 1), padding=(1, 0))self.branch3x3dbl_1 = conv_block(in_channels, 448, kernel_size=1)self.branch3x3dbl_2 = conv_block(448, 384, kernel_size=3, padding=1)self.branch3x3dbl_3a = conv_block(384, 384, kernel_size=(1, 3), padding=(0, 1))self.branch3x3dbl_3b = conv_block(384, 384, kernel_size=(3, 1), padding=(1, 0))self.branch_pool = conv_block(in_channels, 192, kernel_size=1)def _forward(self, x):branch1x1 = self.branch1x1(x)branch3x3 = self.branch3x3_1(x)branch3x3 = [self.branch3x3_2a(branch3x3),self.branch3x3_2b(branch3x3),]branch3x3 = torch.cat(branch3x3, 1)branch3x3dbl = self.branch3x3dbl_1(x)branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)branch3x3dbl = [self.branch3x3dbl_3a(branch3x3dbl),self.branch3x3dbl_3b(branch3x3dbl),]branch3x3dbl = torch.cat(branch3x3dbl, 1)branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)branch_pool = self.branch_pool(branch_pool)outputs = [branch1x1, branch3x3, branch3x3dbl, branch_pool]return outputsdef forward(self, x):outputs = self._forward(x)return torch.cat(outputs, 1)
第三步:定义辅助分类器InceptionAux

class InceptionAux(nn.Module):def __init__(self, in_channels, num_classes, conv_block=None):super(InceptionAux, self).__init__()if conv_block is None:conv_block = BasicConv2dself.conv0 = conv_block(in_channels, 128, kernel_size=1)self.conv1 = conv_block(128, 768, kernel_size=5)self.conv1.stddev = 0.01self.fc = nn.Linear(768, num_classes)self.fc.stddev = 0.001def forward(self, x):# N x 768 x 17 x 17x = F.avg_pool2d(x, kernel_size=5, stride=3)# N x 768 x 5 x 5x = self.conv0(x)# N x 128 x 5 x 5x = self.conv1(x)# N x 768 x 1 x 1# Adaptive average poolingx = F.adaptive_avg_pool2d(x, (1, 1))# N x 768 x 1 x 1x = torch.flatten(x, 1)# N x 768x = self.fc(x)# N x 1000return x
第四步:搭建GoogLeNet网络
'''-----------------------搭建GoogLeNet网络--------------------------'''
class GoogLeNet(nn.Module):def __init__(self, num_classes=1000, aux_logits=True, transform_input=False,inception_blocks=None):super(GoogLeNet, self).__init__()if inception_blocks is None:inception_blocks = [BasicConv2d, InceptionA, InceptionB, InceptionC,InceptionD, InceptionE, InceptionAux]assert len(inception_blocks) == 7conv_block = inception_blocks[0]inception_a = inception_blocks[1]inception_b = inception_blocks[2]inception_c = inception_blocks[3]inception_d = inception_blocks[4]inception_e = inception_blocks[5]inception_aux = inception_blocks[6]self.aux_logits = aux_logitsself.transform_input = transform_inputself.Conv2d_1a_3x3 = conv_block(3, 32, kernel_size=3, stride=2)self.Conv2d_2a_3x3 = conv_block(32, 32, kernel_size=3)self.Conv2d_2b_3x3 = conv_block(32, 64, kernel_size=3, padding=1)self.Conv2d_3b_1x1 = conv_block(64, 80, kernel_size=1)self.Conv2d_4a_3x3 = conv_block(80, 192, kernel_size=3)self.Mixed_5b = inception_a(192, pool_features=32)self.Mixed_5c = inception_a(256, pool_features=64)self.Mixed_5d = inception_a(288, pool_features=64)self.Mixed_6a = inception_b(288)self.Mixed_6b = inception_c(768, channels_7x7=128)self.Mixed_6c = inception_c(768, channels_7x7=160)self.Mixed_6d = inception_c(768, channels_7x7=160)self.Mixed_6e = inception_c(768, channels_7x7=192)if aux_logits:self.AuxLogits = inception_aux(768, num_classes)self.Mixed_7a = inception_d(768)self.Mixed_7b = inception_e(1280)self.Mixed_7c = inception_e(2048)self.fc = nn.Linear(2048, num_classes)
'''输入(229,229,3)的数据,首先归一化输入,经过5个卷积,2个最大池化层。'''def _forward(self, x):# N x 3 x 299 x 299x = self.Conv2d_1a_3x3(x)# N x 32 x 149 x 149x = self.Conv2d_2a_3x3(x)# N x 32 x 147 x 147x = self.Conv2d_2b_3x3(x)# N x 64 x 147 x 147x = F.max_pool2d(x, kernel_size=3, stride=2)# N x 64 x 73 x 73x = self.Conv2d_3b_1x1(x)# N x 80 x 73 x 73x = self.Conv2d_4a_3x3(x)# N x 192 x 71 x 71x = F.max_pool2d(x, kernel_size=3, stride=2)'''然后经过3个InceptionA结构,1个InceptionB,3个InceptionC,1个InceptionD,2个InceptionE,其中InceptionA,辅助分类器AuxLogits以经过最后一个InceptionC的输出为输入。'''# 35 x 35 x 192x = self.Mixed_5b(x) # InceptionA(192, pool_features=32)# 35 x 35 x 256x = self.Mixed_5c(x) # InceptionA(256, pool_features=64)# 35 x 35 x 288x = self.Mixed_5d(x) # InceptionA(288, pool_features=64)# 35 x 35 x 288x = self.Mixed_6a(x) # InceptionB(288)# 17 x 17 x 768x = self.Mixed_6b(x) # InceptionC(768, channels_7x7=128)# 17 x 17 x 768x = self.Mixed_6c(x) # InceptionC(768, channels_7x7=160)# 17 x 17 x 768x = self.Mixed_6d(x) # InceptionC(768, channels_7x7=160)# 17 x 17 x 768x = self.Mixed_6e(x) # InceptionC(768, channels_7x7=192)# 17 x 17 x 768if self.training and self.aux_logits:aux = self.AuxLogits(x) # InceptionAux(768, num_classes)# 17 x 17 x 768x = self.Mixed_7a(x) # InceptionD(768)# 8 x 8 x 1280x = self.Mixed_7b(x) # InceptionE(1280)# 8 x 8 x 2048x = self.Mixed_7c(x) # InceptionE(2048)'''进入分类部分。经过平均池化层+dropout+打平+全连接层输出'''x = F.adaptive_avg_pool2d(x, (1, 1))# N x 2048 x 1 x 1x = F.dropout(x, training=self.training)# N x 2048 x 1 x 1x = torch.flatten(x, 1)#Flatten()就是将2D的特征图压扁为1D的特征向量,是展平操作,进入全连接层之前使用,类才能写进nn.Sequential# N x 2048x = self.fc(x)# N x 1000 (num_classes)return x, auxdef forward(self, x):x, aux = self._forward(x)return x, aux'''-----------------------搭建GoogLeNet网络--------------------------'''
class GoogLeNet(nn.Module):def __init__(self, num_classes=1000, aux_logits=True, transform_input=False,inception_blocks=None):super(GoogLeNet, self).__init__()if inception_blocks is None:inception_blocks = [BasicConv2d, InceptionA, InceptionB, InceptionC,InceptionD, InceptionE, InceptionAux]assert len(inception_blocks) == 7conv_block = inception_blocks[0]inception_a = inception_blocks[1]inception_b = inception_blocks[2]inception_c = inception_blocks[3]inception_d = inception_blocks[4]inception_e = inception_blocks[5]inception_aux = inception_blocks[6]self.aux_logits = aux_logitsself.transform_input = transform_inputself.Conv2d_1a_3x3 = conv_block(3, 32, kernel_size=3, stride=2)self.Conv2d_2a_3x3 = conv_block(32, 32, kernel_size=3)self.Conv2d_2b_3x3 = conv_block(32, 64, kernel_size=3, padding=1)self.Conv2d_3b_1x1 = conv_block(64, 80, kernel_size=1)self.Conv2d_4a_3x3 = conv_block(80, 192, kernel_size=3)self.Mixed_5b = inception_a(192, pool_features=32)self.Mixed_5c = inception_a(256, pool_features=64)self.Mixed_5d = inception_a(288, pool_features=64)self.Mixed_6a = inception_b(288)self.Mixed_6b = inception_c(768, channels_7x7=128)self.Mixed_6c = inception_c(768, channels_7x7=160)self.Mixed_6d = inception_c(768, channels_7x7=160)self.Mixed_6e = inception_c(768, channels_7x7=192)if aux_logits:self.AuxLogits = inception_aux(768, num_classes)self.Mixed_7a = inception_d(768)self.Mixed_7b = inception_e(1280)self.Mixed_7c = inception_e(2048)self.fc = nn.Linear(2048, num_classes)
'''输入(229,229,3)的数据,首先归一化输入,经过5个卷积,2个最大池化层。'''def _forward(self, x):# N x 3 x 299 x 299x = self.Conv2d_1a_3x3(x)# N x 32 x 149 x 149x = self.Conv2d_2a_3x3(x)# N x 32 x 147 x 147x = self.Conv2d_2b_3x3(x)# N x 64 x 147 x 147x = F.max_pool2d(x, kernel_size=3, stride=2)# N x 64 x 73 x 73x = self.Conv2d_3b_1x1(x)# N x 80 x 73 x 73x = self.Conv2d_4a_3x3(x)# N x 192 x 71 x 71x = F.max_pool2d(x, kernel_size=3, stride=2)'''然后经过3个InceptionA结构,1个InceptionB,3个InceptionC,1个InceptionD,2个InceptionE,其中InceptionA,辅助分类器AuxLogits以经过最后一个InceptionC的输出为输入。'''# 35 x 35 x 192x = self.Mixed_5b(x) # InceptionA(192, pool_features=32)# 35 x 35 x 256x = self.Mixed_5c(x) # InceptionA(256, pool_features=64)# 35 x 35 x 288x = self.Mixed_5d(x) # InceptionA(288, pool_features=64)# 35 x 35 x 288x = self.Mixed_6a(x) # InceptionB(288)# 17 x 17 x 768x = self.Mixed_6b(x) # InceptionC(768, channels_7x7=128)# 17 x 17 x 768x = self.Mixed_6c(x) # InceptionC(768, channels_7x7=160)# 17 x 17 x 768x = self.Mixed_6d(x) # InceptionC(768, channels_7x7=160)# 17 x 17 x 768x = self.Mixed_6e(x) # InceptionC(768, channels_7x7=192)# 17 x 17 x 768if self.training and self.aux_logits:aux = self.AuxLogits(x) # InceptionAux(768, num_classes)# 17 x 17 x 768x = self.Mixed_7a(x) # InceptionD(768)# 8 x 8 x 1280x = self.Mixed_7b(x) # InceptionE(1280)# 8 x 8 x 2048x = self.Mixed_7c(x) # InceptionE(2048)'''进入分类部分。经过平均池化层+dropout+打平+全连接层输出'''x = F.adaptive_avg_pool2d(x, (1, 1))# N x 2048 x 1 x 1x = F.dropout(x, training=self.training)# N x 2048 x 1 x 1x = torch.flatten(x, 1)#Flatten()就是将2D的特征图压扁为1D的特征向量,是展平操作,进入全连接层之前使用,类才能写进nn.Sequential# N x 2048x = self.fc(x)# N x 1000 (num_classes)return x, auxdef forward(self, x):x, aux = self._forward(x)return x, aux
第五步*:网络结构参数初始化
'''-----------------------网络结构参数初始化--------------------------'''# 目的:使网络更好收敛,准确率更高def _initialize_weights(self): # 将各种初始化方法定义为一个initialize_weights()的函数并在模型初始后进行使用。# 遍历网络中的每一层for m in self.modules():# isinstance(object, type),如果指定的对象拥有指定的类型,则isinstance()函数返回True'''如果是卷积层Conv2d'''if isinstance(m, nn.Conv2d):# Kaiming正态分布方式的权重初始化nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')'''判断是否有偏置:'''# 如果偏置不是0,将偏置置成0,对偏置进行初始化if m.bias is not None:# torch.nn.init.constant_(tensor, val),初始化整个矩阵为常数valnn.init.constant_(m.bias, 0)'''如果是全连接层'''elif isinstance(m, nn.Linear):# init.normal_(tensor, mean=0.0, std=1.0),使用从正态分布中提取的值填充输入张量# 参数:tensor:一个n维Tensor,mean:正态分布的平均值,std:正态分布的标准差nn.init.normal_(m.weight, 0, 0.01)nn.init.constant_(m.bias, 0)
实现效果

完整代码
from __future__ import divisionimport torch
import torch.nn as nn
import torch.nn.functional as F'''-------------------------第一步:定义基础卷积模块-------------------------------'''
class BasicConv2d(nn.Module):def __init__(self, in_channels, out_channels, **kwargs):super(BasicConv2d, self).__init__()self.conv = nn.Conv2d(in_channels, out_channels, bias=False, **kwargs)self.bn = nn.BatchNorm2d(out_channels, eps=0.001)def forward(self, x):x = self.conv(x)x = self.bn(x)return F.relu(x, inplace=True)'''-----------------第二步:定义Inceptionv3模块---------------------''''''---InceptionA---'''
class InceptionA(nn.Module):def __init__(self, in_channels, pool_features, conv_block=None):super(InceptionA, self).__init__()if conv_block is None:conv_block = BasicConv2dself.branch1x1 = conv_block(in_channels, 64, kernel_size=1)self.branch5x5_1 = conv_block(in_channels, 48, kernel_size=1)self.branch5x5_2 = conv_block(48, 64, kernel_size=5, padding=2)self.branch3x3dbl_1 = conv_block(in_channels, 64, kernel_size=1)self.branch3x3dbl_2 = conv_block(64, 96, kernel_size=3, padding=1)self.branch3x3dbl_3 = conv_block(96, 96, kernel_size=3, padding=1)self.branch_pool = conv_block(in_channels, pool_features, kernel_size=1)def _forward(self, x):branch1x1 = self.branch1x1(x)branch5x5 = self.branch5x5_1(x)branch5x5 = self.branch5x5_2(branch5x5)branch3x3dbl = self.branch3x3dbl_1(x)branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)branch3x3dbl = self.branch3x3dbl_3(branch3x3dbl)branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)branch_pool = self.branch_pool(branch_pool)outputs = [branch1x1, branch5x5, branch3x3dbl, branch_pool]return outputsdef forward(self, x):outputs = self._forward(x)return torch.cat(outputs, 1)'''---InceptionB---'''
class InceptionB(nn.Module):def __init__(self, in_channels, conv_block=None):super(InceptionB, self).__init__()if conv_block is None:conv_block = BasicConv2dself.branch3x3 = conv_block(in_channels, 384, kernel_size=3, stride=2)self.branch3x3dbl_1 = conv_block(in_channels, 64, kernel_size=1)self.branch3x3dbl_2 = conv_block(64, 96, kernel_size=3, padding=1)self.branch3x3dbl_3 = conv_block(96, 96, kernel_size=3, stride=2)def _forward(self, x):branch3x3 = self.branch3x3(x)branch3x3dbl = self.branch3x3dbl_1(x)branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)branch3x3dbl = self.branch3x3dbl_3(branch3x3dbl)branch_pool = F.max_pool2d(x, kernel_size=3, stride=2)outputs = [branch3x3, branch3x3dbl, branch_pool]return outputsdef forward(self, x):outputs = self._forward(x)return torch.cat(outputs, 1)'''---InceptionC---'''
class InceptionC(nn.Module):def __init__(self, in_channels, channels_7x7, conv_block=None):super(InceptionC, self).__init__()if conv_block is None:conv_block = BasicConv2dself.branch1x1 = conv_block(in_channels, 192, kernel_size=1)c7 = channels_7x7self.branch7x7_1 = conv_block(in_channels, c7, kernel_size=1)self.branch7x7_2 = conv_block(c7, c7, kernel_size=(1, 7), padding=(0, 3))self.branch7x7_3 = conv_block(c7, 192, kernel_size=(7, 1), padding=(3, 0))self.branch7x7dbl_1 = conv_block(in_channels, c7, kernel_size=1)self.branch7x7dbl_2 = conv_block(c7, c7, kernel_size=(7, 1), padding=(3, 0))self.branch7x7dbl_3 = conv_block(c7, c7, kernel_size=(1, 7), padding=(0, 3))self.branch7x7dbl_4 = conv_block(c7, c7, kernel_size=(7, 1), padding=(3, 0))self.branch7x7dbl_5 = conv_block(c7, 192, kernel_size=(1, 7), padding=(0, 3))self.branch_pool = conv_block(in_channels, 192, kernel_size=1)def _forward(self, x):branch1x1 = self.branch1x1(x)branch7x7 = self.branch7x7_1(x)branch7x7 = self.branch7x7_2(branch7x7)branch7x7 = self.branch7x7_3(branch7x7)branch7x7dbl = self.branch7x7dbl_1(x)branch7x7dbl = self.branch7x7dbl_2(branch7x7dbl)branch7x7dbl = self.branch7x7dbl_3(branch7x7dbl)branch7x7dbl = self.branch7x7dbl_4(branch7x7dbl)branch7x7dbl = self.branch7x7dbl_5(branch7x7dbl)branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)branch_pool = self.branch_pool(branch_pool)outputs = [branch1x1, branch7x7, branch7x7dbl, branch_pool]return outputsdef forward(self, x):outputs = self._forward(x)return torch.cat(outputs, 1)'''---InceptionD---'''
class InceptionD(nn.Module):def __init__(self, in_channels, conv_block=None):super(InceptionD, self).__init__()if conv_block is None:conv_block = BasicConv2dself.branch3x3_1 = conv_block(in_channels, 192, kernel_size=1)self.branch3x3_2 = conv_block(192, 320, kernel_size=3, stride=2)self.branch7x7x3_1 = conv_block(in_channels, 192, kernel_size=1)self.branch7x7x3_2 = conv_block(192, 192, kernel_size=(1, 7), padding=(0, 3))self.branch7x7x3_3 = conv_block(192, 192, kernel_size=(7, 1), padding=(3, 0))self.branch7x7x3_4 = conv_block(192, 192, kernel_size=3, stride=2)def _forward(self, x):branch3x3 = self.branch3x3_1(x)branch3x3 = self.branch3x3_2(branch3x3)branch7x7x3 = self.branch7x7x3_1(x)branch7x7x3 = self.branch7x7x3_2(branch7x7x3)branch7x7x3 = self.branch7x7x3_3(branch7x7x3)branch7x7x3 = self.branch7x7x3_4(branch7x7x3)branch_pool = F.max_pool2d(x, kernel_size=3, stride=2)outputs = [branch3x3, branch7x7x3, branch_pool]return outputsdef forward(self, x):outputs = self._forward(x)return torch.cat(outputs, 1)'''---InceptionE---'''
class InceptionE(nn.Module):def __init__(self, in_channels, conv_block=None):super(InceptionE, self).__init__()if conv_block is None:conv_block = BasicConv2dself.branch1x1 = conv_block(in_channels, 320, kernel_size=1)self.branch3x3_1 = conv_block(in_channels, 384, kernel_size=1)self.branch3x3_2a = conv_block(384, 384, kernel_size=(1, 3), padding=(0, 1))self.branch3x3_2b = conv_block(384, 384, kernel_size=(3, 1), padding=(1, 0))self.branch3x3dbl_1 = conv_block(in_channels, 448, kernel_size=1)self.branch3x3dbl_2 = conv_block(448, 384, kernel_size=3, padding=1)self.branch3x3dbl_3a = conv_block(384, 384, kernel_size=(1, 3), padding=(0, 1))self.branch3x3dbl_3b = conv_block(384, 384, kernel_size=(3, 1), padding=(1, 0))self.branch_pool = conv_block(in_channels, 192, kernel_size=1)def _forward(self, x):branch1x1 = self.branch1x1(x)branch3x3 = self.branch3x3_1(x)branch3x3 = [self.branch3x3_2a(branch3x3),self.branch3x3_2b(branch3x3),]branch3x3 = torch.cat(branch3x3, 1)branch3x3dbl = self.branch3x3dbl_1(x)branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)branch3x3dbl = [self.branch3x3dbl_3a(branch3x3dbl),self.branch3x3dbl_3b(branch3x3dbl),]branch3x3dbl = torch.cat(branch3x3dbl, 1)branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)branch_pool = self.branch_pool(branch_pool)outputs = [branch1x1, branch3x3, branch3x3dbl, branch_pool]return outputsdef forward(self, x):outputs = self._forward(x)return torch.cat(outputs, 1)'''-------------------第三步:定义辅助分类器InceptionAux-----------------------'''
class InceptionAux(nn.Module):def __init__(self, in_channels, num_classes, conv_block=None):super(InceptionAux, self).__init__()if conv_block is None:conv_block = BasicConv2dself.conv0 = conv_block(in_channels, 128, kernel_size=1)self.conv1 = conv_block(128, 768, kernel_size=5)self.conv1.stddev = 0.01self.fc = nn.Linear(768, num_classes)self.fc.stddev = 0.001def forward(self, x):# N x 768 x 17 x 17x = F.avg_pool2d(x, kernel_size=5, stride=3)# N x 768 x 5 x 5x = self.conv0(x)# N x 128 x 5 x 5x = self.conv1(x)# N x 768 x 1 x 1# Adaptive average poolingx = F.adaptive_avg_pool2d(x, (1, 1))# N x 768 x 1 x 1x = torch.flatten(x, 1)# N x 768x = self.fc(x)# N x 1000return x'''-----------------------第四步:搭建GoogLeNet网络--------------------------'''
class GoogLeNet(nn.Module):def __init__(self, num_classes=1000, aux_logits=True, transform_input=False,inception_blocks=None):super(GoogLeNet, self).__init__()if inception_blocks is None:inception_blocks = [BasicConv2d, InceptionA, InceptionB, InceptionC,InceptionD, InceptionE, InceptionAux]assert len(inception_blocks) == 7conv_block = inception_blocks[0]inception_a = inception_blocks[1]inception_b = inception_blocks[2]inception_c = inception_blocks[3]inception_d = inception_blocks[4]inception_e = inception_blocks[5]inception_aux = inception_blocks[6]self.aux_logits = aux_logitsself.transform_input = transform_inputself.Conv2d_1a_3x3 = conv_block(3, 32, kernel_size=3, stride=2)self.Conv2d_2a_3x3 = conv_block(32, 32, kernel_size=3)self.Conv2d_2b_3x3 = conv_block(32, 64, kernel_size=3, padding=1)self.Conv2d_3b_1x1 = conv_block(64, 80, kernel_size=1)self.Conv2d_4a_3x3 = conv_block(80, 192, kernel_size=3)self.Mixed_5b = inception_a(192, pool_features=32)self.Mixed_5c = inception_a(256, pool_features=64)self.Mixed_5d = inception_a(288, pool_features=64)self.Mixed_6a = inception_b(288)self.Mixed_6b = inception_c(768, channels_7x7=128)self.Mixed_6c = inception_c(768, channels_7x7=160)self.Mixed_6d = inception_c(768, channels_7x7=160)self.Mixed_6e = inception_c(768, channels_7x7=192)if aux_logits:self.AuxLogits = inception_aux(768, num_classes)self.Mixed_7a = inception_d(768)self.Mixed_7b = inception_e(1280)self.Mixed_7c = inception_e(2048)self.fc = nn.Linear(2048, num_classes)'''输入(229,229,3)的数据,首先归一化输入,经过5个卷积,2个最大池化层。'''def _forward(self, x):# N x 3 x 299 x 299x = self.Conv2d_1a_3x3(x)# N x 32 x 149 x 149x = self.Conv2d_2a_3x3(x)# N x 32 x 147 x 147x = self.Conv2d_2b_3x3(x)# N x 64 x 147 x 147x = F.max_pool2d(x, kernel_size=3, stride=2)# N x 64 x 73 x 73x = self.Conv2d_3b_1x1(x)# N x 80 x 73 x 73x = self.Conv2d_4a_3x3(x)# N x 192 x 71 x 71x = F.max_pool2d(x, kernel_size=3, stride=2)'''然后经过3个InceptionA结构,1个InceptionB,3个InceptionC,1个InceptionD,2个InceptionE,其中InceptionA,辅助分类器AuxLogits以经过最后一个InceptionC的输出为输入。'''# 35 x 35 x 192x = self.Mixed_5b(x) # InceptionA(192, pool_features=32)# 35 x 35 x 256x = self.Mixed_5c(x) # InceptionA(256, pool_features=64)# 35 x 35 x 288x = self.Mixed_5d(x) # InceptionA(288, pool_features=64)# 35 x 35 x 288x = self.Mixed_6a(x) # InceptionB(288)# 17 x 17 x 768x = self.Mixed_6b(x) # InceptionC(768, channels_7x7=128)# 17 x 17 x 768x = self.Mixed_6c(x) # InceptionC(768, channels_7x7=160)# 17 x 17 x 768x = self.Mixed_6d(x) # InceptionC(768, channels_7x7=160)# 17 x 17 x 768x = self.Mixed_6e(x) # InceptionC(768, channels_7x7=192)# 17 x 17 x 768if self.training and self.aux_logits:aux = self.AuxLogits(x) # InceptionAux(768, num_classes)# 17 x 17 x 768x = self.Mixed_7a(x) # InceptionD(768)# 8 x 8 x 1280x = self.Mixed_7b(x) # InceptionE(1280)# 8 x 8 x 2048x = self.Mixed_7c(x) # InceptionE(2048)'''进入分类部分。经过平均池化层+dropout+打平+全连接层输出'''x = F.adaptive_avg_pool2d(x, (1, 1))# N x 2048 x 1 x 1x = F.dropout(x, training=self.training)# N x 2048 x 1 x 1x = torch.flatten(x, 1)#Flatten()就是将2D的特征图压扁为1D的特征向量,是展平操作,进入全连接层之前使用,类才能写进nn.Sequential# N x 2048x = self.fc(x)# N x 1000 (num_classes)return x, auxdef forward(self, x):x, aux = self._forward(x)return x, aux'''-----------------------第五步:网络结构参数初始化--------------------------'''# 目的:使网络更好收敛,准确率更高def _initialize_weights(self): # 将各种初始化方法定义为一个initialize_weights()的函数并在模型初始后进行使用。# 遍历网络中的每一层for m in self.modules():# isinstance(object, type),如果指定的对象拥有指定的类型,则isinstance()函数返回True'''如果是卷积层Conv2d'''if isinstance(m, nn.Conv2d):# Kaiming正态分布方式的权重初始化nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')'''判断是否有偏置:'''# 如果偏置不是0,将偏置置成0,对偏置进行初始化if m.bias is not None:# torch.nn.init.constant_(tensor, val),初始化整个矩阵为常数valnn.init.constant_(m.bias, 0)'''如果是全连接层'''elif isinstance(m, nn.Linear):# init.normal_(tensor, mean=0.0, std=1.0),使用从正态分布中提取的值填充输入张量# 参数:tensor:一个n维Tensor,mean:正态分布的平均值,std:正态分布的标准差nn.init.normal_(m.weight, 0, 0.01)nn.init.constant_(m.bias, 0)
'''---------------------------------------显示网络结构-------------------------------'''
if __name__ == '__main__':net = GoogLeNet(1000).cuda()from torchsummary import summarysummary(net, (3, 299, 299))番外
上面实现的是torchvision中的Inception v3结构,和论文中不太一样。因此我上GitHub上找到了论文复现的代码。先放个链接:https://github.com/AlgorithmicIntelligence/GoogLeNetv3_Pytorch/tree/master/models

(论文中结构)
代码
import torch
import torch.nn as nn
from functools import partial
# functools.partial():减少某个函数的参数个数。 partial() 函数允许你给一个或多个参数设置固定的值,减少接下来被调用时的参数个数'''-----------------------第一步:定义卷积模块-----------------------'''
#基础卷积模块
class Conv2d(nn.Module):def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0, output=False):super(Conv2d, self).__init__()'''卷积层'''self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)'''输出层'''self.output = outputif self.output == False:'''bn层'''self.bn = nn.BatchNorm2d(out_channels)'''relu层'''self.relu = nn.ReLU(inplace=True)def forward(self, x):x = self.conv(x)if self.output:return xelse:x = self.bn(x)x = self.relu(x)return xclass Separable_Conv2d(nn.Module):def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0):super(Separable_Conv2d, self).__init__()self.conv_h = nn.Conv2d(in_channels, in_channels, (kernel_size, 1), stride=(stride, 1), padding=(padding, 0))self.conv_w = nn.Conv2d(in_channels, out_channels, (1, kernel_size), stride=(1, stride), padding=(0, padding))self.bn = nn.BatchNorm2d(out_channels)self.relu = nn.ReLU(inplace=True)def forward(self, x):x = self.conv_h(x)x = self.conv_w(x)x = self.bn(x)x = self.relu(x)return xclass Concat_Separable_Conv2d(nn.Module):def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0):super(Concat_Separable_Conv2d, self).__init__()self.conv_h = nn.Conv2d(in_channels, out_channels, (kernel_size, 1), stride=(stride, 1), padding=(padding, 0))self.conv_w = nn.Conv2d(in_channels, out_channels, (1, kernel_size), stride=(1, stride), padding=(0, padding))self.bn = nn.BatchNorm2d(out_channels * 2)self.relu = nn.ReLU(inplace=True)def forward(self, x):x_h = self.conv_h(x)x_w = self.conv_w(x)x = torch.cat([x_h, x_w], dim=1)x = self.bn(x)x = self.relu(x)return x#Flatten()就是将2D的特征图压扁为1D的特征向量,是展平操作,进入全连接层之前使用,类才能写进nn.Sequential
class Flatten(nn.Module):# 传入输入维度和输出维度def __init__(self):# 调用父类构造函数super(Flatten, self).__init__()# 实现forward函数def forward(self, x):# 保存batch维度,后面的维度全部压平return torch.flatten(x, 1)#Squeeze()降维
class Squeeze(nn.Module):def __init__(self):super(Squeeze, self).__init__()def forward(self, x):return torch.squeeze(x)'''-----------------------搭建GoogLeNet网络--------------------------'''
class GoogLeNet(nn.Module):def __init__(self, num_classes, mode='train'):super(GoogLeNet, self).__init__()self.num_classes = num_classesself.mode = modeself.layers = nn.Sequential(Conv2d(3, 32, 3, stride=2),Conv2d(32, 32, 3, stride=1),Conv2d(32, 64, 3, stride=1, padding=1),nn.MaxPool2d(kernel_size=3, stride=2),Conv2d(64, 80, kernel_size=3),Conv2d(80, 192, kernel_size=3, stride=2),Conv2d(192, 288, kernel_size=3, stride=1, padding=1),#输入:35*35*288。将5*5用两个3*3代替Inceptionv3(288, 64, 48, 64, 64, 96, 64, mode='1'), # 3aInceptionv3(288, 64, 48, 64, 64, 96, 64, mode='1'), # 3bInceptionv3(288, 0, 128, 384, 64, 96, 0, stride=2, pool_type='MAX', mode='1'), # 3c#输入:17*17*768。Inceptionv3(768, 192, 128, 192, 128, 192, 192, mode='2'), # 4aInceptionv3(768, 192, 160, 192, 160, 192, 192, mode='2'), # 4bInceptionv3(768, 192, 160, 192, 160, 192, 192, mode='2'), # 4cInceptionv3(768, 192, 192, 192, 192, 192, 192, mode='2'), # 4dInceptionv3(768, 0, 192, 320, 192, 192, 0, stride=2, pool_type='MAX', mode='2'), # 4e#8*8*1280Inceptionv3(1280, 320, 384, 384, 448, 384, 192, mode='3'), # 5aInceptionv3(2048, 320, 384, 384, 448, 384, 192, pool_type='MAX', mode='3'), # 5bnn.AvgPool2d(8, 1),Conv2d(2048, num_classes, kernel_size=1, output=True),Squeeze(),)if mode == 'train':self.aux = InceptionAux(768, num_classes)def forward(self, x):for idx, layer in enumerate(self.layers):if (idx == 14 and self.mode == 'train'):aux = self.aux(x)x = layer(x)if self.mode == 'train':return x, auxelse:return x'''-----------------------网络结构参数初始化--------------------------'''# 目的:使网络更好收敛,准确率更高def _initialize_weights(self): # 将各种初始化方法定义为一个initialize_weights()的函数并在模型初始后进行使用。# 遍历网络中的每一层for m in self.modules():# isinstance(object, type),如果指定的对象拥有指定的类型,则isinstance()函数返回True'''如果是卷积层Conv2d'''if isinstance(m, nn.Conv2d):# Kaiming正态分布方式的权重初始化nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')'''判断是否有偏置:'''# 如果偏置不是0,将偏置置成0,对偏置进行初始化if m.bias is not None:# torch.nn.init.constant_(tensor, val),初始化整个矩阵为常数valnn.init.constant_(m.bias, 0)'''如果是全连接层'''elif isinstance(m, nn.Linear):# init.normal_(tensor, mean=0.0, std=1.0),使用从正态分布中提取的值填充输入张量# 参数:tensor:一个n维Tensor,mean:正态分布的平均值,std:正态分布的标准差nn.init.normal_(m.weight, 0, 0.01)nn.init.constant_(m.bias, 0)'''---------------------Inceptionv3-------------------------------------'''
'''
Inceptionv3由三个连续的Inception模块组组成
'''
class Inceptionv3(nn.Module):def __init__(self, input_channel, conv1_channel, conv3_reduce_channel,conv3_channel, conv3_double_reduce_channel, conv3_double_channel, pool_reduce_channel, stride=1,pool_type='AVG', mode='1'):super(Inceptionv3, self).__init__()self.stride = strideif stride == 2:padding_conv3 = 0padding_conv7 = 2else:padding_conv3 = 1padding_conv7 = 3if conv1_channel != 0:self.conv1 = Conv2d(input_channel, conv1_channel, kernel_size=1)else:self.conv1 = Noneself.conv3_reduce = Conv2d(input_channel, conv3_reduce_channel, kernel_size=1)#第一种Inception模式:输入的特征图尺寸为35x35x288,采用了论文中图5中的架构,将5x5以两个3x3代替。if mode == '1':self.conv3 = Conv2d(conv3_reduce_channel, conv3_channel, kernel_size=3, stride=stride,padding=padding_conv3)self.conv3_double1 = Conv2d(conv3_double_reduce_channel, conv3_double_channel, kernel_size=3, padding=1)self.conv3_double2 = Conv2d(conv3_double_channel, conv3_double_channel, kernel_size=3, stride=stride,padding=padding_conv3)#第二种Inception模块:输入特征图尺寸为17x17x768,采用了论文中图6中nx1+1xn的不对称卷积结构elif mode == '2':self.conv3 = Separable_Conv2d(conv3_reduce_channel, conv3_channel, kernel_size=7, stride=stride,padding=padding_conv7)self.conv3_double1 = Separable_Conv2d(conv3_double_reduce_channel, conv3_double_channel, kernel_size=7,padding=3)self.conv3_double2 = Separable_Conv2d(conv3_double_channel, conv3_double_channel, kernel_size=7,stride=stride, padding=padding_conv7)#第三种Inception模块:输入特征图尺寸为8x8x1280, 采用了论文图7中所示的并行模块的结构elif mode == '3':self.conv3 = Concat_Separable_Conv2d(conv3_reduce_channel, conv3_channel, kernel_size=3, stride=stride,padding=1)self.conv3_double1 = Conv2d(conv3_double_reduce_channel, conv3_double_channel, kernel_size=3, padding=1)self.conv3_double2 = Concat_Separable_Conv2d(conv3_double_channel, conv3_double_channel, kernel_size=3,stride=stride, padding=1)self.conv3_double_reduce = Conv2d(input_channel, conv3_double_reduce_channel, kernel_size=1)if pool_type == 'MAX':self.pool = nn.MaxPool2d(kernel_size=3, stride=stride, padding=padding_conv3)elif pool_type == 'AVG':self.pool = nn.AvgPool2d(kernel_size=3, stride=stride, padding=padding_conv3)if pool_reduce_channel != 0:self.pool_reduce = Conv2d(input_channel, pool_reduce_channel, kernel_size=1)else:self.pool_reduce = Nonedef forward(self, x):output_conv3 = self.conv3(self.conv3_reduce(x))output_conv3_double = self.conv3_double2(self.conv3_double1(self.conv3_double_reduce(x)))if self.pool_reduce != None:output_pool = self.pool_reduce(self.pool(x))else:output_pool = self.pool(x)if self.conv1 != None:output_conv1 = self.conv1(x)outputs = torch.cat([output_conv1, output_conv3, output_conv3_double, output_pool], dim=1)else:outputs = torch.cat([output_conv3, output_conv3_double, output_pool], dim=1)return outputs'''------------辅助分类器---------------------------'''
class InceptionAux(nn.Module):def __init__(self, input_channel, num_classes):super(InceptionAux, self).__init__()self.layers = nn.Sequential(nn.AvgPool2d(5, 3),Conv2d(input_channel, 128, 1),Conv2d(128, 1024, kernel_size=5),Conv2d(1024, num_classes, kernel_size=1, output=True),Squeeze())def forward(self, x):x = self.layers(x)return x'''-------------------显示网络结构-------------------------------'''
if __name__ == '__main__':net = GoogLeNet(1000).cuda()from torchsummary import summarysummary(net, (3, 299, 299))