在当今的技术环境中,许多组织已经从构建单一的应用程序转变为采用微服务架构。微服务架构是将服务分解成多个较小的应用程序,这些应用程序可以独立开发、设计和运行。这些被拆分的小的应用程序相互协作和通信,为用户提供全面的服务。在设计和部署微服务应用时利用无服务器计算和无服务器架构,可有效解决微服务架构本身存在的复杂性、模块间过度依赖以及系统可扩展性有限等难题。本文将以 FreeWheel 的 AD Debug Service 为例,探索从现有微服务架构过渡到无服务器架构过程中解决问题的技术实践。AD Debug Service 是为用户提供的对 FreeWheel 广告服务器决策进行诊断和深入了解的工具。
亚马逊云科技开发者社区为开发者们提供全球的开发技术资源。这里有技术文档、开发案例、技术专栏、培训视频、活动与竞赛等。帮助中国开发者对接世界最前沿技术,观点,和项目,并将中国优秀开发者或技术推荐给全球云社区。如果你还没有关注/收藏,看到这里请一定不要匆匆划过,点这里让它成为你的技术宝库!
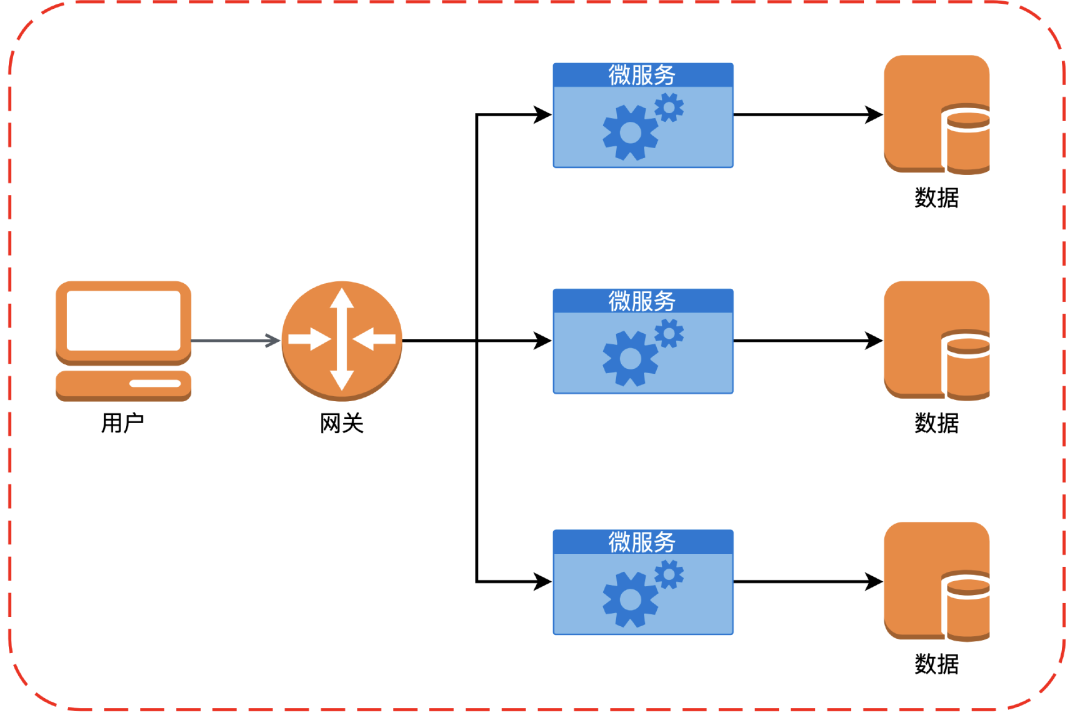
如下图所示,Freewheel 的核心业务团队放弃了最初构建单一、庞大的单体应用程序的方法,转而采用微服务架构。
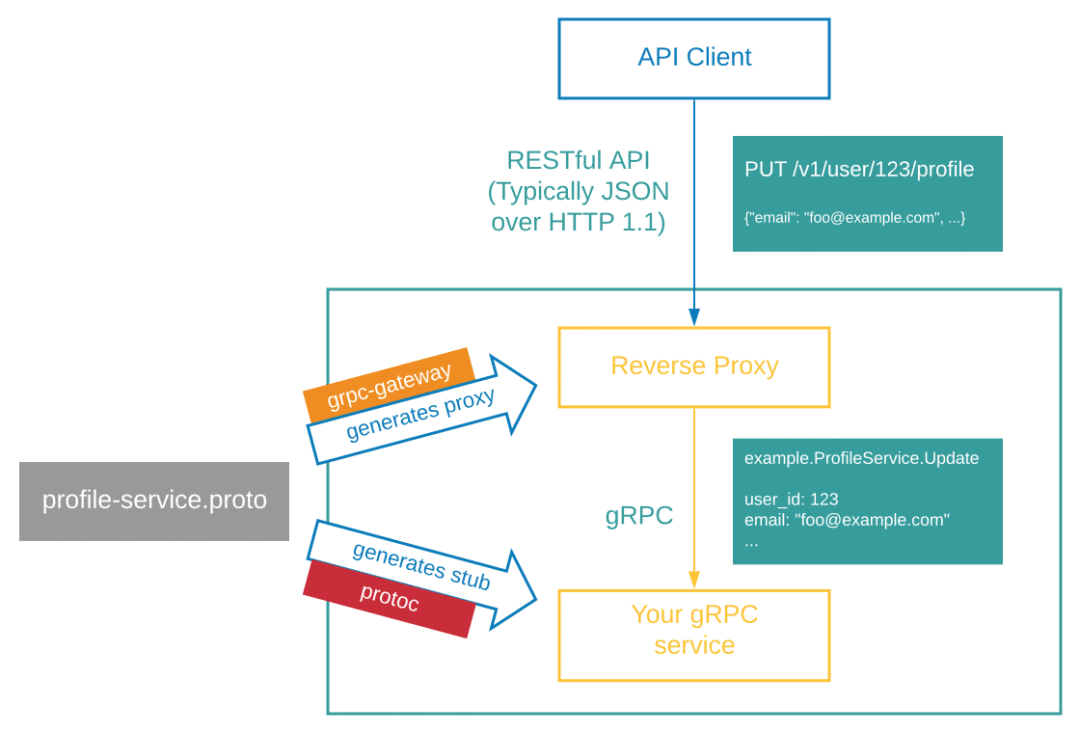
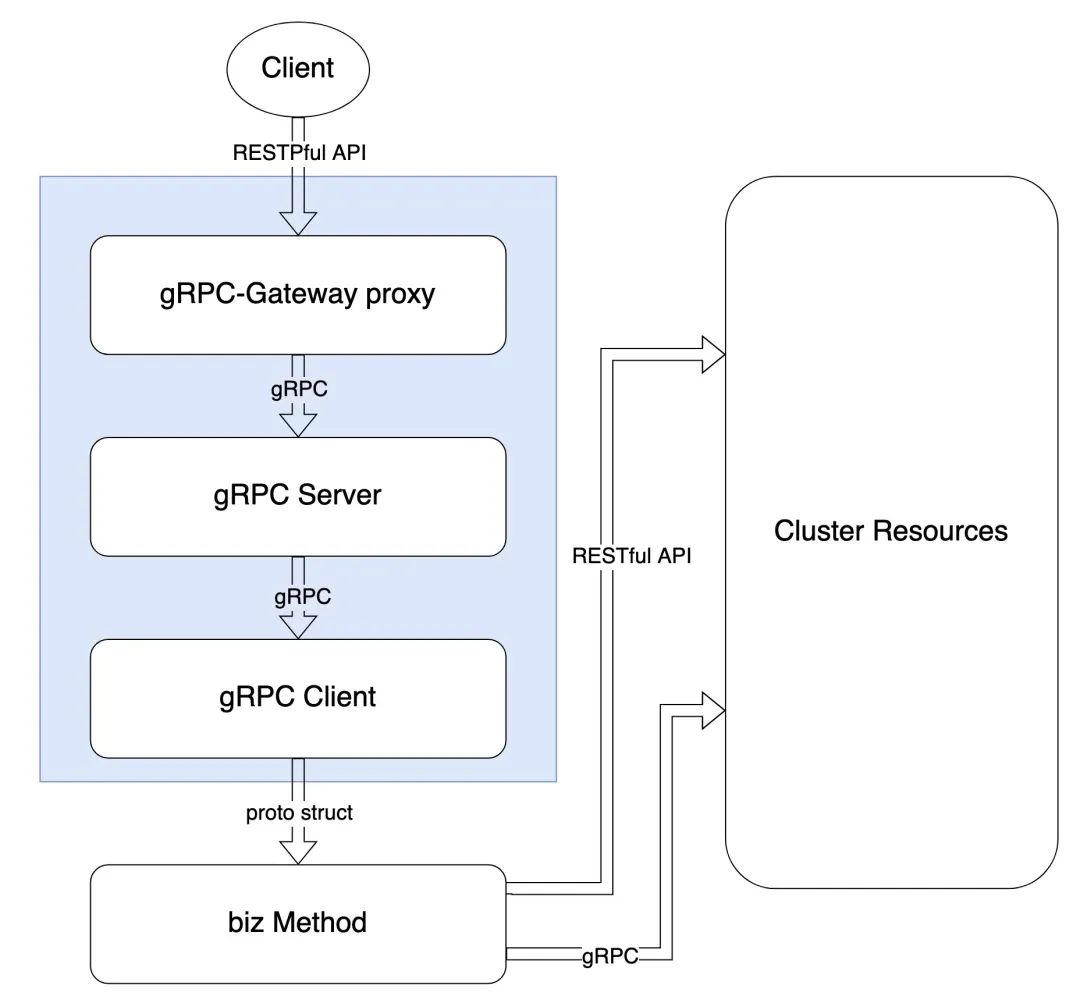
与 Freewheel 的众多微服务一样,AD Debug Service 也是采用 gRPC 框架创建 gRPC API,并通过 gRPC-Gateway 同时对外提供 RESTful API。AD Debug Service 的整体流程大致如下图所示。为了更容易理解后续的迁移步骤,我们先仔细了解一下 AD Debug Service 的工作流程 :
- 当用户的诊断请求到达 AD Debug Service 的 gRPC-Gateway 时,它将 JSON 数据解析为 Protobuf 消息;
- gRPC-Gateway 使用解析的 Protobuf 消息发出正常的 gRPC 客户端请求;
- gRPC 客户端将二进制格式的 Protobuf 发送到 gRPC 服务器;
- gRPC 服务器处理请求,此时会真正执行业务代码,并且通过 gRPC 或 HTTP 模式调用其他微服务(其中包括调用 Freewheel 的 AD Debug Service 并获取广告决策结果);
- gRPC 服务器以 Protobuf 二进制格式返回响应给 gRPC 客户端,客户端将其解析为 Protobuf 消息并返回到 gRPC-Gateway;最后 gRPC-Gateway 将 Protobuf 消息编码为 JSON 并将其返回给原始客户端。
https://grpc.io/blog/coreos/?trk=cndc-detail
通过上面的流程图我们可以看出来,AD Debug Service 与其他微服务不同之处在于,它实际上只有 RESTful API 会被访问,gRPC API 则只用于处理 HTTP 请求,因此从这里我们也可以看出来,AD Debug Service 的迁移不会影响到别的 gRPC 的微服务。
1 向无服务器改造和迁移的原因
1.1 现有服务存在的问题
- 伸缩粒度粗: 微服务中各个子业务的不同接口,QPS 差距较大,对扩展的诉求完全不同,升级的频率也可能不同;进一步拆分的话则会使微服务数量提升一个数量级,进一步增加基础设施管理的负担;
- 成本高: 每个微服务都要考虑冗余,保证高可用。随着微服务数量的增加,基础设施的数量会呈现指数级增长,但云服务的基础设施收费方式没有改变,依然采用按照资源大小及以小时为单位计费的方式;以容器为基础的微服务基础设施在弹性等方面仍有不足。
1.2 Serverless 可以帮助解决现有问题
开发者实现的服务器端应用逻辑(微服务甚至粒度更小的服务)以事件驱动的方式运行在无状态的临时容器中,这些容器和计算资源完全由云提供商管理,开发者只需关心和维护业务层面的正常运行,其他部分如运行时、容器、操作系统、硬件等,都由云提供商来解决。
总体来说,Serverless 有以下优势:
- 免运维: 不需要管理服务器主机或者服务器进程;监控以确保服务仍然运行良好;自动系统升级,包括安全修补;
- 弹性伸缩: 云平台负责负载平衡和请求路由以有效利用资源,并且根据负载进行自动规模伸缩与自动配置;
- 按需付费: 根据使用情况决定实际成本;
- 高可用: 可用性冗余,以便单个机器故障不会导致服务中断;具备隐含的高可用性。
1.3 选择 AD Debug Service 实现无服务器架构改造和迁移
在我们现有的业务场景中,AD Debug Service 是一个典型的用完即走的业务场景,而且其工作内容主要是与 交互,获取广告投放的决策信息,并调用多个其他微服务获取相关业务数据信息,整合好返回给前端客户用于展示,每个月接收的请求不到 10 万条,并且,用户对于请求的响应速度需求不高,也不对外暴露 因此对比于部署在 EKS 的 Cluster 中,分配固定的 pod 资源,Serverless 中的 FaaS 是一种更适合它的模式。
2 技术方案选型
Amazon Lambda 是亚马逊云科技在 2014 年推出的 Serverless 计算服务, 允许开发人员构建和运行应用程序而无需管理服务器。在 Lambda 里,使用函数(Function)来存储代码,供 Lambda 调用,因此,Lambda 类的无服务器计算服务也被称作函数即服务(Function-as-a-Service / FaaS)。
Freewheel 一直以来都是使用的亚马逊云科技提供的云服务,所以后续我会以亚马逊云科技提供的服务为例来介绍我们从现有微服务架构迁移到 Serverless 的过程。Amazon Lambda 因为与其他云上服务深度集成而更快速并且更安全,因此我们选用 FaaS 模式以 Amazon Lambda 作为核心来迁移我们的微服务。
亚马逊云科技为 Lambda 提供高可用性的计算基础设施以及所有的所有管理工作,我们只需将我们的业务代码使用 Lambda 支持的语言运行系统(我们选择的是 Go 语言)组织到 Lambda 函数即可。
亚马逊云科技目前为止提供了 3 种可以同步调用 Lambda 的方式:
方式1:采用 Amazon API Gateway 与 Lambda 集成的方式
方式2:采用 Application Load Balancer 与 Lambda 集成的方式
方式3:直接使用 Lambda Function URL
2.1 Amazon API Gateway + Lambda
亚马逊云科技支持使用 API Gateway 为 Lambda 函数创建带有 HTTP 端点的 Web API。Amazon API Gateway 是一项完全托管的服务,可帮助开发人员轻松创建、发布、维护、监控和保护任何规模的 API。使用 API Gateway 可以构建 REST API 和 HTTP API 两种类型的 RESTful API,同时也支持创建 WebSocket API,使得客户端可以通过 HTTP 和 WebSocket 协议连接到应用程序。API Gateway 还提供了一些高级功能,例如授权和访问控制、缓存、请求转发等服务。API Gateway 的架构图如下所示:
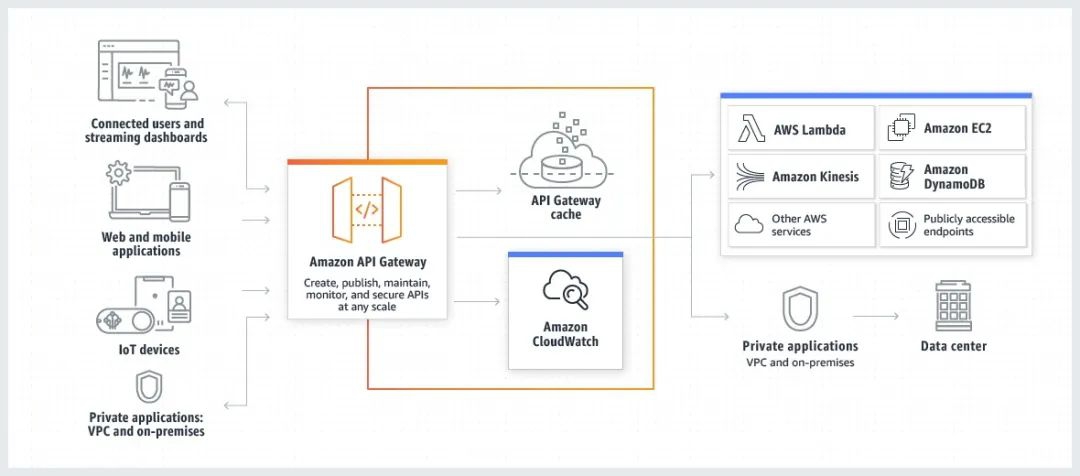
2.2 Application Load Balancer + Lambda
Elastic Load Balancing 支持 Lambda 函数作为 Application Load Balancer 的目标。使用负载均衡器规则,基于路径或标头值将 HTTP 请求路由到一个函数。处理请求并从 Lambda 函数返回 HTTP 响应。
我们需要将 Lambda 函数注册到 Target Group,并在 ALB 中将侦听器规则配置为将请求转发到 Lambda 函数的 Target Group。当负载均衡器将请求转发到 Target Group 并使用 Lambda 函数作为目标时,它会调用 Lambda 函数并以 JSON 格式将请求内容传递到 Lambda 函数。
ALB 在应用层进行操作,将 HTTP 请求路由到多个后端资源,这些后端资源包括 Amazon Lambda 函数。ALB 通常用于暴露一个公共的 Web 地址端点,其资源则是托管在 AmazonVPC 的私有子网中;同时也支持只能从组织内部网络访问的私有 ALB。
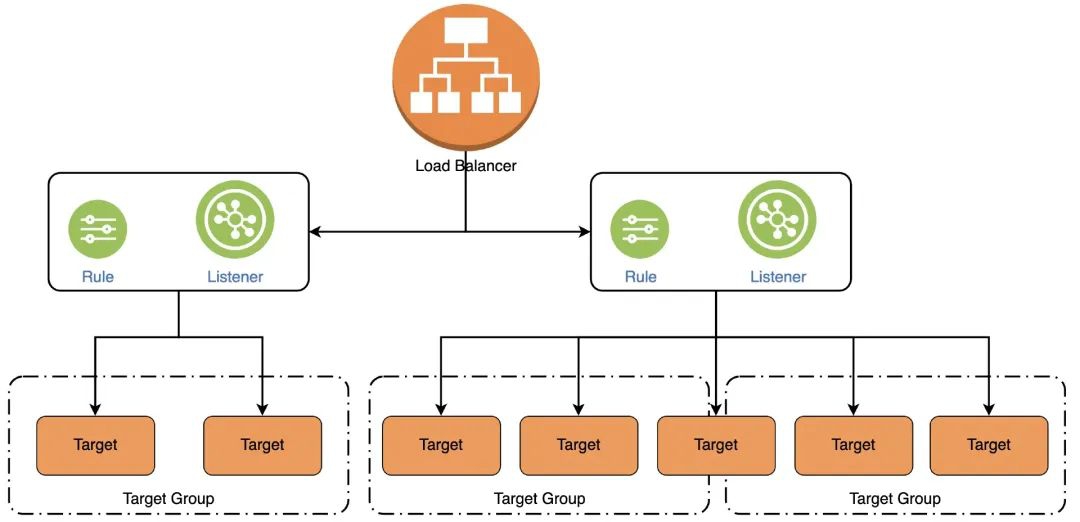
但是使用 Target Group 本身存在一些限制:
- Lambda 函数和目标组必须位于同一账户中,且位于同一 Region 中;
- 可以发送到 Lambda 函数的请求正文的最大大小为 1 MB;
- Lambda 函数可以发送的响应 JSON 的最大大小为 1 MB;
- 不支持 WebSocket;
- 不支持 Local Zones(Amazon Web Services Local Zones 是亚马逊云科技提供的基础设施部署的一种形式,可将计算、存储、数据库和其他某些初级服务放置在更靠近大量人口聚居的位置)。
2.3 Lambda Function URL
Lambda Function URL 是 Lambda 函数的专用 HTTP(S) 端点。创建函数 URL 时,Lambda 会自动生成唯一的 URL 端点。创建函数 URL 后,其 URL 端点永远不会改变。函数 URL 支持跨源资源共享(CORS)配置选项。并且 Function URL 可以支持两种方式返回响应体:BUFFERED 和 RESPONSE_STREAM。
BUFFERED 是一种默认的响应方式:当选择这种方式返回响应时,只有当负载完成时,调用结果才会被返回,并且响应负载的限制为 6 MB。
RESPONSE_STREAM 方式则会将响应负载流式传输回客户端。响应流式处理可在部分响应可用时就将其发送回客户端。因此,我们可以使用 RESPONSE_STREAM 方式处理来构建返回较大负载的函数。响应流负载的软限制为 20MB。响应的前 6MB 的带宽无上限,超过 6M 之后的最大处理速率是 2MBps,并且流式处理响应会产生费用,超过 6M 的部分按照 0.008USD/GB 计算。
值得注意的是,Lambda Function URL 只能通过公共网络访问,截止到 2023 年 9 月,它并不支持 Amazon PrivateLink,保护 Lambda 函数 URL 的方式是选择 Amazon IAM 授权,或者使用基于资源的策略进行安全和访问控制。
2.4 三种方式优缺点对比
我们从以下几个方面简单对比一下 API GW,ALB 和 Function URL:
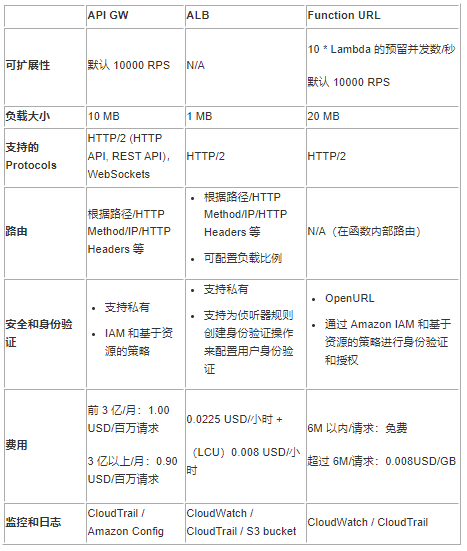
从上对比来看,如果有负载的硬性要求(大于 6M),那最好选择 Function URL 的 RESPONSE_STREAM 响应方式;如果需要支持私有访问,那最好选择 API GW 或者 ALB 的方式。
因为 Freewheel 对于安全的监管严格,我们需要使用统一的登录鉴权方式访问公司服务,所以不推荐使用 Function URL 的方式;同时鉴于公司已经有实例在使用 ALB,如果我们共享这个 ALB,只在该 ALB 上加入 AD Debug Service 的 Target Group,那么我们可以将 ALB 本身按时间的费用忽略不计。
所以针对 AD Debug Service,我们选择通过 ALB + Lambda 的方式实现从微服务到 Serverless 的迁移。
3 代码迁移的过程
AD Debug Service 的调用流程如图:用户端的 RESTful 请求经过 gRPC-Gateway 代理转化为 gRPC 请求,调用 gRPC 客户端,客户端调用业务方法最终返回响应。
在改造的过程,我们可以保证进行最少的改动,保持其中业务逻辑部分不变,将下图蓝色部分全部替换。
虽然 Freewheel 已经支持通过内部的 Serverless LCDP 平台创建 ALB+Lambda,但是本文中,我将通过控制台操作的方式演示所有流程。

3.1 Step1 创建 Lambda
- 打开 Lambda 控制台的 Functions page
- 选择 Create function
- 选择 Author from scratch
- 输入函数名称: ad_debug
- Runtime 选择 Go 1.x
- 在 Execution Role(执行角色)中,选择 Create a new role with basic Lambda permissions(创建具有基本 Lambda 权限的新角色)
创建完空的 Lambda 之后,我们需要将我们的包上传并部署。上面说到我们的服务是基于 gRPC 的,而且保持业务处理部分的代码不变,我们的业务处理 Handler 基本上类似于:
func (h *BizHandler) BizExec(ctx context.Context, req *proto.BizRequest) (*proto.BizRequestResponse, error) { return h.bizDomain.BizExec(ctx, req)
}
我们现在要解决的问题主要有两个:如何进行内部路由,以及怎么处理 TargetGroup event 与 proto 结构体的相互转化。这两部分所解决的就是上图蓝色框内的内容。类似于 gRPC-Gateway 代理,我们针对每个 BizHandler 在外部做一个 Wrapper,其中 Wrapper 做的事情包括,注册 Handler,转化请求体。
内部的路由
我们通过 Register 方法,把所有方法的 Method,Pattern 和 HanlerFunc 注册到数组里,当请求来时,我们通过匹配数组里的 Method 和 Pattern 来决定调用哪个 Pattern。其中 PathMatchAndParse 会根据正则匹配 path,可以根据自己的需求定制,这里不展开赘述。
// Register
func (controller *Controller) RegisterEndpoint(method string, pattern string, handleFunc func(ctx context.Context, req *event.ALBTargetGroupRequest) (events.ALBTargetGroupResponse,error)) {controller.routes = append(controller.routes, &route{pattern: pattern, method: method, handleFunc: handleFunc, })
}// Handle
func (controller *Controller) Handle(ctx context.Context, req *events.ALBTargetGroupRequest) (resp events.ALBTargetGroupResponse, err error) { var isMatch = false var fn DomainFunc for _, route := range controller.routes { m, vars, err := PathMatchAndParse(req.Path, route.pattern) if err != nil { return ResponseInternalServerError() } if m && req.HTTPMethod == route.method { isMatch = true fn = route.handleFunc break } } if !isMatch { return ResponseMethodNotAllowed() } return fn(ctx, req)
}
TargetGroup event 与 proto 结构体的转化
这部分比较简单,可以直接使用 grpc-gateway 包里的 JSONPb。但是处理把 proto 结构体转化到 json 作为响应体这部分,我们可以抽取到一个公共的 interceptor:
var jsonPb = &runtime.JSONPb{}
func Interceptor(ctx context.Context, req *events.ALBTargetGroupRequest, bizHandler func(ctx context.Context, req *events.ALBTargetGroupRequest) (interface{}, error)) (resp events.ALBTargetGroupResponse, err error) { res, err := bizHandler(ctx, req) if err != nil { return } resBytes, err := jsonPbEmitDefaults.Marshal(res) if err != nil { return } resp = events.ALBTargetGroupResponse{ StatusCode: 200, Body: string(resBytes), Headers: map[string]string{ "Content-Type": "application/json", }, } return
}func BizExec(ctx context.Context, req *events.ALBTargetGroupRequest) (resp interface{}, err error) { var adReq proto.BizRequest err = jsonPb.Unmarshal([]byte(req.Body), &adReq) if err != nil { return events.ALBTargetGroupResponse{}, err } res, err := bizHandler.BizExec(ctx, &adReq) if err != nil { return events.ALBTargetGroupResponse{}, err } return bizHandler.BizExec(ctx, &adReq)
}
所以,最终 Lambda 的 main 函数类似于:
var controller *Controller
func init() { controller = NewController() // Register endpoints controller.RegisterEndpoint("POST", "/exec", Interceptor(BizExec)) controller.RegisterEndpoint(...) ...
}func main() { lambda.Start(controller.Handle)
}
完成 Lambda 的函数体之后,我们可以通过以下命令创建 Lambda 的 zip 包,选择上面创建好的 Lambda,点击 Code 页面,选择 Upload from.zip file 部署到 Amazon Web Service 上:
GOOS=linux GOARCH=amd64 go build -o bin/ad_debug_service main.go cd bin && zip -r ad_debug_service.zip .
3.2 Step2 创建 Target Group
- 通过以下网址打开 Amazon EC2 控制台:
https://console.aws.amazon.com/ec2/?trk=cndc-detail - 在导航窗格上的 LOAD BALANCING(负载均衡) 下,选择 Target Groups(目标组)
- 选择 Create target group(创建目标组)
- 选择目标类型,选择 Lambda 函数
- Target group name,键入目标组的名称
- 选择 Next(下一步)
- 指定单个 Lambda 函数为上面我们创建的 Lambda
- 选择创建目标组
3.3 创建 ALB 并设置 Listener
- 通过以下网址打开 Amazon EC2 控制台:https://console.aws.amazon.com/ec2/?trk=cndc-detail
- 在导航窗格中,选择负载均衡器
- 选择创建负载均衡器并选择类型为 Application Load Balancer
- Scheme 选择 internal,并且 sg 和 VPC 保持跟 Lambda 的一致
- 在 Listeners 选项卡上,选择 Add listener(添加侦听器)
- 对于协议:端口,选择 HTTP 并保留默认端口
- 对于 Default actions (默认操作),选择转发,然后选择上面创建的目标组
- 选择 Add
3.4 Step4 将 ALB 注册到 Gateway
因为我们创建的 ALB 是私有的,如果想要外部用户访问的话,那我们需要将这个 ALB 的 DNS 注册到我们对外的 gateway 上,这个 Gateway 也帮我们完成用户登录验证的工作。
4 代码改造过程中解决的问题
4.1 超大负载处理
上述提到 AD Debug Service 会请求 AD Decision Service 来获取广告投放的相关调试信息,所以返回的数据量会比较大(一般会超过 1M),而在上面的介绍里我们也提到了使用 TargetGroup 会有 1M 负载的限制,并且,我们了解到响应体的大小也会影响到最后费用的计算,所以针对怎么去处理这些超大的负载(大于 1M),我们探讨了几个方案。
压缩
对于如何减少负载的大小,压缩是一个很好的方式,针对这个方法,我们考虑了从输入和输出两个方向上的负载的压缩。
压缩影响体
针对输出做压缩的方案很常见,我们要做的是让其适配 ALB+Lambda 的这种模式。我们依然采用 go 自带的 compression/gzip 包,稍微做了一些调整。
因为 TargetGroup 的响应只支持 base64 的压缩,所以我们使用 encoding/base64 包作为 gzip 的写入,并且切记需要将响应体的 IsBase64Encoded 设置为 true。压缩流程可以概括为:
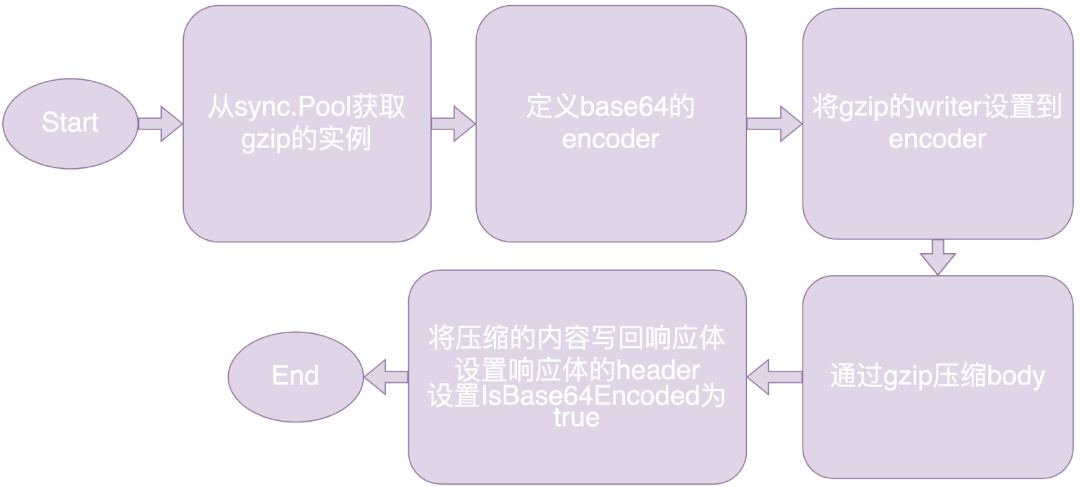
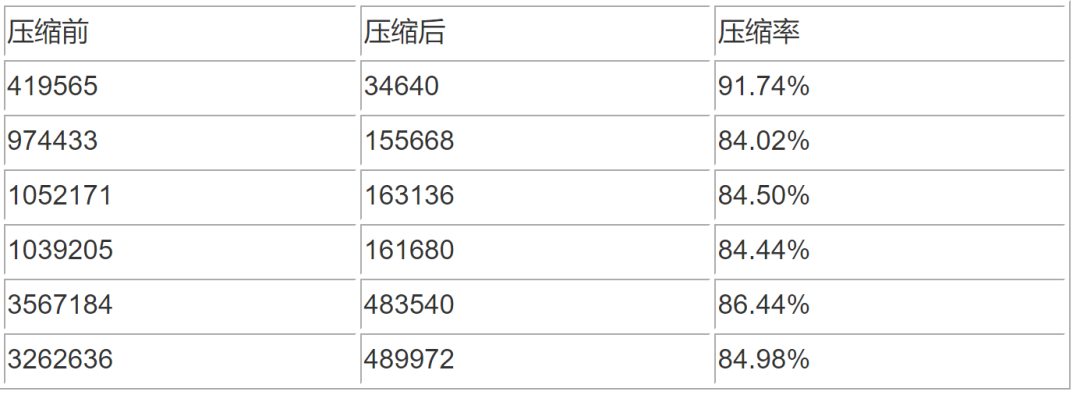
我们可以简单看一下应用到 AD Debug Service 的压缩效果:
压缩请求体
除了需要关注输出之外,我们同样需要关注输入也就是请求体的大小。特别是在 AD Debug Service 中存在需要上传文件的场景,所以针对上传文件的请求体,我们也做了压缩处理。
在前端,我们支持上传 csv 文件,所以在上传文件的时候,我们选择去压缩文件的内容,压缩使用到的包是 react-zlib-js,在上传文件的时候,创建一个 FileReader 读取文件内容,然后通过压缩包里的 gzipSync 方法将文件内容进行 gzip 压缩,最后将压缩后的文件内容上传到后端:
import { gzipSync } from 'react-zlib-js';const processFileInCompress = (uploadFile File) => { const rd = new FileReader(); rd.readAsBinaryString(uploadFile); rd.onload = content => { const conRes = content?.target?.result; const bf = gzipSync(conRes); const gzc = new File([bf], uploadFile.name); uploadCompressedFile(gzc); };
};
在后端,我们接收到压缩后的文件内容,需要进行解压缩。需要注意的是,通过 ALB 传输的数据如果 Content-Type 是 multipart/form-data 类型,那么都会自动进行 base64 编码处理,因此我们在获取响应体之后,需要先进行 base64 解码,获得解码之后的 body,然后进行 gzip 解压缩。
上传 S3
压缩的方式在很大程度上解决了 1M 的限制,但是并不能从根本上解决问题。其实,除了上述所说的压缩的方式来解决 ALB 对于负载大小的限制之外,我们也可以通过将请求体上传 S3,后端从 S3 下载请求体,以及将响应体上传 S3,前端通过 S3 下载响应体的方式来解决这个问题。
例如在 AD Debug Service 中,我们将响应体中占比较大的 AD Decision 的结果,上传到 S3,然后将 S3 的下载链接返回,同时,在前端接收到响应体之后,再根据响应体中的 S3 的链接去下载相应的内容。
这个时候需要注意的一点是,一定要允许 S3 的跨域访问(CORS)。
[ { "AllowedHeaders": [ "*" ], "AllowedMethods": [ "GET" ], "AllowedOrigins": [ "*" ], "ExposeHeaders": [] }
]
4.2 处理 IncomingContext
在使用 gRPC 架构中 garpc-gatway 代理会通过 AnnotateContext 的方法把请求头里的 key/value 对转化成 context 里的 metadata,然后透传到整个服务的各个函数中,而 ALB 并不会特殊处理请求,所以我们需要在 Lambda 里提供一个 interceptor,能够帮我们根据请求头生成新的 context。
func WithIncomingHeaderMatcher(next ALBFunc) ALBFunc { return func(ctx context.Context, req events.ALBTargetGroupRequest) (resp events.ALBTargetGroupResponse, err error) { m := map[string]string{} for k, v := range req.Headers { key, t := matcher(k) if t { m[key] = v } } md := metadata.New(m) ctx = metadata.NewIncomingContext(ctx, md) return next(ctx, req) }
}
4.3 处理 URL 中查询字符串的解码
同样的,我们也希望可以通过 interceptor 的方式帮我们统一处理 URL 中查询字符串的转译问题。需要 url.QueryUnescape() 方法对请求里的 QueryStringParameters 进行转义操作。
4.4 个性化处理响应 Error
如果我们不对 bizHandler 的 error 做处理的话,最终通过 ALB 的响应体返回的 error 将会是个普通文本的类型。但是,原先我们基于 grpc-gateway 的模式产生的 error,都是做过了处理的,也就是最后的返回 error 也会是 json 格式,方便前端处理,因此,为了减少改动,也为了可读性,我们可以将 error 做个性化处理。
errMsg := fmt.Sprintf("{\"message\": \"%s\"}", err.Error())
return events.ALBTargetGroupResponse{ StatusCode: 500, Headers: map[string]string{ header.ContentType: "application/json", }, Body: errMsg,
}
4.5 配置其他依赖的 Endpoint
因为我们将原本属于某个集群的微服务迁移到了 Lambda 上,而这个服务还需要通过 RESTful 方式或者 gRPC 的方式调用原来集群中的其他微服务,那么我们必须配置被调用服务的 Endpoint,并且需要保证这些微服务可以允许集群外的访问。
5 流量迁移
5.1 Metrics 收集
如果服务中涉及到 Prometheus Metrics 的收集,并且在原来 gRPC 服务中采取的是 pull 的方式拉取 metrics 的值,那现在我们必须更新到采用 push 的方式将 metrics 推送到 Pushgateway,然后 Prometheus 通过 pull 的方式去 Pushgateway 拉取 metrics 的值,这是因为 Lambda 是一个用完即销毁的运行模式,我们不能保证 Prometheus 能够在 Lambda shutdown 之前来拉取 metrics,所以我们必须采用主动推送的方式更新。
我们使用 push 方式收集 metrics 的具体步骤如下:
- 首先我们必须有自己运行的 Pushgateway,暴露一个 Lambda 可以访问的 URL
- 然后在 Lambda 中我们定义一个 prometheus 包里的 pusher,使用 Pushgateway 的 URL,一个唯一的名字,以及访问这个 URL 使用到的用户名和密码,初始化这个 pusher
- 初始化一个 Collector,例如 CounterVec
- 将该 Collector 添加到 pusher 中
- 最后,可以在 Lambda 销毁之前,调用 Push() 方法将 metrics 推送到 gateway 上
var Pusher *push.Pusher
func init() { Pusher = push.New(pqmURL, pqmJob).BasicAuth(pqmUser, pqmPasswd).Collector(metricCounter)
}
var metricCounter = prometheus.NewCounterVec(prometheus.CounterOpts{ Namespace: nameSpace, Name: "metric_name", Help: "Total number of metrics",
}, []string{"metric_1", "metric_2"},
)func CollectTotalMetrics(metric1, metric2 string) { metricCounter.WithLabelValues(metric1, metric2).Inc() if err := Pusher.Push(); err != nil { bizlog.Errorf("Push metrics: %v error: %s", metricCounter, err) }
}
5.2 日志收集
日志的收集可以直接使用 Amazon CloudWatch,也可以使用自定义的方式。我们可以使用 Lambda 的外部扩展的功能,将日志收集进程运行在外部扩展中,随着 Lambda 的运行,外部扩展也会开始运行,将日志收集到远端服务,随着 Lambda 的停止,外部扩展也会随之停止
5.3 流量迁移
上述部分都确认之后,我们可以开始流量的迁移,流量切换的安排必须保证顺利上线且风险可控。
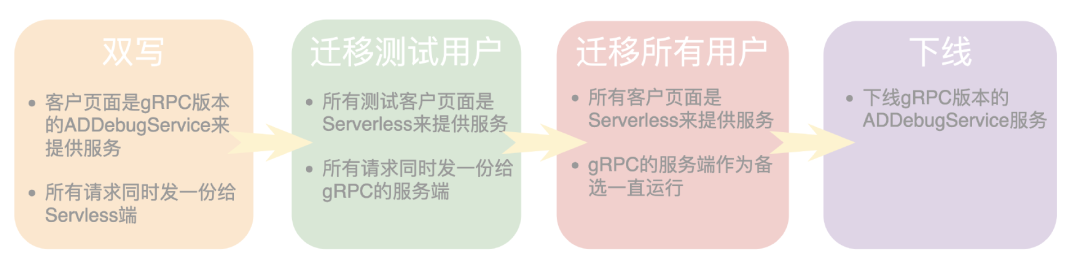
Step1 双写
首先,我们需要保证所有请求在 gRPC 服务和 Serverless 服务返回的结果是一致的,所以我们需要对于同一个请求获取两份响应结果。而 AD Debug Service 的特别之处在于对于同一个请求,不同时刻的响应结果是不一样的,所以我们需要尽可能同一时间发出两个请求才获得来自两个终端的结果才能做比对。
因此,我们上线了“双写“方案,也就是客户的页面依然是 gRPC 版本的 AD Debug Service 来提供服务,但是会同时发一个请求给 Serverless 端,用来对同样的请求在“尽可能同一时刻“提供服务,来方便校验。
Step2 迁移测试用户
先将所有测试用户的流量切换到 Serverless 服务,观察一段时间,可以暴露一些问题,如果运行顺畅,那么我们进行到下一阶段。
Step3 迁移所有用户
将所有用户的流量迁移到 Serverless 服务,但是保留 gRPC 版本的 AD Debug Service 服务作为备选。
在这个阶段,我们采用了新的 A/B 测试策略,一旦出现紧急问题,可以通过用户参数(通过 ENG 控制的)操作来切换到原来的服务。
整个页面默认使用 Serverless 服务,但如果想切换到的原来版本的 AD Debug Service,可以通过更新用户的某个参数,然后重刷页面即可。
Step4 gRPC 版本服务
将 gRPC 版本的 AD Debug Service 服务下线。
总结
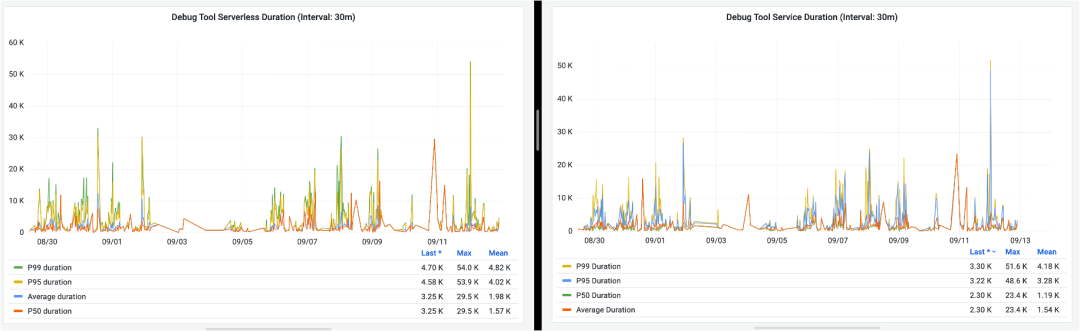
经过上述的一系列过程之后,我们可以将 gRPC 微服务逐步迁移到 Serverless 服务,并且通过一段时间的监控,我们发现响应时间上的差异在我们可接受的范围之内。以下是记录的某一个用户的某一种请求在近 3 天之内两种响应时长的对比,左边是 Serverless 模式下的响应时间,右边的 gRPC 模式下的响应时间:
P95 的请求响应时长如下图所示:
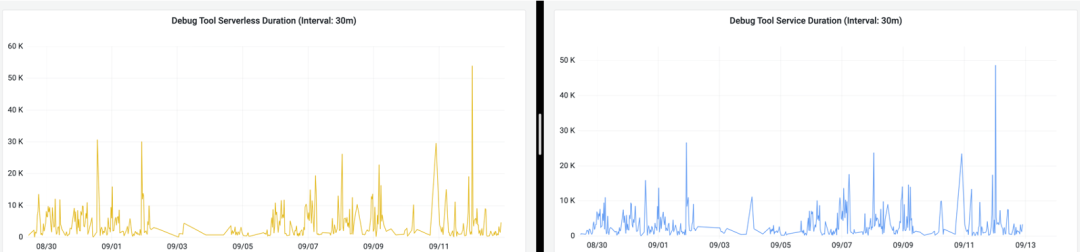
可以看出,Serverless 的响应时长可能会比 gRPC 服务的响应时长多几秒,导致这种情况的很大一部分原因在于,前面我们也提到过,我们的 AD Debug Service 会调用很多别的服务获取相应的结果,而我们的其他服务现阶段还在 EKS 的集群中,这里的调用时长势必会比 gRPC 的 AD Debug Service 在 EKS 里直接调用要更长一些,等后续别的服务陆续迁移之后,响应时长应该也会有所减少。
并且也记录到我们每次重启 Lambda 的时候用来初始化应用所用到时间也是很短的,基本都在 10ms 以内完成:

同时也可以监控到这段时间内的费用对比如下:

注:因为我们的 Domain Service 部署在一个 EKS 集群内,因此没法给每个 pod 单独计费,所以 AD Debug Service 部分的花费是根据 pod 的平均花费做的估计。
从上面表格可以看出来,迁移到 Serverless 之后的花费减少了 99% 以上。

文章来源:
https://dev.amazoncloud.cn/column/article/6551e333a0321109d83179c3?sc_medium=regulartraffic&sc_campaign=crossplatform&sc_channel=CSDN