自然语言生成是让计算机自动或半自动地生成自然语言的文本。这个领域涉及到自然语言处理、语言学、计算机科学等多个领域的知识。
1.简介
自然语言生成系统可以分为基于规则的方法和基于统计的方法两大类。基于规则的方法主要依靠专家知识库和语言学规则来生成文本,而基于统计的方法则通过大量的语料库和训练数据来学习生成文本的规律和模式。
- 在机器翻译领域,自然语言生成技术可以将一种语言的文本自动翻译成另一种语言的文本;
- 在智能客服领域,自然语言生成技术可以帮助企业自动回答用户的问题和解决用户的问题;
- 在自动摘要领域,自然语言生成技术可以将大量的文本自动摘要为一个简短的文本;
- 在对话系统领域,自然语言生成技术可以帮助人们自动地与机器人进行对话交流。
自然语言生成技术是人工智能领域的重要分支之一,它可以帮助计算机更好地理解和生成人类语言,从而为人们的生活和工作带来更多的便利和价值。
2.基于规则生成
2.1基于规则的自然语言生成特点
基于规则的自然语言生成方法是一种通过事先定义规则和模式来处理文本的方法。这种方法依赖于人工设计的规则,通过匹配和处理规则来实现对文本的分析和理解。
在基于规则的自然语言生成方法中,规则是由语言学家和专家根据语言学知识和领域知识设计的。这些规则通常包括语法规则、语义规则、词汇规则等,用于指导计算机如何生成符合语言规范的自然语言文本。
基于规则的自然语言生成方法通常分为两个阶段:分析阶段和生成阶段。在分析阶段,计算机将输入的文本进行分析和处理,以获得其语法和语义信息。在生成阶段,计算机使用规则和模式将分析阶段获得的语法和语义信息转换为自然语言文本。

基于规则的自然语言生成方法的优点是可以对文本进行精确的控制和处理,因为规则是由人工设计的,可以根据具体需求进行调整和修改。这种方法适用于处理特定领域的文本,例如法律、医学等专业领域的文本。然而,基于规则的自然语言生成方法也存在一些局限性。首先,设计和维护规则需要耗费大量的人力和时间,而且规则的覆盖范围有限,无法处理一些复杂的语言现象。其次,规则方法对于新的、未知的文本往往无法处理,因为缺乏对未知现象的规则定义。


为了克服基于规则的自然语言生成方法的局限性,一些研究人员提出了基于统计的自然语言生成方法。这种方法通过大量的语料库和训练数据来学习生成文本的规律和模式,可以自动生成符合语言规范的自然语言文本。相比之下,基于统计的自然语言生成方法具有更高的灵活性和可扩展性,可以适应各种类型的文本和领域。
2.2基于规则生成的代码示例
基于规则的自然语言生成方法通常需要大量的手动干预和定制,因此很难用简单的代码来展示。但是,我们可以尝试用一些伪代码来描述基于规则的自然语言生成方法的基本原理。
假设我们有一个简单的规则,用于将英文句子中的代词(例如it、them等)替换为相应的名词。我们可以定义一个规则如下:
rule: replace_pronoun(sentence, pronoun, noun) 1. find the position of pronoun in sentence 2. replace pronoun with noun in sentence at the found position 3. return the modified sentence这个规则可以通过一些参数来调用,例如:
sentence = "I saw them playing football"
pronoun = "them"
noun = "boys"
new_sentence = replace_pronoun(sentence, pronoun, noun)
print(new_sentence) # "I saw boys playing football"自然语言生成系统中,可能需要考虑更多的规则和模式,例如句子的结构、词序、语气、时态等等。因此,基于规则的自然语言生成方法需要更多的手动干预和定制,通常需要专业的语言学家和领域专家参与开发。
3.基于统计生成
基于统计生成(Statistical Generation)是一种自然语言处理方法,它基于大量的训练数据,学习语言规律,然后根据学习结果生成自然语言。该方法主要包括以下几个步骤:
- 收集语料库:收集一定量的语言数据,可以是书籍、报纸、网站、对话等,数据的规模和质量直接影响到生成结果的好坏。
- 数据预处理:对收集到的数据进行处理,如去除标点符号、停用词等。
- 模型训练:使用统计模型对处理后的数据进行训练,学习语言规律。
- 生成文本:根据模型的学习结果生成自然语言文本。
基于统计生成的方法通常使用机器学习算法,如朴素贝叶斯、决策树、神经网络等,来学习和生成文本。相比基于规则的方法,基于统计生成的方法具有更高的灵活性和可扩展性,可以适应各种类型的文本和领域。但是,它也需要大量的训练数据和计算资源。
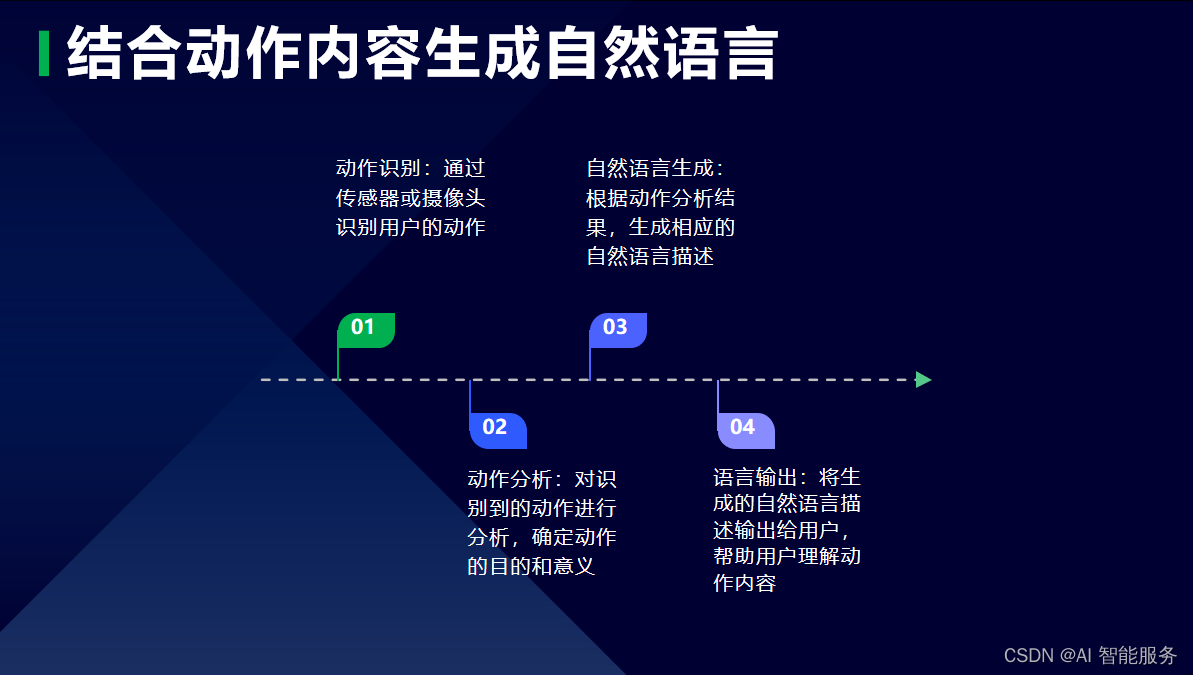
3.1基于统计生成的步骤




3.2基于统计生成的代码示例
下面是一个基于Python的简单示例,展示如何使用基于统计的方法生成文本。这个例子使用了朴素贝叶斯分类器来生成文本。
import nltk
from nltk.corpus import reuters # 加载路透社语料库
reuters_corpus = reuters.sents() # 训练朴素贝叶斯分类器
classifier = nltk.NaiveBayesClassifier.train(reuters_corpus) # 生成文本
def generate_text(n): for _ in range(n): # 使用分类器生成文本 label = classifier.classify(nltk.NaiveBayesClassifier.prob_classify(classifier).sample()) print(f"{label}: {nltk.translate.ibm1.ibm1(classifier, reuters_corpus, label)}") # 生成10个文本
generate_text(10)这个例子使用了NLTK库来加载路透社语料库,并使用朴素贝叶斯分类器来学习和生成文本。在生成文本时,我们首先使用分类器来预测文本的类别,然后根据类别和已有的文本生成新的文本。在这个例子中,我们只生成了10个文本,但是你可以通过增加generate_text函数的参数来生成更多的文本。请注意,这个例子是一个简单的演示,实际上基于统计的自然语言生成方法需要更复杂的模型和大量的训练数据。