据外媒爆料,亚马逊正在训练他的第二个大语言模型——Olympus,很有可能在今年12月份上线。亚马逊计划将Olympus接入在线零售商店、Echo等设备上的Alexa语音助手,并为AWS平台提供新的功能。据说这个大语言模型规模达到2万亿(2000B)参数,远远超过GPT-4(爆料显示GPT-4的参数约为1万亿)。

早在今年4月13日,亚马逊宣布推出Amazon Bedrock服务和Amazon Titan大语言模型。继微软和谷歌之后,亚马逊也加入生成式AI竞赛中。
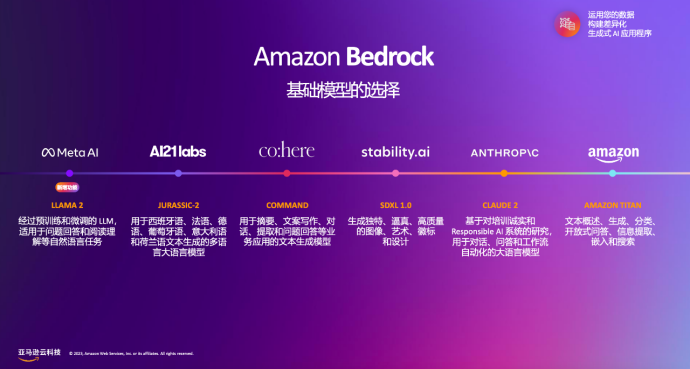
Amazon Titan基础模型目前包括了两个全新的大语言模型。
第一个是针对总结、文本生成(如原创博客)、分类、开放式问答和信息提取等任务的生成式大语言模型。
第二个是文本嵌入(embeddings)大语言模型,能够将文本输入(字词、短语甚至是大篇幅文章)翻译成包含语义的数字表达(即embeddings 嵌入编码)。
AWS 副总裁 Bratin Saha 在接受采访时表示,亚马逊非常关心准确性并确保其Titan大语言模型产生高质量的响应。
客户将能够使用自己的数据定制 Titan 大语言模型。但另一位副总裁表示,这些数据永远不会用于训练 Titan 大语言模型,以确保包括竞争对手在内的其他客户最终不会从这些数据中受益。
不过,在今年的这场人工智能竞赛中,亚马逊并不属于第一梯队。尽管亚马逊已经训练了Titan等较小的大语言模型,并且它还与Anthropic和AI21 Labs等人工智能模型初创公司合作,并将这些大语言模型提供给亚马逊云科技(AWS)。但是缺乏自有的真正大规模的大语言模型对亚马逊来说始终是个问题。

面对这即将到来的人工智能新时代,一个拥有全球数亿用户的购物平台训练属于自己的大语言模型,会为自己和用户创造难以估量的巨大价值。
首先,训练直到拥有自己的大语言模型可以帮助亚马逊改进其产品和服务,例如智能语音助手、自然语言理解系统等,从而提高用户体验。
其次,拥有大语言模型还可以为亚马逊提供更多的数据支持,使其在自然语言处理、语义理解和对话系统等方面取得更好的结果。
此外,拥有大语言模型还可以增强亚马逊在人工智能领域的技术实力,并为未来的创新和发展奠定基础。
同时,通过训练自己的大语言模型,亚马逊还可以更加灵活地控制数据隐私和安全,以保护用户的信息。
总的来说,拥有自有的大语言模型可以使其产品在AWS上更具吸引力,也能确保信息的安全性。

Olympus的出现将成为一个明确的信号:亚马逊希望在AI时代开发属于自己的大语言模型,不在关键技术上依赖他人,这对亚马逊来说具有重要的战略意义和技术意义。

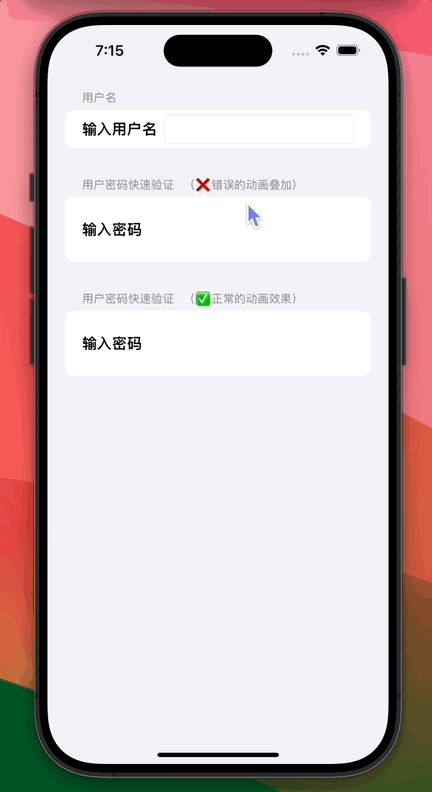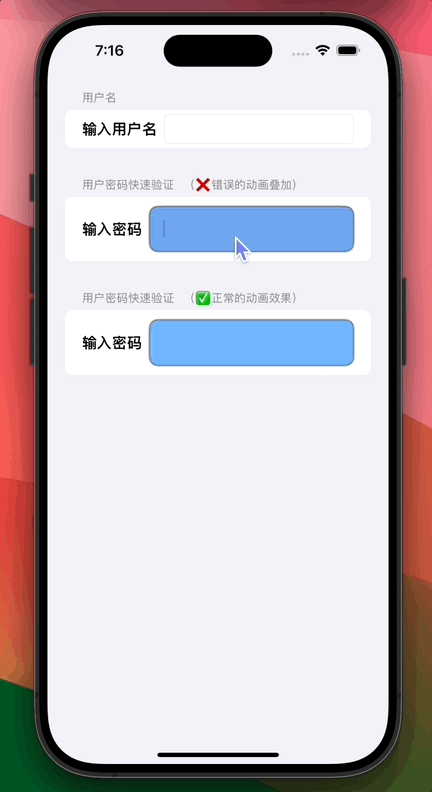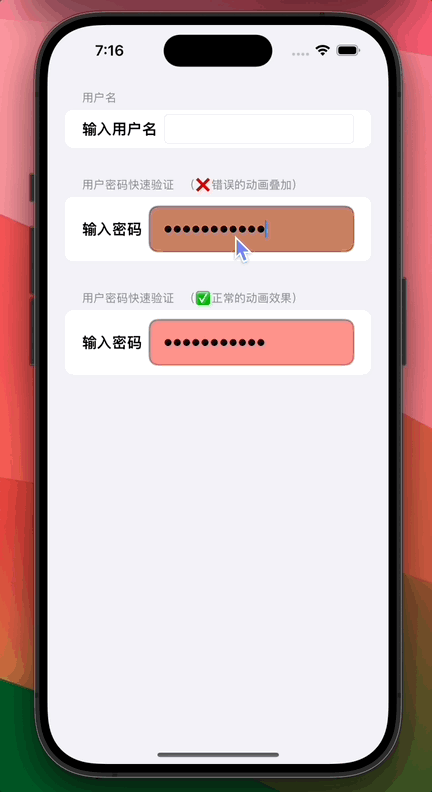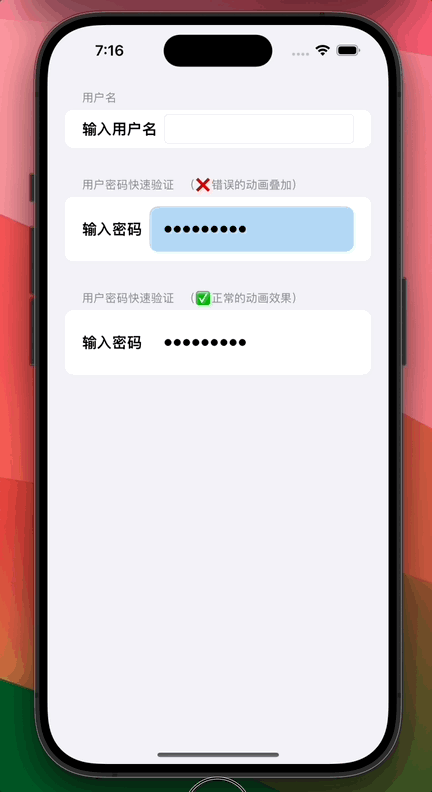
![[vxe-table] expandAll:true 当table数据更新后无法展开,只有第一次能展开才能生效的问题](https://img-blog.csdnimg.cn/09fc97e1c7414eedb26f6612e35dc750.png)