一句话总结
本综述全面回顾了生成模型的历史、基本模型组件、AIGC从单模态交互和多模态交互的最新进展,以及模态之间的交叉应用,最后讨论了AIGC中存在的开放问题和未来挑战。
摘要
最近,ChatGPT 与 DALL-E-2 和 Codex 一起受到了社会的广泛关注。因此,许多人对相关资源产生了兴趣,并试图揭开其出色表现背后的背景和秘密。
实际上,ChatGPT 和其他生成式人工智能 (GAI) 技术属于人工智能生成内容 (AIGC) 的范畴,涉及通过人工智能模型创建数字内容,例如图像、音乐和自然语言。
AIGC 的目标是使内容创建过程更加高效和易于访问,从而能够以更快的速度制作高质量的内容。
AIGC是通过从人类提供的指令中提取和理解意图信息,并根据其知识和意图信息生成内容来实现的。
近年来,大型模型在 AIGC 中变得越来越重要,因为它们提供了更好的意图提取,从而改进了生成结果。
随着数据的增长和模型的规模,模型可以学习的分布变得更加全面和接近现实,从而导致更真实和高质量的内容生成。
本调查全面回顾了生成模型的历史、基本组件、AIGC 从单模态交互和多模态交互的最新进展。我们从单峰性的角度介绍了文本和图像的生成任务和相关模型。我们从多模态的角度来介绍上述模态之间的交叉应用。最后,我们讨论了 AIGC 中存在的开放性问题和未来的挑战。
论文:A Comprehensive Survey of AI-Generated Content (AIGC): A History of Generative AI from GAN to ChatGPT
链接: https://arxiv.org/pdf/2303.04226v1.pdf
单位:CMU & Lehigh University
贡献
一共有三点贡献:
据我们所知,我们是第一个为 AIGC 和 AI 增强生成过程提供正式定义和全面调研的人。
我们回顾了AIGC 的历史和基础技术,并从单模态生成和多模态生成的角度对GAI 任务和模型的最新进展进行了全面分析。
我们讨论了AIGC 面临的主要挑战和AIGC 未来的研究趋势。
总体看
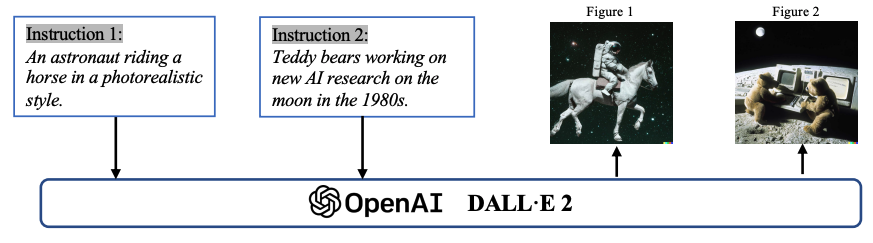
图像生成中的 AIGC 示例。向 OpenAI DALL-E-2 模型给出文本指令,它根据指令生成两张图像:
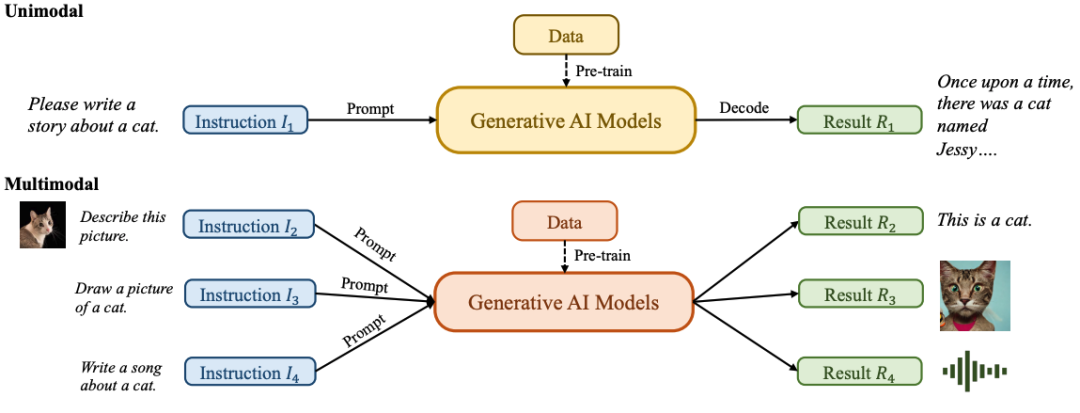
AIGC整体图。一般来说,GAI模型可以分为两类:单峰模型和多峰模型。单模态模型从与生成的内容模态相同的模态接收指令,而多模态模型接受跨模态指令并产生不同模态的结果:
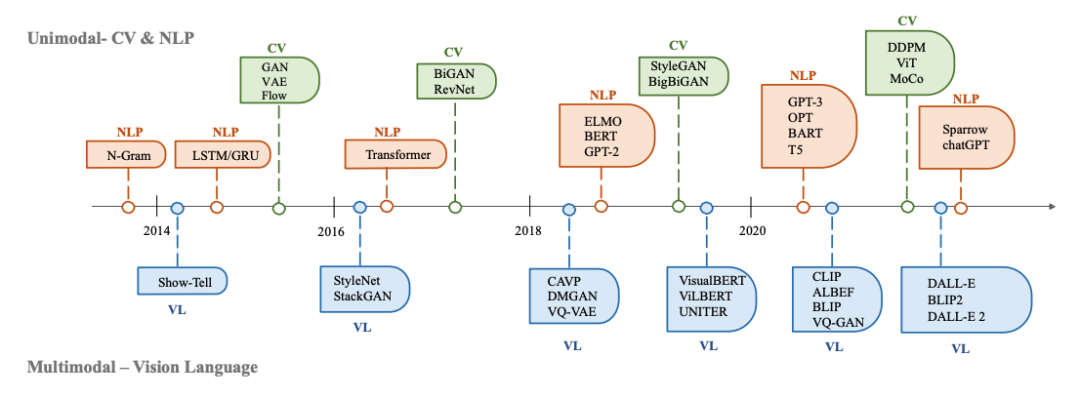
生成AI在CV、NLP和VL领域的历史:
单模态
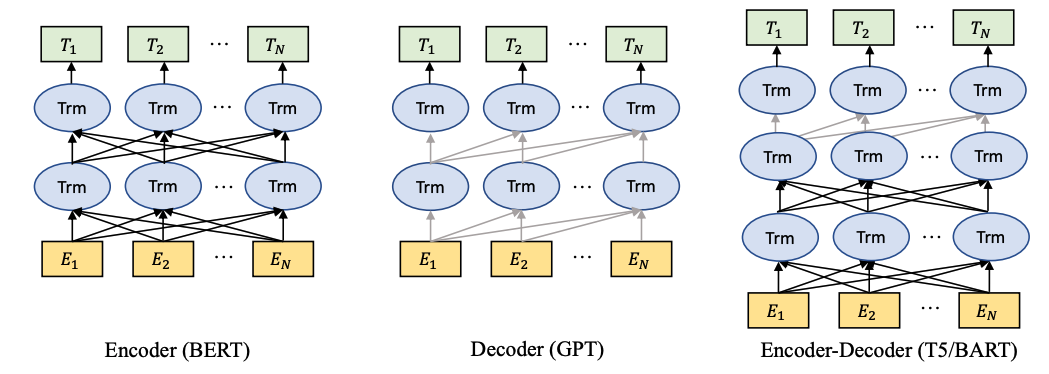
预训练大语言模型的大体类型:
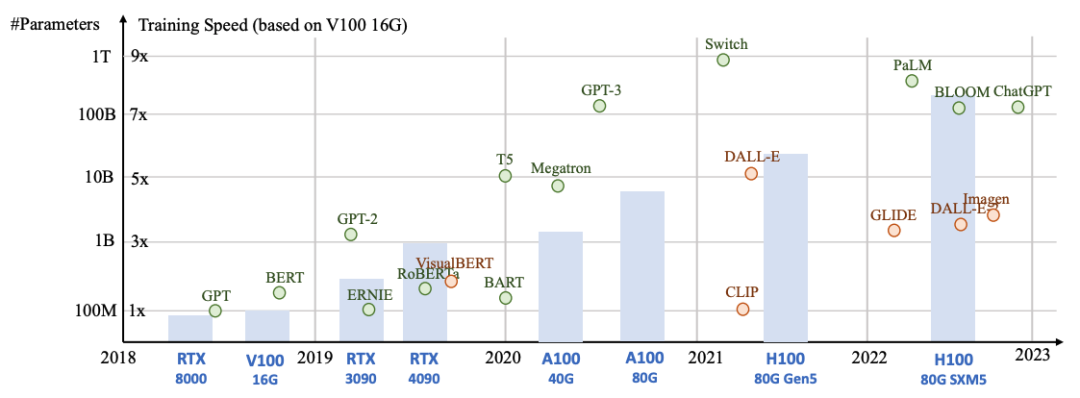
模型大小、训练速度在不同模型和计算设备的统计数据:
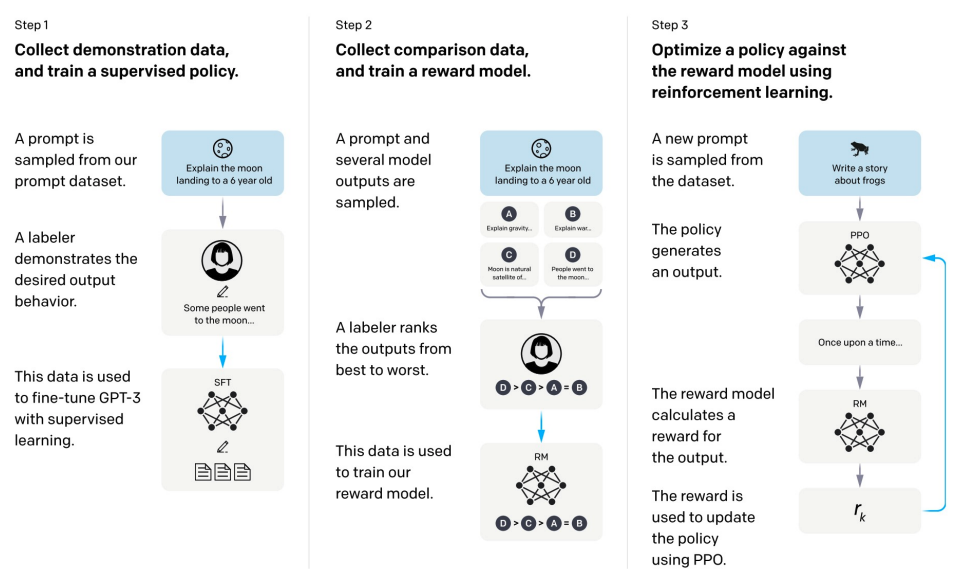
InstructGPT的架构:
视觉分类的模型分类:
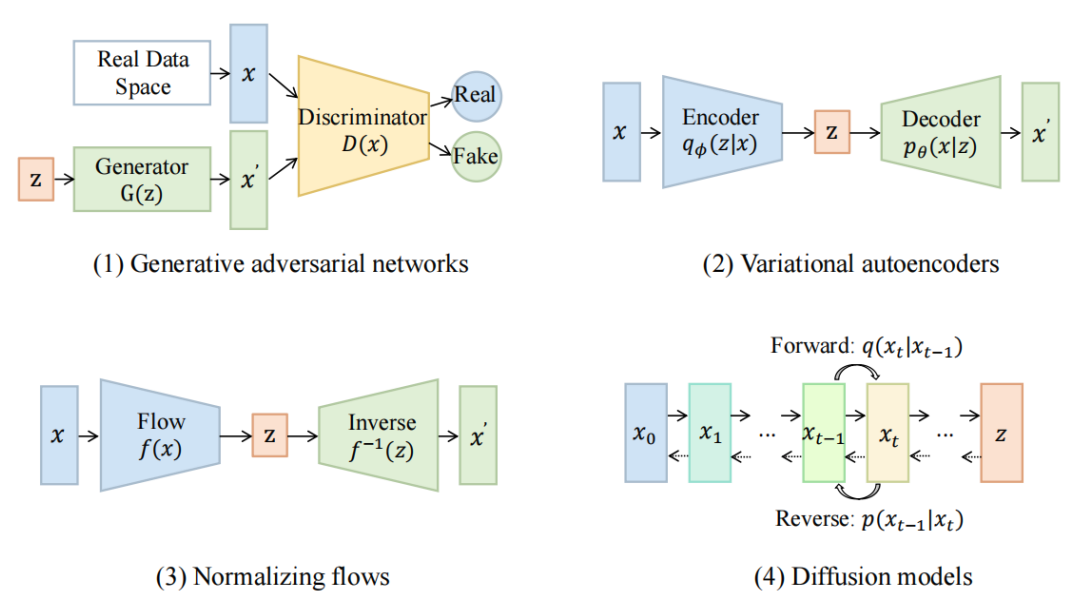
视觉生成模型的基本框架:
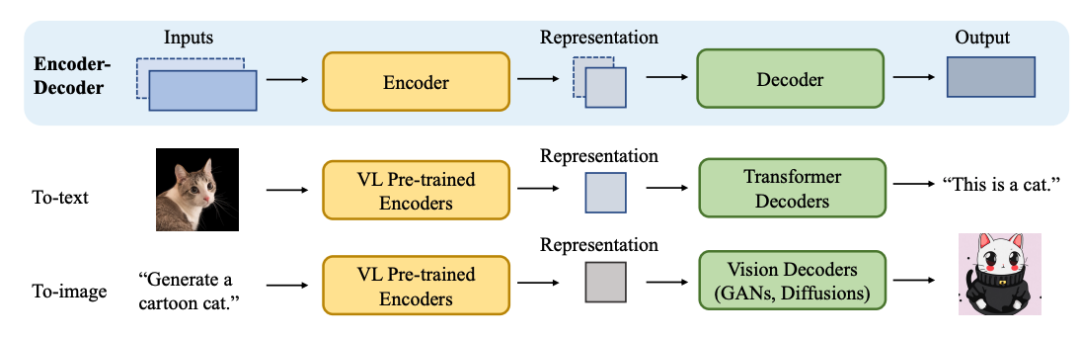
多模态
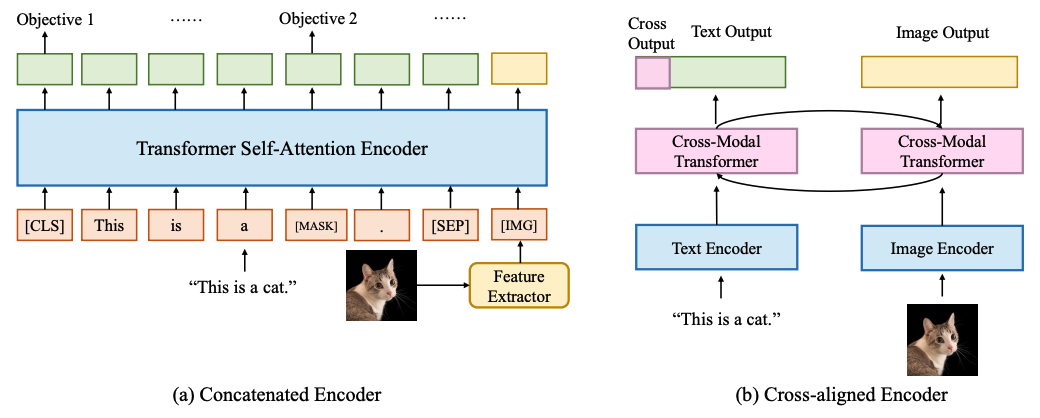
两种视觉语言编码类型:
两种解码类型:

DALL-E-2模型结构:

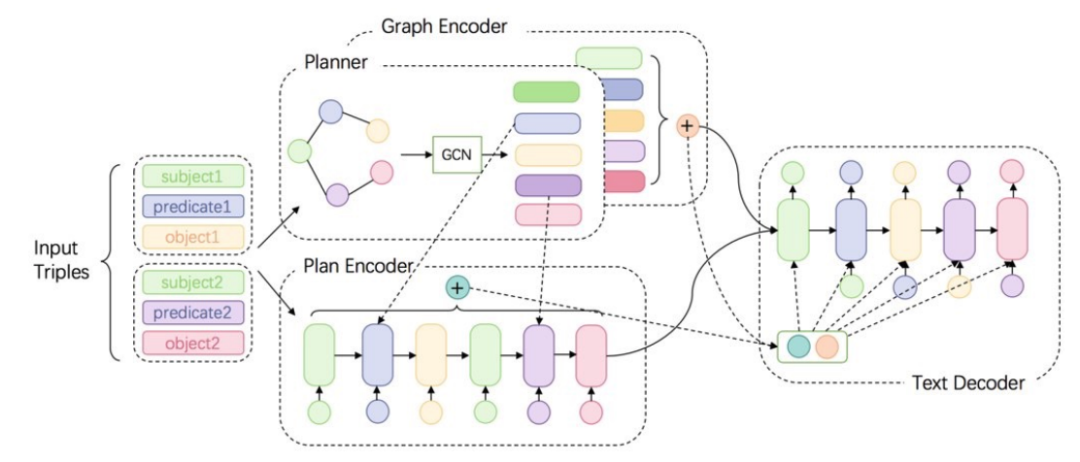
KG-文本的生成模型的一种方法DUALENC:
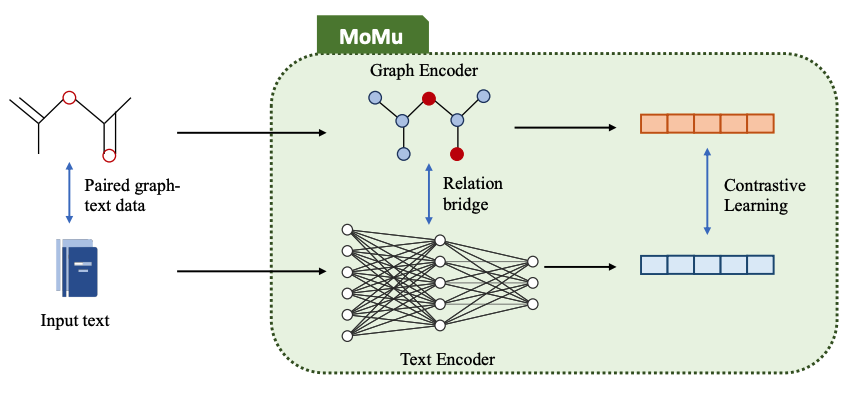
跨模态文本分子生成模型MoMu:
当前研究领域、应用与相关公司的关系图,其中深蓝色圆圈代表研究领域,浅蓝色圆圈代表应用,绿色圆圈代表公司:
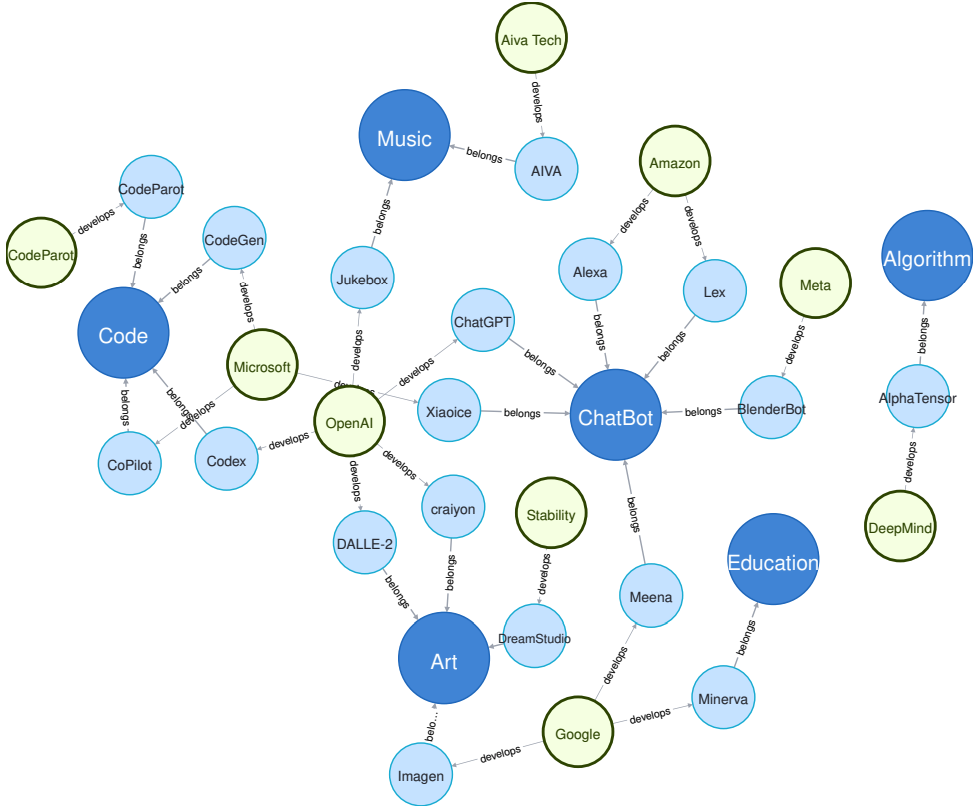
应用
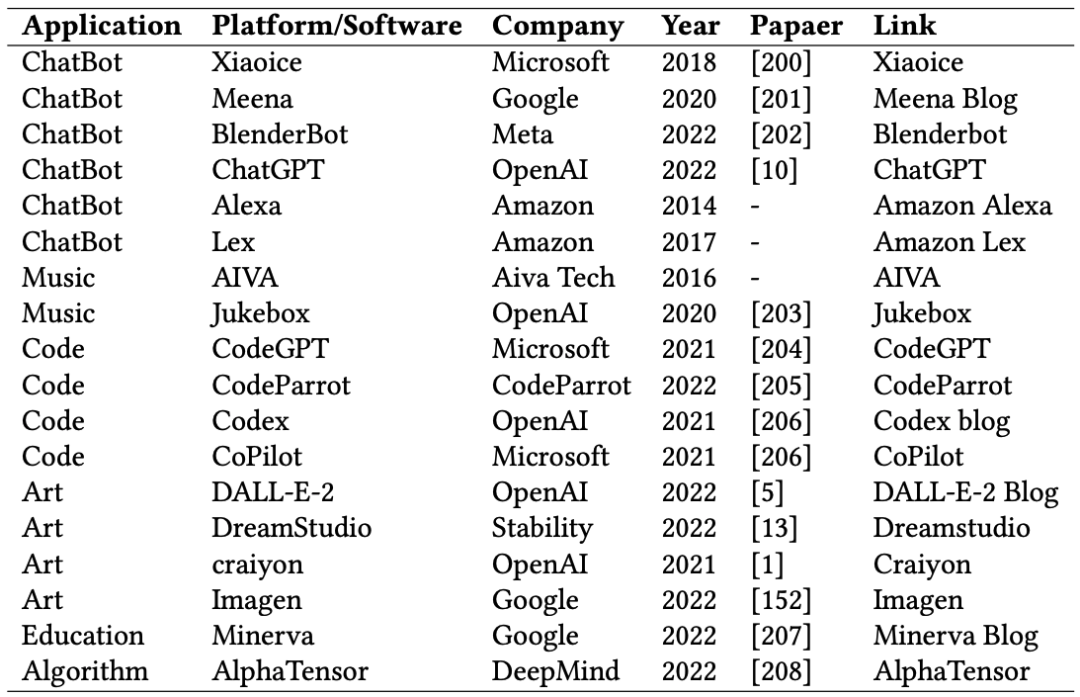
生成AI模型应用:
AIGC的效率
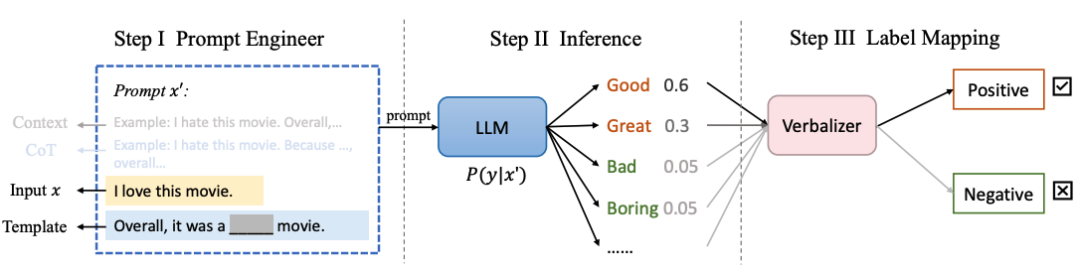
prompt learning的通常流程: