文章目录
- 如何确保不重复消费消息?
- 消费者业务逻辑重试
- 消费者提交
- 自定义反序列化类
- 消费者参数配置及其说明
- 重要的参数session.time.ms和heartbeat.interval.ms和group.instance.id
- 增加消费者的吞吐量
- 消费者消费的超时时间和poll()方法的关系
- 消费者消费逻辑
- 启动消费者
- 关闭消费者
- 配置listener
- 结语
- 示例源码仓库
在 上一篇文章里,对于生产者,发送时失败之后会由定时任务进行重新发送, 并且我们是根据消息的key进行分区的, 所以不管我们重新发送了多少次,对于同一个key,始终会被送到同一个分区。
那么到消费者这里,最重要的问题是如何确保不会重复消费之前因为各种原因被重新发送到某个分区的消息。
如何确保不重复消费消息?
基本思路如下
- 我们在数据库中创建了一个已成功消费的消息表,里面只有一列,消息的key。当消费者消费逻辑成功之后,我们会把其key保存到这张表里 。
- 当消费者拉取新的一批消息时,我们会去数据库的消息表里查是否已经存在该消息的key,存在的话,就跳过实际的消费业务。
- 一批消息里也可能存在相同的key,所以我们处理完一次消费业务,就把该key放到一个set里,消费下一条消息时,则先去set里看一下,存在的话即跳过,不存在则正常执行消费业务。即使前面的消息消费业务失败了,后面相同key的消息也直接跳过,不会再次消费
消费者业务逻辑重试
对于消费者业务逻辑的重试,我们使用failsafe框架进行重试,该框架的使用可参考官方文档,这里不做过多赘述。
消费者提交
这里的方式采用的是Kafka权威指南中消费者一章中提出的方式。 异步+同步。平时使用异步提交,在关闭消费者时,使用同步提交,确保消费者退出之前将当前的offset提交上去。
自定义反序列化类
在生产者端,我们发送自定义的对象时,利用自定义序列化类将其序列化为JSON。在消费者端,我们同样需要自定义反序列类将JSON转为我们之前的对象
public class UserDTODeserializer implements Deserializer<UserDTO> {@Override@SneakyThrowspublic UserDTO deserialize(final String s, final byte[] bytes) {ObjectMapper objectMapper = new ObjectMapper();return objectMapper.readValue(bytes, UserDTO.class);}
}
消费者参数配置及其说明
/*** 以下配置建议搭配 官方文档 + kafka权威指南相关章节 + 实际业务场景需求 自己调整* https://kafka.apache.org/26/documentation/#group.instance.id** 为什么需要group.instance.id?* 假设auto.offset.reset=latest* 1. 如果没有group.instance.id,那么kafka会认为此消费者是dynamic member,在重启期间如果有消息发送到topic,那么重启之后,消费者会【丢失这部分消息】* 假如auto.offset.reset=earliest* 1. 如果没有group.instance.id,那么kafka会认为此消费者是dynamic member,在重启期间如果有消息发送到topic,那么重启之后,消费者会重复消费【全部消息】** 光有group.instance.id还不够,还需要修改heartbeat.interval.ms和session.timeout.ms的值为合理的值* 如果程序部署,重启期间,重启时间超过了session.timeout.ms的值,那么kafka会认为此消费者已经挂了会触发rebalance,在一些大型消息场景,rebalance的过程可能会很慢, 更详细的解释请参考* https://kafka.apache.org/26/documentation/#static_membership* @param groupInstanceId* @return*/public static Properties loadConsumerConfig(int groupInstanceId, String valueDeserializer) {Properties result = new Properties();result.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.0.102:9093");result.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");result.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, valueDeserializer);result.put(ConsumerConfig.GROUP_ID_CONFIG, "test");// 代表此消费者是消费者组的static memberresult.put(ConsumerConfig.GROUP_INSTANCE_ID_CONFIG, "test-" + ++groupInstanceId);// 修改heartbeat.interval.ms和session.timeout.ms的值,和group.instance.id配合使用,避免重启或重启时间过长的时候,触发rebalanceresult.put(ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG, 1000 * 60);result.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 1000 * 60 * 5);// 关闭自动提交result.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, Boolean.FALSE);// 默认1MB,增加吞吐量,其设置对应的是每个分区,也就是说一个分区返回10MB的数据result.put(ConsumerConfig.MAX_PARTITION_FETCH_BYTES_CONFIG, 1048576 * 10);result.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 500);// 返回全部数据的大小result.put(ConsumerConfig.FETCH_MAX_BYTES_CONFIG, 1048576 * 100);// 默认5分钟result.put(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG, 1000 * 60 * 5);return result;}
重要的参数session.time.ms和heartbeat.interval.ms和group.instance.id
三者的使用方式见上面代码中的注释。
增加消费者的吞吐量
和上一篇文章一样,由于我们的邮件消息每个大概是20KB,使用默认的消费者参数,吞吐量是上不来的。 所以做了一些优化,除了消费者消费逻辑要尽可能简单之外,为了增加消费者的吞吐量,可以根据实际场景修改倒数第4、3、2个参数。
消费者消费的超时时间和poll()方法的关系
由max.poll.interval.ms参数控制,默认5分钟。如果消费者业务逻辑处理特别耗时,在5分钟之内没有再次调用poll()拉取消息,则Kafka认为消费者已死,根据具体配置会立刻触发rebalance还是等一段时间再触发rebalance。
这里特别强调一下,网上有一部分文章说是要确保消费逻辑在poll(timeUnit)时间内处理完,否则就会触发rebalance。这都是很早之前的Kafka版本了,是因为原来消费者的poll()线程和心跳线程使用的是同一个线程。现在的版本早就把这两个分开了。所以你只需要注意,自己的消费逻辑别超过max.poll.interval.ms即可,如果觉得不够用,也可自己调整。
poll()方法中的时间代表的是多长时间去拉取一次消息。假设你设置的是1分钟,你的消费逻辑处理的很快,可能用了10s。那么在你消费完了之后,消费者会在1分钟之后拉取新消息。
在消费者中使用手动提交。
消费者消费逻辑
这里要注意
- 如果消费逻辑可能抛出异常,则使用try-catch处理,防止因为抛出异常,导致我们错误的关闭了消费者
- 消费者消费逻辑失败时会重试,重试N次之后,我们会将其保存在数据库中,以便和生产者一样,定时处理失败的消息
- 消费逻辑没问题的话,则把该消息的key进行入库处理
@Log
public class MessageConsumerRunner implements Runnable {private final AtomicBoolean closed = new AtomicBoolean(false);private MessageAckConsumesSuccessService messageAckConsumesSuccessService = new MessageAckConsumesSuccessService();private MessageFailedService messageFailedService = new MessageFailedService();private final KafkaConsumer<String, UserDTO> consumer;private final int consumerPollIntervalSecond;public MessageConsumerRunner(KafkaConsumer<String, UserDTO> consumer, int consumerPollIntervalSecond) {this.consumer = consumer;this.consumerPollIntervalSecond = consumerPollIntervalSecond;}/*** 1. 使用https://failsafe.dev/进行重试* 2. 每次消费消息前,判断消息ID是否存在于数据库中和当前Set集合中,避免重复消费,* 我们的消息时根据消息的key进行hash分区的,所以同一个消息即使生产多次,一定会到同一个partition中,partition动态增加引起的特殊情况不在考虑范围之内* 4. 在一次消费消息中重试两次,如果两次都失败,那么将失败原因、消息的JSON字符串插入到message_failed表中,以便后续再次生产或排查问题* 3. 平时异步提交,关闭消费者时使用同步提交*/@Overridepublic void run() {AtomicReference<String> errorMessage = new AtomicReference<>(StringUtils.EMPTY);RetryPolicy<Boolean> retryPolicy = RetryPolicy.<Boolean>builder().handle(Exception.class)// 如果业务逻辑返回false或者抛出异常,则重试.handleResultIf(Boolean.FALSE::equals)// 不包含首次.withMaxRetries(2).withDelay(Duration.ofMillis(200)).onRetry(e -> log.warning("consume message failed, start the {}th retry"+ e.getAttemptCount())).onRetriesExceeded(e -> {Optional.ofNullable(e.getException()).ifPresent(u -> errorMessage.set(u.getMessage()));log.severe("max retries exceeded" + e.getException());}).build();Fallback<Boolean> fallback = Fallback.<Boolean>builder(e -> {// do nothing, suppress exceptions}).build();try {consumer.subscribe(Collections.singletonList("email"));while (!closed.get()) {// get message from kafkaConsumerRecords<String, UserDTO> records = consumer.poll(Duration.ofSeconds(consumerPollIntervalSecond));if (records.isEmpty()) {return;}Set<UserDTO> successConsumed = new HashSet<>();Set<UserDTO> failedConsumed = new HashSet<>();Map<String, String> failedConsumedReason = new HashMap<>();// check message if exist in databaseSet<String> checkingMessageIds = new HashSet<>(records.count());records.iterator().forEachRemaining(item -> checkingMessageIds.add(item.value().getMessageId()));Set<String> hasBeenConsumedMessageIds = messageAckConsumesSuccessService.checkMessageIfExistInDatabase(checkingMessageIds);records.forEach(item -> {if (hasBeenConsumedMessageIds.contains(item.value().getMessageId())) {// if exist, continuereturn;}// 每一批消息中也可能存在同样的消息,所以需要再次判断hasBeenConsumedMessageIds.add(item.value().getMessageId());try {Failsafe.with(fallback, retryPolicy).onSuccess(e -> successConsumed.add(item.value())).onFailure(e -> {failedConsumed.add(item.value());failedConsumedReason.put(item.value().getMessageId(), StringUtils.isNotBlank(errorMessage.get()) ? errorMessage.get() : "no reason, may be check server log");errorMessage.set(StringUtils.EMPTY);}).get(() -> {// 这里是业务逻辑,可以返回true或false,为什么要这样?是因为上面RetryPolicy这里定义的boolean,根据自己实际业务设置相应的类型return true;});// 这里要catch住所有业务异常,防止由业务异常导致消费者线程退出}catch (Exception e) {log.severe("failed to consume email message" + e);failedConsumed.add(item.value());failedConsumedReason.put(item.value().getMessageId(), StringUtils.isNotBlank(e.getMessage()) ? e.getMessage() : e.getCause().toString());}});postConsumed(successConsumed, failedConsumed, failedConsumedReason);// 平时使用异步提交consumer.commitAsync();}}catch (WakeupException e) {if (!closed.get()) {throw e;}} finally {// 消费者退出时使用同步提交try {consumer.commitSync();} catch (Exception e) {log.info("commit sync occur exception: " + e);} finally{try {consumer.close();}catch (Exception e) {log.info("consumer close occur exception: " + e);}log.info( "shutdown kafka consumer complete");}}}/*** 处理成功、成功后的回调、失败* @param successConsumed* @param failedConsumed* @param failedConsumedReason*/private void postConsumed(Set<UserDTO> successConsumed, Set<UserDTO> failedConsumed, Map<String, String> failedConsumedReason) {// 后置处理开启异步线程处理,不阻塞消费者线程// 克隆传进来的集合,而不使用原集合的引用,因为原集合每次消费都会重置Set<UserDTO> cloneSuccessConsumed = new HashSet<>(successConsumed);Set<UserDTO> cloneFailedConsumed = new HashSet<>(failedConsumed);Map<String, String> cloneFailedConsumedReason = new HashMap<>(failedConsumedReason);new Thread( () -> {if (!cloneSuccessConsumed.isEmpty()) {messageAckConsumesSuccessService.insertMessageIds(cloneSuccessConsumed.stream().map(UserDTO::getMessageId).collect(Collectors.toSet()));cloneFailedConsumed.forEach(item -> {if (Objects.nonNull(item.getCallbackMetaData())) {// do callbackCallbackProducer callbackProducer = new CallbackProducer();callbackProducer.sendCallbackMessage(item.getCallbackMetaData(), MessageFailedPhrase.PRODUCER);}});}if (!cloneFailedConsumed.isEmpty()) {ObjectMapper objectMapper = new ObjectMapper();cloneFailedConsumed.forEach(item -> {MessageFailedEntity entity = new MessageFailedEntity();entity.setMessageId(item.getMessageId());entity.setMessageType(MessageType.EMAIL);entity.setMessageFailedPhrase(MessageFailedPhrase.CONSUMER);entity.setFailedReason(cloneFailedConsumedReason.get(item.getMessageId()));try {entity.setMessageContentJsonFormat(objectMapper.writeValueAsString(item));} catch (JsonProcessingException e) {log.info("failed to convert UserDTO message to json string");}messageFailedService.saveOrUpdateMessageFailed(entity);});}}).start();}public void shutdown() {log.info( Thread.currentThread().getName() + " shutdown kafka consumer");closed.set(true);consumer.wakeup();}
}
启动消费者
通过实现ServletContextListener接口对于方法使其在Tomcat启动之后,启动消费者
public class StartUpConsumerListener implements ServletContextListener {/*** 假设开启10个消费者.** 消费者的数量要和partition的数量一致,实际情况下,可以调用AdminClient的方法获取到topic的partition数量,然后根据partition数量来创建消费者.* @param sce*/@Overridepublic void contextInitialized(final ServletContextEvent sce) {ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(10, 10, 30L, TimeUnit.SECONDS, new LinkedBlockingDeque<>(100), new AbortPolicy());for (int i = 0; i < 10; i++) {KafkaConsumer<String, UserDTO> consumer = new KafkaConsumer<>(KafkaConfiguration.loadConsumerConfig(i, UserDTO.class.getName()));MessageConsumerRunner messageConsumerRunner = new MessageConsumerRunner(consumer, 10);// 使用另外一个线程来关闭消费者Thread shutdownHooks = new Thread(messageConsumerRunner::shutdown);KafkaListener.KAFKA_CONSUMERS.add(shutdownHooks);// 启动消费者线程threadPoolExecutor.execute(messageConsumerRunner);}}
}
关闭消费者
public class KafkaListener implements ServletContextListener {public static final Vector<Thread> KAFKA_CONSUMERS = new Vector<>();@Overridepublic void contextInitialized(ServletContextEvent sce) {// do noting}@Overridepublic void contextDestroyed(ServletContextEvent sce) {KAFKA_CONSUMERS.forEach(Thread::run);}
}
配置listener
<?xml version="1.0" encoding="UTF-8" ?>
<web-app xmlns="https://jakarta.ee/xml/ns/jakartaee"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="https://jakarta.ee/xml/ns/jakartaeehttps://jakarta.ee/xml/ns/jakartaee/web-app_6_0.xsd"version="6.0"><display-name>Kafka消息的消费者-消息系统</display-name><!-- listener的contextInitialized顺序按照声明顺序执行, contextDestroyed方法按照声明顺序反向执行--><listener><listener-class>com.message.server.listener.KafkaListener</listener-class></listener><listener><listener-class>com.message.server.listener.StartUpConsumerListener</listener-class></listener>
</web-app>
结语
- 在处理消费者相关逻辑时,我们重点关心如何确保消息不重复消费以及如何增加消费者的吞吐量
- 消费逻辑尽可能保证处理速度快,尽量减少耗时的逻辑
示例源码仓库
- Github地址
- 项目下message-server module代表生产者
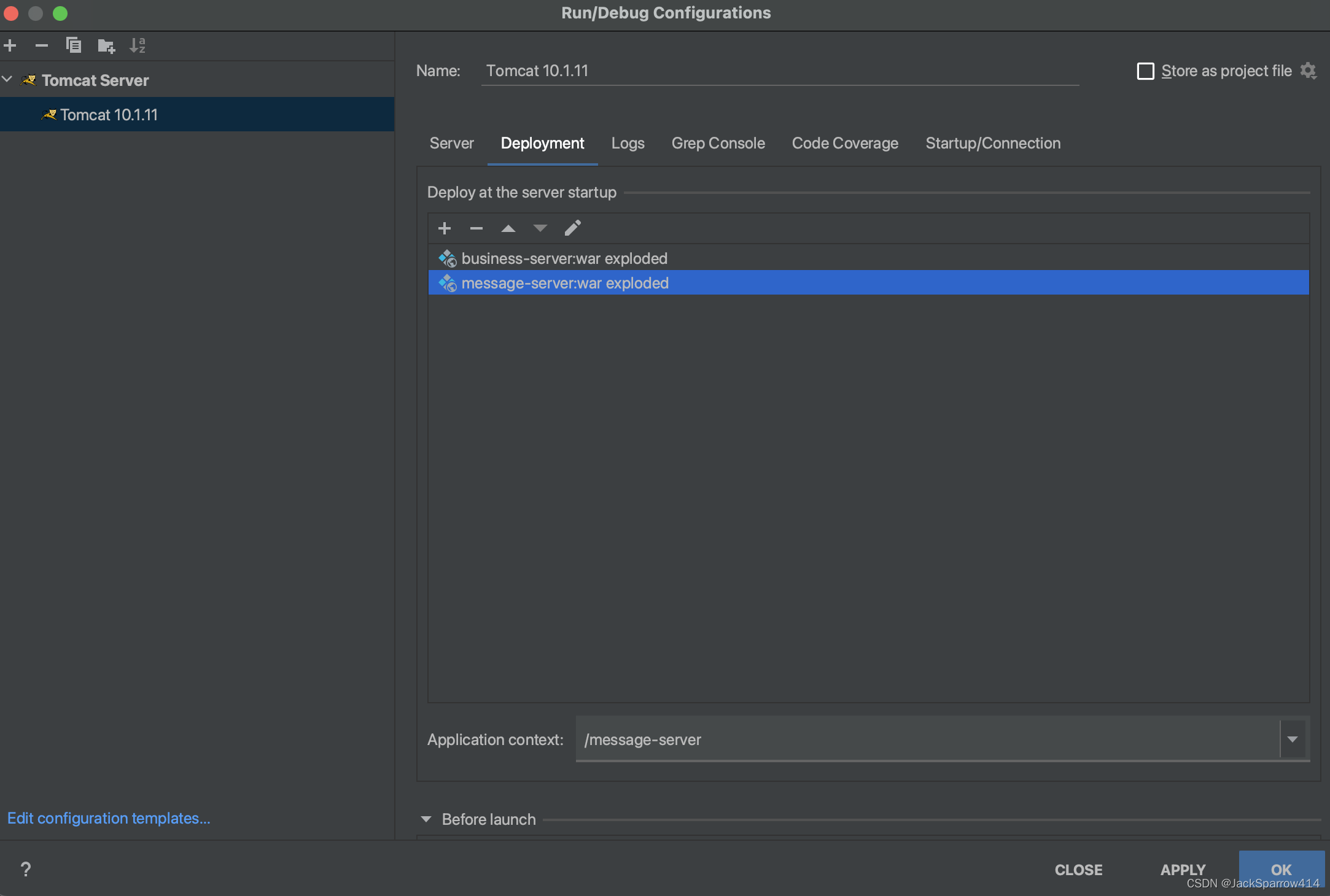
- 运行时IDEA配置如下
我们生产者和消费者的正常情况都以处理完了,下一篇文章我们将重点处理生产者失败和消费者失败之后重新生产消息和消费消息的逻辑,以及简单说一下Kafka中的rebalance。